Table of contents
A Memory Abstraction: Address Space
Storage management using bitmaps
Storage management using linked lists
Optimal Page Replacement Algorithm
The page replacement algorithm has not been used recently
FIFO page replacement algorithm
Least Recently Used Page Replacement Algorithm
Summary of Page Replacement Algorithms
Design Issues in Paging Systems
Local vs. Global Allocation Strategies
Memory (Random Access Memory, RAM) is an important resource in a computer that needs to be carefully managed. No matter how big the memory is, the program can fill it up. After years of exploration, we have the concept of memory hierarchy , that is, the computer has several MiB fast, expensive and volatile Cache, several GiB speed and moderately priced volatile memory, and several TiB fast , cheap but non-volatile disk storage. The part of the computer that manages the hierarchical memory hierarchy is called the memory manager . Its job is to manage memory efficiently, keeping track of which memory is in use and which is free, allocating memory to a process when it needs it, and freeing memory when the process is done using it.
no memory abstraction
The simplest memory abstraction is to use no abstraction. Early mainframes (before the 1960s), minicomputers (before the 1970s), and personal computers (before the 1980s) had no memory abstraction, and each program directly accessed physical memory. In this model, the system only runs a process.
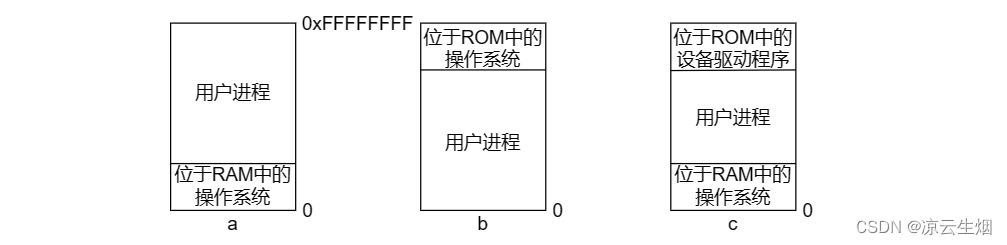
Although physical memory is used directly, there are different models, and the figure below shows three models. a model with the operating system at the bottom of RAM, used in mainframes and minicomputers; b model with the operating system in ROM (read-only memory) at the top of memory, used in handheld or embedded system; in the c model, device drivers are located in ROM at the top, while the rest of the operating system is located at the bottom of RAM. This scheme was used in early personal computers (such as computers running MS-DOS), in ROM. The system part is called BIOS (Basic Input Output System, Basic Input Output System). Models a and c When a user program makes an error, it may destroy the operating system, causing catastrophic consequences.
The way to achieve parallelism in a system with no memory abstraction is to use multithreaded programming. Since threads were introduced with the assumption that all threads in a process see the same memory image, parallelism is not a problem. While the approach works, it's not widely used because people generally want to be able to run unrelated programs at the same time, which the threading abstraction doesn't provide. Therefore, a system without memory abstraction is unlikely to provide the function of thread abstraction.
With concurrent processes using the memoryless abstraction, it is possible to load other processes from disk into RAM after one process has been running for some time. But since both processes refer to the absolute address, it may refer to the private address of the first process, causing the process to crash. The IBM 360's solution to the above problem is to use static relocation to modify the second process when it is loaded into memory.
A Memory Abstraction: Address Space
When the physical address is exposed to the process, it will bring the following serious problems:
- If user programs could address every byte of memory, they could easily (intentionally or accidentally) corrupt the operating system, slowly bringing the whole system to a halt unless special hardware protection (IBM 360's key lock mode)
- Using this model, it is very difficult to run multiple programs at the same time
The concept of address space
To keep multiple applications in memory at the same time without affecting each other, two problems need to be solved: protection and relocation .
For the protection solution, a method has been used on the IBM 360: mark the memory block with a protection key, and compare the key of the executing process with the protection key of the memory word it accesses. However, this approach by itself does not solve the latter problem, which can be solved by relocating the program when it is loaded, but this is a slow and complicated solution.
A better approach is to create a new memory abstraction: the address space. Just as the concept of a process creates an abstract kind of CPU for running programs, an address space creates an abstract kind of memory for programs. An address space is a set of address combinations that a process can use to address memory. Each process has its own address space, and this address space is independent of the address spaces of other processes. Taking the domain name as an example, the collection of network domain names ending with .com is a kind of address space. This address space is composed of all strings containing 2 to 63 characters followed by .com . The characters that make up these strings can be are letters, numbers, and hyphens. The more difficult thing is to give each process its own unique address space, so that the physical address corresponding to address 28 in one program is different from the physical address corresponding to address 28 in another program.
A simple way is to use dynamic relocation , which simply maps the address space of each process to a different part of physical memory. This method configures two special hardware registers, the base register and the limit register , for the CPU . When using base registers and limit registers, programs are loaded into contiguous free locations in memory without relocation during loading. When the program starts to run, the starting physical address of the program is loaded into the base address register, and the length of the program is loaded into the limit register. Every time a process accesses memory, fetches an instruction, reads or writes a word of data, the CPU hardware automatically adds the base address value to the address value issued by the process before sending the address to memory. At the same time, check whether the address provided by the program is greater than or equal to the value in the limit register. If the accessed address exceeds the limit, an error will be generated and the access will be terminated.
switching technology
If the computer's physical memory is large enough to hold all the processes, then more or less all the solutions mentioned before are feasible. In practice, however, the sum of the amount of RAM required by all processes is often far greater than what the memory can support. There are two general methods for dealing with memory overload. The simplest strategy is swapping , which is to load a process into memory completely, let the process run for a while, and then save it back to disk. Idle processes are mostly stored on disk, so when they are not running they will not take up memory. Another strategy is virtual memory , which enables programs to run even with only part of them loaded into memory.
