1. Sorting algorithm

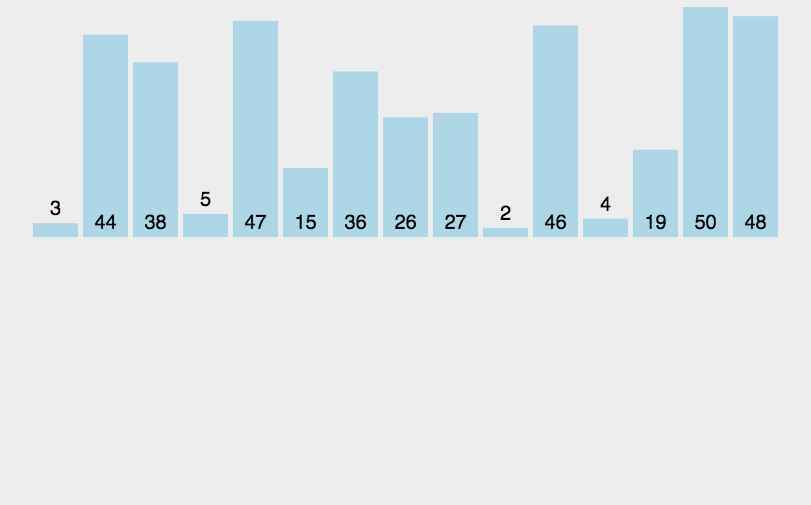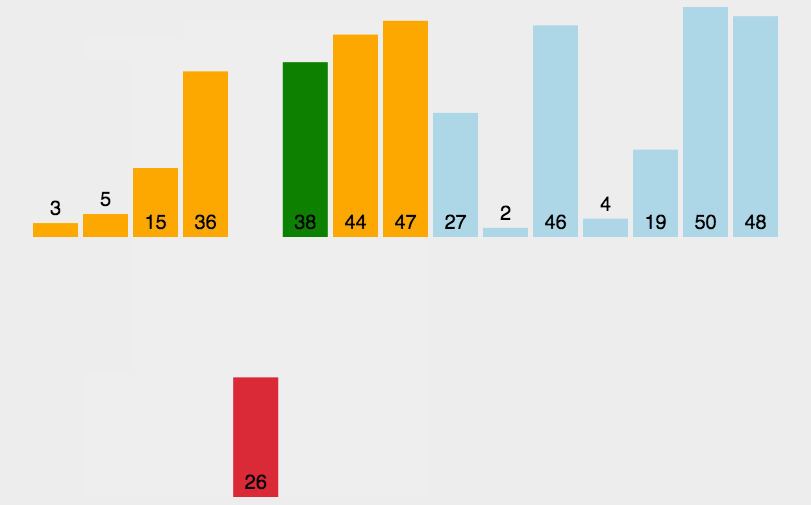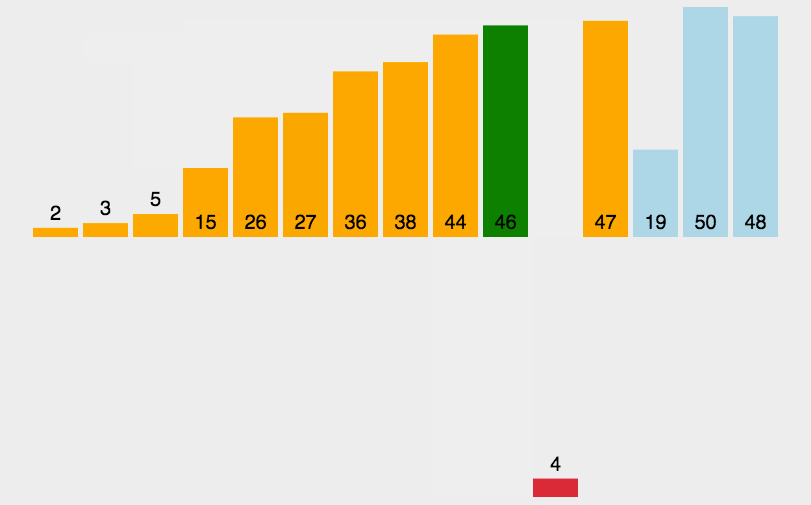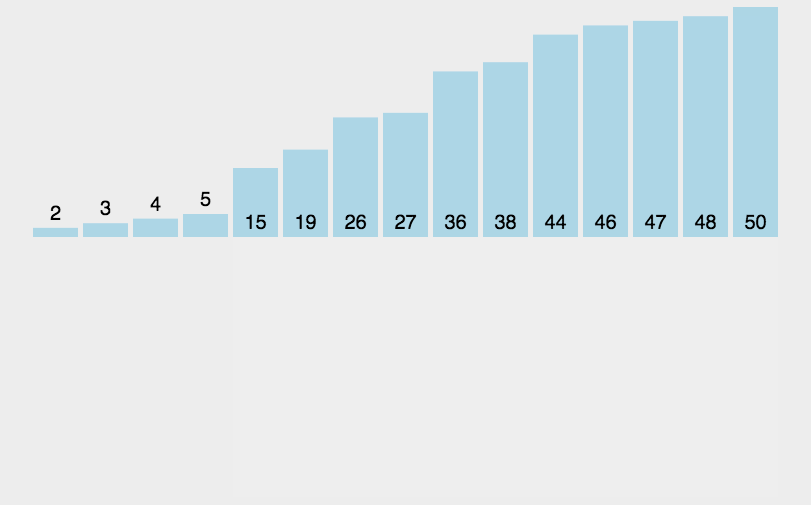
1.1 Insertion sort
//插入排序
public static void InsertionSort(int[] dataArray)
{
for (int i = 1; i < dataArray.Length; i++)
{
for (int j = i; j > 0; j--)
{
if (dataArray[j] < dataArray[j - 1])
{
int temp = dataArray[j];
dataArray[j] = dataArray[j - 1];
dataArray[j - 1] = temp;
}
else
{
break;
}
}
}
}
1.2 Selection sort
//选择排序
public static void SelectionSort(int[] dataArray)
{
for (int i = 0; i < dataArray.Length; i++)
{
for (int j = i + 1; j < dataArray.Length; j++)
{
if (dataArray[i] > dataArray[j])
{
int temp = dataArray[i];
dataArray[i] = dataArray[j];
dataArray[j] = temp;
}
}
}
}
Pick the smallest one each time
1.3 Bubble sort
//冒泡排序
public static void BubbleSort(int[] dataArray)
{
for (int i = 0; i < dataArray.Length; i++)
{
bool flag = true;
for (int j = 0; j < dataArray.Length - i - 1; j++)
{
if (dataArray[j] > dataArray[j + 1])
{
int temp = dataArray[j];
dataArray[j] = dataArray[j + 1];
dataArray[j + 1] = temp;
flag = false;
}
}
if (flag)
{
break;
}
}
}
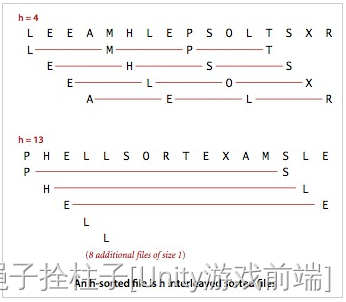
1.4 Hill sort (group insertion sort)
interval d = n, then divide infinitely by 2
public void shellsort(int[]a)
