Article directory
-
-
- basic concept
- SVM optimization problem solving ideas
- Mathematical Principles of Support Vector Machines
-
-
- Step 1: Establish the support vector equation
- Step 2: Find the maximum interval LLL expression
- Step 3: Find LLL constraints, resulting in an optimization problem
- Step 4: Solve the first four conditions for the solution of the optimization problem
- Step 5: Obtain the fifth condition for the solution of the optimization problem
- Step 6: Convert to SVM dual problem
- Step 7: Optimizing the Equation
- Step 8: Deriving the Algorithm Steps
-
- title
-
Literature reference
basic concept
support vector
Concept: The sample points located near the classification hyperplane are called support vectors
In mathematics, the concept of a point is often replaced by a vector. For example, in the Cartesian coordinate system, the coordinates of point A are (3,4), we can think that it represents the vector OA = (3,4)
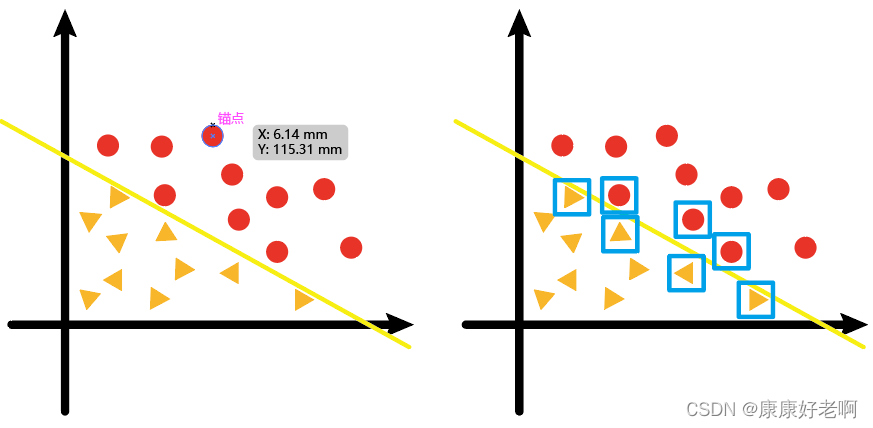
Now we have a two-dimensional sample point (vector) as shown in the left picture below, where the yellow line is the classification line calculated by linear regression; and those points close to the regression line in the right picture (marked with a blue square) are called support vector.
The meaning of "support" can be understood as follows:
Those points close to the classification boundary are the points that affect the direction of the regression line (hyperplane); points farther away from the classification boundary, they have no effect on how the regression line (hyperplane) is drawn
If we understand "machine" as "algorithm", then support vector machine is not difficult to understand as "algorithm related to support points (finding classification hyperplane)"
The following is a more standard concept of support vector machine:
Support Vector Machine (SVM)
It is a binary classification model, and its basic model is a linear classifier with the largest interval defined in the feature space.
For the following data sets, a regression line should be used to separate them. There are three lines ①, ②, and ③. Which one works best?
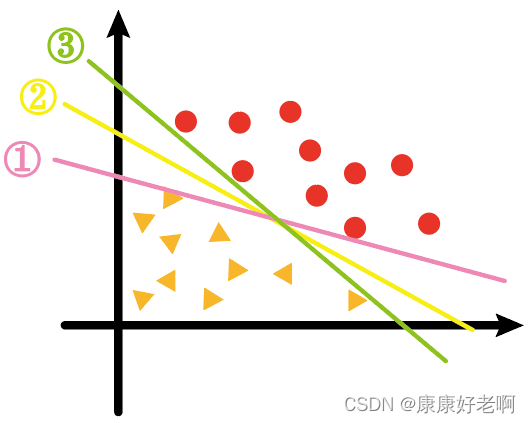
I think most people will think it is ②. Although the three lines are all satisfied to separate the triangle and the circle, for the ② line, the distance from the support vectors of the triangle and the circle to the ② line looks more "balanced", as if separating it from the middle.
In fact, the meaning of support vector machine refers to the algorithm that finds the sum of the distances from the support vector to the hyperplane as large as possible.
In fact, according to the basic inequality, the sum of the distances is the largest and the distance is more "balanced" is actually equivalent
Then here comes the concept of the maximum margin hyperplane
maximum margin hyperplane
The corresponding line ② in the figure above—that is, what we see as the most "balanced line" is actually a line that separates the two types of samples with the maximum interval (high-dimensional one is called a hyperplane), that is, the maximum interval hyperplane.
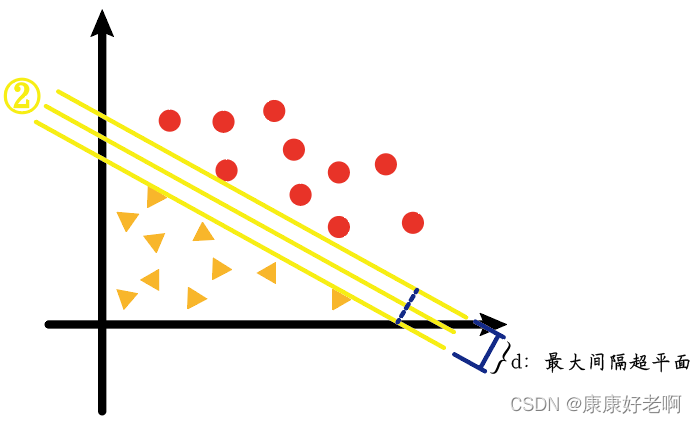
We will find that the sample interval of the two lines ① and ③ is much smaller than that of ②, as shown in the figure below
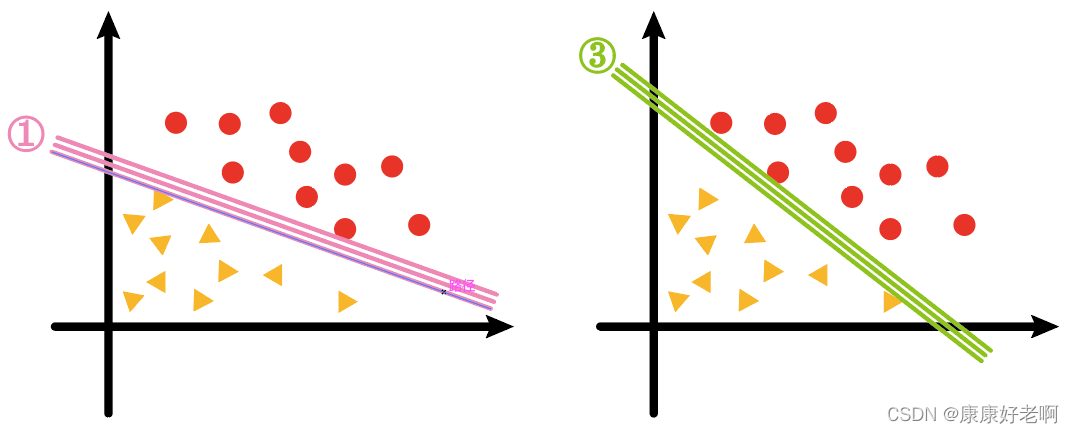
And what our support vector machine algorithm (SVM) essentially seeks is ② such a line, plane or hyperplane
Soft and hard intervals
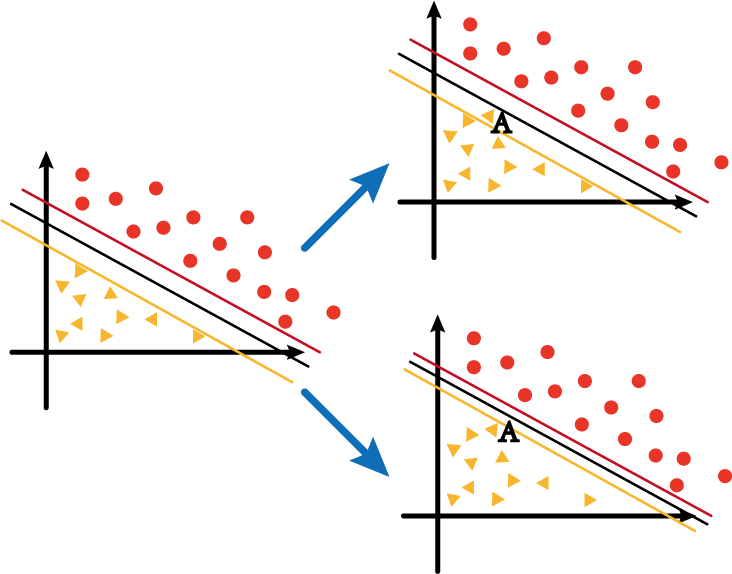
Assume that yellow, black and red in the coordinate system on the left in the above figure are negative/decision/positive hyperplanes respectively, and at this time if a new data point AA is added between the yellow line and the red lineA , then whether to adjust around the hyperplane will be divided into two cases:
- The first is Figure 1 in the upper right corner, although AA is addedA , but still keep it between the yellow and red lines;
- The second is Figure 2 in the lower right corner, with AAWith the addition of A , the hyperplane also changes, and finally guarantees thatAAA is below the yellow line.
