This week, I will introduce an article about graph learning on ICML2018 "Representation Learning on Graphs with Jumping Knowledge Networks".
One of the issues that this paper wants to explore is: Although the calculation method of graph convolutional neural network can adapt to graphs with different structures, its fixed hierarchical structure and the information propagation method of aggregated neighbor nodes will bring comparisons to the node expressions of different neighborhood structures. big deviation. While pointing out this problem, the author also proposed his own solution - jumping knowledge (JK) networks. The JK mechanism combined with the convolution model in the above figure has achieved state-of-art effects in various experiments.
question
The author of the article "Semi-supervised classification with graph convolutional networks" pointed out that the best effect of GCN is when the model is only two layers deep, and the effect decreases when the number of layers increases. What is the reason? The author of this article drew the following picture to illustrate this problem:
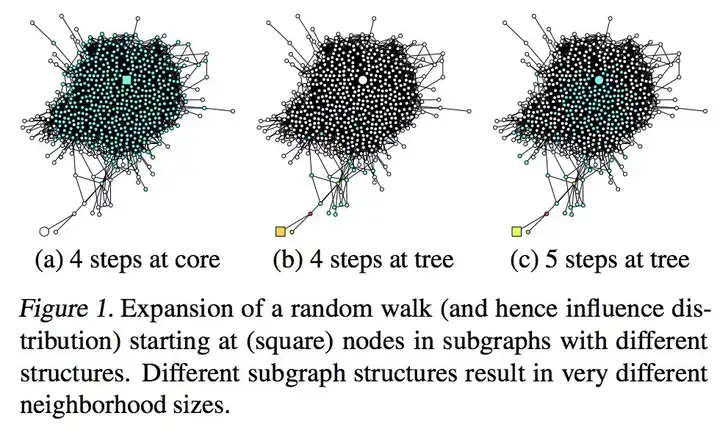
We know that the update method of GCN is to integrate the information from the first-order neighbor nodes every time, so that after updating k times, the k-hop information can be integrated. But in the graph, different nodes will have different k-hop structures. Looking at an extreme situation, in the above picture a, b, the 4-hop structure centered on the square node is completely different.
The nodes in a are in the dense core, so after updating 4 times, the node information of the entire graph can basically be integrated, which will lead to the problem of over-smooth: in GCN, every time there is an additional convolution operation, the expression of the node Both are more global, but the expression is smoother, which causes many nodes, especially those in the dense core area, to have no distinguishing expression in the end, so we cannot use too many GCN layers for such nodes;
The nodes in b are in the bounded part. Even if they are updated 4 times, there are very few nodes that are fused, which will lead to the problem of less information. For such nodes, we hope to increase the number of GCN layers to allow them to obtain more sufficient information to learn. In this way, due to the different neighborhood structures of nodes, how should we choose the number of layers of the model when GCN is modeling?
solution
In the final analysis, the essence of this problem is that some nodes need more local information, and some need more global information. The author of this article uses layer aggregation to enable the final expression of nodes to be adaptively integrated into information of different layers, local or global? Let the model learn by itself. The method is shown in the figure below:
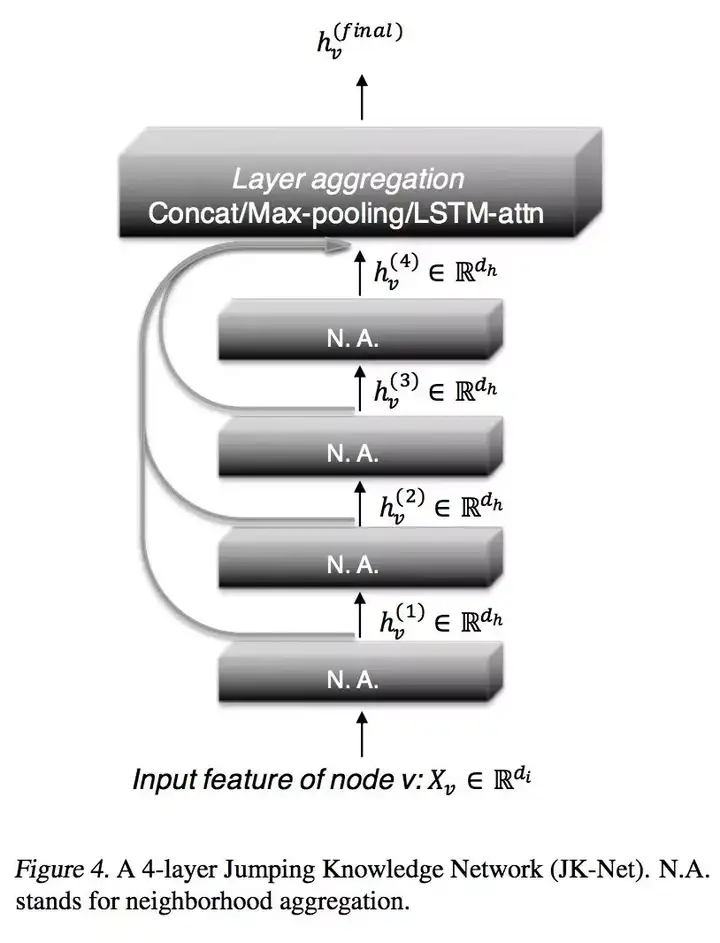
The underlying information is more local, and the high-level information is more global. The JK network will perform a fusion operation on all layers to obtain the final expression. The specific fusion methods include Concatenation, Max-pooling, and LSTM-attention :
Concatenation : Splicing the expressions of each layer together and sending them to the linear layer for classification;
Max-pooling: gather the expressions of each layer together to perform an element-wise max-pooling operation. This method does not introduce any new parameters;
LSTM-attention: This is the most complex aggregation method, learning an attention score for each layer
![]()
,at the same time
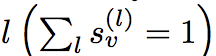
, this score represents the important coefficients of each layer. The learning of attention score is to send the expression of each layer into a bidirectional LSTM in turn, so that each layer has a forward expression
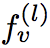
and backward expression
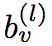
, and then splice these two expressions together and send them into a linear layer to fit a score, and then perform softmax normalization on this score to get the attention score
![]()
, and finally perform weighted summation on the expressions of each layer according to the important coefficients to obtain the final expression.
