Article Directory
foreword
How can we see that the use of cuda programming improves the performance of the program, which is generally verified by comparing the running time of the program. Therefore, if you are familiar with the timing of the running time of the program, you can view the optimized performance effect.
1. CUDA timing program
Cuda provides a timing method based on cuda events. The following timing program is introduced in the cuda programming book:
// 定义变量
cudaEvent_t start, stop;
// cudaEventCreate初始化变量
CHECK(cudaEventCreate(&start));
CHECK(cudaEventCreate(&stop));
// 在计时的代码块之前要记录一个代表开始的事件
CHECK(cudaEventRecord(start));
// 需要添加cudaEventQuery操作刷新队列,才能促使前面的操作在GPU上执行
cudaEventQuery(start); // 不用CHECK,返回值不对但不代表程序出错
// 需要计时的代码块
add<<<grid_size, block_size>>>(d_x, d_y, d_z, N);
// 在计时的代码块结束要记录一个代表结束的事件
CHECK(cudaEventRecord(stop));
// 要让主机等待事件stop被记录完毕
CHECK(cudaEventSynchronize(stop));
// 计算程序执行的时间差
float elapsed_time;
CHECK(cudaEventElapsedTime(&elapsed_time, start, stop));
printf("Time = %g ms.\n", elapsed_time);
// 销毁start和stop事件
CHECK(cudaEventDestroy(start));
CHECK(cudaEventDestroy(stop));
2. Timing of CUDA programs
Repeat the timing 10 times and calculate the average value and error. Ignore the first time. The machine may be in the warm-up state on the CPU or GPU for the first time, and the measured time is often too large.
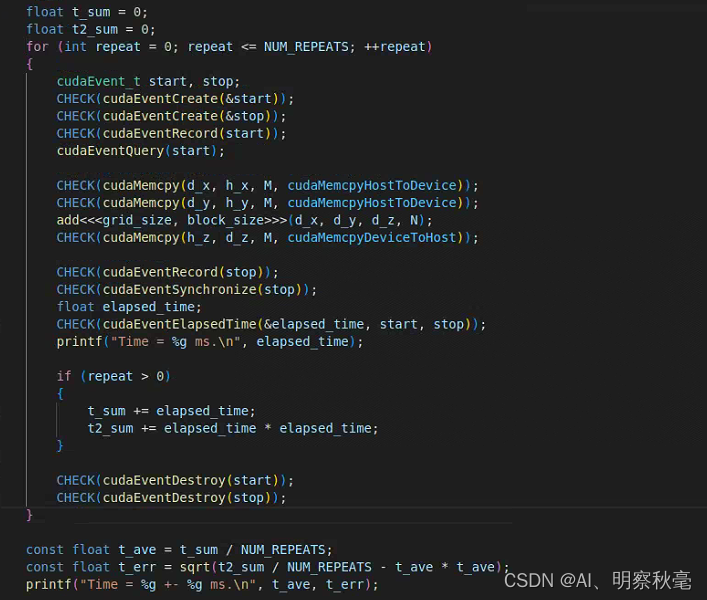
Modify in the previous program of adding arrays:
float t_sum = 0;
float t2_sum = 0;
for (int repeat = 0; repeat <= NUM_REPEATS; ++repeat)
{
cudaEvent_t start, stop;
CHECK(cudaEventCreate(&start));
CHECK(cudaEventCreate(&stop));
CHECK(cudaEventRecord(start));
cudaEventQuery(start);
add<<<grid_size, block_size>>>(d_x, d_y, d_z, N);
CHECK(cudaEventRecord(stop));
CHECK(cudaEventSynchronize(stop));
float elapsed_time;
CHECK(cudaEventElapsedTime(&elapsed_time, start, stop));
printf("Time = %g ms.\n", elapsed_time);
// 忽略第一次.第一次机器可能处于预热状态,测得的时间往往偏大.
if (repeat > 0)
{
t_sum += elapsed_time;
t2_sum += elapsed_time * elapsed_time;
}
CHECK(cudaEventDestroy(start));
CHECK(cudaEventDestroy(stop));
}
Here, when compiling with nvcc, you need to add the -O3 command to the command line, which is an optimization level, which means three levels of optimization, which can improve the performance of c++ programs. The difference between using optimization instructions and not using them is relatively large, about 2-3 times.
