Mastering the characteristics of different data structures allows you to use appropriate data structures to deal with different problems, achieving twice the result with half the effort.
So this time we introduce the characteristics of various data structures in detail, hoping that you can master them.
intensive reading
array
Arrays are very commonly used. It is a continuous memory space, so it can be directly accessed according to the subscript, and its search efficiency is O(1).
However, the insertion and deletion efficiency of the array is low, only O(n). The reason is that in order to maintain the continuity of the array, some operations must be performed on the array after insertion or deletion: for example, to insert the Kth element, the following elements need to be moved back ; To delete the Kth element, you need to move the following elements forward.
linked list

The linked list was invented to solve the array problem. It improves the efficiency of insertion and deletion at the expense of search efficiency.
The insertion and deletion efficiency of the linked list is O(1), because the insertion and deletion can be completed as long as the corresponding element is disconnected and reconnected, without caring about other nodes.
The corresponding search efficiency is low, because the storage space is not continuous, so it cannot be directly searched through subscripts like an array, but needs to be continuously searched through pointers, so the search efficiency is O(n).
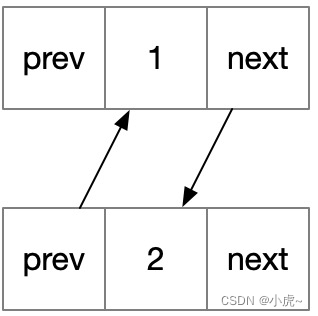
By the way, a linked list can be .prev transformed into a doubly linked list by adding attributes, or .next a binary tree ( .left .right) or a multi-fork tree (N .next) can be formed by defining two.
the stack