A switching system is shown in the figure below. At the beginning, only process A exists in the memory, and then processes B and C are created, and the memory image of D is loaded after A is swapped to disk, then B is called out, and finally A is called in again. Since the location of A changes, its address is relocated when it is swapped in through software or through hardware during program execution.

Swapping creates multiple free areas (holes, or holes ) in memory . By moving all processes down as far as possible, it is possible to merge these small holes into a large block. This technique is called memory compaction . ). Usually this is not done because it would consume a lot of CPU time.
How much memory should be allocated at process creation is an important issue. If a process is created with a fixed size and never changes, the operating system allocates exactly that size. But if the process data segment can grow (most programming languages allow dynamic allocation of memory from the heap), then there will be problems when the process grows. Assuming that most processes grow while they are running, to reduce the overhead of process swapping and moving due to insufficient memory areas, some extra memory can be allocated for processes when they are swapped in or moved. When a process is swapped out to disk, only the memory contents actually used by the process are swapped. If the process has two segments that can grow (the data segment used by the heap and the stack segment that stores local variables and return addresses), a part of the area can be reserved. The stack segment occupies the top of the process memory and grows downward, and the data segment occupies The program bottoms and grows upwards, with memory reserved for free memory in between. As shown below.

free memory management
When memory is allocated dynamically, the operating system must manage it. Generally speaking, there are two management methods : bitmap and free area linked list .
Storage management using bitmaps
In this method, memory may be divided into allocation units as small as a few words or as large as thousands of words, and each allocation unit corresponds to a bit in the bitmap.
The size of the allocation unit is an important design factor: the smaller the allocation unit, the larger the bitmap. However even with only 4 byte sized allocation units, 32 bits of memory require 1 bit in the bitmap, so the bitmap takes up as much memory as possible. If you choose a larger allocation unit, if the size of the process is not an integer multiple of the allocation unit, it will easily waste memory.
Storage management using linked lists
Maintain a linked list that records allocated memory segments and free memory segments, where each node contains domains: free area (H) or process (P) indicator, start address, length, and pointer to the next node. The node representing the terminated process in the process table usually contains a pointer to the node corresponding to its segment linked list, so it is more convenient to use a doubly linked list for the segment linked list, and it is easy to find the previous node and check whether it can be merged.
There are several algorithms that can be used to allocate memory for process swapping when storing processes and free areas in a linked list using address order. Assume the memory manager knows how much memory a process needs.
- The simplest method is the first fit algorithm, the memory is searched along the segment linked list until a large enough free area is found
- The next fit (next fit) algorithm is modified by first fit. When a large enough free area is found, next fit will record the current position for the next search.
- The best fit (best fit) algorithm searches the entire linked list to find the smallest free area that can accommodate the process. best fit to best match the request to available free space, rather than splitting a large free space that may be used later. But unfortunately, best fit will generate a lot of useless small free areas, resulting in a waste of memory
- The worst fit (worst fit) algorithm is an improvement of the best fit, which always allocates the largest free area to keep the new free area large for future use. But this is not a good way
If the free area linked list is implemented separately from the process linked list, the speed of memory allocation can be increased, but the speed of memory release will be slower. But you can sort the free area from small to large to improve the performance of best fit, but next fit will become meaningless. Another optimization is that instead of using the free area linked list, the first word of each free area stores the size of the free area, and the second word points to the next free area, which will greatly reduce the memory usage of the storage manager.
The quick fit algorithm maintains separate linked lists for those commonly sized free regions. For example, in an N-item table, the first item is a pointer to the head of the free area linked list with a size of 4KB, the second item is a pointer to the head of the free area linked list with a size of 8KB, and so on. The 21 KB free area can be placed in a special free area linked list with a relatively special size. This algorithm is very fast when searching for a free area of a specified size, but it is very time-consuming to find and merge adjacent free areas when a process is terminated or swapped out. If not merged, the memory will quickly split into a large number of useless small free areas.
Virtual Memory
Software's demand for memory capacity grows extremely fast. The programs that need to be run are often too large for RAM to accommodate, and the system must support multiple programs to run at the same time. Even if RAM can meet the memory demand of a software, the total demand must exceed the RAM size. The solution adopted in the 1960s was to divide the program into many pieces, called overlays . Overlay blocks are stored on disk and are dynamically swapped in and out by the operating system as needed. Although the system can automatically switch in and out, it still requires the programmer to actively divide the program into multiple segments. Splitting a large project into small, modular pieces is time-consuming, tedious, and error-prone. Later, a method that can be automatically performed by the system is proposed, which is called virtual memory (virtual memory).
