Single Server High Performance Mode
High performance is the pursuit of every programmer. Whether we are building a system or writing a line of code, we hope to achieve high performance, and high performance is the most complicated part. The operating system, CPU, memory, disk, Cache, network, programming language, architecture, etc., each have the potential to affect the system to achieve high performance.
A line of inappropriate debug logs may reduce the performance of the server from TPS 30000 to 8000;
A tcp_nodelay parameter, it is possible to extend the response time from 2 milliseconds to 40 milliseconds.
Therefore, to achieve high-performance computing is a very complex and challenging task. Different stages in the software system development process are related to whether high performance can be realized in the end.
From the perspective of an architect, of course, special attention needs to be paid to the design of a high-performance architecture. High-performance architecture design mainly focuses on two aspects:
-
1. Try to improve the performance of a single server, and maximize the performance of a single server.
-
2. If a single server cannot support performance, design a server cluster solution.
In addition to the above two points, whether the final system can achieve high performance is also related to the specific implementation and coding.
However, architecture design is the basis of high performance. If architecture design does not achieve high performance, the room for improvement in subsequent specific implementation and coding is limited. Visually speaking, the architecture design determines the upper limit of system performance, and the implementation details determine the lower limit of system performance.
One of the keys to the high performance of a single server is the concurrency model adopted by the server. The concurrency model has the following two key design points:
-
1. How the server manages connections.
-
2. How the server handles the request.
The above two design points are ultimately related to the I/O model & process model of the operating system.
-
I/O model: blocking, non-blocking, synchronous, asynchronous.
-
Process model: single process, multi-process, multi-thread.
The above basic knowledge points will be used when introducing the concurrency model in detail below, so I suggest that you first check the mastery of these basic knowledge. For more information, you can refer to the three volumes of "UNIX Network Programming".
PPC(Process Per Connection)
Its meaning means that every time there is a new connection, a new process is created to specifically handle the connection request. This is the model adopted by traditional UNIX network servers.
The basic flowchart is:
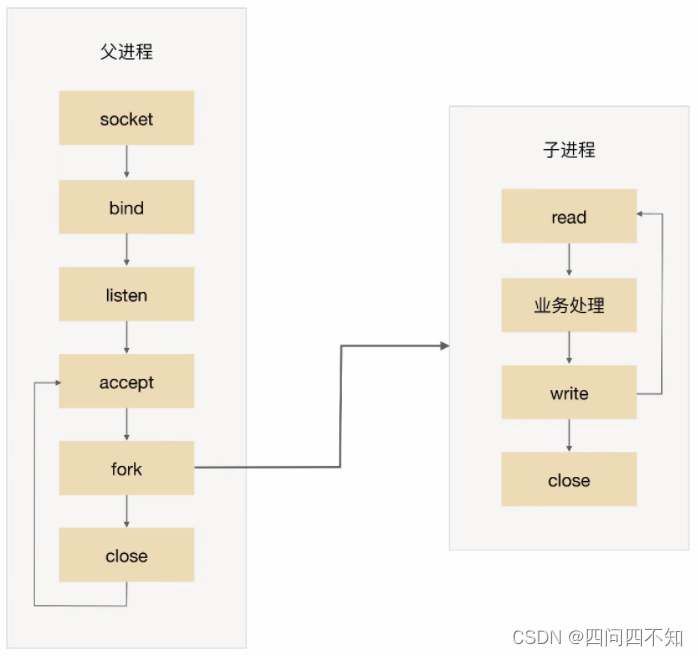
-
The parent process accepts the connection (accept in the figure).
-
The parent process "forks" the child process (fork in the figure).
-
The child process handles the read and write requests of the connection (the child process read, business processing, and write in the figure).
-
The child process closes the connection (close in the child process in the figure).
