- Paper address: VPS
- Code address: GitHub - GewelsJI/VPS: Video Polyp Segmentation (VPS)
- Dataset description: VPS/DATA_PREPARATION.md at main GewelsJI/VPS GitHub
contribute:
- Effect: 170fps
- Video Polyp Segmentation Dataset: SUN-SEG-Easy Dataset
- VPS Baseline: PNS+ (baseline refers to the baseline, which means that the performance lower than this method is unacceptable)
- VPS Benchmark
Targets: colonic polyp diversity (e.g. border contrast, shape, orientation, camera angle), internal artifacts (e.g. water flow, residue) and imaging degradation (e.g. color distortion, specular reflection).
SUN-SEG dataset
Based on the SUN dataset, new annotations are added, including object masks, boundaries,
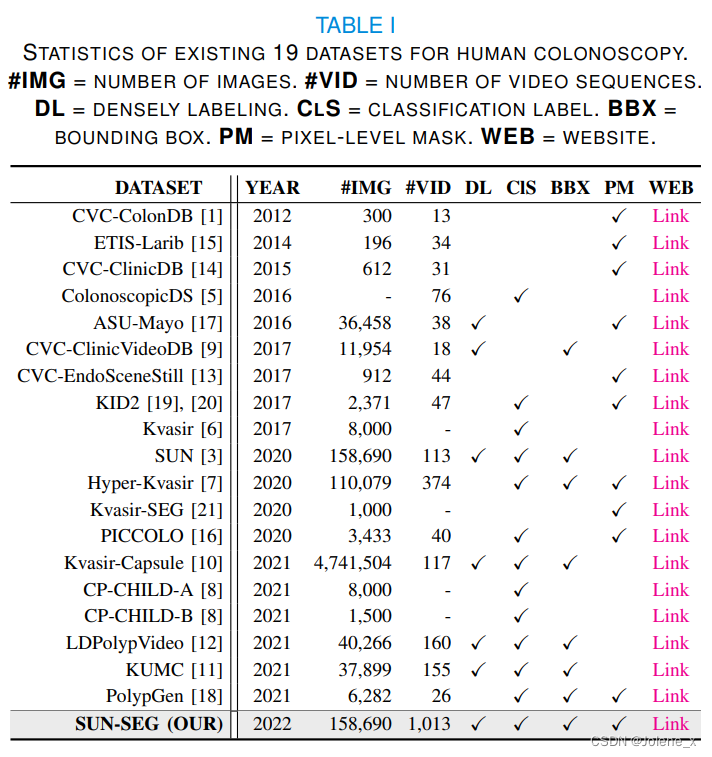
Network Architecture
Global Encoder
Take the first frame (H', W', 3) in the T frame sequence as the anchor point, and extract the anchor point feature A h ∈ RH h × W h × C h A^h ∈ R^{H^ h×W^h×C^h}Ah∈RHh×Wh×Ch
Local Encoder
Using a continuous frame in the sliding window as input, use the encoder to extract two sets of features high and low
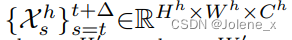
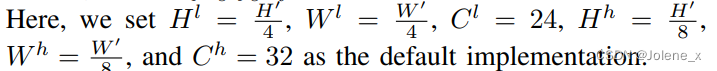
NS block
Dynamically update the receptive field
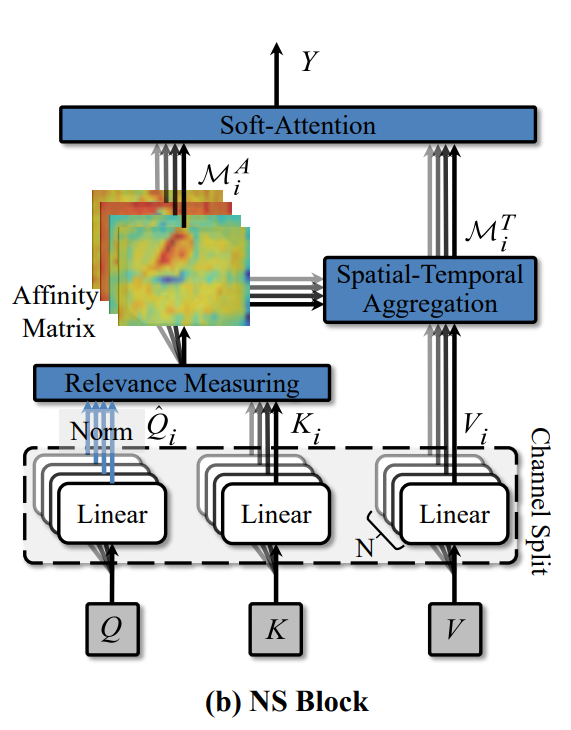
channel division
After obtaining the Q, K, and V matrices (T * H * W * C), dimension them into N parts from the channel to obtain Q i , K i , V i ∈ RT × H × W × CN {Q_i, K_i, V_i} ∈R^{T\times H\times W\times \frac{C}{N}}Qi,Ki,Vi∈RT×H×W×NC, respectively input N self-attention modules
Query dependency rules
Referenced: PCSA
In order to model the spatio-temporal relationship between consecutive frames, it is necessary to measure the segmented query features ( Q i ) i = 1 N {(Q_i)}_{i=1}^N(Qi)i=1Nand key features ( K i ) i = 1 N {(K_i)}_{i=1}^N(Ki)i=1NThe similarity between, referring to PCSA introduces N correlation measure blocks to calculate the space-time matrix of the restricted field of target pixels.