The distance between the yellow line and the red line in the first case is called soft interval; the distance between the yellow line and red line in the second case is called hard interval.
SVM optimization problem solving ideas
In linear algebra, any hyperplane can be described by the following linear equation:
WTX + b = 0 W^{T}X+b=0WTX+b=0
of which
W = [ w 1 , w 2 , ⋅ ⋅ ⋅ ,wn ] W=[w_1,w_2, ,w_n]W=[w1,w2,⋅⋅⋅,wn]
X = [ x 1 , x 2 , ⋅ ⋅ ⋅ , x n ] X=[x_1,x_2,···,x_n] X=[x1,x2,⋅⋅⋅,xn]
is the coefficient matrix, after the matrix W is transposed
[ W 1 W 2 ⋅ ⋅ ⋅ W n ] \left[ \begin{array} {} W_1\\ W_2\\ ·\\ ·\\ ·\\ W_n \end{array} \right] W1W2⋅⋅⋅Wn
$$
故
W T X = w 1 x 1 + w 2 x 2 + w 3 x 3 + ⋅ ⋅ ⋅ + w n x n W^TX=w_1x_1+w_2x_2+w_3x_3+···+w_nx_n WTX=w1x1+w2x2+w3x3+⋅⋅⋅+wnxn
It is the hyperplane function expression we normally see
According to the distance formula from point to line
∣ A x + B y + C ∣ A 2 + B 2 \frac{|Ax+By+C|}{\sqrt{A^2+B^2}} A2+B2∣Ax+By+C∣
Expand from two dimensions to high dimension∣
w 1 x 1 + w 2 x 2 + w 3 x 3 + ⋅ ⋅ ⋅ + wnxn + b ∣ w 1 2 + w 2 2 + ⋅ ⋅ ⋅ + wn 2 \frac{|w_1x_1 +w_2x_2+w_3x_3+···+w_nx_n+b|}{\sqrt{w_1^2+w_2^2+···+w_n^2}}w12+w22+⋅⋅⋅+wn2∣w1x1+w2x2+w3x3+⋅⋅⋅+wnxn+b∣
其中
w 1 x 1 + w 2 x 2 + w 3 x 3 + ⋅ ⋅ ⋅ + w n x n = W T X w_1x_1+w_2x_2+w_3x_3+···+w_nx_n=W^TX w1x1+w2x2+w3x3+⋅⋅⋅+wnxn=WT X
is the formula
w 1 2 + w 2 2 + ⋅ ⋅ ⋅ + wn 2 = ∣ ∣ W ∣ ∣ ∣ \sqrt{w_1^2+w_2^2+···+w_n^2}=|| W||w12+w22+⋅⋅⋅+wn2=∣∣ W ∣∣
is the definition of the modulus of the vector
For a two-dimensional vector X = (3,4), its modulus
∣ ∣ X ∣ ∣ = 3 2 + 4 2 = 5 ||X||=\sqrt{3^2+4^2}=5∣∣X∣∣=32+42=5
high-dimensional vectors and so on
So the above high-dimensional distance formula can be transformed into
∣ W T X + b ∣ ∣ ∣ W ∣ ∣ \frac{|W^TX+b|}{||W||} ∣∣W∣∣∣WTX+b∣
Mathematical Principles of Support Vector Machines
Through the above introduction, we have a general understanding of the function and simple principle of the support vector machine. Let's introduce the mathematical principle and algorithm of support vector machine in detail.
First of all, let me add the content of the hyperplane introduced above. We generally call the hyperplane used for separation in the middle as the decision hyperplane, and the decision hyperplane is also the hyperplane we finally obtain. There are two hyperplanes in the positive direction and negative direction of the decision hyperplane: a positive hyperplane and a negative hyperplane. These two hyperplanes are used to assist in generating decision hyperplanes. For simplicity, we only consider two-dimensional support vector machines.
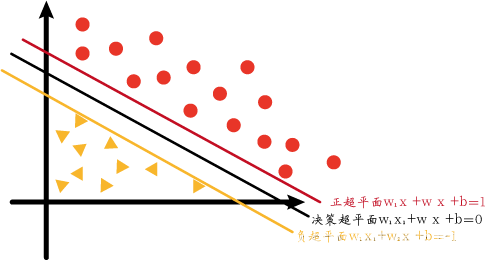
The equations of the positive hyperplane, decision hyperplane and negative hyperplane in the figure are as follows:
w 1 x 1 + w 2 x 2 + b = 1 w 1 x 1 + w 2 x 2 + b = 0 w 1 x 1 + w 2 x 2 + b = − 1 w_1x_1+w_2x_2+b=1\\w_1x_1+w_2x_2+b=0\\w_1x_1+w_2x_2+b=-1w1x1+w2x2+b=1w1x1+w2x2+b=0w1x1+w2x2+b=− 1
is not the only way to write a hyperplane. In the previous basic part, we introduced how to express linear equations in matrices. This way of writing is just an equivalent variant (transposition) of the above, which is convenient for subsequent operations.
Now we assume that there are two support vectors M and N on the positive hyperplane and negative hyperplane respectively. They respectively satisfy the following formula:
w 1 x 1 m + w 2 x 2 m + b = 1 w 1 x 1 n + w 2 x 2 n + b = − 1 w_1x_{1m}+w_2x_{2m}+b=1 \\w_1x_{1n}+w_2x_{2n}+b=-1w1x1 m+w2x2 m+b=1w1x1n+w2x2 n+b=− 1
The two existing equations do not have any effect or inspiration for us. Considering that the common factorsw 1 , w 2 w_1, w_2w1、w2, and have constant bbb , so we take the difference between the two formulas and get the following result:
w 1 ( x 1 m − x 1 n ) + w 2 ( x 2 m − x 2 n ) = 2 w_1(x_{1m}-x_{1n })+w_2(x_{2m}-x_{2n})=2w1(x1 m−x1n)+w2(x2 m−x2 n)=2
If we regard the above formula as a dot product of two vectors, we will get:
w ⃗ ( xm ⃗ − xn ⃗ ) = 2 \vec{w}(\vec{x_m}-\vec{x_n})= 2w(xm−xn)=2
inw ⃗ = [ w 1 w 2 ] \vec{w}=[w_1 \ w_2]w=[w1 w2], x m ⃗ = [ x 1 m x 2 m ] T \vec{x_m}=[x_{1m} \ x_{2m}]^T xm=[x1 m x2 m]T, x n ⃗ = [ x 1 n x 2 n ] T \vec{x_n}=[x_{1n} \ x_{2n}]^T xn=[x1n x2 n]T
Conditions ⃗ ⋅ b ⃗ = ∣ ∣ a ⃗ ∣ ∣ ∗ ∣ ∣ b ⃗ ∣ ∣ ∗ cos θ \vec{a}·\vec{b}=||\vec{a}||*||\vec{ b}||*cos\thetaa⋅b=∣∣a∣∣∗∣∣b∣∣∗cos θ,
∣ ∣ w ⃗ ∣ ∣ ∗ ∣ ∣ xm ⃗ − xn ⃗ ∣ ∣ ∗ cos θ = 2 ||\vec{w}||*||\vec{x_m}-\vec{x_n}||* cos\theta=2∣∣w∣∣∗∣∣xm−xn∣∣∗cosθ=2
Among them∣ ∣ w ⃗ ∣ ∣ = w 1 2 + w 2 2 ||\vec{w}||=\sqrt{w_1^2+w_2^2}∣∣w∣∣=w12+w22。
移题
∣ ∣ xm ⃗ − xn ⃗ ∣ ∣ ∗ cos θ = 2 ∣ ∣ w ⃗ ∣ ∣ ||\vec{x_m}-\vec{x_n}||*cos\theta=\frac{2}{|| \vec{w}||}∣∣xm−xn∣∣∗cosθ=∣∣w∣∣2
By transposing xxx givewww are on the left and right sides of the equation. The coordinates of the data points are on the left, and the weight values to be found are on the right.
