navigation:
Table of contents
1 Video transcoding requirements
1.1 Video encoding format and file format
1.2 Windows uses the encoding tool FFmpeg
1.3.1 Assembling various tool classes of FFmpeg commands
1.3.2 Mp4VideoUtil tool class, convert video to mp4 format
2.1 Introduction to Task Scheduling
2.2 Four methods of singleton task scheduling
2.2.1 Method 1: Multithreading + sleep
2.2.3 Method 3: ScheduledExecutor
2.2.5 Method 5: Task (single case recommendation)
2.3 Introduction to Distributed Task Scheduling
2.4.3 Build the executor, corresponding to the application name
2.4.4 Test, dispatch center and project new tasks, corresponding task names
2.4.5 Detailed task configuration
2.4.7 Test fragmentation and dynamic expansion
3.2 Ensure that tasks are not repeated, set policies and ensure idempotence (distributed locks)
3.3 Video processing business flow chart
4.1 Requirements, pending task list, historical task list
4.2 Add pending tasks, after the files are put into storage
4.3 Query the pending task list according to the sharding parameters and quantity limit
4.3.2 mapper, query pending task list
5.1.1 The flexible expansion of the dispatch center leads to the problem of repeated tasks
5.1.2 Three methods to realize distributed locks, database, redis, zookeeper
5.2.1 Optimistic lock implementation method
5.2.2 SQL statement, modify task status to "processing"
5.2.3 mapper, modify the task status to "processing"
5.2.4 service, modify the task status to "processing"
7 Video processing task class, @Component and @XxlJob
8 Add pending tasks after uploading video stock
9 Add executors and tasks to the dispatch center
11.1 Task compensation mechanism, periodically query and process overtime tasks
11.2 The number of failures reaches the maximum number of failures, manual processing
11.3 Periodically scan and clean up junk block files
1Video transcoding requirements
After the video is uploaded successfully, the video needs to be transcoded.
1.1 Video encoding format and file format
What is video encoding?
The so-called video encoding method refers to the method of converting the original video format file into another video format file through compression technology. The most important codec standards in video stream transmission include ITU's H.261, H.263, and H.264.
file format:
Refers to the file format of video files with different extensions such as .mp4, .avi, .rmvb, etc. The content of video files mainly includes video and audio, and the file format is encoded according to a certain encoding format, and according to the provisions of the file The encapsulation format encapsulates video, audio, subtitles and other information together, and the player will extract the code according to their encapsulation format , and then decode it by the player , and finally play the audio and video.
Audio and video encoding format:
Through audio and video compression technology, the video format is converted into another video format, and streaming media transmission is realized through video encoding.
There are several types of audio and video encoding formats:
MPEG series
(Developed by MPEG [Motion Picture Experts Group] under ISO [International Standards Organization]) Video coding is mainly Mpeg1 (vcd uses it), Mpeg2 (DVD uses it), Mpeg4 (DVDRIP uses it) variants, such as: divx, xvid, etc.), Mpeg4 AVC (hot); audio coding is mainly MPEG Audio Layer 1/2, MPEG Audio Layer 3 (the famous mp3), MPEG-2 AAC, MPEG-4 AAC, etc. wait. Note: DVD-Audio does not use Mpeg.
H.26X series
(led by ITU[International Telex Video Union], focusing on network transmission, note: only video encoding)
Including H.261, H.262, H.263, H.263+, H.263++, H.264 (the crystallization of MPEG4 AVC-cooperation)
Currently the most commonly used encoding standards are video H.264 and audio AAC.
Ask:
Is H.264 an encoding format or a file format? coding.
Is mp4 an encoding format or a file format? document.
1.2 Windows uses the encoding tool FFmpeg
After we record the video, we use video encoding software to encode the video. This project uses FFmpeg to encode the video.
FFmpeg is a set of open source computer programs that can be used to record, convert digital audio and video, and convert them into streams. Adopt LGPL or GPL license. It providesa complete solution for recording, converting and streaming audio and video .
FFmpeg is adopted by many open source projects, such as QQ Video, Baofeng Video, VLC, etc.
Download: FFmpeg Download FFmpeg
Environment variable: Add ffmpeg.exe to the environment variable path.
Test whether it is normal: cmd run ffmpeg -version
test:
To convert the nacos.avi file to mp4, run the following command:
D:\soft\ffmpeg\ffmpeg.exe -i 1.avi 1.mp4If ffmpeg.exe has been configured in the environment variable path, enter the video directory and run directly:
ffmpeg.exe -i 1.avi 1.mp4Convert to mp3:
ffmpeg -i nacos.avi nacos.mp3Convert to gif:
ffmpeg -i nacos.avi nacos.gifOfficial Documentation (English): ffmpeg Documentation
1.3 Video processing tools
1.3.1 Assembling various tool classes of FFmpeg commands
Copy the tool class to the base project.

These tool classes are written by streaming media programmers, mainly to assemble some FFmpeg commands , we can use them directly.
1.3.2 Mp4VideoUtil tool class, convert video to mp4 format
It is used to convert video to mp4 format , which is a tool class to be used in our project.
We want to transcode the video through ffmpeg, the Mp4VideoUtil tool class calls ffmpeg, and uses java.lang.ProcessBuilder to complete it, specifically in line 63 of the Mp4VideoUtil class.
The following code runs the QQ software installed on this machine:
ProcessBuilder builder = new ProcessBuilder(); builder.command("C:\\Program Files (x86)\\Tencent\\QQ\\Bin\\QQScLauncher.exe"); //将标准输入流和错误输入流合并,通过标准输入流程读取信息 builder.redirectErrorStream(true); Process p = builder.start();
Use Mp4VideoUtil tool class to convert avi video to mp4 video:
public static void main(String[] args) throws IOException {
//ffmpeg的路径
String ffmpeg_path = "D:\\soft\\ffmpeg\\ffmpeg.exe";//ffmpeg的安装位置
//源avi视频的路径
String video_path = "D:\\develop\\bigfile_test\\nacos01.avi";
//转换后mp4文件的名称
String mp4_name = "nacos01.mp4";
//转换后mp4文件的路径
String mp4_path = "D:\\develop\\bigfile_test\\nacos01.mp4";
//创建工具类对象
Mp4VideoUtil videoUtil = new Mp4VideoUtil(ffmpeg_path,video_path,mp4_name,mp4_path);
//开始视频转换,成功将返回success
String s = videoUtil.generateMp4();
System.out.println(s);
}Execute the main method, and finally output success on the console, indicating that the execution is successful.
2 Distributed task processing
2.1 Introduction to Task Scheduling
The transcoding of a video can be understood as the execution of a task. If there are a large number of videos , how to efficiently process a batch of tasks?
1. Multithreading
Multi-threading is to make full use of the resources of a single machine.
2. Distributed and multi-threaded
Take advantage of multiple computers , each using multithreading .
Option 2 is more scalable.
Scheme 2 is a processing scheme for distributed task scheduling.
Task scheduling usage scenarios:
Perform data backup tasks every 24 hours.
The 12306 website will release tickets in batches at several time points according to the number of trains.
A financial system needs to settle the bill data of the previous day before 10 am every day, and collect statistics.
After the product is successfully shipped, it is necessary to send a SMS reminder to the customer.
2.2 Four methods of singleton task scheduling
2.2.1 Method 1: Multithreading + sleep
We can start a thread, and every time we sleep for a period of time, we will check whether the expected execution time has arrived.
The following code simply implements the function of task scheduling:
public static void main(String[] args) {
//任务执行间隔时间
final long timeInterval = 1000;
Runnable runnable = new Runnable() {
public void run() {
while (true) {
//TODO:something
try {
Thread.sleep(timeInterval);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
};
Thread thread = new Thread(runnable);
thread.start();
}The above code implements the function of executing task scheduling at a certain interval.
Jdk also provides us with related support, such as Timer, ScheduledExecutor, let's understand below.
2.2.2 Method 2: Timer class
public static void main(String[] args){
Timer timer = new Timer();
timer.schedule(new TimerTask(){
@Override
public void run() {
//TODO:something
}
}, 1000, 2000); //1秒后开始调度,每2秒执行一次
}The advantage of Timer is that it is easy to use. Each Timer corresponds to a thread, so multiple Timers can be started at the same time to execute multiple tasks in parallel, and the tasks in the same Timer are executed serially.
2.2.3 Method 3: ScheduledExecutor
public static void main(String [] agrs){
ScheduledExecutorService service = Executors.newScheduledThreadPool(10);
service.scheduleAtFixedRate(
new Runnable() {
@Override
public void run() {
//TODO:something
System.out.println("todo something");
}
}, 1,
2, TimeUnit.SECONDS);
}Java 5 introduced the ScheduledExecutor based on the thread pool design. The design idea is that each scheduled task will be executed by a thread in the thread pool, so the tasks are executed concurrently and will not interfere with each other.
Both Timer and ScheduledExecutor can only provide task scheduling based on start time and repetition interval, and cannot meet more complex scheduling requirements. For example, setting tasks to be executed at 1 am on the first day of each month, managing complex scheduling tasks, transferring data between tasks, and so on.
2.2.4 Method 4: Quartz
For details, please refer to section 5-2 below. Here, only the usage of Task is written:
2.2.5 Method 5: Task (single case recommendation)
According to the characteristics of timing tasks, spring simplifies the development of timing tasks to the extreme. how to say? To do a scheduled task, you must always tell the container that it has this function, and then tell the corresponding bean when to execute the task at regular intervals. It’s that simple. Let’s see how to do it together.
Step ① : Turn on the scheduled task function , turn on the switch of the scheduled task function on the boot class, and use the annotation @EnableScheduling
@SpringBootApplication
//开启定时任务功能
@EnableScheduling
public class Springboot22TaskApplication {
public static void main(String[] args) {
SpringApplication.run(Springboot22TaskApplication.class, args);
}
}
Step ② : Define the Bean under the task package , and use the annotation @Scheduled to define the execution time above the operation corresponding to the scheduled execution. The description method of the execution time is still a cron expression
@Component
public class MyBean {
@Scheduled(cron = "0/1 * * * * ?")
public void print(){
System.out.println(Thread.currentThread().getName()+" :spring task run...");
}
}
How to configure the timing task in detail, you can do it through the configuration file
spring:
task:
scheduling:
pool:
size: 1 #任务调度线程池大小 默认 1
thread-name-prefix: ssm_ #调度线程名称前缀 默认 scheduling-
shutdown:
await-termination: false #线程池关闭时等待所有任务完成
await-termination-period: 10s #调度线程关闭前最大等待时间,确保最后一定关闭
2.3 Introduction to Distributed Task Scheduling
Task scheduling, as the name implies, is the scheduling of tasks. It refers to the automatic execution of tasks by the system based on a given time point, a given time interval, or a given number of executions in order to complete a specific business.
What is distributed task scheduling?
Usually, the task scheduling program is integrated in the application. For example, the coupon service includes a scheduler for regularly issuing coupons, and the settlement service includes a task scheduler for periodically generating reports. Due to the distributed architecture, a service We often deploy multiple redundant instances to run our business. Running task scheduling in this distributed system environment is called distributed task scheduling , as shown in the following figure:
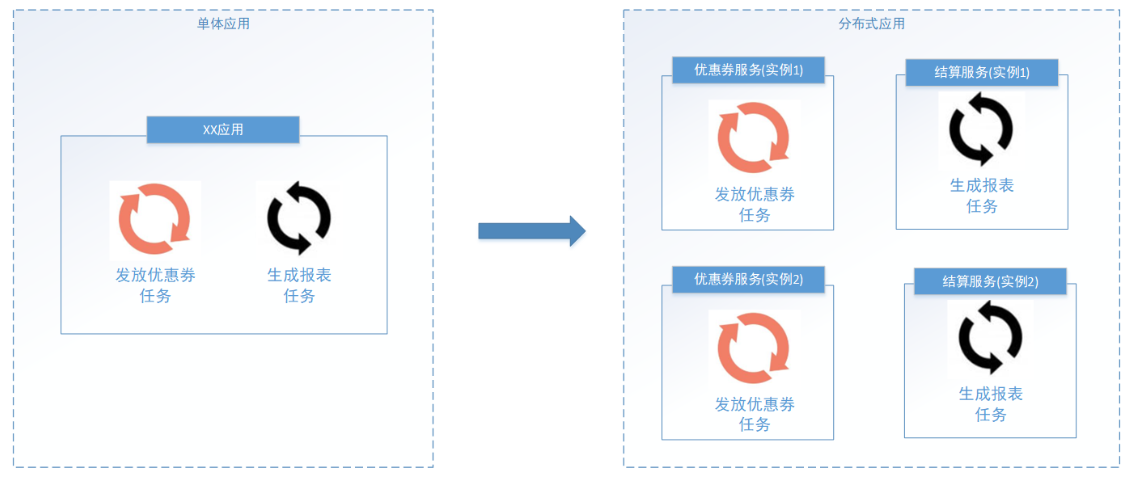
The goals to be achieved by distributed scheduling:
Regardless of whether the task scheduler is integrated in the application program or a task scheduling system built separately, if the distributed task scheduling method is adopted, it is equivalent to the distributed construction of the task scheduler, so that it can have the characteristics of a distributed system and improve Task scheduling and processing capabilities:
1. Parallel task scheduling
The realization of parallel task scheduling relies on multi-threading. If there are a large number of tasks to be scheduled, multi-threading alone will have a bottleneck at this time, because the processing power of a computer CPU is limited.
If the task scheduler is deployed in a distributed manner, each node can also be deployed as a cluster, so that multiple computers can jointly complete task scheduling. We can divide the task into several fragments and execute them in parallel by different instances. To improve the processing efficiency of task scheduling.
2. High availability
If a certain instance goes down, it does not affect other instances to perform tasks.
3. Elastic expansion
When more instances are added to the cluster, the processing efficiency of executing tasks can be improved.
4. Task management and monitoring
Unified management and monitoring of all timed tasks existing in the system. Allow developers and operation and maintenance personnel to keep abreast of task execution status, so as to make rapid emergency response.
5. Avoid repetitive tasks
When task scheduling is deployed in cluster mode, the same task scheduling may be executed multiple times. For example, in the e-commerce system mentioned above, coupons will be distributed multiple times, causing a lot of losses to the company. So we need to control the same task to be executed only once on multiple running instances.
2.4 XXL-JOB
2.4.1 Introduction
XXL-JOB is a lightweight distributed task scheduling platform . Its core design goals are rapid development, easy learning, lightweight, and easy expansion. The source code is now open and connected to the online product lines of many companies, out of the box.
Official website: https://www.xuxueli.com/xxl-job/
Documentation: https://www.xuxueli.com/xxl-job/#%E3%80%8A%E5%88%86%E5%B8%83%E5%BC%8F%E4%BB%BB%E5% 8A%A1%E8%B0%83%E5%BA%A6%E5%B9%B3%E5%8F%B0XXL-JOB%E3%80%8B
XXL-JOB mainly includes scheduling center, executor, and tasks:
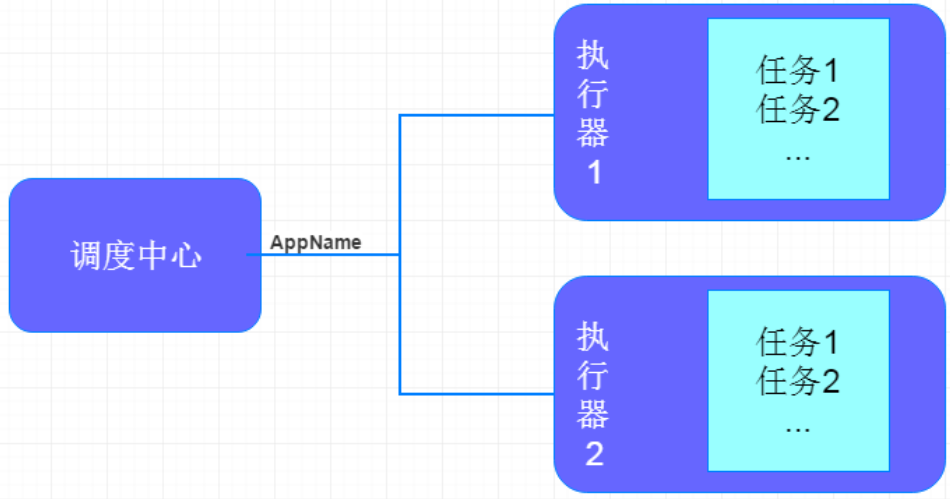
Dispatch Center:
Responsible for managing scheduling information, sending scheduling requests according to scheduling configuration, and not responsible for business codes;
The main responsibilities are executor management, task management, monitoring operation and maintenance, log management, etc.