The key to GPU acceleration
In the above use of the timing program to time the core function of cuda, when using single precision and double precision to compare the running time, it is found that on the GeForce RTX2080Ti, the double precision is almost twice the relationship between the single precision running time.
Define a program that uses double-precision and single-precision floating-point calculations:
// 在源程序中使用条件编译,定义双精度和单精度
#ifdef USE_DP
typedef double real; // 给double和float类型取别名,方便直接使用real,后面统一做类型的修改
const real EPSILON = 1.0e-15;
#else
typedef float real;
const real EPSILON = 1.0e-6f;
#endif
When compiling, use the command line input -D USE_UP to specify the option to use double-precision floating-point numbers for calculations
Use single precision:
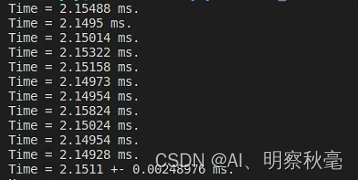
use double precision:
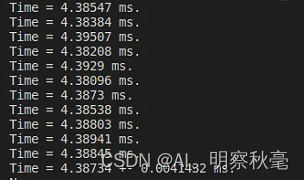
the above is only the running time of the program in the calculated kernel function, and does not calculate the time relative to the memory allocation and data transfer in the c++ program. Using single precision, if the timing is started when the data is transmitted, it is found that the cuda program takes a significant increase in time.
Running time:
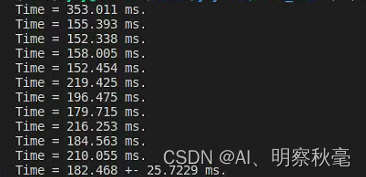
For programs that only use cpu, running time:
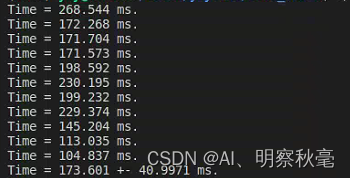
You can find:
- In the cuda program, the addition of arrays and the use of kernel functions take a relatively small amount of time, basically because data transmission consumes a lot of time. Compared with using the CPU directly, the performance may not be improved.
In the cuda toolbox, you can use the nvprof command to view the execution time consumption of each part of the program: it is
 very intuitive to analyze that data transmission occupies the main execution time, and the maximum time consumed by the kernel function is only 2.1864ms. 0.81% of the time.
very intuitive to analyze that data transmission occupies the main execution time, and the maximum time consumed by the kernel function is only 2.1864ms. 0.81% of the time.
In summary, it can be found that the data transmission between the host and the device consumes a relatively large amount of time. So why do you say that the performance of cuda can be improved?
- Through the time comparison of the kernel function, it can be seen that there are many cores on the GPU, and the calculation speed is much faster than that on the CPU. It should be that the operation of adding arrays is too simple, so it cannot intuitively reflect the acceleration of cuda. Later, by using more complex floating-point operations, it is proved that cuda can greatly improve the performance of the program. In addition, since data transmission takes up a large amount of time, as long as a complex operation is performed once and the transmission of large data is avoided as much as possible later, considerable performance improvement can be obtained.
To sum up here, the key to GPU acceleration is two points:
(1) The ratio of data transmission: more calculations are performed on the GPU to avoid excessive data transmission, and the data is transmitted through PCIe.
(2) Arithmetic intensity of floating-point calculations: complex floating-point calculations are performed on the GPU.
The book also mentions the ratio of execution time between single-precision and double-precision GPUs of different models. For problems with high arithmetic intensity, when using double-precision floating-point operations, the performance of Tesla series GPUs compared to GeForce series GPU has more advantages. There are not many single-precision GPUs, and GeForce series GPUs are more cost-effective.
Summarize
The timing method of cuda program execution and the analysis of GPU performance acceleration
Reference:
If the blog content is infringing, you can contact and delete it in time!
CUDA Programming: Basics and Practice
https://docs.nvidia.com/cuda/
https://docs.nvidia.com/cuda/cuda-runtime-api
https://github.com/brucefan1983/CUDA-Programming