Here we might as well think about ∣ ∣ xm ⃗ − xn ⃗ ∣ ∣ ∗ cos θ ||\vec{x_m}-\vec{x_n}||*cos\theta∣∣xm−xn∣∣∗The meaning of cos θ .
So we draw the picture below and try to observe the meaning of the above formula from a geometric point of view.
We know that the vector dot product can be converted into a projection, that is, the modulus of a vector is multiplied by cos θ cos\thetaCos θ is projected to the direction of another vector, and the same direction will greatly facilitate calculation.

So we draw the following coordinate system and vectors (referred to as Figure 1). We want to use vector dot product projection, but we don't know MN and w ⃗ \vec{w}wangle.
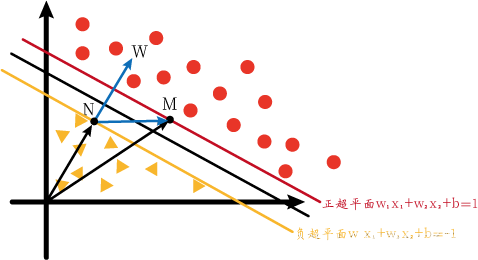
But we can convert. We know that M and N are on the positive and negative hyperplanes, so what if M and N are on the decision hyperplane? Since the equations of these three hyperplanes are only different on the right side of the equal sign, if M and N are on the decision hyperplane, w ⃗ \vec{w}wIt should be the same as pictured above. So we might as well set M and N on the decision hyperplane first. We can draw the following graph (call it Figure 2):
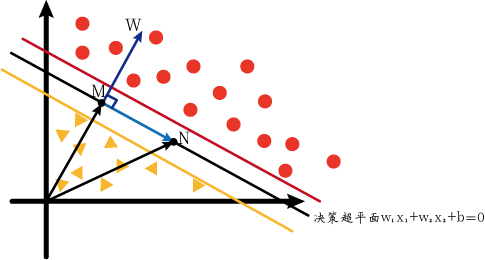
At this time, M and N respectively satisfy the following formula:
w 1 x 1 m + w 2 x 2 m + b = 0 w 1 x 1 n + w 2 x 2 n + b = 0 w_1x_{1m}+w_2x_{2m }+b=0\\w_1x_{1n}+w_2x_{2n}+b=0w1x1 m+w2x2 m+b=0w1x1n+w2x2 n+b=0
, we can get:
w 1 ( x 1 m − x 1 n ) + w 2 ( x 2 m − x 2 n ) = 0 w_1(x_{1m}-x_{1n})+w_2(x_ {2m}-x_{2n})=0w1(x1 m−x1n)+w2(x2 m−x2 n)=0
即
w ⃗ ( xm ⃗ − xn ⃗ ) = 0 \vec{w}(\vec{x_m}-\vec{x_n})=0w(xm−xn)=
A dot product of 0 vectors is zero indicating that the two vectors are perpendicular to each other. Observe the above figure,xm ⃗ − xn ⃗ \vec{x_m}-\vec{x_n}xm−xnThat is NM ⃗ \vec{NM}NM. And this means that w ⃗ \vec{w}wPerpendicular to the decision hyperplane, that is, perpendicular to the positive and negative hyperplanes. Well, at this time we turn back from Figure 2 to Figure 1, and we will release Figure 1 again for the convenience of explanation.
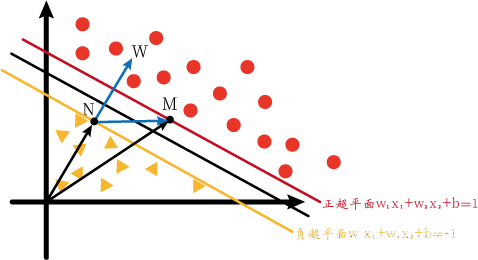
Since w ⃗ \vec{w}wis perpendicular to the hyperplane, so ∣ ∣ NM ⃗ ∣ ∣ ||\vec{NM}||∣∣NM∣∣在w ⃗ \vec{w}wThe projection on is the maximum interval LL of positive and negative hyperplanesL ._ \theta∣∣NM∣∣=∣∣xm−xn∣∣∗cosθ,故
L = 2 ∣ ∣ w ⃗ ∣ ∣ L=\frac{2}{||\vec{w}||} L=∣∣w∣∣2
Positive hyperplane: all red points belong to the positive class, so yi = 1 y_i=1yi=1 ; all red points are above the positive hyperplane, sow ⃗ ⋅ xi ⃗ + b ≥ 1 \vec{w}·\vec{x_i}+b≥1w⋅xi+b≥1
Negative hyperplane: all yellow points belong to the negative class, so yi = − 1 y_i=-1yi=− 1 ; all yellow points are below the negative hyperplane, sow ⃗ ⋅ xi ⃗ + b ≤ 1 \vec{w}·\vec{x_i}+b≤1w⋅xi+b≤1
The above two situations can be summarized into the following formula:
yi ∗ ( w ⃗ ⋅ xi ⃗ + b ) ≥ 1 y_i*(\vec{w}·\vec{x_i}+b)≥1yi∗(w⋅xi+b)≥1
and this formula is the constraint condition.
Therefore, the problem of finding a decision hyperplane is transformed into:
在 y i ∗ ( w ⃗ ⋅ x i ⃗ + b ) ≥ 1 y_i*(\vec{w}·\vec{x_i}+b)≥1 yi∗(w⋅xi+b)≥1 condition,∣ ∣ w ⃗ ∣ ∣ ||\vec{w}||∣∣w∣∣ minimum value.
由于∣ ∣ w ⃗ ∣ ∣ = w 1 2 + w 2 2 ||\vec{w}||=\sqrt{w_1^2+w_2^2}∣∣w∣∣=w12+w22contains a root sign, so the minimum value is not very easy to find. So let's convert it, will ∣ ∣ w ⃗ ∣ ∣ ||\vec{w}||∣∣w∣∣ is transformed into∣ ∣ w ⃗ ∣ ∣ 2 2 \frac{||\vec{w}||^2}{2}2∣∣w∣∣2, so the problem is equivalent to:
在 y i ∗ ( w ⃗ ⋅ x i ⃗ + b ) ≥ 1 y_i*(\vec{w}·\vec{x_i}+b)≥1 yi∗(w⋅xi+b)≥1 condition,∣ ∣ w ⃗ ∣ ∣ 2 2 \frac{||\vec{w}||^2}{2}2∣∣w∣∣2minimum value.
We will use the method of Lagrange multipliers to solve this kind of problem.
But there is a problem, that is, the constraint condition yi ∗ ( w ⃗ ⋅ xi ⃗ + b ) ≥ 1 y_i*(\vec{w}·\vec{x_i}+b)≥1yi∗(w⋅xi+b)≥1 is an inequality rather than an equality, so we have to go through a step of conversion to convert the inequality into an equality.
We have ∗ ( w ⃗ ⋅ xi ⃗ + b ) ≥ 1 y_i*(\vec{w}·\vec{x_i}+b)≥1yi∗(w⋅xi+b)≥1 Transformyi ∗ ( w ⃗ ⋅ xi ⃗ + b ) − 1 = pi 2 y_i*(\vec{w}\vec{x_i}+b)-1=p_i^2yi∗(w⋅xi+b)−1=pi2, since pi 2 ≥ 0 p_i^2≥0pi2≥0恒成立,故 y i ∗ ( w ⃗ ⋅ x i ⃗ + b ) − 1 ≥ 0 y_i*(\vec{w}·\vec{x_i}+b)-1≥0 yi∗(w⋅xi+b)−1≥0 constant is established.
So the original problem is equivalent to:
在 y i ∗ ( w ⃗ ⋅ x i ⃗ + b ) − 1 = p i 2 y_i*(\vec{w}·\vec{x_i}+b)-1=p_i^2 yi∗(w⋅xi+b)−1=pi2Under the condition, ∣ ∣ w ⃗ ∣ ∣ 2 2 \frac{||\vec{w}||^2}{2}2∣∣w∣∣2minimum value.
