Article directory
- 1. Simulation implementation of list
- Two, the comparison between list and vector
- 3. Summary: Simulate the overall code of list implementation
1. Simulation implementation of list
Overview of the three classes and their member function interfaces
namespace cl
{
//模拟实现list当中的结点类
template<class T>
struct _list_node
{
//成员函数
_list_node(const T& val = T()); //构造函数
//成员变量
T _val; //数据域
_list_node<T>* _next; //后继指针
_list_node<T>* _prev; //前驱指针
};
//模拟实现list迭代器类
template<class T, class Ref, class Ptr>
struct _list_iterator
{
typedef _list_node<T> node;
typedef _list_iterator<T, Ref, Ptr> self;
_list_iterator(node* pnode); //构造函数
//各种运算符重载函数
self operator++();
self operator--();
self operator++(int);
self operator--(int);
bool operator==(const self& s) const;
bool operator!=(const self& s) const;
Ref operator*();
Ptr operator->();
//成员变量
node* _pnode; //一个指向结点的指针
};
//模拟实现list
template<class T>
class list
{
public:
typedef _list_node<T> node;
typedef _list_iterator<T, T&, T*> iterator;
typedef _list_iterator<T, const T&, const T*> const_iterator;
//默认成员函数
list();
list(const list<T>& lt);
list<T>& operator=(const list<T>& lt);
~list();
//迭代器相关函数
iterator begin();
iterator end();
const_iterator begin() const;
const_iterator end() const;
//访问容器相关函数
T& front();
T& back();
const T& front() const;
const T& back() const;
//插入、删除函数
void insert(iterator pos, const T& x);
iterator erase(iterator pos);
void push_back(const T& x);
void pop_back();
void push_front(const T& x);
void pop_front();
//其他函数
size_t size() const;
void resize(size_t n, const T& val = T());
void clear();
bool empty() const;
void swap(list<T>& lt);
private:
node* _head; //指向链表头结点的指针
size_t _size;//统计节点个数
};
}
Mock implementation of node class
We often say that the list is a linked list when it is implemented at the bottom layer. More precisely, the list is actually a two-way circular linked list with the lead.

Therefore, if we want to implement list, we first need to implement a node class. The information that a node needs to store is: data, the address of the previous node, and the address of the next node, so the member variables of the node class will come out (data, predecessor pointer, successor pointer).
For the member functions of the node class, we only need to implement a constructor. Because the node class only needs to construct a node according to the data, and the release of the node is completed by the destructor of the list.
//结点类
template<class T>
struct list_node
{
//成员变量
list_node<T>* _next;//后继指针
list_node<T>* _prev;//前驱指针
T _data;//数据域
//成员函数
list_node(const T& val = T())//构造函数
:_next(nullptr)
, _prev(nullptr)
, _data(val)
{
}
};
Note: If no data is passed in when constructing the node, the value constructed by the default constructor of the type stored in the list container will be used as the passed in data by default.
Mock implementation of the iterator class
Significance of the existence of the iterator class:
When simulating the implementation of string and vector before, there is no mention of implementing an iterator class. Why does it need to implement an iterator class when implementing a list?
Because both string and vector objects store their data in a continuous memory space, we can perform a series of operations on the data at the corresponding location through operations such as increment, decrement, and dereference of pointers. Therefore, among string and vector The iterators of are just raw pointers.
But for the list, the position of each node in the memory is random and not continuous. We cannot operate the data of the corresponding node only through operations such as self-increment, self-decrement, and dereference of the node pointer. .
The meaning of the iterator is to allow users to access the data in the container in a simple and unified way without having to care about the underlying implementation of the container.
Since the behavior of the node pointer of the list does not meet the iterator definition, then we can encapsulate the node pointer and overload the various operator operations of the node pointer, so that we can use the iteration in string and vector Use the iterators in the list in the same way as the list. For example, when you use the iterator in the list to perform an auto-increment operation, the p = p->next statement is actually executed, but you don't know it.
