Article directory
I. Introduction
(Before reading this article, you need to have the basic knowledge of Linux basic IO)
In some specific cases, multi-processes need to cooperate to process tasks, and process interaction is required at this time. However, we know that processes are independent , so the cost of data interaction is relatively high. Driven by this contradiction, inter-process communication came into being, which mainly has the following four purposes:
- Data transfer: one process needs to send its data to another process
- Resource sharing: The same resource is shared between multiple processes.
- Notification event: A process needs to send a message to another process or a group of processes, informing it (they) that some event has occurred (such as notifying the parent process when the process terminates).
- Process control: Some processes want to completely control the execution of another process (such as Debug process), at this time the control process hopes to be able to intercept all traps and exceptions of another process, and to be able to know its state changes in time
There is no intersection between two processes, so the essence of inter-process communication is how to makeTwo processes see the same resource, rather than how to communicate, the difference in resources determines the difference in communication methods. It is very important to understand this! !
When we can use the cat()and echo()commands to print the contents of the same disk file, this is essentially a very primitive communication—the cat process and the echo process see the same disk resource. However, the read and write speed of the disk is very slow. We expect to achieve memory-level inter-process communication, so memory must be used as a data buffer.
2. What is an anonymous channel?
Everyone must have come into contact with the anonymous pipeline. In fact, it is in the command line| window .|output resultas a grep ncurses commandInput data. Why call it a pipe? In fact, it is not difficult to understand. When talking about pipelines, people may think of oil, and data is oil in the computer world. The medium for transmitting data is naturally called pipelines.
A command actually corresponds to a process. Therefore, through anonymous pipes, we realize the data interaction between the yum process and the grep process. From the

above example, we can also initially summarize the characteristics of the pipe (the same applies to named pipes):
- Pipes are used to transfer data
- Pipeline transfer data is one- way
3. The principle of anonymous pipes
