Training purpose
- from daily_stocks.csv
- File import stock transaction data
- group the data
- Calculate the price of the stock, including the average maximum and minimum prices, average opening and closing prices
- Export calculated data
Training content
1. Understand the data
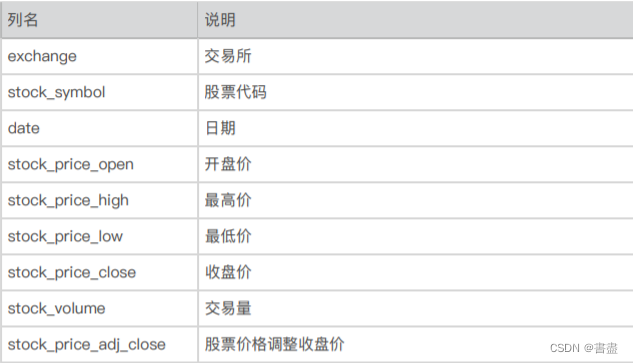
- The file daily_stocks.csv saves 65020 pieces of stock transaction data, and the descriptions of each column are as follows.
2. Environment preparation
- install pig
Tutorial recommendation https://blog.csdn.net/qq_42881421/article/details/84331794
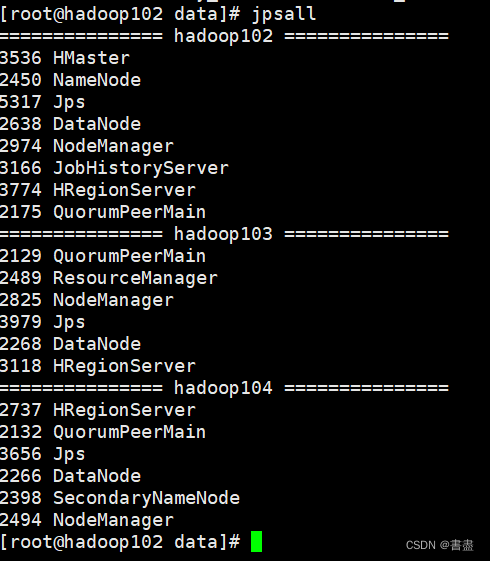
- Start hadoop environment
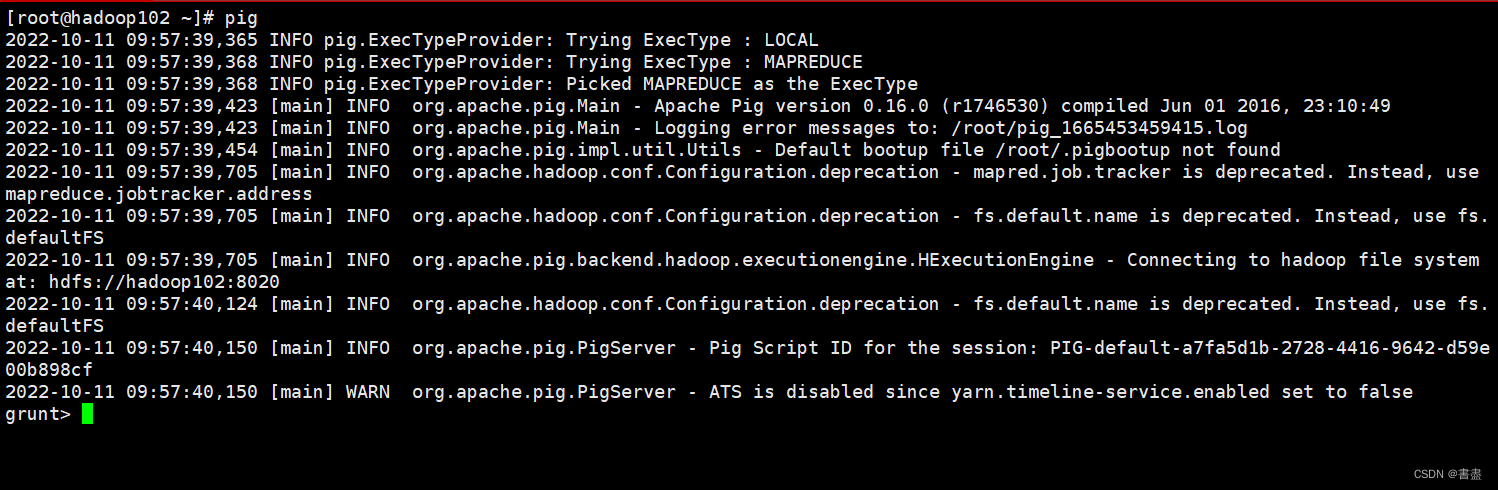
- Start the grunt shell.
pig
3. Data upload
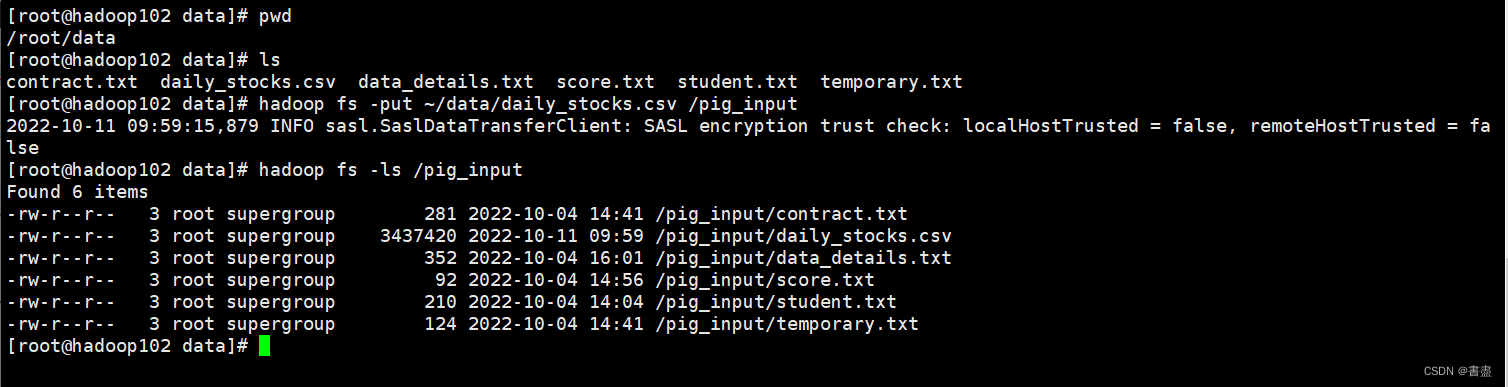
- Upload the data file daily_stocks.csv to the /pig_input directory of HDFS, and check whether the upload is successful.
hadoop fs -put ~/data/daily_stocks.csv /pig_input
hadoop fs -ls /pig_input
4. Load data
- Load the data from daily_stocks.csv into a relation named stock,
- Enter the following command in the grunt shell:
#注意自己设置的端口
stock = LOAD 'hdfs://hadoop102:8020/pig_input/daily_stocks.csv' USING PigStorage(',') as (exchange:chararray,symbol:chararray,date:chararray,stock_price_open:double,stock_price_high:double,stock_price_low:double,stock_price_close:double,stock_volume:double,stock_price_adj_close:double);