{
int d = a.Length / 2;
while(d>=1)
{
// 由于间隔d,故从0-d开始遍历一遍就全遍历了
for(int i=0;i<d;i++)
{
// 遍历的时候,加一次就加d
for(int j=i+d;j<a.Length;j+=d)
{
int temp=a[j];//存储和其比较的上一个a[x];
int loc = j;
//间隔d的插入排序
while (loc - d >= i&&temp < a[loc - d])//&&j-d>=i
{
a[loc] = a[loc - d];
loc = loc - d;
}
a[loc] = temp;
}
}
//一次插入排序结束,d缩小一半
d = d / 2;
}
}Steps:
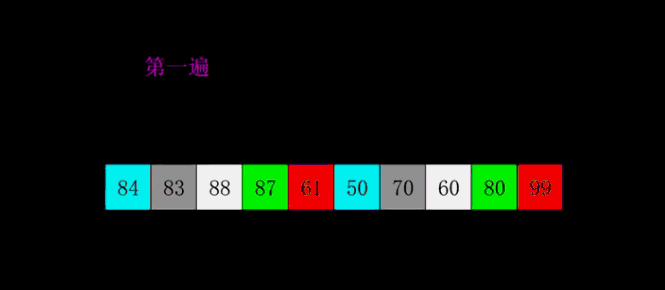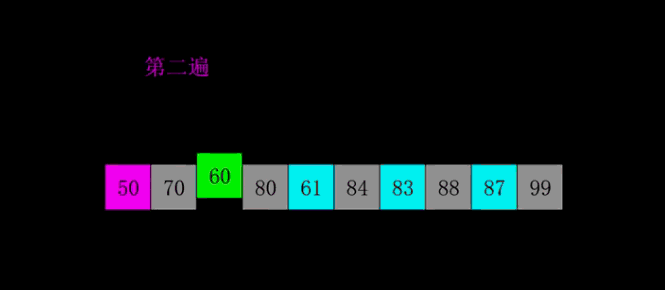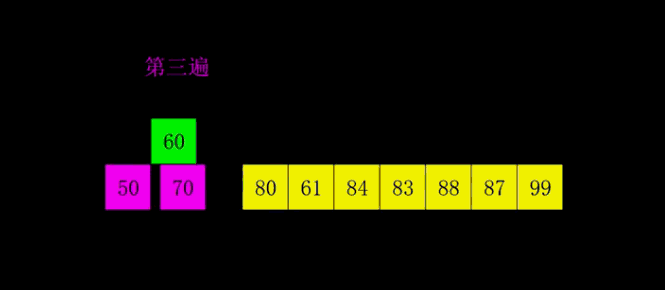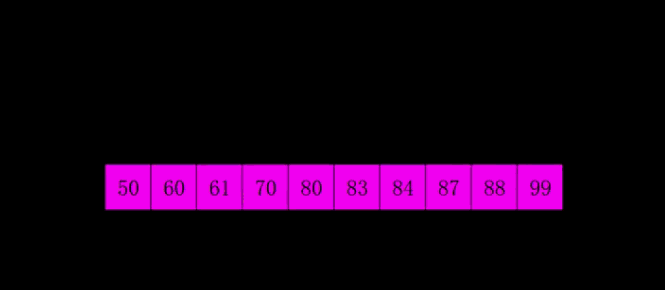
Initially, there is an unordered sequence of size 10. (N = 10)
- In the first sorting, let the increment d = N / 2 = 5, (it seems to start from shrinking in half), that is, elements with a distance of 5 form a group, which can be divided into 5 groups.
- Each group is sorted by insertion sort.
- In the second sorting, we reduce the last d by half, that is, d= d / 2 = 2 (take an integer). In this way, elements separated by a distance of 2 form a group, which can be divided into 2 groups.
- Each group is sorted by insertion sort.
- In the third sorting pass, d is reduced by half again, that is, d = d / 2 = 1. In this way, elements separated by a distance of 1 form a group, that is, there is only one group.
- Each group is sorted by insertion sort. At this point, sorting has ended.
