Fengse organizes self-concave non-temple
qubits | public account QbitAI
At present, the view that "pre-training large models are the foundation of the AIGC era" has become a consensus in the industry.
However, training a large model with a scale of 100 billion parameters still faces many challenges.
At the China AIGC Industry Summit, Zhang Peng, CEO of Zhipu AI , pointed out that we face at least three major challenges in this regard:
One is the cost . For example, a GPT-3 with 175 billion parameters burned 12 million US dollars (about 83 million yuan);
The second is manpower . There are nearly 70 authors in the Google PaLM-530B author list, but there is still a shortage of large-scale model talents in China;
The third is the algorithm . The training process of the 100 billion large model is extremely unstable. Once an accident occurs, the cost and risk will be additionally increased, and the performance cannot be guaranteed.
Therefore, Zhang Peng believes that we should give more patience to domestic practitioners.

Zhang Peng, graduated from the Department of Computer Science and Technology of Tsinghua University, is now the CEO of Beijing Zhipu Huazhang Technology Co., Ltd. (referred to as Zhipu AI). The vision of machines thinking like humans". Over the past few years, the company has successively released GLM series large-scale models, ChatGLM, CodeGeeX code large-scale models, etc., and has become one of the earliest and most experienced companies in large-scale model development in China.
At this conference, in addition to thinking about the pre-training large model itself, Zhang Peng introduced the latest research and development and implementation progress of Zhipu AI in this field, including:
(1) GLM-130B that can be compared with the GPT-3 base model
(2) ChatGLM-6B, which can run with only a single GPU, has more than 1 million downloads worldwide
(3) CodeGeeX, an auxiliary programming tool that helps programmers "write" more than 4 million lines of code every day
In order to fully reproduce these wonderful contents, Qubit has edited his speech without changing the original meaning.
China AIGC Industry Summit is an industry summit hosted by Qubit, and nearly 20 industry representatives participated in the discussion. The offline audience was 600+, and the online audience was nearly 3 million. It received extensive coverage and attention from dozens of media including CCTV2 and BTV.
Key points of the speech:
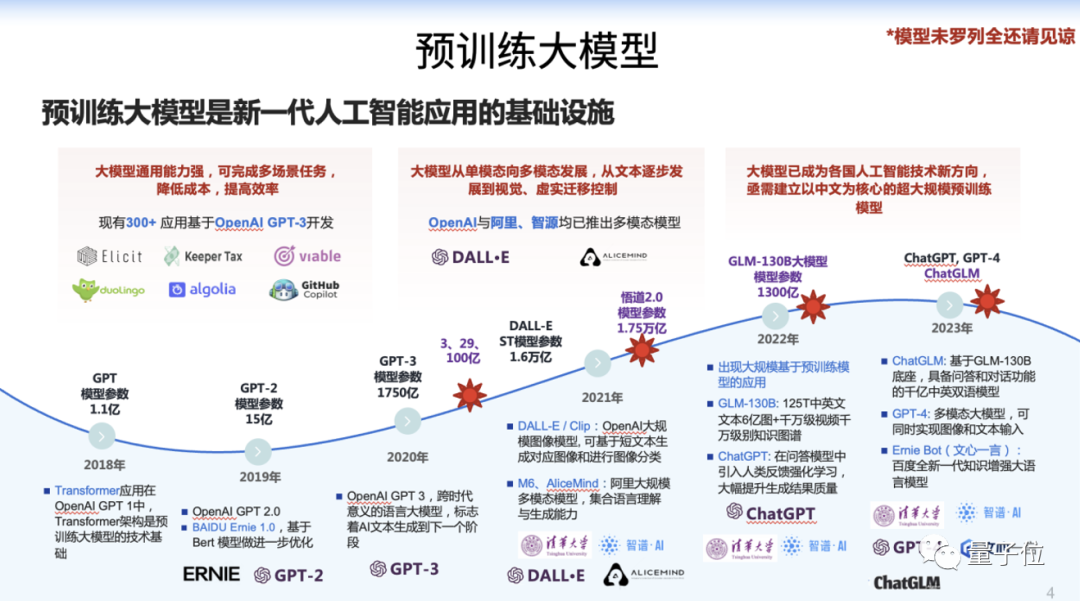
The pre-trained large model is the infrastructure of a new generation of artificial intelligence applications.
Training a high-precision 100 billion Chinese-English bilingual dense model is of great significance to the research and application of large models.
The cost of training hundreds of billions of large models is high. For example, the total cost of GPT-3 with 175 billion parameters is $12 million.