When we use the fork() function to create a child process, the kernel data structure of the child process is basically copied from the parent process, and naturally the child process will also inherit the file descriptor ( Linux Basic IO (2): In-depth understanding of Linux file descriptor ), which means that the file opened by the child process is exactly the same as that opened by the parent process. The parent and child processes read or write to the same file, thereby realizing inter-process communication.
However, we also mentioned above that the disk access speed is too slow, and we need to implement memory-level inter-process communication. Therefore, the pipe file opened by the parent process is a special file, whichDisassociate from disk, write directly to the buffer when writing, and read directly from the buffer when reading, thereby realizing memory-level communication.
[Question 1]: How to distinguish between ordinary files and pipeline files?
// 在inode结构体下可以看到如下的联合体(adree_space包含有struct inode) struct inode { union { struct pipe_inode_info *i_pipe; // 管道设备 struct block_device *i_bdev; // 磁盘设备 struct cdev *i_cdev; // 字符设备 }; }The bottom layer distinguishes file attributes through a union. When a pipeline is created, the corresponding pipeline fields will take effect
From the perspective of file descriptors - in-depth understanding of pipelines:
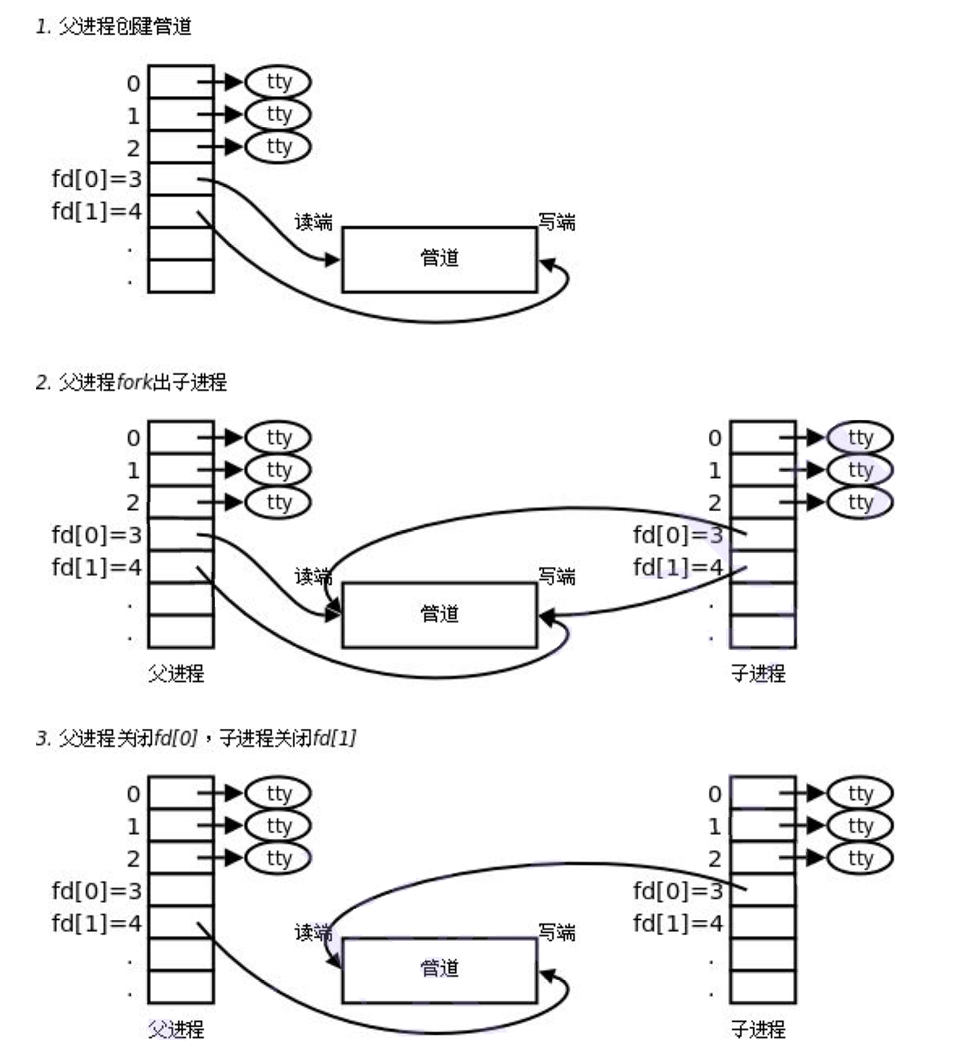
[Question 2]: Why does the parent process open the same pipe file successively for reading and writing?
Answer: After the child process copies the parent process, it does not need to open the pipe file for reading or writing.
[Question 3 ]: Why do the parent and child processes close the read end and write end respectively?
Answer: Ensure the one-way communication of the pipeline.
What determines whether to close the write terminal or close the write terminal?
Answer: It depends on the user's needs. If you want data to flow from the parent process to the child process, close the read end of the parent process and the write end of the child process; if you want data to flow from the child process to the parent process, close the write end of the parent process and the read end of the child process
Third, the creation of anonymous pipes
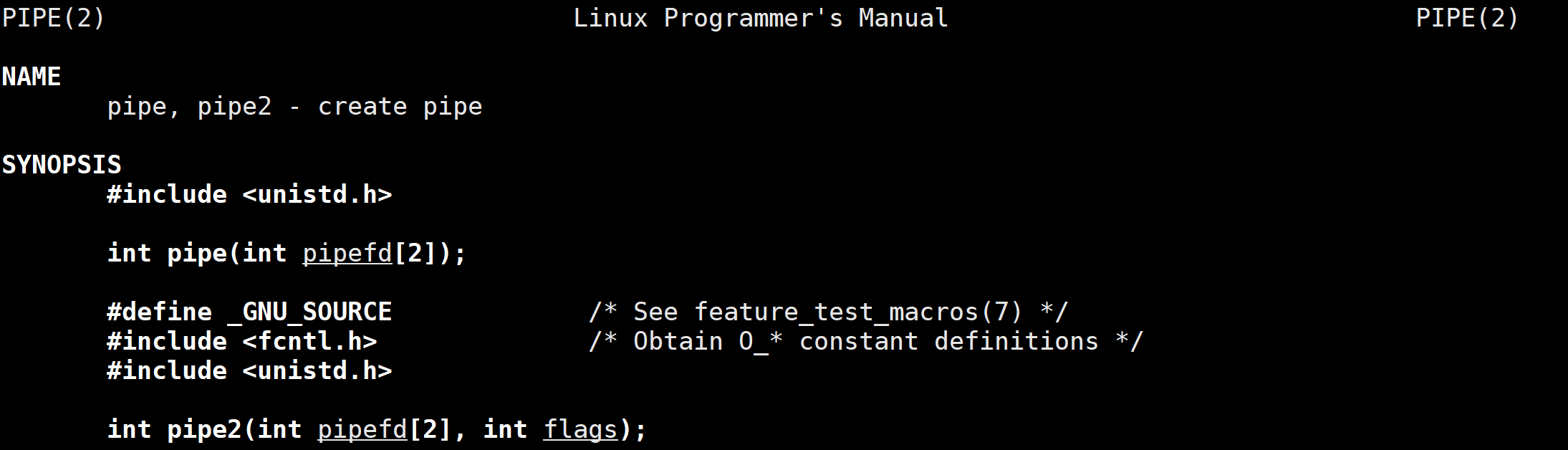
[Function] : create an anonymous pipe
[parameter description] : pipefd[2] is a return type parameter
- pipefd[0] stores the file descriptor returned by opening the pipe file for reading
- pipefd[1] stores the file descriptor returned by opening the pipe file for writing
(memory method: 0 → mouth → read 1 → pen → write)