Lower-surface structural Rager Rokuhi function:
L ( w , b , λ i , pi ) = ∣ ∣ w ⃗ ∣ ∣ 2 2 − ∑ i = 1 s λ i ∗ ( yi ∗ ( w ⃗ ⋅ xi ⃗ + b ) − 1 − pi 2 ) L(w,b,\lambda_i,p_i)=\frac{||\vec{w}||^2}{2}-\sum_{i=1}^s\lambda_i*(y_i *(\vec{w}\vec{x_i}+b)-1-p_i^2)L(w,b,li,pi)=2∣∣w∣∣2−i=1∑sli∗(yi∗(w⋅xi+b)−1−pi2)
and then solve it. The Lagrange function takes the partial derivative for each unknown and sets it equal to zero.
∂ L ∂ w = 0 ; ∂ L ∂ b = 0 ; ∂ L ∂ λ i = 0 ; ∂ L ∂ pi = 0 \frac{\partial{L}}{\partial{w}}=0;\frac{ \partial{L}}{\partial{b}}=0;\frac{\partial{L}}{\partial{\lambda_i}}=0;\frac{\partial{L}}{\partial{p_i }}=0∂w∂L=0;∂b∂L=0;∂λi∂L=0;∂pi∂L=0
Let's calculate one by one below.
- First ∂ L ∂ w = 0 \frac{\partial{L}}{\partial{w}}=0∂w∂L=0。 w w w appears in two positions, namely∣ ∣ w ⃗ ∣ ∣ 2 2 \frac{||\vec{w}||^2}{2}2∣∣w∣∣2和 ∑ i = 1 s λ i ∗ y i ∗ ( w ⃗ ⋅ x i ⃗ + b ) \sum_{i=1}^s\lambda_i*y_i*(\vec{w}·\vec{x_i}+b) ∑i=1sli∗yi∗(w⋅xi+b ) , it is easy to derive the following formula:
w ⃗ − ∑ i = 1 s λ i y i x i ⃗ = 0 ⋅ ⋅ ⋅ ⋅ ⋅ ⋅ ⋅ ⋅ ⋅ ⋅ ⋅ ⋅ ① \vec{w}-\sum_{i=1}^s\lambda_iy_i\vec{x_i}=0············① w−i=1∑sliyixi=0⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅①
- Then ∂ L ∂ b = 0 \frac{\partial{L}}{\partial{b}}=0∂b∂L=0。 b b b only appears in one position,∑ i = 1 s λ i ∗ yi ∗ b \sum_{i=1}^s\lambda_i*y_i*b∑i=1sli∗yi∗b , it is easy to derive the following formula:
∑ i = 1 s λ i y i = 0 ⋅ ⋅ ⋅ ⋅ ⋅ ⋅ ⋅ ⋅ ⋅ ⋅ ⋅ ⋅ ② \sum_{i=1}^s\lambda_iy_i=0············② i=1∑sliyi=0⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅②
- Then ∂ L ∂ λ i = 0 \frac{\partial{L}}{\partial{\lambda_i}}=0∂λi∂L=0。 λ i\lambda_ilionly appear in one position, as ∑ i = 1 s λ i ∗ ( yi ∗ ( w ⃗ ⋅ xi ⃗ + b ) − 1 − pi 2 ) \sum_{i=1}^s\lambda_i*(y_i*(\ vec{w}\vec{x_i}+b)-1-p_i^2)∑i=1sli∗(yi∗(w⋅xi+b)−1−pi2) . Originally, the result of partial derivative should be∑ i = 1 syi ∗ ( w ⃗ ⋅ xi ⃗ + b ) − 1 − pi 2 = 0 \sum_{i=1}^{s}{y_i*(\vec{w }·\vec{x_i}+b)-1-p_i^2=0}∑i=1syi∗(w⋅xi+b)−1−pi2=0 , but according to the constraints,yi ∗ ( w ⃗ ⋅ xi ⃗ + b ) − 1 − pi 2 = 0 y_i*(\vec{w}·\vec{x_i}+b)-1-p_i^2= 0yi∗(w⋅xi+b)−1−pi2=0 , there is no need to use the summation sign.
y i ∗ ( w ⃗ ⋅ x i ⃗ + b ) − 1 − p i 2 = 0 ⋅ ⋅ ⋅ ⋅ ⋅ ⋅ ⋅ ⋅ ⋅ ⋅ ⋅ ⋅ ③ y_i*(\vec{w}·\vec{x_i}+b)-1-p_i^2=0············③ yi∗(w⋅xi+b)−1−pi2=0⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅③
- Finally ∂ L ∂ pi = 0 \frac{\partial{L}}{\partial{p_i}}=0∂pi∂L=0。 p i p_i piAppears in only one position, ∑ i = 1 s λ i ∗ ( − pi 2 ) \sum_{i=1}^s\lambda_i*(-p_i^2)∑i=1sli∗(−pi2) , it is easy to derive the following formula:
2 λ i p i = 0 ⋅ ⋅ ⋅ ⋅ ⋅ ⋅ ⋅ ⋅ ⋅ ⋅ ⋅ ⋅ ④ 2\lambda_ip_i=0············④ 2 minipi=0⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅④
The following steps are to use ①~④ and the original formula to find ∣ ∣ w ⃗ ∣ ∣ ||\vec{w}||∣∣w∣∣ minimum value. First, we divide the left and right sides of equation ④ by 2 and multiply bypi p_ipi, the formula:
λ ipi 2 = 0 \lambda_ip_i^2=0lipi2=0
is doing this because there is api 2 p_i^2pi2, which can simplify the calculation to some extent. We substitute formula ③ into formula ④ and get:
λ i ( yi ∗ ( w ⃗ ⋅ xi ⃗ + b ) − 1 ) = 0 \lambda_i(y_i*(\vec{w}·\vec{x_i}+b)- 1)=0li(yi∗(w⋅xi+b)−1)=0
is very interesting. Before we got yi ∗ ( w ⃗ ⋅ xi ⃗ + b ) ≥ 1in the third stepyi∗(w⋅xi+b)≥1 , the above formula can only be established in two situations:
① y i ∗ ( w ⃗ ⋅ x i ⃗ + b ) − 1 ) > 0 y_i*(\vec{w}·\vec{x_i}+b)-1)>0 yi∗(w⋅xi+b)−1 ) 0 0 ,λ i = 0 \lambda_i=0li=0;
② y i ∗ ( w ⃗ ⋅ x i ⃗ + b ) − 1 = 0 y_i*(\vec{w}·\vec{x_i}+b)-1=0 yi∗(w⋅xi+b)−1=0 ,λ i ≠ 0 \lambda_i≠0li=0。
对于Ragerangi function L ( w , b , λ i , pi ) = ∣ ∣ w ⃗ ∣ ∣ 2 2 − ∑ i = 1 s λ i ∗ ( yi ∗ ( w ⃗ ⋅ xi ⃗ + b ) − 1 − pi 2 ) L(w,b,\lambda_i,p_i)=\frac{||\vec{w}||^2}{2}-\sum_{i=1}^s\lambda_i*(y_i*( \vec{w}\vec{x_i}+b)-1-p_i^2)L(w,b,li,pi)=2∣∣w∣∣2−∑i=1sli∗(yi∗(w⋅xi+b)−1−pi2) , when the constraints are not satisfied, that is, yi ∗ ( w ⃗ ⋅ xi ⃗ + b ) − 1 < 0 y_i*(\vec{w}·\vec{x_i}+b)-1<0yi∗(w⋅xi+b)−1<0 , ifλ i < 0 \lambda_i<0li<0,则 ∑ i = 1 s λ i ∗ ( y i ∗ ( w ⃗ ⋅ x i ⃗ + b ) − 1 − p i 2 ) > 0 \sum_{i=1}^s\lambda_i*(y_i*(\vec{w}·\vec{x_i}+b)-1-p_i^2)>0 ∑i=1sli∗(yi∗(w⋅xi+b)−1−pi2)>0,而 L ( w , b , λ i , p i ) L(w,b,\lambda_i,p_i) L(w,b,li,pi) will be smaller. According to the properties of the Lagrangian function, the value of the Lagrangian function is smaller if the constraints are met. This means thatλ i \lambda_iliIt is unreasonable to be less than 0, so it should be greater than or equal to 0.
We can also explain this problem through images.