Task Executor:
Responsible for receiving scheduling requests and executing task logic;
As long as the responsibilities are registration services, task execution services (task queues that will be placed in the thread pool after receiving tasks), execution result reporting , log services, etc.
Task: responsible for executing specific business processing.
The workflow between the dispatch center and the executor is as follows:
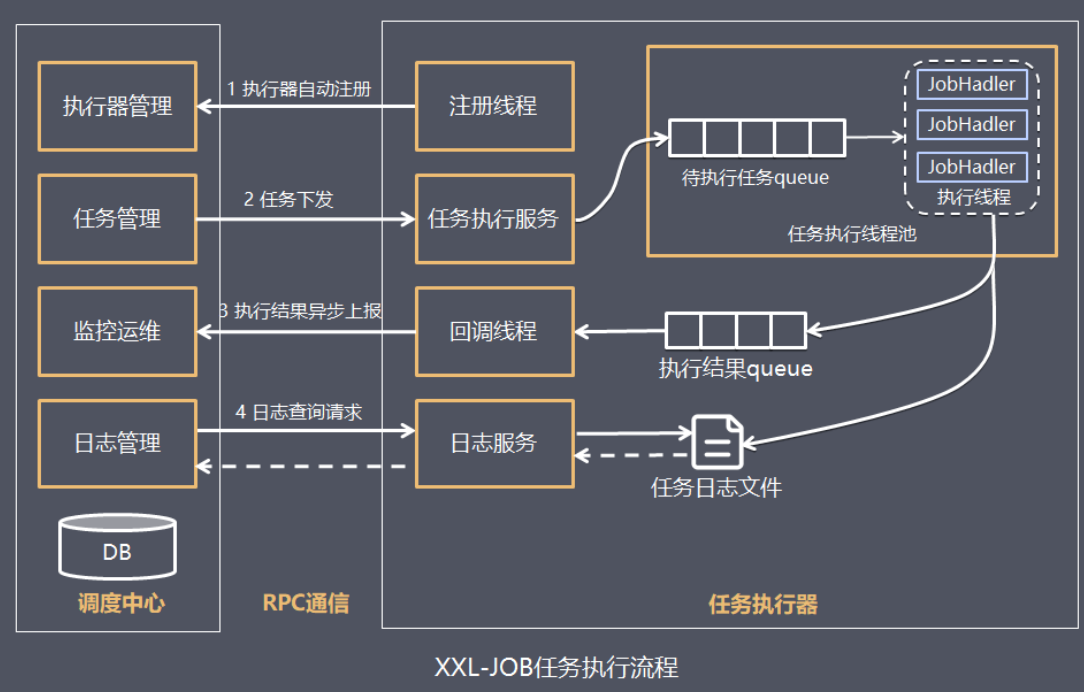
Implementation process:
1. The task executor automatically registers with the dispatch center according to the configured dispatch center address
2. When the task trigger condition is met, the dispatch center will issue the task
3. The executor executes the task based on the thread pool, puts the execution result into the memory queue , and writes the execution log into the log file
4. The executor consumes the execution results in the memory queue and actively reports to the scheduling center
5. When the user checks the task log in the dispatch center, the dispatch center requests the task executor, and the task executor reads the task log file and returns the log details
2.4.2 Build a dispatch center
Download XXL-JOB
The project uses version 2.3.1 of the Linux version: https://github.com/xuxueli/xxl-job/releases/tag/2.3.1
Windows version:
xxl-job-admin: scheduling center
xxl-job-core: public dependencies
xxl-job-executor-samples: Executor Sample (select the appropriate version of the executor and use it directly)
:xxl-job-executor-sample-springboot: Springboot version, manage the executor through Springboot, this method is recommended;
:xxl-job-executor-sample-frameless: frameless version;
doc : documentation, including database scripts
Install the Linux version on the virtual machine.
Create xxl_job_2.3.1 database
Run the sql script, as shown below:
After running:
Automatically start the xxl-job dispatch center:
sh /data/soft/restart.shaccess:
http://192.168.101.65:8088/xxl-job-admin/Account and password: admin/123456
If you cannot use the virtual machine to run xxl-job, you can run the xxl-job dispatch center on the local idea.
2.4.3 Build the executor, corresponding to the application name
The executor is responsible for communicating with the dispatch center to receive the task dispatch request initiated by the dispatch center.
1. Enter the dispatch center to add executors
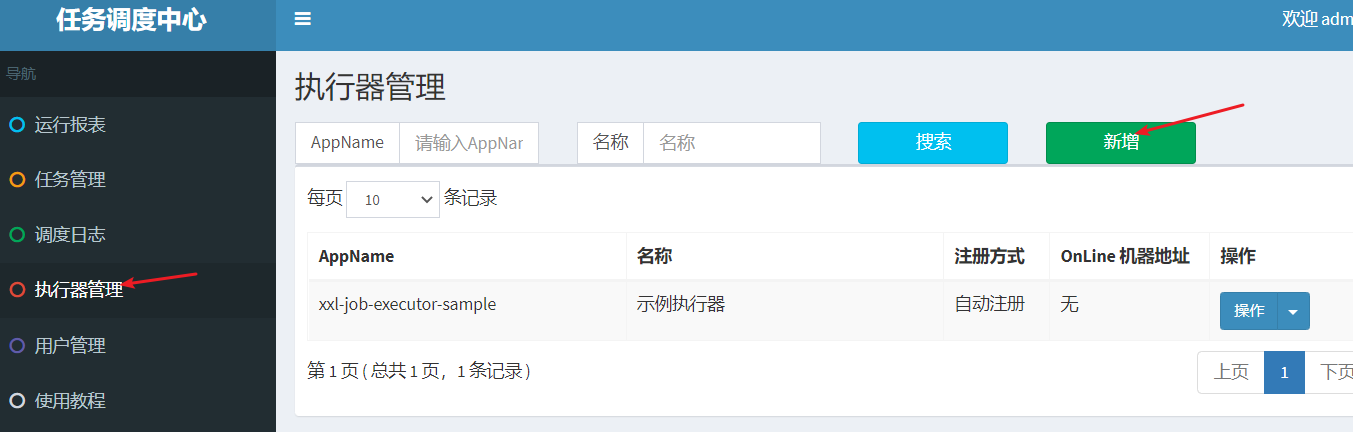
Click Add to fill in the executor information.
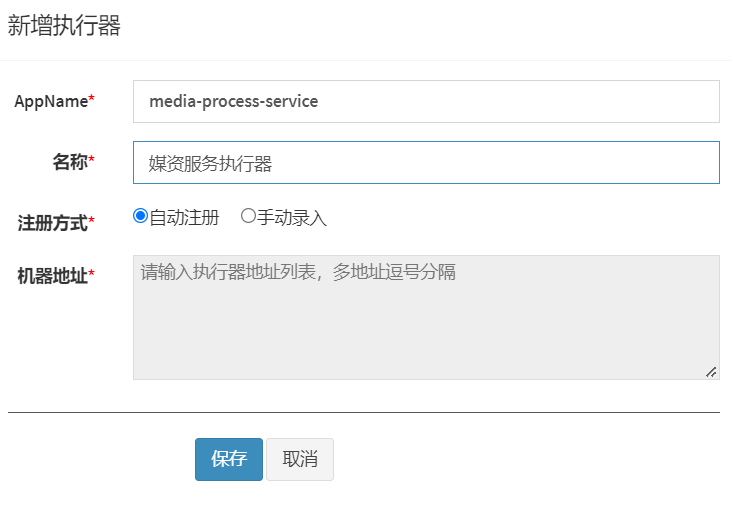
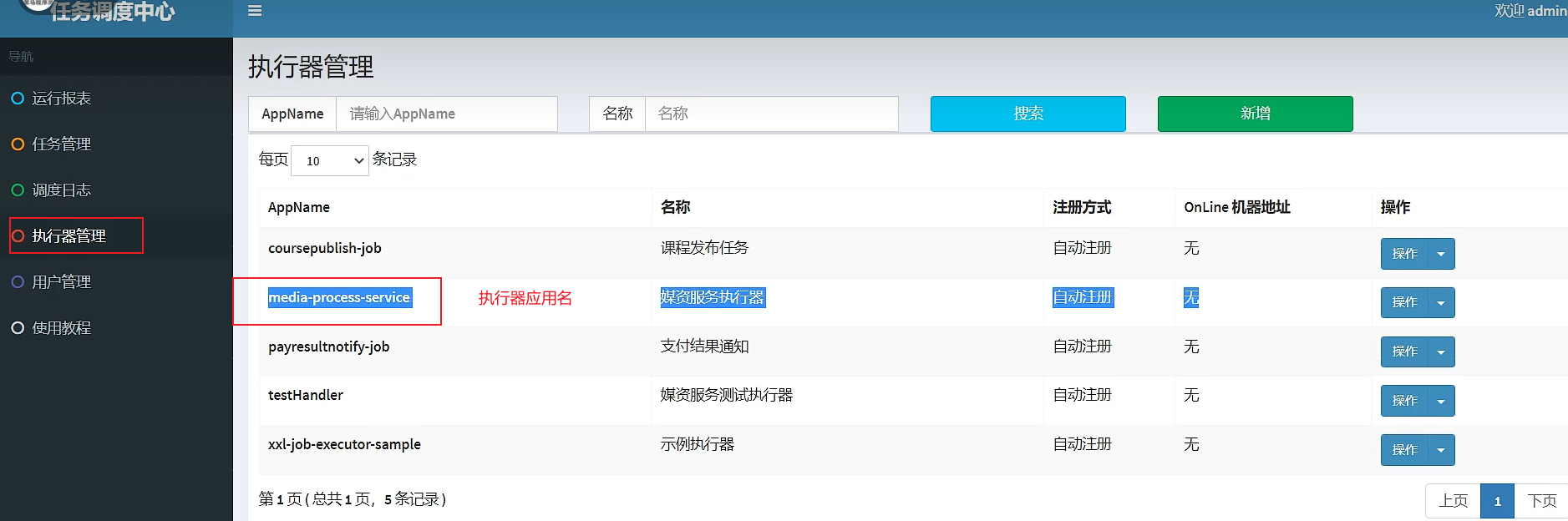
appname is the application name of the executor specified when configuring xxl information in nacos in the third step below.
The machine address is now filled in the blank. After the actuator is configured and the project is started, the machine address will display the address of the xxl actuator configured in the yml below.
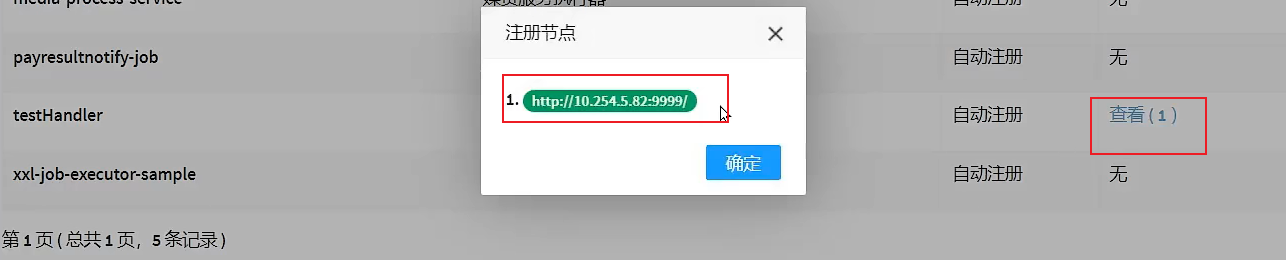
Added successfully:
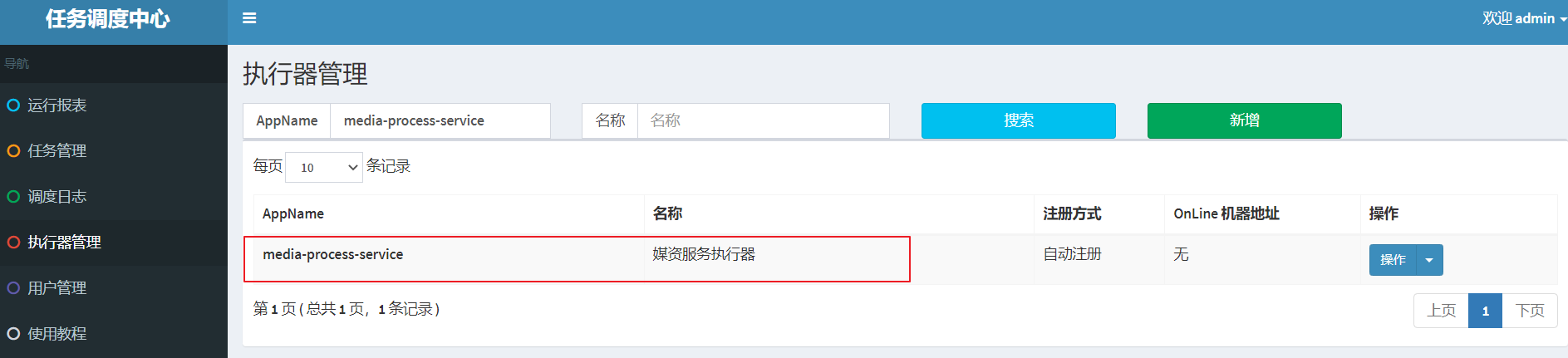
2. Add dependencies
First, add dependencies to the service project of the media asset management module. The parent project of the project has agreed on version 2.3.1
<dependency>
<groupId>com.xuxueli</groupId>
<artifactId>xxl-job-core</artifactId>
</dependency>3. yml configuration
Configure xxl-job under media-service-dev.yaml under nacos
xxl:
job:
admin:
addresses: http://192.168.101.65:8088/xxl-job-admin
executor:
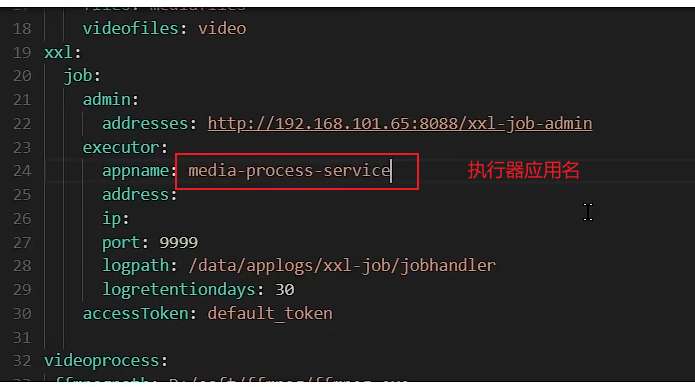
appname: media-process-service #appname这是第一步指定的执行器应用名
address:
ip:
port: 9999
logpath: /data/applogs/xxl-job/jobhandler
logretentiondays: 30
accessToken: default_tokenbootstrap.yml is configured with hot update, and it will take effect once nacos is modified.
Note: The appname in the configuration is the application name of the executor specified in the first step , and the port is the port started by the executor. If multiple executors are started locally, the ports cannot be repeated.
