Table of contents
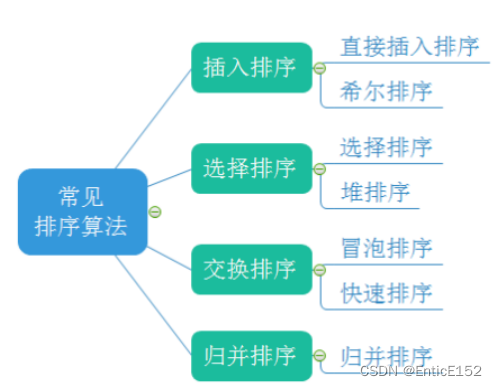
Implementations of common sorting algorithms:
1. The concept of sorting and its application
9. Sorting algorithm complexity and stability analysis
10. Sorting multiple choice practice
Implementations of common sorting algorithms:
1. The concept of sorting and its application
Sorting: The so-called sorting is the operation of arranging a string of records in ascending or descending order according to the size of one or some of the keywords.
Stability: Assume that there are multiple records with the same keyword in the sequence of records to be sorted. If sorted, the relative order of these records remains unchanged, that is, in the original sequence, r[i]=r[j] , and r[i] is before r[j], and in the sorted sequence, r[i] is still before r[j], the sorting algorithm is said to be stable, otherwise it is called unstable.
Internal sorting: A sorting in which all data elements are placed in memory.
External sorting: Too many data elements cannot be placed in memory at the same time, and the sorting of data cannot be moved between internal and external memory according to the requirements of the sorting process.

Performance comparison of test sorting:
//测试排序的性能对比
void TestOP()
{
srand(time(0));
const int N = 100000;
int* a1 = (int*)malloc(sizeof(int) * N);
int* a2 = (int*)malloc(sizeof(int) * N);
int* a3 = (int*)malloc(sizeof(int) * N);
int* a4 = (int*)malloc(sizeof(int) * N);
int* a5 = (int*)malloc(sizeof(int) * N);
int* a6 = (int*)malloc(sizeof(int) * N);
for (int i = 0; i < N; ++i)
{
a1[i] = rand();
a2[i] = a1[i];
a3[i] = a1[i];
a4[i] = a1[i];
a5[i] = a1[i];
a6[i] = a1[i];
}
int begin1 = clock();
InsertSort(a1, N);
int end1 = clock();
int begin2 = clock();
ShellSort(a2, N);
int end2 = clock();
int begin3 = clock();
SelectSort(a3, N);
int end3 = clock();
int begin4 = clock();
HeapSort(a4, N);
int end4 = clock();
int begin5 = clock();
QuickSort(a5, 0, N - 1);
int end5 = clock();
int begin6 = clock();
MergeSort(a6, N);
int end6 = clock();
printf("InsertSort:%d\n", end1 - begin1);
printf("ShellSort:%d\n", end2 - begin2);
printf("SelectSort:%d\n", end3 - begin3);
printf("HeapSort:%d\n", end4 - begin4);
printf("QuickSort:%d\n", end5 - begin5);
printf("MergeSort:%d\n", end6 - begin6);
free(a1);
free(a2);
free(a3);
free(a4);
free(a5);
free(a6);
}2. Insertion sort
The basic idea of insertion sort:
Insertion sorting is a simple insertion sorting algorithm. Its basic idea is: insert the records to be sorted into a sorted sequence one by one according to the size of their key values until all records are inserted. Get a new sorted sequence.
In practice, when we play poker, we use the idea of insertion sort:

void InsertSort(int* a, int n)
{
for (int i = 0; i < n - 1; i++)
{
int end = i;
int tmp = a[end] + 1;
while (end >= 0)
{
if (a[end] > tmp)
{
a[end + 1] = a[end];
--end;
}
else
{
break;
}
}
a[end + 1] = tmp;
}
}3. Hill sorting (reducing incremental sorting)
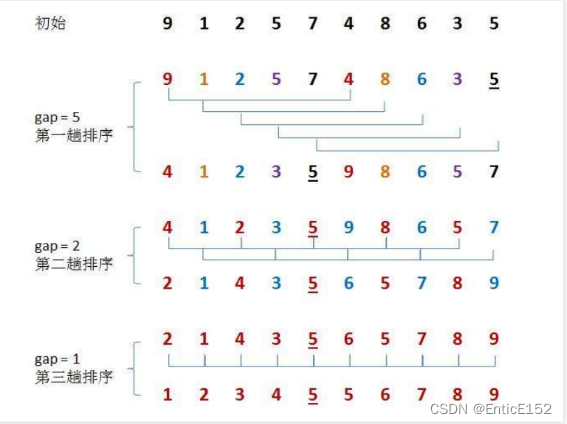
The basic idea of Hill sorting:
Hill sorting is also known as shrinking incremental method. The basic idea of Hill sorting is: first select an integer, divide all records in the file to be sorted into groups, and divide all records with a distance of gap into the same group, and sort each The records within a group are sorted, and then the above grouping and sorting work is repeated. When gap=1 is reached, all records are sorted in the same group.
Summary of the characteristics of Hill sorting:
1. Hill sort is an optimization of insertion sort.
2. When gap>1 is pre-sorted, the purpose is to make the array closer to order. When gap==1, the array is already close to order, so it will be very fast, and overall, the optimization effect can be achieved.
3. The time complexity of Hill sorting is not easy to calculate, because there are many ways to value the gap, which makes it difficult to calculate. Therefore, the time complexity of Hill sorting given in many books is not fixed.


"Data Structure - Using Object-Oriented Method and C++ Description" --- Yin Renkun

Note: Our gap is valued according to the method proposed by Knuth, and Knuth has conducted a large number of experimental statistics. For the time being, we will calculate according to: O(n^1.25) to O(1.6*n^1.25).
