smartctl is a tool for monitoring and analyzing the health status of hard disks, and can be used to detect whether there are bad disks. Here are the steps to check disk health using smartctl:
-
Install smartctl software
In Linux systems, smartctl is usually included in the smartmontools package. If you have not installed smartmontools, you can use the following command to install it (most NAS comes with it, such as TrueNas):sudo apt-get install smartmontools # Debian/Ubuntu sudo yum install smartmontools # RedHat/CentOS -
Find Disk Device Names
Use the following command to find disk device names:sudo fdisk -l -
Run smartctl to check disk
Run smartctl to check disk with the following command:sudo smartctl -a /dev/sdaReplace
/dev/sdawith the name of the disk device you want to check. This command will list detailed information about the health status of the disk, including error count and predicted time to failure, etc. Note that you may need root privileges to run smartctl. -
Check smartctl output
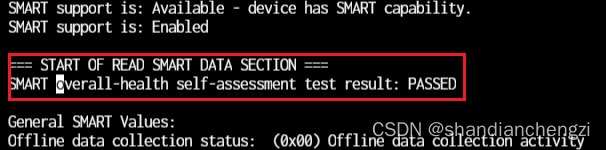
Find information about disk health in smartctl output. Focus on the following fields:- SMART overall-health self-assessment test result: If the value of this field is "PASSED", no health problems have been found on the disk. If the value of this field is "FAILED" or "UNKNOWN", there is a health issue with the disk.
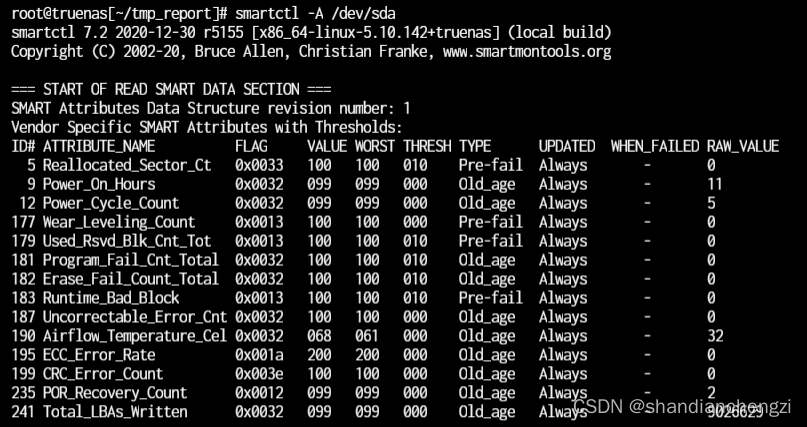
- Reallocated_Sector_Ct: This is the number of sectors that have been reallocated. If the value is not 0, the disk has bad sectors. The normal RAW_VALUE is as follows:
ID# ATTRIBUTE_NAME FLAG VALUE WORST THRESH TYPE UPDATED WHEN_FAILED RAW_VALUE 5 Reallocated_Sector_Ct 0x0033 100 100 010 Pre-fail Always - 0 - Current_Pending_Sector: This is the number of sectors currently waiting to be reallocated. If the value is not 0, the disk has potentially bad sectors.
- SMART overall-health self-assessment test result: If the value of this field is "PASSED", no health problems have been found on the disk. If the value of this field is "FAILED" or "UNKNOWN", there is a health issue with the disk.
If no health issues are found in the smartctl output, then the disk should be fine. Otherwise, you may need to analyze the problem more deeply or consider replacing the disk.
The following are some of the problems I personally encountered during the detection process.
Article directory
1 When should it be used smartctl -t?
The "-t" option of the smartctl command is used to perform a disk self-test in order to find any potential problems on the disk. When the "-t" option is used, smartctl will start a self-test in the background and provide the results upon completion. Therefore, if you want to get the latest self-test results for your disk , you need to run smartctl with the "-t" option.
However, if you just want to check the current status of the disk without running a self-test, you can directly run the "smartctl -a" command to get the disk health status information. This command will list information about the current status and properties of the disk, such as temperature, power cycle, failure count, and more.
