Table of contents
1 Definition of activation function
2 The role of activation function in deep learning
3 What is the significance of choosing a suitable activation function for neural networks
4.2 sigmoid activation function
4.4 softmax activation function
1 Definition of activation function
The activation function is a function that runs on the neurons of the artificial neural network and is responsible for mapping the input of the neuron to the output.
Activation functions are very important for artificial neural network models to learn and understand very complex and nonlinear functions. They introduce nonlinear properties into our network.

2 The role of activation function in deep learning
If you don’t use the activation function (in fact, the activation function is f(x) = x), in this case, the input of each layer of your node is a linear function of the output of the upper layer, which is easy to verify, no matter how many layers your neural network has , the output is a linear combination of the input, which is equivalent to the effect of no hidden layer. In this case, it is the most primitive perceptron (Perceptron), so the approximation ability of the network is quite limited. For the above reasons, we decided to introduce a nonlinear function as the activation function, so that the expressive ability of the deep neural network is more powerful (it is no longer a linear combination of inputs, but can almost approximate any function).
Activation functions have properties such as nonlinearity, differentiability, monotonicity, and range of output values.
3 What is the significance of choosing a suitable activation function for neural networks
The neural network model with a large number of layers will have gradient disappearing problem and gradient exploding problem during training. The gradient disappearance problem and the gradient explosion problem generally become more and more obvious as the number of network layers increases. The disappearance of the gradient will make the network training immobile, and even make the learning of the model stagnate. Gradient explosion generally occurs when the deep network and the weight initialization value are too large . The gradient explosion will cause network instability. The best result is that it cannot learn from the training data, and the worst result is NaN that cannot be updated. Weights.
For example, a network contains three hidden layers. When the gradient disappearance problem occurs, the weight update of hidden layer 3 near the output layer is relatively normal, but the weight update of hidden layer 1 near the input layer will become very slow, resulting in The hidden layer weights of the layers are almost unchanged and are still close to the initialized weights. This leads to hidden layer 1 being equivalent to just a mapping layer, which makes a function mapping for all inputs. At this time, the learning of this deep neural network is equivalent to learning only the hidden layer network of the last few layers. The situation of gradient explosion is: when the initial weight is too large, the weight of hidden layer 1 near the input layer changes faster than the weight of hidden layer 3 near the output layer, which will cause the problem of gradient explosion.