4. Configure the executor of xxl-job
Copy the configuration class of the xxl-job project downloaded from GitHub to the service project of media asset management
Copy to:

@Configuration
public class XxlJobConfig {
private Logger logger = LoggerFactory.getLogger(XxlJobConfig.class);
@Value("${xxl.job.admin.addresses}")
private String adminAddresses;
@Value("${xxl.job.accessToken}")
private String accessToken;
@Value("${xxl.job.executor.appname}")
private String appname;
@Value("${xxl.job.executor.address}")
private String address;
@Value("${xxl.job.executor.ip}")
private String ip;
@Value("${xxl.job.executor.port}")
private int port;
@Value("${xxl.job.executor.logpath}")
private String logPath;
@Value("${xxl.job.executor.logretentiondays}")
private int logRetentionDays;
@Bean
public XxlJobSpringExecutor xxlJobExecutor() {
logger.info(">>>>>>>>>>> xxl-job config init.");
XxlJobSpringExecutor xxlJobSpringExecutor = new XxlJobSpringExecutor();
xxlJobSpringExecutor.setAdminAddresses(adminAddresses);
xxlJobSpringExecutor.setAppname(appname);
xxlJobSpringExecutor.setAddress(address);
xxlJobSpringExecutor.setIp(ip);
xxlJobSpringExecutor.setPort(port);
xxlJobSpringExecutor.setAccessToken(accessToken);
xxlJobSpringExecutor.setLogPath(logPath);
xxlJobSpringExecutor.setLogRetentionDays(logRetentionDays);
return xxlJobSpringExecutor;
}
/**
* 针对多网卡、容器内部署等情况,可借助 "spring-cloud-commons" 提供的 "InetUtils" 组件灵活定制注册IP;
*
* 1、引入依赖:
* <dependency>
* <groupId>org.springframework.cloud</groupId>
* <artifactId>spring-cloud-commons</artifactId>
* <version>${version}</version>
* </dependency>
*
* 2、配置文件,或者容器启动变量
* spring.cloud.inetutils.preferred-networks: 'xxx.xxx.xxx.'
*
* 3、获取IP
* String ip_ = inetUtils.findFirstNonLoopbackHostInfo().getIpAddress();
*/
}At this point, the service project configuration of the media resource management module is completed, the xxl-job executor is configured, and the executor is added to the xxl-job dispatch center.
Test whether the executor communicates with the dispatch center normally:
Because the interface project depends on the service project, start the interface project of the media asset management module.
Observe the log after startup, and the following log appears, indicating that the executor has successfully registered in the dispatch center
![]()
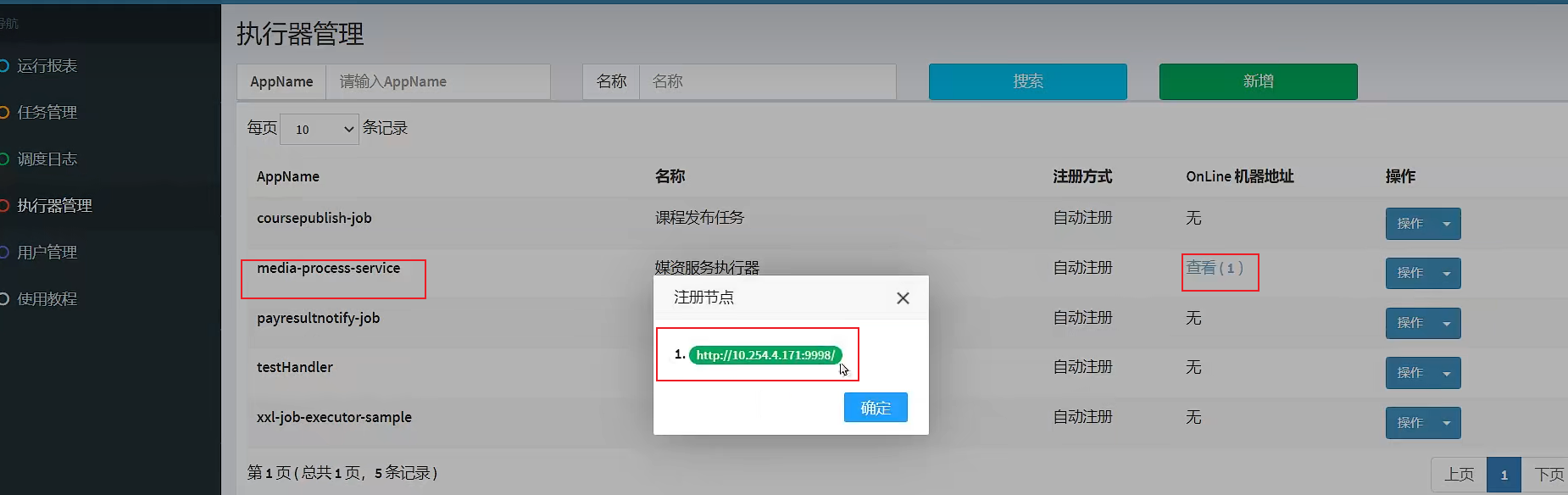
Simultaneously observe the executor interface in the dispatch center
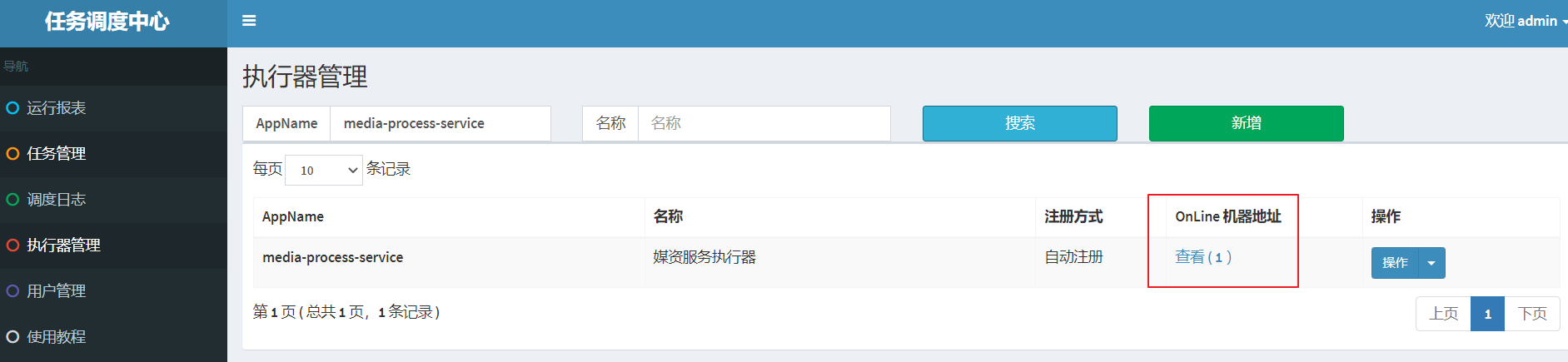
1 actuator has been shown at the online machine address.
2.4.4 Test, dispatch center and project new tasks, corresponding task names
To write the task below, refer to the writing method of the task class in the sample project, as shown in the figure below:

1. Write task class
Create a new jobhandler package under the media resource service service package to store task classes, and write a task class with reference to the sample project below
package com.xuecheng.media.service.jobhandler;
/**
* @description 测试执行器
*/
@Component
@Slf4j
public class SampleJob {
/**
* 1、简单任务示例(Bean模式)
*/
@XxlJob("testJob") //指定任务名称为testJob
public void testJob() throws Exception {
log.info("开始执行.....");
}
}2. Add task
Add tasks in the dispatch center below and enter task management
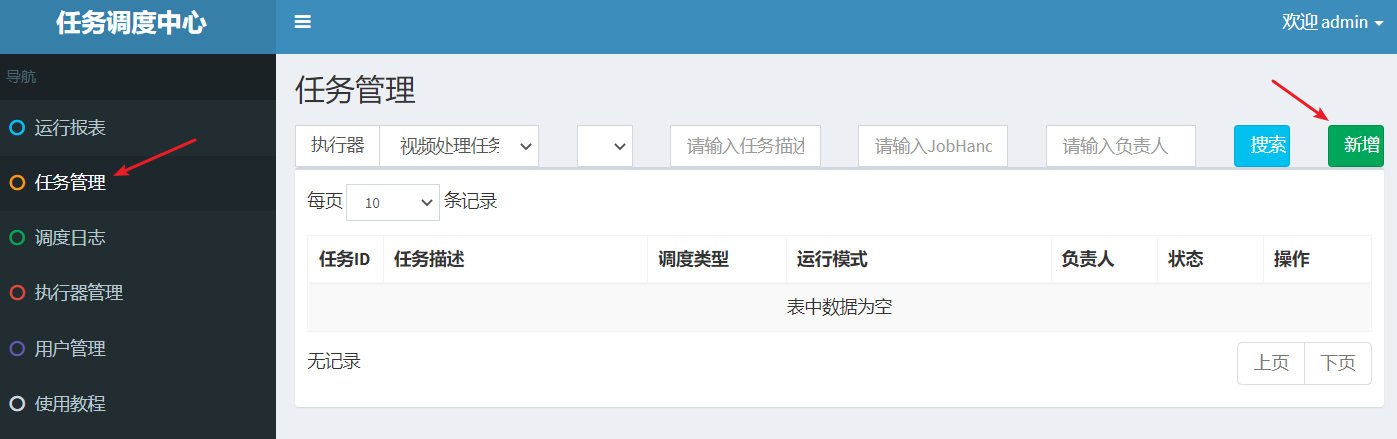
Click Add and fill in the task information
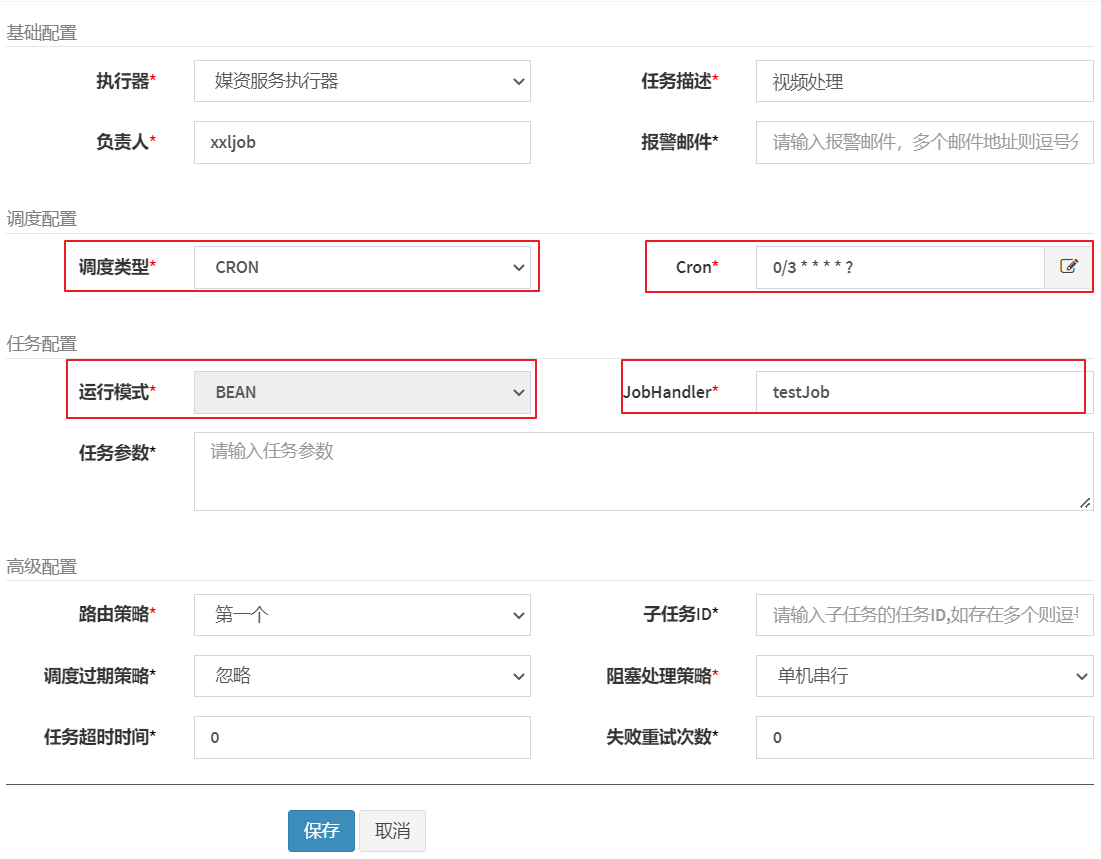
You can view the documentation for details.
Scheduling type: divided into fixed speed and cron.
Fixed speed: refers to timing scheduling at fixed intervals.
Cron: Implement richer timing scheduling strategies through Cron expressions.
A cron expression is a string through which a scheduling policy can be defined, in the following format:
{seconds} {minutes} {hours} {date} {month} {week} {year (can be empty)}
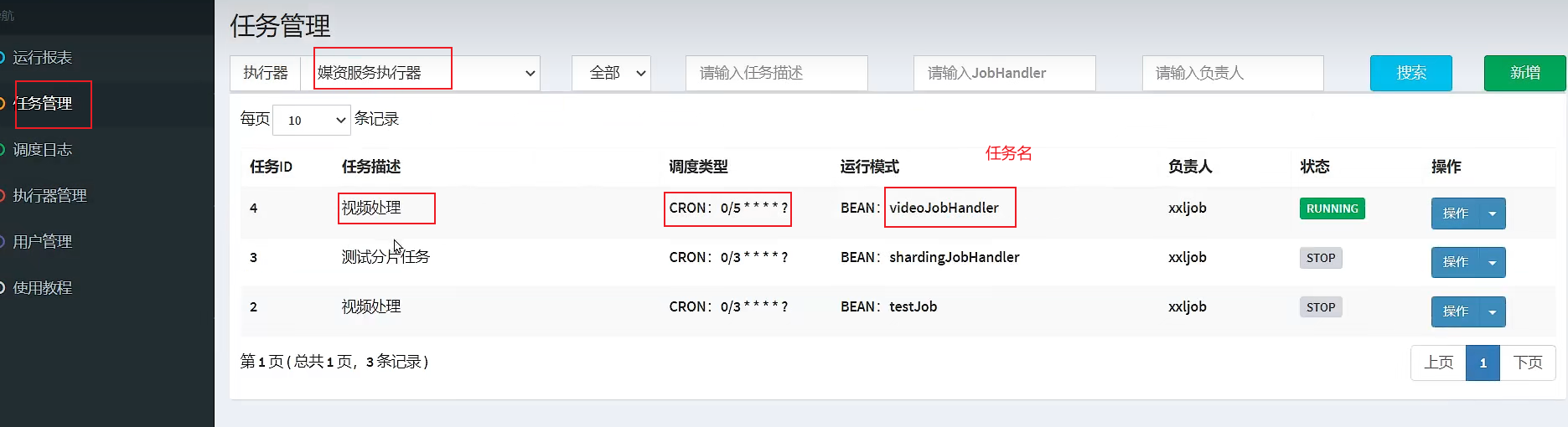
JobHandler: fill in the task name specified in @XxlJob.
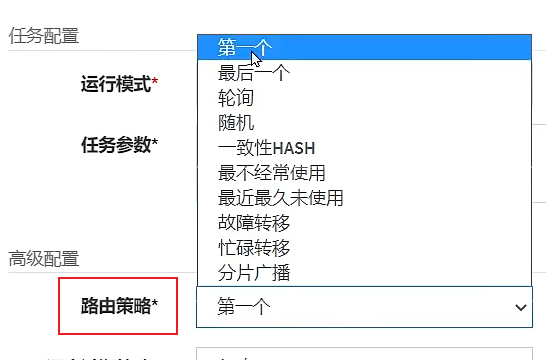
Routing policy:
The first one: Indicates that the dispatch center sends the task to the first executor each time.
Consistency hash: Determine which executor executes the task according to the hash value of the task id.
Failover: If a machine in the executor cluster fails, it will automatically fail over to another normal machine to initiate a scheduling request.
