overview
The second part of the Redis high-availability and high-performance cache application series mainly introduces the knowledge points of Redis transaction mechanism, IO multiplexing, and persistence.
Redis transaction mechanism
The Redis transaction mechanism is quite different from Mysql, which is divided into 4 steps for execution:
- 1. Before committing a transaction, check whether the syntax of the command is correct
- 2. After the command is submitted, it will be executed
- 3. If there is an error in the command, it will be executed
- 4. Cannot be rolled back
The difference between Redis transactions and batch operations: When Redis executes exec, the commands are either executed or not executed, and batch operations do not check syntax.
Redis transaction command description:
- multi: Tell Redis to open a transaction (note that it is only opened, not executed)
- exec: tell Redis to start executing the transaction
- discard: tell Redis to cancel the transaction
- watch: monitor a certain key-value pair, its function is that before the execution of the transaction, if the monitored key value is modified, the transaction will be canceled
When the multi command is executed, it indicates that Redis starts a transaction, and the subsequent commands are all in the queue. When the exec command is executed, the commands of the Redis transaction are either all executed or not executed at all.
redis-cli> set name "stark"
OK
redis-cli> multi
OK
redis-cli> set name "stark张宇"
QUEUED
redis-cli> set age 33
QUEUED
redis-cli> exec
1) OK
2) OK
If the syntax of the executed command is incorrect, the entire Redis transaction will be rejected by the service and not executed at all.
redis-cli> multi
OK
redis-cli> set name "stark张宇"
QUEUED
redis-cli> lpop "changchang" "quanquan" "xiaoshenyang"
QUEUED
redis-cli> exec
(error) wrong number of arguments (given 3, expected 1)
If there is no syntax error, Redis will execute all the data if an error is thrown during execution. As long as the syntax is correct, the command will be executed.
redis-cli> multi
OK
redis-cli> set name "stark张宇"
QUEUED
redis-cli> lpop name
QUEUED
redis-cli> exec
1) OK
2) WRONGTYPE Operation against a key holding the wrong kind of value
I/O multiplexing
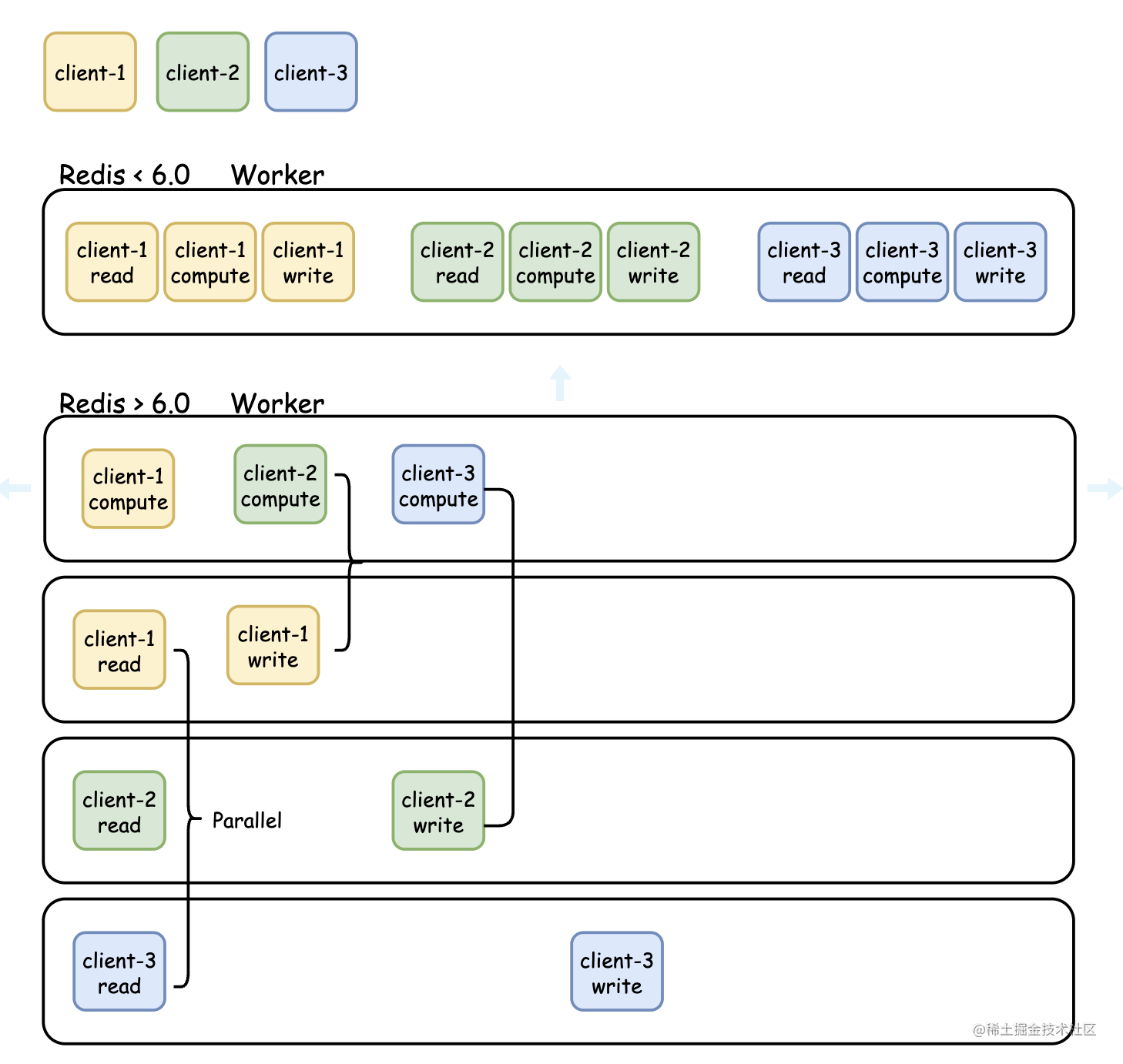
First of all, I want to explain that redis uses a single thread to process requests. Assuming that the server is a 4-core CPU, only one will be occupied, and the other 3 will not participate. The thread processing is parallel.
After Redis 6.0 version, this is optimized, using the concept of I/O thread. The main process of Redis 6.0 only does calculations and does not participate in read and write operations. The I/O thread processing is all parallel, making full use of multi-core CPUs. The advantage of saving processing time and improving the performance of processing requests.