In Non-local, the relationship between the pixels in Q and all the pixels in K is calculated, and the relationship between the query position and key features of all positions is calculated, while the blocks in this paper gradually expand the range of feature blocks
Specifically, it is similar to the pyramid network, given Q i Q_iQiA pixel of the matrix X q X^qXq (more precisely, it should be height x, width y, all C/8 channel pixel values of the zth frame), according to the size of the windowkkDilation rate di d_i of k and dilated convolutiondi, in K i K_iKiSelect the height in the matrix as ( x − kdi , x + kdi ) (x-kd_i, x+kd_i)(x−kdi,x+kdi),宽为 ( y − k d i , y + k d i ) (y-kd_i,y+kd_i) (y−kdi,y+kdi) , add up the pixel values of all channels in all frames, and as the number of blocks in N blocks increases,di = 2 i − 1 d_i=2i-1di=2i _−1 will increase, which is equivalent to obtainingQ i Q_iQiwith a larger range of K i K_iKiThe relationship between. Similar to expanding the receptive field

normalization rules
对 Q i Q_i QiUsing Norm ( ) Norm()N o r m ( ) layer normalization along the time dimension
Q i ^ = N orm ( Q i ) \hat{Q_i}=Norm(Q_i)Qi^=Norm(Qi)
correlation measure
The final correlation calculation formula, the overall form is the same as the original transformer's self-attention formula
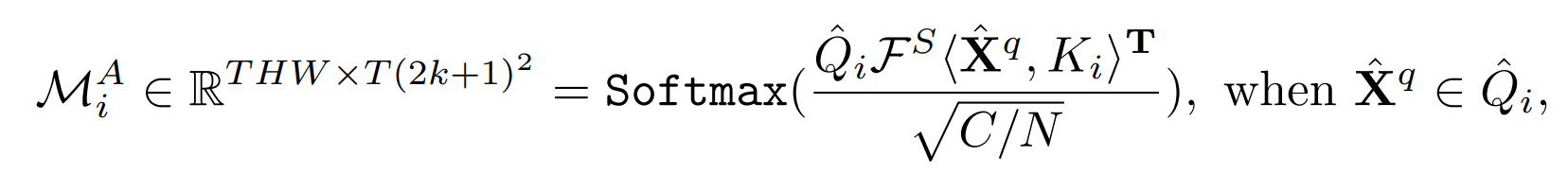
Spatial-Temporal (space-time aggregation)
Similar to the similarity calculation, the calculation of the V matrix and the Q and K similarity results, in fact
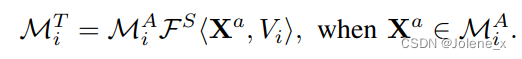
In fact, the overall calculation process is the same as the transformer's self-attention mechanism, but the way of calculating the correlation between pixels has been changed.