Fragmented broadcasting (recommended) : detailed explanation later
Subtask: The second task executed is related to the first task.
Blocking handling strategy:
Stand-alone serial: wait in line when the stand-alone is blocked.
Discard subsequent schedules: Discard new tasks when blocking.

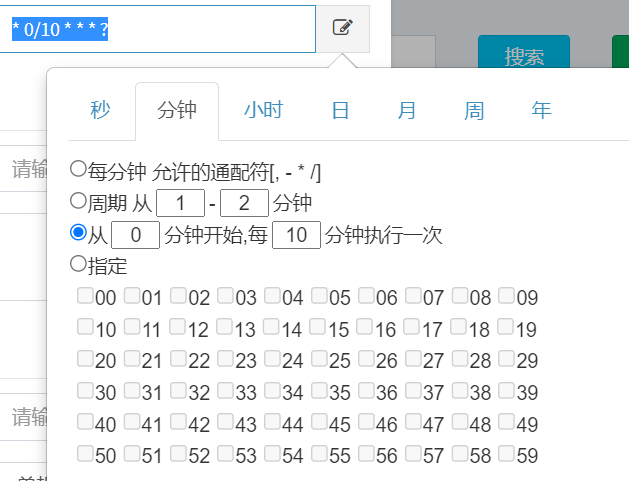
xxl-job provides a graphical interface to configure cron:
Some examples are as follows:
30 10 1 * * ? Triggered at 1:10:30 every day
0/30 * * * * ? Fires every 30 seconds
* 0/10 * * * ? Fires every 10 minutes
There are BEAN and GLUE operating modes. The bean mode is more commonly used to write the task code of the executor in the project engineering. GLUE is to write the task code in the dispatch center.
JobHandler is the name of the task method, fill in the name in the @XxlJob annotation above the task method.
Routing strategy: When the executor cluster is deployed, which executor the dispatch center will deliver the task to. Selecting the first one here means only sending the task to the first executor. Other options of the routing strategy will be detailed in the fragment broadcast section later. explain.
Other configuration items of advanced configuration will be explained in detail later in the Fragment Broadcasting chapter.
3. Select the executor and start the task
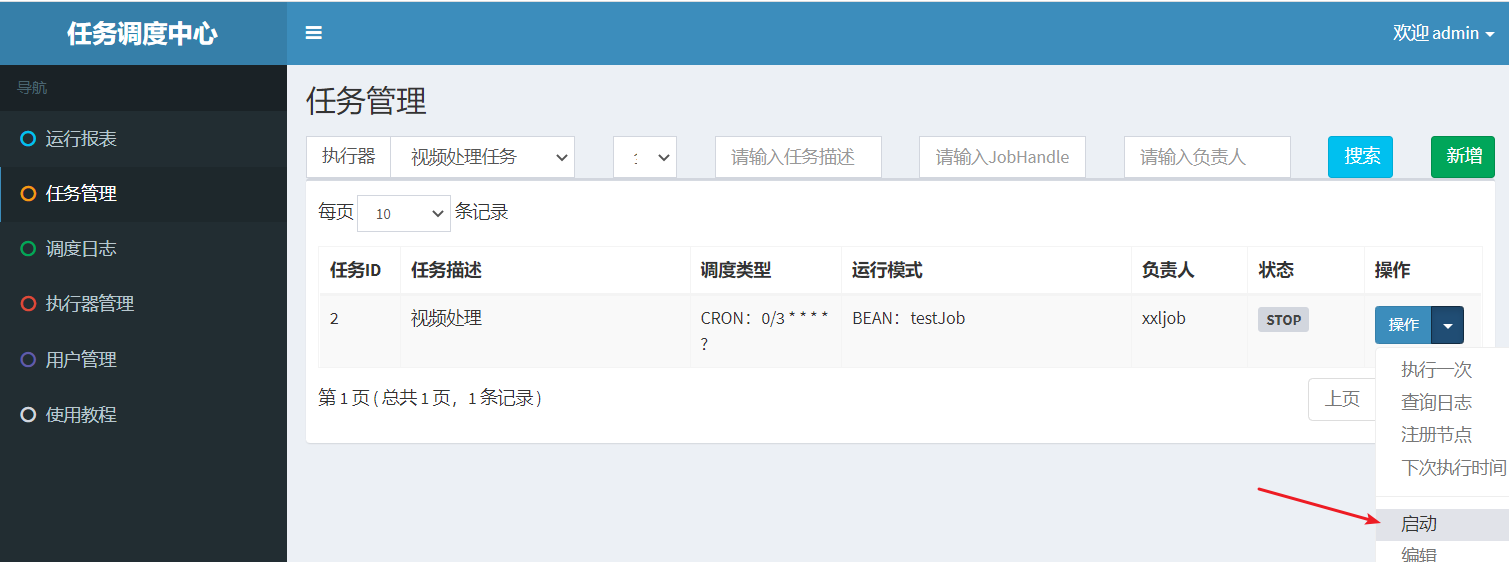
View task execution status through scheduling logs

4. Start the service project of media asset management and start the executor.
Watch the execution of the executor method.
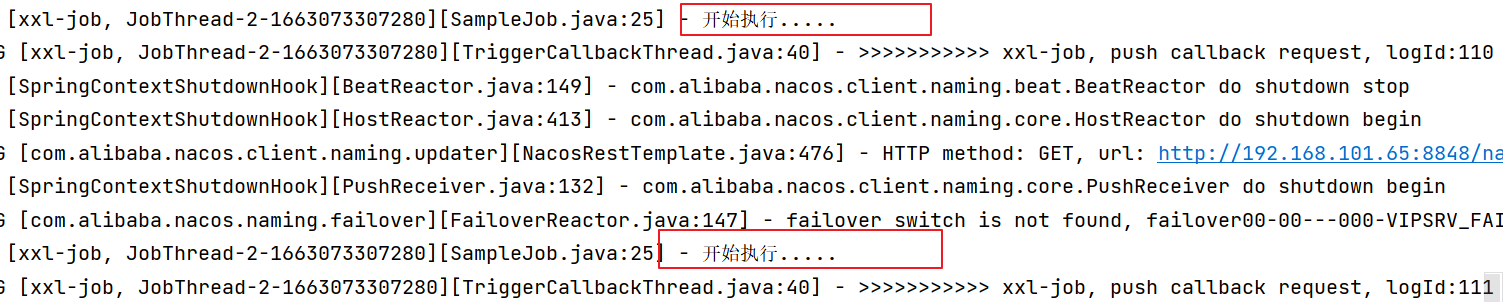
If you want to stop the task, you need to operate in the dispatch center
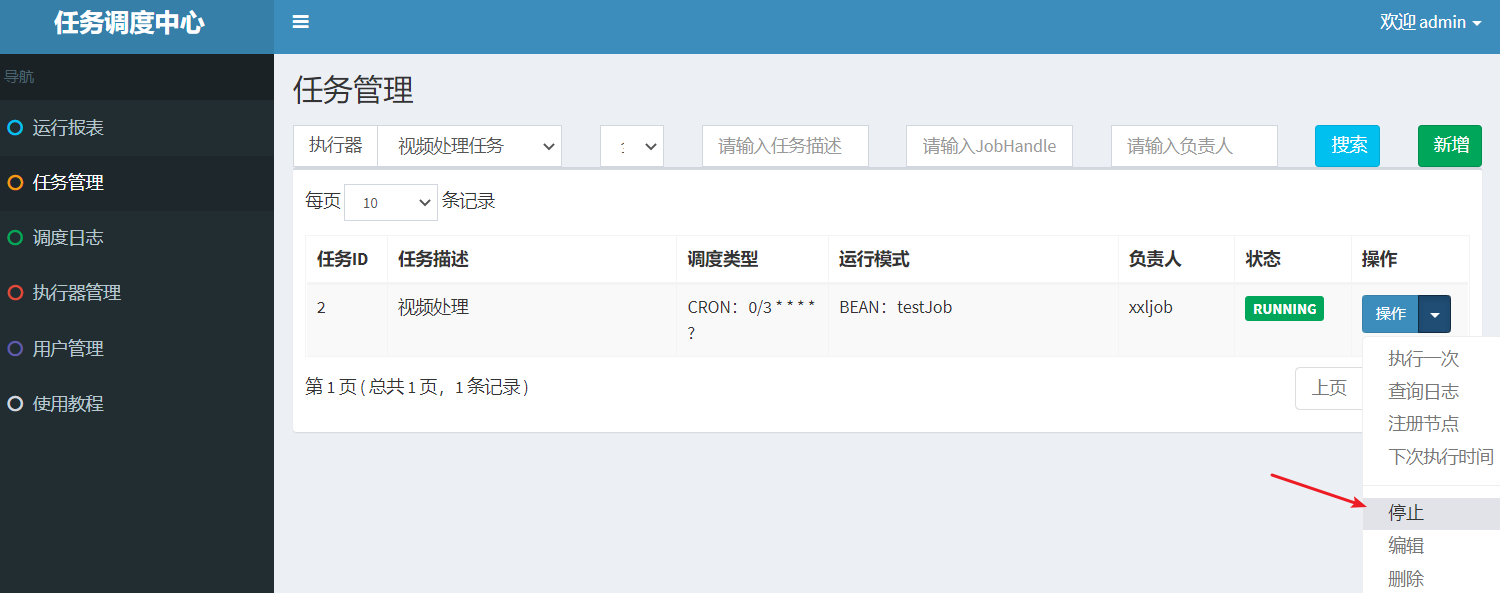
The task runs for a period of time and pays attention to clearing the log
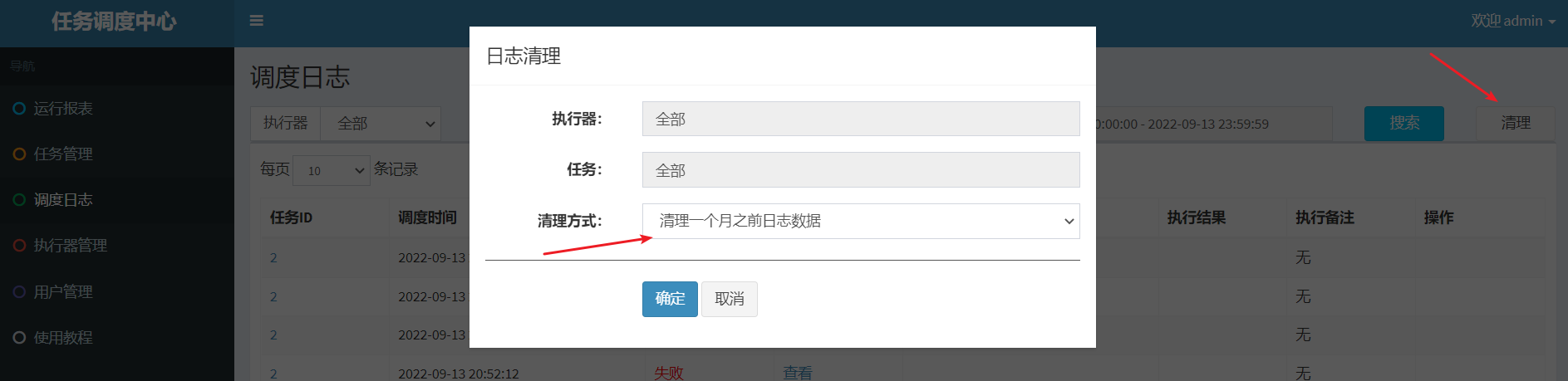
2.4.5 Detailed task configuration
xxl-job official document advanced configuration:
- Routing strategy: When the executor cluster is deployed, a rich routing strategy is provided, including;
FIRST (first): fixedly select the first machine;
LAST (last): fixedly select the last A machine;
ROUND (polling):;
RANDOM (random): randomly select an online machine;
CONSISTENT_HASH (consistency HASH): each task selects a certain machine according to the Hash algorithm, and all tasks are uniformly hashed on different machines superior.
LEAST_FREQUENTLY_USED (least frequently used): the machine with the lowest frequency of use is elected first;
LEAST_RECENTLY_USED (most recently unused): the machine that has not been used for the longest time is elected first;
FAILOVER (failover): heartbeat detection is performed in sequence, the first The machine with successful heartbeat detection is selected as the target executor and initiates scheduling;
BUSYOVER (busy transfer): idle detection is performed sequentially, and the first machine with successful idle detection is selected as the target executor and initiates scheduling;
SHARDING_BROADCAST (sharding Broadcast): Broadcast triggers all machines in the corresponding cluster to execute a task, and the system automatically transmits the fragmentation parameters; fragmentation tasks can be developed according to the fragmentation parameters;
- Subtask: Each task has a unique task ID (the task ID can be obtained from the task list). When the execution of this task is completed and executed successfully, an active scheduling of the task corresponding to the subtask ID will be triggered. Through Subtasks allow one task to complete another task.
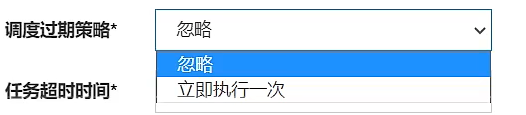
- Scheduling expiration strategy:
- Ignore: After the scheduling expires, ignore the expired task, and recalculate the next trigger time from the current time;
- Execute once immediately: After the scheduling expires, execute it once immediately, and recalculate the next time from the current time Trigger time;
- Blocking processing strategy: the processing strategy when the scheduling is too intensive for the executor to process;
single-machine serial (default): after the scheduling request enters the single-machine executor, the scheduling request enters the FIFO queue and runs in a serial manner;
discard subsequent scheduling : After the scheduling request enters the stand-alone executor, it is found that there are running scheduling tasks on the executor, and this request will be discarded and marked as failed; scheduling
before coverage: After the scheduling request enters the stand-alone executor, it is found that the executor has running scheduling tasks , will terminate the running scheduling task and clear the queue, and then run the local scheduling task;
- Task timeout: support custom task timeout, task running timeout will actively interrupt the task;
- Number of failed retries; support custom tasks The number of failed retries. When the task fails, it will actively retry according to the preset number of failed retries;
2.4.6 Fragmented broadcast
Fragmentation
Fragmentation means that the scheduling center performs sharding in the dimension of executors , and marks the executors in the cluster with serial numbers: 0, 1, 2, 3....
broadcast
Broadcasting means that each scheduling will send task scheduling to all executors in the cluster , and the request carries fragmentation parameters (serial number and quantity) . Each executor receives the scheduling request and receives the slice parameters at the same time .
The scheduling center schedules all the executors in the cluster, so that each executor executes a part of the task group.
As shown in the figure below: the scheduling center sends task scheduling to the first executor, carrying parameters 0 and 3, 0 is the serial number of the executor, and 3 is the number of executors in the cluster.

xxl-job supports dynamic expansion of the executor cluster to dynamically increase the number of shards. When the amount of tasks increases, more executors can be deployed to the cluster, and the scheduling center will dynamically modify the number of shards.
What scenarios are job slices suitable for?
- Sharding task scenario: a cluster of 10 executors processes 100,000 pieces of data, each machine only needs to process 10,000 pieces of data, and the time-consuming is reduced by 10 times;
- Broadcast task scenario: The broadcast executor runs shell scripts at the same time, broadcasts cluster nodes for cache updates, etc.
Therefore, the broadcast sharding method can not only give full play to the capabilities of each executor, but also control whether the task is executed according to the sharding parameters, and finally flexibly control the distributed processing tasks of the executor cluster.
Instructions for use:
"Shard broadcast" is consistent with the normal task development process, the difference is that the slice parameters can be obtained for slice business processing.