1.5 Quick sort (requires dictation)
- First set a cutoff value , through which the array is divided into left and right parts
- All values in the right part are greater than the decomposition value and all values in the left part are smaller than the cutoff value
- Then separate the left and right sides and do quick sorting respectively
void add(int a[10],int left,int right)
{
int l=left;
int r=right;
int x=a[left];
while(r>l)
{
if(r>=l&&a[r]>=x)
r--;
a[l]=a[r];
if(r>=l&&a[l]<=x)
l++;
a[r]=a[l];
}
a[r]=x;
}
int main(int argc, char *argv[])
{
int a[10]={4,3,6,1,8,0,3,2,5,7};
add(a,0,9);
int i;
for(i=0;i<10;i++)
{
// printf("%d\t",a[i]);
Console.WriteLine(a[i]);
}
return 0;
}
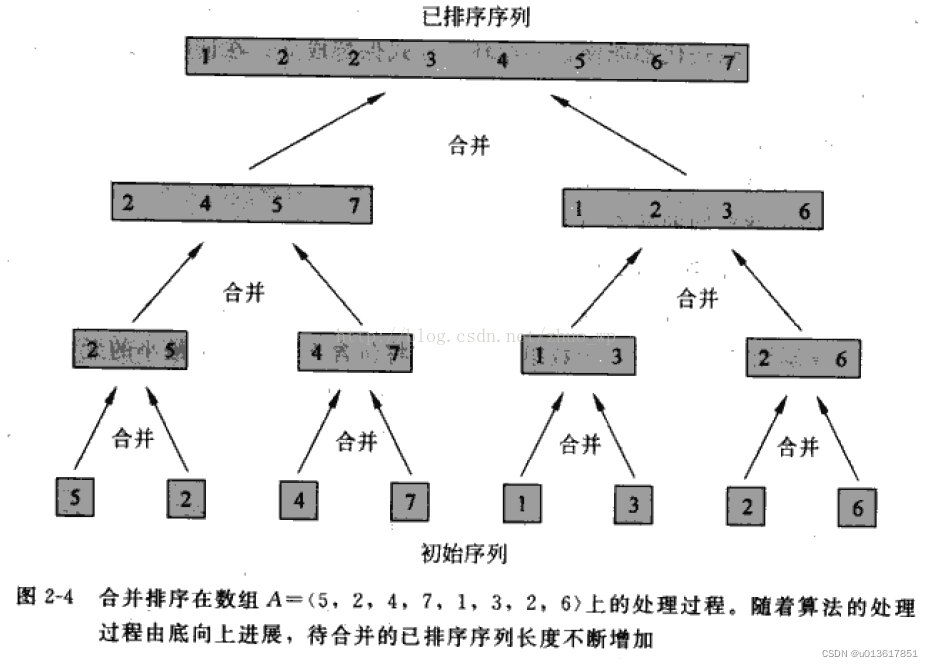
1.6 Merge sort (requires dictation)
Algorithm Description - Divide an input sequence of length n into two subsequences of length n/2;
- -Merge and sort the two subsequences respectively ;
- - Merge two sorted subsequences into a final sorted sequence .
//给外面的接口
public static void MergeSort(int[] array)
{
MergeSort(array, 0, array.Length - 1);
}
//给自己的递归接口
private static void MergeSort(int[] array, int p, int r)
{
if (p < r)
{
int q = (p + r) / 2;
MergeSort(array, p, q);
MergeSort(array, q + 1, r);
Merge(array, p, q, r);
}
}
//合并两个有序列表
private static void Merge(int[] array, int p, int q, int r)
{
int[] L = new int[q - p + 2];
int[] R = new int[r - q + 1];
L[q - p + 1] = int.MaxValue;
R[r - q] = int.MaxValue;
for (int i = 0; i < q - p + 1; i++)
{
L[i] = array[p + i];
}
for (int i = 0; i < r - q; i++)
{
R[i] = array[q + 1 + i];
}
int j = 0;
int k = 0;
for (int i = 0; i < r - p + 1; i++)
{
if (L[j] <= R[k])
{
array[p + i] = L[j];
j++;
}
else
{
array[p + i] = R[k];
k++;
}
}
}
1.7 Heap sorting (Heap Sort needs to be silently written)
Heapsort (Heapsort) refers to a sorting algorithm designed using the data structure of the heap. A heap is a structure that approximates a complete binary tree, and at the same time satisfies the nature of accumulation: that is, the key value or index of a child node is always smaller (or larger) than its parent node .
Algorithm Description
- Build the initial sequence of keywords to be sorted (R1, R2....Rn) into a large top heap, which is the initial unordered area;
- Exchange the top element R[1] with the last element R[n], and get a new unordered area (R1, R2,...Rn-1) and a new ordered area (Rn), and satisfy R [1,2...n-1]<=R[n];
- Since the new heap top R[1] after the exchange may violate the nature of the heap, it is necessary to adjust the current unordered area (R1, R2,...Rn-1) to a new heap, and then combine R[1] with the unordered area again The last element of the region is exchanged to obtain a new disordered region (R1, R2....Rn-2) and a new ordered region (Rn-1, Rn). This process is repeated until the number of elements in the ordered area is n-1, and the entire sorting process is completed.
/*
* 堆排序是一种选择排序,时间复杂度为O(nlog<sub>2</sub>n)。
*
* 堆排序的特点是:
* 在排序过程中,将待排序数组看成是一棵完全二叉树的顺序存储结构,
* 利用完全二叉树中父结点和子结点之间的内在关系,在当前无序区中选择关键字最大(或最小)的记录。
*
* 基本思想
* 1.将待排序数组调整为一个大根堆。大根堆的堆顶元素就是这个堆中最大的元素。
* 2.将大根堆的堆顶元素和无序区最后一个元素交换,并将无序区最后一个位置列入有序区,然后将新的无序区调整为大根堆。
* 3.重复操作,直到无序区消失为止。
* 初始时,整个数组为无序区。每一次交换,都是将大根堆的堆顶元素换入有序区,以保证有序区是有序的。
*/
namespace HeapSort
{
using System;
/// <summary>
/// The program.