The common hundreds of billions of models have a huge amount of training data and a long training period, and various accidents will inevitably occur. All of these surprises introduce additional costs and risks, as well as unpredictable model performance degradation.
The open source dialogue model ChatGLM-6B has only 6.2 billion parameters and can run on a single GPU, which means that a slightly better graphics card with a notebook is fine.
The intelligent emergence of large models has not yet seen the limit...
For the current GPT-4, humans can't pass it, at least in the exam.
The following is the full text of Zhang Peng’s speech:
The pre-trained large model is the foundation of the AIGC era
What exactly is the pedestal of the AIGC era?
I believe everyone will definitely say that it is a pre-trained large model.
The so-called pedestal is the infrastructure, why can it become the infrastructure?
There are two reasons.
First, such a large model can provide very powerful generalization capabilities, can complete multi-scenario tasks, reduce costs, and improve efficiency. This is a very key feature.
Second, when the scale of the model reaches a certain level, we can incorporate more knowledge into it, including cross-modal knowledge, so that the model can better simulate human intelligence.
Therefore, related work has become a research hotspot in the entire industry in the past few years, including the generative capabilities brought by models such as ChatGPT and SD (stable diffusion), which are derived from the birth of such large models.
During this process, we continued to track the frontiers of technology and did some related work, which we will gradually develop later.
Today we are delighted to observe that large model capabilities are emerging.
Why does quantitative change cause qualitative change in intelligence?
In the past few years, everyone talked about Moore's Law for large models, and the number of parameters in a single model increased tenfold or even a hundredfold every year.
Now, the emergence of intelligence also shows Moore's Law, and even develops at a higher speed.
Among them, training a high-precision 100 billion Chinese-English bilingual dense model is of great significance to the research and application of large models.

We can see that in the past three or four years, many people have come to do related exploration and research.
Not only foreign countries, but also many domestic enterprises and research groups have done related work. Every success is the cornerstone of the achievements we see today, and bricks are spliced into the final foundation.
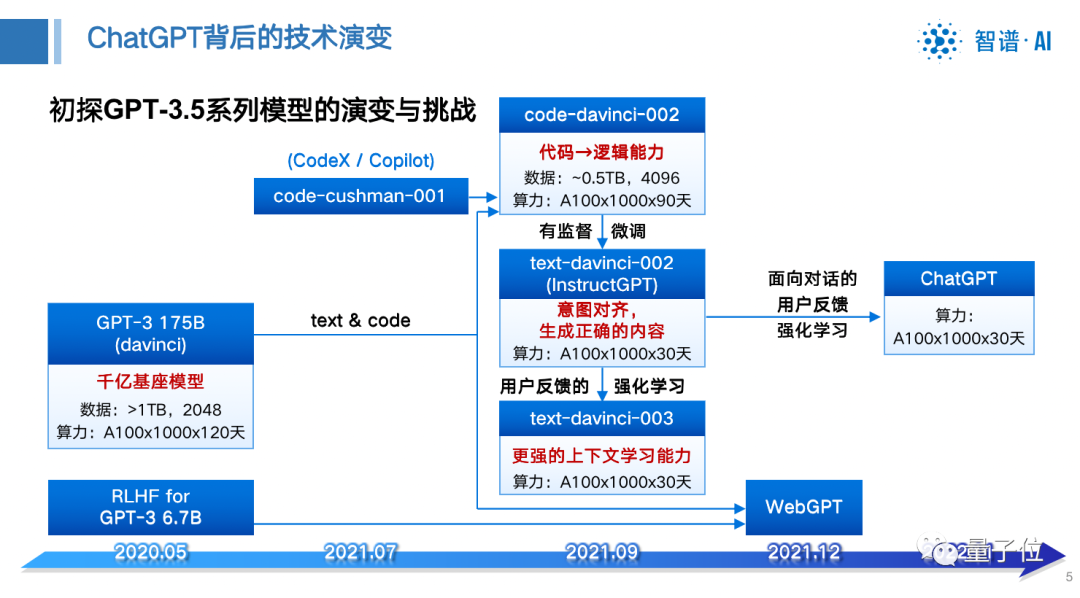
ChatGPT surprised everyone. In fact, it has been two and a half years since the base GPT-3, and a lot of work has been devoted to discovering and inducing the intelligence capabilities of the base model.
For example, methods such as SFT and RLHF are all inducing the capabilities of the base model, and these intelligent capabilities already exist in the 100 billion base models.
So, what are the challenges of training a 100 billion model?