Persistence
Redis data is stored in memory, so when the server restarts, data will be lost. Redis provides a data persistence solution to save data to disk and use files to restore data. There are three main persistence methods:
- rdb : Generate a snapshot at a certain moment and save it in a binary file
- aof: record each command, append it to the file, open it to see the specific operation record
- Mixed mode: it is a combination of the above two methods
- manual trigger
- save will keep Redis in a blocked state until the rdb persistence is completed. Use it with caution in the online environment
- bgsave, it will fork a child process to perform persistence, the main process continues to respond to client requests, it will be blocked for a short time
2. Automatic trigger
- Within m seconds, the execution command will finally execute bgsave
The execution process of bgsave: 1) First, the redis main process forks out the child process, 2) the child process will share the data of the child process, and set the main process to read only, and then start to execute the persistent operation, when there is a new command to When modifying data, Redis uses the method of realistic replication to solve the problem of data inconsistency.
Advantages and disadvantages of rdb persistence:
advantage:
- Good disaster tolerance, convenient backup
- Maximize performance, fork out a child process to operate, and have no effect on the main process
- When there is a lot of data, the startup efficiency is higher than that of aof
shortcoming:
- If a failure occurs in the middle, data loss will occur during the failure
Aof synchronization strategy
- appendfsync everysec sync every second, the default is sync every second
- appendfsync always needs to be synchronized after each operation
- appendfsync no is scheduled by the operating system
Aof's rewriting strategy: Because many commands operate on the same key during the Redis operation, a large number of commands will be repeated, causing the Aof file to be too large, and the solution is sorted out.
- Trigger manually, execute the bgrewriteaof command
- automatic trigger
auto-aof-rewrit-precentage: The ratio between the current Aof file size and the size after the last rewrite is equal to or equal to the specified growth percentage. For example, 100 means that the current Aof file is rewritten when it is twice the size of the last rewrite.
auto-aof-rewrit-mini-size: It is possible to rewrite when the Aof file size is greater than this value.
Advantages: data security, will not cause data loss
Disadvantages: lower restart efficiency than rdb, lower operating efficiency than rdb