[Return value] : Create a pipeline successfully and return 0; fail to return -1
[Function description]:
pipe()The function automatically opens the same pipe file for reading and writing and returns the file descriptor to pipefd[2]- The pipe function is a system call , so the operating system can directly set the file type to a pipe in the kernel
[Pipeline read and write rules]:
- when there is no data to read
O_NONBLOCKdisable: The read call is blocked and waits until data arrivesO_NONBLOCKenable: The read call returns -1, and the errno value is EAGAIN
(use the fcntl function to set the non-blocking option)
- when the pipe is full
O_NONBLOCKdisable: The write call is blocked until a process reads the dataO_NONBLOCKenable: the call returns -1, and the errno value is EAGAIN
- If all the file descriptors corresponding to the write end of the pipe are closed, read returns 0 to indicate that the end of the file has been read
- If all the file descriptors corresponding to the read end of the pipe are closed, the write operation will generate a signal
SIGPIPE, which may cause the write process to exit - When the amount of data to be written is not greater than PIPE_BUF ( 4096 bytes under Linux ), Linux will guarantee the atomicity of writing. otherwise no guarantee
4. Anonymous channels for data transmission
// 使用案例:数据从父进程传递给子进程
int main()
{
int pipefd[2] = {
0};
if(pipe(pipefd) != 0) // 创建管道失败
{
cerr << "pipe" << endl;
return 1;
}
pid_t pid = fork();
if(pid == 0) // 子进程关闭写端
{
close(pipefd[1]);
char buff[20];
while(true)
{
ssize_t ss = read(pipefd[0], buff, sizeof(buff));
if(ss == 0)
{
cout << "父进程不写入了,我也不读取了" << endl;
break;
}
buff[ss] = '\0';
cout << "子进程收到消息:" << buff << " 时间:" << time(nullptr) << endl;
}
}
else // 父进程关闭读端
{
close(pipefd[0]);
char msg[] = "hello world!";
for(int i = 0; i < 5; i++)
{
// 不要写入字符串末尾的'\0'
// ‘\0’结尾是C语言的标准,文件可不吃这一套
write(pipefd[1], msg, sizeof(msg) - 1);
sleep(1);
}
cout << "父进程写入完毕" << endl;
close(pipefd[1]);
waitpid(pid, nullptr, 0);
}
return 0;
}
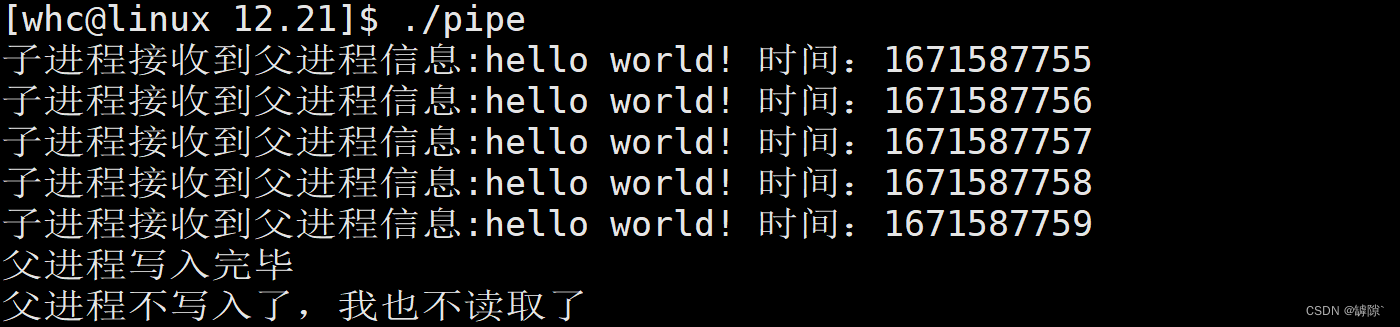
[Question 5]: Why does the child process not sleep, but it sleeps with the parent process? (Observe the timestamp)
Answer: The pipe function comes withaccess control mechanism, the father and son have a certain sequence when reading and writing:
- When a process tries to read from an empty pipe, the read interface is blocked until there is data in the pipe
- When a process tries to write to a full pipe, the write interface is blocked until enough data has been read from the pipe
[Question 6]: How does the child process perceive that the parent process has closed the pipe?