Note that there is a small detail in the figure. After the parent process "fork" the child process, it directly calls close, which seems to close the connection. In fact, it just reduces the reference count of the file descriptor of the connection by one. The real closing of the connection is to wait After the child process also calls close and the reference count of the file descriptor fd (File Descriptor) corresponding to the connection becomes 0, the operating system will actually close the connection. For more details, please refer to "UNIX Network Programming: Volume 1".
The PPC mode is simple to implement, and is more suitable for situations where the number of connections to the server is not so many, such as a database server.
For ordinary business servers, before the rise of the Internet, this model actually worked well because the server’s visits and concurrency were not so large. CERN httpd, the world’s first web server, adopted this model ( For details, you can refer to https://en.wikipedia.org/wiki/CERN_httpd).
After the rise of the Internet, the number of concurrency and visits of servers has increased from dozens to tens of thousands. The disadvantages of this model have been highlighted, mainly in the following aspects:
-
Fork is expensive: From the perspective of the operating system, the cost of creating a process is very high. It needs to allocate a lot of kernel resources and copy the memory image from the parent process to the child process. Even if the current operating system uses the Copy on Write (copy-on-write) technology when copying the memory image, the overall cost of creating a process is still very high.
-
The communication between parent and child processes is complicated: when the parent process "forks" the child process, the file descriptor can be copied from the parent process to the child process through memory image copying, but after the "fork" is completed, the communication between the parent and child processes is more troublesome, and IPC (Interprocess Communication) and other process communication schemes. For example, the child process needs to tell the parent process how many requests it has processed before closing to support the parent process for global statistics, then the child process and the parent process must use the IPC scheme to transfer information.
-
The number of concurrent connections supported is limited: if each connection survives for a long time and new connections come in continuously, the number of processes will increase, and the frequency of operating system process scheduling and switching will also increase. The pressure will also increase. Therefore, under normal circumstances, the maximum number of concurrent connections that a PPC solution can handle is several hundred.
Apache Prefork mode
In the PPC mode, when a connection comes in, a new process is forked to process the connection request. Due to the high cost of the fork process, the user may feel slower when accessing. The emergence of the prefork mode is to solve this problem.
As the name implies, prefork is to create a process in advance (pre-fork). The system pre-creates a process when it starts, and then begins to accept user requests. When a new connection comes in, the operation of the fork process can be omitted, allowing users to access faster and experience better. The basic diagram of prefork is:
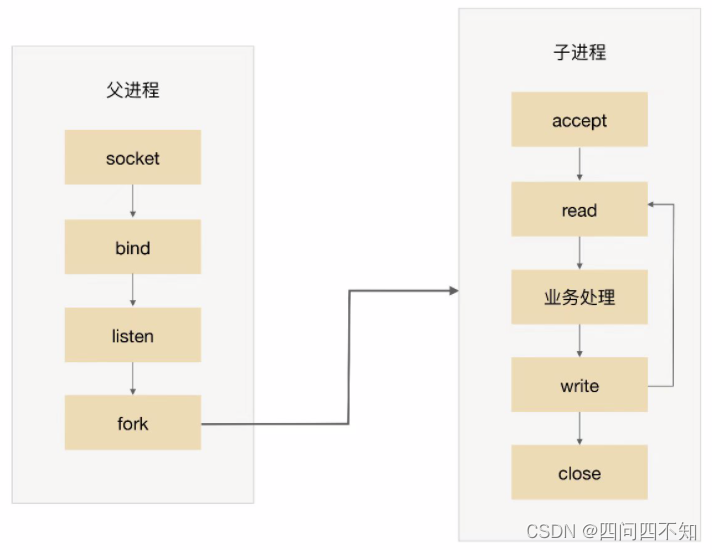
The key to the realization of prefork is that multiple child processes accept the same socket. When a new connection enters, the operating system guarantees that only one process can finally accept successfully. But there is also a small problem here: the "shocking group" phenomenon means that although only one child process can accept successfully, all child processes blocked on accept will be awakened, which leads to unnecessary process scheduling and Context switched. Fortunately, the operating system can solve this problem. For example, the kernel after version 2.6 of Linux has solved the problem of accept thundering herd.
