Crawling static webpages is the most basic crawler technology. In fact, it is to obtain the source code of webpages. The principle is to imitate the process of users accessing webpages through browsers, send requests to web servers, receive requests and respond to them, and finally return source code process.
This mainly uses the Requests library, taking Baidu as an example: receiving the response information returned by the Baidu server
import requests
url = 'https://www.baidu.com/'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:98.0) Gecko/20100101 Firefox/98.0'
}
response = requests.get(url,headers=headers)
response.encoding = 'utf-8'
print(response.status_code)Among them, url is the URL, and headers are request headers, which are anti-crawler measures to prevent some servers from maliciously grabbing web page information by web crawlers; response is to construct a request based on url, send a GET request, and receive the response information returned by the server .
Try to climb Baidu's logo
import requests
baidu_logo_url = 'https://www.baidu.com/img/PCtm_d9c8750bed0b3c7d089fa7d55720d6cf.png'
response = requests.get(baidu_logo_url)
with open ('baidu_logo.png','wb') as file:
file.write(response.content)#获取图片的二进制数据
Climb the logo of csdn
import requests
csdn_logo_url = 'https://img-home.csdnimg.cn/images/20201124032511.png'
response = requests.get(csdn_logo_url)
with open ('csdn_logo.png','wb') as file:
file.write(response.content)try to crawl the web
import requests
def load_page(url):
'''
根据url发送请求,获取服务器返回的响应
:param url: 待抓取的url
:return:
'''
headers = {"user-Agent":"Mozilla/5.0(compatible;MSIE 9.0;"
"Windows NT 6.1;Trident / 5.0;"}
#发送GET请求,接收服务器返回的响应
response = requests.get(url,headers=headers)
return response.text
def save_file(html,filename):
'''
将抓取的网页数据写入本地文件
:param html: 服务器返回的相应内容
:param filename:
:return:
'''
print('正在保存',filename)
with open(filename,'wb')as file:
file.write(html)
def scrape_forum(begin_page,end_page):
'''
控制网络爬虫抓取网页数据的流程
:param begin_page: 起始页码
:param end_page: 结束页码
:return:
'''
for page in range(begin_page,end_page+1):
#组合所有页面的完整URL
url = f'https://ssr1.scrape.center/page/{page}'
file_name = "第"+str(page)+"页.html"
html = load_page(url)
save_file(html,file_name)
scrape_forum(1,5)
E:\ProgramFiles\anaconda\python.exe E:/python learning/reptile learning/2022.9.22.py
Traceback (most recent call last):
File "E:\python learning\reptile learning\2022.9.22.py", line 82, in <module>
scrape_forum(1,5)
File "E:\python learning\crawler learning\2022.9.22.py", line 80, in scrape_forum
save_file(html,file_name)
File "E:\python learning\ Crawler Learning\2022.9.22.py", line 65, in save_file
file.write(html)
TypeError: a bytes-like object is required, not 'str'
is saving page 1.htmlProcess ended with exit code 1
An error occurred, why did it report an error? According to my observation, I tried to crawl 5 pages of content at a time. It was because of crawling 5 pages of content that some of them had grammatical errors. Then I changed my mind and crawled 1 page first. Try it out:
import requests
def load_page(url):
'''
根据url发送请求,获取服务器返回的响应
:param url: 待抓取的url
:return:
'''
headers = {"user-Agent":"Mozilla/5.0(compatible;MSIE 9.0;"
"Windows NT 6.1;Trident / 5.0;"}
#发送GET请求,接收服务器返回的响应
print('正在发送GET请求')
response = requests.get(url,headers=headers)
print('GET请求发送成功')
return response.text
def save_file(html,filename):
print('开始保存文件')
'''
将抓取的网页数据写入本地文件
:param html: 服务器返回的相应内容
:param filename:
:return:
'''
print('正在保存',filename)
with open(filename+'.html','w',encoding='utf-8')as file:
file.write(html)
print(filename,'保存成功!')
def forum(url):
'''
控制网络爬虫抓取网页数据的流程
:param begin_page: 起始页码
:param end_page: 结束页码
:return:
'''
file_name = ''
for i in range(8,len(url)):
if url[i]=='/':
break
file_name += url[i]
html = load_page(url)
save_file(html,file_name)
url = input('输入网址')
forum(url)
This time it was very smooth to crawl out the html file.