/// </summary>
public static class Program
{
/// <summary>
/// 程序入口点。
/// </summary>
public static void Main()
{
int[] a = {1, 14, 6, 2, 8, 66, 9, 3, 0, 10, 5, 34, 76, 809, 4, 7};
Console.WriteLine("Before Heap Sort:");
foreach (int i in a)
{
Console.Write(i + " ");
}
Console.WriteLine("\r\n");
Console.WriteLine("In Heap Sort:");
HeapSort(a);
Console.WriteLine("");
Console.WriteLine("After Heap Sort:");
foreach (int i in a)
{
Console.Write(i + " ");
}
}
/// <summary>
/// 堆排序方法。
/// </summary>
/// <param name="a">
/// 待排序数组。
/// </param>
private static void HeapSort(int[] a)
{
// 建立大根堆。
BuildMaxHeap(a);
Console.WriteLine("Build max heap:");
foreach (int i in a)
{
// 打印大根堆。
Console.Write(i + " ");
}
Console.WriteLine("\r\nMax heap in each heap sort iteration:");
for (int i = a.Length - 1; i > 0; i--)
{
// 将堆顶元素和无序区的最后一个元素交换。
Swap(ref a[0], ref a[i]);
// 将新的无序区调整为大根堆。
MaxHeaping(a, 0, i);
// 打印每一次堆排序迭代后的大根堆。
for (int j = 0; j < i; j++)
{
Console.Write(a[j] + " ");
}
Console.WriteLine(string.Empty);
}
}
/// <summary>
/// 由底向上建堆。
/// 由完全二叉树的性质可知,叶子结点是从index=a.Length/2开始,
/// 所以从index=(a.Length/2)-1结点开始由底向上进行大根堆的调整。
/// </summary>
/// <param name="a">
/// 待排序数组。
/// </param>
private static void BuildMaxHeap(int[] a)
{
for (int i = (a.Length / 2) - 1; i >= 0; i--)
{
MaxHeaping(a, i, a.Length);
}
}
/// <summary>
/// 将指定的结点调整为堆。
/// </summary>
/// <param name="a">
/// 待排序数组。
/// </param>
/// <param name="i">
/// 需要调整的结点。
/// </param>
/// <param name="heapSize">
/// 堆的大小,也指数组中无序区的长度。
/// </param>
private static void MaxHeaping(int[] a, int i, int heapSize)
{
// 左子结点。
int left = (2 * i) + 1;
// 右子结点。
int right = 2 * (i + 1);
// 临时变量,存放大的结点值。
int large = i;
// 比较左子结点。
if (left < heapSize && a[left] > a[large])
{
large = left;
}
// 比较右子结点。
if (right < heapSize && a[right] > a[large])
{
large = right;
}
// 如有子结点大于自身就交换,使大的元素上移;并且把该大的元素调整为堆以保证堆的性质。
if (i != large)
{
Swap(ref a[i], ref a[large]);
MaxHeaping(a, large, heapSize);
}
}
/// <summary>
/// 交换两个整数的值。
/// </summary>
/// <param name="a">整数a。</param>
/// <param name="b">整数b。</param>
private static void Swap(ref int a, ref int b)
{
int tmp = a;
a = b;
b = tmp;
}
}
}
// Output:
/*
Before Heap Sort:
1 14 6 2 8 66 9 3 0 10 5 34 76 809 4 7
In Heap Sort:
Build max heap:
809 14 76 7 10 66 9 3 0 8 5 34 1 6 4 2
Max heap in each heap sort iteration:
76 14 66 7 10 34 9 3 0 8 5 2 1 6 4
66 14 34 7 10 4 9 3 0 8 5 2 1 6
34 14 9 7 10 4 6 3 0 8 5 2 1
14 10 9 7 8 4 6 3 0 1 5 2
10 8 9 7 5 4 6 3 0 1 2
9 8 6 7 5 4 2 3 0 1
8 7 6 3 5 4 2 1 0
7 5 6 3 0 4 2 1
6 5 4 3 0 1 2
5 3 4 2 0 1
4 3 1 2 0
3 2 1 0
2 0 1
1 0
0
After Heap Sort:
0 1 2 3 4 5 6 7 8 9 10 14 34 66 76 809
*/1.8 Radix Sort (Radix Sort)
Cardinality sorting belongs to "Distribution Sort", which distributes the elements to be sorted into certain "buckets" through partial information of the key value, so as to achieve the sorting effect. The cardinality sorting method is a stable sorting method, and its time complexity is O (n*log(r)*m) . Among them, r is the base used, and m is the number of heaps . In some cases, the efficiency of the base sorting method is higher than other stability sorting methods. (It can be understood that, first assign to the hash table according to the ones, so that their ones are in order, and then assign to the hash table according to the tens, then according to the hundreds, according to the thousands)
public int[] RadixSort2(int[] array)
{
//求最(大)值
int max = array[0];
foreach (var item in array)
{
max = item > max ? item : max;
}
int maxDigit = 0;
while(max!=0)
{
max /= 10;maxDigit++;
}
//初新桶
var bucket = new List<List<int>>();
for (int i = 0; i < 10; i++)
{
bucket.Add(new List<int>());
}
// 先按个位平铺并比较各自的大小,这样个位顺序就是正确的了,再按十位,再按百位
for (int i = 0; i < maxDigit; i++)
{
//正填充,div用来下面构成“个十百千.....位”
int div = (int)Math.Pow(10, (i + 1));
foreach (var item in array)
{
//获取基数 获取数的第几位数字
int radix = (item % div) / (div / 10);
//这一位,比如十位,添加好整个排好序的数列。
bucket[radix].Add(item);
}
//反填充(个位已经按顺序铺好了,就按个位ok的顺序弄回array)
int index = 0;
foreach (var item in bucket)
{
foreach (var it in item)
{
array[index++] = it;
}
item.Clear();//清除数据
}
}
return array;
}
2. Search algorithm
2.1 Binary search
Basic idea: elements must be in order, which belongs to the ordered search algorithm.