Summary: The list iterator class actually encapsulates the node pointer and overloads its various operators, so that the various behaviors of the node pointer look the same as ordinary pointers. (For example, auto-incrementing the node pointer can point to the next node)
Template parameter description for iterator class
Why are there three template parameters in the template parameter list of the iterator class we implemented here?
template<class T, class Ref, class Ptr>
In the simulation implementation of list, we typedef two iterator types, normal iterator and const iterator.
typedef _list_iterator<T, T&, T*> iterator;
typedef _list_iterator<T, const T&, const T*> const_iterator;
Here we can see that in the template parameter list of the iterator classRef and Ptr represent reference type and pointer type respectively.
When we use a normal iterator, the compiler will instantiate a normal iterator object; when we use a const iterator, the compiler will instantiate a const iterator object.
If the iterator class does not design three template parameters, then it cannot distinguish between ordinary iterators and const iterators.
Overloads for iterator operator->
In some scenarios, we may use the -> operator when using iterators.
//*的重载:返回节点的数据
Ref operator*()
{
return _pnode->_data;
}
//->的重载:返回数据的指针
T* operator->()
{
return &_pnode->_data;
}
For example:
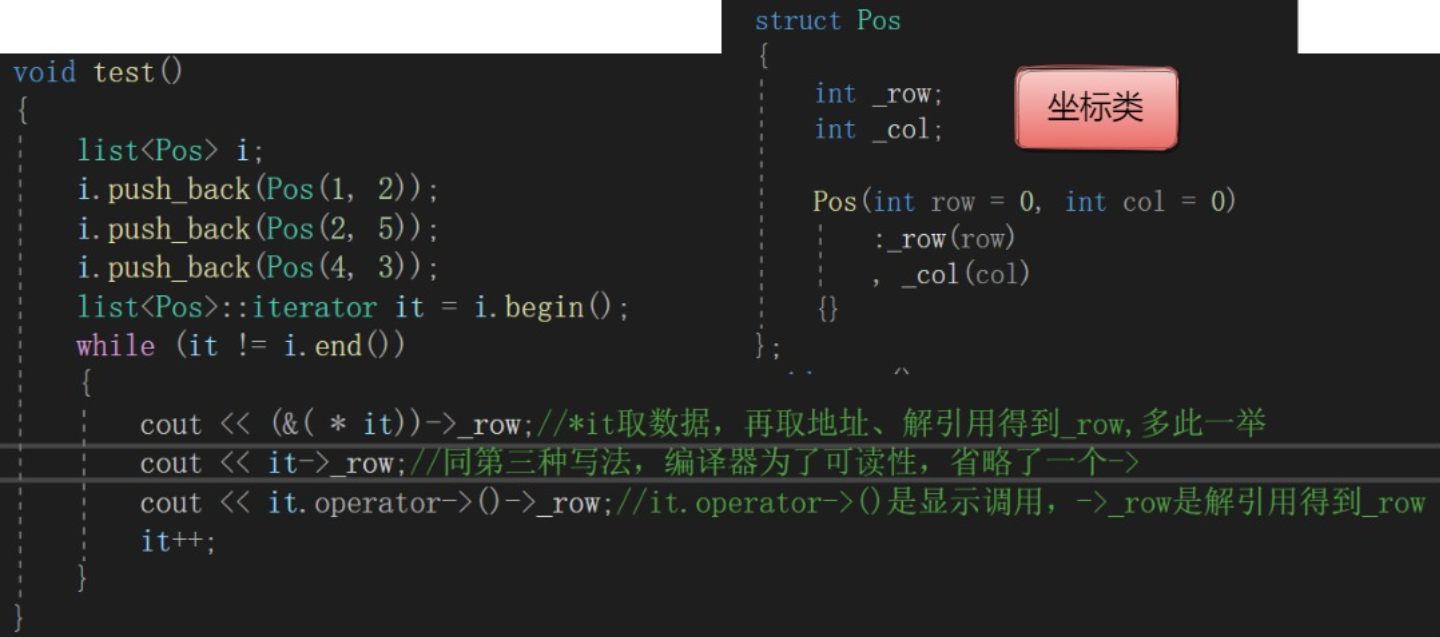
But operator-> uses T* as the return value type, so that both ordinary iterators and const iterators can be modified, so the return value type of operator-> should be changed to generic:
template <class T, class Ref,class Ptr>
Ptr operator->()
{
return &_pnode->_data;
}
typedef __list_iterator<T, T&, T*> iterator;
typedef __list_iterator<T, const T&, const T*> const_iterator;
Iterator simulation implementation code
//用类封装迭代器
// 同一个类模板实例化出的两个类型
// typedef __list_iterator<T, T&, T*> iterator;
// typedef __list_iterator<T, const T&, const T*> const_iterator;
template<class T, class Ref, class Ptr>
struct __list_iterator
{
typedef list_node<T> node;
node* _pnode;
typedef __list_iterator<T, Ref, Ptr> Self; //self是当前迭代器对象的类型:
//Ref就表示当我需要使用*it时,我们返回的是const T&,还是T&,即支持两种迭代器
//Ptr支持我们像指针一样使用->
//迭代器类实际上就是对结点指针进行了封装,
//其成员变量就只有一个,那就是结点指针,其构造函数直接根据所给结点指针构造一个迭代器对象即可。
__list_iterator(node* p)
:_pnode(p)
{
}
Ptr operator->()
{
return &_pnode->_data;
}
// iterator it
// *it
// ++it;
//当我们使用解引用操作符时,是想得到该位置的数据内容。
//因此,我们直接返回当前结点指针所指结点的数据即可,但是这里需要使用引用返回,因为解引用后可能需要对数据进行修改。
Ref operator*()
{
return _pnode->_data;
}
// ++it
//前置++原本的作用是将数据自增,然后返回自增后的数据。
//我们的目的是让结点指针的行为看起来更像普通指针,
