Contrastive experiment of Sarsa of reinforcement learning and Cliff-Walking of Q-Learning
Description of the Cliff-Walking problem
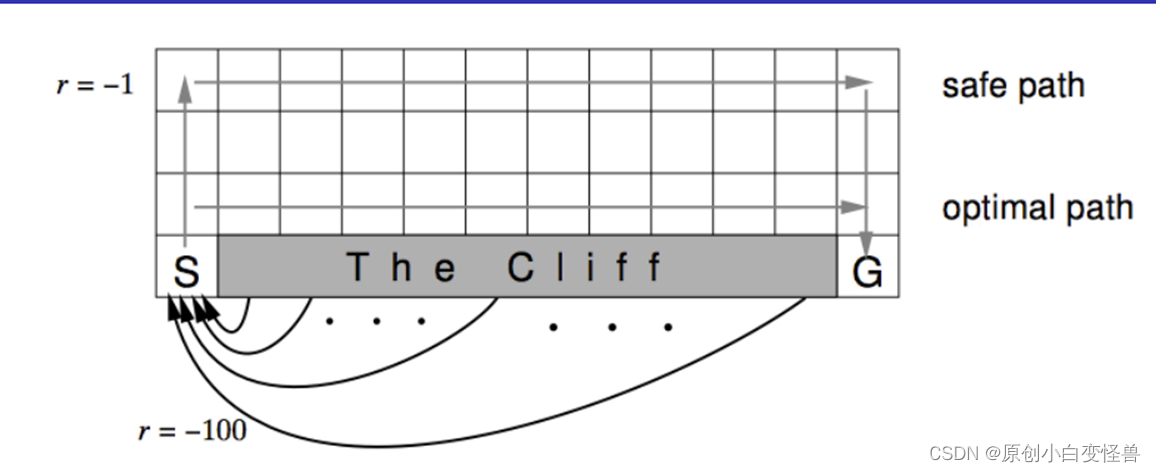
Cliff walking: walk from S to G, where the gray part is that the cliff is unreachable.
In the modeling of the feasible solution, the reward for falling off the cliff is -100, the reward for G is 10, the reward for staying still is -1, and the reward for reaching non- The reward at the end position is 0 (inconsistent with the schematic diagram in the figure, but the difference is not bad). Using the Sarsa strategy of the on-track strategy and the Q-learning algorithm of the off-track strategy, safe path and optimal path are obtained after 20,000 evolutionary iterations. Finally, the final strategy is obtained according to the Q value, so as to reproduce the above picture
Comparison of Sarsa and Q-Learning Algorithms
Sarsa Algorithm

Q-Learning Algorithm
 The first thing to introduce is ε-greedy, that is, the ε-greedy algorithm. Generally, ε is set as a small value between 0-1 (such as 0.2). When the
The first thing to introduce is ε-greedy, that is, the ε-greedy algorithm. Generally, ε is set as a small value between 0-1 (such as 0.2). When the
algorithm is in progress, a pseudo-random number is generated by the computer. , when the random number is less than ε, the principle of arbitrary equal probability selection is adopted, and when it is greater than ε, the optimal action is taken.
After introducing the two algorithms and the ε-greedy algorithm, in a nutshell, Sarsa’s choice of a in the current state s is ε-greedy, and the choice of a’ in s’ is also ε-greedy Q-Learning Same as sarsa, but the choice of a' for s' is directly the largest.