A stack is a first-in, last-out structure that can be simulated with an array.
const stack: number[] = [] // push stack.push(1) // pop out stack.pop()
heap
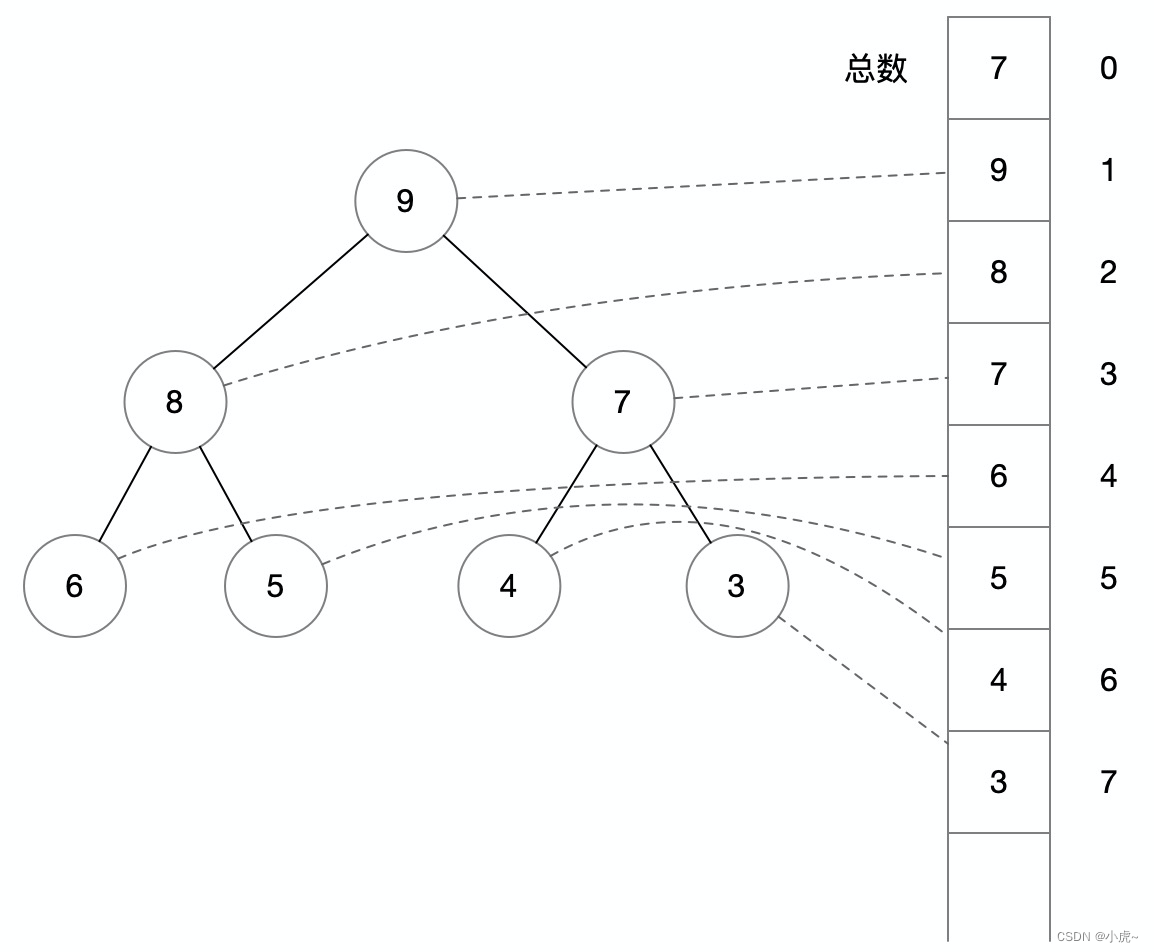
A heap is a special complete binary tree, which is divided into a large top heap and a small top heap.
The big top heap means that the root node of the binary tree is the largest number, and the small top heap means that the root node of the binary tree is the smallest number. For the convenience of explanation, the following is an example of a large top heap, and the logic of the small top heap can be just the opposite.
In the big top heap, any node is larger than its leaf node, so the root node is the largest node. The advantage of this data structure is that the maximum value can be found with O(1) efficiency (small top stack to find the minimum value), because the stack[0] root node is taken directly.
Here is a little mention of the mapping between the binary tree and the array structure, because using the array method to operate the binary number has advantages in both operation and space: the first item stores the total number of nodes, and for a node whose subscript is K, its parent node subscript Yes floor(K / 2), the subscripts of its child nodes are respectively K * 2, K * 2 + 1, so the parent and child positions can be quickly located.
Using this feature, the efficiency of insertion and deletion can be achieved O(logn), because the order of other nodes can be adjusted by moving up and down, and for a complete binary tree with n nodes, the depth of the tree is logn.
hash table
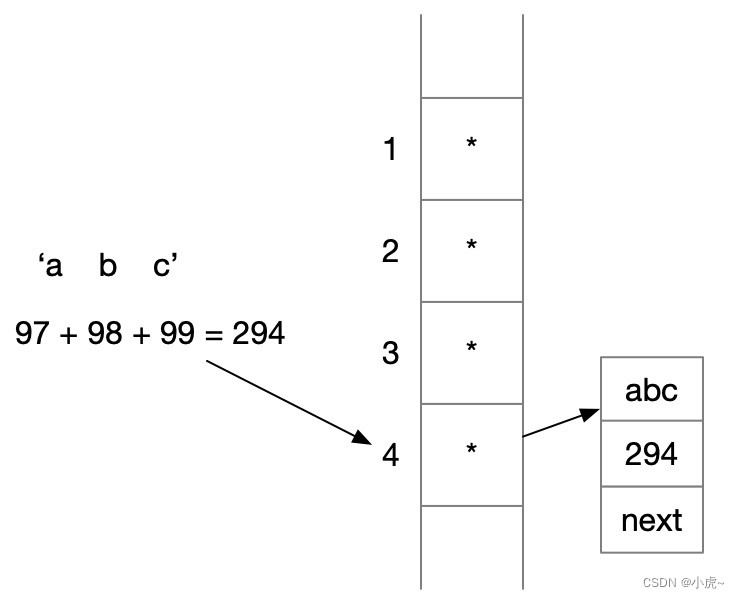
The hash table is the so-called Map. Different Maps are implemented in different ways. The common ones are HashMap, TreeMap, HashSet, and TreeSet.
