Regular expressions are a string matching tool that can help us search, obtain, and replace strings. It is a concept of computer science, not only belongs to a certain language, regular expressions can be widely used in Python, JavaScript, Java and other languages.
Table of contents
1. What is a regular expression?
2. Regular expressions in JavaScript
3. How to use regular expressions
3.1. Instance methods of regular objects
9.1. As individual items in the resulting array
9.2. Treat parentheses as a whole
9.3. Naming of capturing groups
9.4. Exclusion of capture groups
1. What is a regular expression?
- Regular expression (English: Regular Expression, often abbreviated as RegExp ), also known as regular expression, regular expression, regular expression, regular expression;
- A regular expression is described by a single string, matching a series of strings that match a certain syntax rule;
- Many programming languages support string manipulation using regular expressions.
2. Regular expressions in JavaScript
In JavaScript, regular expressions are created using the RegExp class , but there are also corresponding literal methods: regular expressions are mainly composed of two parts: patterns (patterns) can also be understood as matching rules and modifiers (flags)
const re1 = new RegExp("hello", "i")
//使用RegExp类创建正则表达式 "hello"是模式 "i"是修饰符
const re2 = /hello/i
//使用字面量创建正则表达式 3. How to use regular expressions
There are two ways to use it:
- You can use the instance (exec and test) methods on the regular object (RegExp);
- Use the (match, matchAll, replace, search, split) method of String (String), passing in a regular expression.
3.1. Instance methods of regular objects
A RegExp method that performs a find match in a string, returning an array (or null if no match is found).
let message = "hello ABC, abc ,ASbc, AABC"
const re1 = /abc/ig
console.log(re1.exec(message)) 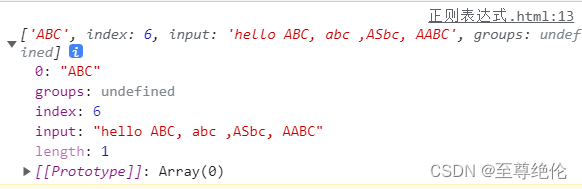
A RegExp method that tests for a match in a string, returning true or false.
let message = "hello ABC, abc ,ASbc, AABC"
const re1 = /abc/ig
console.log(re1.test(message)) //true3.2. String methods
let message = "hello ABC abc ASbc AABC"
const re1 = /abc/ig
const result = message.match(re1)
console.log(result) 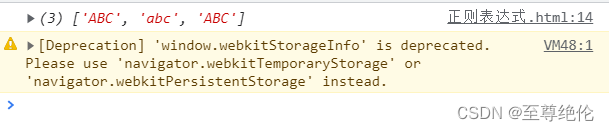
matchAll regular must add g modifier.
let message = "hello ABC abc ASbc AABC"
const re1 = /abc/ig
const result = message.matchAll(re1)
console.log(result)
What is returned is an iterator, which is iterable and can be traversed using the for of loop.
for (const item of result){
console.log(item)
}
4. Use of modifier flag
There are three common modifiers:
const re1 = /abc/ig5. Rules
5.1. Character classes
◼ A character class is a special symbol that matches any symbol in a particular set .
let message = "hello123 ABC545 abc6546 AS56346bc AA6546BC"
const re1 = /\d/ig
const result = message.match(re1)
console.log(result) 
let message = "hello123 A BC545 abc6546 AS56346bc AA6546BC"
const re1 = /\s/ig
const result = message.match(re1)
console.log(result) ![]()
let message = "hello123 A BC545 abc6546 AS56346bc AA6546BC"
const re1 = /\w/ig
const result = message.match(re1)
console.log(result)
let message = "hello123 A BC545 abc6546 AS56346bc AA6546BC"
const re1 = /./ig
const result = message.match(re1)
console.log(result)
5.2. Anchors
The symbol ^ matches the beginning of the text;
let message = "ABcder AbCdess abkkkiruj bAcurj"
const re1 = /^abc/ig
const result = re1.test(message)
console.log(result) //trueThe symbol $ matches the end of the text;
let message = "ABcder AbCdess abkkkiruj bAcurj"
const re1 = /urj$/ig
const result = re1.test(message)
console.log(result) //truelet message = "ABCd ABC ABCDD ABCDF"
const re1 = /\bABC\b/ig
const result = message.match(re1)
console.log(result)![]()
Only single ABC words will be matched, nothing else will be matched.