Answer: Whenever a process opens a file, the reference count of the file will increase by one; whenever a process closes a file, the reference count of the file will decrease by one. When the reference count of a file is reduced to 0, it means that no process has opened the file, and then the file will be actually closed.When the reference count of the pipeline file is 1, it indicates that the parent process has closed the pipeline file, and the child process can exit as the end of the file after reading the current message. Therefore, the child process can sense whether the parent process closes the write end.
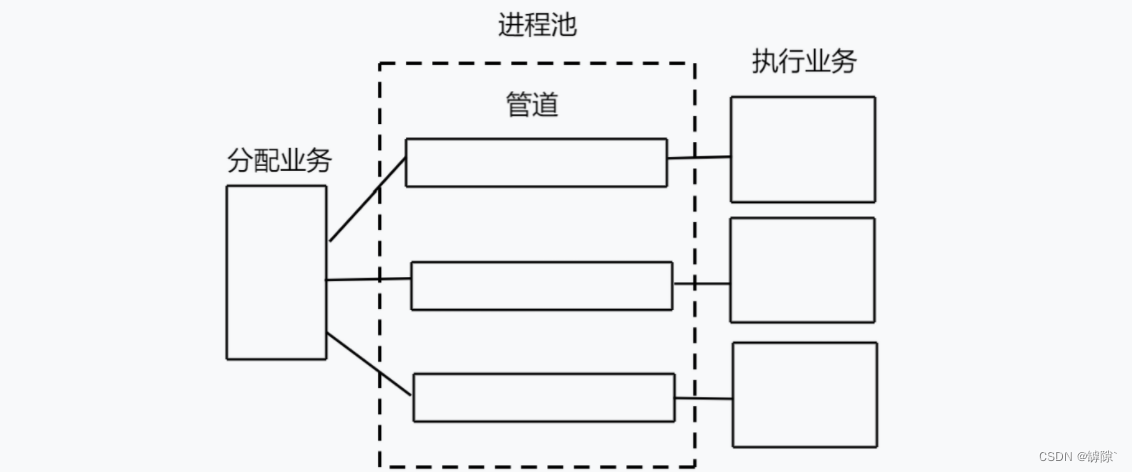
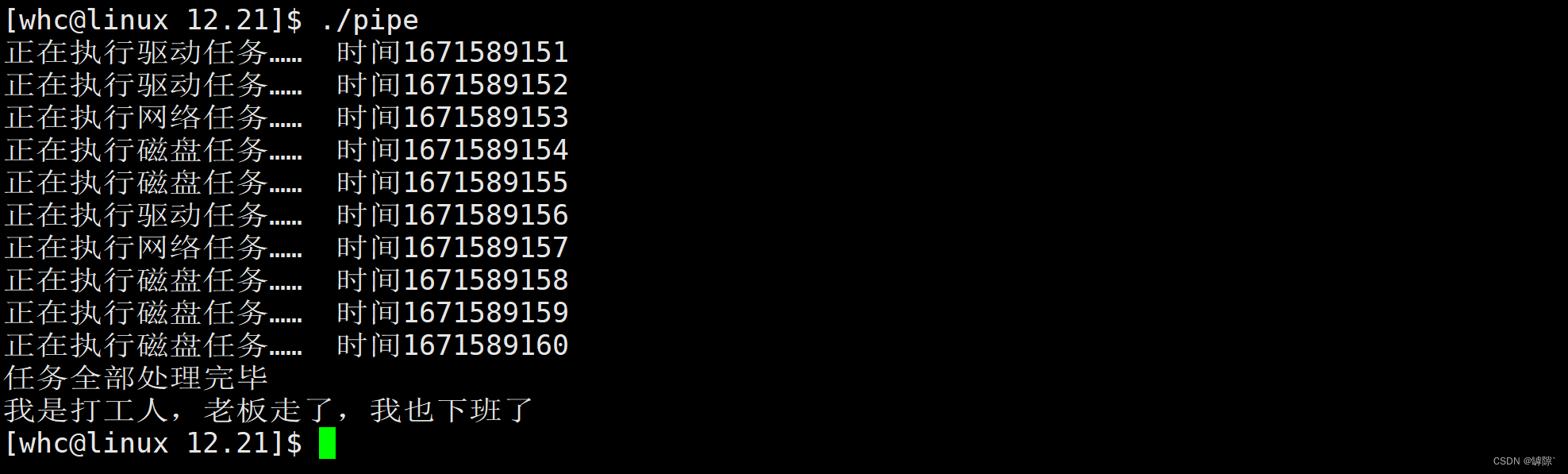
5. Anonymous pipes realize process control
- Create multiple pipeline files (in fact, one can also be used)
- Create multiple child processes
- The parent process randomly assigns tasks (specify which process, specify what task)
- Subprocess processing tasks
#include <iostream>
#include <unistd.h>
#include <sys/types.h>
#include <sys/wait.h>
#include <fcntl.h>
#include <ctime>
#include <cassert>
#include <vector>
using namespace std;
typedef void(*function)();
vector<function> task;
void func1()
{
cout << "正在执行网络任务……" << " 时间" << time(nullptr) << endl;
}
void func2()
{
cout << "正在执行磁盘任务……" << " 时间" << time(nullptr) << endl;
}
void func3()
{
cout << "正在执行驱动任务……" << " 时间" << time(nullptr) << endl;
}
void LoadFunc() // 加载任务到vector中
{
task.push_back(func1);
task.push_back(func2);
task.push_back(func3);
}
int main()
{
LoadFunc();
srand((unsigned int)time(nullptr) ^ getpid());