- And look at the first ten rows of the data:

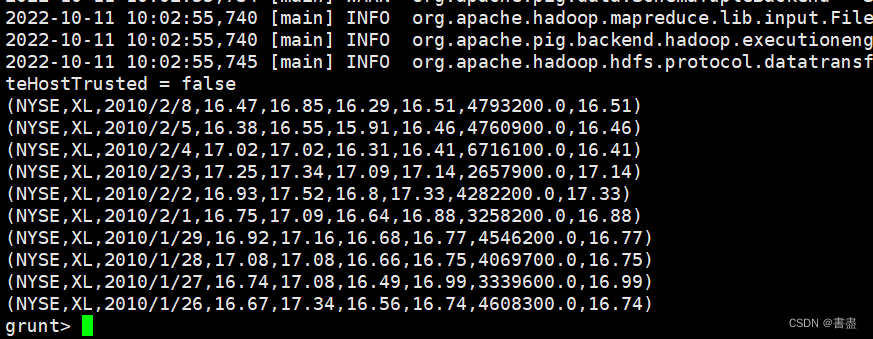
5. Data grouping
- Group by exchange, save the result into a relation called stock_exc_grp and check the grouped result:
stock_exc_grp = GROUP stock BY exchange;
dump stock_exc_grp;

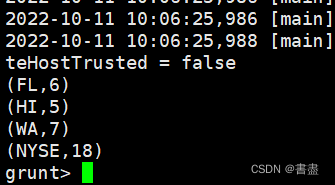
6. Count the number of exchanges
- According to the grouped data, count how many exchanges each stock is available for trading:
unique_symbols = FOREACH stock_exc_grp {symbols = stock.symbol;unique_symbol = DISTINCT symbols;GENERATE group, COUNT(unique_symbol);};
- Show results
dump unique_symbols;
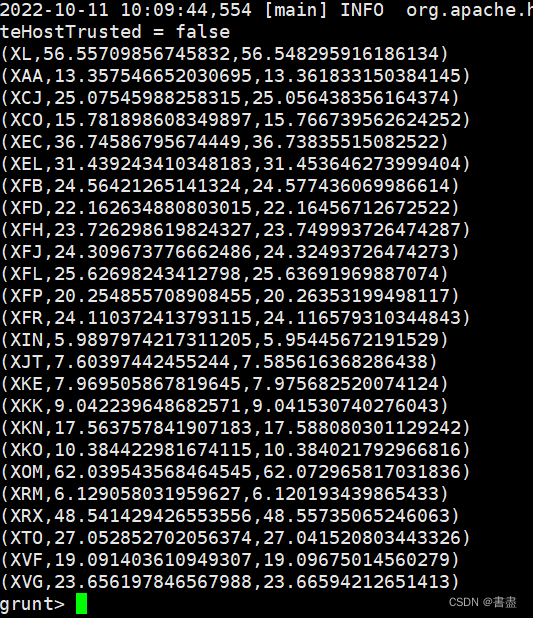
7. Statistical average opening and closing prices
- Group the stock relationship by stock code (symbol), and count the average opening and closing prices of each stock:
stock_symbol_grp = GROUP stock BY symbol;
avg_stock_price_opens_closes = FOREACH stock_symbol_grp {stock_price_open = stock.stock_price_open;stock_price_close = stock.stock_price_close;GENERATE group, AVG(stock_price_open),AVG(stock_price_close); };
dump avg_stock_price_opens_closes;