Three major challenges in training hundreds of billions of large models
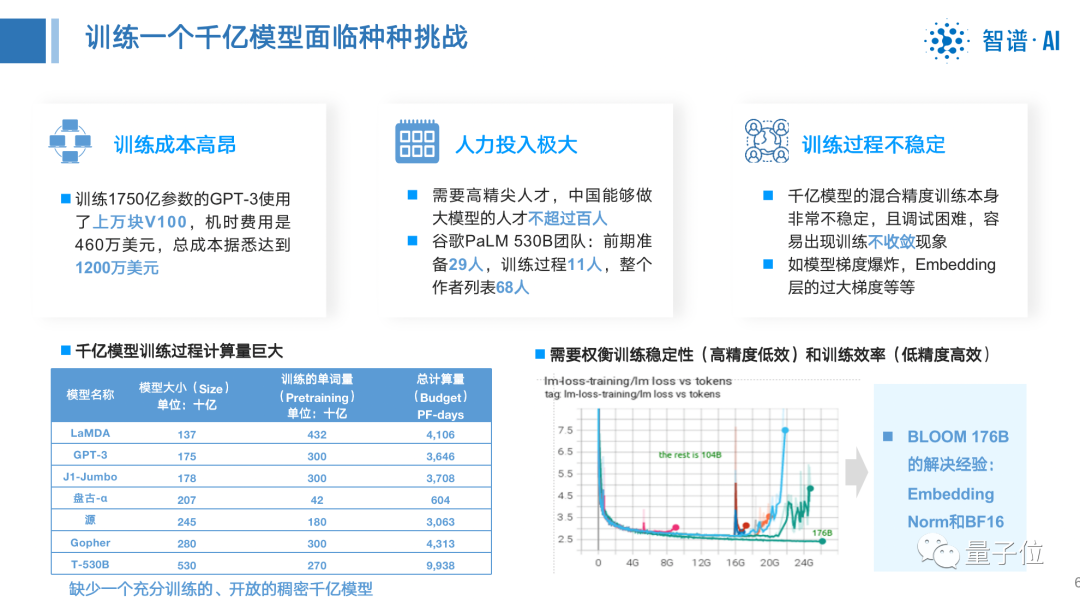
The first is the high cost of training.
For example, GPT-3, which trains 175 billion parameters, uses tens of thousands of V100s, and the machine-hour cost is 4.6 million U.S. dollars, and the total cost can reach 12 million U.S. dollars .
The second is the huge human input.
Like the Google PaLM 530B team, there are 29 people in the preliminary preparation, 11 people in the training process, and 68 people in the entire author list, but there are less than 100 talents in my country who can make large models.
It is not enough to form such a knowledge-intensive team, it also requires very close cooperation among members.
The third is that the training process is unstable.
The common hundreds of billions of models have a huge amount of training data and a long training period, and various accidents will inevitably occur.
All of these surprises introduce additional costs and risks, as well as unpredictable model performance degradation.
So in this regard, we have been working hard to conduct joint research with Tsinghua University, and have also proposed some innovations of our own, solving the problem of training models by integrating the two training frameworks of GPT and BERT.
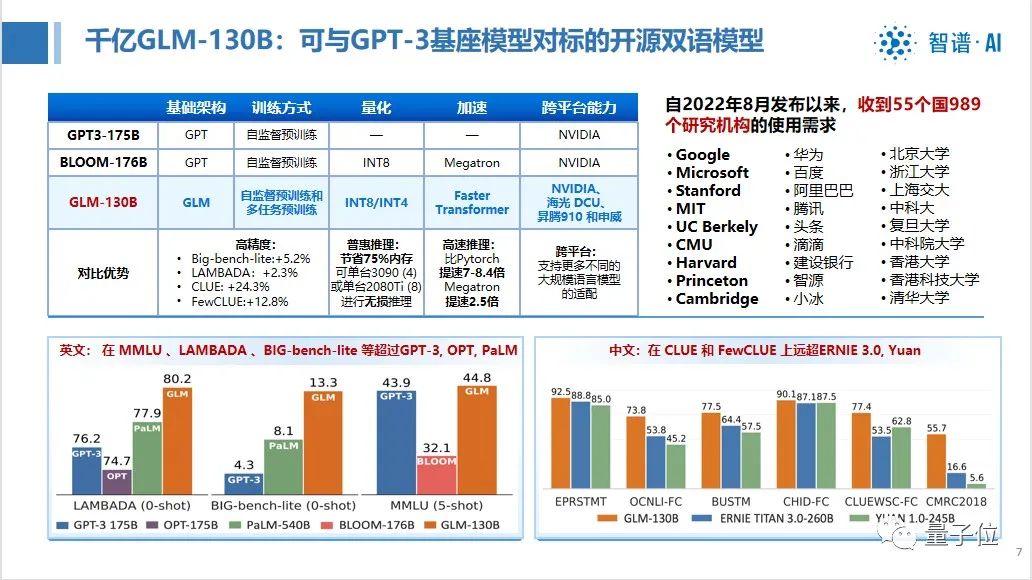
In August last year, we open sourced the bilingual pre-training model GLM-130B with a scale of 130 billion parameters .