4. Stability: Unstable
Code:
//希尔排序(缩小增量排序)
//希尔排序又称缩小增量法 希尔排序的基本思想是:先选定一个整数,把待排序文件中所有
//记录分成n个组 所有距离为的记录分在同一个组 并对每一组内的记录进行排序,然后取重复上述分组
//和排序的工作,当达到1时,所有记录在统一组内排好序
//希尔排序的时间复杂度为O(N^1.3) 数据量特别大时略逊于N*logN
void ShellSort(int* a, int n)
{
//gap > 1预排序 gap == 1直接插入排序
int gap = n;
while (gap > 1)
{
//gap = gap / 2;
gap = gap / 3 + 1;
for (int j = 0; j < gap; ++j)
{
for (int i = j; i < n - gap; i += gap)
{
//[0,end] 插入 end+gap [0,end+gap]有序——间隔为gap的数据
int end = i;
int tmp = a[end + gap];
while (end >= 0)
{
if (a[end] > tmp)
{
a[end + gap] = a[end];
end -= gap;
}
else
{
break;
}
}
a[end + gap] = tmp;
}
}
}
}4. Selection sort
The basic idea of selection sort:
Each time the smallest (or largest) element is selected from the data elements to be sorted and stored at the beginning of the sequence until all the data elements to be sorted are exhausted.
Select the data element with the largest (smallest) key code in the element set array[i]—array[n-1], if it is not the last (first) element in this group of elements, then combine it with this group of elements The last (first) element in is exchanged, and in the remaining array[i]—array[n-2] (array[i+1]—array[n-1]) collection, repeat the above steps until The set has one element remaining.

A summary of the properties of selection sort:
1. The code for selection sorting is very easy to understand, but the efficiency is not very good, and it is rarely used in practice
2. Time complexity: O(N^2)
3. Space complexity: O(1)
4. Stability: Unstable
Code:
//选择排序
//最坏时间复杂度:O(N^2)
//最好时间复杂度:O(N^2)
void Swap(int* p1, int* p2)
{
int tmp = *p1;
*p1 = *p2;
*p2 = tmp;
}
void SelectSort(int* a, int n)
{
int begin - 0.end = n - 1;
while (begin < end)
{
//选出最小的放begin位置
//选出最大的放end位置
int mini = begin, maxi = begin;
for (int i = begin + 1; i <= end; ++i)
{
if (a[i] > a[maxi])
{
maxi = i;
}
if (a[i] < a[mini])
{
mini = i;
}
}
Swap(&a[begin], &a[mini]);
//最大数据在第一个位置时需要修正一下maxi
if (maxi == begin)
maxi = mini;
Swap(&a[end], &a[maxi]);
++begin;
--end;
}
}5. Bubble sort
Basic idea:
The so-called exchange is to swap the positions of the two records in the sequence according to the comparison result of the key values of the two records in the sequence. Smaller data is moved toward the front of the sequence.
Summary of the characteristics of bubble sort:
1. Time complexity: O(N^2)
2. Space complexity: O(1)
3. Stability: stable
Code:
//冒泡排序
//最坏时间复杂度——O(N^2)
//最好时间复杂度——O(N)
void BubbleSort(int* a, int n)
{
for (int j = 0; j < n; ++j)
{
int exchange = 0;
for (int i = 1; i < n - j; ++i)
{
if (a[i - 1] > a[i])
{
Swap(&a[i - 1], &a[i]);
exchange = 1;
}
}
if (exchange == 0)
{
break;
}
}
}6. Heap sort
Heap sorting (HeapSort) refers to a sorting algorithm designed using the data structure of the heap. It is a kind of selection sorting. It selects data through the heap. It should be noted that a large heap should be built for ascending order, and a small heap should be built for descending order. heap.
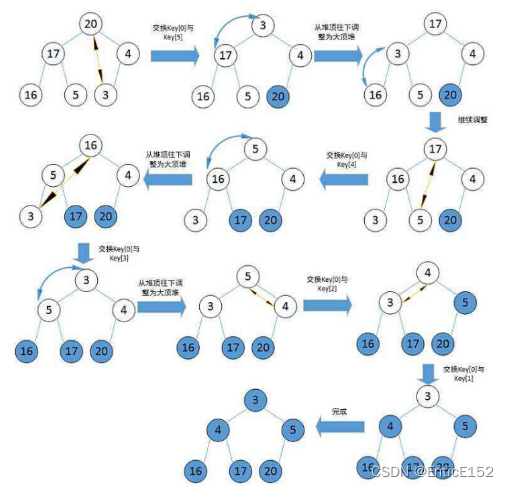
Summary of the characteristics of heap sorting:
1. Heap sorting uses the heap to select numbers, which is much more efficient
2. Time complexity: O(N*logN)
3. Space complexity: O(1)
4. Stability: Unstable
Code:
void Swap(int* p1, int* p2)
{
int tmp = *p1;
*p1 = *p2;
*p2 = tmp;
}
void AdjustDown(int* a, int n, int parent)
{
int minChild = parent * 2 + 1;
while (minChild < n)
{
if (minChild + 1 < n && a[minChild + 1] > a[minChild]);
{
minChild++;
}
if (a[minChild] > a[parent])
{
Swap(&a[minChild], &a[parent]);
parent = minChild;
minChild = parent * 2 + 1;
}
else
{
break;
}
}
}
void HeapSort(int* a, int n)
{
for (int i = (n - 1 - 1) / 2; i >= 0; --i)
{
AdjustDown(a, n, i);
}
int i = 1;
while (i < n)
{
Swap(&a[0], &a[n - i]);
AdjustDown(a, n - i, 0);
++i;
}
}7. Quick Sort
//假设按照升序对array数组中[left, right)区间中的元素进行排序
void QuickSort(int array[], int left, int right)
{
if(right - left <= 1)
return;
// 按照基准值对array数组的 [left, right)区间中的元素进行划分
int div = partion(array, left, right);
// 划分成功后以div为边界形成了左右两部分 [left, div) 和 [div+1, right)
// 递归排[left, div)
QuickSort(array, left, div);
// 递归排[div+1, right)