The basic idea of VM is: each process has its own address space, which is divided into multiple blocks, and each block is called a page (page) or a page. Pages have a continuous address range and are mapped to physical memory, but not all pages must be in memory to run the program. When the program refers to a part of the address space in the physical memory, the hardware immediately executes the necessary mapping; while referring to the address space not in the physical memory, the operating system is responsible for loading the missing part into the physical memory and re-executing the failed instruction.
paging
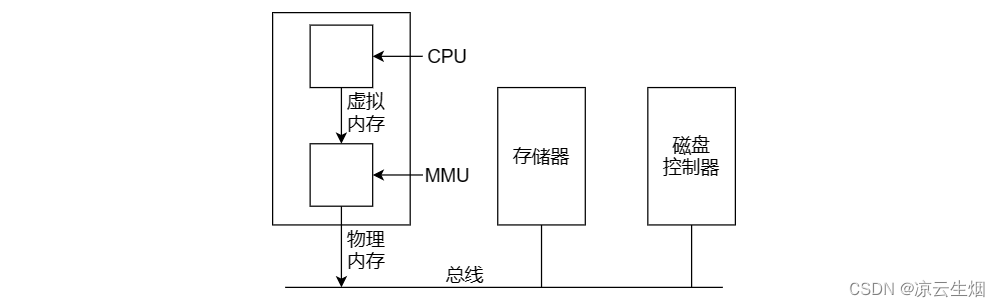
Most VM systems use a technique called paging . Addresses can be generated by indexing, base registers, segment registers, or other means. These addresses generated by the program are called virtual addresses (virtual address), and they form a virtual address space (virtual address space). On a computer without a VM, the system sends the virtual address directly to the memory bus, and read and write operations use physical memory words with the same address; in the case of a VM, the virtual address is sent to the Memory Management Unit ( MMU ) ), the MMU translates virtual addresses into physical addresses.

The address of virtual space is divided into several units of page according to a fixed size, and the corresponding unit in physical memory is called page frame, and the size of page and frame is usually the same. The size of the page can range from 512B to 1GB. The exchange of RAM and disk is always exchanged in units of the entire page. On some processors, the mixed use and matching of pages of different sizes is supported according to the way the operating system thinks appropriate .
Since virtual memory is larger than physical memory, the hardware will use a flag to record whether the page exists in RAM. When the MMU notices that the accessed virtual memory does not exist in RAM, it will trap the CPU into the kernel. This trap is called a page fault . The operating system swaps a page out of RAM according to a certain strategy, and swaps the page that needs to be accessed into the page frame, modifies the mapping relationship and restarts the instruction that caused the interrupt.
page table
Page tables are used to index between virtual addresses and physical memory to derive the page frame number to apply to that virtual page. The virtual address is divided into the virtual page number of the high part and the offset of the low part. For a 16-bit address and a 4KB page, the high four bits can specify the page in the 16 virtual pages, and the low 12 bits can determine the page in the page. byte offset. Find the page frame number from the page table entry, and then splicing the page frame number to the high-order end of the offset to replace the virtual page number to form the physical address sent to the memory.

The result of a page table entry is closely machine dependent, but the information stored is roughly the same, an example is shown in the figure below. 保护 The (protection) field indicates what type of access the page allows. The simplest protection has only one bit, and its value is generally 0 (readable and writable) and 1 (read-only); more complicated cases are three-digit protection, each corresponding to Read, write, execute flags. 修改 The (modified) field and 访问 (referenced) field record the usage of the page, and the modified is automatically set by the hardware when the page is written. This field is very useful when the operating system reallocates the page frame: if the page is modified (that is, dirty memory) must be written back to disk, and pages that have not been modified can be discarded directly. modified is also known as dirty bit (dirty bit). Regardless of the read-write system, referenced will be set when the page is accessed, which will help the management strategy eliminate useless pages when a page fault occurs in the system. The last bit is a field to disable the cache and is important for pages that are mapped to device registers rather than RAM.

Speed up the paging process
In any paging system, there are two issues to consider:
- The mapping of virtual addresses to physical addresses must be very fast
- If the virtual address space is large, the page table will be large
The easiest way is to use a complete hardware page table without accessing memory, but it is expensive and needs to replace the entire page table when switching processes. Another method is to use RAM to store the page table, only use the page table register to point to the header of the memory page table, and only need to load the new header address when the process is switched, but each instruction needs to access RAM to read the corresponding page frame.
Most programs always do a lot of access to a small number of pages, not the other way around. So it is possible to set up a small hardware device that maps virtual addresses directly to physical addresses without accessing page tables. This kind of device is called translation lookaside buffer (TLB), or associative memory (associate memory) or fast table . The TLB is usually placed directly in the MMU and contains a small number of entries. Each entry records information about a page, and these entries are similar to those in the page table.
When a virtual address is input into the MMU, the hardware first matches the virtual page number with the entry in the TLB in parallel to determine whether it exists. If there is a valid match and the operation does not violate the protection, the page frame number will be output directly without accessing the page table; when the protection operation is violated, it is the same as the illegal operation on the page table; when the virtual page number is no longer in the TLB , the query of the page table will be performed, and the page table will be replaced with an entry.
When implementing a TLB in software, invalidation needs to be dealt with. When a page is accessed in memory but not in the TLB, it is called a soft miss . At this time, only the TLB needs to be updated without disk I/O. If it is not in the memory itself, a hard failure will occur , and the page needs to be loaded from the disk at this time.
Page tables for large memory
Using multi-level page tables, you can easily split and store large-memory page tables to avoid keeping all page tables in memory. The more stages of multi-level page tables, the stronger the flexibility.