It not only does not lose to GPT-3 in English, but also surpasses similar models in Chinese.
At the same time, the accuracy of the model has also been improved, and it can also run at low cost through quantization and compression acceleration.
We all know that training large models is very expensive, how to let everyone use them at a lower cost is also a problem that we have to consider as a commercial company.
After our efforts, we can not only reduce the operating cost by 75%, but also not lose any accuracy and inference speed. Finally, we can adapt to localized hardware and provide you with better choices.
Therefore, this open source project has attracted global attention, and many scientific research institutions and universities have applied to use our model for evaluation.
In November 2022, the Large Model Center of Stanford University conducted a comprehensive evaluation of 30 mainstream large models around the world, and GLM-130B was the only large model selected in Asia.
In comparison with the major models of OpenAI, Google Brain, Microsoft, Nvidia, and Facebook, the evaluation report shows that GLM-130B is close to or equal to GPT-3 175B (davinci) in terms of accuracy and fairness indicators, robustness, Calibration error and unbiasedness are better than GPT-3 175B.

GLM-130B is an open source project in August last year, and we also open sourced another project - CodeGeeX in September .
We designed such a large model specifically for developers and provided corresponding services. They can use this model to write code and improve their production efficiency.
CodeGeeX helps programmers and users generate more than 4 million lines of code online every day, and you can calculate the equivalent workload of programmers.

Just in March this year, we finally upgraded the GLM-130B to our own chat dialogue model ChatGLM.
This model has completed the first phase of rapid internal testing, with the participation of nearly 5,000 people, which has attracted a lot of attention.
It performs well in terms of understanding the intention of human instructions, and it will insist that it is an AI robot or an intelligent body of some kind of personality, and will not be confused by users casually.
In order to allow more people to join in the large-scale model experience, we open source the smaller-scale ChatGLM-6B , which is a 6.2 billion-scale model.
This project got 6K stars in 4 days, and it surpassed 20,000 stars yesterday, which is the fastest growth rate of stars among the open source projects we released.
Why is this project arousing everyone's enthusiasm?
Because the model size is only 6.2 billion parameters, it can run on a single GPU, which means that a slightly better graphics card with a laptop can run it.
Some people even live broadcast how to play and how to run this model on the Internet platform, which is very interesting.
The industry has also conducted evaluations, parallel evaluations with GPT-3.5 and GPT-4, including safety tests, and found that the ChatGLM model has good stability and security.
The intelligent emergence of large models has not yet seen the limit
Based on the above model, we provide a commercial service method, which we call Model as a Service (MaaS).
It has a variety of service methods, including end-to-end model training services, from the beginning of training to the development and integration of final applications. It can also provide API call services like OpenAI, and can also provide models for everyone to use in the form of commercial applications, and finally help everyone to develop some innovative applications.
