foreword
This note records my learning of the basic knowledge of the network under the Linux system, starting with various concepts and relationships about the network, and gradually building up the understanding of the network and the knowledge related to network programming. This article is inherited from Network Basics 1, if you are interested, you can take a look~
In this article, I will record my thoughts on learning the https protocol, and then transition to the transport layer to learn the details and ideas of the udp protocol and the tcp protocol.
My previous Linux notes:
Network socket programming - UDP and TCP:
[Linux] Network socket programming - qihaila's blog - CSDN blog

Table of contents
1. Application layer: https protocol
3. Data summary (data fingerprint), signature:
1. Option 1 - Only use symmetric encryption:
2. Scheme 2 - only use asymmetric encryption:
3. Scheme 3 - Both parties use asymmetric encryption:
4. Scheme 4 - Simultaneous use of symmetric encryption and asymmetric encryption:
5. Scheme five - CA authentication + asymmetric encryption and symmetric encryption:
1. Talk about the port number again
Specific message fields and understanding
Understanding Full Duplex and Half Duplex
Application layer protocol based on udp
Confirm response mechanism && serial number
TCP establishes a connection: three-way handshake
1. Application layer: https protocol
Today's mainstream protocol in the application layer is the https protocol. It is actually a secure version of http.
Because when transmitting information in http, it is transmitted in clear text . If there is an intermediary to forward and accept at this time, then there will be a problem of information leakage, and real-time monitoring can be performed to pretend to be the other party, so that neither the client nor the server knows whether they have leaked the secret.
Now, let's understand what is security? For computers or networks, security is to encrypt information, and then use decryption to extract it after transmission, so as to achieve the effect of security. In short: security = encryption + decryption .
However, absolute security does not exist in today's society. Even if the information is transmitted through encryption, others can still crack it, so the strict definition of security should be considered in essence: that is, why does the cracker crack its information? If you think about the benefits, security should be that the cost of cracking is far greater than the benefits of cracking .
We can first look at the relationship between http and https, and then talk about the security method of https.
http&&https
First of all, you can look at the content of the network protocol stack in detail:

It can be found that after we put a security layer on http, it becomes the https protocol, so we only need to focus on the security layer here, and the rest are consistent with http.
Because https involves a lot of knowledge. So here is just an understanding of how it works.
Because the tcp protocol is oriented to byte streams, the plaintext transmission of the http protocol is easily obtained by the middleman and attacked by the middleman . HTTPS transmits the plaintext, encrypts the plaintext , and transmits it to the corresponding host for decryption according to the key , so as to obtain information, so that it is not a process of transmitting plaintext, but a process of transmitting ciphertext. So, as you can see, encryption and decryption require intermediate data: the key.
For encryption, we first understand several encryption methods.
Encryption
The knowledge points here are related to mathematics, and here is just a simple understanding.
1. Symmetric encryption :
The same key is used to encrypt and decrypt information. - Encryption algorithms include DE3, 3DES, AES....
The characteristics are: open algorithm, small amount of calculation, fast encryption speed and high encryption efficiency.
Plaintext - key -> ciphertext; ciphertext - key -> plaintext;
Here is a simple example of symmetric encryption:
Bitwise XOR is a very simple symmetric encryption.
For example, I set the key key = 2, send the plaintext: 6, and get the ciphertext: 100 after bitwise XOR. The other host obtains the ciphertext 100 and decrypts it according to the bitwise XOR of the key to obtain the plaintext 110, which is 6.
In fact, it is aimed at bitwise XOR: a^b = key; key^b = a; that is to say, XOR with itself is 0, and any number XOR with 0 is itself.
2. Asymmetric encryption :
Use one key to encrypt the plaintext into ciphertext, and the other key to decrypt the ciphertext and decrypt it into plaintext. One of these two keys is public and the other is private. As for how to distribute the public and private keys, it is optional.
Common asymmetric encryption algorithms are: RSA DSA ECDSA...
The strength of asymmetric encryption algorithm is complex, but the speed of encryption and decryption is not as fast as that of symmetric encryption. The public key and the private key are paired with each other, and the disadvantage is that the operation speed is very slow. The public key is transmitted in plain text on the network, and the private key is kept by itself.
Plaintext-public key->ciphertext; ciphertext-private key->plaintext; (Of course, it can also be reversed)
3. Data summary (data fingerprint), signature :
For plaintext (raw text), a hash function is used to convert the original text into a string of fixed-length strings. At this time, this string is called a data summary, also known as a data fingerprint. Using hash, any text can be different after passing through this function, and the generation is irreversible. Generally used for compressing text.
For the data digest, the data signature is obtained after encryption . The role of the data summary is to determine the uniqueness of the data.
After understanding some encryption methods, let's explore how the security layer of https is protected:
Working exploration of https:
According to the above encryption methods, we will gradually explore the encryption methods of https from one by one:
1. Option 1 - Only use symmetric encryption :
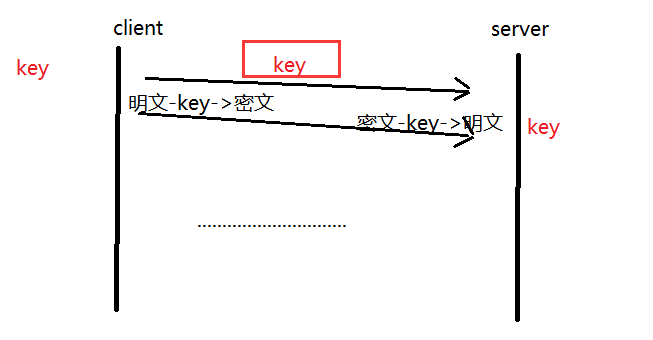
It can be seen that since it is symmetric encryption, both parties need to have the same key. In this way, the dependent key is sent in plain text, and it is not without any difference after being obtained by an intermediary.
2. Scheme 2 - only use asymmetric encryption :

It looks quite safe, but note that it can only be transmitted in one direction, that is to say, only the client can encrypt information to the server, but the server cannot encrypt information to the client.
3. Scheme 3 - Both parties use asymmetric encryption:

It seems to be possible at this time, and both parties can encrypt and transmit through ciphertext, which seems to be safe. But we should note that because the speed of asymmetric encryption itself is very slow, if there are two pairs of keys at this time, the efficiency will be very slow, so we should consider more efficient encryption.
4. Scheme 4 - Simultaneous use of symmetric encryption and asymmetric encryption:
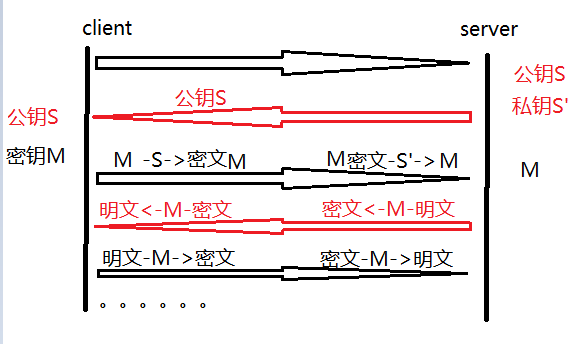
It can be found that we only need to combine the characteristics of the two encryption methods (symmetric and asymmetric), use the asymmetric public key to transmit in plain text in the network, and then encrypt the symmetric key M, so that both parties can transmit under the condition of cipher text Symmetric keys, from now on, using symmetric keys to encrypt data, isn't it perfect at this time, and the efficiency problem has also been well solved.
But are the three methods of 234, that is, the use of asymmetric transmission of public keys, really safe? We can briefly understand the man-in-the-middle attack:
man-in-the-middle attack
For solution 4, the man-in-the-middle attack has the following methods to deal with (23 is the same, so 234 is the same unsafe)
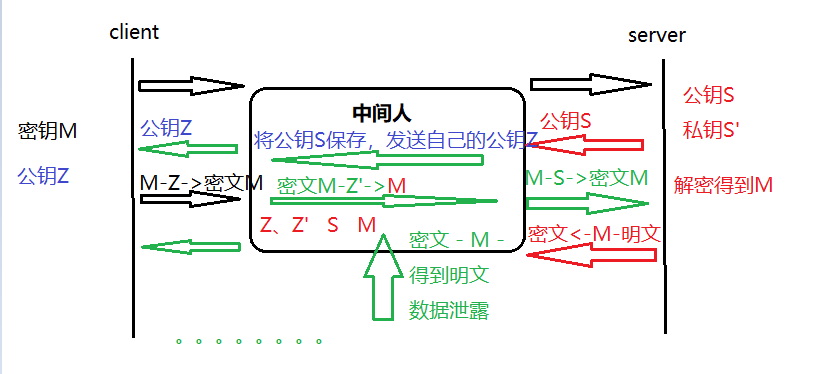
It can be found that even though the public key can be disclosed, the middleman can simulate the server to send its own public key to the client, so that the client thinks that the public key belongs to the server, which leads to the problem of data leakage.