Inverted page table (inverted page table) is a solution to solve the growing multi-level page table level, mainly used in PowerPC, the page frame in the physical memory corresponds to a table entry instead of a virtual page number. The table entry records which process and virtual page pair are located in the page frame. Although the space is greatly reduced, it makes the translation of virtual addresses to physical addresses difficult.
Page Replacement Algorithm
When a page fault occurs, the operating system must select a page in memory and swap it out to make room for the page that is about to be loaded. If the page to be swapped out has been modified during memory residence, it must be written back to disk to update the copy of the page on disk; if it has not been modified, it will be directly transferred into the page and overwritten and eliminated.
Optimal Page Replacement Algorithm
Some pages in memory will be used soon, and some will be used after a long time. Each page can be marked with the number of instructions that need to be executed before the page will be accessed. When a page fault occurs page with the largest mark is swapped out.
The only problem with Optimal Replacement Algorithm (OPT) is that it cannot be implemented. When a page fault occurs, the operating system cannot know when each page will be accessed next. The only solution is to run the simulation program for the first time to track page access, and then use the results of the first run to implement the optimal page replacement algorithm.
The page replacement algorithm has not been used recently
In order for the operating system to collect useful statistics, two status bits, modified and referenced, are set for each page, which are set directly by the hardware each time the memory is accessed. If the hardware does not have these two status bits, the page fault interrupt and clock interrupt simulation will be used: when the process is started, all pages will be marked as not in memory; when any page is accessed, a page fault interrupt will be triggered, and the operating system can Set referenced (an internal table implemented by the operating system), modify the page table entry to point to the correct page and set it to read-only mode, and then restart the instruction that caused the page fault; if subsequent modifications to the page cause another fault If the page is interrupted, the operating system sets the modified value of this page and changes it to read-write mode.
A simple replacement algorithm can be constructed using modified and referenced: referenced is periodically cleared to mark a page that has not been accessed recently. The replacement algorithm divides pages into four categories
- has not been accessed, has not been modified
- has not been accessed, has been modified
- accessed, not modified
- has been accessed, has been modified
Not Recently Used (NRU) is easy to understand and can be effectively implemented. When NRU eliminates pages, it may be better to eliminate a second-type page than the first-type page.
FIFO page replacement algorithm
The First -In First-Out (FIFO) algorithm is similar to the implementation of a queue. When a page is swapped in, it is added to the end of the page pair. When a page needs to be swapped out, the page at the head of the queue is swapped out. . FIFO has an obvious problem. When a commonly used page reaches the head of the queue, it will be swapped out of RAM, and a page fault interrupt will be generated shortly thereafter to swap it into RAM. Therefore, pure FIFO algorithms are rarely used.
The second chance (Second Chance) algorithm is an optimization of FIFO to prevent commonly used pages from being swapped out of RAM. The second chance algorithm checks the referenced flag of the first page of the team. If the flag is 0, then this page is the first to enter RAM and is not used, so it should be swapped out of RAM; if it is 1, it will be cleared and the page will be added to the end of the line. The second-chance algorithm looks for a page that has not been accessed in the most recent clock interval. If all pages have been accessed, the algorithm will degenerate into a FIFO algorithm.
Although the second chance is more reasonable, it needs to frequently move pages in the linked list, which reduces efficiency and is not very necessary. A better method is to change the linked list into a circular linked list, which can be changed into a clock (Clock) page replacement algorithm. The clock algorithm is the same as the second chance algorithm, check the referenced flag of the current node page, if the flag is 0, the current node will be removed from the linked list, if it is 1, the flag will be cleared. The clock algorithm no longer needs to implement the movement of the node page in the linked list, it only needs to remove or clear the flag bit.
Least Recently Used Page Replacement Algorithm
Based on observations of software instruction execution, pages that are frequently used in the first few instructions are likely to be used in the next few instructions. Conversely, pages that have not been used for a long time are likely to remain unused for a long period of time in the future. In this way, a method can be implemented to replace the page that has not been used for the longest time when a page fault is interrupted. This strategy is called the least recently used (Least Recently Used, LRU) page replacement algorithm.
While LRU is theoretically possible, it is expensive. In order to fully implement LRU, it is necessary to maintain a linked list of all pages in memory, the most recently used page is at the head of the list, and the least recently used page is at the end of the list. The difficulty is that the entire linked list must be updated every time the memory is accessed. Finding a page in the linked list and deleting it, and then moving it to the head of the list is a very time-consuming operation.
A software solution is called the least frequently used (Least Frequently Used, LFU) algorithm, also known as NFU (Not Frequently Used), this algorithm associates each page with a software counter, the initial value is 0, when When the clock is interrupted, the OS scans all pages and adds the referenced of each page to the corresponding counter. This counter tracks how frequently each page is accessed, and when a page fault occurs, the page with the smallest counter value is replaced.
LFU never forgets anything, but fortunately, LFU can be simulated by a small modification of LFU algorithm: firstly, the counter is shifted right by one bit before referenced is added to the counter, and then referenced is added to the leftmost end of the counter instead of the far right. This algorithm is called the aging algorithm. Aging will cause the LFU to forget the count of some pages so that the counter is 0. These 0 pages will be selected to be swapped out of RAM, thereby simulating the limitation of the memory 最近 .