How to obtain fragmentation parameters for Java tasks:
BEAN, GLUE mode (Java), please refer to the sample task "ShardingJobHandler" in the Sample sample executor:
/**
* 2、分片广播任务
*/
@XxlJob("shardingJobHandler")
public void shardingJobHandler() throws Exception {
// 分片序号,从0开始
int shardIndex = XxlJobHelper.getShardIndex();
// 分片总数
int shardTotal = XxlJobHelper.getShardTotal();
....2.4.7 Test fragmentation and dynamic expansion
1. Define the task method of job sharding
/**
* 2、分片广播任务
*/
@XxlJob("shardingJobHandler")
public void shardingJobHandler() throws Exception {
// 分片参数
int shardIndex = XxlJobHelper.getShardIndex();
int shardTotal = XxlJobHelper.getShardTotal();
log.info("分片参数:当前分片序号 = {}, 总分片数 = {}", shardIndex, shardTotal);
log.info("开始执行第"+shardIndex+"批任务");
}2. Add tasks in the dispatch center
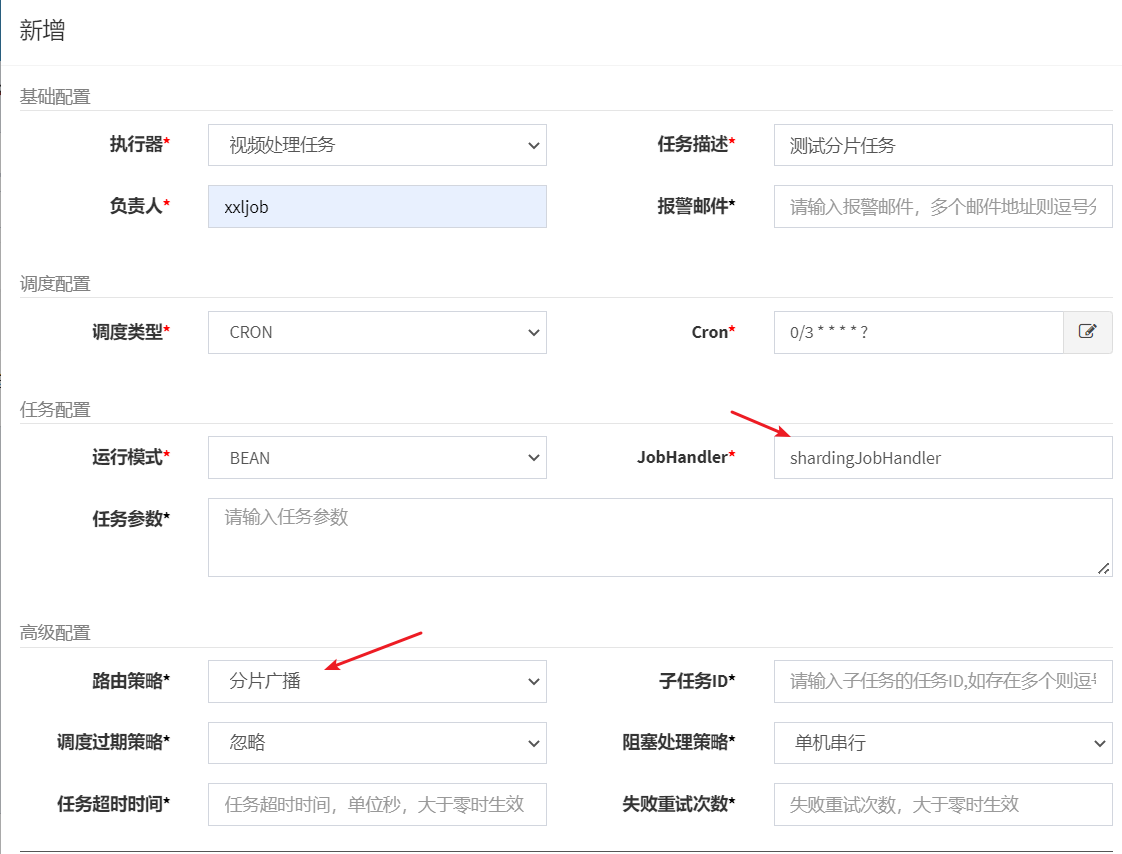
The JobHandler must be consistent with the task name configured by @XxlJob("shardingJobHandler").
Added successfully:
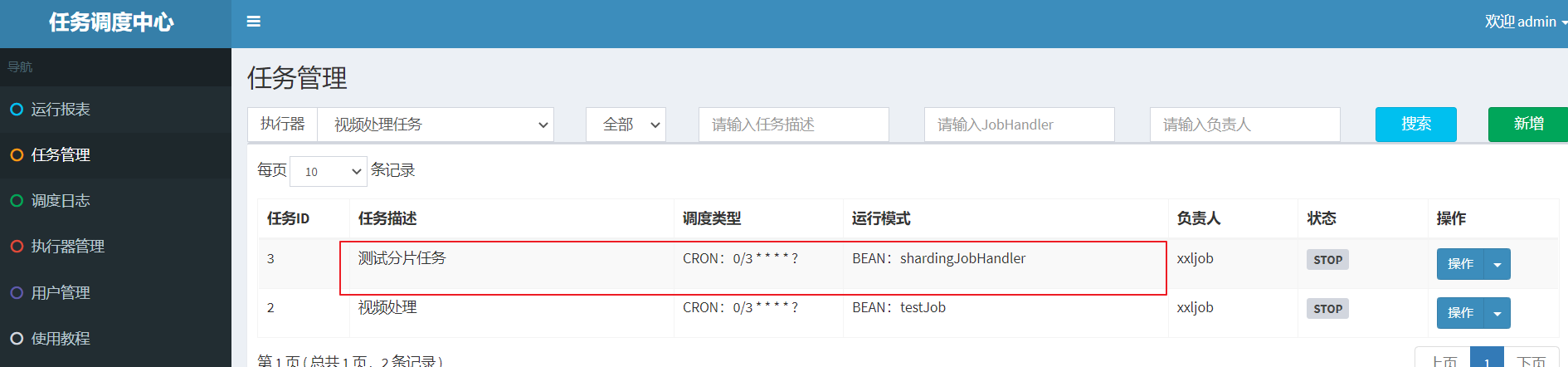
Start the task and observe the log
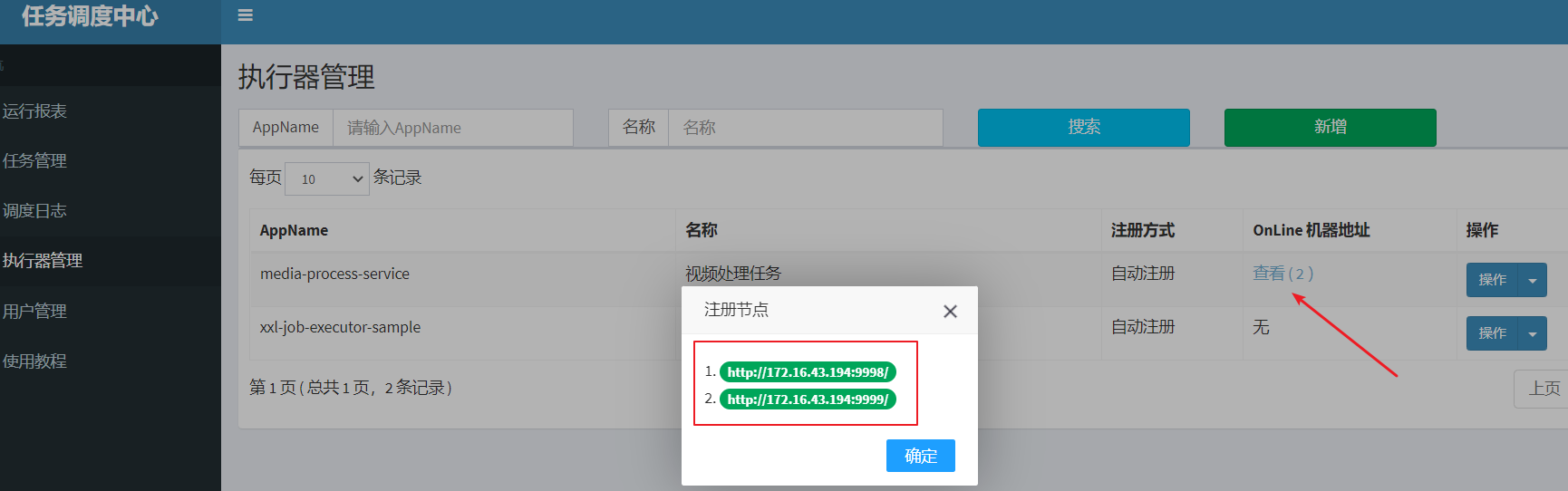
Start two executor instances
Start two executor instances below and observe the execution of each instance
First configure the local priority configuration of media-service in nacos:
#配置本地优先
spring:
cloud:
config:
override-none: trueStart two instances of media-service
Note that the ports of the two instances cannot conflict when starting:
Instance 1 Add at VM options: -Dserver.port=63051 -Dxxl.job.executor.port=9998
Instance 2 Add at VM options: -Dserver.port=63050 -Dxxl.job.executor.port=9999
For example:

Observe the task scheduling center, wait for a while, there are two executors
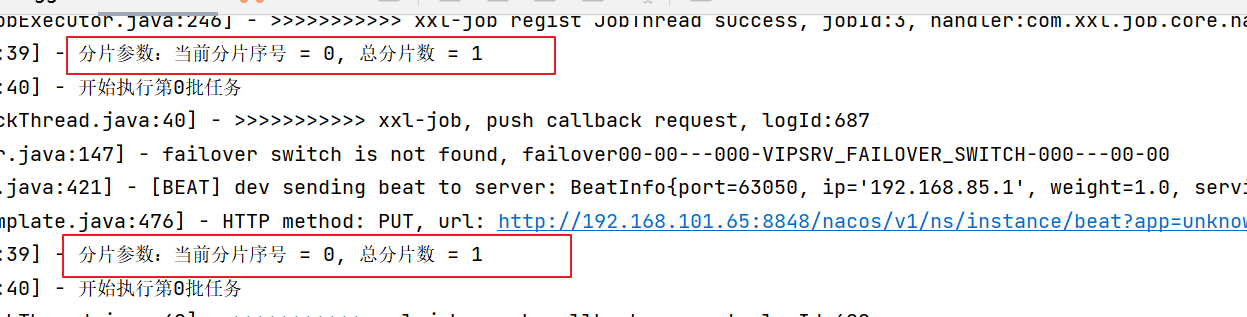
Observe the logs of the two execution instances:

The log of another instance is as follows:
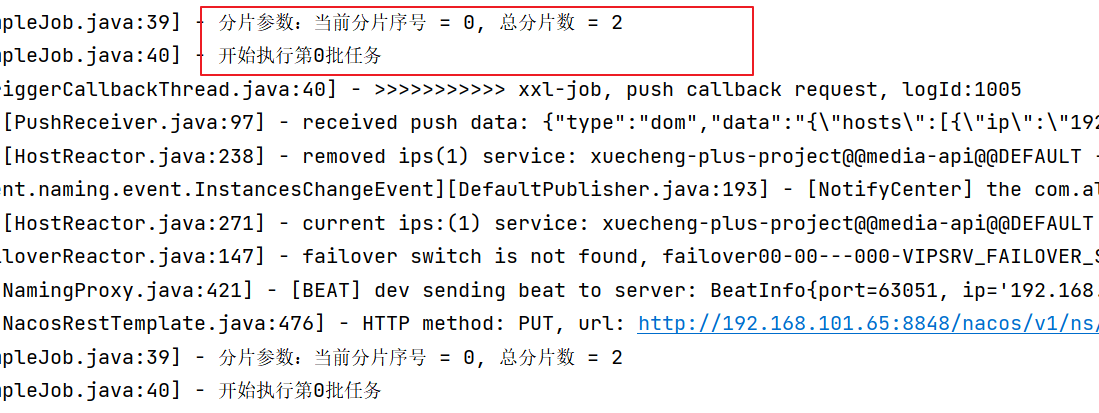
From the log, we can see that the fragment sequence number of each instance is different.
Test dynamic expansion :
At this time, if one of the executors hangs up, only one executor is left to work. After a while, the call center will dynamically adjust the total number of shards to 1 if it finds that there is one less executor. If a new instance is added, the total number of slices will also be dynamically adjusted.
3 technical solutions
3.1 Job Fragmentation Scheme
Thinking: How to distribute the video processing tasks in Xuecheng online platform?
think:
After the task is successfully added, the task to be processed will be added to the pending task table. Now start multiple executor instances to query these pending tasks. How to ensure that multiple executors will not query duplicate tasks at this time ?
Answer: Take the remainder . Task number % number of shards.
XXL-JOB does not directly provide the function of data processing, it only assigns the shard serial number to the executor, and sends parameters such as the total number of shards and the shard serial number to the executor at the same time, and the executor receives these parameters Use these parameters according to your own business needs.
The following figure shows the structure of multiple executors to obtain video processing tasks:
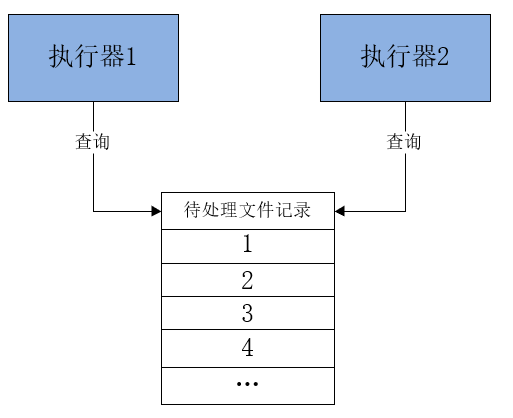
Each executor receives broadcast tasks with two parameters: the total number of fragments and the sequence number of fragments. When each task is fetched from the data table, the task id % total number of fragments can be set . If it is equal to the serial number of the fragment, this task will be executed.
For the above two executor instances, the total number of fragments is 2, and the serial numbers are 0 and 1, starting from task 1, as follows:
1 % 2 = 1 Actuator 2 executes
2 % 2 = 0 Actuator 1 executes
3 % 2 = 1 Actuator 2 executes
and so on.
3.2 Ensure that tasks are not repeated, set policies and ensure idempotence (distributed locks)
The job sharding scheme ensures that executors can query non-repeated tasks. If an executor has not finished processing a video, the scheduling center requests scheduling again at this time. What should I do in order not to process the same video repeatedly?
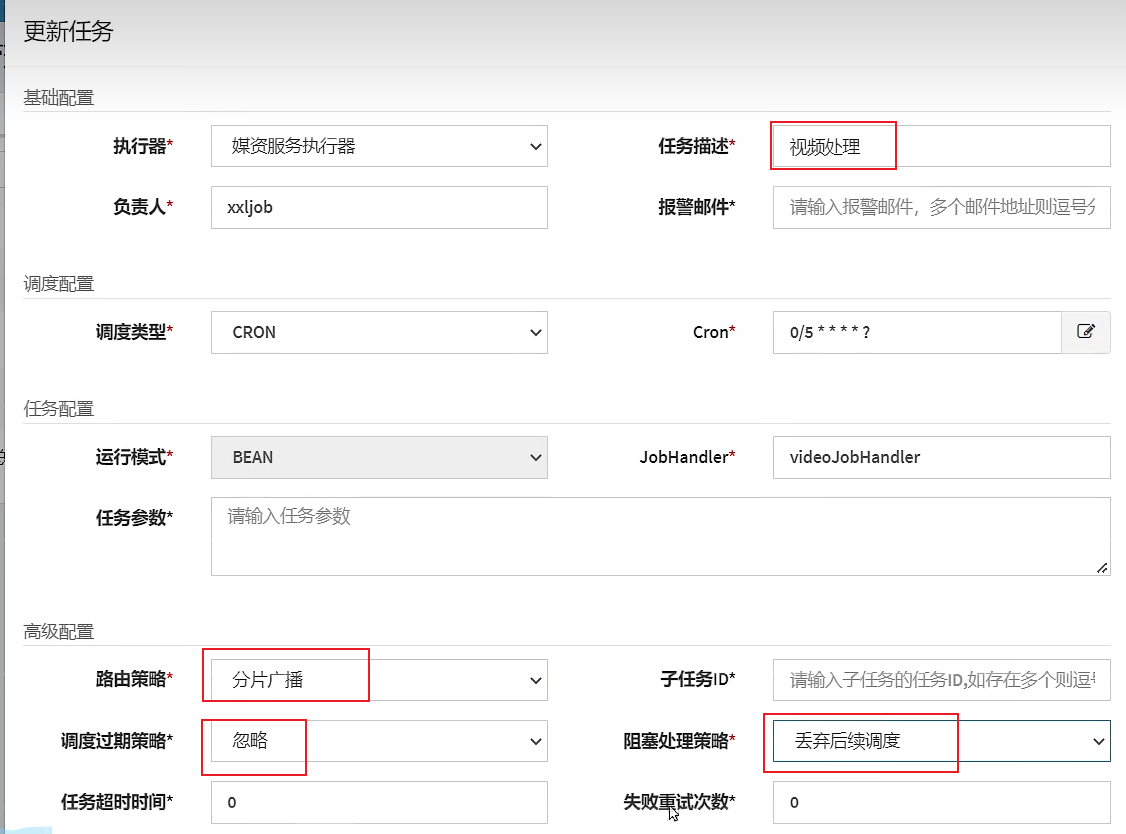
Conclusion: The scheduling expiration strategy is "ignore", and the blocking processing strategy is "discard subsequent scheduling". And it is necessary to ensure the idempotence of tasks (store all tasks in a table, and use a field to mark the status of this task).