QuickSort(array, div+1, right);
}//快速排序
//单趟排序:
//1.选1个key(一般是第一个或者是最后一个)
//2.单趟排序要求小的在key的左边,大的在key的右边
//相遇位置如何保证比key要小——左边第一个做key R先走
//1.R停下来 L遇到R 二者相遇 相遇位置比key小
//2.L停下来 R遇到L 二者相遇 相遇位置比key小
//发生第二种情况一定是R没有找到小的和L相遇,但此时L的位置已经被换成比key小的数据
//同样的道理:如果右边第一个做key——L先走
//单趟排序的价值
//1.key已经找到了它的最终位置,这个数已经排好了
//2.分割出去了两个子区间,如果子区间有序。整体就有序了
//子区间如何有序呢?——子区间递归
//最好时间复杂度:O(N*logN)
//最坏时间复杂度:O(N^2)
int PartSort(int* a, int left, int right)
{
//数组之间的交换 不能和值换 要和对应的位置换
int keyi = left;
while (left < right)
{
//R找小
while (left < right && a[right] >= a[keyi])
{
--right;
}
//L找大
while (left < right && a[left] <= a[keyi])
{
++left;
}
if(left < right)
Swap(&a[left], &a[right]);
}
int meeti = left;
Swap(&a[meeti], &a[keyi]);
return meeti;
}Hoare version
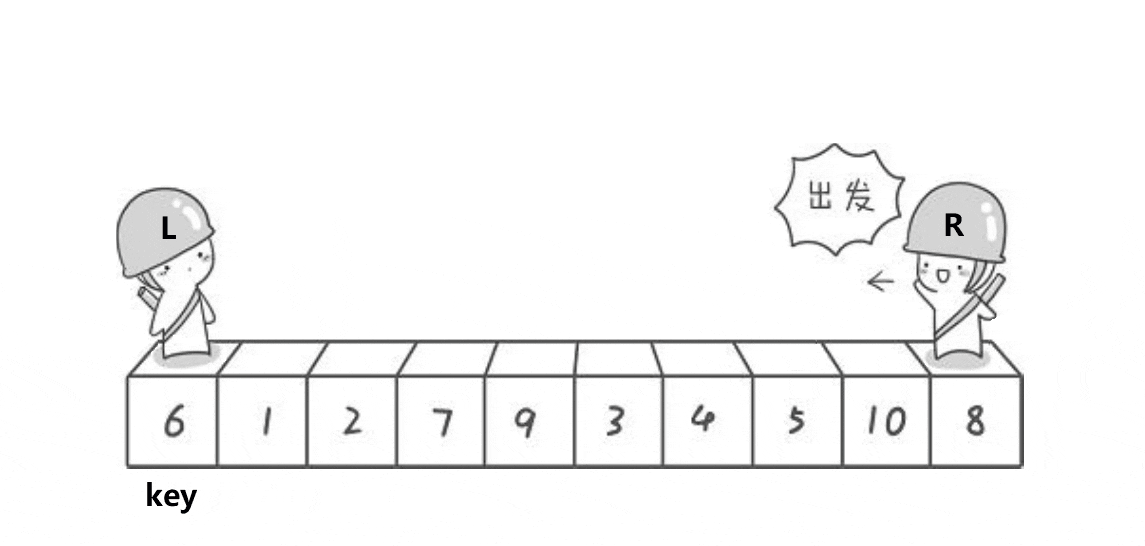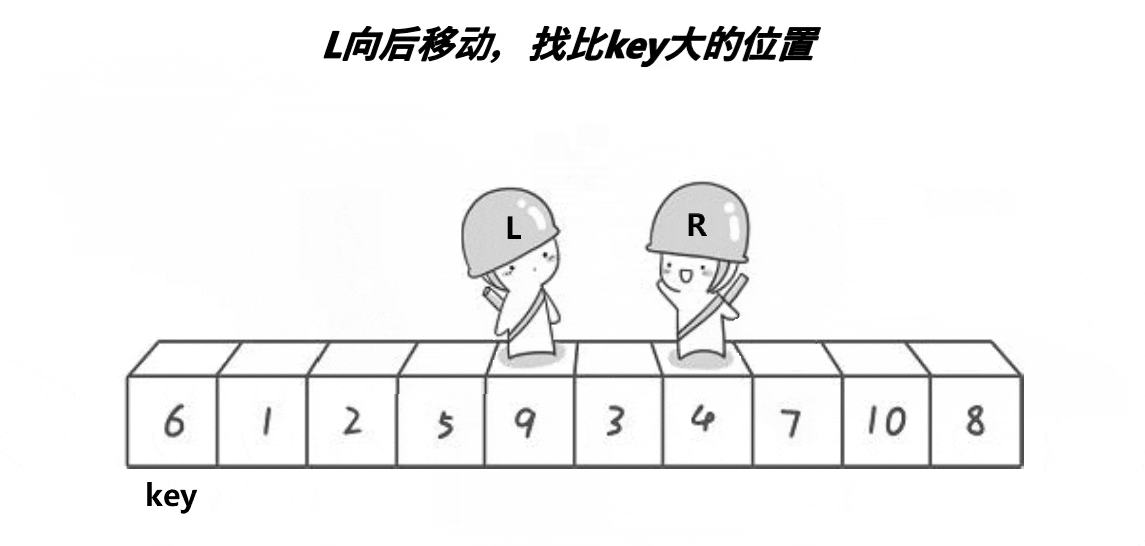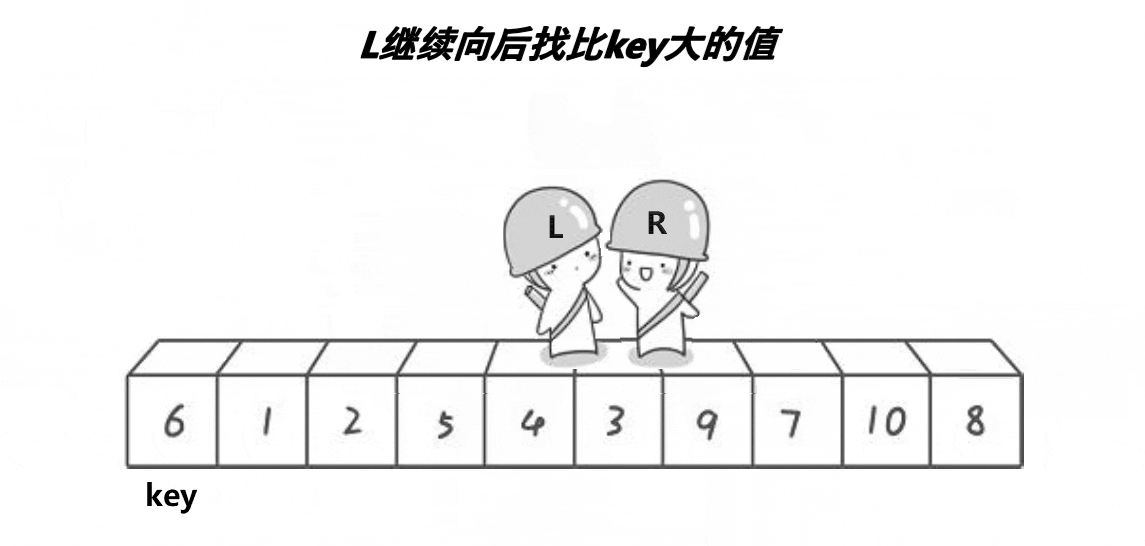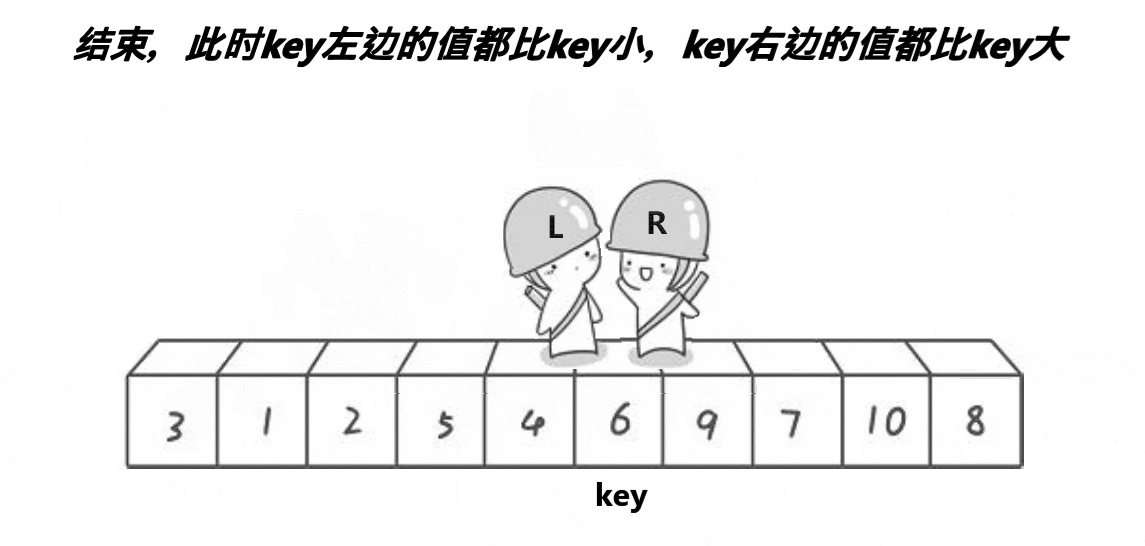
//优化快速排序:1.三数取中 2.小区间优化减少递归次数
//三数取中
int GetMidIndex(int* a, int left, int right)
{
int mid = (right + left) / 2;
if (a[left] < a[mid])
{
if (a[mid] < a[right])
{
return mid;
}
else if (a[left] > a[right])
{
return left;
}
else
{
return right;
}
}
else//a[left]>=a[mid]
{
if (a[mid] > a[right])
{
return mid;
}
else if (a[left] > a[right])
{
return left;
}
else
{
return right;
}
}
}
//Hoare
int PartSort1(int* a, int left, int right)
{
//三数取中
int mid = GetMidIndex(a, left, right);
Swap(&a[left], &a[mid]);
int keyi = left;
while (left < right)
{
//R找小
while (left < right && a[right] >= a[keyi])
{
--right;
}
//L找大
while (left < right && a[left] <= a[keyi])
{
++left;
}
if (left < right)
Swap(&a[left], &a[right]);
}
int meeti = left;
Swap(&a[meeti], &a[keyi]);
return meeti;
}
//[begin,end]
void QuickSort(int* a, int begin, int end)
{
if (begin >= end)
{
return;
}
if (end - begin <= 8)
{
InsertSort(a + begin, end - begin + 1);
}
else
{
int keyi = PartSort1(a, begin, end);
//[begin,keyi-1] keyi [keyi+1,end]
QuickSort(a, begin, keyi - 1);
QuickSort(a, keyi + 1, end);
}
}pit digging

//挖坑法
//理解:1.左边是坑必然右边先走找数填坑 2.相遇位置必然是坑