So as long as the public key is passed, as long as there is a middleman intercepting it, the middleman can completely overcome it. But as long as we have exchanged the key, it will be too late if the middleman comes, but if the middleman comes first , it can be tampered with and replaced.
Therefore, the essence of a successful man-in-the-middle attack is:
1. The essence is that the middleman can tamper with the data.
2. The client cannot verify that the received public key is legal, that is, whether it is the public key of the other server.
Then if we want to transmit safely, we must destroy the two layers of essence, as long as the middleman cannot tamper with the data and the client can verify that the public key is legal, then it is safe!
Before introducing scheme 5, we first understand a CA certification, and then we can understand that scheme 4 using the authentication function can effectively prevent man-in-the-middle attacks.
CA certification:
In order to solve the problems caused by man-in-the-middle attacks, we need to enable the client to authenticate the validity of the public key passed in by the server.
Then we need an authoritative institution-CA institution to issue certificates-CA certificates. The validity is authenticated by a CA certificate.
Let's use the following figure to understand the process of client authentication legitimacy:

When we pass the audit, the CA will issue a certificate to the server. Let's first understand the process of issuing a certificate:
First of all, the certified personal information we send plus the public key (generated by algorithm) generates a data digest (data fingerprint) through a hash function, and then encrypts it with the private key of the signer (CA organization), and at this time a data signature. Then return the data signature + the data itself to the server to issue a certificate.
So how is it verified when verifying?
After the client receives the digital certificate (data + data signature), it first separates it, and uses the hash function to obtain a hash value, which is the data digest. Then use the CA's public key to decrypt the data signature to obtain the data digest. At this time, the two data summaries are compared. If they are consistent, it means that there is no man-in-the-middle attack. If they are inconsistent, it means that there is a man-in-the-middle attack, and the user is prompted.
So why can this process prevent man-in-the-middle attacks? Because in this way, the client will know that a man-in-the-middle attack has occurred, so as to terminate the communication and prevent data leakage, instead of continuing to communicate stupidly like solution 4.
We enable the client to identify whether the public key is legitimate. Because first, the client uses the public key of the CA-authority to decrypt the data signature, which means that the middleman cannot forge the data signature because he cannot obtain the private key of the CA. So even if the intermediary replaces the data in the data certificate, the client can identify it because the data digest generated by the hash function is inconsistent.
For the CA's public key, the client only uses its built-in CA public key to decrypt the signature.
If the intermediary replaces all the information, that is, does not forge the data certificate, apply for one by yourself, and replace the data with your own. Don't forget, the client communicates with the server. Before sending the communication, you must know the target ip and port number. These are in the certificate. Even if you are real, but you are not the server, everything is useless.
To sum up, scheme 4 with CA authentication is scheme 5, as shown in the figure below:
5. Scheme five - CA authentication + asymmetric encryption and symmetric encryption:
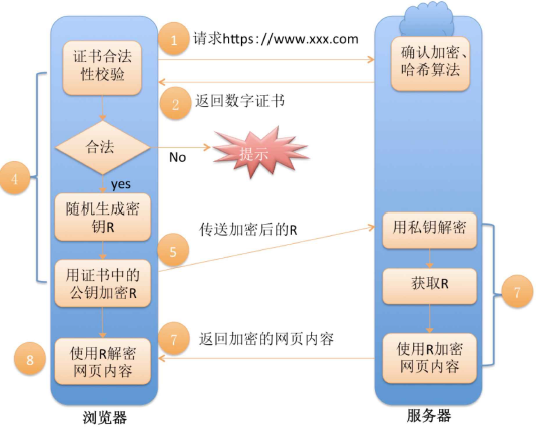
You can see that there are three sets of keys in the security layer of https. The first is the official asymmetric key of the CA, the second is the asymmetric key on the server side, and the third is the symmetric key - used to encrypt the ciphertext. We have done so much protection is actually to protect the transmission of plaintext in ciphertext, so that hackers cannot decipher the ciphertext. If the ciphertext cannot be deciphered, it will be prevented from obtaining the symmetric key, and the symmetric key will be encrypted. However, hackers are prevented from forging during the encryption process, and a CA authentication and identification mechanism is added to ensure the security of the symmetric key encryption. Thus, the security of https transmission is guaranteed.
So how does the middleman forward and accept messages between the client and the server?
how to be a middleman
ARP spoofing, ICMP attack, fake wifi && fake website.
You can find out by yourself~
2. Transport layer
1. Talk about the port number again
When we have a certain understanding of the application layer, we can continue to learn a layer of protocols related to the operating system kernel-that is, the transport layer.
In socket programming, we need to explicitly bind the port to the server. This port corresponds to a process in the host, and a port can only correspond to one process, and a process can correspond to multiple ports.
As for the client, since there are many clients that provide network services, it is not clear which ports are bound, so we leave it to the operating system for automatic binding.
Now, we can think that in the TCP/IP system, a five-tuple such as {source ip, source port, destination ip, destination port, protocol (UDP/TCP)} identifies a communication .
For the port number, we know that it is an unsigned 16-bit integer, so its value range should be: 0~(2^16 - 1).
0 - 1023 : Well-known port number. The ports of the extensive application layer protocols such as http(80), https(443), FTP(31), and ssh(22) are fixed.
1024 - 65535 : Port numbers dynamically assigned by the operating system. The port number of the client level is divided in this range by the operating system.
So we generally need to avoid these well-known ports when binding ports. For the kernel, the port number and process id are generally mapped together using a hash table, and the port number is used to find the corresponding process through the hash table.
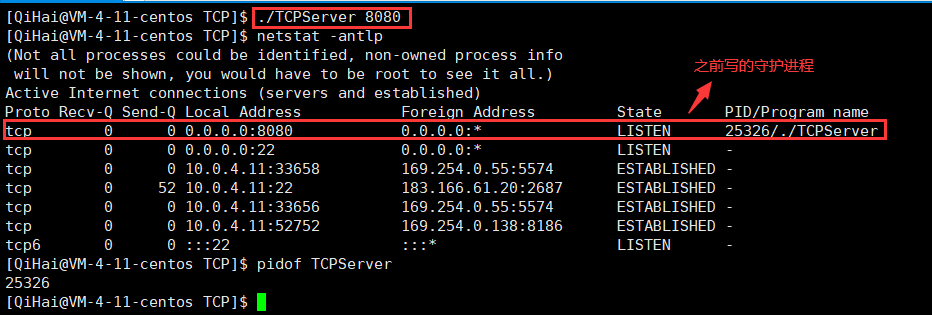
In the Linux command line environment, we can use netstat to view the process of transport layer protocol transmission.
Use of netstat
View the network status of the process.
options:
-n All that can be displayed as numbers are displayed as numbers.
-t TCP protocol communication
-u UDP protocol communication
-a displays all (some are not displayed by default)
-p View its process status
-l View the service in the listen state

Use of xargs command
In addition, you can actually use the command pidof to view the pid of the service, followed by the name of the service. For example, let's look for this daemon below. (Daemons generally end in d-naming convention)
What if we want to pipe this data to another command as a "command line parameter" instead of standard input ?
At this time, xargs can be used to convert the content of standard input into the content of command line parameters.

pidof TCPServer | xargs kill -9
can find that the process is indeed killed at this time.
2. udp agreement
User Datagram Protocol.
After a new understanding of the port, let's take a closer look at the principle of the transport layer udp protocol.
In network socket programming, we found that the client and server mode we implemented using TCP or UDP protocol is to serve the upper application layer. Such as http, our custom web calculator.
In the previous cognition of network foundation 1, we know that the application layer is together with the upper layer of the computer system, while the transport layer and network layer are together with the operating system kernel, and the data link layer is the driver.