Note: The prerequisite for the half search is that the ordered table needs to be stored sequentially. For the static lookup table, it will not change after a sort, and the half search can get good efficiency. However, for datasets that require frequent insertion or deletion operations, maintaining an orderly sort will bring a lot of work, so it is not recommended.
public static int BinarySearch(int[] arr, int low, int high, int key)
{
int mid = (low + high) / 2;
if (low > high)
return -1;
else
{
if (arr[mid] == key)
return mid;
else if (arr[mid] > key)
return BinarySearch(arr, low, mid - 1, key);
else
return BinarySearch(arr, mid + 1, high, key);
}
}For bit operation, mid = (low + hi) >> 1; equivalent to mid = (low + hi) / 2;
Bitwise operations are faster than division operations.
2.2 Interpolation search
Basic idea: Interpolation search is an optimization of binary search. Interpolation optimizes mid to make it closer to the actual position of the search value in the ordered sequence, which is also an ordered search.
/// <summary>
/// 插值查找,是对二分法查找的优化
/// 二分法: mid = low + 1/2 *(high - low)
/// 插值查找:mid = low + ((point-array[low])/(array[high]-array[low]))*(high-low)
/// 插值优化了mid,使之更接近查找数值在有序序列的实际位置
/// </summary>
/// <param name="arr"></param>
/// <param name="low"></param>
/// <param name="height"></param>
/// <param name="value"></param>
/// <returns></returns>
private static int InterpolationSearch(int[] arr, int low, int height, int value)
{
if (arr == null || arr.Length == 0 || low >= height)
{
return -1;
}
int hi = height - 1;
int lowValue = arr[low];
int heightValue = arr[hi];
if (lowValue > value || value > heightValue)
{
return -1;
}
int mid;
while (low <= hi)
{
// 主要是这行做了特殊处理,不直接找中间,而是按比例找一个数
mid = low + ((value - lowValue) / (heightValue - lowValue)) * (hi - low);
int item = arr[mid];
if (item == value)
{
return mid;
}
else if (item > value)
{
hi = mid - 1;
}
else
{
low = mid + 1;
}
}
return -1;
}2.3 Fibonacci search
Basic idea: On the basis of binary search, it is divided according to the Fibonacci sequence.
/// <summary>
/// 斐波那契查找就是在二分查找的基础上根据斐波那契数列进行分割的。
/// 在斐波那契数列找一个等于略大于查找表中元素个数的数F[n],
/// 将原查找表扩展为长度为F[n](如果要补充元素,则补充重复最后一个元素,直到满足F[n]个元素),
/// 完成后进行斐波那契分割,即F[n]个元素分割为前半部分F[n-1]个元素,后半部分F[n-2]个元素,
/// 那么前半段元素个数和整个有序表长度的比值就接近黄金比值0.618,
/// 找出要查找的元素在那一部分并递归,直到找到。
/// middle = low + fb[k - 1] - 1
/// </summary>
private static int FbSearch(int[] arr, int value)
{
if (arr == null || arr.Length == 0)
{
return -1;
}
int length = arr.Length;
// 创建一个长度为20的斐波数列 1 1 2 3 5 8 ....
int[] fb = MakeFbArray(20);
int k = 0;
//从左向右滑动,滑动到临界点
while (length > fb[k] - 1)
{
// 找出数组的长度在斐波数列(减1)中的位置,将决定如何拆分
k++;
}
// 满足黄金比例分割
if (length == fb[k - 1])
{
return FindFbSearch(arr, fb, --k, value, length);
}
else
{
// 构造一个长度为fb[k] - 1的新数列,就是扩建原数组到斐波那契长度
int[] temp = new int[fb[k] - 1];
// 把原数组拷贝到新的数组中
arr.CopyTo(temp, 0);
int tempLen = temp.Length;
for (int i = length; i < tempLen; i++)
{
// 从原数组长度的索引开始,用最大的值补齐新数列
temp[i] = arr[length - 1];
}
//从扩建好的数组中进行斐波那契查找查找
return FindFbSearch(temp, fb, k, value, length);
}
}
private static int FindFbSearch(int[] arr, int[] fb, int k, int value, int length)
{
int low = 0;
int hight = length - 1;
while (low <= hight)
{
// 黄金比例分割点
int middle = low + fb[k - 1] - 1;
if (arr[middle] > value)
{
hight = middle - 1;
// 全部元素 = 前半部分 + 后半部分
// 根据斐波那契数列进行分割,F(n)=F(n-1)+F(n-2)
// 因为前半部分有F(n-1)个元素,F(n-1)=F(n-2)+F(n-3),
// 为了得到前半部分的黄金分割点n-2,
// int middle = low + fb[k - 1] - 1; k已经减1了
// 所以k = k - 1
k = k - 1;
}
else if (arr[middle] < value)
{
low = middle + 1;
// 全部元素 = 前半部分 + 后半部分
// 根据斐波那契数列进行分割,F(n)=F(n-1)+F(n-2)
// 因为后半部分有F(n-2)个元素,F(n-2)=F(n-3)+F(n-4),
// 为了得到后半部分的黄金分割点n-3,
// int middle = low + fb[k - 1] - 1; k已经减1了
// 所以k = k - 2
k = k - 2;
}
else
{
if (middle <= hight)
{
return middle;// 若相等则说明mid即为查找到的位置
}
else
{
return hight;// middle的值已经大于hight,进入扩展数组的填充部分,即原数组最后一个数就是要查找的数
}
}
}
return -1;
}
// 构建斐波那契数列 1 1 2 3 5 8 ....