//那么对于结点指针的前置++,我们就应该先让结点指针指向后一个结点,然后再返回“自增”后的结点指针即可。
Self& operator++()
{
_pnode = _pnode->_next;
return *this;
}
// it++
//对于后置++,我们则应该先记录当前结点指针的指向,然后让结点指针指向后一个结点,最后返回“自增”前的结点指针即可。
Self operator++(int)
{
Self tmp(*this);
_pnode = _pnode->_next;
return tmp;
}
//--it
//对于前置- -,我们应该先让结点指针指向前一个结点,然后再返回“自减”后的结点指针即可。
Self& operator--()
{
_pnode = _pnode->_prev;
return *this;
}
//it--
//对于后置- -,我们则应该先记录当前结点指针的指向,然后让结点指针指向前一个结点,最后返回“自减”前的结点指针即可。
Self operator--(int)
{
Self tmp(*this);
_pnode = _pnode->_prev;
return tmp;
}
//判断这两个迭代器当中的结点指针的指向是否不同即可。
bool operator!=(const Self& it) const
{
return _pnode != it._pnode;
}
//当使用==运算符比较两个迭代器时,
//我们实际上想知道的是这两个迭代器是否是同一个位置的迭代器,也就是说,我们判断这两个迭代器当中的结点指针的指向是否相同即可。
bool operator==(const Self& it) const
{
return _pnode == it._pnode;
}
};
The mock implementation of list
no-argument constructor
list is a leading bidirectional circular linked list. When constructing a list object, directly apply for a head node, and let its predecessor pointer and successor pointer both point to itself.
//构造函数
list()
{
_head = new node(T()); //申请一个头结点,给一个缺省值,调用结点类的默认构造
_head->_next = _head;//头结点的后继指针指向自己
_head->_prev = _head; //头结点的前驱指针指向自己
_size = 0;//结点个数为0
}
Construct with parameters
list also provides an iterative interval structure, first create a head node, then loop through and insert to the back in turn
template <class InputIterator>
list(InputIterator first, InputIterator last)
{
_head = new node(T()); //申请一个头结点,给一个缺省值,调用结点类的默认构造
_head->_next = _head;//头结点的后继指针指向自己
_head->_prev = _head; //头结点的前驱指针指向自己
while (first != last)
{
push_back(*first);
++first;
}
}
copy constructor
The copy constructor is to copy and construct an object according to the given list container. For the copy constructor, we first apply for a head node, and let its predecessor pointer and successor pointer point to itself, and then insert the data in the given container into the back of the newly constructed container one by one by traversal. .
//拷贝构造函数
list(const list<T>& lt)
{
_head = new node(T()); //申请一个头结点,给一个缺省值,调用结点类的默认构造
_head->_next = _head; //头结点的后继指针指向自己
_head->_prev = _head; //头结点的前驱指针指向自己
for (const auto& e : lt)
{
push_back(e); //将容器lt当中的数据一个个尾插到新构造的容器后面
}
}
assignment operator overloaded function
For the overloading of the assignment operator, here are two ways of writing:
Writing method 1: traditional writing method
This is a relatively easy-to-understand writing method. First call the clear function to clear the original container, and then insert the data in the container lt into the empty container one by one by traversal.