In terms of data acquisition, I mainly use the XPath module. Through the chrome browser and the installed xpath plug-in, I can obtain the address of the required file, and then I can obtain the required data from the web page.
To learn Xpath, I mainly use csdn to learn, and of course there is a book
Example: Get the name of a movie on a page of Scrape
# 导入urllib与lxml库
import urllib.request
from lxml import etree
# 爬取网页的网址
url = 'https://ssr1.scrape.center/'
# 请求网页获取网页源码
response=urllib.request.urlopen(url=url)
html=response.read().decode("utf-8")
# 将文本转化为HTML元素树
parse = etree.HTML(html)
# 写入xpath路径
for i in range(1,11):
item_list = parse.xpath('//*[@id="index"]/div/div/div['+str(i)+']/div/div/div[2]/a/h2/text()')
print(item_list)Get the names of movies on all pages of the website and save them in excel
import urllib.request
from lxml import etree
import csv
# 创建文件对象
f = open('csv_file.csv', 'w', encoding='utf-8')
# 构建csv写入对象
csv_write = csv.writer(f)
for j in range(1,11):
# 爬取网页的网址
url = 'https://ssr1.scrape.center/page/'+str(j)
# 请求网页获取网页源码
response=urllib.request.urlopen(url=url)
html=response.read().decode("utf-8")
# 将文本转化为HTML元素树
parse = etree.HTML(html)
# 写入xpath路径
for i in range(1,11):
item_list = parse.xpath('//*[@id="index"]/div/div/div['+str(i)+']/div/div/div[2]/a/h2/text()')
csv_write.writerow(item_list)
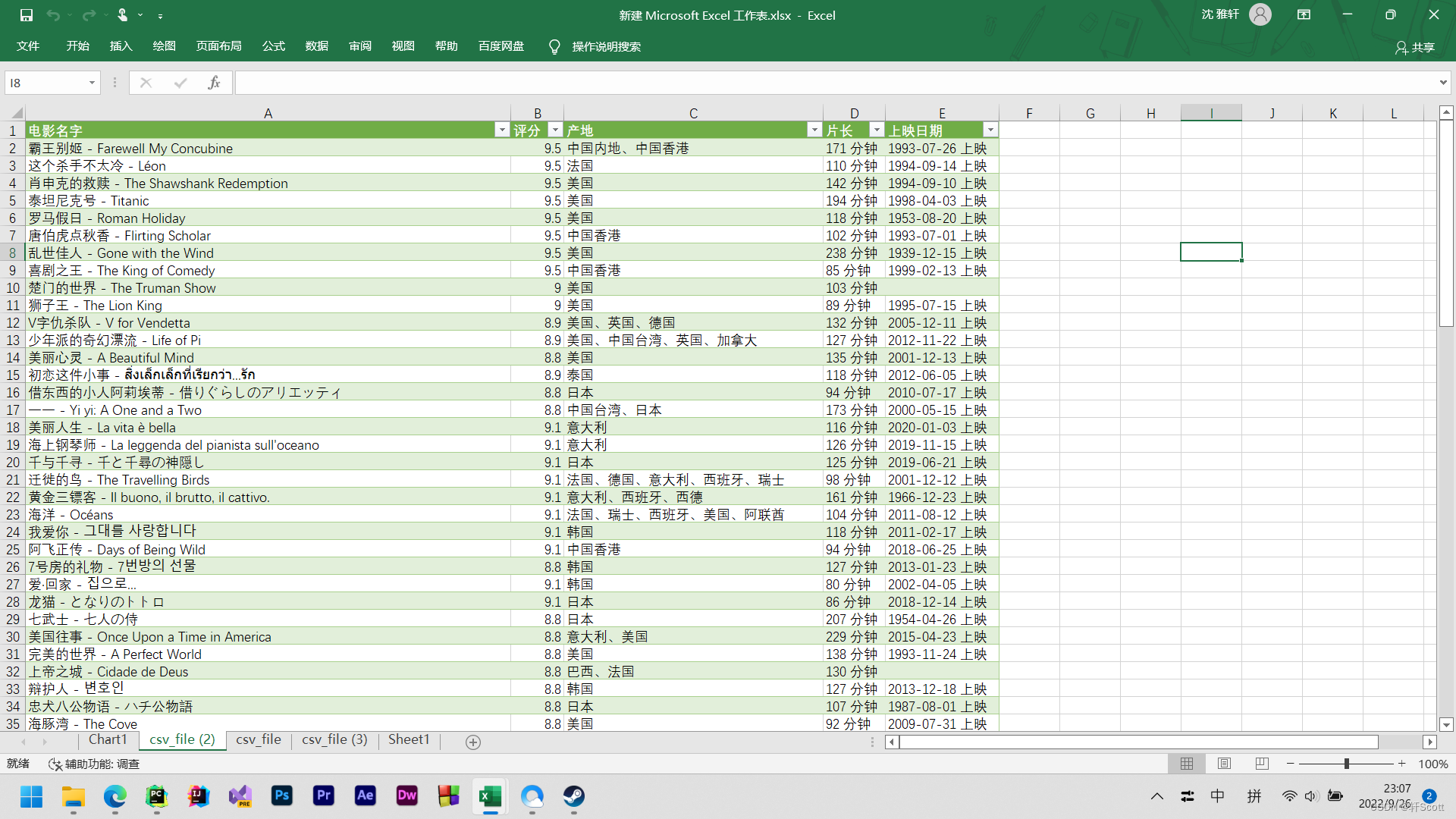
