Ov Seg - a Hugging Face Space by facebook Discover amazing ML apps made by the community ![]() https://huggingface.co/spaces/facebook/ov-seg https://gitee.com/leeguandong/ov-seg/blob/main/ open_vocab_seg/modeling/clip_adapter/adapter.py
https://huggingface.co/spaces/facebook/ov-seg https://gitee.com/leeguandong/ov-seg/blob/main/ open_vocab_seg/modeling/clip_adapter/adapter.py ![]() https://gitee.com/leeguandong/ov-seg/blob/main/open_vocab_seg/modeling/clip_adapter/adapter.py After dividing everything, SAM can distinguish the category again: Meta/UTAustin It is not difficult to propose a new open class segmentation model to let the model know the category of the object after segmentation.
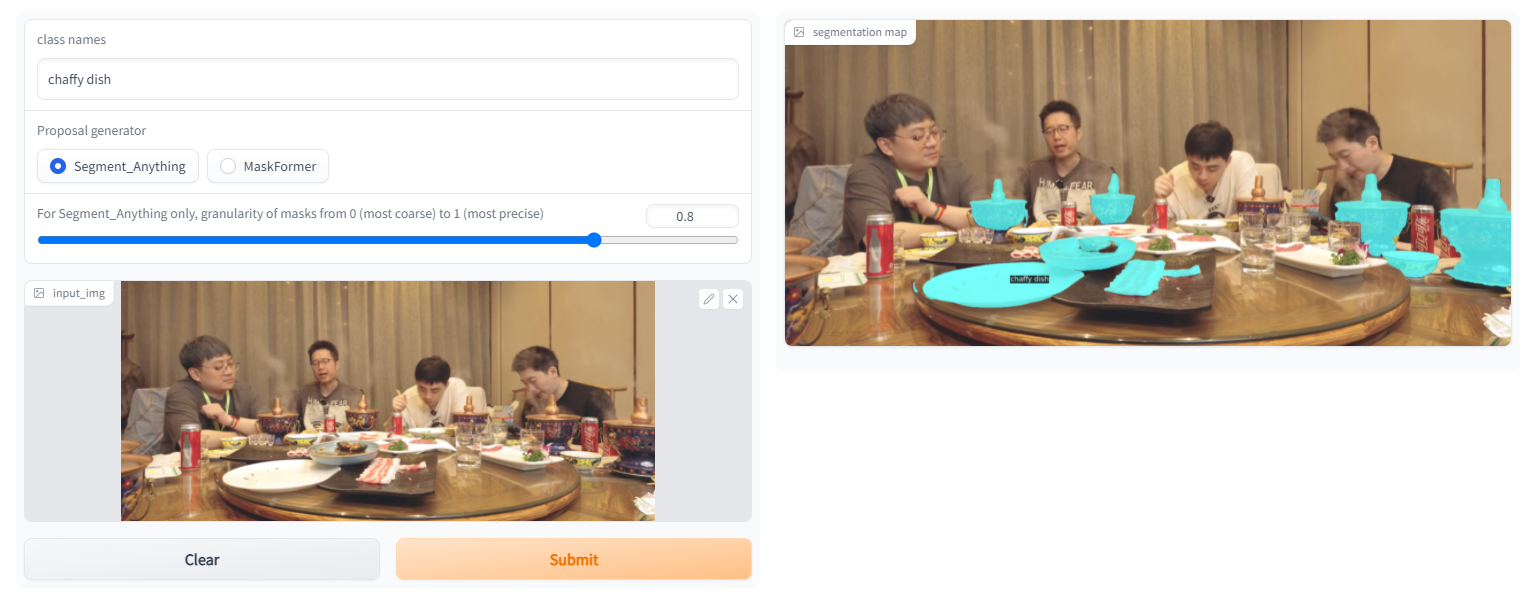
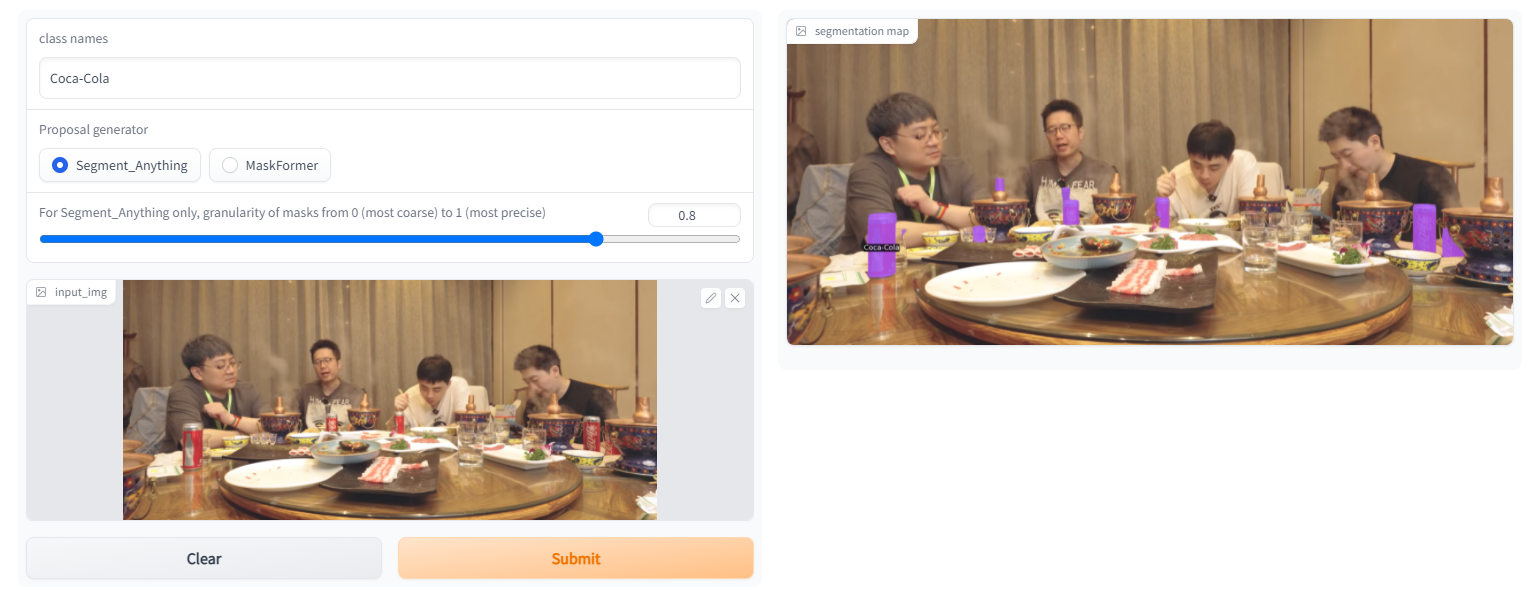
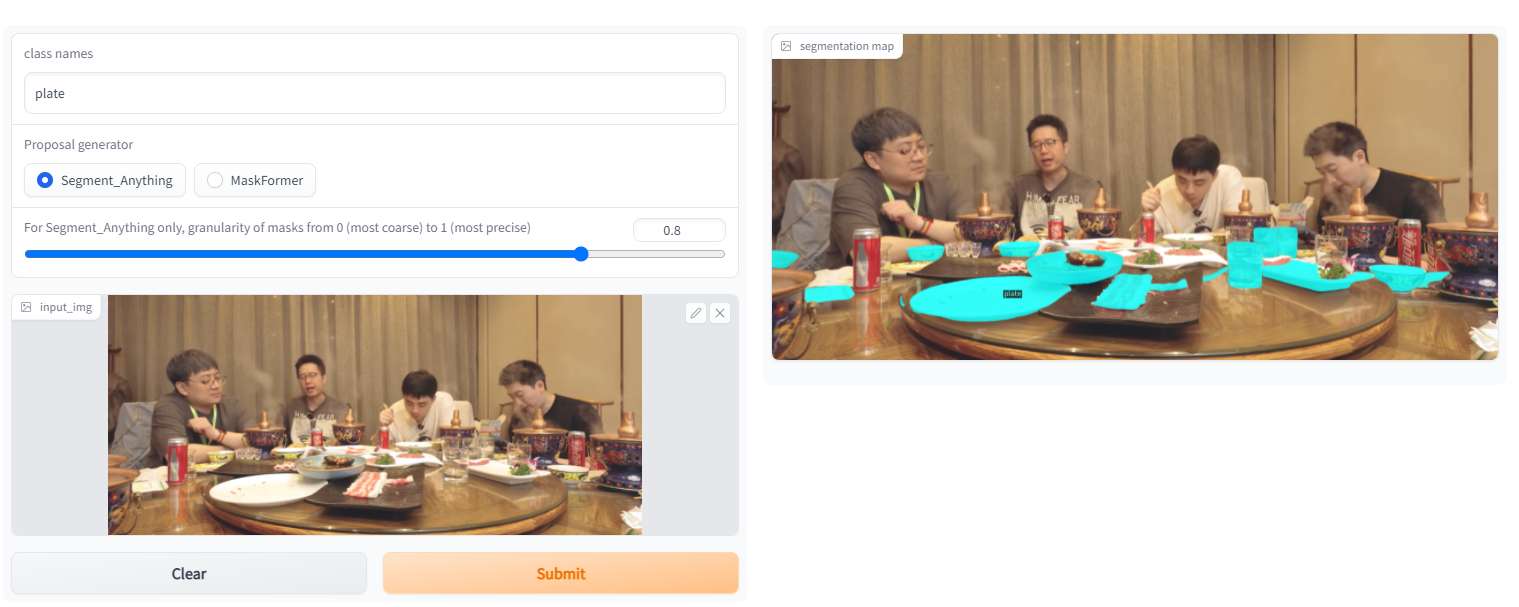
https://gitee.com/leeguandong/ov-seg/blob/main/open_vocab_seg/modeling/clip_adapter/adapter.py After dividing everything, SAM can distinguish the category again: Meta/UTAustin It is not difficult to propose a new open class segmentation model to let the model know the category of the object after segmentation. http://mp.weixin.qq.com/s?__biz=MzIwMTc4ODE0Mw==&mid=2247616891&idx=2&sn=a1dfad359c90d4e9d842230e9b1790db&chksm=96ebd6fba19c5fedd6a848caa8771840ec3a9ec c98fb7896e6358d916de94c0edba0fc409b51&mpshare=1&scene=24&srcid=04162WE9ctPSQ6qY1mDZn8VT&sharer_sharetime=1681605145081&sharer_shareid=72612fe2642f85b9e226 cd89f212cc14#rdYou can try the demo that the author put on the hugging face. The sam version in it is very strong and can handle many problems. I have received a business requirement before. Party A gave a 200 labels, basically no labeled data. I hope that some film and television Some objects in works, TV dramas and online dramas are identified, and the explosive products may be dug up and linked to the commodity chain in the future. If you use the labeled data, you don’t have to do this, but this article improves the clip, uses sam to generate the mask, and calculates the cosine similarity between the mask and the text prompt (label) to obtain the target.
