1. Basic concepts
Elasticsearch is also a full-text search library based on Lucene, and its essence is to store data. Many concepts are similar to MySQL.
Comparison relationship:
Index (indices) ---------------------Databases Database
type (type) ------------------ --------Table data table [7.x obsolete]
document (Document)----------------------Row row
field (Field)- ------------------------Columns column
It should be noted that Elasticsearch itself is distributed, so even if you only have one node, Elasticsearch will perform fragmentation and copy operations on your data by default. When you add new data to the cluster, the data will also be in the newly added Nodes are balanced.
2. Index operation
1. Query index
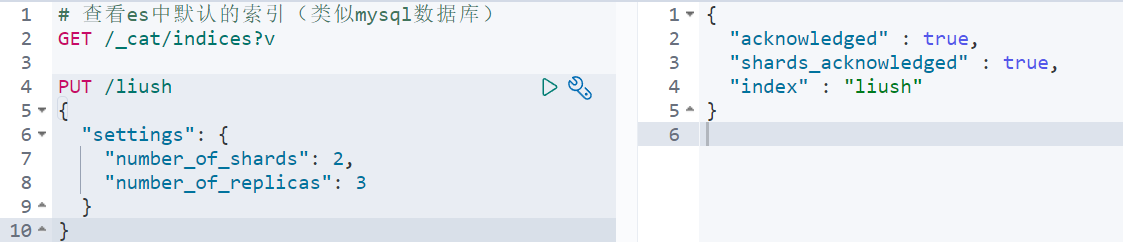
Check which index libraries are available in es (similar to mysql database) : GET /_cat/indices?v
# es默认对中文的分词 支持不友好,它认为一个字代表一个词
# 查看es的分词方式
GET _analyze
{
"text": ["我是中国人"]
}
{
"text": "我爱你你爱我"
}
# 给es配置中文分词器:ik分词器
# 指定ik分词器分词:ik_smart粗粒度分词
# ik_max_word细粒度分词
GET _analyze
{
"text": "咖喱人,鸡你太美,你这个老六",
"analyzer": "ik_max_word"
}
There will be an index named .kibana and .kibana_task_manager by default in es
| field name | Meaning |
|---|---|
| health | green (cluster complete) yellow (single point normal, cluster incomplete) red (single point is not normal) |
| status | Can it be used |