soft-attention
Through this module, the features M i AM^A_i of the similarity matrix are fusedMiAand spatio-temporal aggregation feature M i TM^T_iMiT, should strengthen correlated spatiotemporal patterns and suppress weakly correlated spatiotemporal patterns
First, a group of similarity matrices M i A M_i^AMiAConcatenate along the channel dimension to generate MAM^AMA
The Max function calculates MAM^AMThe maximum value of A on the channel dimension, and then a set of spatiotemporal aggregation features along the channel dimensionM i TM^T_iMiTSplicing to generate MTM^TMT
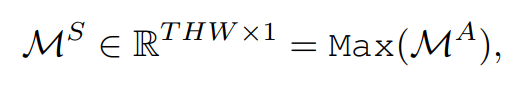
normalized self-attention
W T W_T WTIt is a learnable weight, and ※ indicates the channel-type Hadamard product (multiplying the corresponding elements of the matrix)
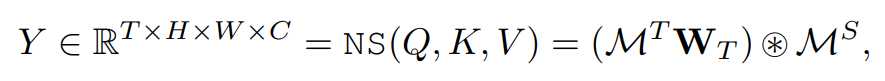
Hadama product:
For m × nm\times nm×n的两个矩阵A和B,相同位置元素相乘
( a 11 a 12 a 13 a 21 a 22 a 23 a 31 a 32 a 33 ) ∗ ( b 11 b 12 b 13 b 21 b 22 b 23 b 31 b 32 b 33 ) = ( a 11 b 11 a 12 b 12 a 13 b 13 a 21 b 21 a 22 b 22 a 23 b 23 a 31 b 31 a 32 b 32 a 33 b 33 ) \left( \begin{matrix} a_{11}\ a_{12}\ a_{13}\\ a_{21}\ a_{22}\ a_{23}\\ a_{31}\ a_{32}\ a_{33}\\ \end{matrix} \right) * \left( \begin{matrix} b_{11}\ b_{12}\ b_{13}\\ b_{21}\ b_{22}\ b_{23}\\ b_{31}\ b_{32}\ b_{33}\\ \end{matrix} \right) = \left( \begin{matrix} a_{11}b_{11}\ a_{12}b_{12}\ a_{13}b_{13}\\ a_{21}b_{21}\ a_{22}b_{22}\ a_{23}b_{23}\\ a_{31}b_{31}\ a_{32}b_{32}\ a_{33}b_{33}\\ \end{matrix} \right) ⎝⎛a11 a12 a13a21 a22 a23a31 a32 a33⎠⎞∗⎝⎛b11 b12 b13b21 b22 b23b31 b32 b33⎠⎞=⎝⎛a11b11 a12b12 a13b13a21b21 a22b22 a23b23a31b31 a32b32 a33b33⎠⎞
Output of the NS block
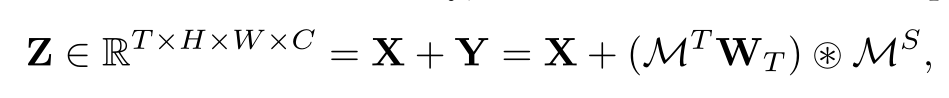
global-local learning strategy
Realize long-term and short-term space-time propagation over arbitrary time distances
Global Spatial-Temporal Modeling
global spatiotemporal modeling
The first NS block to model long-term relationships over arbitrary temporal distances requires four-dimensional temporal features as input.
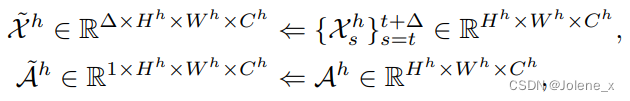
Using the anchor feature A h A^hAh as query matrixQ g Q^gQg , using the high features generated by the local encoder asK g K^gKg andQ g Q^gQg
The purpose is to establish the pixel similarity between the anchor point and the local high feature, residual connection, get Z g Z^gZg , where + is element-wise addition