Because it is serving the upper layer. Therefore, we need to separate the packets received from the lower layer or encapsulate the packets received from the upper layer, and then how to deliver them to the upper layer . In other words, we must first separate the header and payload.
udp protocol end format
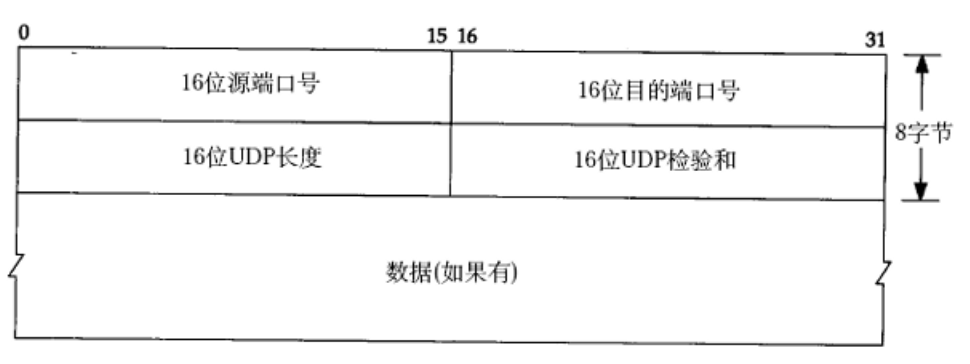
Through the above pictures, we can find that the header of the udp protocol is a fixed size, the size is eight bytes. That is 16*4 = 8 * 8 (1 byte is 8 bits). For the source port number, that is, the header attribute that needs to be sent down to the host in the future, and the destination port number is the basis for our delivery to the application layer. By extracting the header attribute, the port number can be obtained, so that the corresponding process can be found through the hash, and the payload can be copied into it. So how to cut out the payload? It can be found that there is a udp length of 16, and what is left after subtracting the fixed eight-byte length is the payload. Of course, if the UDP checksum fails, the entire udp packet will be discarded directly.
In fact, there is a structure to describe the 8-byte header attribute. struct udp_hdr. It allocates memory for each variable in the form of bit fields:
struct udp_hdr
{
uint32_t src_port: 16;
uint32_t dst_port: 16;
uint32_t udp_len: 16;
uint32_t udp_check: 16;
}When encapsulating, the application layer transmits to the transport layer, fills in according to the source port and target port, counts the length of the payload, and marks the checksum. Form a message and send it to the next layer.
When unpacking, first extract the header data: (struct udp_hdr*)start->src_port;...Extract each field of the header, then you can separate the payload, and deliver it to the application layer process according to the port .
Of course, there may be a lot of messages, that is, a large amount of information is transmitted. At this time, it is necessary to manage it, that is, the kernel data structure sk_buff. for collection management.
Specific message fields and understanding
First of all, both parties must know such an agreement, that is, the TCP/IP system can be used to communicate.
How to understand the unreliability and connectionless of UDP ?
Packet loss, no confirmation and retransmission mechanism, network failure cannot prompt the other party. (Note that unreliable here is not a derogatory term, but a characteristic of description: just because these mechanisms are not designed, so that their cost is low and the code is simple, they can be used in some cases)
How to understand datagram-oriented ?
The amount of data sent by the application layer to the transport layer will be sent as it is, without splitting or merging. That is to say, the payload is directly given to the buffer without any processing on it.
So how to understand the interfaces such as sendto and recvfrom provided by the operating system ?
First of all, we need to understand that interfaces such as sendto, write, recvfrom, read, etc. are copied to the buffer or copied from the buffer to the application layer, rather than directly sent to the other party. Sending is managed by the transport layer.
For udp, if you use sendto, you usually call the kernel directly to copy, and there is no sending buffer.
But udp has a receiving buffer, but there is no guarantee that the order of received udp is consistent with the order of sending, and it will be discarded when the buffer is full.
The udp socket can both read and write - it is a full-duplex mode.
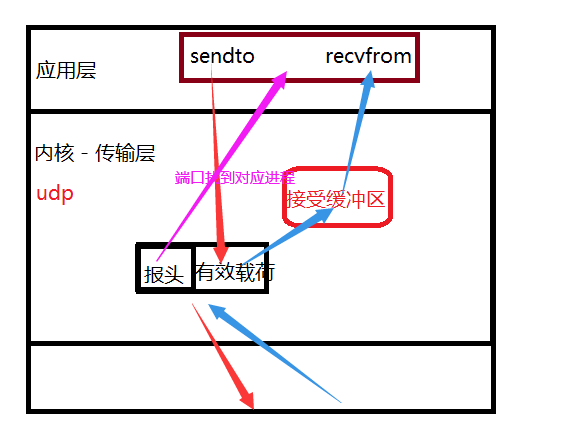
Understanding Full Duplex and Half Duplex
Full-duplex: For an io object, data can be read or written, and the two do not affect each other. Generally, in this case, two buffers (one sending buffer and one receiving buffer) are used without affecting each other.
Half-duplex: either listening or writing, both cannot happen at the same time.
For udp, according to the field udp_len, it seems that only 16-bit data can be stored, that is, 2^16 bytes = 2^10 * 64 = 64k. This size is a very small number in today's Internet environment, so when transmitting multiple data, it is generally transmitted multiple, subpackaged, and manually assembled by yourself.
Application layer protocol based on udp
NFS: Network File System
TFTP: Simple File Transfer Protocol
DHCP: Dynamic Host Configuration Protocol
BOOTP: Boot Protocol (for diskless device boot)
DNS: Domain Name Resolution Protocol
Of course, it also includes your custom application layer protocol using the udp socket program.
3. tcp protocol
Transmission Control Protocol.
Similarly, understanding this transport layer protocol requires understanding from two aspects: 1. How to encapsulate (unpack) the incoming message? 2. How to deliver ?
Like udp, let's first look at the message structure of the tcp transport layer protocol.
TCP protocol end format

It can be seen that the header structure of tcp and udp is much more complicated, because the header structure has a total of 5 rows, and each row is 32 bytes, so the size of the first 5 rows of the standard tcp header is 20 bytes.
If it is delivered, we first need to find the destination port number of this communication based on the header information, and then map the payload to this memory through hash mapping and copy the payload to the file cache for the upper layer to call.
For the 4-bit header length , since it is 4 bits, the range of representation is 0 ~ 60 bytes. It represents the total length of the header + options. Because the options are variable, the header can also be long, up to 60 bytes.
If we deliver, we must first unpack it.
Unpacking is similar to udp unpacking, and there is also a struct tcp_hdr (bit segment implementation) in the operating system. It's just that it should store the data in the first 20 bytes. So when the header is read, all that's left is the payload.
But what we need to pay attention to is that the data length of the entire message does not exist in the tcp header , which means that TCP is byte-oriented. In principle, it is impossible to judge the boundaries of packets and packets. How to be interpreted at this time is something that the application layer should worry about.
Confirm response mechanism && serial number
We know that the TCP protocol is reliable , that is to say, it can guarantee that the communication is received. How is this done?
It's like communicating between two people. If they are close, it can be said that the communication is very smooth. But once the distance is long, the communication will not be smooth, the cost will increase (it needs to be repeated), and the reliability will decrease. The reason is that the distance becomes longer.
Reliability is not discussed within the operating system stand-alone (after all, it is within the entire machine, and the distance is very small), but the reliability belongs to the network-TCP/IP, that is, whether the message sent by a host is received by the other party. (Received a similar communication, I can hear you clearly)
have to be aware of is:
1. In the network, is there a 100% reliable protocol? Nature does not exist. Because no matter whether it is the hosts of both parties, there is no guarantee that they will be received by the other party as the latest sent data. However, it can be 100% reliable locally: when a host receives a response, it can guarantee that the data sent last time is reliable. - That is, to ensure the reliability of history. -The essence is all the messages I send, as long as there is a matching response, it can guarantee that the message I just sent will be received by the other party . The confirmation response mechanism of the TCP protocol: But as long as a message receives the corresponding response, it can be guaranteed that the data I sent has been received by the other party. TCP three-way handshake.
2. However, there is no guarantee that the packet will not be lost. I can only identify it and save the data that did not lose the packet last time.
So, as long as I respond to you, you can confirm that I heard you clearly in the last communication, which is reliability.