One problem with LFU simulation is that aging does not know which page was accessed first if two pages were accessed between two clock interrupts. Another problem is that the number of counter bits will limit the strategy for page elimination. If the 8-bit counter can record the situation within 8 clock interrupts, if page1 has been accessed before 9 clock interrupts, and page2 has been accessed before 1000 clock interrupts. Visited, then one of these two pages will be randomly selected to be eliminated when eliminating, because their counters are all 0.
Summary of Page Replacement Algorithms

We can use the ratio of the number of page fault interrupts to the total number of paging times to obtain the page fault rate, which can simply and intuitively measure the quality of a replacement algorithm. Among them, the page calls of the first n empty physical blocks are also counted as page faults.
Assuming that there are 4 allocated physical blocks and pages 4,3,2,1,4,3,5,4,3,2,1,5, take OPT, FIFO, LFU as an example
1.OPT
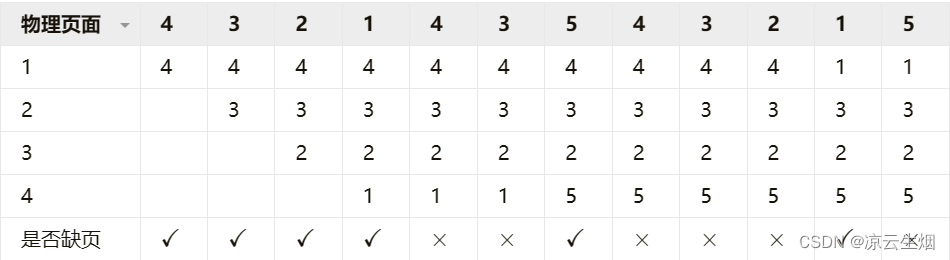
The number of page faults is 6, the total number of visits is 12, and the page fault rate
2.FIFO
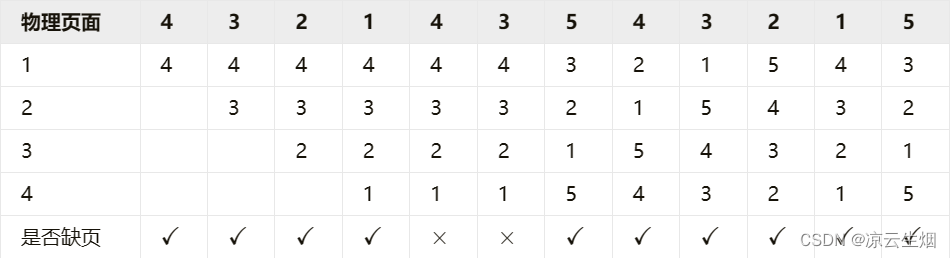
The number of page faults is 10, the total number of visits is 12, and the page fault rate
3. LFU
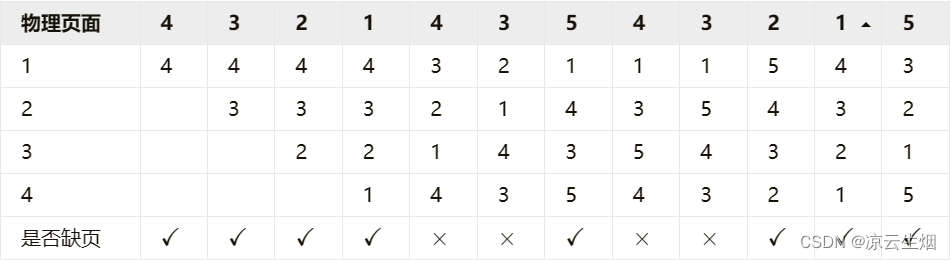
The LFU algorithm can be implemented using a linked list, placing the node that has just been visited at the end of the list, and the head of the list is the page that will be eliminated, which is different from the counter scheme introduced above. The number of page faults is 8, the total number of visits is 12, and the page fault rate .
Design Issues in Paging Systems
Local vs. Global Allocation Strategies
How to allocate memory among competing processes, when process A suffers a page fault, only the pages allocated to A or all memory pages need to be considered. The former is called a local (local) page replacement algorithm, and the latter is called a global (global) page replacement algorithm. local effectively allocates a fixed segment of memory to each process, and global dynamically allocates page frames among running processes, so the number of page frames per process varies over time.
global is generally preferred over local, becoming more pronounced as the size of the working set changes over process runtime. Even when there are a lot of free page frames, the local algorithm can cause thrashing as the working set grows, and wastes memory if the working set shrinks. The global algorithm requires the system to constantly determine how many page frames should be allocated to each process. Generally, page frames can be evenly allocated to n running processes, but this is unreasonable. A 300KB process should get 30 times the share of a 10KB process, not the same share. Another solution is to impose a minimum number of page frames so that no matter how small a process can run. Because on some machines, an instruction with two operands may use as many as 6 pages, because the instruction itself, source operand, and destination operand may cross page boundaries.
One way to manage the dynamic allocation of memory is to use the Page Fault Frequently (PFF) algorithm. PFF indicates when to increase or decrease the pages allocated to a process, but says nothing at all about the pages that should be replaced when a page fault occurs. Which page is dropped, only controls the size of the allocation set. PFF also assumes that PFF decreases as more pages are allocated.
page size
The page size is a parameter that the operating system can choose. To determine the optimal page size, several contradictory factors need to be weighed. From the results, there is no global optimal solution.