We assume that it is a two-dimensional space. In this two-dimensional space, the horizontal and vertical coordinates are w 1 w_1w1Sum w 2 w_2w2, N ∣ ∣ w ⃗ ∣ ∣ = w 1 2 + w 2 2 ||\vec{w}||=\sqrt{w_1^2+w_2^2}∣∣w∣∣=w12+w22The geometric meaning expressed on the image is a circle with the center as the origin, and the radius is w 1 2 + w 2 2 \sqrt{w_1^2+w_2^2}w12+w22circle.

The optimization problem we require is min ∣ ∣ w ⃗ ∣ ∣ 2 2 min\frac{||\vec{w}||^2}{2}min2∣∣w∣∣2, which is ∣ ∣ w ⃗ ∣ ∣ ||\vec{w}||∣∣w∣∣ It is obtained when the minimum value is taken. And since∣ ∣ w ⃗ ∣ ∣ ||\vec{w}||∣∣w∣∣ is the radius of the circle, so we want the circle to be as small as possible.
Now we add constraints. The first constraint is g 1 = y 1 ∗ ( w ⃗ ⋅ x 1 ⃗ + b ) − 1 ≥ 0 g_1=y_1*(\vec{w}·\vec{x_1}+b)-1≥0g1=y1∗(w⋅x1+b)−1≥0 , it means on the image that the feasible area is above a straight line (light green), as shown in the following figure:
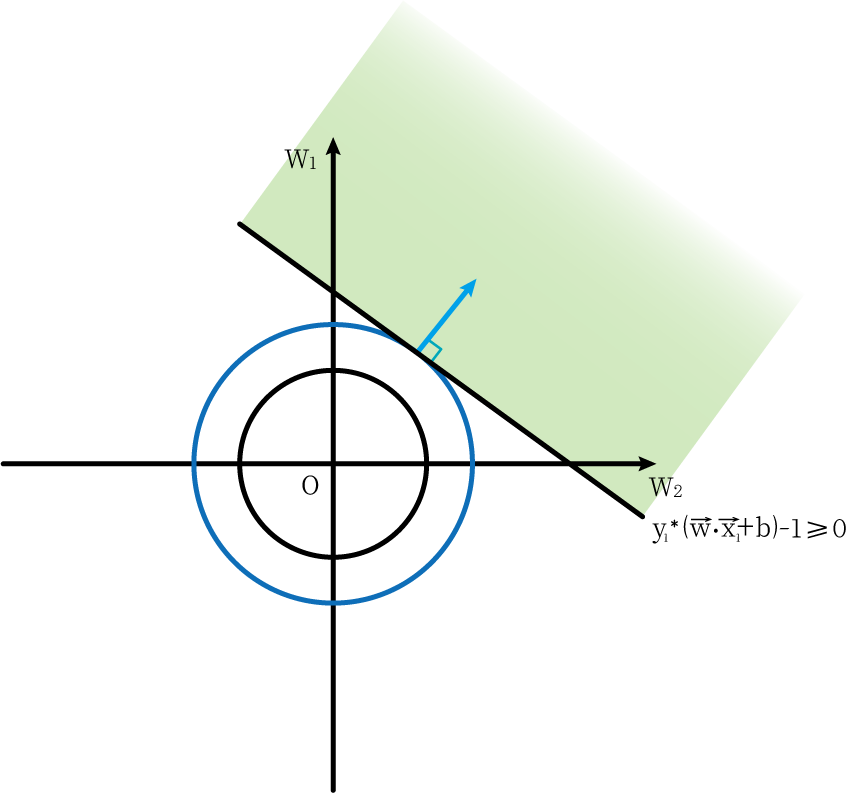
And the situation where a point on the circle can be within the feasible area and the radius of the circle is the smallest is that the circle is tangent to the line (indicated by the dark blue circle in the figure)
At this point we add another restriction, g 2 = y 2 ∗ ( w ⃗ ⋅ x 2 ⃗ + b ) − 1 ≥ 0 g_2=y_2*(\vec{w}·\vec{x_2}+b)-1 ≥0g2=y2∗(w⋅x2+b)−1≥0 . At this time, under the two constraints, the smallest circle is the circle passing through the intersection of two straight lines. At this timew ⃗ = ( w 1 , w 2 ) \vec{w}=(w_1,w_2)w=(w1,w2) direction (represented by the red line) as long as it is within two straight lines.
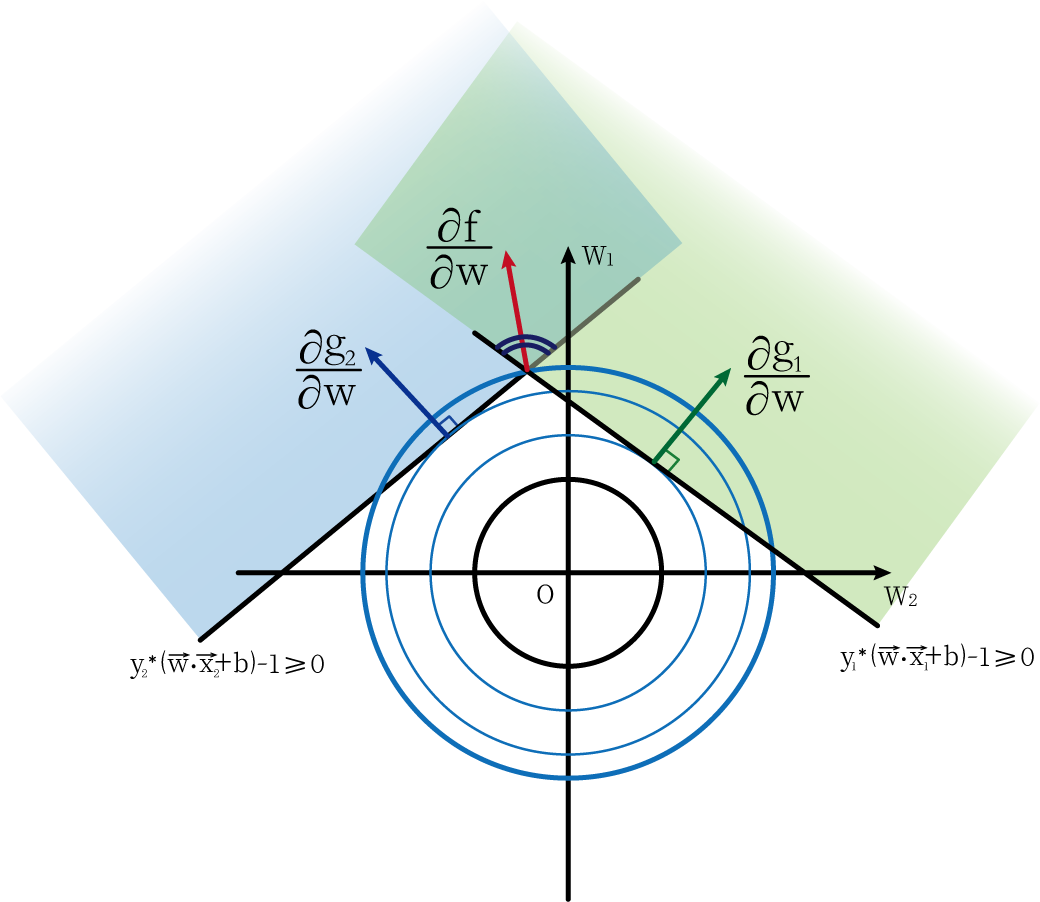
Through the intuitive understanding of the above figure, we can also get the following formula: Vector ∂ f ∂ w \frac{\partial{f}}{\partial{w}}∂w∂fCan be obtained by ∂ g 1 ∂ w and ∂ g 2 ∂ w \frac{\partial{g_1}}{\partial{w}} and \frac{\partial{g_2}}{\partial{w}}∂w∂g1and∂w∂g2Linear expression, and their coefficients λ 1 \lambda_1l1and λ 2 \lambda_2l2Both are non-negative numbers (understood intuitively or with vector triangles).