| index | index name |
| uuid | index uniform number |
| at | how many master nodes |
| rep | How many slave nodes |
| docs.count | number of documents |
| docs.deleted | How many documents were deleted |
| store.size | Overall footprint |
| pri.store.size | The master node accounts for |
2. Create an index
PUT /indexname
Optional parameters: specify the shard and copy, the default shard is 3, and the copy is 2.
PUT /liush
{
"settings": {
"number_of_shards": 2,
"number_of_replicas": 3
}
}
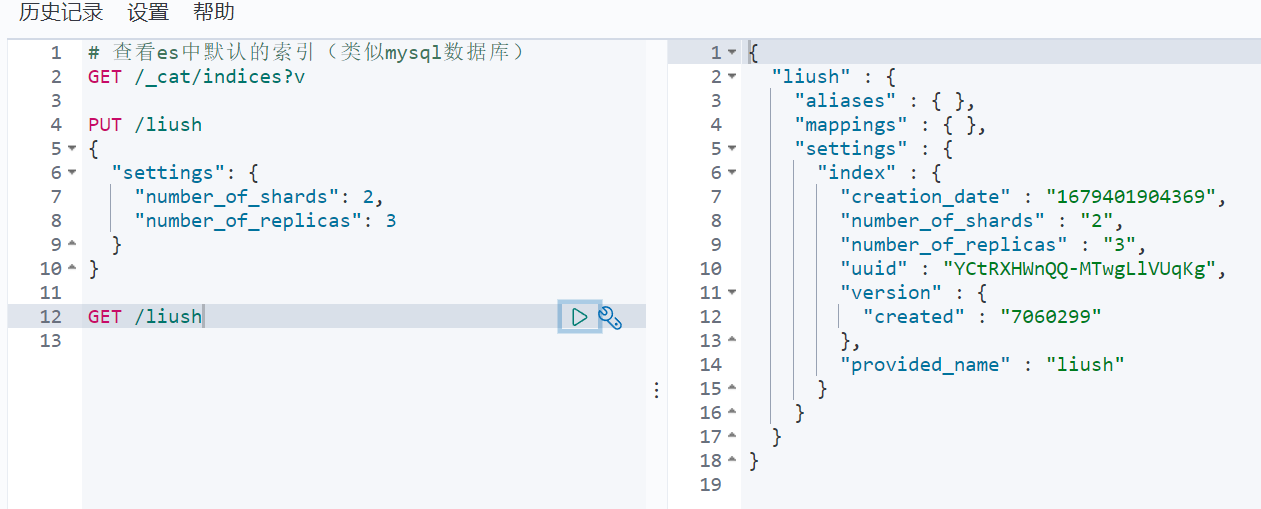
3. View the specific information of the index
GET /indexname
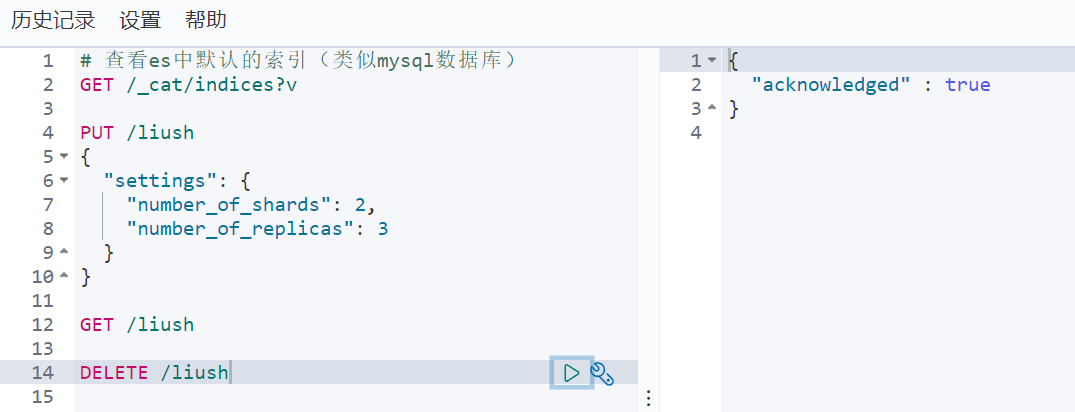
4. Delete the index
DELETE /index library name
3. Mapping configuration (_mapping)
With the index, the next step is to add data. However, the mapping must be defined before data can be added.
What is a mapping?
Mapping is the process of defining a document, which fields the document contains, whether these fields are saved, indexed, word-segmented, etc.
Only when the configuration is clear, Elasticsearch will help us create the index library (not necessarily)
1. Create a mapping field
PUT /index library name/_mapping
{ "properties": { "field name": { "type": "type", "index": true, "store": true, "analyzer": "word breaker" } } }
Field name: Similar to the column name, many fields can be specified under properties.