First configure the scheduling expiration policy:
View the document as follows:
- Scheduling expiration strategy: The compensation processing strategy for the dispatch center to miss the dispatch time. For example, it should be dispatched at 10 o'clock, but due to some reasons, it will expire. Including: Ignore, Immediate compensation trigger once, etc.;
- Ignore (recommended): After the schedule expires, ignore the expired task, and recalculate the next trigger time from the current time ;
- Execute once immediately: After the schedule expires, execute it once immediately, and Recalculate the next trigger time from the current time; it is likely to be executed repeatedly
- blocking processing strategy: the processing strategy when the scheduling is too intensive for the executor to process in time;
Here we choose to ignore, if it is executed once immediately, the same task may be executed repeatedly.
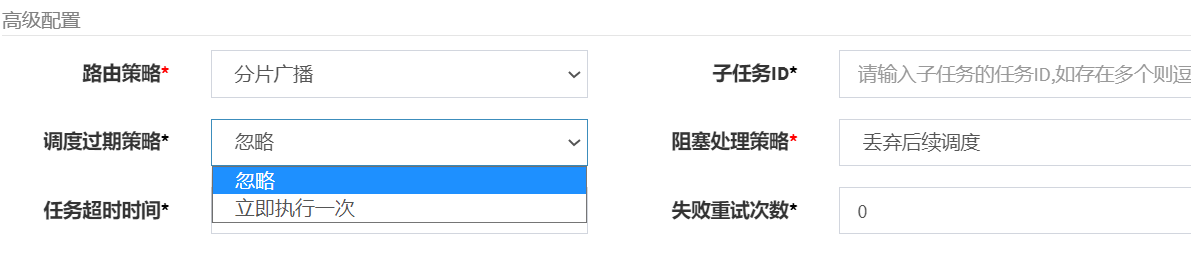
Secondly, let’s look at the blocking processing strategy . The blocking processing strategy is how to deal with the scheduling center when the current executor is executing the task and the task is not finished.
View the document as follows:
Stand-alone serial (default): After the scheduling request enters the single-machine executor, the scheduling request enters the FIFO queue and runs in serial mode;
discard subsequent scheduling (recommended): After the scheduling request enters the single-machine executor, it is found that the executor exists For the running scheduling task, this request will be discarded and marked as failed;
Overwrite the previous scheduling: After the scheduling request enters the stand-alone executor, if there is a running scheduling task in the executor, the running scheduling task will be terminated and the queue will be cleared. Then run the local scheduling task;
Here, if you choose to override the previous scheduling, the task may be repeated. Here, you choose to discard the subsequent scheduling or stand-alone serial mode to avoid repeated task execution.
Doing only these configurations can guarantee that the task will not be repeated?
If it can’t be done, the idempotence of task processing needs to be guaranteed. What is idempotency of tasks? The idempotency of the task means that no matter how many times the data is operated, the result of the operation is always consistent. What is to be achieved in this project is that no matter how many times the same video is scheduled, only one successful transcoding is performed.
What is idempotency?
It describes that one and multiple requests for a resource should have the same result for the resource itself .
Idempotence is to solve the problem of repeated submission, such as: malicious swiping, repeated payment , etc.
Commonly used solutions to idempotence:
1) Database constraints, such as: unique index, primary key. The same primary key cannot be inserted successfully twice.
2) Optimistic locking. Add a version field to the database table, and judge whether it is equal to a certain version when updating
3) Unique serial number. The Redis key is the task id, and the value is a random serialized uuid. Generate a unique serial number before the request, carry the serial number to the request, and record the serial number in redis during execution, indicating that the request with this serial number has been executed. If the same serial number is executed again, it means repeated execution.
Based on the above analysis, when the executor receives a scheduling request to execute video processing tasks, it is necessary to realize the idempotence of video processing, and there must be a way to judge whether the video processing is complete . If it is being processed or processed, it will not be processed. Here we add a processing status field to the video processing table in the database. The updated status of the video processing is completed. Before executing the video processing, it is judged whether the status is complete. If it is completed, it will not be processed.
3.3 Video processing business flow chart
The fragmentation scheme is determined, and the business process of the entire video upload and processing is sorted out below.
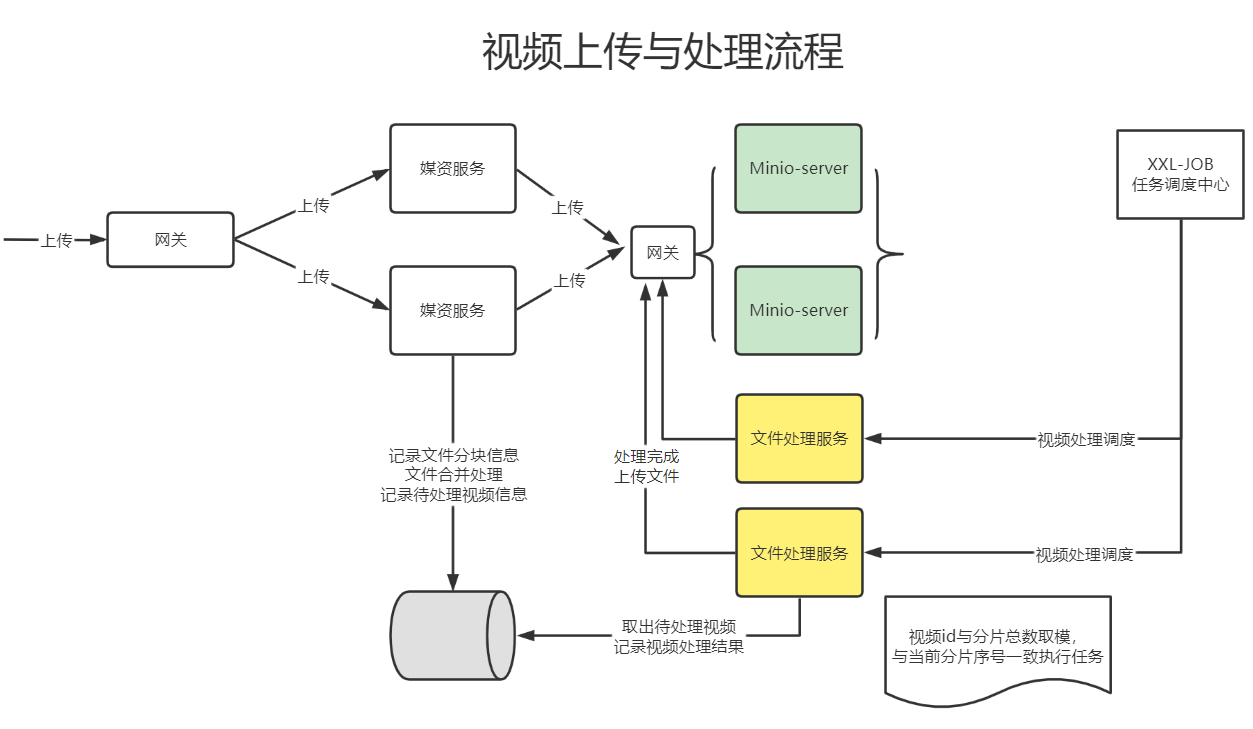
Add a record to the video pending table when uploading the video successfully.
The detailed flow of video processing is as follows:
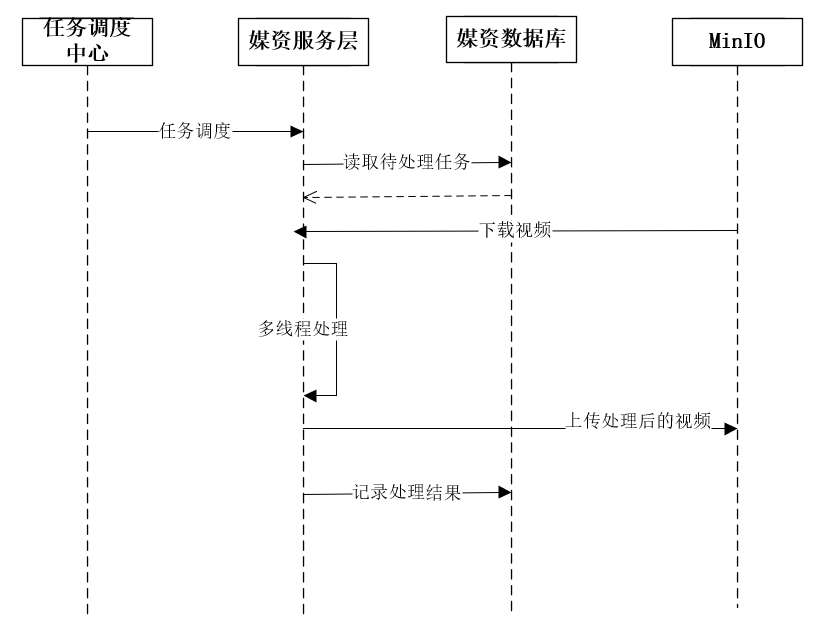
1. The task scheduling center broadcasts job fragments.
2. The executor receives the broadcast job fragments, reads pending tasks from the database, and reads unprocessed and failed tasks.
3. The executor updates the task to processing, and downloads the file to be processed from MinIO according to the task content.
4. The executor starts multi-threading to process tasks.
5. After the task processing is completed, upload the processed video to MinIO.
6. The task processing result will be updated. If the video processing is completed, in addition to updating the task processing result, the access address of the file will also be updated to the task processing table and file table, and finally the task completion record will be written into the history table.
4Query pending tasks
4.1 Requirements, pending task list, historical task list
need:
Query pending tasks only process tasks that have not been submitted or failed to process , and retry after task processing fails, up to 3 times . Successful task processing moves the pending records to the historical task table .
The following figure is the list of pending tasks:
The history task table has the same structure as the pending task table, storing the completed tasks.
4.2 Add pending tasks, after the files are put into storage
The uploaded video is successfully added to the video processing pending table, and only the processing record of the avi video is added for the time being.
According to the MIME Type to judge whether it is an avi video, some MIME Types are listed below
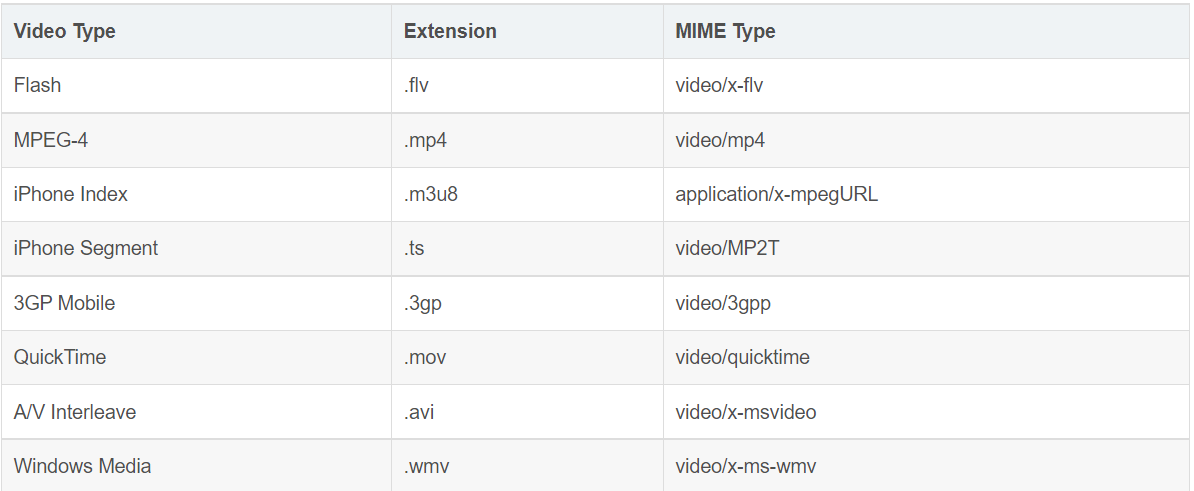
The MIME Type of the avi video is video/x-msvideo
Modify the file information storage method. If the video is of avi type (it can be extended to other types such as mpeg in the future), put it into the pending task table:
@Transactional
public MediaFiles addMediaFilesToDb(Long companyId, String fileMd5, UploadFileParamsDto uploadFileParamsDto, String bucket, String objectName) {
//从数据库查询文件
MediaFiles mediaFiles = mediaFilesMapper.selectById(fileMd5);
if (mediaFiles == null) {
mediaFiles = new MediaFiles();
//拷贝基本信息
BeanUtils.copyProperties(uploadFileParamsDto, mediaFiles);
mediaFiles.setId(fileMd5);
mediaFiles.setFileId(fileMd5);
mediaFiles.setCompanyId(companyId);
//媒体类型
mediaFiles.setUrl("/" + bucket + "/" + objectName);
mediaFiles.setBucket(bucket);
mediaFiles.setFilePath(objectName);
mediaFiles.setCreateDate(LocalDateTime.now());
mediaFiles.setAuditStatus("002003");
mediaFiles.setStatus("1");
//保存文件信息到文件表
int insert = mediaFilesMapper.insert(mediaFiles);
if (insert < 0) {
log.error("保存文件信息到数据库失败,{}", mediaFiles.toString());
XueChengPlusException.cast("保存文件信息失败");
}
//添加到待处理任务表
addWaitingTask(mediaFiles);
log.debug("保存文件信息到数据库成功,{}", mediaFiles.toString());
}
return mediaFiles;
}
/**
* 添加待处理任务
* @param mediaFiles 媒资文件信息
*/
private void addWaitingTask(MediaFiles mediaFiles){
//文件名称
String filename = mediaFiles.getFilename();
//文件扩展名
String extension = filename.substring(filename.lastIndexOf("."));
//文件mimeType
String mimeType = getMimeType(extension);
//如果是avi视频添加到视频待处理表
if(mimeType.equals("video/x-msvideo")){
MediaProcess mediaProcess = new MediaProcess();
BeanUtils.copyProperties(mediaFiles,mediaProcess);
mediaProcess.setStatus("1");//未处理
mediaProcess.setFailCount(0);//失败次数默认为0
mediaProcessMapper.insert(mediaProcess);
}
}test:
Perform front-end and back-end tests, upload 4 avi videos, and observe whether there are records in the pending task table and whether the records are completed.