∂ f ∂ w = λ 1 ∂ g 1 ∂ w + λ 2 ∂ g 2 ∂ w \frac{\partial{f}}{\partial{w}}=\lambda_1\frac{\partial{g_1}}{\ partial{w}}+\lambda_2\frac{\partial{g_2}}{\partial{w}}∂w∂f=l1∂w∂g1+l2∂w∂g2
The above image can also help us understand, λ i \lambda_iliWhy is greater than or equal to 0. We also get the fifth condition:
λ i ≥ 0 ⋅ ⋅ ⋅ ⋅ ⋅ ⋅ ⋅ ⋅ ⋅ ⋅ ⋅ ⋅ ⑤ \lambda_i≥0···········⑤li≥0⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⑤
In summary, the above five conditions that we have reached and understood, or so-called KKT conditions:
w ⋅ ⋅ ① ① ① i = 1 s λ Iyi = 0 ⋅ ⋅ ⋅ ⋅ ⋅ ⋅ ⋅ ⋅ ⋅ ⋅ ⋅ ⋅ ⋅ ⋅ ⋅ ⋅ ⋅ ⋅ ⋅ ⋅ ⋅ ⋅ ⋅ ⋅ ⋅ ⋅ ⋅ ⋅ ⋅ ⋅ ⋅ ⋅ ⋅ ⋅ ⋅ ⋅ ⋅ ⋅ ⋅ ⋅ ⋅ ⋅ ⋅ ⋅ − − 1 - pi 2 = 0 ⋅ ⋅ ⋅ ⋅ ⋅ ⋅ ⋅ ⋅ ⋅ ⋅ ⋅ ⋅ ⋅ ⋅ ⋅ ⋅ ⋅ ⋅ ⋅ ⋅ ⋅ ⋅ ⋅ ⋅ ⋅ ⋅ ⋅ ⋅ ⋅ ⋅ ⋅ ⋅ ⋅ ⋅ ⋅ ⋅ ⋅ ⋅ ⋅ ⋅ ⋅ ⋅ ⋅ ⋅ ⋅ ⋅ ⋅ ⋅ ⋅ ⋅ ⋅ ⋅ ⋅ ⋅ ⋅ ⋅ ⋅ ⋅ ⋅ ⋅ ⋅ ⋅ ⋅ ⋅ ⋅ ④ ④ ④ ≥ ≥ ≥ ⋅ ⋅ ⋅ ⋅ ⋅ ⋅ ⋅ ⋅ ⋅ ⋅ ⋅ ⋅ ⋅ ⋅ ⋅ ⋅ ⋅ ⋅ ⋅ ⋅ ⋅ ⋅ ⋅ ⋅ ⋅ ⋅ ⋅ ⑤ ⋅ ⋅ ⋅ ⋅ ⑤ ⑤ ⋅ ⑤ ⑤ ⋅ ⑤ ⋅ ⑤ ⑤ ⑤ ⑤ 1}^s\lambda_iy_i\vec{x_i}=0 (1)\\\sum_{i=1}^s\lambda_iy_i=0 2 =0·················③\\2\lambda_ip_i=0············ ④\\\lambda_i≥0 ⑤w−i=1∑sliyixi=0⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅①i=1∑sliyi=0⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅②yi∗(w⋅xi+b)−1−pi2=0⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅③2 minipi=0⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅④li≥0⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅⑤
The dual problem is a common method for solving linear programming problems. The difficulty of solving a problem can sometimes be greatly simplified by converting a problem into its dual.
Let's review the original question first:
在 g i ( w , b ) = y i ∗ ( w ⃗ ⋅ x i ⃗ + b ) − 1 = p i 2 g_i(w,b)=y_i*(\vec{w}·\vec{x_i}+b)-1=p_i^2 gi(w,b)=yi∗(w⋅xi+b)−1=pi2condition, find ∣ ∣ w ⃗ ∣ ∣ 2 2 find \frac{||\vec{w}||^2}{2}beg2∣∣w∣∣2minimum value.
Let's first assume that the optimal solution to the original problem is w ∗ , b ∗ w^*, b^*w∗、b∗。然后设
q ( λ i ) = m i n ( L ( w , b , λ i ) ) = m i n ( ∣ ∣ w ⃗ ∣ ∣ 2 2 − ∑ i = 1 s λ i ∗ ( y i ∗ ( w ⃗ ⋅ x i ⃗ + b ) − 1 − p i 2 ) ) q(\lambda_i)=min(L(w,b,\lambda_i))=min(\frac{||\vec{w}||^2}{2}-\sum_{i=1}^s\lambda_i*(y_i*(\vec{w}·\vec{x_i}+b)-1-p_i^2)) q(λi)=min ( L ( w ,b,li))=min(2∣∣w∣∣2−i=1∑sli∗(yi∗(w⋅xi+b)−1−pi2))
Substitutionw ∗ , b ∗ w^*, b^*w∗、b∗ , possible-to-be-obtainable formula:
q ( λ i ) = min ( L ( w , b , λ i ) ) ≤ min ( L ( w ∗ , b ∗ , λ i ) ) q(\lambda_i)=min( L(w,b,\lambda_i))≤min(L(w^*,b^*,\lambda_i))q(λi)=min ( L ( w ,b,li))≤min ( L ( w∗,b∗,li))
即min ( ∣ ∣ w ⃗ ∣ ∣ 2 2 − ∑ i = 1 s λ i ∗ ( yi ∗ ( w ⃗ ⋅ xi ⃗ + b ) − 1 − pi 2 ) ) ≤ ∣ ∣ w ∗ ⃗ ∣ ∣ 2 2 − ∑ i = 1 s λ i ∗ ( yi ∗ ( w ∗ ⃗ ⋅ xi ⃗ + b ∗ ) − 1 − pi 2 ) min(\frac{||\vec{w}||^2}{2} -\sum_{i=1}^s\lambda_i*(y_i*(\vec{w}·\vec{x_i}+b)-1-p_i^2))≤\frac{||\vec{w^ *}||^2}{2}-\sum_{i=1}^s\lambda_i*(y_i*(\vec{w^*}\vec{x_i}+b^*)-1-p_i^ 2)min(2∣∣w∣∣2−∑i=1sli∗(yi∗(w⋅xi+b)−1−pi2))≤2∣∣w∗∣∣2−∑i=1sli∗(yi∗(w∗⋅xi+b∗)−1−pi2)
The presence of a less than or equal sign is defined by min minIt is determined by the min minimum function.
∑ i = 1 s λ i ∗ ( yi ∗ ( w ∗ ⃗ ⋅ xi ⃗ + b ∗ ) − 1 − pi 2 ) \sum_{i=1}^s\lambda_i*( y_i *(\vec{w^*}\vec{x_i}+b^*)-1-p_i^2)∑i=1sli∗(yi∗(w∗⋅xi+b∗)−1−pi2)必定 is greater than0,故
∣ ∣ w ∗ ⃗ ∣ ∣ 2 2 − ∑ i = 1 s λ i ∗ ( yi ∗ ( w ∗ ⃗ ⋅ xi ⃗ + b ∗ ) − 1 − pi 2 ) ≤ ∣ ∣ w ∗ ⃗ ∣ ∣ 2 2 \frac{||\vec{w^*}||^2}{2}-\sum_{i=1}^s\lambda_i*(y_i*(\vec{w^*}·\ vec{x_i}+b^*)-1-p_i^2)≤\frac{||\vec{w^*}||^2}{2}2∣∣w∗∣∣2−i=1∑sli∗(yi∗(w∗⋅xi+b∗)−1−pi2)≤2∣∣w∗∣∣2
And because w ∗ ⃗ \vec{w^*}w∗is the optimal solution to the original problem, so we can get:
∣ ∣ w ∗ ⃗ ∣ ∣ 2 2 ≤ ∣ ∣ w ⃗ ∣ ∣ 2 2 \frac{||\vec{w^*}||^2}{2} ≤\frac{||\vec{w}||^2}{2}2∣∣w∗∣∣2≤2∣∣w∣∣2
So we can get the following inequality chain:
q ( λ i ) ≤ min ( L ( w ∗ , b ∗ , λ i ) ) ≤ ∣ ∣ w ∗ ⃗ ∣ ∣ 2 2 ≤ ∣ ∣ w ⃗ ∣ ∣ 2 2 q( \lambda_i)≤min(L(w^*,b^*,\lambda_i))≤\frac{||\vec{w^*}||^2}{2}≤\frac{||\vec{ w}||^2}{2}q(λi)≤min ( L ( w∗,b∗,li))≤2∣∣w∗∣∣2≤2∣∣w∣∣2
We assume that λ i ∗ is q ( λ i ) \lambda_i^* is q(\lambda_i)li∗is q ( λi) is the optimal solution.∪q
( λ i ) ≤ q ( λ i ∗ ) ≤ ∣ ∣ w ∗ ⃗ ∣ ∣ 2 2 ≤ ∣ ∣ w ⃗ ∣ ∣ 2 2 q(\lambda_i)≤q(\lambda_i^* )≤\frac{||\vec{w^*}||^2}{2}≤\frac{||\vec{w}||^2}{2}q(λi)≤q(λi∗)≤2∣∣w∗∣∣2≤2∣∣w∣∣2
Well, at this point we can transform the original problem into a dual problem.