int PartSort2(int* a, int left, int right)
{
//三数取中
int mid = GetMidIndex(a, left, right);
Swap(&a[left], &a[mid]);
int keyi = left;
int key = a[left];
int hole = left;
while (left < right)
{
//右边找小 填到左边的坑
while (left < right && a[right] >= key)
{
--right;
}
a[hole] = a[right];
hole = right;
//左边找大填到右边的坑
while (left < right && a[left] <= key)
{
++left;
}
a[hole] = a[left];
hole = left;
}
a[hole] = key;
return hole;
}
//[begin,end]
void QuickSort(int* a, int begin, int end)
{
if (begin >= end)
{
return;
}
if (end - begin <= 8)
{
InsertSort(a + begin, end - begin + 1);
}
else
{
int keyi = PartSort2(a, begin, end);
//[begin,keyi-1] keyi [keyi+1,end]
QuickSort(a, begin, keyi - 1);
QuickSort(a, keyi + 1, end);
}
}Back and forth pointer method:
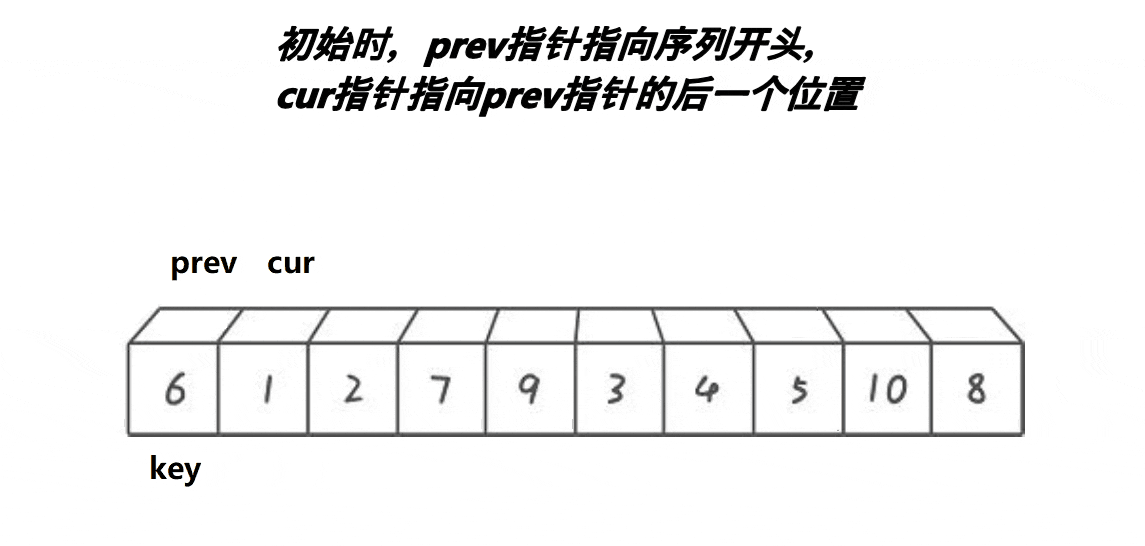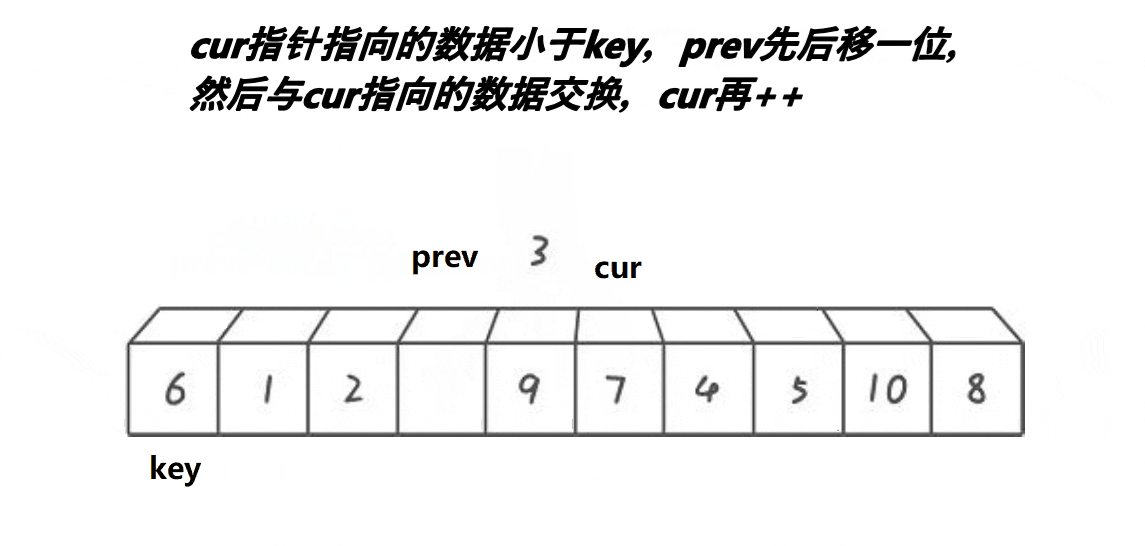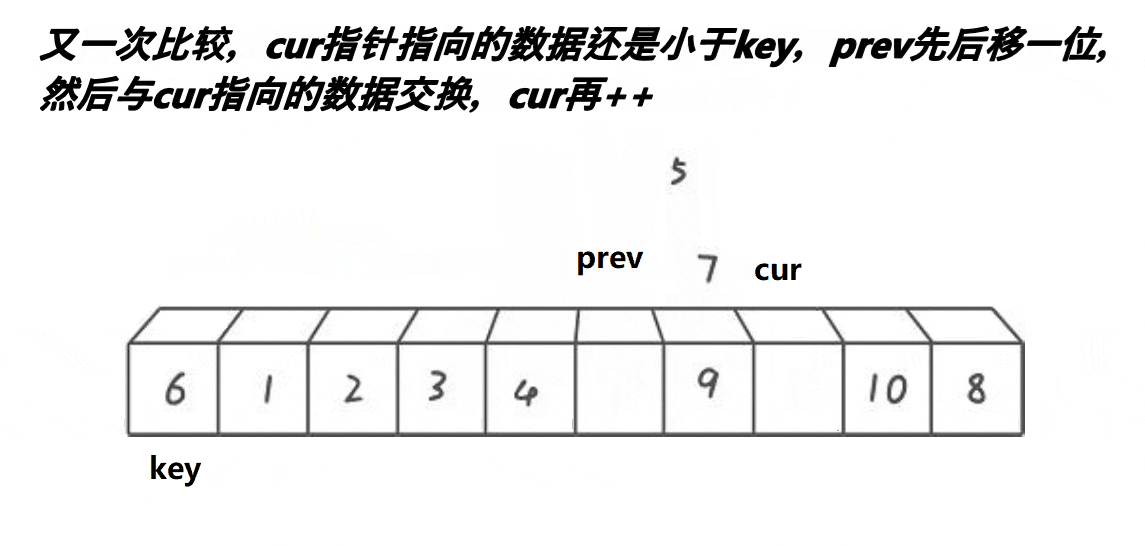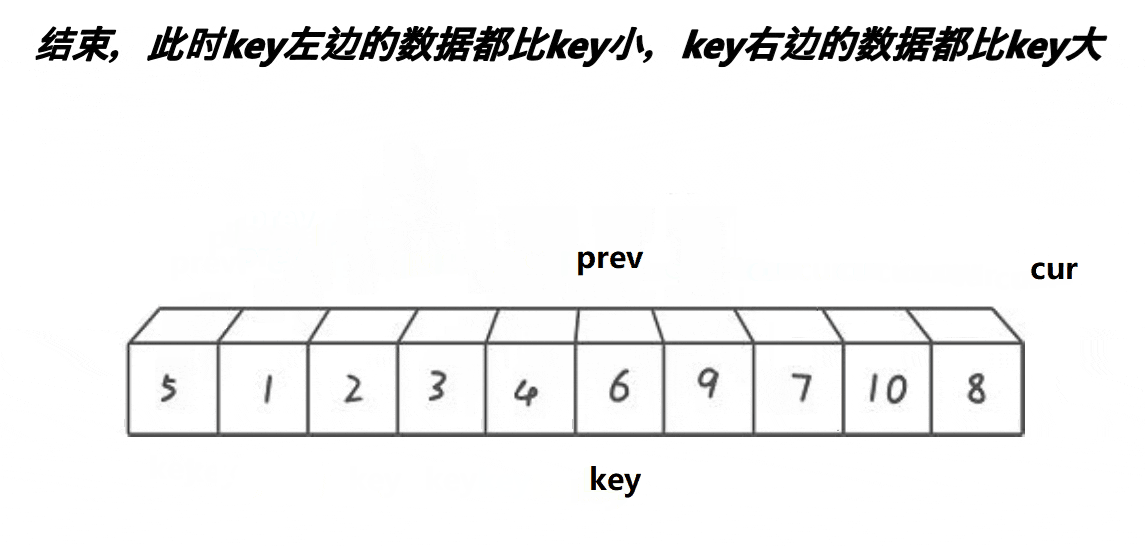
//前后指针法
//cur找小 prev紧跟着cur prev和cue之间间隔的是比key大的值
//cur遇到比key小的值时 就停下来 ++prev
//交换prev和cur位置的值
int PartSort3(int* a, int left, int right)
{
//三数取中
int mid = GetMidIndex(a, left, right);
Swap(&a[left], &a[mid]);
int keyi = left;
int prev = left;
int cur = left + 1;
while (cur <= right)
{
if (a[cur] < a[keyi] && ++prev != cur)
Swap(&a[cur], &a[prev]);
++cur;
}
//如果交换的是数组中的值 int key = a[left] Swap(&left,&a[prev])只是和局部变量key进行交换 并没有改变数组中的值
Swap(&a[keyi], &a[prev]);
return prev;
}
void QuickSort(int* a, int begin, int end)
{
if (begin >= end)
{
return;
}
if (end - begin <= 8)
{
InsertSort(a + begin, end - begin + 1);
}
else
{
int keyi = PartSort3(a, begin, end);
//[begin,keyi-1] keyi [keyi+1,end]
QuickSort(a, begin, keyi - 1);
QuickSort(a, keyi + 1, end);
}
}Quick sort non-recursive:
#pragma once
#include<stdio.h>
#include<stdlib.h>
#include<stdbool.h>
#include<assert.h>
//静态栈
/*#define N 100
typedef int STDataType;
struct Stack
{
STDataType a[N];
int top;
};*/
//动态栈
typedef char STDataType;
typedef struct Stack
{
STDataType * a;
int top;
int capacity;
}ST;
void StackInit(ST* ps);
void StackDestory(ST* ps);
void StackPush(ST* ps, STDataType x);