Among them, the implementation of Map and Set is similar, so we take Map as an example to explain.
First find the ASCII code value of the character to be stored, and then locate the subscript of an array according to methods such as the remainder. The same subscript may correspond to multiple values, so this subscript may correspond to a linked list, and further search according to the linked list , this method is called the zipper method.
If the stored value exceeds a certain number, the query efficiency of the linked list will be reduced, and it may be upgraded to a red-black tree storage. In short, the efficiency of adding, deleting, and checking is 100%, but the disadvantage is that its content is out of order O(1).
In order to ensure that the content is in order, you can use tree structure storage, this data structure is called HashTree, so the time complexity degenerates to O(logn), but the advantage is that the content can be in order.
Trees & Binary Search Trees

A binary search tree is a special kind of binary tree, and there are more complex red-black trees, but I won’t go into depth here, only introducing a binary search tree.
The binary search tree satisfies that for any node, left 的所有节点 < 根节点 < right 的所有节点, note that here are all nodes, so all situations need to be considered recursively when judging.
The advantage of a binary search tree is that the time complexity of access, search, insertion, and deletion is O(logn), because any operation can be performed in a binary manner. But in the worst case, it will be degraded to O(n). The reason is that after multiple operations, the binary search tree may no longer be balanced, and finally degenerates into a linked list, which becomes the time complexity of the linked list.
Better solutions include AVL tree, red-black tree, etc. The binary search tree implemented by JAVA and C++ standard library is all red-black tree.
dictionary tree
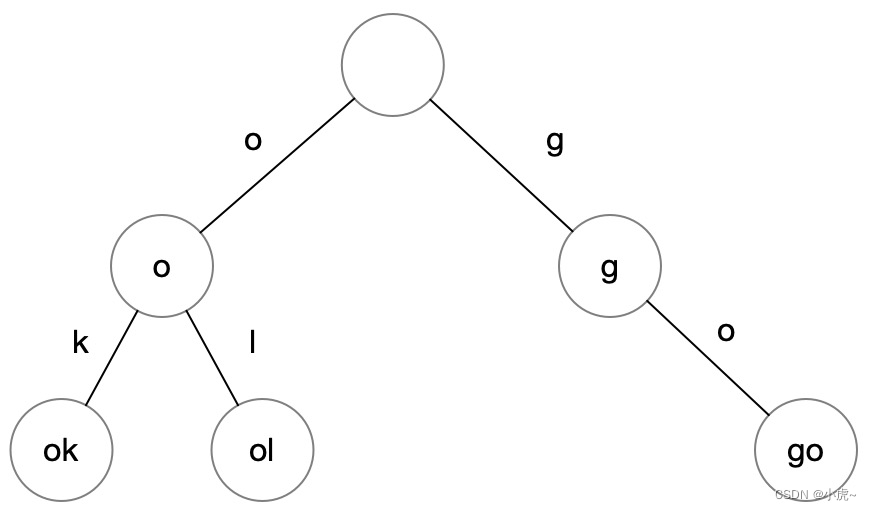
The dictionary tree is mostly used in word search scenarios. As long as a single beginning is given, several recommended words can be quickly found.
For example, in the above example, if you input "o", you can quickly find the words "ok" and "ol" behind it. It should be noted that each node must have an attribute isEndOfWord indicating whether it is a complete word so far: for example, go both good are complete words, but goo not, so the second o and fourth d have isEndOfWord marks, indicating After reading here, you can find a complete word, and the mark of the leaf node can also be omitted.
And lookup
And the check set is used to solve the gang problem, or the island problem, that is, to judge whether multiple elements belong to a certain set. The English for Union and Find is Union and Find, that is, merge and search. Therefore, the Union and Find data structure can be written as a class, providing two basic methods and union methods find.
Among them, union any two elements can be placed in a collection, and find it is possible to find which root collection any element belongs to.