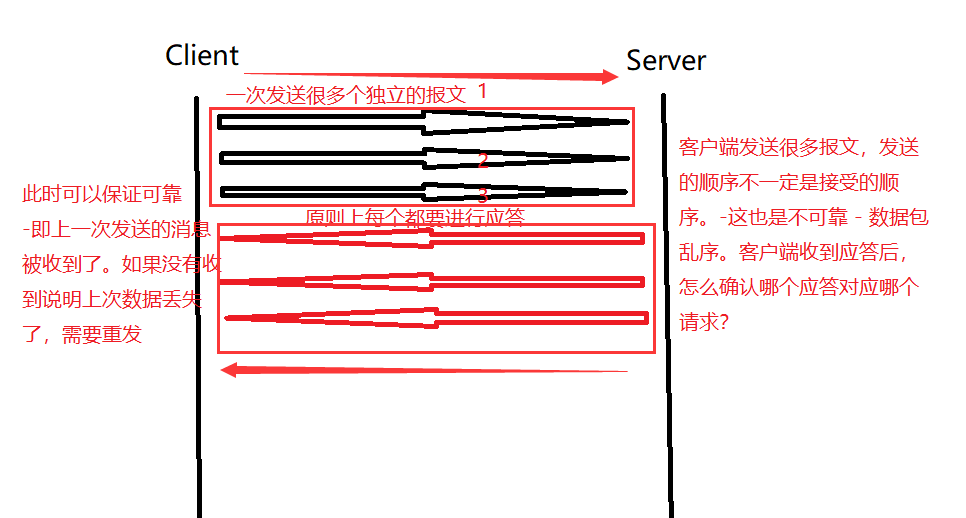
So how to identify it as accepted in the header attribute ? And how to solve this order problem?
Introduce the concept: serial number
Note that the sent message is not a simple string, and each message must carry a TCP message with a complete header. So a 32-bit serial number is included. For example, the serial number of the first message is 1000, the second is 2000, and the third is 3000. After sending out a response, the server will definitely give a serial number after the response, and will add 1 to the basis. For example, the received one is the confirmation serial number: 2001 1001 3001 At this time, the request message and the response message can be matched. (The confirmation sequence number means: all the messages before the corresponding number have been received, tell the other party to send from the sequence number indicated by the confirmation sequence number next time )
1. Match the request and response one by one.
2. The meaning of the confirmation sequence number: all the data before the confirmation sequence number have been received - the client is not afraid of partial packet loss.
3. Allow partial acknowledgments to be lost, or not to respond.
4. Why are there two field numbers? TCP is full duplex. Either party can receive or send. One party to any communication is full-duplex, and may also carry new data when sending an acknowledgment.
5. Out of order is the existence of unreliability. But it has been solved, because the sequence number in the message will carry the sequence number, you only need to sort multiple sequence numbers, and you can get the sequence number to the largest .
The reserved six bits are the temporarily unused part of the message. For sending and receiving data, we can understand it according to the following figure:
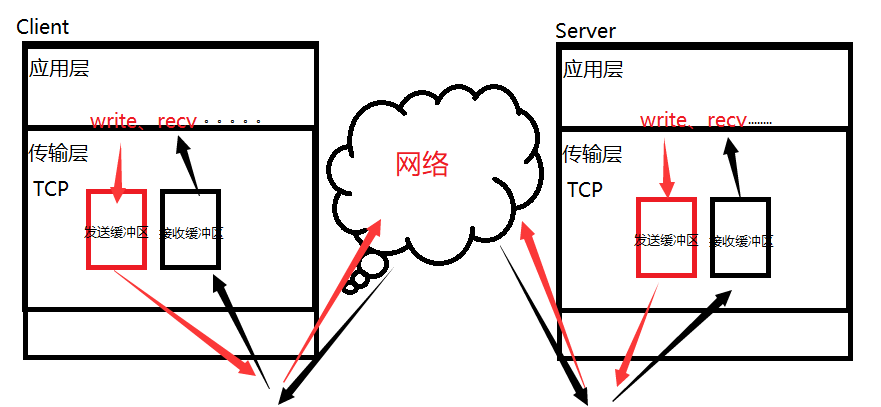 The problem that TCP solves is the problem of how to send, -Transmission Control Protocol-. The essence of TCP communication is to send and receive buffers to copy back and forth - the medium of copying is the network. TCP has sending and receiving buffers, and there are two teams of receiving and sending buffers with client and server. It is sent and received independently, so TCP supports full duplex.
The problem that TCP solves is the problem of how to send, -Transmission Control Protocol-. The essence of TCP communication is to send and receive buffers to copy back and forth - the medium of copying is the network. TCP has sending and receiving buffers, and there are two teams of receiving and sending buffers with client and server. It is sent and received independently, so TCP supports full duplex.
16-bit window size
Then, in the process of sending and receiving messages, if one party sends a message too fast and the other direction transmits too slowly (sent to the other party's buffer), we need to slow down the sender. So how to decide the slow amount?
For example, when the teacher is in class, if he speaks too fast during the explanation, we students can raise our hands and explain to him. And the process of raising my hand and explaining it is just telling the teacher my specific situation and asking him to make corrections according to the situation. For the TCP protocol, the presence of a 16-bit window size in the header helps us store similar information.
Because the two parties communicate, if one party wants to understand the situation and adjust the sending speed, it is based on the remaining space in its buffer . 16-bit window size, that is, the size of the remaining space. And the size of this window is sent by the sender, it is filled by the sender - it is to be sent to the other party. The other party adjusts the rate to the sent party according to this size. It is also the flow control of both parties . - Message exchange.
6 marker bits
The standard marker bit is 6 bits. Of course, it also depends on the actual situation.
First of all, we need to confirm one thing: What is the use of the marker bit? Why do we need so many flags?
Think about it, since it is called a marker bit, it is natural to mark the message type. Let the receiver make different processing actions according to this type.
For example, the client may send different types of messages to the other server: regular, connection establishment, disconnection, confirmation and other messages (the same is true in reverse)
It should be noted that different packets are processed in different ways . For example, when a connection is established - the connection is processed, and when it is disconnected, it must be released. Therefore, the server may receive a large number of different messages.
The meaning of each flag bit:
| marker bit | meaning |
|---|---|
| SYN | request connection |
| FIN | Disconnect |
| ACK | response characteristics |
| RST | connection reset |
| PSH | urge upward delivery |
| URG | emergency sign |
For ACK, the attribute of any message that has a response needs to be set to 1 (for example, there is no data - no payload, only one header is sent for response, and the response is made while replying to the message).
For RST, re-establish tcp connection. This kind of situation mainly occurs after the connection, the server restarts, the client is not clear, and the server will send this when it is still sending.
For PSH, if the remaining data in the window 16 sent by the server to the client is 0, and then the client waits repeatedly, it will send a message with PSH, urging the server to take it up as soon as possible.
For URG, it is an emergency flag, so it needs to be used with a 16-bit emergency pointer.
16-bit urgent pointer
Because tcp has an in-order arrival mechanism (advantage). When the data we send is read by the upper layer of the other party, it must be in order. But what if you want to jump in line?
If there is a URG in the message at this time, then through the mechanism, read the position of the 16-bit urgent pointer and deliver it upward as soon as possible. The 16-bit urgent pointer points to: the offset in the payload . And just one byte of data. Generally used for machine-system management, not normal business processing.
Now, let's combine some important concepts to deepen our understanding of the above-mentioned markers.
TCP establishes a connection: three-way handshake
For a server, there may be a large number of clients connecting in the future. Then there must be a lot of links in the server. For these link OS must be managed - first described in the organization.
- How to understand the link?
The essence is a data structure type of the kernel. When the connection is successfully established, the corresponding link structure object is created in memory, and a certain data structure is organized for multiple objects.
Also, there is a cost for the OS to maintain the link . (memory resources + CPU resources)
-Understanding the three-way handshake
First, we use the following diagram to understand the three-way handshake process:
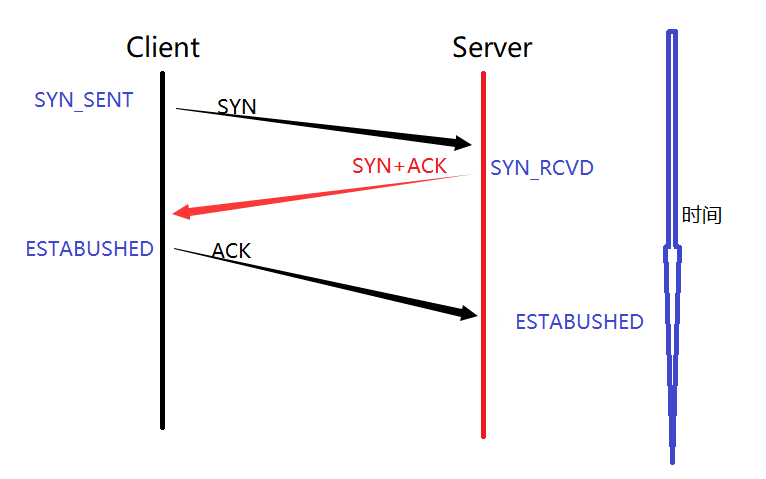
Notice:
1. The SYN and ACK shown in the figure are both messages with this flag bit, and the actual transmission is still a message, so don't be misled. And according to the actual situation, it takes a certain amount of time to send to the other party, so the line is inclined. English words in blue indicate the status of this network process.