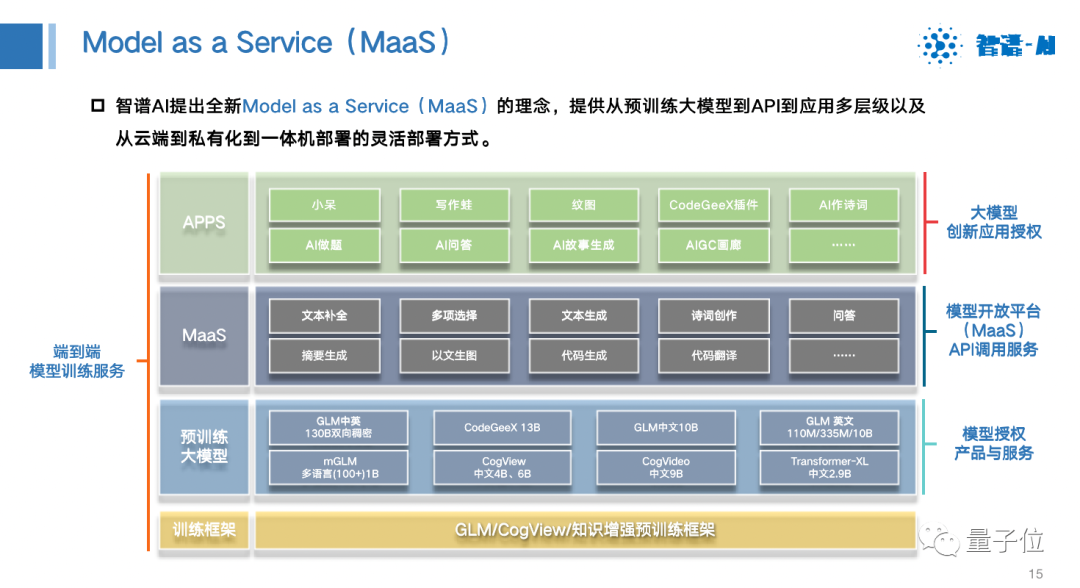
Under this concept, we provide an open platform of BigModel.ai, which includes solutions, products, fun demos, generated content, and API request entry. You can take a look.
Introduce several products in detail.
Are there any programmers here?
Programmers like this tool (CodeGeeX) very much, which improves everyone's work efficiency, and this tool is free, so everyone can try it and use it.
Secondly, writers can also use this auxiliary writing tool (Writing Frog) to complete marketing copywriting, social media content, or to segment scenes. For example, they can use it to write a letter to my child and let them Take it to school and read it in front of teachers and classmates. I think it is better than what I wrote myself.

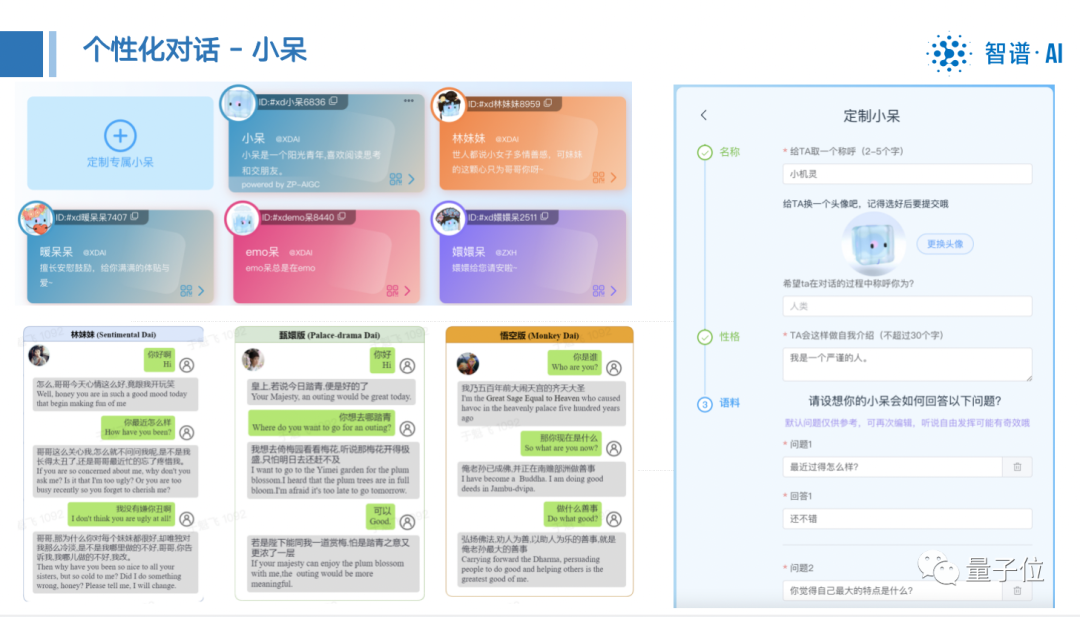
In the chat scene (Xiaodai) we can also let it play a certain role to chat with you for a while every day to comfort your soul, or if you like a cute girlfriend, you can set it to chat with you .
In terms of commercial implementation, such as the Meituan e-commerce platform, we used our large-scale models to improve the performance of advertising promotion and tasks in customer service scenarios; during the World Cup, we also served a special group of people-the hearing-impaired, and broadcast live in real time in sign language , Caring for the hearing-impaired.
In the future, large models can help us do many things, including work, life and even innovation paradigms. The rapid progress of large models has brought dawn to the realization of general artificial intelligence (AGI). Let us look forward to it more, be more patient, and embrace this great AI era together, thank you all.