8. Statistical average highest and lowest price
- Calculate the average highest and lowest price for each stock
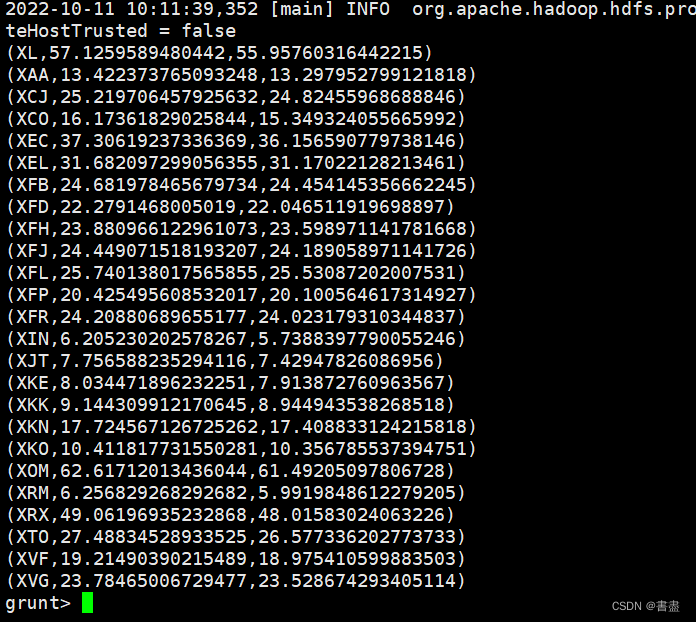
avg_stock_price_high_low = FOREACH stock_symbol_grp {stock_price_high = stock.stock_price_high;stock_price_low = stock.stock_price_low;GENERATE group, AVG(stock_price_high),AVG(stock_price_low);};
dump avg_stock_price_high_low;

9. Export data
- Export avg_stock_price_high_low, avg_stock_price_opens_closes and unique_symbols to HDFS
file system
store unique_symbols into 'unique_symbols' using PigStorage(',');
store avg_stock_price_opens_closes into 'avg_stock_price_opens_colses' using PigStorage(',');
store avg_stock_price_high_low into 'avg_stock_price_high_low' using PigStorage(',');
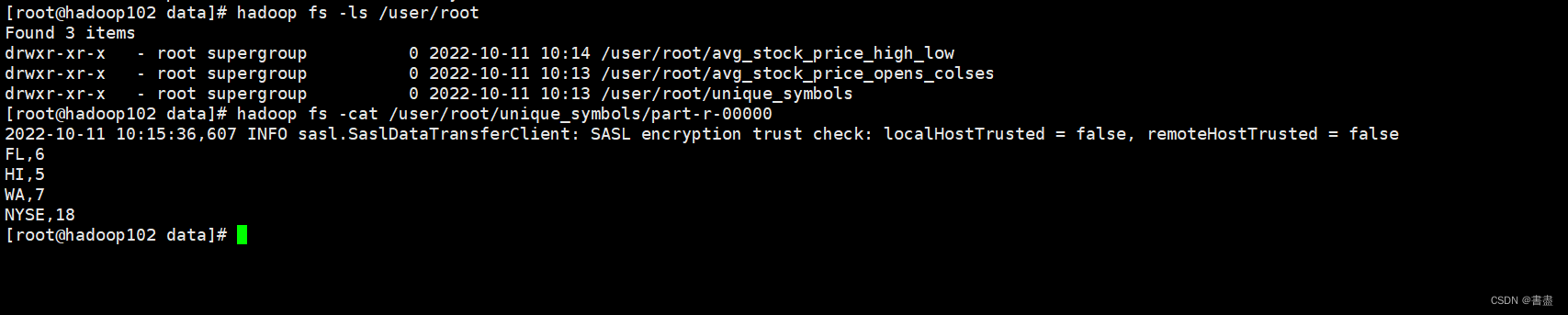
- View exported data
hadoop fs -ls /user/root
hadoop fs -cat /user/root/unique_symbols/part-r-00000
Training summary
- Pig consists of two parts: a language for describing data flow, called Pig Latin; and an execution environment for running Pig Latin programs.
- Pig is not suitable for all data processing tasks, like MapReduce, it is designed for data batch processing. If you only want to query a small part of a large data set, the implementation of pig will not be very good, because it will scan the entire data set or a large part of it.
- A Pig Latin program consists of a series of statements. Operations and commands are case-insensitive, while aliases and function names are case-sensitive.
- When Pig processes multi-line statements, Pig does not process data until the logical plan of the entire program is constructed.