2. The three-way handshake does not necessarily guarantee success. - Reliability is established after the link is successful. Note that after the last ACK message is sent, it is not necessarily guaranteed to be received.
3. For the client, once the ACK message is sent out for the last time, the state needs to be set to ESTABUSHED. For the first two times, it must be guaranteed that no packet is lost (there is a response, if not, it will trigger subsequent processing). But in fact, the last ACK message may not necessarily be received by the other party. - so may fail. A link can only be established when the server has truly changed to the ESTABUSHED state.
-Why the three- way handshake?
According to the above three-way handshake diagram and precautions. Can we understand why we chose the three-way handshake? And why not choose one handshake, two handshakes, or even four handshakes or more handshakes?
First of all, we need to understand a security risk to the server, such as SYN flood. denial of service attack
Understand a premise: OS maintenance links are costly . A server will inevitably have thousands of clients connected. The operating systems of so many linked servers must be managed. Once managed, it will consume the server's memory and cpu resources!
Once a malicious person repeats meaningless applications to the server for no reason, it may cause the server to consume too much resources, cause the OS to hang up the server process, and cause the server to crash.
In terms of consuming server-side resources, the design of TCP should try to make the server pay as much or less as the cost of the client. But the main purpose of TCP is just to facilitate network communication, and it doesn't think too much about security . So in fact, the design of TCP should be to verify the dual-end full-duplex of its TCP service, and security is only considered by the way.
If it is a handshake :
Then once sent, the server should establish a connection. But there is a cost for the server to maintain the link. If the client sends multiple times, the server is likely to hang up directly. (SYN flood) (But in fact, the three-way handshake cannot prevent this kind of bombing, but the cost becomes higher)
twice ?
Similar to the third sending, the server has no way of knowing whether the client knows it or discards it maliciously. But at this time the link has been established. So similar to the first attack, it is equally easy to cause the server to hang up.
Three times !
If it is repeated three times, it can be found that the one who initiates the connection needs to complete a response. That is, to complete a response, the sending end enters the ESTABUSHED state first , and the sent end only establishes the ESTABUSHED state after receiving the response . Time will be pushed back. In this case, like the previous two attacks, the client's expenditure on the server is relatively low. And now, the cost on the client side is on the higher side - if the attack is successful, then it's an equivalent resource outlay. It cannot be eliminated, but it can be effectively resisted. Note that the previous refers to the cost of a single machine attack.
four times ?
If it is four times, it can be found that at this time, the last ACK message is still handed over to the sender. If the sender is malicious, it will cause similar things to be sent twice, which is also not advisable.
In fact, security guarantees are still carried out on the application layer . The purpose of the three-way handshake is not for security. 1. It is to allow the client to bear the same pressure as the server in the process of establishing a connection . 2. Verify full duplex . Verifying full-duplex is like when we make a call, I get through, and the other party says hello, which means he is connected, can you hear it? I also responded with a hello, indicating that I heard it, and now our call can start-this time is to verify that I can hear and speak, and the other party can do the same.
In fact, a simple conclusion can be drawn Odd number of handshakes: the pressure is biased towards the sender .
For the signal RST, it is also possible that if the server does not receive the ACK sent for the third time, if the client sends a message instantly - at this time the server receives it, because the connection is not established successfully - the server will send RST to the secondary client - connection reset . Of course, this is just a simple example, and the chances of actually appearing are very small.
TCP disconnect: four waves
Similarly, both ends need a three-way handshake when establishing a link, and both parties need to be clear when the link is disconnected, so four waves are required.
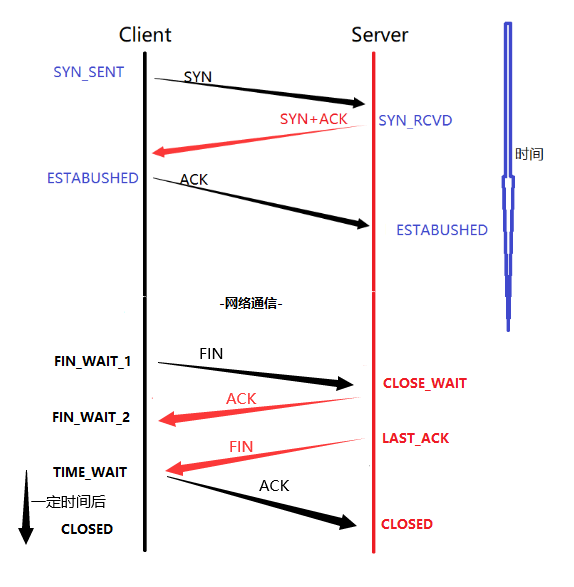
What is CLOSE_WAIT?
CLOSE_WAIT can be found that as long as the client actively sends the header (FIN) of the disconnection mark, the server will be in a CLOSE_WAIT state at this time.
So if the server does not send FIN to the corresponding client at this time - that is, disconnect, then there will be a large number of links in the CLOSE_WAIT state on the server at this time.
Let's use a simple experiment to prove the CLOSE_WAIT state of the above server. It can be realized very simply, that is to say, the server side accepts that the other party closes the connection without closing the file descriptor. (Write a test code below, by the way, review the process of TCP native writing network communication - only the server side is used for testing, and the client side can be replaced by telnet)
// TCPServer.cpp
#include <iostream>
#include <sys/types.h>
#include <sys/socket.h>
#include <netinet/in.h>
#include <arpa/inet.h>
#include <cstring>
#include <signal.h>
#include <unistd.h>
#include <errno.h>
#include <stdlib.h>
// 样例测试,测试服务器端出现CLOSE_WAIT状态
// 即客户端发送断开链接,服务器不断开链接也就是不close。此时就会维护在此状态
void User(char* str)
{
std::cout << "./" << str << " port\n";
}
int main(int arc, char* argv[])
{
if (arc != 2)
{
User(argv[0]);
}
int serverSock = socket(AF_INET, SOCK_STREAM, 0); // 0自动识别,使用TCP协议进行通信
struct sockaddr_in addr;
memset(&addr, 0, sizeof addr);
addr.sin_family = AF_INET;
addr.sin_port = htons(atoi(argv[1]));
inet_aton("0.0.0.0", &addr.sin_addr);
if (bind(serverSock, (sockaddr*)&addr, sizeof addr) < 0)
{
std::cerr << "bind error: " << errno << "-" << strerror(errno) << std::endl;
exit(1);
}
// TCP初始化绑定完后需要设置监听套接字处于监听状态
if (0 > listen(serverSock, 20)) // 限定等待数列为20个
{
std::cerr << "listen error: " << errno << "-" << strerror(errno) << std::endl;
exit(1);
}
// 连接逻辑处理 常驻进程
signal(SIGCHLD, SIG_IGN); // 子进程退出返回此信号,设置为用户默认,这样就不会产生僵尸进程
while(true)
{
// 首先先建立连接
struct sockaddr_in client_addr;
memset(&client_addr, 0, sizeof(client_addr));
socklen_t addr_len = sizeof(client_addr);
int sock = accept(serverSock, (sockaddr*)&client_addr, &addr_len);
// 网络转本地字节序
uint16_t clien_port = ntohs(client_addr.sin_port);
char* client_ip = inet_ntoa(client_addr.sin_addr);
if (sock < 0) continue;
if (fork() == 0)
{
// 子进程
close(serverSock); // 关闭监听套接字,它不需要
char buffer[1024];
while (true)
{
ssize_t n = recv(sock, buffer, sizeof(buffer) - 1, 0); //阻塞等待接受
if (n > 0)
{
buffer[n] = '\0';
std::cout << "[" << client_ip << ": " << clien_port << "]# " << buffer << std::endl;
}
else if (n == 0)
{
// 对方断开连接了
// close(sock); // 测试CLOSE_WAIT状态
// break; // 测试此状态此进程也不可退出,因为进程退出也会关闭文件描述符的
}
else
{
// n < 0 出现错误
close(sock);
std::cerr << "recv error: " << errno << "-" << strerror(errno) << std::endl;
break;
}
}
}
// 父进程
close(sock); // 关闭服务套接字,父进程不需要
}
return 0;
}It can be found that when the other party closes the connection, the server should also close the connection, but we do not close and do not exit the process. In this way, will there be a connection in the CLOSE_WAIT state in my server TCP connection?