int pipefd[2] = {
0};
if(pipe(pipefd) != 0)
{
cerr << "pipe" << endl;
return 1;
}
pid_t pid = fork();
if(pid == 0)
{
close(pipefd[1]);
while(true)
{
uint32_t n = 0;
ssize_t ss = read(pipefd[0], &n, sizeof(uint32_t));
if(ss == 0)
{
cout << "我是打工人,老板走了,我也下班了" << endl;
break;
}
assert(ss == sizeof(uint32_t));
task[n]();
}
}
else
{
close(pipefd[0]);
for(int i = 0; i < 10; i++)
{
uint32_t ss = rand() % 3;
write(pipefd[1], &ss, sizeof(uint32_t));
sleep(1);
}
cout << "任务全部处理完毕" << endl;
close(pipefd[1]);
waitpid(pid, nullptr, 0);
}
return 0;
}
6. Summary of Anonymous Pipeline Features
- Anonymous pipes can only be used withblood relationbetween the processes. It is usually used for communication between parent and child processes (it can also be used between brothers: the parent process creates two child processes after opening the pipe, and then closes the read and write end of the pipe of the parent process to realize communication between two brother processes)
- The pipe must be one-way , and the Linux kernel is designed to be one-way when the pipe is one-way
- Pipe comes with access control mechanism
- Pipes are byte stream oriented . The character written first must be read first, and there is no format boundary when reading . The user needs to limit the boundary of the content (for example, when using the read function, we need to specify how many bytes to read)
- The pipe is also a file, and the life cycle of the pipe will end when the reference count of the process exits the pipe is reduced to 0
- In general, the kernel will synchronize and mutex pipeline operations