//传统写法
list<T>& operator=(const list<T>& lt)
{
if (this != <) //避免自己给自己赋值
{
clear(); //清空容器
for (const auto& e : lt)
{
push_back(e); //将容器lt当中的数据一个个尾插到链表后面
}
}
return *this; //支持连续赋值
}
Writing method 2: Modern writing method
The amount of code in the modern writing method is small. First, the compiler mechanism is used to deliberately not use the reference receiving parameter, and the compiler automatically calls the copy constructor of the list to construct a list object, and then calls the swap function to replace the original container with the The list object can be exchanged.
//现代写法
list<T>& operator=(list<T> lt) //编译器接收右值的时候自动调用其拷贝构造函数
{
swap(lt); //交换这两个对象
return *this; //支持连续赋值
}
Doing so is equivalent to handing over the data that should be cleaned up by clear to the container lt through the exchange function, and when the assignment operator overloaded function call ends, the container lt will be automatically destroyed and its destructor will be called to clean up.
destructor
When destructing the object, first call the clear function to clear the data in the container, then release the head node, and finally set the head pointer to empty
//析构函数
~list()
{
clear(); //清理容器
delete _head; //释放头结点
_head = nullptr; //头指针置空
}
begin and end
First of all, we should be clear: the begin function returns the iterator of the first valid data, and the end function returns the iterator of the next position of the last valid data.
For list, which is a headed bidirectional circular linked list, the iterator of the first valid data is the iterator constructed using the address of the node after the head node, and the iterator of the next position of the last valid data is An iterator constructed using the address of the head node. (The next node of the last node is the head node)
iterator begin()
{
//返回使用头结点后一个结点的地址构造出来的普通迭代器
return iterator(_head->_next);
}
iterator end()
{
//返回使用头结点的地址构造出来的普通迭代器
return iterator(_head);
}
Above are the begin and end functions of ordinary iterators, which are readable and writable. We also need to implement const iterators, which only allow read operations
const_iterator begin() const
{
//返回使用头结点后一个结点的地址构造出来的const迭代器
return const_iterator(_head->_next);
}
const_iterator end() const
{
//返回使用头结点的地址构造出来的普通const迭代器
return const_iterator(_head);
}
insert
The insert function can insert a new node before the given iterator.
First get the node pointer cur at this position according to the given iterator, then find the node pointer prev at the previous position through the cur pointer, then construct a node to be inserted according to the given data x, and then create a new node and The two-way relationship between cur, and finally establish the two-way relationship between the new node and prev.
iterator insert(iterator pos, const T& x)
{
//创建一个新节点
node* newnode = new node(x);//根据所给数据x构造一个待插入结点
node* cur = pos._pnode;//迭代器pos处的结点指针
node* prev = cur->_prev;//迭代器pos前一个位置的结点指针
// prev newnode cur
//建立newnode与prev之间的双向关系
prev->_next = newnode;
newnode->_prev = prev;
//建立newnode与cur之间的双向关系
newnode->_next = cur;
cur->_prev = newnode;
++_size;
return iterator(newnode);
}
erase
The erase function can delete the node at the given iterator position.
First obtain the node pointer cur at the position according to the given iterator, then find the node pointer prev at the previous position and the node pointer next at the next position through the cur pointer, then release the cur node, and finally create prev The two-way relationship between next and next is enough.
iterator erase(iterator pos)
{
assert(pos != end());//删除的结点不能是头结点
node* prev = pos._pnode->_prev;//迭代器pos前一个位置的结点指针
node* next = pos._pnode->_next;//迭代器pos后一个位置的结点指针
prev->_next = next;
next->_prev = prev;
delete pos._pnode;
--_size;
return iterator(next);//返回所给迭代器pos的下一个迭代器
}
List iterator invalidation problem
- insert, the iterator is not invalidated
- Earse fails (because after deleting the pos node, the space pointed to by pos is no longer there, so it is necessary to return the next node of the pos node)
push_back和pop_back
The push_back and pop_back functions are used for tail insertion and tail deletion of the list respectively. When the insert and erase functions have been implemented, we can implement the push_back and pop_back functions by multiplexing functions.