The text segment, data segment, or stack segment is likely not to fill the entire page exactly, and the last page is usually half empty, and the extra space is thus wasted. This waste is called internal . With n segments in memory and a page size of p bytes, there are bytes wasted by internal fragmentation. From this point of view, it would be better to use small pages, but using small page programs requires more pages, which means larger page tables. The redundant pages are stored on the disk, and more pages mean that pages need to be frequently exchanged with the disk, and a lot of time is wasted here. In addition, small pages can make full use of TLB space, but occupy more TLB entries. Since TLB entries are scarce resources, it is worthwhile to use large pages in this case. And each time the process is switched, the smaller the page means the larger the page table, and the loading time will be longer.
Assuming that the average size of a process is s bytes, the page size is p bytes, and each page table entry is e bytes, each process needs about 2 pages, occupying
1 byte of page table space, and the waste of internal fragments in the last page is
words section, so the total overhead due to page tables and internal fragmentation is
byte. Since the optimal value must be obtained when the page size is at a certain value, by deriving p once and setting the expression to 0, we get
,Solutions have to
share page
It is very common for several different users to run the same program at the same time, but if there are two copies of the same program in memory, it will waste memory, and shared pages are more efficient. But not all pages are suitable for sharing. Those read-only pages can be shared, but data pages cannot be shared.
If two processes share code, there will be some problems with shared pages. If the scheduler decides to swap program A out of memory, undo all its pages and fill the empty pages with other programs, it will cause B to generate a large number of page fault interrupts. So when swapping out or ending a process with shared pages, it is necessary to check whether the pages are still in use. If you look up all page tables to check whether a page is shared, the cost is very high, so a special data structure is needed to record these shared pages.
Sharing data will be more troublesome than sharing code, but not impossible. When two processes share the same data page, the process is required to read only without writing; when a write operation occurs, it triggers read-only protection and falls into the operating system kernel, and then generates a copy of the page, at this time each Each process has its own copy. Each subsequent copy is readable and writable, and further writes will not trap the kernel. This approach is called Copy -on-Write (COW), and it improves performance by reducing copying.
shared library
Other granularities can be used instead of individual pages for sharing. If a program is started twice, most operating systems automatically share all code pages, keeping only one copy of the code page in memory. Since code pages are always read-only, there is no problem doing this. Each process has a private copy of the data page, or uses copy-on-write technology to create a shared data page.
When multiple code libraries are used by different processes, if each program is statically bound to these libraries, the program will become larger. A common technique is to use shared libraries to solve program bloat . When linking the program and the shared library, the linker does not load the called function, but loads a short stub routine (stub routine) that can bind the called function at runtime. Depending on system implementation and configuration information, shared libraries are loaded with the program, or when the contained functions are called for the first time. If another program has already loaded the shared library, it will not be loaded again. When the shared library is loaded, it is not loaded into the memory at one time, but loaded in page units as needed, and the functions that are not called will not be loaded into the memory. In addition to reducing the file size of the executable program and saving memory space, the shared library has another advantage: if a function in the shared library is updated due to bug fixes, the program that calls this function does not need to be recompiled. The binaries can still be run.
But the shared library needs to solve a problem. The shared library is loaded into RAM and located at different addresses by different processes. If this library is not shared, it can be relocated during the loading process, but it will not work if the shared library is relocated during loading. You can use COW to solve this problem, create a new page for the process that calls the shared library, and perform relocation during the process of creating the new page, but this is contrary to the purpose of using the shared library. A better method is: let the compiler not use absolute addresses when compiling shared libraries, but only generate instructions that use relative addresses. In this way, no matter where the shared library is placed in the virtual address space, it can work normally. Code that uses only relative offsets is called position -independent code.
memory mapped file
There is a general mechanism for memory -mapped files, of which shared libraries are actually a special case. The idea behind this mechanism is that a process can map a file to part of its virtual address space by issuing a syscall. In most system implementations, mapped shared pages are not actually read into the content of the page, but are read into memory one page at a time when the page is accessed, and the disk file is used as a backing store. When the process exits or explicitly unmaps the file, all changed pages are written back to the disk file.
Memory-mapped files provide an alternative model of I/O that allows a file to be accessed as an in-memory large character array in memory, rather than through read and write operations to access the file. If two or more processes map the same file at the same time, they can communicate through shared memory. A process has completed a write operation on the shared memory. At this moment, when another process performs a read operation on the virtual address mapped to this file, it can immediately see the modification result of the write operation. Therefore, this mechanism is similar to a high-bandwidth channel between processes, and this mechanism is very mature and practical.
removal strategy
The paging system works best if there are a large number of free page frames in the system when a page fault occurs. If every page frame is occupied and modified, the page should be written back to disk first when swapping in a new page. In order to ensure that there are enough free page frames, many paging systems will have a background process called a paging daemon (paging daemon), which sleeps most of the time, but is woken up periodically to check the memory status. When there are too few free page frames, the daemon chooses to swap out the memory through the reserved page replacement algorithm to ensure that a certain number of page frames are supplied, which has better performance than using all the memory and searching for a page frame when it needs to be used. The daemon at least ensures that all free page frames are clean, so there is no need to rush to write back to disk when free page frames are allocated.
virtual memory interface
Everything currently discussed is transparent to upper-level programmers, and users can use memory normally without knowing the details. But in some advanced systems, the programmer can control the memory map and enhance the behavior of the program in very expensive ways.