We use three clients to connect, and then disconnect in turn, you can see the effect of changing to CLOSE_WAIT state in turn:
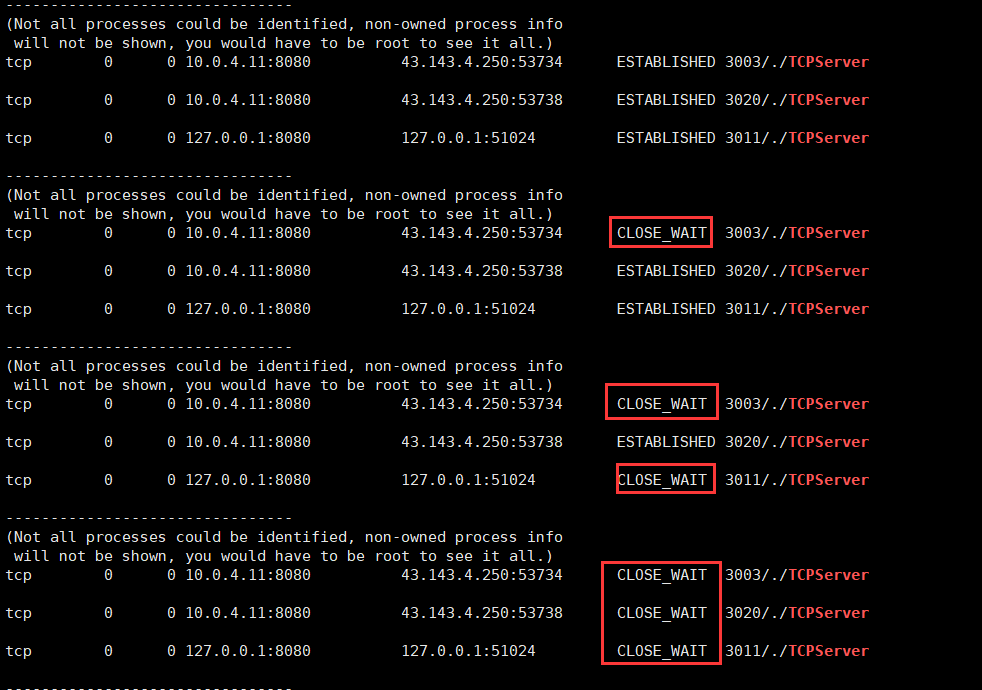
It can be seen that the experimental effect is indeed the same, so we must pay attention to the standardization when writing code, otherwise there may be a danger of the server crashing and exiting!
Understanding: TIME_WAIT
If it is the party that actively disconnects, after four waved hands, it will enter the state TIME_WAIT first in order to send responses at the end. This state will not exit immediately, it needs to be maintained for a period of time. So although the connection has ended at this time, the ip and port are still occupied. So it is impossible to bind repeatedly at this time.
Why do you need the state of TIME_WAIT ?
There may be some packets stuck on the road, (during the four waved hands) the maximum time MSL of the one-way transmission time, waiting for 2MSL can allow the historical data of the network to dissipate - both parties are discarded or received. Because it is possible to reconnect: there is data at this time in history, which may affect the communication between the two parties. So try to ensure the dissipation of network packets. Of course, it is only an estimated time and cannot be 100% sure. (MSL stipulates 2 minutes in RFC1122, the default configuration time of centos is 60s, cat /proc/sys/net/ipv4/tcp_fin_timeout to check MSL is the maximum survival time of the message) Of course, it can also theoretically help the last ACK to be delivered . (This is also a matter of probability)
Of course, there are still some reasons with the server side. If it directly enters the CLOSED state, the last ACK sent is not received, and the server will retransmit the FIN if it does not receive it, and it cannot be received at this time. Although it will also close in the end. But it can be closed accurately within a certain period of time.
However, in practical applications, if the server is actively disconnected (such as a bug), then we need the ability to restart the server immediately! At this time, if you can't restart immediately, there may be a big problem.
setsockopt
In order to enable the server to bind immediately after actively disconnecting and exit the TIME_WAIT state, the system designed this interface to facilitate our immediate binding operation:
man 2 setsockopt
header file :
#include <sys/types.h>
#include <sys/socket.h>Function prototype :
int setsockopt(int sockfd, int level, int optname,
const void *optval, socklen_t optlen);Options for manipulating the socket referenced by the file descriptor sockfd.
Function parameters :
sockfd: corresponds to the socket descriptor.
level: Specifies the level at which the option resides. Such as SOL_SOCKET .
optname: The name of the option. SO_REUSEADDR|SO_REUSEPORT can access the relevant settings of the TIME_WAIT state.
optval: Access the value of setsockopt. When you need to open it and exit the TIME_WAIT state immediately, you can set it to 1 outside.
optlen: the size of optval.
return value :
Returns 0 if successful. If an error occurs, -1 is returned, and errno is set appropriately.
Before there is no binding, our server exits immediately and we can see the following results:
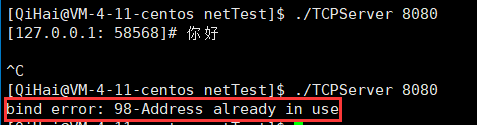
![]()
![]() It can be seen that it is necessary to wait for a certain period of time before continuing to bind the connection.
It can be seen that it is necessary to wait for a certain period of time before continuing to bind the connection.
When we add the code:
main()
{
// ......
int serverSock = socket(AF_INET, SOCK_STREAM, 0); // 0自动识别,使用TCP协议进行通信
// 对监听套接字进行处理,让服务器连接时主动退出,能够立即启动
int opt = 1; // 表示打开
setsockopt(serverSock, SOL_SOCKET, SO_REUSEADDR | SO_REUSEPORT, &opt, sizeof opt); // 在绑定前设置好
//......
if (bind(serverSock, (sockaddr*)&addr, sizeof addr) < 0)
{
std::cerr << "bind error: " << errno << "-" << strerror(errno) << std::endl;
exit(1);
}
//......
}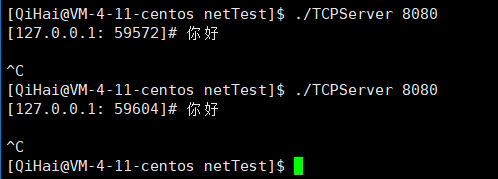
![]()
Through the experimental phenomenon, we can find that although the server actively disconnects the connection to the TIME_WAIT state, our server can still start immediately after connecting again, instead of having to wait for a specific time.
timeout retransmission
In the TCP protocol, if we send a data segment (message), if the sender does not receive the specified response within a certain period of time. If it times out, it is deemed to be discarded and retransmitted .
Then there are two situations at this time: 1. The sent data segment is lost, and the packet is lost. 2. The data segment sent by the sender is lost, and the response is lost. (Small problem: The other party may receive duplicate messages when the packet is lost and retransmitted. Receiving duplicates is also a kind of unreliability. The solution is to deduplicate according to the sequence number in the message.)
How to determine the timeout period? Naturally, the timeout period should neither be too long nor too short. Of course, it cannot be set to a fixed time - when the network is good, the timeout period should be shorter, otherwise the timeout period should be longer. (In Linux, 500ms is used as a unit. Retransmission is performed in integer multiples of 500ms each time. 1*500, 2*500, 4*500 index, if the link is considered invalid after a certain number of times, the client will automatically disconnect the link. )
flow control
Since the possible processing data at both ends of us is limited. The sent data must be sent according to the receiving capacity , instead of sending a lot of data and discarding it directly.
When the receiving end sends ACK, put the receiving buffer size into the header window size field.
If it is full, it will not be sent anymore. It needs to send a window detection data segment (that is, a TCP header) periodically, so that the receiving end can tell the sending end the size of the window. Of course, the window can also be updated, and the window update notification can be sent. (both strategies are in use)Notice:
1. The same is also bidirectional. - full-duplex - do it at the same time.
2. Then when I send a message for the first time, how do I know the size of the receiving area of the other party? - What we need is the ability of the other party to accept, that is, the size of the receive buffer. But what the question says is sending data for the first time. This is not the first time messages have been exchanged. --- During the three-way handshake, no data will be carried during the first two handshakes, but the size of the receiving buffer can be carried on the header.