public static int[] MakeFbArray(int length)
{
int[] array = null;
if (length > 2)
{
array = new int[length];
array[0] = 1;
array[1] = 1;
for (int i = 2; i < length; i++)
{
array[i] = array[i - 1] + array[i - 2];
}
}
return array;
}2.4 Block search
public struct IndexBlock
{
public int max;
public int start;
public int end;
};
const int BLOCK_COUNT = 3;
private static void InitBlockSearch()
{
int j = -1;
int k = 0;
int[] a = new int[] { 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15 };
IndexBlock[] indexBlock = new IndexBlock[BLOCK_COUNT];
for (int i = 0; i < BLOCK_COUNT; i++)
{
indexBlock[i].start = j + 1; //确定每个块范围的起始值
j = j + 1;
indexBlock[i].end = j + 4; //确定每个块范围的结束值
j = j + 4;
indexBlock[i].max = a[j]; //确定每个块范围中元素的最大值
}
k = BlockSearch(12, a, indexBlock);
if (k >= 0)
{
Console.WriteLine("查找成功!你要查找的数在数组中的索引是:{0}\n", k);
}
else
{
Console.WriteLine("查找失败!你要查找的数不在数组中。\n");
}
}
/// <summary>
/// 分块查找
/// 分块查找要求把一个数据分为若干块,每一块里面的元素可以是无序的,但是块与块之间的元素需要是有序的。
/// (对于一个非递减的数列来说,第i块中的每个元素一定比第i-1块中的任意元素大)
/// </summary>
private static int BlockSearch(int x, int[] a, IndexBlock[] indexBlock)
{
int i = 0;
int j;
while (i < BLOCK_COUNT && x > indexBlock[i].max)
{
//确定在哪个块中
i++;
}
if (i >= BLOCK_COUNT)
{
//大于分的块数,则返回-1,找不到该数
return -1;
}
//j等于块范围的起始值
j = indexBlock[i].start;
while (j <= indexBlock[i].end && a[j] != x)
{
//在确定的块内进行查找
j++;
}
if (j > indexBlock[i].end)
{
//如果大于块范围的结束值,则说明没有要查找的数,j置为-1
j = -1;
}
return j;
}2.5 The simplest tree table search algorithm - binary tree search algorithm
Basic idea: The binary search tree is to first generate a tree for the data to be searched, to ensure that the value of the left branch of the tree is smaller than the value of the right branch, and then compare the size with the parent node of each node on the line to find the most suitable range.
Properties of binary trees:
1) If the left subtree of any node is not empty, the values of all nodes on the left subtree are less than the value of its root node; 2) If the right subtree of any node is not
empty, then all nodes on the right subtree The value of the node is greater than the value of its root node;
3) The left and right subtrees of any node are also binary search trees.
using System;
using System.Collections.Generic;
namespace StructScript
{
public class BinaryTree<T>
{
//根节点
private TreeNode<T> mRoot;
//比较器
private Comparer<T> mComparer;
public BinaryTree()
{
mRoot = null;
mComparer = Comparer<T>.Default;
}
public bool Contains(T value)
{
if (value == null)
{
throw new ArgumentNullException();
}
TreeNode<T> node = mRoot;
while (node != null)
{
int comparer = mComparer.Compare(value, node.Data);
if (comparer > 0)
{
node = node.RightChild;
}
else if (comparer < 0)
{
node = node.LeftChild;
}
else
{
return true;
}
}
return false;
}
public void Add(T value)
{
mRoot = Insert(mRoot, value);
}
private TreeNode<T> Insert(TreeNode<T> node, T value)
{
if (node == null)
{
return new TreeNode<T>(value, 1);
}
int comparer = mComparer.Compare(value, node.Data);
if (comparer > 0)
{
node.RightChild = Insert(node.RightChild, value);
}
else if (comparer < 0)
{
node.LeftChild = Insert(node.LeftChild, value);
}
else
{
node.Data = value;
}
return node;
}
public int Count
{
get
{
return CountLeafNode(mRoot);
}
}
private int CountLeafNode(TreeNode<T> root)
{
if (root == null)
{
return 0;
}
else
{
return CountLeafNode(root.LeftChild) + CountLeafNode(root.RightChild) + 1;
}
}
public int Depth
{
get
{
return GetHeight(mRoot);
}
}
private int GetHeight(TreeNode<T> root)
{
if (root == null)
{
return 0;
}
int leftHight = GetHeight(root.LeftChild);
int rightHight = GetHeight(root.RightChild);
return leftHight > rightHight ? leftHight + 1 : rightHight + 1;
}
public T Max
{
get
{
TreeNode<T> node = mRoot;
while (node.RightChild != null)
{
node = node.RightChild;
}
return node.Data;
}
}
public T Min
{
get
{
if (mRoot != null)
{
TreeNode<T> node = GetMinNode(mRoot);
return node.Data;
}
else
{
return default(T);
}
}
}
public void DelMin()
{
mRoot = DelMin(mRoot);
}
private TreeNode<T> DelMin(TreeNode<T> node)
{
if (node.LeftChild == null)
{
return node.RightChild;
}
node.LeftChild = DelMin(node.LeftChild);
return node;
}
public void Remove(T value)
{
mRoot = Delete(mRoot, value);
}
private TreeNode<T> Delete(TreeNode<T> node, T value)
{
if (node == null)
{
Console.WriteLine("没有找到要删除的节点: " + value);
return null;
}
int comparer = mComparer.Compare(value, node.Data);
if (comparer > 0)
{
node.RightChild = Delete(node.RightChild, value);
}
else if (comparer < 0)
{
node.LeftChild = Delete(node.LeftChild, value);
}
else
{
// 1.如果删除节点没有子节点,直接返回null
// 2.如果只有一个子节点,返回其子节点代替删除节点即可
if (node.LeftChild == null)
{
return node.RightChild;
}
else if (node.RightChild == null)
{
return node.LeftChild;
}
else
{
// 3.当左右子节点都不为空时
// 找到其右子树中的最小节点,替换删除节点的位置
TreeNode<T> tempNode = node;
node = GetMinNode(tempNode.RightChild);
node.RightChild = DelMin(tempNode.RightChild);
node.LeftChild = tempNode.LeftChild;
}
}
return node;
}
private TreeNode<T> GetMinNode(TreeNode<T> node)
{
while (node.LeftChild != null)
{
node = node.LeftChild;
}
return node;
}
// 中序遍历:首先遍历其左子树,然后访问根结点,最后遍历其右子树。
// 递归方法实现体内再次调用方法本身的本质是多个方法的简写,递归一定要有出口
public void ShowTree()
{
ShowTree(mRoot);
}
private void ShowTree(TreeNode<T> node)
{
if (node == null)
{
return;
}
ShowTree(node.LeftChild);
//打印节点数据
Console.WriteLine(node.Data);
ShowTree(node.RightChild);
}
}
public class TreeNode<T>
{
//数据
public T Data { get; set; }
//左孩子
public TreeNode<T> LeftChild { get; set; }
//右孩子
public TreeNode<T> RightChild { get; set; }
public TreeNode(T value, int count)
{
Data = value;
LeftChild = null;
RightChild = null;
}
}
}Binary tree search:
Compare the value to be searched with the value of the node, if it is less than, then search in the Left Node node; if it is greater than, then search in the Right Node node, if they are equal, update the Value.