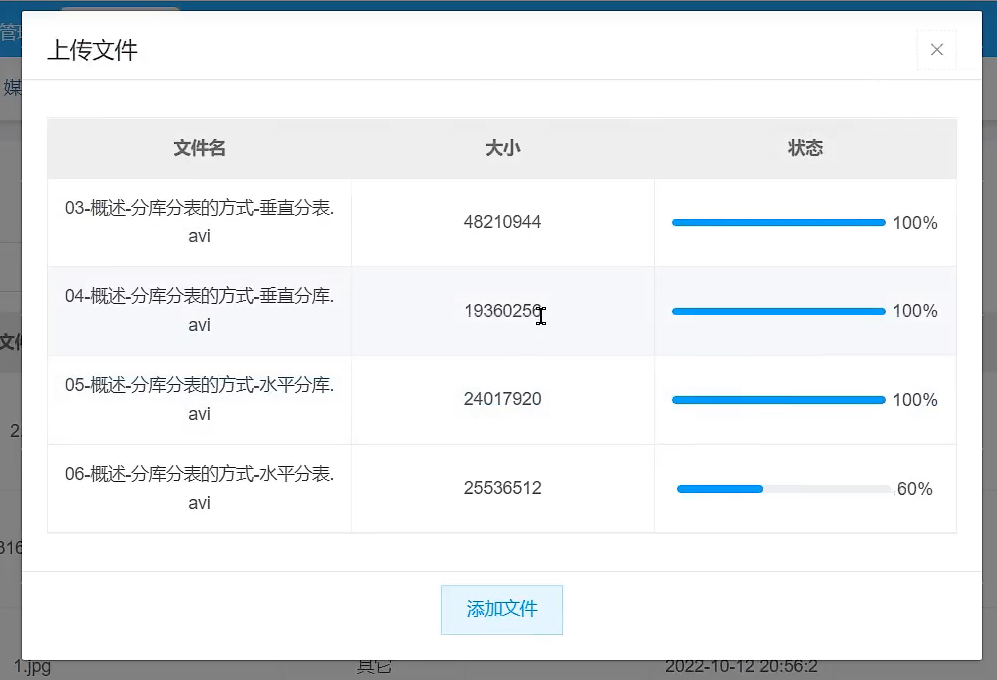
You can see that pending tasks have been inserted:
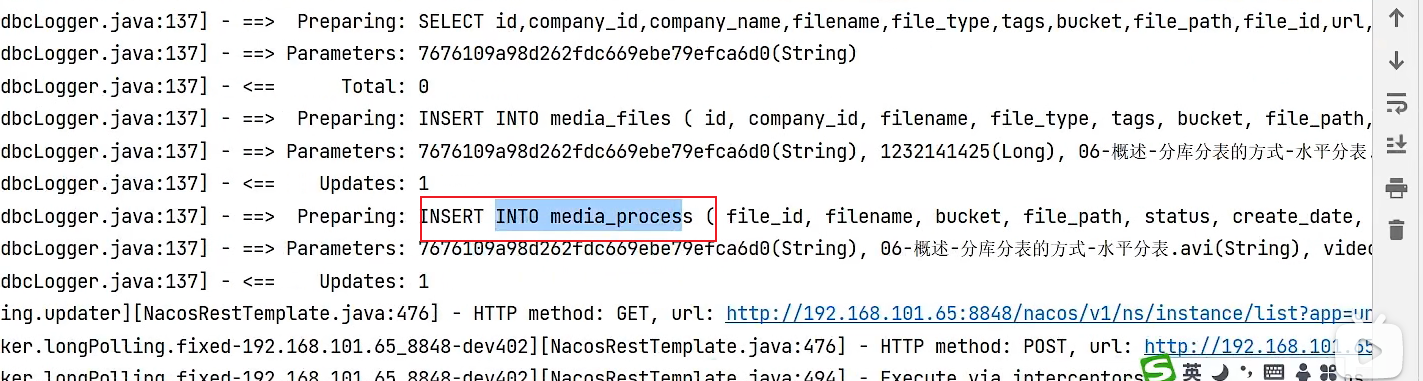
4.3 Query the pending task list according to the sharding parameters and quantity limit
How to ensure that the queried video records to be processed are not repeated?
4.3.1 SQL statements
Assuming there are two executors, query the tasks that have not been processed by No. 0 executor or the number of failures is less than 3, and only check two:
select * from media_process t where t.id % 2 = 0 and (t,status=1 or t,status=3) and t.fail_count<3 limit 24.3.2 mapper, query pending task list
Write a DAO method that obtains tasks to be processed according to the fragmentation parameters, and define the DAO interface as follows:
public interface MediaProcessMapper extends BaseMapper<MediaProcess> {
/**
* @description 根据分片参数获取待处理任务
* @param shardTotal 分片总数
* @param shardindex 分片序号
* @param count 任务数
* @return java.util.List<com.xuecheng.media.model.po.MediaProcess
*/
@Select("select * from media_process t where t.id % #{shardTotal} = #{shardIndex} and (t.status = '1' or t.status = '3') and t.fail_count < 3 limit #{count}")
List<MediaProcess> selectListByShardIndex(@Param("shardTotal") int shardTotal,@Param("shardIndex") int shardIndex,@Param("count") int count);
}4.3.3 service, query the list of pending tasks according to the fragmentation parameters and quantity limit
package com.xuecheng.media.service.impl;
@Slf4j
@Service
public class MediaFileProcessServiceImpl implements MediaFileProcessService {
@Autowired
MediaFilesMapper mediaFilesMapper;
@Autowired
MediaProcessMapper mediaProcessMapper;
@Override
public List<MediaProcess> getMediaProcessList(int shardIndex, int shardTotal, int count) {
List<MediaProcess> mediaProcesses = mediaProcessMapper.selectListByShardIndex(shardTotal, shardIndex, count);
return mediaProcesses;
}
}5 start the task
5.1 Distributed lock
5.1.1 The flexible expansion of the dispatch center leads to the problem of repeated tasks
Previously, we analyzed the solution to ensure that tasks are not repeated. In theory, the tasks assigned to each executor are not repeated. However, when the executor is elastically expanded, it is impossible to absolutely prevent tasks from being repeatedly executed.
For example: there are four executors that are performing tasks. Due to network problems, the original executors 0 and 1 cannot communicate with the dispatch center. The dispatch center will renumber the executors, and the original executors 3 and 4 may be lost. Execute the same tasks as executors 0 and 1.
Singleton lock and distributed lock
In order to avoid multiple threads competing for the same task, you can use synchronized synchronization locks to solve the problem, as shown in the following code:
synchronized(锁对象){ 执行任务... }Synchronized can only ensure that multiple threads in the same virtual machine compete for locks.
If multiple executors are deployed in a distributed manner, there is no guarantee that only one executor can process the same video.
Now to realize the synchronous execution of threads in all virtual machines in a distributed environment, multiple virtual machines need to share a lock. Virtual machines can be deployed in a distributed manner, and locks can also be deployed in a distributed manner, as shown in the following figure:
The virtual machines all grab the same lock, and the lock is a separate program that provides locking and unlocking services.
The lock no longer belongs to a certain virtual machine, but is distributed and shared by multiple virtual machines. This kind of lock is called a distributed lock.


5.1.2 Three methods to realize distributed locks, database, redis, zookeeper
1. Implement distributed locks based on the unique index of the database (used in this project)
Unique index: For example, if two threads insert data with id 1 at the same time, only one thread will be able to insert successfully, because the primary key id is unique.
Optimistic locking works this way. Utilize the characteristics of the uniqueness of the primary key of the database, or the characteristics of the unique index and row-level lock of the database, for example: multiple threads insert the same record with the same primary key into the database at the same time, whoever inserts successfully gets the lock, and multiple threads update at the same time For the same record, whoever updates successfully will grab the lock.
2. Implement lock based on redis
Redis provides implementations of distributed locks, such as: SETNX, set nx, redisson, etc.
Take SETNX as an example. The working process of the SETNX command is to set a key that does not exist. If multiple threads set the same key, only one thread will set it successfully, and the set thread will get the lock.
3. Implemented using zookeeper
Zookeeper is a distributed coordination service that mainly solves the problem of synchronization between distributed programs. The structure of zookeeper is similar to the file directory. When multiple threads create a subdirectory (node) to zookeeper, only one will be created successfully. Using this feature, distributed locks can be realized. Whoever successfully creates the node will get the lock.
This time we choose the database to implement distributed locks, and we will introduce other solutions in the later modules in detail.
5.2 Start the task
5.2.1 Optimistic lock implementation method
Synchronized is a pessimistic lock . When executing the code wrapped by synchronized, you need to acquire the lock first . If you don't get the lock, you can't execute it. It is always pessimistic that other threads will grab it , so you need to be pessimistic about the lock.
The idea of optimistic locking is that it does not think that there will be threads competing for it, just execute it , and try again if it fails to execute successfully .
Optimistic lock implementation steps:
The optimistic locking method of the database is to add a version field in the table , and judge whether it is equal to a certain version when updating . If it is equal, update or the update fails, as follows.
update t1 set t1.data1 = '',t1.version='2' where t1.version='1'5.2.2 SQL statement, modify task status to "processing"
The following implements distributed locks based on the database method , starts to execute the task and updates the task execution status to 4 to indicate that the task is in progress.
Use optimistic locking to implement update operations:
The first person changes the status field from "unprocessed" or "processing failure" to "processing", and the first person gets the lock; the second person wants to execute the update status statement and finds that the condition is not satisfied, because the status Not "unprocessed" or "failed to process" anymore:
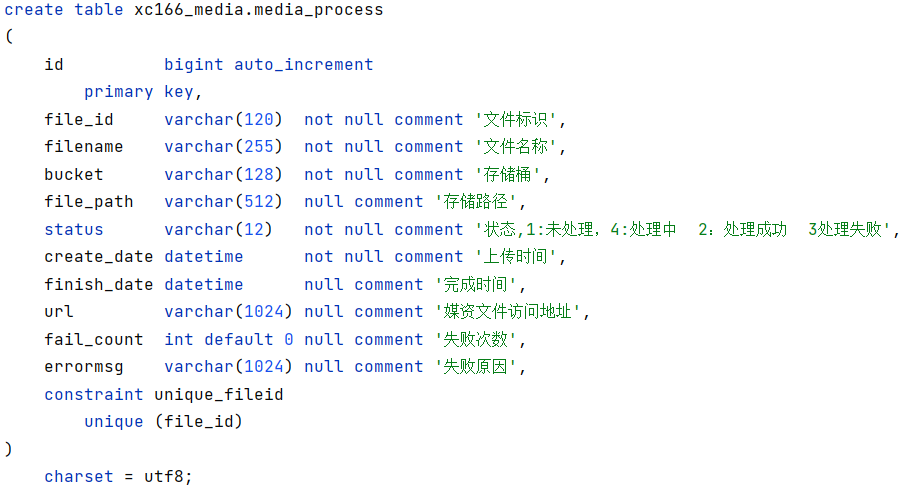
update media_process m set m.status='4' where (m.status='1' or m.status='3') and m.fail_count<3 and m.id=?Status, 1: unprocessed, 2: processed successfully, 3 processed failed, 4 processing
If multiple threads execute the above SQL at the same time, only one thread will execute successfully.
5.2.3 mapper , modify the task status to "processing"
public interface MediaProcessMapper extends BaseMapper<MediaProcess> {
/**
* 开启一个任务
* @param id 任务id
* @return 更新记录数
*/
@Update("update media_process m set m.status='4' where (m.status='1' or m.status='3') and m.fail_count<3 and m.id=#{id}")
int startTask(@Param("id") long id);
}5.2.4 service , modify the task status to "processing"
MediaFileProcessServiceImpl
/**
* 开启一个任务
* @param id 任务id
* @return true开启任务成功,false开启任务失败
*/
public boolean startTask(long id) {
int result = mediaProcessMapper.startTask(id);
return result<=0?false:true;
}6 Save task results
need:
After the task processing is completed, the task processing result needs to be updated.
The URL of the video and the task processing result are updated successfully when the task is executed, the pending task record is deleted, and a record is added to the historical task table at the same time.
service:
package com.xuecheng.media.service.impl;
@Slf4j
@Service
public class MediaFileProcessServiceImpl implements MediaFileProcessService {
@Autowired
MediaFilesMapper mediaFilesMapper;
@Autowired
MediaProcessMapper mediaProcessMapper;
@Autowired
MediaProcessHistoryMapper mediaProcessHistoryMapper;
/**
* @description 保存任务结果
* @param taskId 任务id
* @param status 任务状态
* @param fileId 文件id
* @param url url
* @param errorMsg 错误信息
*/
@Transactional
@Override
public void saveProcessFinishStatus(Long taskId, String status, String fileId, String url, String errorMsg) {
//查出任务,如果不存在则直接返回
MediaProcess mediaProcess = mediaProcessMapper.selectById(taskId);
if(mediaProcess == null){
return ;
}
//处理失败,更新任务处理结果
LambdaQueryWrapper<MediaProcess> queryWrapperById = new LambdaQueryWrapper<MediaProcess>().eq(MediaProcess::getId, taskId);
//处理失败
if(status.equals("3")){
MediaProcess mediaProcess_u = new MediaProcess();
mediaProcess_u.setStatus("3");
mediaProcess_u.setErrormsg(errorMsg);
mediaProcess_u.setFailCount(mediaProcess.getFailCount()+1);
mediaProcessMapper.update(mediaProcess_u,queryWrapperById);
log.debug("更新任务处理状态为失败,任务信息:{}",mediaProcess_u);
return ;
}
//任务处理成功
MediaFiles mediaFiles = mediaFilesMapper.selectById(fileId);
if(mediaFiles!=null){
//更新媒资文件表中的访问url
mediaFiles.setUrl(url);
mediaFilesMapper.updateById(mediaFiles);
}
//处理成功,更新url和状态
mediaProcess.setUrl(url);
mediaProcess.setStatus("2");
mediaProcess.setFinishDate(LocalDateTime.now());
mediaProcessMapper.updateById(mediaProcess);
//添加到历史记录
MediaProcessHistory mediaProcessHistory = new MediaProcessHistory();
BeanUtils.copyProperties(mediaProcess, mediaProcessHistory);
mediaProcessHistoryMapper.insert(mediaProcessHistory);
//删除mediaProcess
mediaProcessMapper.deleteById(mediaProcess.getId());
}
@Override
public List<MediaProcess> getMediaProcessList(int shardIndex, int shardTotal, int count) {
List<MediaProcess> mediaProcesses = mediaProcessMapper.selectListByShardIndex(shardTotal, shardIndex, count);
return mediaProcesses;
}
}7 Video processing task class, @Component and @XxlJob
Videos are processed concurrently, each video is processed by one thread , and the number of videos processed each time should not exceed the number of CPU cores .
All video processing is completed and this execution is completed. In order to prevent code exceptions from waiting indefinitely, a timeout setting is added . If the timeout is reached and the processing is not completed, the task will still end.