The prefork mode, like PPC, still has the problem of complex communication between parent and child processes and the limited number of concurrent connections supported, so there are not many practical applications at present. The Apache server provides the MPM prefork mode, which is recommended for sites that require reliability or compatibility with old software. By default, a maximum of 256 concurrent connections are supported.
In addition to Prefork mode, Apache also has Worker and Event modes. Compared with the prefork mode, the worker uses a mixed mode of multi-process and multi-thread. The worker mode will also pre-fork some sub-processes first, and then create some threads for each sub-process, including a listening thread. Each request will be processed Assigned to a thread to serve. Threads are lighter than processes, because threads share the memory space of the parent process, so the memory usage will be reduced. In high concurrency scenarios, there will be more available threads than prefork, and the performance will be better. ; In addition, if there is a problem with one thread, it will also cause problems with threads under the same process. If there are problems with multiple threads, it will only affect part of Apache, not all. Due to the use of multi-process and multi-thread, it is necessary to consider the safety of threads. When using keep-alive long connection, a certain thread will always be occupied, even if there is no request in the middle, it needs to wait until the timeout will be released (this problem Also exists in prefork mode). The event mode is the latest working mode of Apache. It is very similar to the worker mode. The difference is that it solves the problem of wasting thread resources during keep-alive long connections. In the event working mode, there will be some dedicated threads It is used to manage these keep-alive type threads. When a real request comes, the thread that passes the request to the server, and allows it to be released after the execution is completed. This enhances request handling in high concurrency scenarios.
TPC(Thread Per Connection)
Its meaning means that every time there is a new connection, a new thread is created to specifically process the connection request.
Compared with processes, threads are lighter-weight, and the consumption of creating threads is much less than that of processes; at the same time, multi-threads share the process memory space, and thread communication is simpler than process communication. Therefore, TPC actually solves or weakens the problem of high cost of PPC fork and the problem of complicated communication between parent and child processes.
The basic process of TPC is:
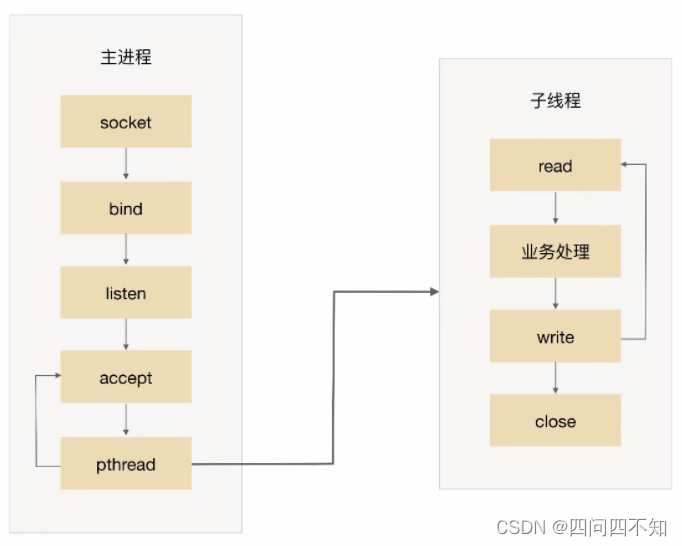
-
The parent process accepts the connection (accept in the figure).
-
The parent process creates a child thread (pthread in the figure).
-
The sub-thread handles the read and write requests of the connection (sub-thread read, business processing, and write in the figure).
-
The child thread closes the connection (close in the child thread in the figure).
Note that compared with PPC, the main process does not use "close" connections. The reason is that the sub-threads share the process space of the main process, and the connected file descriptors are not copied, so only one close is required.