Both gradient disappearance and gradient explosion problems are caused by the network being too deep and the update of network weights unstable, which is essentially due to the multiplication effect in gradient backpropagation. For the more general gradient disappearance problem, three solutions can be considered:
1. Replace the sigmoid function with ReLU, etc.
2. 用Batch Normalization。
3. The structural design of LSTM can also improve the gradient disappearance problem in RNN.
4 Common activation functions
Early research on neural networks mainly used sigmoid function or tanh function, the output is bounded, and it is easy to serve as the input of the next layer.
In recent years, the Relu function and its improved types (such as Leaky-ReLU, P-ReLU, R-ReLU, etc.) have been widely used in multi-layer neural networks. Let's summarize these activation functions below:
4.1 Relu activation function
Relu function expression:
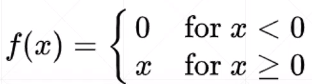
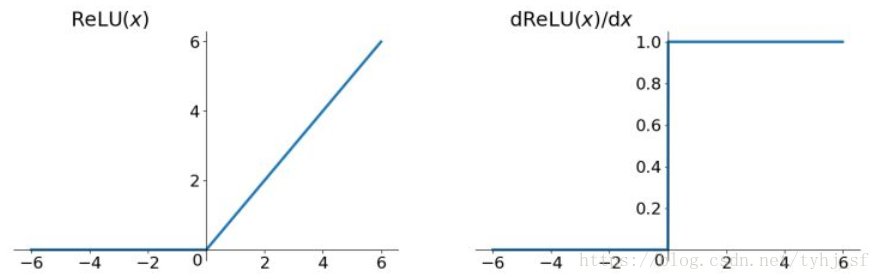
function, and its derivative image:
Custom code:
函数表达式:f(x) = 1/(1+e^-x)
函数特点:
优点:1.输出[0,1]之间;2.连续函数,方便求导。
缺点:1.容易产生梯度消失;2.输出不是以零为中心;3.大量运算时相当耗时(由于是幂函数)。
函数定义:
def sigmoid(x):
y = 1/(1+np.exp(-x))
return y
pytorch code:
# ReLU函数在torch中如何实现
import torch
a = torch.linspace(-1,1,10)
b = torch.relu(a)
print(a)
print(b)
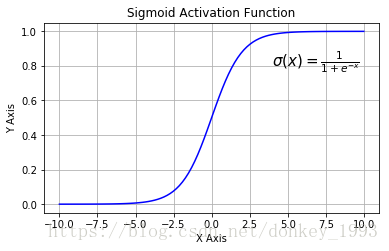
4.2 sigmoid activation function
Function expression:
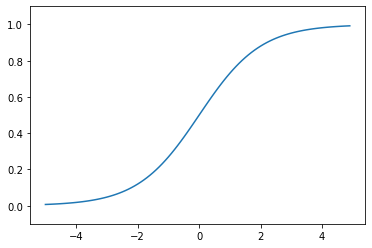
Function image:
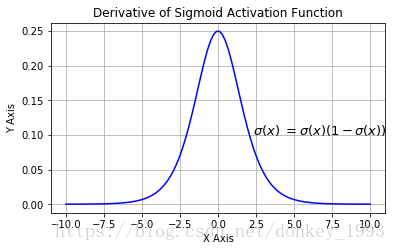
Function derivative image:
Custom code:
函数表达式:f(x) = 1/(1+e^-x)
函数特点:
优点:1.输出[0,1]之间;2.连续函数,方便求导。
缺点:1.容易产生梯度消失;2.输出不是以零为中心;3.大量运算时相当耗时(由于是幂函数)。
函数定义:
def sigmoid(x):
y = 1/(1+np.exp(-x))
return y
pytorch code:
# sigmoid函数在torch中如何实现
import torch
# a从-100到100中任取10个数
a = torch.linspace(-100,100,10)
print(a)
# 或者F.sigmoid也可以 F是从from torch.nn import functional as F
b = torch.sigmoid(a)
print(b)
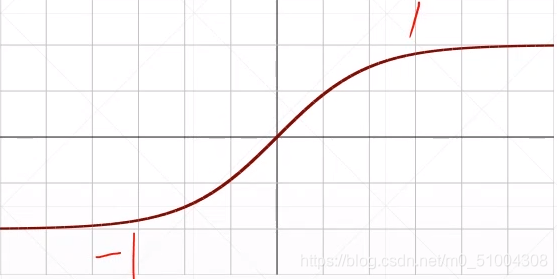
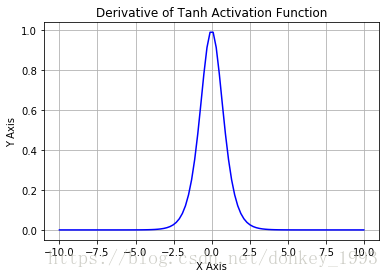
4.3 Tanh activation function
Function expression:
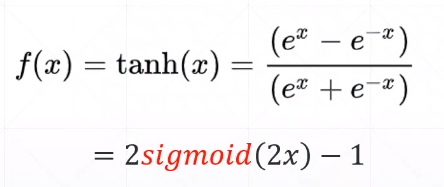
Function image:
Function derivative image:
Custom code:
函数表达式:f(x) = (e^x-e^-x)/(e^x+e-x)
函数特点:
优点:1.输出[-1,1]之间;2.连续函数,方便求导;3.输出以零为中心。
缺点:1.容易产生梯度消失; 2.大量数据运算时相当耗时(由于是幂函数)。
函数定义:
def tanh(x):
y = (np.exp(x) - np.exp(-x))/(np.exp(x) + np.exp(-x))
return y
pytorch code:
# tanh函数在torch中如何实现
import torch
a = torch.linspace(-10,10,10)
b = torch.tanh(a)
print(a)
print(b)
4.4 softmax activation function
Function expression:
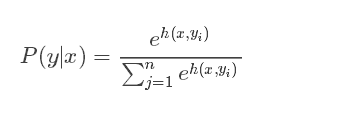
Function image:
Function derivative image:
Custom code:
def softmax(x):
if x.ndim == 2:
x = x.T
x = x - np.max(x, axis=0)
y = np.exp(x) / np.sum(np.exp(x), axis=0)
return y.T
x = x - np.max(x) # 溢出操作
return np.exp(x) / np.sum(np.exp(x))