print(item_list)Then we process it again, crawl the movie name, release date, film length, country and other data and organize them into the table
import urllib.request
from lxml import etree
import csv
f = open('csv_file.csv', 'w', encoding='utf-8')
csv_write = csv.writer(f)
item_list = []
csv_write.writerow(['电影名字','评分','产地','片长','上映日期'])
for j in range(1,11):
url = 'https://ssr1.scrape.center/page/'+str(j)
response=urllib.request.urlopen(url=url)
html=response.read().decode("utf-8")
parse = etree.HTML(html,parser = etree.HTMLParser(encoding='utf-8'))
for i in range(1,11):
movie_name = parse.xpath('//*[@id="index"]/div/div/div['+str(i)+']/div/div/div[2]/a/h2/text()')
fraction = parse.xpath('//*[@id="index"]/div[1]/div[1]/div['+str(i)+']/div/div/div[3]/p[1]/text()')
country = parse.xpath('//*[@id="index"]/div[1]/div[1]/div['+str(i)+']/div/div/div[2]/div[2]/span[1]/text()')
minute = parse.xpath('//*[@id="index"]/div[1]/div[1]/div['+str(i)+']/div/div/div[2]/div[2]/span[3]/text()')
time = parse.xpath('//*[@id="index"]/div[1]/div[1]/div['+str(i)+']/div/div/div[2]/div[3]/span/text()')
fra = list(fraction)
item_list.append(list(movie_name)[0][:])
item_list.append(fra[0][17:])
item_list.append(list(country)[0][:])
item_list.append(list(minute)[0][:])
a = []
if list(time)==a:
pass
else:
item_list.append(list(time)[0][:])
csv_write.writerow(item_list)
print(item_list)
item_list.clear()