Although TPC solves the problems of high cost of fork and complex process communication, it also introduces new problems, specifically:
-
Although the cost of creating a thread is lower than that of creating a process, it is not without cost. There are still performance problems when there is high concurrency (such as tens of thousands of connections per second).
-
There is no need for inter-process communication, but the mutual exclusion and sharing between threads introduces complexity, which may lead to deadlock problems if you are not careful.
-
Multi-threads will affect each other. When a thread is abnormal, it may cause the entire process to exit (for example, the memory is out of bounds).
In addition to introducing new problems, TPC still has the problem of CPU thread scheduling and switching costs. Therefore, the TPC scheme is basically similar to the PPC scheme in essence. In the scenario of hundreds of concurrent connections, the PPC scheme is used more, because the PPC scheme does not have the risk of deadlock and does not affect each other between multiple processes. Greater stability.
prethread
In the TPC mode, a new thread is created to process the connection request when a connection comes in. Although creating a thread is lighter than creating a process, it still has a certain cost, and the prethread mode is to solve this problem.
Similar to prefork, prethread mode will create threads in advance, and then start to accept user requests. When a new connection comes in, the operation of creating threads can be omitted, making users feel faster and have a better experience.
Since data sharing and communication between multiple threads are more convenient, the implementation of prethread is actually more flexible than that of prefork. The common implementation methods are as follows:
The main process accepts, and then hands over the connection to a thread for processing.
The sub-threads all try to accept, and finally only one thread accepts successfully. The basic diagram of the scheme is as follows: The
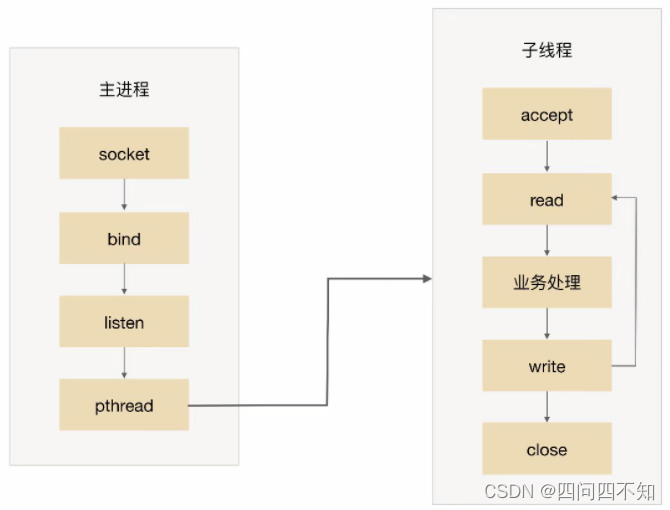
MPM worker mode of the Apache server is essentially a prethread scheme , but it has been slightly improved. The Apache server will first create multiple processes, and then create multiple threads in each process. The child process continues to provide services without causing the entire server to hang up.
Prethread can theoretically support more concurrent connections than prefork, and the Apache server MPM worker mode supports 16 × 25 = 400 concurrent processing threads by default.
Reactor
The main problem of the PPC mode is that each connection needs to create a process (for the sake of brevity, we only use PPC and process as an example, in fact, it is replaced by TPC and thread, the principle is the same), and the process is destroyed after the connection ends. Doing so is actually a big waste. In order to solve this problem, a natural idea is resource reuse, that is, instead of creating a separate process for each connection, a process pool is created to assign connections to processes, and one process can handle the business of multiple connections.
After introducing the resource pool processing method, a new question will arise: how can a process efficiently handle multiple connected services? When a connection is made to a process, the process can adopt the processing flow of "read -> business processing -> write". If the current connection has no data to read, the process will be blocked on the read operation. This blocking method has no problem in the scenario of one connection and one process, but if a process handles multiple connections, the process is blocked on the read operation of a certain connection. At this time, even if other connections have data to read, the process cannot read Processing, it is obvious that high performance cannot be achieved in this way.