Of course, if you want to expand the acceptance capacity, you need to adjust the window size field. In fact, there is an expansion factor M in the TCP40 byte option, and the value of the actual window size field is moved to the left by M bits.
sliding window
First of all, in the TCP mechanism we have seen before, the reliability of data is basically guaranteed. So can we mainly improve the efficiency of network sending data?

Before, it was a serial operation. Reply one at a time. very slow. So now a large amount of data is sent at one time, and the efficiency can be improved.

1 Therefore, when sending in parallel, the response is also sent in parallel. The IO time coincides.
2 Theoretically, how many sends should be sent and how many replies should be sent.
3 Flow control: It is allowed to send a batch of data (simultaneously), of course, the premise is that the total amount is less than the receiving capacity of the other party (the size of the window).
As for the origin of the sliding window, we can regard the sender's buffer as the following structure:
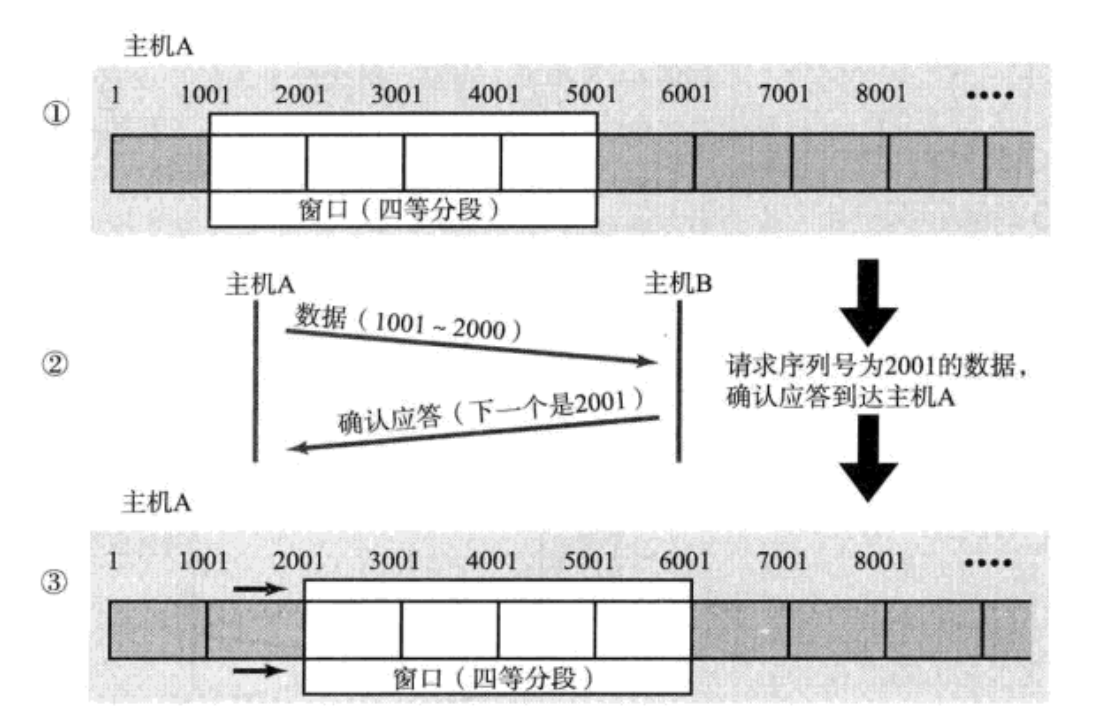
In fact, according to the window, we can divide it into three parts: 1. Before the window: send and receive the response part (can be deleted), 2. It can be sent directly, no response is needed for the time being, 3. Not yet sent.
The sliding window belongs to the sent data in its own send buffer. The window size is the maximum value of data without waiting for a response.
Essence: The sender can push the upper limit of data to the other party at one time. - Sliding windows need to obey flow control. == It is determined by the other party's ability to accept . (Not only want to push more data to the other party, but also ensure that the other party comes and accepts)
The essence of sliding window:
In fact, there are two pointers to the start and end positions of the sliding window, int win_start, win_end;
1. The sliding window does not necessarily move right as a whole. If the other party does not upload, the acceptability is reduced
by 2. It can be 0, that is to say, the acceptability of the other party is 0.
3. If you do not receive the response of the start message, but receive the middle one, then there is no problem at all. (The meaning of the serial number is)
4. The meaning behind the timeout retransmission: the data must be temporarily saved if no response is received.One strategy: update according to the acknowledgment sequence number of the reply:
w in_start = received the confirmation sequence number in the response message , end = start + the ability of the other party to accept ( there are two conditions )
5. If the sliding window keeps sliding to the right, will it go out of bounds? -nature doesn't exist. In fact, TCP's send buffer is circular. Use linear to simulate the ring, and then perform modulo processing.
high speed retransmission
Does the sliding window solve the efficiency problem or the reliability problem? Naturally, it focuses on efficiency issues.
If packet loss occurs during the sliding window:
1. If the data packet has arrived and the ACK is lost, in this case, it does not matter if part of the ACK is lost, because it can be confirmed by the subsequent ACK.
2. If the data packet is lost during transmission and the receiver does not accept it, according to the returned response, it will confirm that there are three or more consecutive serial numbers, and the corresponding data will be retransmitted at this time.
The above is the high-speed retransmission mechanism.
- High-speed retransmission mechanism. There is a loss in the middle, and the ACK sequence number can only transmit the sequence number before the loss. At this time, multiple message responses transmitted are all of this sequence number. If three of the same are received, then this will be resent.

So since there is a fast retransmission (high-speed retransmission mechanism), why do we need a timeout retransmission? Of course, because fast retransmission must be conditional : three times in a row! And it is also possible that the ACK response is lost. So they are not opposites, they are complementary and cooperative . For fast retransmission, during the waiting time for timeout retransmission, if the confirmation sequence number in the confirmation header appears three times in a row to specify a position, then it has been confirmed that the confirmation here is lost, not possibly lost, and there is no need to wait for the timeout at this time Retransmission time, and direct transmission saves time and increases efficiency.
congestion control
Earlier, we can find that whether it is timeout retransmission, fast retransmission, flow control, link management, sliding window, deduplication & sequential arrival, sequence number mechanism, confirmation response and other TCP mechanisms seem to be directly aimed at both ends. But it seems to have overlooked an important factor in the middle: the network .
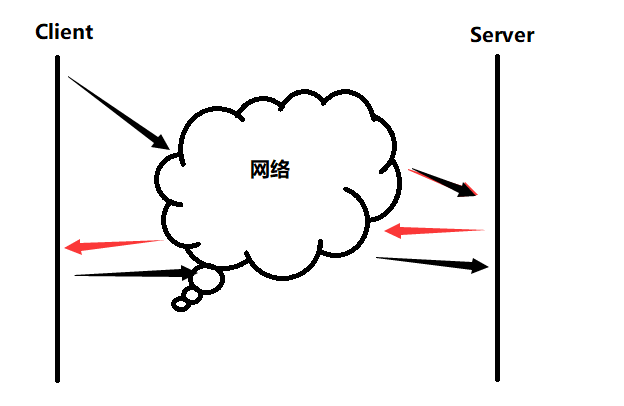
If there is a small amount of packet loss in the transmission state, it should be your own problem, and you can use the double-ended mechanism to solve it, but if a large number of packets are lost, then it is a network problem (network congestion). Do you need to retransmit at this time? ? ? ?
Don't forget, this network is not just for your link, but for thousands of links. A protocol that everyone uses, if it is recognized as retransmission, then the congestion will be aggravated.
So how to solve it at this time? Use the slow start strategy to solve it.
Send one at first, receive the response, gradually increase the transmission, and continue to send if the response is received. For example: 1, 2, 4, 8...

Congestion Window: A number on the TCP/IP protocol stack. When a single host sends a large amount of data to the network at one time, it may cause an upper limit for network congestion .
So can we grow up to 1, 2, 4, 8... infinite times? Of course not. First of all, the size of the sliding window actually = min ( the size of the congestion window , the acceptance capacity of the other party) ;
For the congestion window, it should be exponential growth in the early stage, and linear growth in the later stage is reasonable.