code sharing
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.patches as patches # 图形类
np.random.seed(2022)
class Agent():
terminal_state = np.arange(36, 48) # 终止状态
def __init__(self, board_rows, board_cols, actions_num, epsilon=0.2, gamma=0.9, alpha=0.1):
self.board_rows = board_rows
self.board_cols = board_cols
self.states_num = board_rows * board_cols
self.actions_num = actions_num
self.epsilon = epsilon
self.gamma = gamma
self.alpha = alpha
self.board = self.create_board()
self.rewards = self.create_rewards()
self.qtable = self.create_qtable()
def create_board(self): # 创建面板
board = np.zeros((self.board_rows, self.board_cols))
board[3][11] = 1
board[3][1:11] = -1
return board
def create_rewards(self): # 创建奖励表
rewards = np.zeros((self.board_rows, self.board_cols))
rewards[3][11] = 10
rewards[3][1:11] = -100
return rewards
def create_qtable(self): # 创建Q值
qtable = np.zeros((self.states_num, self.actions_num))
return qtable
def change_axis_to_state(self, axis): # 将坐标转化为状态
return axis[0] * self.board_cols + axis[1]
def change_state_to_axis(self, state): # 将状态转化为坐标
return state // self.board_cols, state % self.board_cols
def choose_action(self, state): # 选择动作并返回下一个状态
if np.random.uniform(0, 1) <= self.epsilon:
action = np.random.choice(self.actions_num)
else:
p = self.qtable[state, :]
action = np.random.choice(np.where(p == p.max())[0])
r, c = self.change_state_to_axis(state)
new_r = r
new_c = c
flag = 0
#状态未改变
if action == 0: # 上
new_r = max(r - 1, 0)
if new_r == r:
flag = 1
elif action == 1: # 下
new_r = min(r + 1, self.board_rows - 1)
if new_r == r:
flag = 1
elif action == 2: # 左
new_c = max(c - 1, 0)
if new_c == c:
flag = 1
elif action == 3: # 右
new_c = min(c + 1, self.board_cols - 1)
if new_c == c:
flag = 1
r = new_r
c = new_c
if flag:
reward = -1 + self.rewards[r,c]
else:
reward = self.rewards[r, c]
next_state = self.change_axis_to_state((r, c))
return action, next_state, reward
def learn(self, s, r, a, s_,sarsa_or_q):
# s状态,a动作,r即时奖励,s_演化的下一个动作
q_old = self.qtable[s, a]
# row,col = self.change_state_to_axis(s_)
done = False
if s_ in self.terminal_state:
q_new = r
done = True
else:
if sarsa_or_q == 0:
if np.random.uniform(0.1) <= self.epsilon:
s_a = np.random.choice(self.actions_num)
q_new = r + self.gamma * self.qtable[s_, s_a]
else:
q_new = r + self.gamma * max(self.qtable[s_, :])
else:
q_new = r + self.gamma * max(self.qtable[s_, :])
# print(q_new)
self.qtable[s, a] += self.alpha * (q_new - q_old)
return done
def initilize(self):
start_pos = (3, 0) # 从左下角出发
self.cur_state = self.change_axis_to_state(start_pos) # 当前状态
return self.cur_state
def show(self,sarsa_or_q):
fig_size = (12, 8)
fig, ax0 = plt.subplots(1, 1, figsize=fig_size)
a_shift = [(0, 0.3), (0, -.4),(-.3, 0),(0.4, 0)]
ax0.axis('off') # 把横坐标关闭
# 画网格线
for i in range(self.board_cols + 1): # 按列画线
if i == 0 or i == self.board_cols:
ax0.plot([i, i], [0, self.board_rows], color='black')
else:
ax0.plot([i, i], [0, self.board_rows], alpha=0.7,
color='grey', linestyle='dashed')
for i in range(self.board_rows + 1): # 按行画线
if i == 0 or i == self.board_rows:
ax0.plot([0, self.board_cols], [i, i], color='black')
else:
ax0.plot([0, self.board_cols], [i, i], alpha=0.7,
color='grey', linestyle='dashed')
for i in range(self.board_rows):
for j in range(self.board_cols):
y = (self.board_rows - 1 - i)
x = j
if self.board[i, j] == -1:
rect = patches.Rectangle(
(x, y), 1, 1, edgecolor='none', facecolor='black', alpha=0.6)
ax0.add_patch(rect)
elif self.board[i, j] == 1:
rect = patches.Rectangle(
(x, y), 1, 1, edgecolor='none', facecolor='red', alpha=0.6)
ax0.add_patch(rect)
ax0.text(x + 0.4, y + 0.5, "r = +10")
else:
# qtable
s = self.change_axis_to_state((i, j))
qs = agent.qtable[s, :]
for a in range(len(qs)):
dx, dy = a_shift[a]
c = 'k'
q = qs[a]
if q > 0:
c = 'r'
elif q < 0:
c = 'g'
ax0.text(x + dx + 0.3, y + dy + 0.5,
"{:.1f}".format(qs[a]), c=c)
if sarsa_or_q == 0:
ax0.set_title("Sarsa")
else:
ax0.set_title("Q-learning")
if sarsa_or_q == 0:
plt.savefig("Sarsa")
else:
plt.savefig("Q-Learning")
plt.show(block=False)
plt.pause(5)
plt.close()
Add the following paragraph to make the program run!