The easiest way to solve this problem is to change the read operation to non-blocking , and then the process continuously polls multiple connections. This method can solve the blocking problem, but the solution is not elegant. First of all, polling consumes CPU; secondly, if a process handles tens of thousands of connections, the efficiency of polling is very low.
In order to better solve the above problems, it is easy to think that the process only processes when there is data on the connection, which is the source of I/O multiplexing technology.
I/O multiplexing technology can be summed up in two key implementation points:
-
When multiple connections share one blocking object, the process only needs to wait on one blocking object without polling all connections. Common implementation methods include select, epoll, kqueue, etc.
-
When a certain connection has new data that can be processed, the operating system will notify the process, and the process returns from the blocked state to start business processing.
I/O multiplexing combined with thread pool perfectly solves the problems of PPC and TPC, and the "great gods" gave it a very good name: Reactor, which means "reactor" in Chinese. Thinking of "nuclear reactor", it sounds scary. In fact, the "reaction" here does not mean fusion or fission reaction, but " event response ", which can be understood as " when an event comes, I will respond Response ", the "I" here is Reactor, the specific response is the code we wrote, Reactor will call the corresponding code according to the event type to process. The Reactor mode is also called the Dispatcher mode (you will see a class with this name in many open source systems, which actually implements the Reactor mode), which is closer to the meaning of the mode itself, that is, the I/O multiplexing unified monitoring event, received Assign (Dispatch) to a process after the event.
The core components of Reactor mode include Reactor and processing resource pool (process pool or thread pool), in which Reactor is responsible for monitoring and distributing events, and processing resource pool is responsible for processing events. At first glance, the implementation of Reactor is relatively simple, but in fact, combined with different business scenarios, the specific implementation scheme of Reactor mode is flexible and changeable, mainly reflected in:
The number of Reactors can vary: it can be one Reactor or multiple Reactors.
The number of resource pools can vary: taking a process as an example, it can be a single process or multiple processes (similar to threads).
Combining the above two factors, there are theoretically 4 options. However, compared with the "single Reactor single process" implementation scheme, the "multiple Reactor single process" solution is complex and has no performance advantages. Therefore, "multiple Reactor single process" "The plan is only a theoretical plan, and it has no actual application.
The final Reactor pattern has these three typical implementations:
-
Single Reactor single process/thread.
-
Single Reactor multithreading.
-
Multiple Reactor processes/threads.
The specific choice of process or thread in the above scheme is more related to programming language and platform. For example, the Java language generally uses threads (for example, Netty), and the C language can use both processes and threads. For example, Nginx uses processes and Memcache uses threads.
Single Reactor single process/thread
The schematic diagram of single-reactor single-process/thread scheme is as follows (taking process as an example):
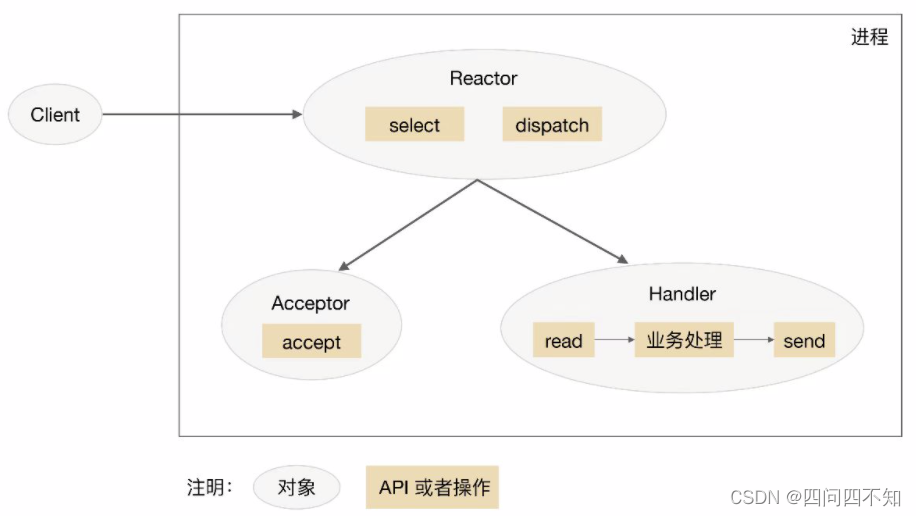
Note that select, accept, read, and send are standard network programming APIs, and dispatch and "business processing" are operations that need to be completed. The schematic diagrams of other schemes are similar.