The push_back function is to insert a node before the head node, and pop_back is to delete the previous node of the head node.
void push_back(const T& x)
{
//规范写法
//node* newnode = new node(x);
//node* tail = _head->_prev;
_head tail newnode
//tail->_next = newnode;
//newnode->_prev = tail;
//newnode->_next = _head;
//_head->_prev = newnode;
//复用insert
insert(end(), x);
}
void pop_back()
{
erase(--end());//删除头结点的前一个结点
}
push_front和pop_front
Of course, the push_front and pop_front functions used for head insertion and head deletion can also be implemented by multiplexing the insert and erase functions.
The push_front function is to insert a node before the first valid node, and pop_front is to delete the first valid node.
//头插
void push_front(const T& x)
{
insert(begin(), x); //在第一个有效结点前插入结点
}
//头删
void pop_front()
{
erase(begin()); //删除第一个有效结点
}
clear
The clear function is used to clear the container. We delete the nodes one by one by traversing, and only keep the head node.
void clear()
{
iterator it = begin();
while (it != end())
{
it = erase(it);
}
}
empty
The empty function is used to judge whether the container is empty, because there is a _size in the member variable of our list, so we only need to judge whether the _size is 0
bool empty() const
{
return _size == 0;
}
size
The size function is used to count the number of data in the container, we can directly return _size
size_t size() const
{
return _size;
}
swap
The swap function is used to exchange two containers. In fact, only the head pointer of the linked list is stored in the list container. We can exchange the head pointers of the two containers.
void swap(list<T>& lt)
{
std::swap(_head, lt._head); //交换两个容器当中的头指针即可
std::swap(_size, lt._size);
}
Two, the comparison between list and vector
Advantages and disadvantages of vector:
Advantages:
1. Support random access of subscripts;
2. The efficiency of tail insertion and tail deletion is high (of course, the tail insertion will be slower during the expansion);
3. The CPU cache hit is high (data is loaded from the cache to the CPU, and a continuous piece of data will be loaded, and the vector has a high cache hit because of its continuous structure).
Disadvantages
1. Inserting and deleting data at the head or in the middle is inefficient (O(N))
2. Expansion is expensive, and there is still a certain waste of space
Vector iterator invalidation problem:
Insert/erase are invalid. (If the insert and erase parameters of the string are iterators, they will also fail, but most of the interfaces use subscripts to pass parameters, regardless of the invalidation problem. Only a few interfaces use iterators to pass parameters, and iterator failures need to be paid attention to)
listAdvantages and disadvantages
Advantages
1. Apply for release on demand, no need to expand;
2. Insertion and deletion at any position takes O(1); (Here we are talking about insertion and deletion, do not add the search time)
Disadvantage
1. Does not support random access of subscripts
2. Low CPU cache hit rate;
List iterator invalidation problem:
insert does not fail, erase fails.