Original question:
- 在 g i ( w , b ) = y i ∗ ( w ⃗ ⋅ x i ⃗ + b ) − 1 ≥ 0 g_i(w,b)=y_i*(\vec{w}·\vec{x_i}+b)-1≥0 gi(w,b)=yi∗(w⋅xi+b)−1≥Under the condition of 0 , find ∣ ∣ w ⃗ ∣ ∣ 2 2 find \frac{||\vec{w}||^2}{2}beg2∣∣w∣∣2minimum value.
Dual problem:
- 在λ i ≥ 0 \lambda_i≥0li≥0的条件下,求 q ( λ i ) = m i n ( L ( w , b , λ i ) ) q(\lambda_i)=min(L(w,b,\lambda_i)) q(λi)=min ( L ( w ,b,li)) maximum value.
当 q ( λ i ∗ ) = ∣ ∣ w ∗ ⃗ ∣ ∣ 2 2 q(\lambda_i^*)=\frac{||\vec{w^*}||^2}{2} q(λi∗)=2∣∣w∗∣∣2When , the two problems are strong dual problems, and the optimal solution should be obtained at the same time. The proof is as follows:
Since
q ( λ i ) ≤ ∣ ∣ w ⃗ ∣ ∣ 2 2 q(\lambda_i)≤\frac{||\vec{w}||^2}{2}q(λi)≤2∣∣w∣∣2
So
q ( λ i ∗ ) ≤ ∣ ∣ w ⃗ ∣ ∣ 2 2 q(\lambda_i^*)≤\frac{||\vec{w}||^2}{2}q(λi∗)≤2∣∣w∣∣2
故
∣ ∣ w ∗ ⃗ ∣ ∣ 2 2 ≤ ∣ ∣ w ⃗ ∣ ∣ 2 2 \frac{||\vec{w^*}||^2}{2}≤\frac{||\vec{w} ||^2}{2}2∣∣w∗∣∣2≤2∣∣w∣∣2
And according to the previous q ( λ i ) ≤ min ( L ( w ∗ , b ∗ , λ i ) ) ≤ ∣ ∣ w ∗ ⃗ ∣ ∣ 2 2 q(\lambda_i)≤min(L(w^*, b^*,\lambda_i))≤\frac{||\vec{w^*}||^2}{2}q(λi)≤min ( L ( w∗,b∗,li))≤2∣∣w∗∣∣2,Let
q ( λ i ) ≤ ∣ ∣ w ∗ ⃗ ∣ ∣ 2 2 = q ( λ i ∗ ) q(\lambda_i)≤\frac{||\vec{w^*}||^2}{2} =q(\lambda_i^*)q(λi)≤2∣∣w∗∣∣2=q(λi∗)
soq ( λ i ∗ ) q(\lambda_i^*)q(λi∗)为 q ( λ i ) q(\lambda_i) q(λi) maximum solution.
Therefore, it is proved that under the condition of strong duality, the optimal solutions of the primal problem and the dual problem are obtained at the same time.
According to the previous Lagrange function, we have obtained:
max ( q ( λ ) ) = max ( min ( ∣ ∣ w ⃗ ∣ ∣ 2 ) − ∑ i = 1 s λ i ∗ ( yi ∗ ( w ∗ ⃗ ⋅ xi ⃗ + b ∗ ) − 1 ) ) ) max(q(\lambda))=max(min(\frac{||\vec{w}||}{2})-\sum_{i=1}^ s\lambda_i*(y_i*(\vec{w^*}\vec{x_i}+b^*)-1)))max(q(λ))=max(min(2∣∣w∣∣)−i=1∑sli∗(yi∗(w∗⋅xi+b∗)−1 )))
将KKT condition代入化简可得:
max ( q ( λ ) ) = max ( ∑ i = 1 s λ i − 1 2 ∑ i = 1 s ∑ j = 1 s λ i λ jyiyjxi ⃗ ⋅ xj ⃗ ) max(q(\lambda))=max(\sum_{i=1}^s{\lambda_i}-\frac{1}{2}\sum_{i=1}^{s}\sum_{j =1}^s\lambda_i\lambda_jy_iy_j\vec{x_i}·\vec{x_j})max(q(λ))=max(i=1∑sli−21i=1∑sj=1∑sliljyiyjxi⋅xj)
Above we derived the following formula:
① y i ∗ ( w ⃗ ⋅ x i ⃗ + b ) − 1 > 0 y_i*(\vec{w}·\vec{x_i}+b)-1>0 yi∗(w⋅xi+b)−1>0 ,λ i = 0 \lambda_i=0li=0;
② y i ∗ ( w ⃗ ⋅ x i ⃗ + b ) − 1 = 0 y_i*(\vec{w}·\vec{x_i}+b)-1=0 yi∗(w⋅xi+b)−1=0 ,λ i ≠ 0 \lambda_i≠0li=0。
At the same time, we also deduce that λ i ≥ 0 \lambda_i≥0li≥0 for this condition.
According to the above two conditions we can draw some conclusions.
-
If the data points are in the positive and negative hyperplane w ⃗ ⋅ xi ⃗ + b ± 1 = 0 \vec{w}·\vec{x_i}+b±1=0w⋅xi+b±1=0 , because∣ yi ∣ = 1 |y_i|=1∣yi∣=1,所以 y i ∗ ( w ⃗ ⋅ x i ⃗ + b ) − 1 = 0 y_i*(\vec{w}·\vec{x_i}+b)-1=0 yi∗(w⋅xi+b)−1=0 , it belongs to the case ②, soλ i > 0 \lambda_i>0li>0。
-
If the data point is not on the positive and negative hyperplane w ⃗ ⋅ xi ⃗ + b ± 1 = 0 \vec{w}·\vec{x_i}+b±1=0w⋅xi+b±1=0 , it belongs to the case ①, soλ i = 0 \lambda_i=0li=0 . Thenλ i = 0 \lambda_i=0li=0 Substitutableλ i ( yi ∗ ( w ⃗ ⋅ xi ⃗ + b ) − 1 ) = 0 \lambda_i(y_i*(\vec{w}\vec{x_i}+b)-1)=0li(yi∗(w⋅xi+b)−1)=0。
The above derivation shows that we are calculating the hyperplane weight value wwWhen w only needs to use support vectors (data points on the positive and negative hyperplanes), no non-support vectors are required.
With the previous foreshadowing, we can get the support vector machine SVM algorithm.
① Obtain λ i \lambda_i through the following questionslivaluemax
( q ( λ ) ) = max ( ∑ i = 1 s λ i − 1 2 ∑ i = 1 s ∑ j = 1 s λ i λ jyiyjxi ⃗ ⋅ xj ⃗ ) where λ i ≥ 0 max(q( \lambda))=max(\sum_{i=1}^s{\lambda_i}-\frac{1}{2}\sum_{i=1}^{s}\sum_{j=1}^s\ lambda_i\lambda_jy_iy_j\vec{x_i}·\vec{x_j})\\ among which\lambda_i≥0max(q(λ))=max(i=1∑sli−21i=1∑sj=1∑sliljyiyjxi⋅xj)where λi≥0
② Underlying KKT condition
w ⃗ = ∑ i = 1 s λ iyixi ⃗ \vec{w}=\sum_{i=1}^s\lambda_iy_i\vec{x_i}w=i=1∑sliyixi
can find w ⃗ \vec{w}w
title
③ 根据 y i ∗ ( w ⃗ ⋅ x i ⃗ + b ) − 1 = 0 y_i*(\vec{w}·\vec{x_i}+b)-1=0 yi∗(w⋅xi+b)−1=0 solves forbbb
Dimension Ascension Transformation and Kernel Techniques
Let's look at the following scenario:
For example, now there are some data points on the 1D x-axis, red and blue. We now want to use a function (a constant for one dimension) to divide the red and blue points. It can be seen intuitively that this is impossible.