To elaborate on this scheme:
-
1. The Reactor object monitors the connection event through select, and distributes it through dispatch after receiving the event.
-
2. If it is an event of connection establishment, it will be processed by the Acceptor. The Acceptor accepts the connection through accept and creates a Handler to handle various subsequent events of the connection.
-
3. If it is not a connection establishment event, Reactor will call the Handler corresponding to the connection (the Handler created in step 2) to respond.
-
4. Handler will complete the complete business process of read->business processing->send.
The advantage of the single-reactor single-process mode is that it is very simple, there is no inter-process communication, no process competition, and everything is completed in the same process. But its shortcomings are also very obvious, the specific manifestations are:
-
There is only one process, and the performance of multi-core CPUs cannot be utilized; only multiple systems can be deployed to utilize multi-core CPUs, but this will bring complexity to operation and maintenance. Originally, only one system needs to be maintained, but this method needs to be maintained on one machine. Multiple systems.
-
When the Handler is processing the business on a certain connection, the entire process cannot handle events of other connections, which can easily lead to performance bottlenecks.
Therefore, the single-reactor single-process solution has few application scenarios in practice, and is only suitable for scenarios with very fast business processing . At present, the well-known open source software that uses single-reactor single-process is Redis.
It should be noted that systems written in C language generally use single Reactor and single process, because there is no need to create threads in the process; while systems written in Java generally use single Reactor and single thread, because the Java virtual machine is a process, and the virtual machine There are many threads, and the business thread is just one of them.
Single Reactor multithreading
In order to overcome the shortcomings of the single-reactor single-process/thread solution, it is obvious to introduce multi-process/multi-thread, which leads to the second solution: single-reactor multi-thread.
The schematic diagram of the single Reactor multi-threading scheme is:
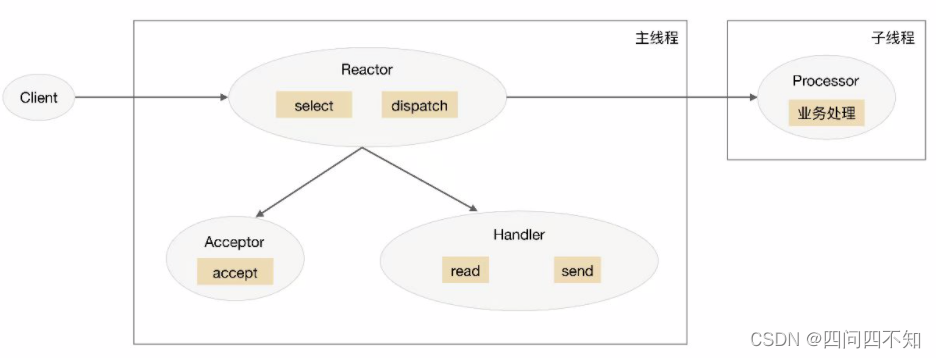
introduce this scheme:
-
1. In the main thread, the Reactor object monitors the connection event through select, and distributes it through dispatch after receiving the event.
-
2. If it is an event of connection establishment, it will be processed by the Acceptor. The Acceptor accepts the connection through accept and creates a Handler to handle various subsequent events of the connection.
-
3. If it is not a connection establishment event, Reactor will call the Handler corresponding to the connection (the Handler created in step 2) to respond.
-
4. The Handler is only responsible for responding to events and does not perform business processing; after the Handler reads the data through read, it will send it to the Processor for business processing.