void StackPop(ST* ps);
bool StackEmpty(ST* ps);
int StackSize(ST* ps);
//访问栈顶数据
STDataType StackTop(ST* ps);
#include"Stack.h"
void StackInit(ST* ps)
{
assert(ps);
ps->a = NULL;
ps->top = ps->capacity = 0;
}
void Destory(ST* ps)
{
assert(ps);
free(ps->a);
ps->a = NULL;
ps->capacity = ps->top = 0;
}
//数据结构建议不要直接访问结构体数据,一定要通过函数接口访问
//解耦:高内聚,低耦合
void StackPush(ST* ps, STDataType x)
{
assert(ps);
if (ps->top == ps->capacity)
{
int newCapacity = ps->capacity == 0 ? 4 : ps->capacity * 2;
STDataType* tmp = (STDataType*)realloc(ps->a, newCapacity * sizeof(STDataType));
if (tmp == NULL)
{
perror("realloc fail");
exit(-1);
}
ps->a = tmp;
ps->capacity = newCapacity;
ps->a[ps->top] = x;
ps->top++;
}
}
void StackPop(ST* ps)
{
assert(ps);
assert(!StackEmpty(ps));
--ps->top;
}
STDataType StackTop(ST* ps)
{
assert(ps);
//为空不能访问栈顶元素
assert(!StackEmpty(ps));
return ps->a[ps->top - 1];
}
bool StackEmpty(ST* ps)
{
assert(ps);
return ps->top == 0;
}
int StackSize(ST* ps)
{
assert(ps);
return ps->top;
}
#include"Stack.h"
//快速排序的非递归
//改非递归:递归函数中的栈帧保存什么 数据结构中的栈就保存什么
void QuickSortNonR(int* a, int begin, int end)
{
ST st;
StackInit(&st);
StackPush(&st, begin);
StackPush(&st, end);
while (!StackEmpty(&st)
{
int right = StackTop(&st);
StackPop(&st);
int left = StackTop(&st);
StackPop(&st);
if (left >= right)
{
continue;
}
int keyi = PartSort3(a, left, right);
//[left,keyi-1] l=keyi [keyi+1,right]
StackPush(&st, keyi+1);
StackPush(&st, right);
StackPush(&st, left);
StackPush(&st, keyi-1);
}
StackDestory(&st);
}
//优化:在区间为1或者区间不存在的时候 区间值不压入栈中
void QuickSortNonR(int* a, int begin, int end)
{
ST st;
StackInit(&st);
StackPush(&st, begin);
StackPush(&st, end);
while (!StackEmpty(&st)
{
int right = StackTop(&st);
StackPop(&st);
int left = StackTop(&st);
StackPop(&st);
int keyi = PartSort3(a, left, right);
//[left,keyi-1] l=keyi [keyi+1,right]
if (keyi + 1 < right)
{
StackPush(&st, keyi + 1);
StackPush(&st, right);
}
if (left < right - 1)
{
StackPush(&st, left);
StackPush(&st, keyi - 1);
}
}
StackDestory(&st);
}Summary of quick sort features:
1. The overall comprehensive performance and usage scenarios of quick sort are relatively good, so it dares to be called quick sort
2. Time complexity: O(N*logN)
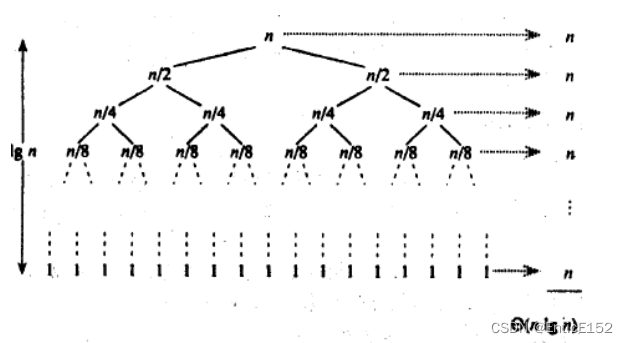
3. Space complexity: O(logN)
4. Stability: Unstable
8. Merge sort
Basic idea:

Summary of the characteristics of merge sort:
//归并排序
//归并思想:左右区间均有序 取小的尾插到新数组
//归并排序的时间复杂度:O(N*logN) 空间复杂度为O(N)
//归并排序写子函数的原因:避免频繁malloc
void _MergeSort(int* a, int begin, int end, int* tmp)
{
if (begin == end)
{
return;
}
int mid = (end + begin) / 2;
//[begin,mid] [mid+1,end]
_MergeSort(a, begin, mid, tmp);
_MergeSort(a, mid + 1, end, tmp);
//归并 取小的尾插
//[begin,mid] [mid+1,end]
int begin1 = begin, end1 = mid;
int begin2 = mid + 1, end2 = end;
int i = begin;
while (begin1 <= end1 && begin2 <= end2)
{
if (a[begin1] <= a[begin2])
{
tmp[i++] = a[begin1++];
}
else
{
tmp[i++] = a[begin2++];
}
}
while (begin1 <= end1)
{
tmp[i++] = a[begin1++];
}
while (begin2 <= end2)
{
tmp[i++] = a[begin2++];
}
//拷贝回原数组——归并哪部分就拷贝哪部分回去
memcpy(a + begin, tmp + begin, (end - begin + 1) * sizeof(int));
}
void MergeSort(int* a, int n)
{
int* tmp = (int*)malloc(sizeof(int) * n);
if (tmp == NULL)
{
perror("malloc fail");
return;
}
_MergeSort(a, 0, n - 1, tmp);
free(tmp);
tmp = NULL;
}Merge sort non-recursive
//归并排序的非递归
//问题:控制边界 该代码只能处理2的次方次个数据
void MergeSortNonR(int* a, int n)
{
int* tmp = (int*)malloc(sizeof(int) * n);
if (tmp == NULL)
{
perror("malloc fail");
return;
}
int gap = 1;
while (gap < n)
{
//gap个数据 gap个数据进行归并
for (int j = 0; j < n; j += 2 * gap)
{
//归并 取小的尾插
int begin1 = j, end1 = j + gap - 1;
int begin2 = j + gap, end2 = j + 2 * gap - 1;
int i = j;
while (begin1 <= end1 && begin2 <= end2)
{
if (a[begin1] <= a[begin2])
{
tmp[i++] = a[begin1++];
}
else
{
tmp[i++] = a[begin2++];
}
}
while (begin1 <= end1)
{
tmp[i++] = a[begin1++];
}
while (begin2 <= end2)
{
tmp[i++] = a[begin2++];
}
}
//拷贝回原数组
memcpy(a, tmp, n * sizeof(int));
gap *= 2;
}
free(tmp);
tmp = NULL;
}
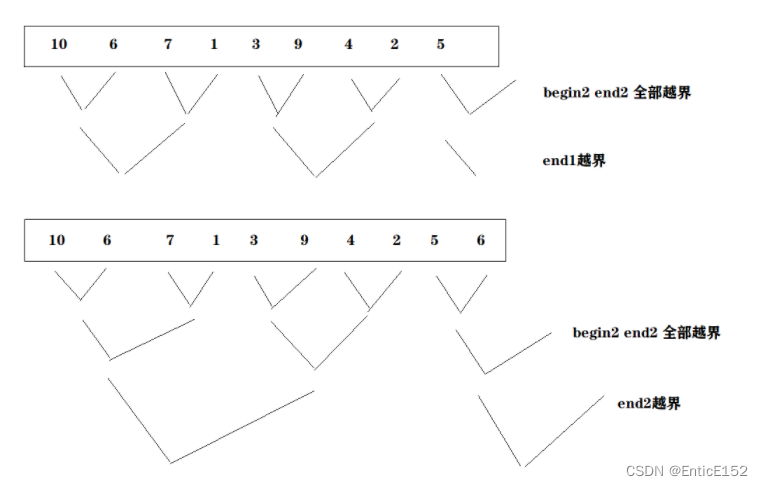
//数据个数不一定是2的整数倍 计算直接按整数倍算的 存在越界 需要修正
//代码优化:控制边界