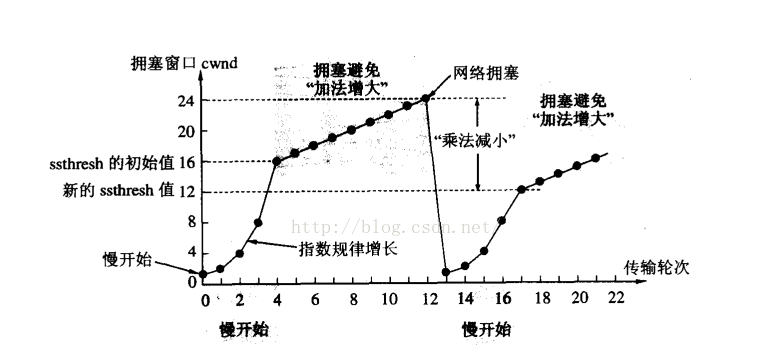
Exponential growth has been too fast. That is to say, the congestion window cannot be doubled. Introduce a slow start threshold . When the threshold is exceeded, it will grow linearly later. Give up exponential growth. (The threshold will also change, becoming half of the last congestion window - the multiplication decreases over the threshold: congestion avoidance - addition increases)
What is the exponential growth in the early period after the congestion?
Slow early stage, very fast late stage. Once congestion: 1. Let the network have a chance to slow down in the early stage. 2. In the middle and late stages, after the network is restored, the process of restoring communication as soon as possible. - Sending slowly may affect communication efficiency.
In summary, we can summarize the way of congestion control:
Because of the influence of network environment factors, the actual size of the sliding window should be determined by the smaller value of the congestion window size and the receiving capacity of the other party. When the congestion window is mainly affected, the mechanism adopted by the congestion window is the slow start + congestion avoidance algorithm .
Once the network is congested, first the congestion window is initialized to a small value, and then every time it increases, it doubles the value of the previous one. When it increases to a certain threshold, stop multiplying, enter the congestion avoidance state, and increase each time in a linear growth manner. It can effectively control the rate of network transmission to ensure the stability and reliability of network transmission.
delayed response
Similar to the buffer, think about what we use to solve the difference in memory and hard disk speed. That is to say, in order to increase the speed or reduce the pressure, we can adopt a delayed response mechanism.
In TCP, because when the receiver receives a message, it will not send it back immediately. If I wait for a while, I can synchronize a larger acceptance capacity for the other party. If the acceptance capacity is greater (regardless of congestion for the time being), then the other According to the sliding window, a single IO will send more data to improve efficiency. And this can also reduce the number of packets in the network and reduce the traffic in the network .
Because of waiting for a while, we can let the upper layer of the receiving party take away the TCP layer data as soon as possible, so that larger data can be written in the window size of the returned message. However, the delayed response mechanism also brings some problems. For example, in a long time interval, if a data packet is lost or damaged, the receiver cannot notify the sender to resend the data in time. Therefore, TCP needs some parameters to control the delayed response, limit the number of reads or the waiting time (the number is generally 2, and the time is 200ms).
piggybacking
When the receiver sends header information with an acknowledgment (ACK) to the other party, it can also carry the data packet itself . In this way, the traffic consumption of the network can be reduced, and there is no need to send it twice to improve efficiency.
However, the piggyback mechanism also has some problems. First, if the sender's acknowledgment information is delayed, the data packets to be sent will also be delayed, resulting in a decrease in network transmission efficiency. Secondly, if the sender sends multiple data packets at the same time, but one of the data packets is lost or damaged, then the receiver cannot just send an acknowledgment message for the data packet, but must resend the acknowledgment information for all data packets, thereby increasing network traffic. traffic.
In short, piggybacking is a means of optimizing efficiency in TCP, which improves the efficiency of TCP transmission to a certain extent.
TCPSummary
After so much TCP learning, we can summarize the above features:
1. The reliability of TCP: checksum, sequence sum, confirmation response, timeout retransmission, connection management, flow control, congestion control.
2. The efficiency of TCP: sliding window, fast retransmission, delayed response, piggyback response.
Moreover, because it is based on byte stream transmission, there are so many mechanisms above to manage reliability and efficiency issues, so how to understand that TCP is byte stream-oriented ?
1. TCP is byte-oriented :
We can use real-life examples for comparison. UDP is a User Datagram Protocol, so it's like sending a courier, we need to accept one by one what we buy.
TCP is a transmission control protocol, like a water pipe. The pipe only needs to ensure reliable and fast water transmission, but there is no obvious distinction or use of water. We need to use different buckets or cups to distinguish the use of these waters.
Byte-stream-oriented is exactly what it means. Data has no boundaries or distinctions . TCP doesn't care what the data actually is. - It is determined by the application layer independently. The application layer does not need to consider when to send and how much to send at a time.
2. TCP data sticky packet problem :
Because the data has no boundaries and distinctions, there may be a problem of data stickiness . Therefore, when TCP is used for data transmission, the upper layer must formulate a protocol to standardize the reading of data. That is to say, the upper layer needs to clarify the boundary between the payload and the payload, and can use some such as fixed length, special characters as line breaks, and set the header-standard field, length and payload. This is done at the application layer. Because of this, UDP data is not sticky, because the protocol helps the application layer to achieve distinction, so it is called user datagram.
3.TCP exception problem :
So have we ever thought that for two hosts that are using TCP connection, if there is an exception (disconnection is not a normal process), how does TCP solve it?
1. The process of one of the hosts terminated suddenly. Because when the process terminates, all file descriptors opened by the process are closed by default, and our socket is actually a file descriptor, so at this time, we will wave to the other party four times, which is a normal process.
2. What if there is a sudden power failure or network disconnection? First of all, because the host has detected that the network environment has changed, the link must be closed (it will be gone immediately when the power is turned off). Then, for the host of the other party, first of all, there is a certain degree of keep-alive for this link. If the other party does not send me messages for a long time, then I will periodically ask the other party if they are still there. If you are absent for many times, you will actively disconnect. (Such a strategy can ensure that the pressure on the server to maintain the link is reduced)
4. Comparison between UDP and TCP :
The application layer protocols that use the TCP protocol include: HTTP/HTTPS ssh telnet fip smtp.
Clarify the following two points:
UDP is an unreliable, connectionless transport layer protocol for user data packet transmission.
TCP is a byte-stream-oriented, reliable, and connected transport layer protocol.
Although UDP is unreliable and connectionless, it is simple to implement. In the environment where you want to develop quickly and allow a small amount of packet loss, you can use UDP for network communication. For those who need accurate data transmission and cannot discard any data, you must use TCP. The network communicates, so each has its own usage environment.
Classic interview question: Please describe how to use UDP to achieve reliable transmission? Use the similar implementation mechanism of TCP to control each data segment of UDP on the application layer.
5. Understand the second parameter of the listen interface :
We know that the listen interface was used by us to set the listening socket of the server in the previous network socket programming , and its second parameter is the length of the connection queue. So how to understand this connection queue?
We know that if two hosts communicate using the TCP protocol, they will first perform a three-way handshake. SYN, SYN+ACK, ACK (After the client sends SYN, it becomes SYN_SENT state. After the server receives the corresponding link, the connection becomes SYN_RCVD state, and then sends SYN+ACK. After the client receives it, it first becomes ESTABUSHED state. Then send a response to the server, and the server will change to the ESTABUSHED state after receiving it). So imagine that the interface accpet to get the link on the server side is involved in this process?
It does not participate, its task is only to obtain the established connection. That is to say: first establish a good connection, and then accept to obtain the corresponding connection. Without calling accept, the connection can be successfully established. If the upper layer does not have time to call accept, the other party still has a large number of connections, so the connection should be established first? No, otherwise the server will easily hang up. And also need to store these connections.
In other words, TCP actually maintains a queue ( full connection queue ) at the bottom layer to store a connected connection. And accept is the pop of this queue. The second parameter of listen is to specify the length of this queue. When this length is full, TCP will maintain another queue ( semi-connection queue ) to temporarily store the subsequent connections - at this time, the server does not send an ACK response, the other party is in the SYN_RCVD state, and the server's connection is in the SYN_RCVD state. If after a certain period of time, the queue is still full, then these subsequent connections will be released and refused service.
int listen(int sockfd, int backlog);
The meaning of the backlog parameter: the length of the bottom full connection queue = parameter + 1; the full connection is used to save the est state, but there is no accpet request on the upper layer. Semi-linked queue : request to save SYN_RECV and SYN_SENT status (very short life cycle)
This parameter cannot be 0 and cannot be too long. (Too long to maintain too much waste of resources and many connections are invalid connections)
We can slightly modify the above code and test the backlog parameter. No more demonstrations here.
To be continued...