-
5. The Processor will complete the real business processing in an independent sub-thread, and then send the response result to the Handler of the main process for processing; the Handler will return the response result to the client through send after receiving the response.
The single Reator multithreading solution can make full use of the processing capabilities of multi-core and multi-CPU, but it also has the following problems:
Multi-thread data sharing and access is more complicated . For example, after the child thread completes the business processing, it needs to pass the result to the Reactor of the main thread for sending, which involves the mutual exclusion and protection mechanism of shared data. Taking Java's NIO as an example, Selector is thread-safe, but the set of keys returned by Selector.selectKeys() is not thread-safe, and the processing of selected keys must be single-threaded or protected by synchronization measures.
Reactor is responsible for monitoring and responding to all events, and only runs in the main thread. It will become a performance bottleneck when the instantaneous high concurrency is high.
You may find that only the " single Reactor multi-thread " solution is listed here , and the " single Reactor multi-process " solution is not listed . What is the reason? The main reason is that if multiple processes are used, after the child process completes the business processing, it returns the result to the parent process and notifies the parent process which client to send it to, which is very troublesome. Because the parent process only listens to events on each connection through Reactor and then distributes them, the child process is not a connection when communicating with the parent process. If you want to simulate the communication between the parent process and the child process as a connection, and add Reactor to listen, it is more complicated. When multi-threading is used, because multi-threading shares data, communication between threads is very convenient. Although the synchronization problem when sharing data between threads needs to be considered additionally, this complexity is much lower than the complexity of inter-process communication.
Multi-Reactor multi-process/thread
In order to solve the problem of single Reactor multithreading, the most intuitive way is to change single Reactor to multi Reactor, which leads to the third solution: multi Reactor multi process/thread.
The schematic diagram of the multi-reactor multi-process/thread scheme is (take the process as an example):
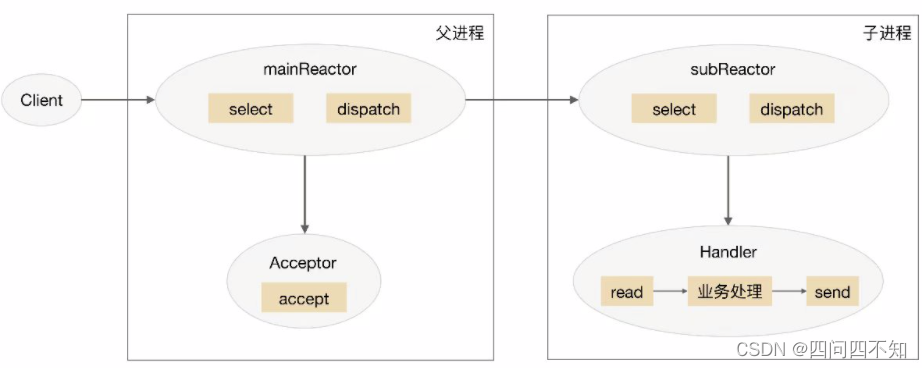
the detailed scheme is as follows:
-
1. The mainReactor object in the parent process monitors the connection establishment event through select, receives the event through the Acceptor, and assigns the new connection to a child process.
-
2. The subReactor of the subprocess adds the connection assigned by the mainReactor to the connection queue for monitoring, and creates a Handler to handle various events of the connection.
-
3. When a new event occurs, subReactor will call the Handler corresponding to the connection (that is, the Handler created in step 2) to respond.
-
4. Handler completes the complete business process of read→business processing→send.
The multi-reactor multi-process/thread solution seems more complicated than the single-reactor multi-thread solution, but it is simpler in actual implementation. The main reasons are:
-
The responsibilities of the parent process and the child process are very clear. The parent process is only responsible for receiving new connections, and the child process is responsible for completing subsequent business processing.