One reason for allowing programmers control over the memory map is to allow two or more processes to share the same portion of memory. If the programmer can name the memory area, it is possible to implement shared memory: by letting one process notify another process of the name of a memory area, other processes can map this area to its virtual space. . Page sharing can implement a high-performance message passing system. When passing messages, data is copied from one address space to another, which will have a lot of overhead; when processes can control their page mapping, they can only copy The name of the page without copying all the data.
section
All current discussion of virtual memory is one-dimensional, and for many problems it may be better to have multiple independent address spaces than one. For example, the compiler creates many tables during compilation, which may include:
- program text saved for printing listings
- Symbol table, containing variable names and attributes
- table containing all integer and floating point constants used
- Parse tree, containing the results of program parsing
- The stack used by the compiler for internal procedure calls
The first four tables grow continuously as the compilation progresses, and the last table grows and shrinks in an unpredictable manner during the compilation. In one-dimensional memory, these five tables can only be allocated in contiguous blocks in the virtual address space. If the number of variables in a program is much larger than the number of other parts, the block allocated for the symbol table in the address space may be filled, but there is still a lot of space for other tables. A better method at this time is to provide multiple independent segment address spaces on the machine, and the length of each segment can be any value from 0 to a certain maximum allowed value. Different segment lengths can be different, and usually are not the same. The length of a segment can be changed dynamically at runtime, increasing when data is pushed in, and decreasing when popping, without affecting other segments.
A segment is a logical entity. A segment may include a procedure, an array, a stack, and a numeric variable, but generally does not contain multiple different types of content at the same time. In addition to simplifying the management of data structures whose lengths often change, each process managed by segmented memory is located in an independent segment and the starting position is 0, so the operation of linking the separately compiled processes can be obtained Great simplification. When all the procedures that make up a program have been compiled and linked, a call to a procedure in segment n will be addressed using a two-part address . When recompiling, compared with the one-dimensional address, the start address of other irrelevant processes will not be affected by the change of the process size.
Since segments can have different types of content, they can have different kinds of protection. A process segment can be specified as execution only, thereby prohibiting reading and writing; the read point array can be read and written but not executed, and any attempt to jump into this segment will be intercepted. Such protection makes it easy to find errors in programming.
Page is fixed length but segment is not. After the system runs for a period of time, the memory will be divided into many blocks, some blocks contain segments, and some become free areas. This phenomenon is called checkerboard fragmentation or external fragmentation . The memory in the free area is wasted, and this can be solved by memory compaction.

segment page implementation
If a segment is large, it might be inconvenient or even impossible to keep it whole in memory, hence the idea of paging it. In this way, only the pages that are really needed will be transferred into memory.
MULTICS
MULTICS is one of the most influential operating systems ever, having had a profound impact on UNIX systems, x86 memory architecture, fast tables, and computing. MULTICS began as a research project at MIT, went online in 1969, and the last MULTICS system was shut down in 2000 after 31 years of operation, and few other operating systems have continued to run for as long as MULTICS with little modification. More importantly, the views and theories based on MULTICS are still the same today as they were when the first related paper was published in 1965. The most innovative aspect of MULTICS is the virtual storage architecture .
MULTICS runs on Honeywell 6000 and subsequent models, and provides each program with a maximum of segments, and the maximum virtual address space of each segment is 65536 words long. To implement it, the designers of MULTICS decided to treat each segment as a virtual memory and page it, in order to combine the advantages of paging (fixed page size and only need to call part of the page) and the advantages of segmentation (easy programming , modularity, protection and sharing).
Each program has a segment table, and each segment corresponds to a descriptor. Because the segment table may have more than 250,000 entries, the segment table itself is also a segment and is paged. A segment descriptor contains an indication of whether a segment is in memory, as long as any part of the segment is in memory it is considered to be in memory. If the segment is in memory, its descriptor will contain an 18-bit page table pointer to it. Since the physical memory is 24 bits and the pages are aligned on 64-byte boundaries (the lower 6 bits of the page address are filled with 0), the descriptor only needs 18 bits to store the page table address. The segment descriptor also contains the segment size, protection bits, and other entries. Each segment is an ordinary virtual address space, and the general page size is 1024 words. The segment used by MULTICS may not be paged or paged with a length of 64 words.

An address in MULTICS consists of two parts: the segment and the address within the segment. The address in the segment is further divided into page number and word in the page. The following algorithm is executed when a memory access is made:
- Find the segment descriptor based on the segment number
- Check that the segment's page table is in memory. If it is, find its location, otherwise, a segment fault is generated, and an out-of-bounds error is issued if the access violates the protection requirements of the segment.
- Check the page table entry of the requested virtual page. If the page is not in the memory, a page fault interrupt will be generated. If it is in the memory, the starting address of the page in the memory will be taken out from the page table entry.