Define the task class VideoTask as follows:
package com.xuecheng.media.service.jobhander;
@Slf4j
@Component
public class VideoTask {
@Autowired
MediaFileService mediaFileService;
@Autowired
MediaFileProcessService mediaFileProcessService;
@Value("${videoprocess.ffmpegpath}")
String ffmpegpath;
@XxlJob("videoJobHandler")
public void videoJobHandler() throws Exception {
// 分片参数
int shardIndex = XxlJobHelper.getShardIndex();
int shardTotal = XxlJobHelper.getShardTotal();
List<MediaProcess> mediaProcessList = null;
int size = 0;
try {
//取出可用的cpu核心数。这个方法返回可用处理器的Java虚拟机的数量
int processors = Runtime.getRuntime().availableProcessors();
//每次任务处理视频的数量不要超过cpu核心数
mediaProcessList = mediaFileProcessService.getMediaProcessList(shardIndex, shardTotal, processors);
size = mediaProcessList.size();
log.debug("取出待处理视频任务{}条", size);
//没有待处理任务了
if (size <= 0) {
return;
}
} catch (Exception e) {
e.printStackTrace();
return;
}
//创建size个线程的线程池。这是执行器工具类方法创建线程池,也可以自定义线程池ThreadPoolExecutor配置类注入方式
ExecutorService threadPool = Executors.newFixedThreadPool(size);
//计数器。初始值是线程数,每执行完一个线程,计数器减一
//使用计数器是为了后面给线程阻塞,保证所有线程执行结束后或者超时时间后再结束整个任务方法。
//不使用计数器的话,下面代码会直接循环开启线程,不等线程结束运行完整个任务方法就结束了,线程就都死了(自定义线程池就不用考虑这种情况),不能控制超时时间。
//也可以不使用计数器,使用自定义线程池ThreadPoolExecutor配置类注入方式,能指定过期时间、核心线程数、最大线程数等
CountDownLatch countDownLatch = new CountDownLatch(size);
//将处理任务加入线程池
mediaProcessList.forEach(mediaProcess -> {
//列表里每个任务启动一个线程。
threadPool.execute(() -> {
try {
//任务id
Long taskId = mediaProcess.getId();
//开启任务,乐观锁防止重复消费,修改任务状态为“处理中”
boolean b = mediaFileProcessService.startTask(taskId);
if (!b) {
return;
}
log.debug("开始执行任务:{}", mediaProcess);
//下边是处理逻辑
//桶
String bucket = mediaProcess.getBucket();
//存储路径
String filePath = mediaProcess.getFilePath();
//原始视频的md5值
String fileId = mediaProcess.getFileId();
//原始文件名称
String filename = mediaProcess.getFilename();
//将要处理的文件下载到服务器上
File originalFile = mediaFileService.downloadFileFromMinIO(mediaProcess.getBucket(), mediaProcess.getFilePath());
if (originalFile == null) {
//下载待处理文件失败,保存任务结果
log.debug("下载待处理文件失败,originalFile:{}", mediaProcess.getBucket().concat(mediaProcess.getFilePath()));
mediaFileProcessService.saveProcessFinishStatus(mediaProcess.getId(), "3", fileId, null, "下载待处理文件失败");
return;
}
//创建mp4临时文件
File mp4File = null;
try {
mp4File = File.createTempFile("mp4", ".mp4");
} catch (IOException e) {
log.error("创建mp4临时文件失败");
mediaFileProcessService.saveProcessFinishStatus(mediaProcess.getId(),
"3", fileId, null, "创建mp4临时文件失败");
return;
}
//处理视频
String result = "";
try {
//开始处理视频,通过ffmpeg将下载的源文件转码成mp4文件
Mp4VideoUtil videoUtil = new Mp4VideoUtil(ffmpegpath, originalFile.getAbsolutePath(), mp4File.getName(), mp4File.getAbsolutePath());
//开始视频转换,成功将返回success
result = videoUtil.generateMp4();
} catch (Exception e) {
e.printStackTrace();
log.error("处理视频文件:{},出错:{}", mediaProcess.getFilePath(), e.getMessage());
}
if (!result.equals("success")) {
//记录错误信息
log.error("处理视频失败,视频地址:{},错误信息:{}", bucket + filePath, result);
mediaFileProcessService.saveProcessFinishStatus(mediaProcess.getId(), "3", fileId, null, result);
return;
}
//将mp4上传至minio
//mp4在minio的存储路径
String objectName = getFilePath(fileId, ".mp4");
//访问url
String url = "/" + bucket + "/" + objectName;
try {
mediaFileService.addMediaFilesToMinIO(mp4File.getAbsolutePath(), "video/mp4", bucket, objectName);
//将url存储至数据,并更新状态为成功,并将待处理视频记录删除存入历史
mediaFileProcessService.saveProcessFinishStatus(mediaProcess.getId(), "2", fileId, url, null);
} catch (Exception e) {
log.error("上传视频失败或入库失败,视频地址:{},错误信息:{}", bucket + objectName, e.getMessage());
//最终还是失败了
mediaFileProcessService.saveProcessFinishStatus(mediaProcess.getId(), "3", fileId, null, "处理后视频上传或入库失败");
}
}finally {
//finally里,不管成功还是失败计数器都减一
countDownLatch.countDown();
}
});
});
//计时器减成0之前或者指定时间之前一直阻塞。给一个充裕的超时时间,防止无限等待,到达超时时间还没有处理完成则结束任务
countDownLatch.await(30, TimeUnit.MINUTES);
}
private String getFilePath(String fileMd5,String fileExt){
return fileMd5.substring(0,1) + "/" + fileMd5.substring(1,2) + "/" + fileMd5 + "/" +fileMd5 +fileExt;
}
}The above task will be executed every 5 seconds:
8 Add pending tasks after uploading video stock
MediaFileServiceImpl
/**
* @param companyId 机构id
* @param fileMd5 文件md5值
* @param uploadFileParamsDto 上传文件的信息
* @param bucket 桶
* @param objectName 对象名称
* @return com.xuecheng.media.model.po.MediaFiles
* @description 将文件信息添加到文件表
* @author Mr.M
* @date 2022/10/12 21:22
*/
@Transactional
public MediaFiles addMediaFilesToDb(Long companyId, String fileMd5, UploadFileParamsDto uploadFileParamsDto, String bucket, String objectName) {
//将文件信息保存到数据库
MediaFiles mediaFiles = mediaFilesMapper.selectById(fileMd5);
if (mediaFiles == null) {
mediaFiles = new MediaFiles();
BeanUtils.copyProperties(uploadFileParamsDto, mediaFiles);
//文件id
mediaFiles.setId(fileMd5);
//机构id
mediaFiles.setCompanyId(companyId);
//桶
mediaFiles.setBucket(bucket);
//file_path
mediaFiles.setFilePath(objectName);
//file_id
mediaFiles.setFileId(fileMd5);
//url
mediaFiles.setUrl("/" + bucket + "/" + objectName);
//上传时间
mediaFiles.setCreateDate(LocalDateTime.now());
//状态
mediaFiles.setStatus("1");
//审核状态
mediaFiles.setAuditStatus("002003");
//插入数据库
int insert = mediaFilesMapper.insert(mediaFiles);
if (insert <= 0) {
log.debug("向数据库保存文件失败,bucket:{},objectName:{}", bucket, objectName);
return null;
}
//记录待处理任务
addWaitingTask(mediaFiles);
return mediaFiles;
}
return mediaFiles;
}
/**
* 添加待处理任务
*
* @param mediaFiles 媒资文件信息
*/
private void addWaitingTask(MediaFiles mediaFiles) {
//文件名称
String filename = mediaFiles.getFilename();
//文件扩展名
String extension = filename.substring(filename.lastIndexOf("."));
//获取文件的 mimeType
String mimeType = getMimeType(extension);
if (mimeType.equals("video/x-msvideo")) {//如果是avi视频写入待处理任务
MediaProcess mediaProcess = new MediaProcess();
BeanUtils.copyProperties(mediaFiles, mediaProcess);
//状态是未处理
mediaProcess.setStatus("1");
mediaProcess.setCreateDate(LocalDateTime.now());
mediaProcess.setFailCount(0);//失败次数默认0
mediaProcess.setUrl(null);
mediaProcessMapper.insert(mediaProcess);
}
}9 Add executors and tasks to the scheduling center
1. Install the scheduling center in linux, import the database table, visit the web page to add an executor, and set the application name
2. Import dependencies, yml configuration dispatch center address and executor application name , configuration class XxlJobSpringExecutor object injection yml configuration
Media service:
3. @Component and @XxlJob("task name") set the task
4. Add a new task to the dispatch center web page, set the task name, cron, routing policy, blocking policy, scheduling expiration policy (set to ignore)
Task scheduling strategy to prevent repeated consumption of tasks.
5. Start the service, find that the executor has been automatically registered, and start the task:
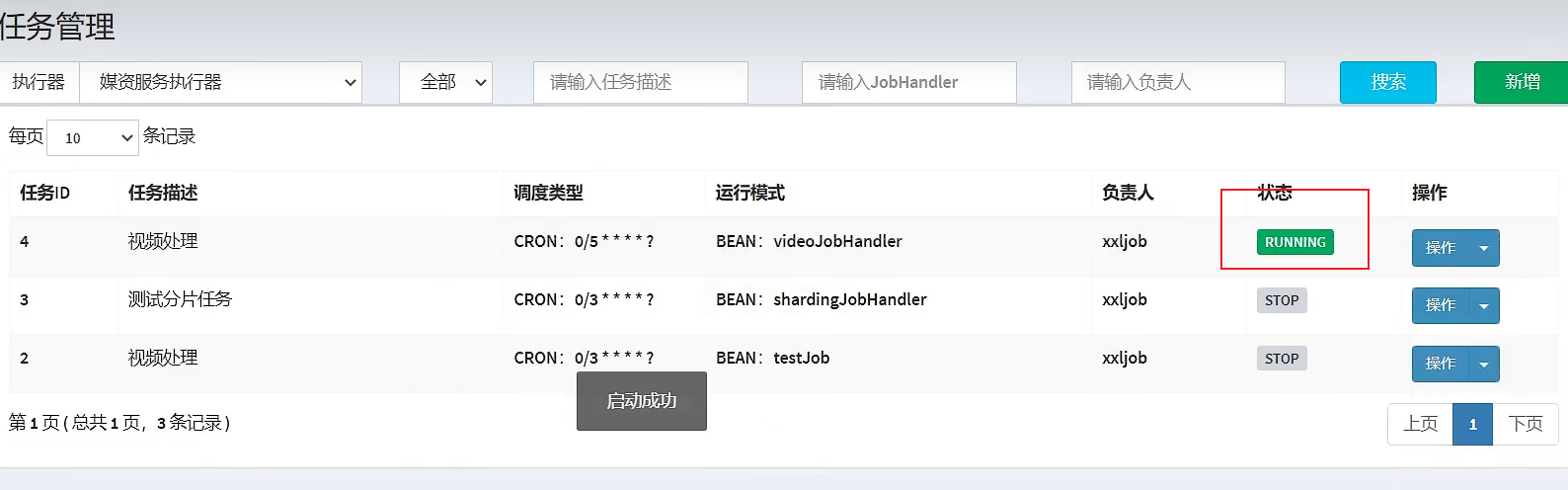
10 tests
10.1 Successful testing
The last two task paths of the media asset task list are intentionally wrong, so as to simulate two successes and two failures:

After the configuration is complete, start testing video processing:
1. First upload at least 4 videos, not in mp4 format.
2. Start the video processing task in xxl-job
3. Observe the background log of the media asset management service
10 .2 Failed tests
1. Stop the video processing tasks in the dispatch center first.
2. Upload the video, manually modify the file_path field in the pending task table to a file address that does not exist
3. Start the task
Observe whether it will retry after the task processing fails, and record the number of failures.
10.3 Preemptive task test
1. Modify the blocking processing strategy of video processing tasks in the scheduling center to "scheduling between coverages"

2. Break at the preemption task code and choose to support multi-threading
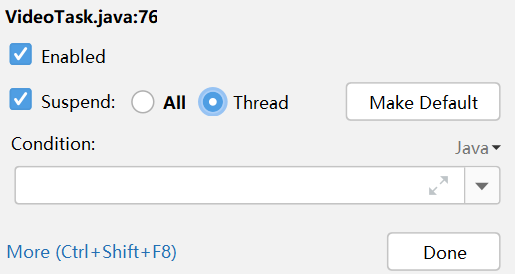
3. Set breakpoints on the two lines of code below the preemptive task code to prevent the code from continuing to execute during observation.
4. Start the task
At this point, multiple threads execute at the breakpoint
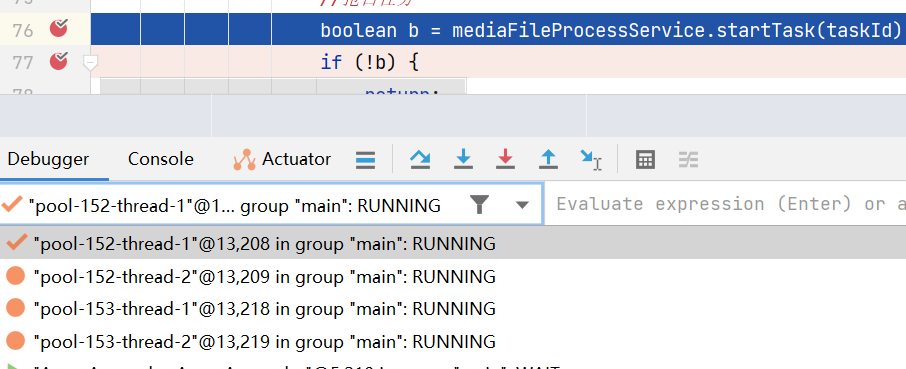
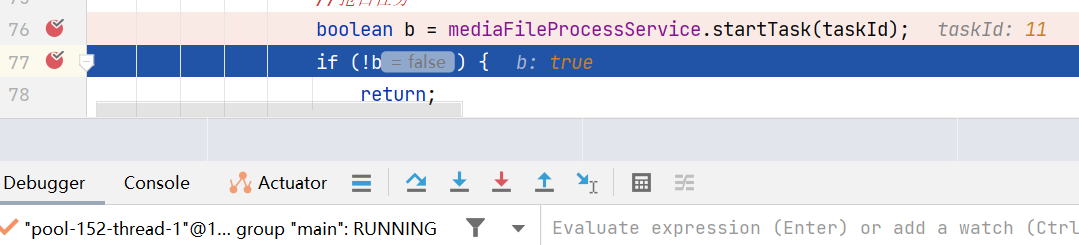
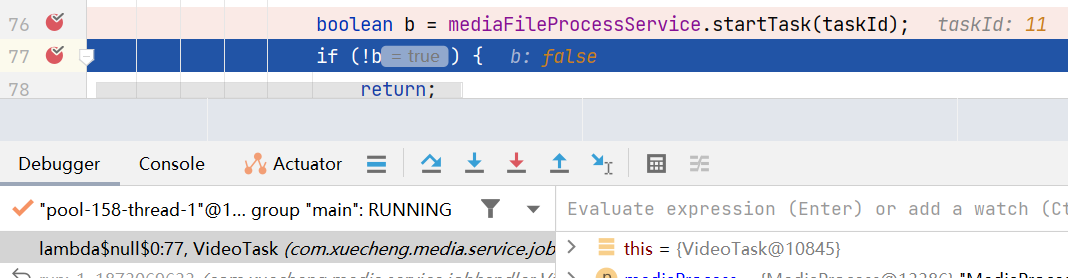
Let them go one by one, and observe that the same task will only be successfully preempted by one thread.
11 other questions
11.1 Task compensation mechanism, periodically query and process overtime tasks
If a thread preempts the processing task of a certain video, if the thread hangs up during processing , the status of the video will always be processing , and other threads will not be able to process it. This problem requires a compensation mechanism .
Start a task separately, periodically query the tasks in the pending task table that have exceeded the execution deadline but are still being processed , and change the status of the task to execution failure .
The task execution deadline is the maximum time for processing a video, for example, it is set to 30 minutes, and the task execution time is used to judge whether the task exceeds the execution deadline.
11.2 The number of failures reaches the maximum number of failures, manual processing
When the task reaches the maximum number of failures, it generally indicates that there is a problem with the program processing the video. In this case, manual processing is required, and a failure message will be displayed on the page. Manually execute the video for processing, or use other transcoding tools. Video transcoding, upload mp4 video directly after transcoding.
11.3 Periodically scan and clean up junk block files
Upload a file and upload it in chunks. Half of the upload will not be uploaded. Do I need to clean up the chunked files that were uploaded to minio before? How do you do it?
1. Create a new file table to record the file information stored in minio.
2. When the file starts to be uploaded, it will be written into the file table, and the status will be uploading, and the status will be updated to upload completed when the upload is completed.
3. When a file has been uploaded halfway and is no longer uploaded, it means that the file has not been uploaded. There will be a scheduled task to query the records in the file table. If the file is not uploaded, delete the file directory in minio that has not been uploaded successfully.