-
The interaction between the parent process and the child process is very simple. The parent process only needs to pass the new connection to the child process, and the child process does not need to return data.
-
The sub-processes are independent of each other, and there is no need for synchronous sharing and other processing (this is limited to select, read, send, etc. related to the network model without synchronous sharing, and "business processing" may still need synchronous sharing).
At present, the well-known open source system Nginx uses multi-reactor and multi-process , and the implementation of multi-reactor and multi-thread includes Memcache and Netty .
Nginx adopts the multi-reactor multi-process mode, but the solution is different from the standard multi-reactor multi-process mode. The specific difference is that only the listening port is created in the main process, and the mainReactor is not created to "accept" the connection, but the Reactor of the child process is used to "accept" the connection, and only one child process "accepts" at a time through the lock. After the process "accept" a new connection, it will be placed in its own Reactor for processing, and will not be assigned to other child processes. For more details, please refer to relevant information or read the Nginx source code.
git clone https://gitclone.com/github.com/nginx/nginx
Proactor
Reactor is a non-blocking synchronous network model, because both real read and send operations require user process synchronization. The "synchronous" here means that the user process is synchronous when performing I/O operations such as read and send. If the I/O operation is changed to asynchronous, the performance can be further improved. This is the asynchronous network model Proactor.
The Chinese translation of Proactor as "proactive device" is difficult to understand. The word similar to it is proactive, which means "active", so we translate it as "proactive device" better to understand. Reactor can be understood as "I will notify you when an event comes, and you handle it", while Proactor can be understood as " I will handle an event when it comes, and I will notify you when it is finished ." "I" here is the operating system kernel, "events" are I/O events that have new connections, data to read, and data to write, and "you" is our program code.
The schematic diagram of the Proactor model is:
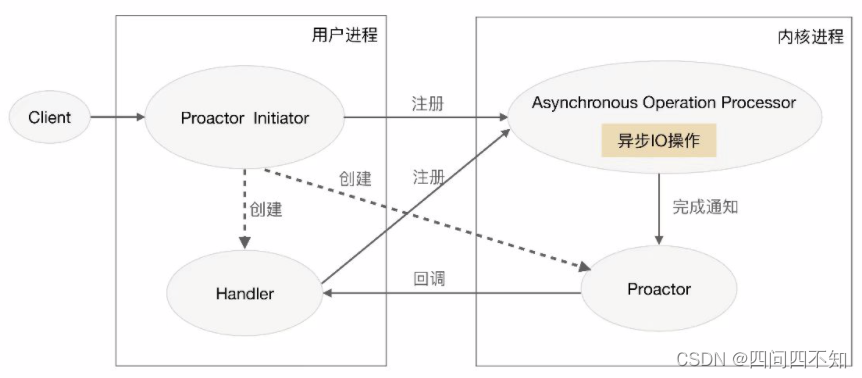
introduce the Proactor solution in detail:
-
1. Proactor Initiator is responsible for creating Proactor and Handler, and registering both Proactor and Handler to the kernel through Asynchronous Operation Processor.
-
2. Asynchronous Operation Processor is responsible for processing registration requests and completing I/O operations.
-
3. The Asynchronous Operation Processor notifies Proactor after completing the I/O operation.
-
4. Proactor calls back different Handlers for business processing according to different event types.
-
5. The Handler completes the business processing, and the Handler can also register a new Handler to the kernel process.
In theory, Proactor is more efficient than Reactor. Asynchronous I/O can make full use of the DMA feature, allowing I/O operations to overlap with calculations. However, to achieve true asynchronous I/O, the operating system needs to do a lot of work. At present, real asynchronous I/O is realized through IOCP under Windows, but the AIO under Linux system is not perfect, so the Reactor mode is the main way to realize high-concurrency network programming under Linux. So even though Boost.Asio claims to implement the Proactor model, it actually uses IOCP under Windows, while under Linux it is an asynchronous model simulated with Reactor mode (using epoll).