3. Summary: Simulate the overall code of list implementation
namespace wyt
{
template<class T>
struct list_node
{
list_node<T>* _next;
list_node<T>* _prev;
T _data;
list_node(const T& val = T())
:_next(nullptr)
, _prev(nullptr)
, _data(val)
{
}
};
// 同一个类模板实例化出的两个类型
// typedef __list_iterator<T, T&, T*> iterator;
// typedef __list_iterator<T, const T&, const T*> const_iterator;
template<class T, class Ref, class Ptr>
struct __list_iterator
{
typedef list_node<T> node;
typedef __list_iterator<T, Ref, Ptr> Self;
node* _pnode;
__list_iterator(node* p)
:_pnode(p)
{
}
Ptr operator->()
{
return &_pnode->_data;
}
// iterator it
// *it
// ++it;
Ref operator*()
{
return _pnode->_data;
}
// const iterator cit
// *cit
// ++cit 这样的话,可以解引用,但是不能++
/*const T& operator*() const
{
return _pnode->_data;
}*/
// ++it
Self& operator++()
{
_pnode = _pnode->_next;
return *this;
}
// it++
Self operator++(int)
{
Self tmp(*this);
_pnode = _pnode->_next;
return tmp;
}
Self& operator--()
{
_pnode = _pnode->_prev;
return *this;
}
Self operator--(int)
{
Self tmp(*this);
_pnode = _pnode->_prev;
return tmp;
}
bool operator!=(const Self& it) const
{
return _pnode != it._pnode;
}
bool operator==(const Self& it) const
{
return _pnode == it._pnode;
}
};
// 跟普通迭代器的区别:遍历,不能用*it修改数据
/*template<class T>
struct __list_const_iterator
{
typedef list_node<T> node;
node* _pnode;
__list_const_iterator(node* p)
:_pnode(p)
{}
const T& operator*()
{
return _pnode->_data;
}
__list_const_iterator<T>& operator++()
{
_pnode = _pnode->_next;
return *this;
}
__list_const_iterator<T>& operator--()
{
_pnode = _pnode->_prev;
return *this;
}
bool operator!=(const __list_const_iterator<T>& it)
{
return _pnode != it._pnode;
}
};*/
//vector<int>
//vector<string>
//vector<vector<int>>
// 类名 类型
// 普通类 类名 等价于 类型
// 类模板 类名 不等价于 类型
// 如:list模板 类名list 类型list<T>
// 类模板里面可以用类名代表类型,但是建议不要那么用
template<class T>
class list
{
typedef list_node<T> node;
public:
typedef __list_iterator<T, T&, T*> iterator;
//typedef __list_const_iterator<T> const_iterator;
typedef __list_iterator<T, const T&, const T*> const_iterator;
const_iterator begin() const
{
return const_iterator(_head->_next);
}
const_iterator end() const
{
return const_iterator(_head);
}
iterator begin()
{
return iterator(_head->_next);
}
iterator end()
{
//iterator it(_head);
//return it;
return iterator(_head);
}
void empty_initialize()
{
_head = new node(T());
_head->_next = _head;
_head->_prev = _head;
_size = 0;
}
list()
{
empty_initialize();
}
lt2(lt1)
//list(const list<T>& lt)
//{
// empty_initialize();
// for (const auto& e : lt)
// {
// push_back(e);
// }
//}
lt1 = lt3
//list<T>& operator=(const list<T>& lt)
//{
// if (this != <)
// {
// clear();
// for (const auto& e : lt)
// {
// push_back(e);
// }
// }
// return *this;
//}
template <class InputIterator>
list(InputIterator first, InputIterator last)
{
empty_initialize();
while (first != last)
{
push_back(*first);
++first;
}
}
void swap(list<T>& lt)
{
std::swap(_head, lt._head);
std::swap(_size, lt._size);
}
// 现在写法
// lt2(lt1)
list(const list<T>& lt)
//list(const list& lt) // 不建议
{
empty_initialize();
list<T> tmp(lt.begin(), lt.end());
swap(tmp);
}
// lt3 = lt1
list<T>& operator=(list<T> lt)
//list& operator=(list lt) // 不建议
{
swap(lt);
return *this;
}
size_t size() const
{
return _size;
}
bool empty() const
{
return _size == 0;
}
~list()
{
clear();
delete _head;
_head = nullptr;
}
void clear()
{
iterator it = begin();
while (it != end())
{
it = erase(it);
}
}
void push_back(const T& x)
{
//node* newnode = new node(x);
//node* tail = _head->_prev;
_head tail newnode
//tail->_next = newnode;
//newnode->_prev = tail;
//newnode->_next = _head;
//_head->_prev = newnode;
insert(end(), x);
}
void push_front(const T& x)
{
insert(begin(), x);
}
void pop_front()
{
erase(begin());
}
void pop_back()
{
erase(--end());
}
iterator insert(iterator pos, const T& x)
{
node* newnode = new node(x);
node* cur = pos._pnode;
node* prev = cur->_prev;
// prev newnode cur
prev->_next = newnode;
newnode->_prev = prev;
newnode->_next = cur;
cur->_prev = newnode;
++_size;
return iterator(newnode);
}
iterator erase(iterator pos)
{
assert(pos != end());
node* prev = pos._pnode->_prev;
node* next = pos._pnode->_next;
prev->_next = next;
next->_prev = prev;
delete pos._pnode;
--_size;
return iterator(next);
}
private:
node* _head;
size_t _size;
};
}