//三种越界情况:1.第一组end1越界 2.第二组全部越界 3.第三组部分越界
void MergeSortNonR(int* a, int n)
{
int* tmp = (int*)malloc(sizeof(int) * n);
if (tmp == NULL)
{
perror("malloc fail");
return;
}
int gap = 1;
while (gap < n)
{
//gap个数据 gap个数据进行归并
for (int j = 0; j < n; j += 2 * gap)
{
//归并 取小的尾插
int begin1 = j, end1 = j + gap - 1;
int begin2 = j + gap, end2 = j + 2 * gap - 1;
//第一组越界 第二组必然越界 只有一组不需要归并 直接跳出循环
if (end1 >= n)
{
break;
}
//第二组全部越界
if (begin2 >= n)f
{
break;
}
//第二组部分越界
if (end2 >= n)
{
//修正一下end2 继续归并
end2 = n - 1;
}
int i = j;
while (begin1 <= end1 && begin2 <= end2)
{
if (a[begin1] <= a[begin2])
{
tmp[i++] = a[begin1++];
}
else
{
tmp[i++] = a[begin2++];
}
}
while (begin1 <= end1)
{
tmp[i++] = a[begin1++];
}
while (begin2 <= end2)
{
tmp[i++] = a[begin2++];
}
//拷贝回原数组
memcpy(a + j, tmp + j, (end2 - j + 1) * sizeof(int));
}
gap *= 2;
printf("\n");
}
free(tmp);
tmp = NULL;
}9. Sorting algorithm complexity and stability analysis
排序总结
直接插入排序最好的时间复杂度是O(N)最坏的时间复杂度是O(N^2)
希尔排序时间复杂度是O(N^1.3)
选择排序最好的时间复杂度是O(N^2)最坏的时间复杂度是O(N^2)
堆排序最好的时间复杂度是O(N*logN)最坏的时间复杂度是O(N*logN)
冒泡排序最好的时间复杂度是O(N)最坏的时间复杂度是O(N^2)
快速排序最好的时间复杂度是O(N*logN)最坏的时间复杂度是O(N^2)
归并排序最好的时间复杂度是O(N*logN)最坏的时间复杂度是O(N)
快速排序的空间复杂度是O(logN)归并排序的空间复杂度是O(N)
稳定性:数组中相同的值 排完序相对顺序可以做到不变就是稳定的 否则就不稳定
冒泡排序的稳定性好
选择排序的稳定性差
插入排序的稳定性好
希尔排序的稳定性差
堆排序的稳定性差
归并排序的稳定性好
快速排序的稳定性差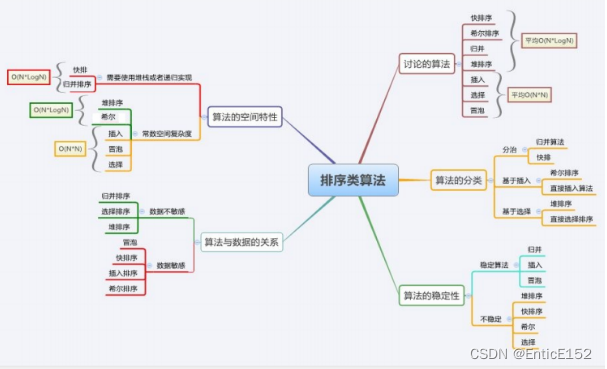
10. Sorting multiple choice practice
1. 快速排序算法是基于( )的一个排序算法。
A分治法
B贪心法
C递归法
D动态规划法
2.对记录(54,38,96,23,15,72,60,45,83)进行从小到大的直接插入排序时,当把第8个记录45插入到有序表时,为找到插入位置需比较( )次?(采用从后往前比较)
A 3
B 4
C 5
D 6
3.以下排序方式中占用O(n)辅助存储空间的是
A 简单排序
B 快速排序
C 堆排序
D 归并排序
4.下列排序算法中稳定且时间复杂度为O(n2)的是( )
A 快速排序
B 冒泡排序
C 直接选择排序
D 归并排序
5.关于排序,下面说法不正确的是
A 快排时间复杂度为O(N*logN),空间复杂度为O(logN)
B 归并排序是一种稳定的排序,堆排序和快排均不稳定
C 序列基本有序时,快排退化成冒泡排序,直接插入排序最快
D 归并排序空间复杂度为O(N), 堆排序空间复杂度的为O(logN)
6.下列排序法中,最坏情况下时间复杂度最小的是( )
A 堆排序
B 快速排序
C 希尔排序
D 冒泡排序
7.设一组初始记录关键字序列为(65,56,72,99,86,25,34,66),则以第一个关键字65为基准而得到的一趟快
速排序结果是()
A 34,56,25,65,86,99,72,66
B 25,34,56,65,99,86,72,66
C 34,56,25,65,66,99,86,72
D 34,56,25,65,99,86,72,66
答案:
1.A
2.C
3.D
4.B
5.D
6.A
7.A