1. Motivation
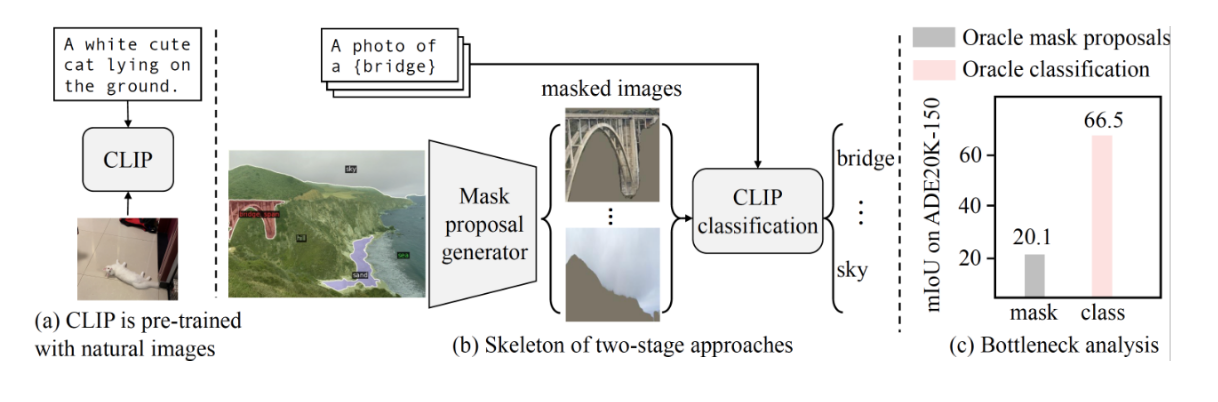
The most recent two-stage method first generates masks of different categories, and then uses clips to classify masked areas, but the current performance bottleneck is on clips, because it does not perform well on mask images. Most of the initial training clips are a picture and Corresponding to a piece of text, clip uses very little data enhancement to pre-train on natural images, and there is a huge difference between the input mask and natural images. Therefore, the author's natural idea is to fine-tune the clip.
2. Method
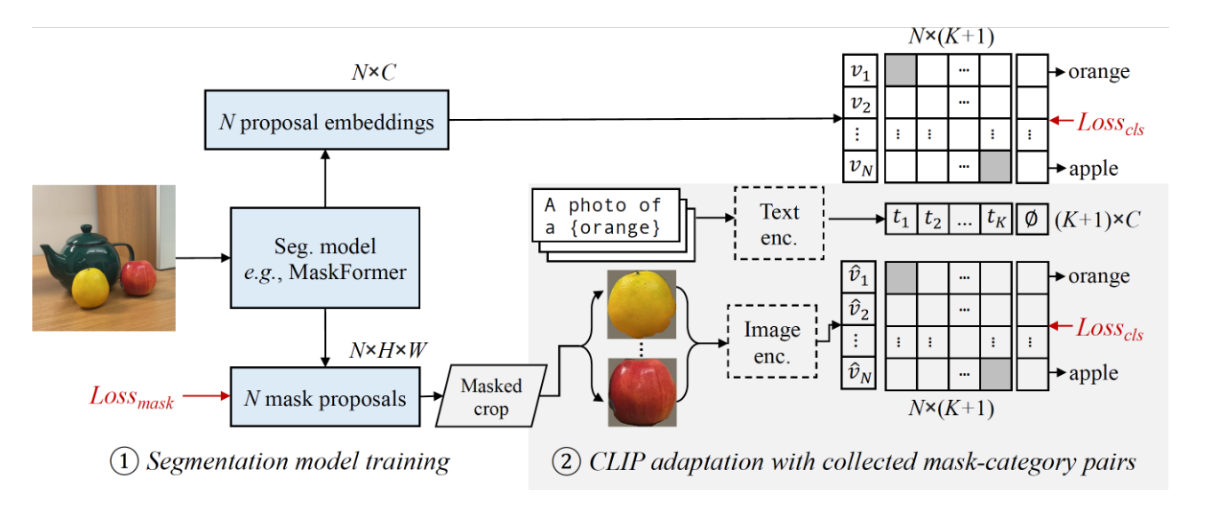
We first train the modified maskformer as a baseline for open vocabulary segmentation, and then collect diverse mask-text pairs from image captions to train clips. Mask-text data pairs can be collected from coco.