Deletion of a binary tree:
- If the deleted node has no child nodes, delete the node directly.
- If there is only one child node, delete the node and put its child node instead of the deleted node.
- When the left and right child nodes are not empty, delete the node, and find the smallest node in its right subtree (the middle value on both sides of the tree), and replace the position of the deleted node.
Addition of binary tree:
If it is larger than its own node, add this value to the right subtree, and if it is smaller than its own node, add this value to the left subtree to recurse.
2.6 Tree table search algorithm - red-black tree
2.7 Tree table lookup algorithm - B tree and B + tree
B-tree, in general, is a binary search tree in which a node can have more than 2 child nodes . Unlike self-balancing binary search trees, B-trees optimize the read and write operations of large blocks of data for the system . The B-tree algorithm reduces the intermediate process of locating records, thereby speeding up access . Commonly used in databases and file systems.
B-tree definition:
The B tree can be seen as an extension of the 2-3 search tree, that is, it allows each node to have M-1 child nodes.
- The root node has at least two child nodes
- Each node has M-1 keys, and they are arranged in ascending order
- The value of the child node located at M-1 and M key is located between the Value corresponding to M-1 and M key
- Other nodes have at least M/2 child nodes
B+ tree definition:
The B+ tree is a modified tree of the B tree. The difference between it and the B tree is:
- A node with k child nodes must have k keys;
- Non-leaf nodes only serve as indexes, and information related to records is stored in leaf nodes.
- All the leaf nodes of the tree form an ordered linked list, and all records can be traversed in the order of key code sorting.
2.8 Tree table search algorithm - 2-3 search tree
2-3 A search tree is defined as follows:
- Either empty, or:
- 2 nodes, which store a key and corresponding value, and two nodes pointing to the left and right nodes, the left node is also a 2-3 node, all values are smaller than the key, the right node is also a 2-3 node, all The value is greater than the key.
- For 3 nodes, the node stores two keys and corresponding values, and three nodes pointing to the left, middle and right. The left node is also a 2-3 node, and all values are smaller than the smallest key among the two keys; the middle node is also a 2-3 node, and the key value of the middle node is between the two node key values ; The right node is also a 2-3 node, and all key values of the node are greater than the largest key of the two keys.
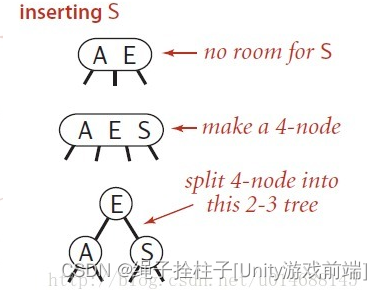
2.9 Hash Lookup
Basic idea:
A hash table is a structure that stores data in a key-value (key-indexed) manner. We only need to enter the value to be searched, namely the key, to find its corresponding value. The idea of hashing is very simple. If all the keys are integers, then a simple unordered array can be used to implement: the key is used as an index, and the value is its corresponding value, so that the value of any key can be quickly accessed . This is the case for simple keys, we extend it to handle more complex types of keys.
There are two steps to lookup using a hash:
- Converts the key being looked up to an index into an array using a hash function . In an ideal situation, different keys would be converted to different index values, but in some cases we need to deal with multiple keys being hashed to the same index value .
- The second step of the hash lookup is to deal with collisions and deal with hash collisions. There are many ways to deal with hash collision collisions, the zipper method and linear detection method will be introduced later in this article .
A hash table is a classic example of a tradeoff between time and space. If there is no memory limit, then you can directly use the key as an index into the array. Then all lookup time complexity is O(1); if there is no time limit, then we can use unordered array and do sequential lookup, which requires very little memory. Hash tables strike a balance between these two extremes using moderate amounts of time and space. You only need to adjust the hash function algorithm to make trade-offs in time and space.
2.9.1 Zipper method
Point each element of the array with size M to a linked list, and each node in the linked list stores the key-value pair whose hash value is the index.