Each field can have many attributes. For example:
type:类型,String(text keyword) Numeric(long integer float double) date boolean
index: whether to index, the default is true
store: Whether to store, the default is false, even if it is false, it will be stored in _source, if it is true, an additional copy will be stored
analyzer: word breaker, here use ik word breaker: or
ik_max_wordik_smart
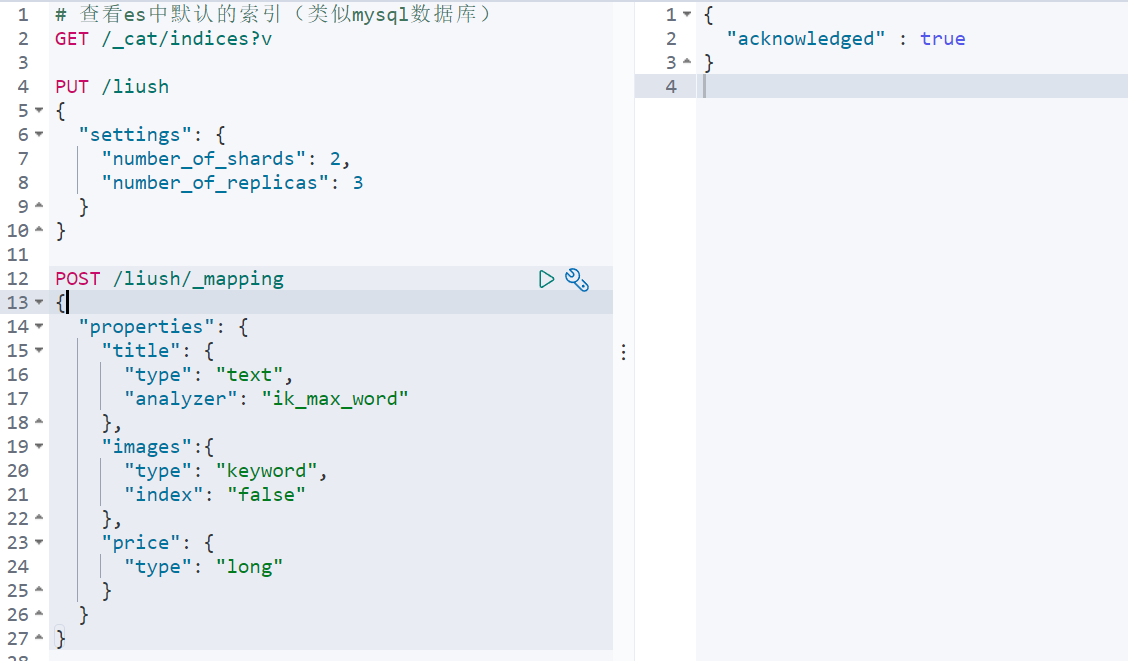
PUT /liush
{
"settings": {
"number_of_shards": 2,
"number_of_replicas": 3
}
}
POST /liush/_mapping
{
"properties": {
"title": {
"type": "text",
"analyzer": "ik_max_word"
},
"images":{
"type": "keyword",
"index": "false"
},
"price": {
"type": "long"
}
}
}2. View the mapping relationship
Syntax: GET /index library name/_mapping
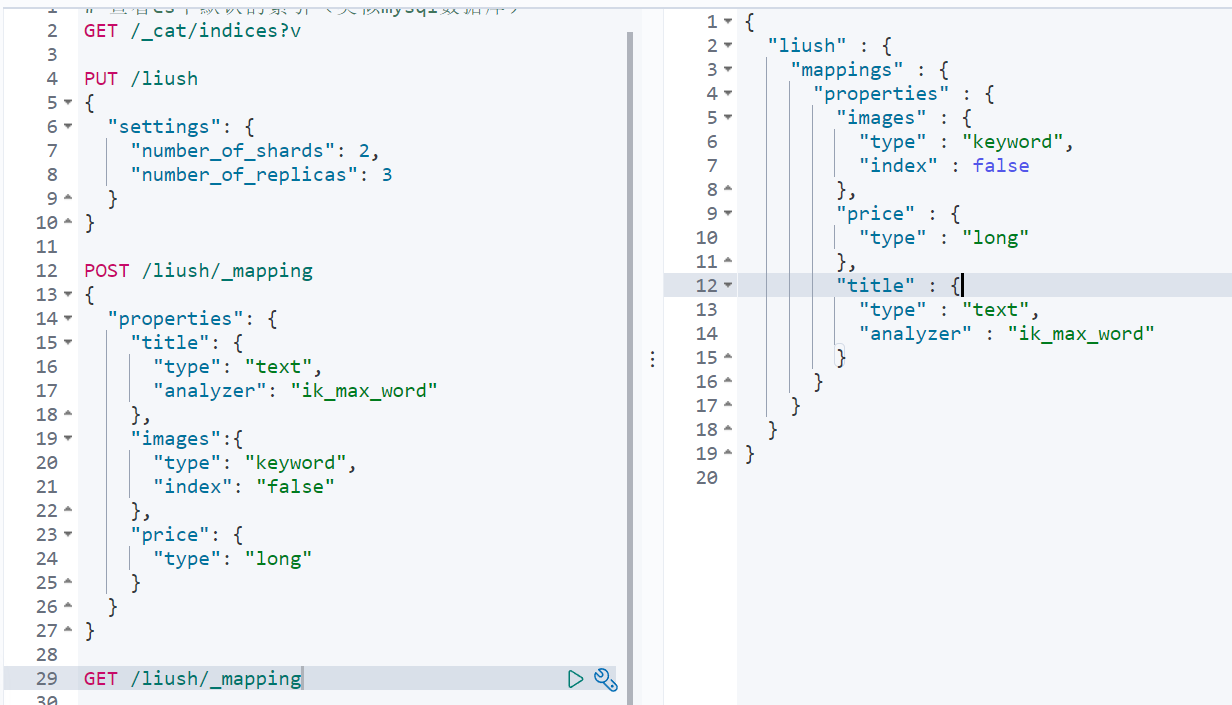
4. New document (document)
With indexes, types, and mappings, you can add, delete, modify, and query documents.