agent = Agent(4, 12, 4)
maxgen = 20000
gen = 1
sarsa_or_q = 0
while gen < maxgen:
current_state = agent.initilize()
while True:
action, next_state, reward = agent.choose_action(current_state)
done = agent.learn(current_state, reward, action, next_state,sarsa_or_q)
current_state = next_state
if done:
break
gen += 1
agent.show(sarsa_or_q)
print(agent.qtable)
Set sarsa_or_q to 0 and 1 respectively to view the schematic diagram of the results calculated by different methods.
According to the Q value, the final convergence strategy can be obtained.
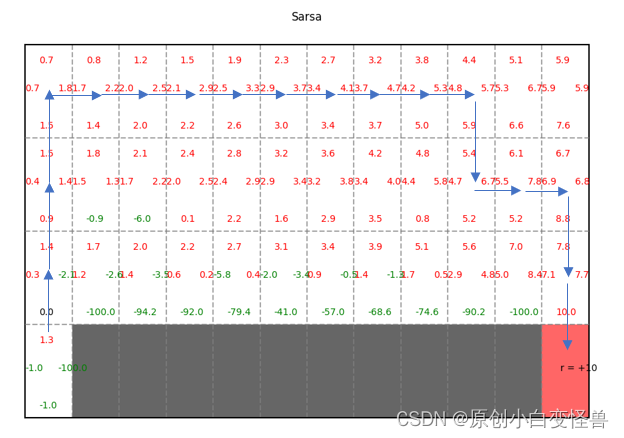
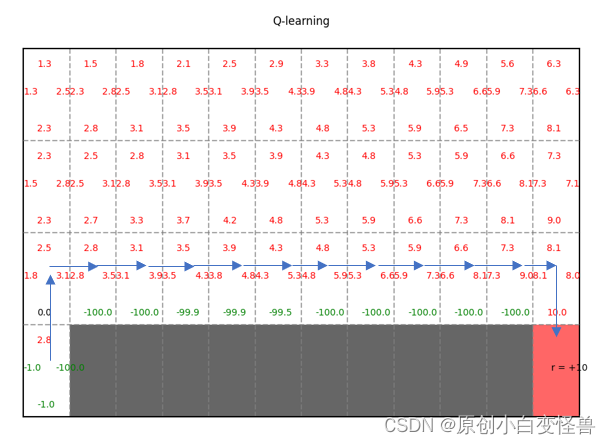
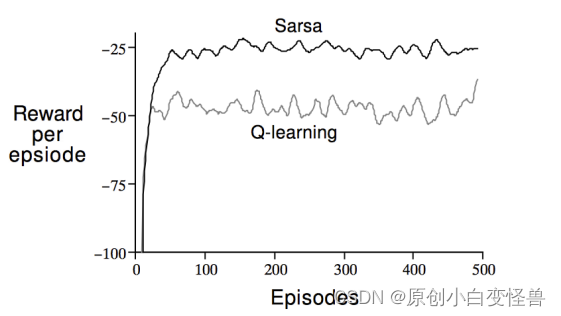
Areas for improvement
The convergence of the code iteration is too slow. The code written by the author took 20,000 iterations to converge. This is inconsistent with the result of convergence in the course of about 100 scenes. The efficiency of the algorithm still needs to be improved. It is worth adding that the convergence of about 100 scenes has not been achieved in the iterative maximum algebra, so when simulating, simply choose 20,000 times, maybe it will converge in advance.
What can be improved: build the model, because the previous code is model-free, and setting up a model to guide the strategy will get better results. Of course, it may also make the problem fall into local exploration. This is something that needs to be discussed for further study .
Combination with scientific research: In terms of research direction, if you want to combine it, you need to learn how to deal with multiple individuals learning at the same time in the environment
Quoted and written at the end
Cliff-Walking simulation isReinforcement Learning Course by David Silver
The address of the example in the fifth lecture in the course is here
. Record that the study of the intensive learning course is temporarily completed, and the flowers are scattered, da da!