c# algorithm implementation:
namespace StructScript
{
/// <summary>
/// 哈希表的查找算法主要分为两步:
/// 第一步是用哈希函数将键转换为数组的一个索引,理想情况下不同的键都能转换为不同的索引值,但是实际上会有多个键哈希到到相同索引值上。
/// 因此,第二步就是处理碰撞冲突的过程。这里有两种处理碰撞冲突的方法:separate chaining(拉链法)和linear probing(线性探测法)。
/// 拉链法:
/// 将大小为M 的数组的每一个元素指向一个条链表,链表中的每一个节点都存储散列值为该索引的键值对,
/// </summary>
public class HashSearch1<T>
{
private int mCount;//散列表大小
private SequentialLinkedList<T>[] mHashArr;
//这个容量是为了测试方便,应根据填充数据,确定最接近且大于链表数组大小的一个素数
//并随着数据的添加,自动扩容
public HashSearch1() : this(997) { }
public HashSearch1(int m)
{
mCount = m;
mHashArr = new SequentialLinkedList<T>[m];
for (int i = 0; i < m; i++)
{
mHashArr[i] = new SequentialLinkedList<T>();
}
}
private int HashCode(T value)
{
return (value.GetHashCode() & 0x7fffffff) % mCount;
}
public void Add(T value)
{
//如果哈希出的索引一样,则依次添加到一个相同链表中
//添加的值,如果在链表中不存在,则依次在链表中添加新的数据
int hashCode = HashCode(value);
mHashArr[hashCode].Add(value);
}
public bool Contains(T value)
{
int hashCode = HashCode(value);
return mHashArr[hashCode].Contains(value);
}
}
}Attached: The single linked list C# code used by the zipper method
using System;
using System.Collections;
using System.Collections.Generic;
namespace StructScript
{
public class SequentialLinkedList<T> : IEnumerable<T>
{
private Node fakehead = new Node(default(T), null);
private Node mFirst;
private int mCount;
public SequentialLinkedList()
{
mFirst = null;
mCount = 0;
}
public void Add(T value)
{
if (value == null)
{
throw new ArgumentNullException();
}
if (!Contains(value))
{
//这里每添加一个新的项,往前依次添加,新增项作为新的表头
//如果往后添加的话,需要遍历所有节点,在最后的位置添加新的项
mFirst = new Node(value, mFirst);
mCount++;
}
}
public bool Remove(T value)
{
if (value == null)
{
throw new ArgumentNullException();
}
fakehead.next = mFirst;
for (Node prev = fakehead; prev.next != null; prev = prev.next)
{
if (value.Equals(prev.next.value))
{
prev.next = prev.next.next;
mFirst = fakehead.next;
mCount--;
return true;
}
}
return false;
}
public void Clear()
{
for (Node current = mFirst; current != null; current = current.next)
{
Node tempNode = current;
tempNode.next = null;
tempNode.value = default(T);
}
mFirst = null;
mCount = 0;
}
public bool Contains(T value)
{
if (value == null)
{
throw new ArgumentNullException();
}
for (Node current = mFirst; current != null; current = current.next)
{
if (value.Equals(current.value))
{
return true;
}
}
return false;
}
public IEnumerator<T> GetEnumerator()
{
return new Enumerator(this);
}
IEnumerator IEnumerable.GetEnumerator()
{
return new Enumerator(this);
}
public struct Enumerator : IEnumerator<T>
{
private SequentialLinkedList<T> list;
private int index;
private T current;
private Node node;
public Enumerator(SequentialLinkedList<T> list)
{
this.list = list;
index = 0;
current = default(T);
node = list.mFirst;
}
object IEnumerator.Current
{
get
{
if (index <= 0 || index > list.Count)
{
throw new IndexOutOfRangeException();
}
return current;
}
}
public T Current
{
get
{
if (index <= 0 || index > list.Count)
{
throw new IndexOutOfRangeException();
}
return current;
}
}
public void Dispose()
{
}
public bool MoveNext()
{
if (index >= 0 && index < list.Count)
{
if (node != null)
{
current = node.value;
node = node.next;
index++;
return true;
}
}
return false;
}
public void Reset()
{
index = 0;
current = default(T);
}
}
public int Count
{
get
{
return mCount;
}
}
private class Node
{
public T value;
public Node next;
public Node(T value, Node next)
{
this.value = value;
this.next = next;
}
}
}
}2.9.2 Linear probing
Using an array of size M to hold N key-value pairs, we need to use the empty space in the array to resolve collisions.
When a collision occurs, directly check the next position in the hash table, that is, increment the index value by 1.
Linear probing, while simple, has some problems, as it leads to clustering of homogeneous hashes . There is a conflict when saving, and the conflict still exists when searching.
C# algorithm implementation:
namespace StructScript
{
/// <summary>
/// 哈希表的查找算法主要分为两步:
/// 第一步是用哈希函数将键转换为数组的一个索引,理想情况下不同的键都能转换为不同的索引值,但是实际上会有多个键哈希到到相同索引值上。
/// 因此,第二步就是处理碰撞冲突的过程。这里有两种处理碰撞冲突的方法:separate chaining(拉链法)和linear probing(线性探测法)。
/// 线性探测法:
/// 使用大小为M的数组来保存N个键值对,我们需要使用数组中的空位解决碰撞冲突
/// 当碰撞发生时即一个键的散列值被另外一个键占用时,直接检查散列表中的下一个位置即将索引值加1
/// 线性探测虽然简单,但是有一些问题,它会导致同类哈希的聚集。在存入的时候存在冲突,在查找的时候冲突依然存在
/// </summary>
public class HashSearch2<T>
{
private int mCount = 16;//线性探测表的大小
private T[] mValues;
public HashSearch2()
{
mValues = new T[mCount];
}
private int HashCode(T value)
{
return (value.GetHashCode() & 0xFFFFFFF) % mCount;
}
public void Add(T value)
{
//当碰撞发生时即一个键的散列值被另外一个键占用时,直接检查散列表中的下一个位置即将索引值加1
for (int i = HashCode(value); mValues[i] != null; i = (i + 1) % mCount)
{
//如果和已有的key相等,则用新值覆盖
if (mValues[i].Equals(value))
{
mValues[i] = value;
return;
}
//插入
mValues[i] = value;
}
}
public bool Contains(T value)
{
//当碰撞发生时即一个键的散列值被另外一个键占用时,直接检查散列表中的下一个位置即将索引值加1
for (int i = HashCode(value); mValues[i] != null; i = (i + 1) % mCount)
{
if (value.Equals(mValues[i]))
{
return true;
}
}
return false;
}
}
}quote
Data Structure and Algorithm Catalog - Short Book
Top Ten Classic Sorting Algorithms and Animation Demonstration
Algorithm - Heap Sort (C#)_LiveEveryDay's Blog-CSDN Blog
C# Data Structure - Seven Search Algorithms
Hanjiang Dudiao has a deep insight and understanding of data structures and algorithms.
Ni Shengwu's blog has a deep understanding of red-black trees, and the implementation of red-black trees in this article is based on this.