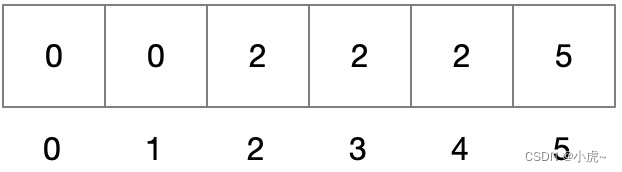
And check uses the data structure of the array, but it has the following special meaning, set the subscript as k:
nums[k]Indicates the collection it belongs to, ifnums[k] === kit means it is the root node of this collection.
If you want to count how many sets there are, you only need to count how many satisfy the nums[k] === k conditions. Just like counting how many gangs there are, you only need to count how many bosses there are.
The implementation of the union search is different, and the data will also be subtly different. When inserting an efficient union search, it will recursively point the value of the element to the root boss as much as possible, so that the calculation of the search and judgment will be faster, but even if it does not point to the root Boss, you can also find the root boss recursively.
bloom filter
Bloom Filter is just a filter, which can eliminate the missing data much faster than other algorithms, but the unexcluded data may not actually exist, so further query is required.
How does a Bloom filter do this? It is through binary judgment.
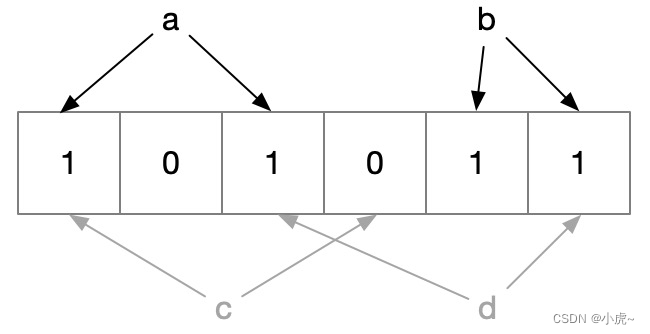
As shown in the figure above, we first store the two data of a and b, convert them into binary, and change the corresponding position to 1, then when we query a or b again, because the mapping relationship is the same, the result is definitely exist.
But when querying c, one item is found to be 0, indicating that c must not exist; but when querying d, both of them are found to be 1, but actually d does not exist, which is the reason for the error.
Bloom filters are widely used in Bitcoin and distributed systems. For example, if Bitcoin inquires whether the transaction is on a certain node, first use the Bloom filter to block it to quickly skip unnecessary searches, while distributed systems Calculations such as Map Reduce also quickly filter out calculations that are not at a certain node through the Bloom filter.
Summarize
Finally, the average and worst time complexity diagrams of each data structure "access, query, insert, delete" are given:

This picture comes from bigocheatsheet , you can also click on the link to visit directly.
After learning these basic data structures, I hope you can master them and be good at combining these data structures to solve practical problems. At the same time, you must also realize that no data structure is omnipotent, otherwise there will not be so many data structures to learn. Just use a universal data structure.
For the combination of data structures, I give two examples:
The first example is how to query the maximum or minimum value of a stack in O(1) average time complexity. At this time, one stack is not enough, and another stack B is needed to assist. When a larger or smaller value is encountered, it is pushed into stack B, so that the first number of stack B is the largest or smallest value in the current stack, and the query efficiency It is O(1), and it needs to be updated only when it is popped, so the overall average time complexity is O(1).
The second example is how to improve the search efficiency of the linked list. You can use the hash table to quickly locate the position of any value in the linked list through the combination of the hash table and the linked list, and use the hash table to quickly locate the position of the linked list, and you can double the space. The time complexity of insertion, deletion, and query is O(1) in exchange for sacrifice. Although the hash table can achieve this time complexity, the hash table is unordered; although the HashTree is ordered, the time complexity is O(logn), so only by combining HashMap and linked list can order and The time complexity is better, but the space complexity is sacrificed.
Including the Bloom filter mentioned at the end is not used alone, it is just a firewall, which blocks some illegal data with extremely high efficiency, but what is not blocked is not necessarily legal, and further inquiries are required.
Therefore, I hope you can understand the characteristics, limitations, and combined usage of each data structure. I believe that you can flexibly use different data structures in actual scenarios to achieve the optimal solution for the current business scenario.