It can be seen that if this mechanism is added, GCN will have two aggregation methods at the same time. The horizontal neighbor aggregation is to learn structural information, and the vertical layer aggregation is to allow the model to selectively learn structural information. In this way, there will no longer be a problem that the GCN model cannot set a very deep number.
experiment
Like other papers, this article also conducted experiments on the following data sets:
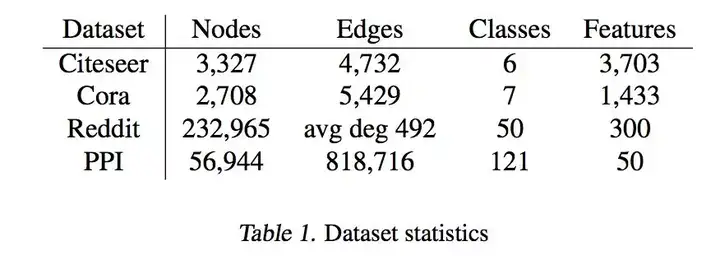
Among them, Citeseer and Cora are two data sets cited by papers, and papers are classified according to the citation relationship between bag of words and papers. Reddit is a dataset of web posts that classifies posts based on word vectors and their poster relationship. PPI is protein molecular interaction protein-protein interaction networks, which classifies protein functions.
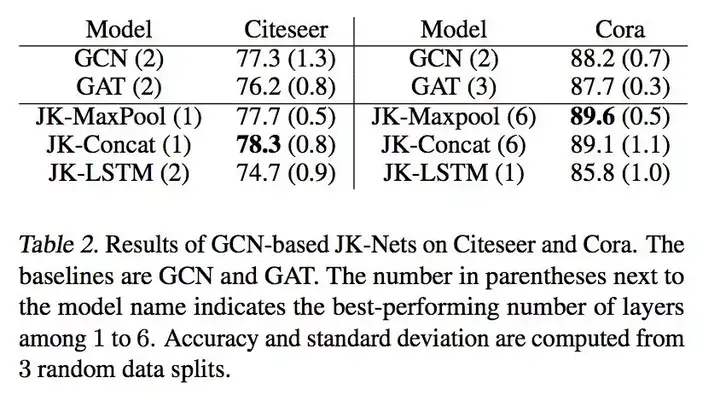
The picture above is the experimental results on Citeseer and Cora. Compared with the traditional GCN that can only use a 2-3 layer structure, the method in this paper can deepen the GCN to 6 layers, and the effect is also improved. Of course, the aggregation method of LSTM is not effective, because the two data sets are relatively small, and the complex aggregation method is easy to overfit.
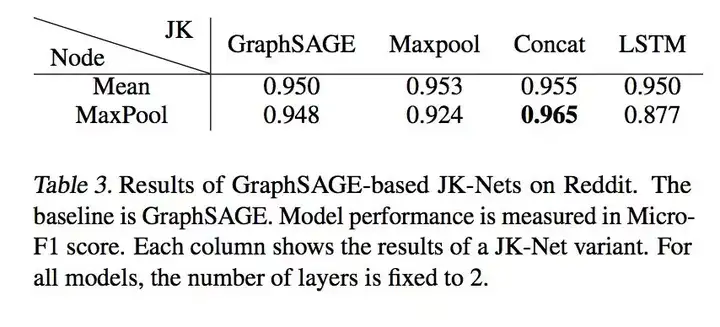
Also promoted on Reddit.
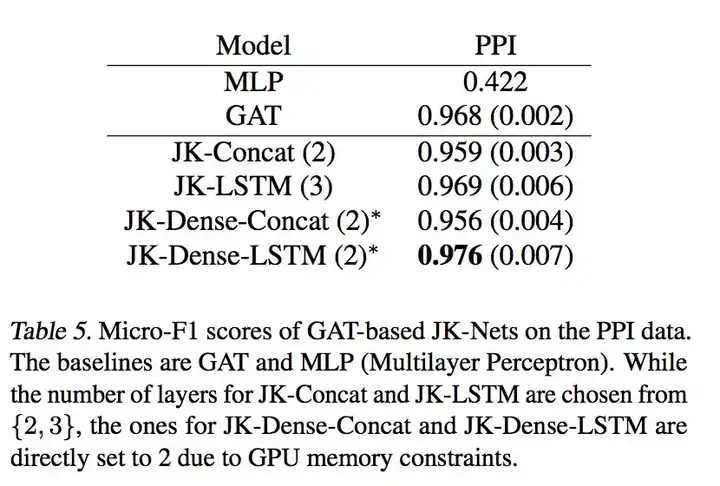
The final effect on PPI data, due to the large amount of PPI data, the complex aggregation method of LSTM has the best effect.
in conclusion
Regarding the problem of GCN, in fact, our own practice in the experiment is to solve the mechanism of adding auxiliary classifier for each layer, and the method of layer aggregation used in this paper can be regarded as a more elegant solution, which is worthy of our follow-up experiment verification.
Paper link:
http://proceedings.mlr.press/v80/xu18c/xu18c.pdfproceedings.mlr.press
For more content, welcome to follow our WeChat public account geetest_jy