1. Basic gameplay
If we want to specify the id when we add it ourselves, we can do this:
POST /index library name/_doc/id value
{ ... }
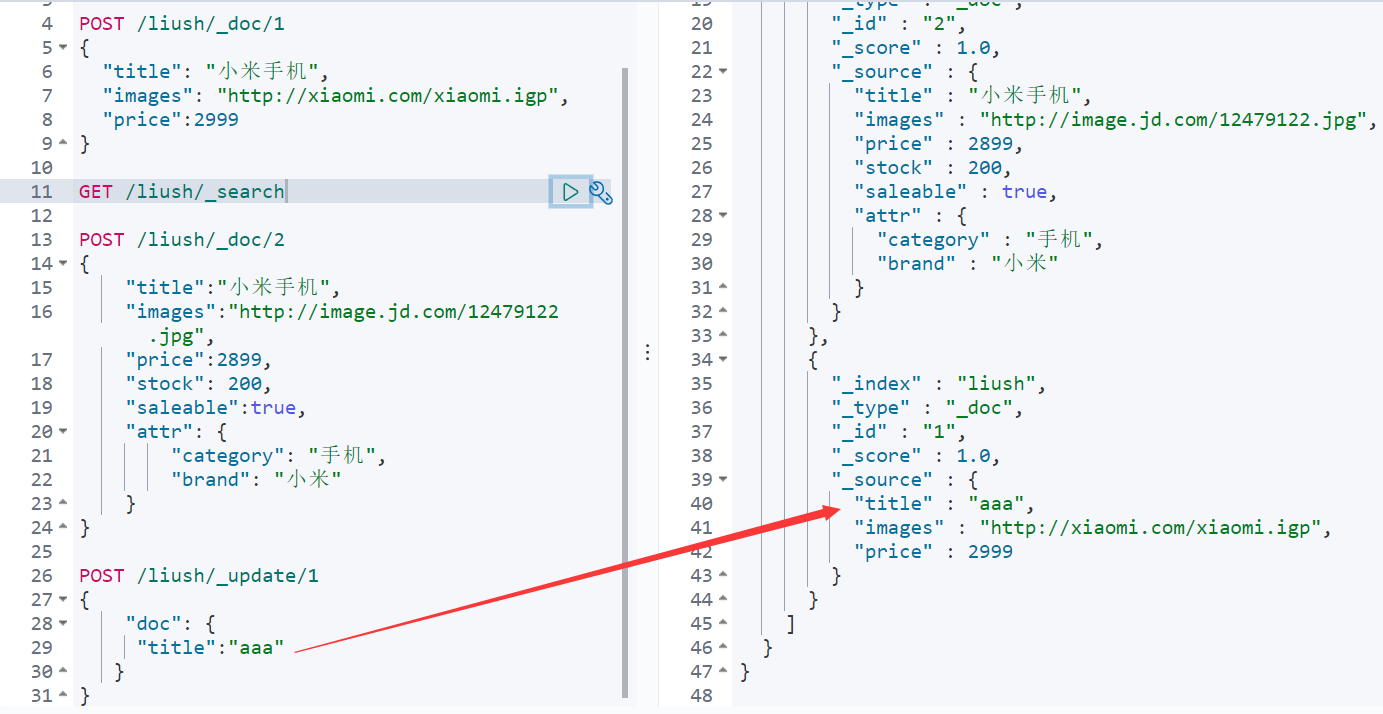
POST /liush/_doc/1
{
"title": "小米手机",
"images": "http://xiaomi.com/xiaomi.igp",
"price":2999
}
GET /liush/_search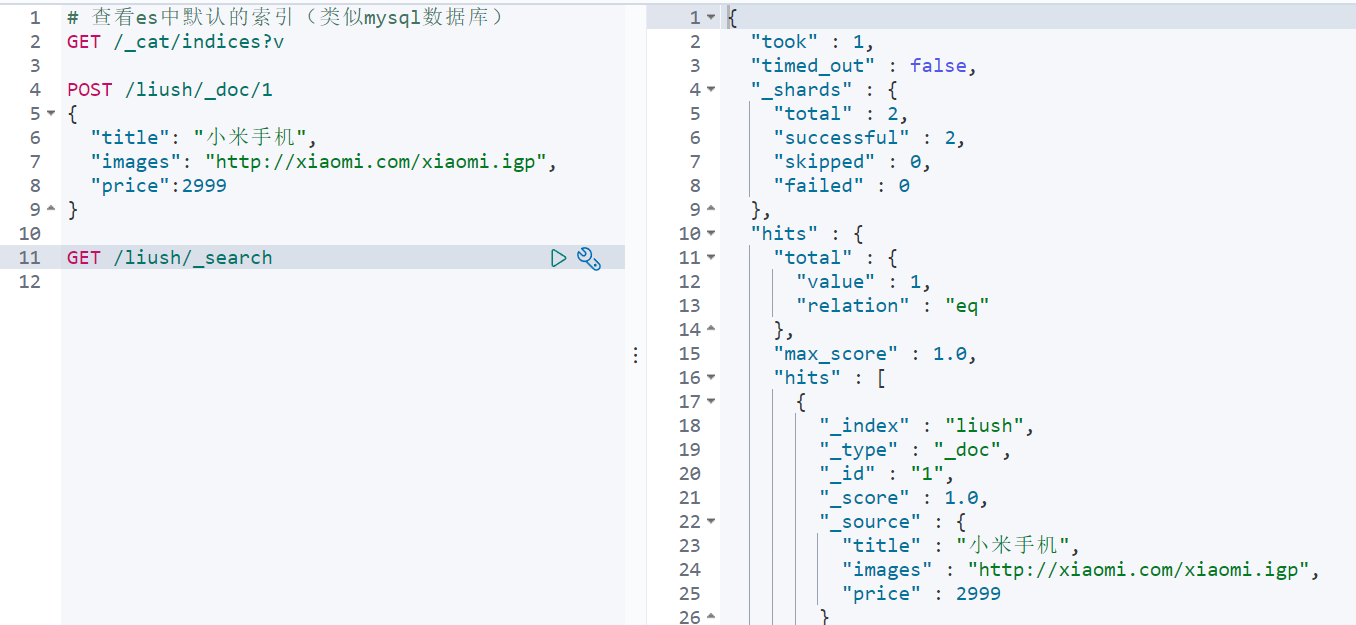
2. Intelligent judgment
In fact, Elasticsearch is very smart. You don't need to set any mappings for the index library. It can also judge the type according to the data you input and dynamically add data mappings.
POST /liush/_doc/2
{
"title":"小米手机",
"images":"http://image.jd.com/12479122.jpg",
"price":2899,
"stock": 200,
"saleable":true,
"attr": {
"category": "手机",
"brand": "小米"
}
}We additionally added several fields of stock inventory, whether the saleable is on the shelves, and other attributes of attr.