5.3. Escape characters
6. Sets and Ranges
◼Sometimes we only need to select one of multiple matching characters:
- Several characters or character classes in square brackets […] mean "search for any one of the given characters";
- For example, [eao] means to find any of the 3 characters 'a', 'e' or `'o';
let message = "abc aac aec adc"
const re1 = /a[abed]c/ig
const result = message.match(re1)
console.log(result) ![]()
- Square brackets can also enclose character ranges;
- For example, [az] will match letters in the range from a to z, and [0-5] means numbers from 0 to 5;
- [0-9A-F] means two ranges: it searches for a character that satisfies the digits 0 to 9 or the letters A to F;
- \d - same as [0-9];
- \w - same as [a-zA-Z0-9_];
let message = "5a 4d 7b 1d"
const re1 = /[0-9][a-z]/ig
const result = message.match(re1)
console.log(result)![]()
7. Quantifiers ( Quantifiers )
- Exact number of digits: {5}
let message = "aaaajccccccaaajjcccccaaaaajccaa"
const re1 = /a{3}/ig
const result = message.match(re1)
console.log(result)![]()
- A range of digits: {3,5}
let message = "aaaajccccccaaajjcccccaaaaajccaa"
const re1 = /a{3,5}/ig
const result = message.match(re1)
console.log(result)![]()
◼ Abbreviation:
- +: stands for "one or more", equivalent to {1,}
let message = "aaaajccccccaaajjcccccaaaaajccaa"
const re1 = /a+/ig
const result = message.match(re1)
console.log(result)![]()
- ?: stands for "zero or one", equivalent to {0,1}. In other words, it makes the symbol optional
- *: represents "zero or more", equivalent to {0,}. That is, this character can appear multiple times or not
8. Greedy and lazy modes
There is a requirement. If you want to match two books, first look at the ones that are matched by default.
let message = "两本书《一本书》和《两本书》"
const re1 = /《.+》/ig
const result = message.match(re1)
console.log(result)![]()
It can be seen that taking the "to the second book" of the first book as a whole, what we want is to match the two books.
- As long as the corresponding content is obtained, it will not continue to match backwards;
- We can add a question mark '?' after the quantifier to enable it;
- So the matching pattern becomes *? or +?, or even '?' becomes ??
let message = "两本书《一本书》和《两本书》"
const re1 = /《.+?》/ig
const result = message.match(re1)
console.log(result)![]()
9. Capture groups
Parts of a pattern can be enclosed in parentheses (...), this is called a "capturing group".
- It allows parts of matches as separate items in the resulting array;
- It treats parentheses as a whole;
9.1. As individual items in the resulting array
For example, in the above example of matching books, if we want to use "" to match the book and get the title of the book, we can use the capture group.
let message = "两本书《一本书》和《两本书》"
const re1 = /(《)(.+?)(》)/ig
const result = message.matchAll(re1)
for(const item of result){
console.log(item)
}We split the matches into three groups, use matchAll to return an iterator, and iterate over it.

for(const item of result){
console.log(item[2])
}![]()
9.2. Treat parentheses as a whole
If you want to get more than two abc, it will only match more than two c without parentheses, because {2,} matches the nearest character by default.
let message = "abcdddabcabcccccabcaaaa"
const re1 = /(abc){2,}/ig
const result = message.match(re1)
console.log(result)![]()
After the brackets are added, the content inside the brackets is regarded as a whole. The above example matches two or more abcs.
9.3. Naming of capturing groups
In the case of taking the title of the book above, the group is recorded using numbers.
let message = "两本书《一本书》和《两本书》"
const re1 = /(?<name1>《)(?<name2>.+?)(?<name3>》)/ig
const result = message.matchAll(re1)
for(const item of result){
console.log(item)
}
This will be more convenient when fetching elements.
9.4. Exclusion of capture groups
In the above example of fetching books, if you do not want to fetch " ", you can exclude this capturing group.
Groups can be excluded by adding ?: at the beginning.
let message = "两本书《一本书》和《两本书》"
const re1 = /(?:《)(?<name2>.+?)(?:》)/ig
const result = message.matchAll(re1)
for(const item of result){
console.log(item)
}
9.5. OR of capturing groups
◼ or is a term in regular expressions, which is actually a simple "or".
- In regular expressions, it is represented by a vertical bar | ;
- It is usually used together with a capture group, where multiple values are represented;
let message = "cbacbadddabcabccaccaabcaaaa"
const re1 = /(abc|cba){2,}/ig
const result = message.match(re1)
console.log(result)![]()