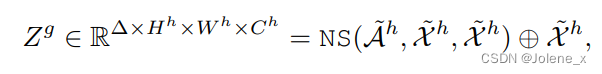
Global-to-Local Propagation
In the second NS block, the long-distance dependency Z g Z^gZg is propagated to the frame within the sliding windowas input to the second NS block
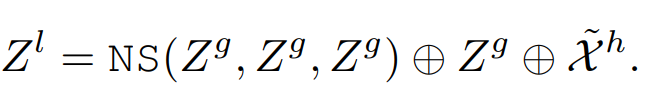
decoder
Combine the low features of the local encoder and the output features of the second NS block Z l Z^lZl restored to spatial form as input to a two-stage U-Net decoder
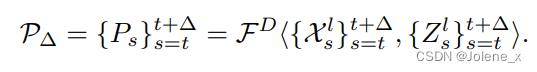
Optimizing with Binary Cross Entropy Loss

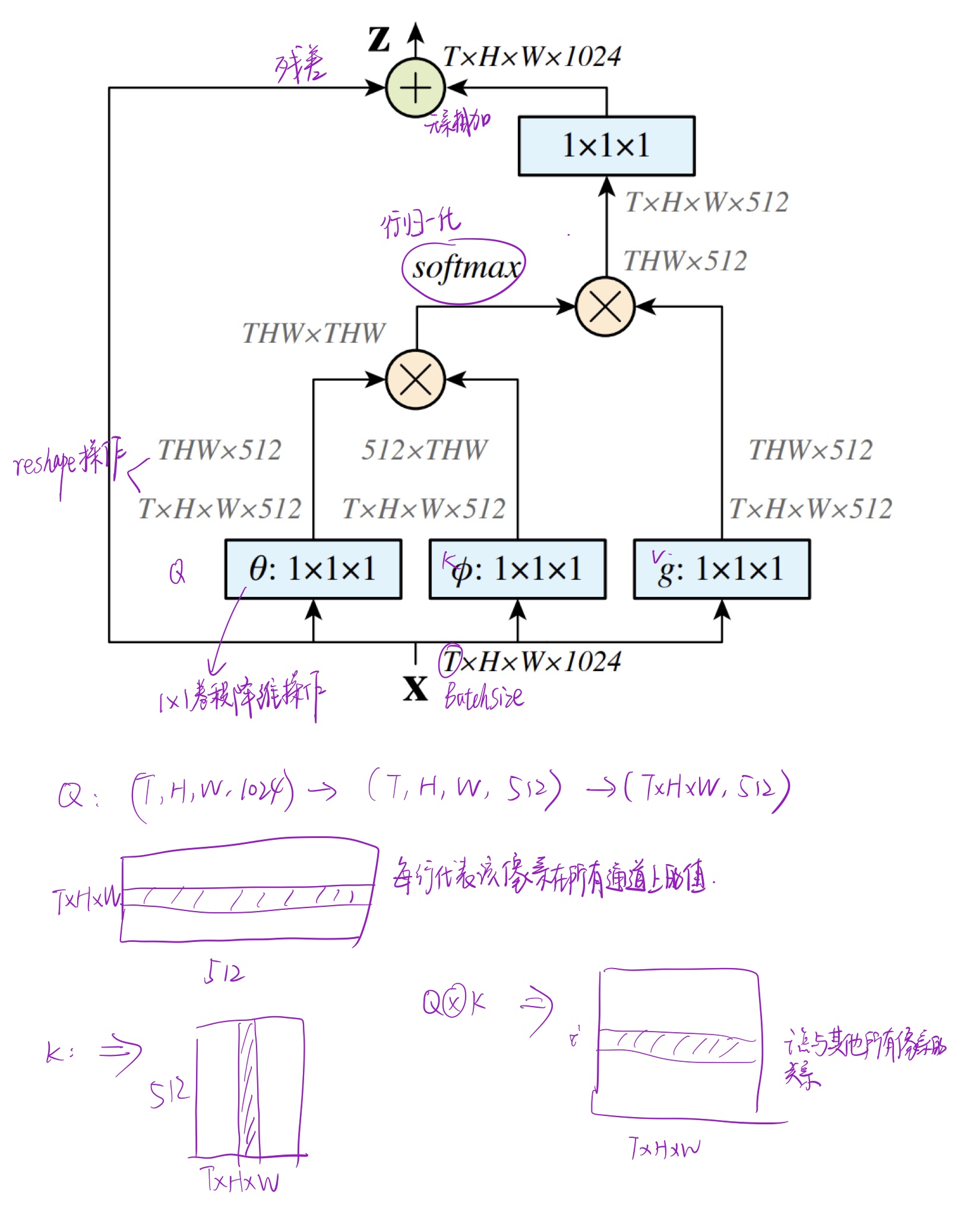
PCSA
CSA (constrained self-attetion) focuses on local motion patterns instead of learning the global background
Considering that protruding objects can have different sizes and move at different speeds, a set of CSAs is used to form a pyramid structure
Constrained self-attention
Constrains correlation measures and context in consecutive frames to the neighborhood of Q
For example, in the picture below, the object in the first frame has a similar position to the object in the adjacent frame. Based on this, for a feature element x(t, h, w) in the Q matrix, take its value in the K matrix The surrounding area is used to measure the correlation, which is limited to frame: 1-T, height: h-dr, h+dr, width: w-dr, w+dr

combination of pyramids
This is the reference used in PNS-Net
A single constrained self-attention with a fixed size cannot recognize moving objects caused by various speeds and various sizes, and the multi-head mechanism has different window sizes and moving ranges for each head to adapt to different motion situations
Combining multiple heads with multiple scales
Multi-head: in parallel, divides the input features into g groups along the channel, and uses constrained self-attention for each group
mg-g44DU2tR-1653467435113)]
combination of pyramids
This is the reference used in PNS-Net
A single constrained self-attention with a fixed size cannot recognize moving objects caused by various speeds and various sizes, and the multi-head mechanism has different window sizes and moving ranges for each head to adapt to different motion situations
Combining multiple heads with multiple scales
Multi-head: in parallel, divides the input features into g groups along the channel, and uses constrained self-attention for each group
Multi-scale: different groups, different window sizes, different d and r