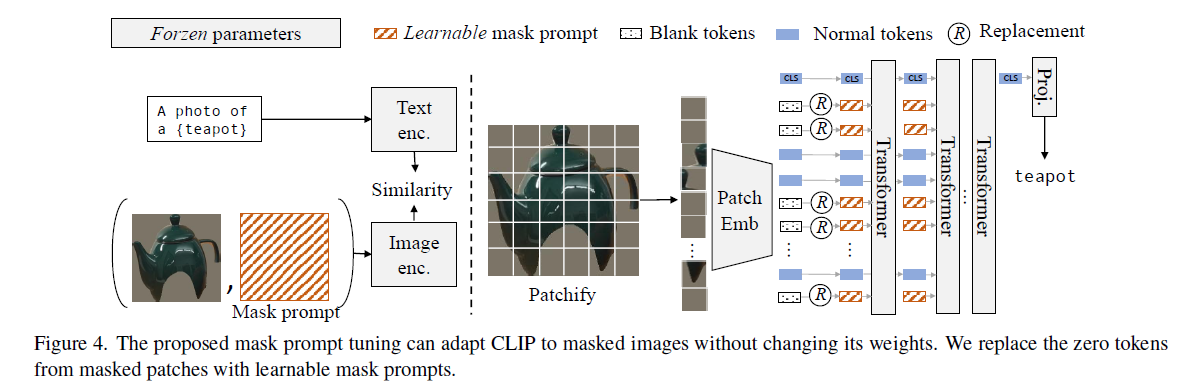
When I looked at the code, the author put the maskformer and clip together for training, but the open source on the hugging face is sam+clip, and clip must have a separate training version.
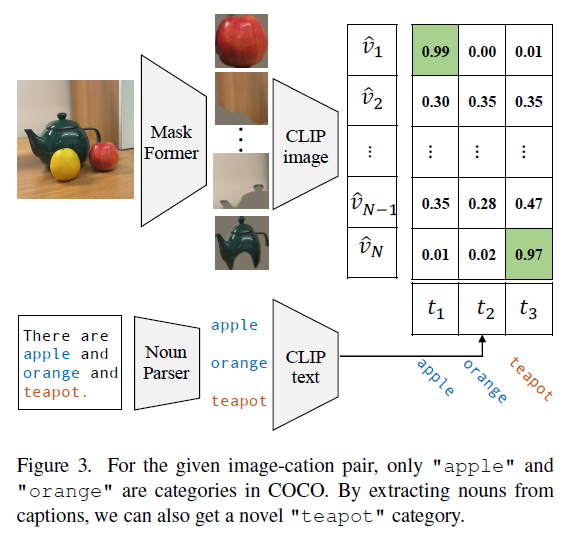
3. Code
class ClipAdapter(nn.Module):
def __init__(self, clip_model_name: str, mask_prompt_depth: int, text_templates: PromptExtractor):
super().__init__()
self.clip_model = build_clip_model(clip_model_name, mask_prompt_depth)
self.text_templates = text_templates
self.text_templates.init_buffer(self.clip_model)
self.text_feature_buffer = {}
def forward(self, image: torch.Tensor, text: List[str], **kwargs):
image = self._preprocess_image(image, **kwargs)
text_feature = self.get_text_features(text) # k,feat_dim
image_features = self.get_image_features(image)
return self.get_sim_logits(text_feature, image_features)
def _preprocess_image(self, image: torch.Tensor):
return image
def _get_text_features(self, noun_list: List[str]):
left_noun_list = [
noun for noun in noun_list if noun not in self.text_feature_buffer
]
if len(left_noun_list) > 0:
left_text_features = self.text_templates(
left_noun_list, self.clip_model
)
self.text_feature_buffer.update(
{
noun: text_feature
for noun, text_feature in zip(
left_noun_list, left_text_features
)
}
)
return torch.stack([self.text_feature_buffer[noun] for noun in noun_list])
def get_text_features(self, noun_list: List[str]):
return self._get_text_features(noun_list)
def get_image_features(self, image: torch.Tensor):
image_features = self.clip_model.visual(image)
image_features = image_features / image_features.norm(dim=-1, keepdim=True)
return image_features
def get_sim_logits(
self,
text_features: torch.Tensor,
image_features: torch.Tensor,
temperature: float = 100,
):
return temperature * image_features @ text_features.T
def normalize_feature(self, feat: torch.Tensor):
return feat / feat.norm(dim=-1, keepdim=True)The code is also very simple. When reasoning, it is to calculate the cosine value of the mask and text, and choose the largest one to return.
4. Examples