However, if the above picture is produced by projecting a two-dimensional plane figure onto the one-dimensional x-axis, we may find a different world if we "restore" the two-dimensional plane:
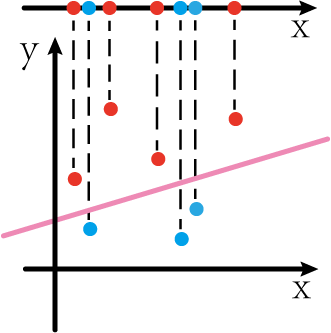
As shown above, if we can convert one-dimensional data points into two-dimensional data points by some methods, then we seem to be able to easily divide the data points (the pink line in the figure)
This process is known as dimension-up conversion.
We can also use this method in support vector machines. Let's review the optimization equation first:
max ( q ( λ i ) ) = max ( ∑ i = 1 s λ i − 1 2 ∑ i = 1 s ∑ j = 1 s λ i λ jyiyjxi ⃗ ⋅ xj ⃗ ) where λ i ≥ 0 max(q(\lambda_i))=max(\sum_{i=1}^s{\lambda_i}-\frac{1}{2}\sum_{i=1}^{s}\sum_{j =1}^s\lambda_i\lambda_jy_iy_j\vec{x_i}·\vec{x_j})\\Where\lambda_i≥0max(q(λi))=max(i=1∑sli−21i=1∑sj=1∑sliljyiyjxi⋅xj)where λi≥0
xi ⃗ ⋅ xj ⃗ \vec{x_i}·\vec{x_j}xi⋅xjIndicates the dot product of the corresponding vector coordinates in the original dimension. But in fact, the above equation is unsolvable, so we can use the kernel technique to perform dimension-boosting transformation. We will pass a function T ( x ) T(x)T ( x ) performs a dimension-boosting transformation operation, and this function is called a dimension conversion function. Through the dimension conversion function, the originalxi ⃗ \vec{x_i}xibecomes T ( xi ⃗ ) T(\vec{x_i})T(xi),xj ⃗ \vec{x_j}xjbecomes T ( xj ⃗ ) T(\vec{x_j})T(xj) . So the original problem is transformed into the following formula:
max ( q ( λ i ) ) = max ( ∑ i = 1 s λ i − 1 2 ∑ i = 1 s ∑ j = 1 s λ i λ jyiyj T ( xi ⃗ ) ⋅ T ( xj ⃗ ) ) where λ i ≥ 0 max(q(\lambda_i))=max(\sum_{i=1}^s{\lambda_i}-\frac{1}{2}\sum_{i= 1}^{s}\sum_{j=1}^s\lambda_i\lambda_jy_iy_jT(\vec{x_i})·T(\vec{x_j}))\\where \lambda_i≥0max(q(λi))=max(i=1∑sli−21i=1∑sj=1∑sliljyiyjT(xi)⋅T(xj))where λi≥0
In fact, here we can passxi ⃗ , xj ⃗ \vec{x_i}, \vec{x_j}xi、xj写出T ( xi ⃗ ) 、 T ( xj ⃗ ) T(\vec{x_i})、T(\vec{x_j})T(xi)、T(xj) , and then perform the dot product operation, or directly setK ( xi ⃗ , xj ⃗ ) = T ( xi ⃗ ) ⋅ T ( xj ⃗ ) K(\vec{x_i},\vec{x_j})=T( \vec{x_i}) T(\vec{x_j})K(xi,xj)=T(xi)⋅T(xj) , and then calculate. The difference between the two is that the latter is directlyxi ⃗ ⋅ xj ⃗ \vec{x_i}·\vec{x_j}xi⋅xjIt is regarded as an unknown number and substituted into the calculation as a whole. And here K ( xi ⃗ , xj ⃗ ) K(\vec{x_i},\vec{x_j})K(xi,xj) is the kernel function. Its general expression is as follows:
K ( xi ⃗ , xj ⃗ ) = ( c + xi ⃗ ⋅ xj ⃗ ) d K(\vec{x_i},\vec{x_j})=(c+\vec{x_i}\vec {x_j})^dK(xi,xj)=(c+xi⋅xj)d
then parametersc and dc and dWhat is the role of c and d ?
for the same ddd , differentccFor c ,ccc can control the presence or absence of low-order terms and the coefficient of low-order terms;
for the same ccc , differentddFor d , ddThe size of d determines the highest dimension size.
In addition, the kernel function can also be formed by a linear combination of multiple kernel functions, such as: K 1 ′ ( xi ⃗ , xj ⃗ ) + K 2 ′ ( xi ⃗ , xj ⃗ ) K_1'(\vec{x_i} ,\vec{x_j})+K_2'(\vec{x_i},\vec{x_j})K1′(xi,xj)+K2′(xi,xj)
There is also a special kernel function that converts two dimensions into infinite dimensions. This kernel function is a Gaussian kernel function (RBF), and its formula is as follows:
K ( xi ⃗ , xj ⃗ ) = e − γ ∣ ∣ xi ⃗ − xj ⃗ ∣ ∣ 2 K(\vec{x_i},\vec{x_j} )=e^{-\gamma||\vec{x_i}-\vec{x_j}||^2}K(xi,xj)=e−γ∣∣xi−xj∣∣2
soft interval
The concept of soft and hard intervals has been explained in the previous article, and we will discuss them in detail below.

As shown in the figure above, there is a point A that violates the constraints and is within the yellow and black lines.
We know that the hard margin constraints are yi ∗ ( w ∗ ⃗ ⋅ xi ⃗ + b ∗ ) − 1 ≥ 0 y_i*(\vec{w^*}·\vec{x_i}+b^*)-1≥0yi∗(w∗⋅xi+b∗)−1≥0 . If point A violates the constraints, then point A satisfies the formulaya ∗ ( w ∗ ⋅ xa ⃗ + b ∗ ) − 1 < 0 y_a*(\vec{w^*}·\vec{x_a}+b^* )-1<0ya∗(w∗⋅xa+b∗)−1 < 0 . We want to convert inequality into equality, we need aϵ a \epsilon_aϵaTo measure the error, the formula is as follows:
ϵ a = 1 − ya ∗ ( w ∗ ⃗ ⋅ xa ⃗ + b ∗ ) \epsilon_a=1-y_a*(\vec{w^*}·\vec{x_a}+b^ *)ϵa=1−ya∗(w∗⋅xa+b∗ )
So the soft margin optimization problem is as follows:
在 g i ( w , b ) = y i ∗ ( w ⃗ ⋅ x i ⃗ + b ) − 1 > 0 g_i(w,b)=y_i*(\vec{w}·\vec{x_i}+b)-1>0 gi(w,b)=yi∗(w⋅xi+b)−1>0和 m a x ( 0 , 1 − y a ∗ ( w ∗ ⃗ ⋅ x a ⃗ + b ∗ ) ) max(0,1-y_a*(\vec{w^*}·\vec{x_a}+b^*)) max(0,1−ya∗(w∗⋅xa+b∗ ))condition,
求 ∣ ∣ w ⃗ ∣ ∣ 2 2 + C ∑ i = 1 s ϵ i 求\frac{||\vec{w}||^2}{2}+C\sum_{i=1}^s{\ epsilon_i}beg2∣∣w∣∣2+C∑i=1sϵiminimum value.
We can compare with the previous hard-margin optimization problem:
在 g i ( w , b ) = y i ∗ ( w ⃗ ⋅ x i ⃗ + b ) − 1 > 0 g_i(w,b)=y_i*(\vec{w}·\vec{x_i}+b)-1>0 gi(w,b)=yi∗(w⋅xi+b)−Under the condition of 1 > 0 ,
Find ∣ ∣ w ⃗ ∣ ∣ 2 2 Find \frac{||\vec{w}||^2}{2}beg2∣∣w∣∣2minimum value.
In fact, the biggest difference between the soft interval and the hard interval is that there is one more term
C ∑ i = 1 s ϵ i C\sum_{i=1}^s{\epsilon_i}Ci=1∑sϵi
The meaning of this item is that all errors ∑ i = 1 s ϵ i \sum_{i=1}^s{\epsilon_i}∑i=1sϵiConsidering the optimization problem, this can also reduce the error when finding the minimum value. while the constant CCC is artificially stipulated by us, and it plays a role in adjusting the tolerance of errors.
- C C The larger C , it means that forϵ i \epsilon_iϵiThe smaller the tolerance, that is, the fewer errors in the final calculated results;
- C CThe smaller C is, it means that forϵ i \epsilon_iϵiThe greater the tolerance, that is, the greater the error in the final calculated result;