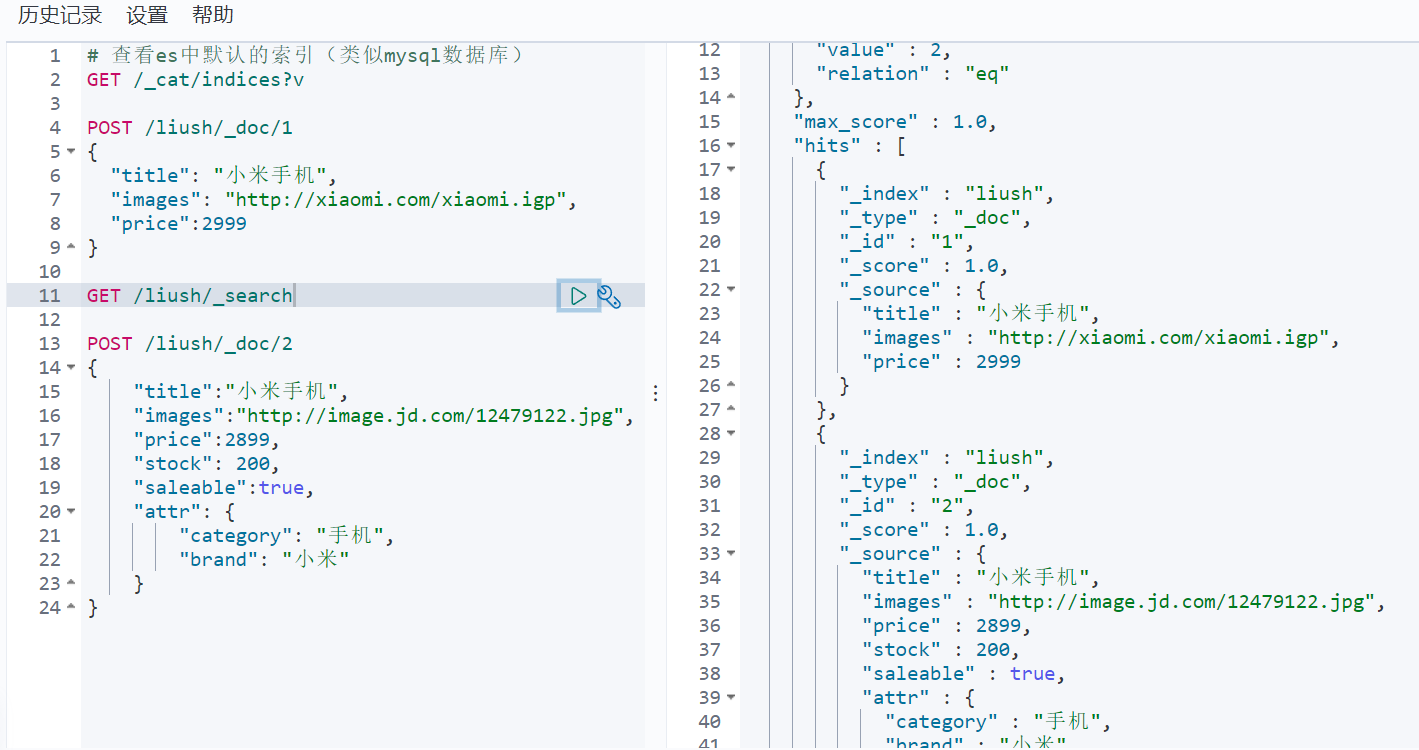
stock, saleable, and attr have all been mapped successfully.
If it is string type data, two types will be added: text + keyword. As in the above example category and brand
5. Delete data
Deletion uses the DELETE request. Similarly, it needs to be deleted according to the id:
Syntax: DELETE /index library name/_doc/id value
example: DELETE /liush/_doc/2
6. Update documents
Syntax:
POST /index library name/_update/id value
{ doc:{ "attribute":"value" } }
POST /liush/_update/1
{
"doc": {
"title":"aaa"
}
}