- Add the offset to the start address of the page to get the target address
- perform a read or write operation
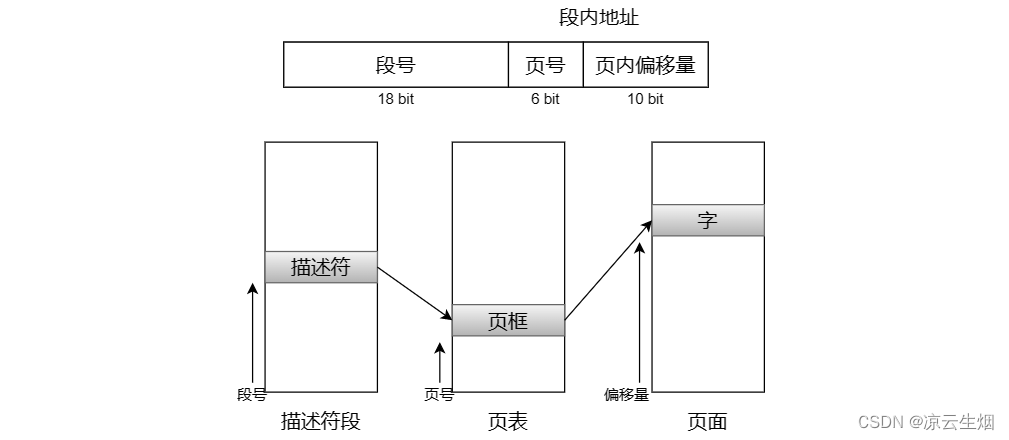
This simply shows the translation of the MULTICS virtual address to the physical address, ignoring the fact that the descriptor segment also needs paging. In fact, the page table of the descriptor segment is found through a register, and this page table points to the page of the descriptor segment. But implementing the above algorithm by the operating system will be very slow, MULTICS uses a 16-word command to tell the TLB to search all entries in parallel.
Intel x86
The x86 processor's virtual memory is similar to MULTICS, including the paging segmentation mechanism, which supports up to a number of segments, and each segment can be up to 1 billion 32-bit words. Although the number of segments is small, the x86's segment size characteristics are much more important than the larger number of segments, because few programs need more than 1000 segments, but many need large segments.
x86-64Fragmentation is considered obsolete and no longer supported since , but some vestiges of fragmentation still exist in native mode.
The core of the virtual memory in the x86 processor is two tables: the local description table (Local Descriptor Table, LDT) and the global description table (Global Descriptor Table, GDT). Each program has its own LDT, but on the same computer All programs share a GDT. LDT describes the segment of each program locally, including its code, data, stack, etc.; GDT describes the system segment, including the operating system itself.
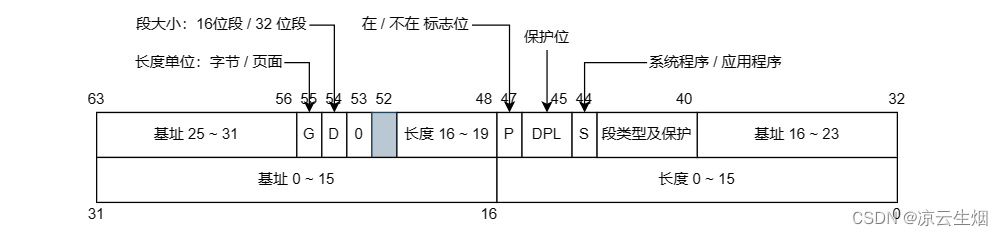
In order to access a segment, the x86 program must load the selector of this segment into one of the 6 registers of the machine. During operation, the CS register holds the selector of the code segment, the DS register holds the selector of the data segment, and the others The segment registers are less important, each selector is a 16 bit number. 1 bit in the selector indicates whether the segment is local or global, and the other 13 bits are the entry numbers of LDT or GDT. Therefore, the length of these tables is limited to a maximum of 8K segment descriptors. The remaining 2 bits are protection bits, which will be discussed later. Descriptor 0 is forbidden, it can be safely loaded into a segment register to indicate that the segment register is not currently available, and will cause an interrupt if used. The selector is designed so that it is very convenient to locate the descriptor according to the selection word. First select the LDT/GDT according to the selector, then the selector is copied into an internal erase register and its lower 3 bits are cleared, and finally the address of the LDT/GDT table is added to the index to obtain a pointer directly to the descriptor.

When the segment register is loaded by the selector, the corresponding descriptor is taken out from the LDT or GDT and loaded into the microprogram register for fast access. A descriptor consists of 8 Bytes, including the base address, size and other information of the segment. The following figure depicts the segment descriptor for an x86 code segment. There should be a simple 32 bit field in the descriptor giving the segment size, but in reality 20 bits are available, so a radically different approach is taken: use a granularity bit field to indicate whether to use bytes or pages. The processor will add the 32-bit base address and the offset to form a linear address (liner address). In order to be compatible with 286 which only has a 24-bit base address, the base address is divided into 3 pieces and distributed on the descriptor. In fact the base address runs each segment anywhere within the 32 bit linear address space.
If paging is disabled, linear addresses will be interpreted as physical addresses and sent to memory for read and write operations, so the disable operation will be a pure segmentation scheme. In addition, segments are allowed to overwrite each other, which may be due to the overhead of verifying that segments do not overlap. If paging is enabled, linear addresses are interpreted as virtual addresses and mapped to physical addresses through page tables. Since a segment may contain as many as 1 million pages with 32-bit virtual addresses and 4 KB pages, two-level mapping is used to reduce page table size when segments are small. Each process has a page directory (page directory) consisting of 1024 32-bit entries , which are located by global registers. Each directory entry in the page directory points to a page table that also contains 1024 32-bit entries, and the page table entries point to page frames. Linear addresses are divided into three fields: 目录, , 页面 and 偏移量. The directory field is used as an index to find the pointer to the correct page table in the page directory, then the page field is used to index the physical address of the page frame in the page table, and finally the offset is added to the page frame address to get the required physical address.