To sum up, if you want to run a self-test to get the latest disk status information, you should use the "smartctl -t" command. If you just want to get information about the current state of the disk, you can use the "smartctl -a" command directly.
2 How to check the type of my disk and its supported SMART attributes?
You can use the smartctl command to see your disk type and supported SMART attributes. Here's how to check them out:
-
Run the "smartctl -i" command to get basic information about the disk. This command will list information such as the manufacturer, model, and serial number of the disk. For example:
$ sudo smartctl -i /dev/sda smartctl 7.1 2019-12-30 r5022 [x86_64-linux-5.4.0-89-generic] (local build) Copyright (C) 2002-19, Bruce Allen, Christian Franke, www.smartmontools.org === START OF INFORMATION SECTION === Model Family: Samsung based SSDs Device Model: Samsung SSD 970 EVO Plus 500GB Serial Number: S5H7NX0N659415D LU WWN Device Id: 5 002538 8b0c6d96d Firmware Version: 2B2QEXM7 User Capacity: 500,107,862,016 bytes [500 GB] Sector Size: 512 bytes logical/physical Rotation Rate: Solid State Device Form Factor: M.2 TRIM Command: Available, deterministic, zeroed Device is: Not in smartctl database [for details use: -P showall] ATA Version is: ACS-4, ATA8-ACS T13/1699-D revision 4 SATA Version is: SATA 3.3, 6.0 Gb/s (current: 6.0 Gb/s) Local Time is: Tue Feb 15 19:48:47 2022 CET SMART support is: Available - device has SMART capability. SMART support is: Enabled -
Look for the "Device Model" property to get the disk model. For example, in the output above, the value of the "Device Model" property is "Samsung SSD 970 EVO Plus 500GB".
-
Run the "smartctl -A" command to get a list of SMART attributes supported by the disk. This command will list the SMART self-testing and reporting attributes supported by the disk. For example:
3 What about power cycle and fault counts?
Power-On Hours (POH) and Error Counters are two common disk attributes in the output of the smartctl command. Here's how to check them out:
Run the "smartctl -a" command to get the details of the disk. In the last part of the command output, you can see all SMART attributes and their current values.
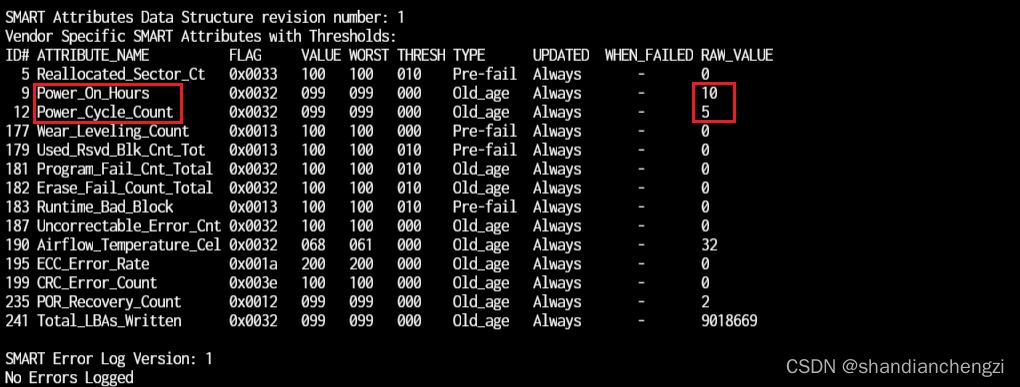
Look for the " Power_On_Hours " attribute. It is the power cycle property of the disk and represents the cumulative usage time since the disk was started, in hours.
Look for the "Error_Counters" property. This is a property that contains several sub-properties that record the disk's error count. For example:
- "Raw_Read_Error_Rate" records the number of uncorrected errors while reading data from disk.
- "Seek_Error_Rate" records the number of errors encountered while seeking.
- "Spin_Retry_Count" records the number of times to retry reading data while spinning the disk.
- "Reallocated_Sector_Ct" records the number of bad sectors that have been reallocated.
- "Current_Pending_Sector" records the number of bad sectors that cannot be read currently.
- "Offline_Uncorrectable" records the number of uncorrectable bad sectors found in offline state.
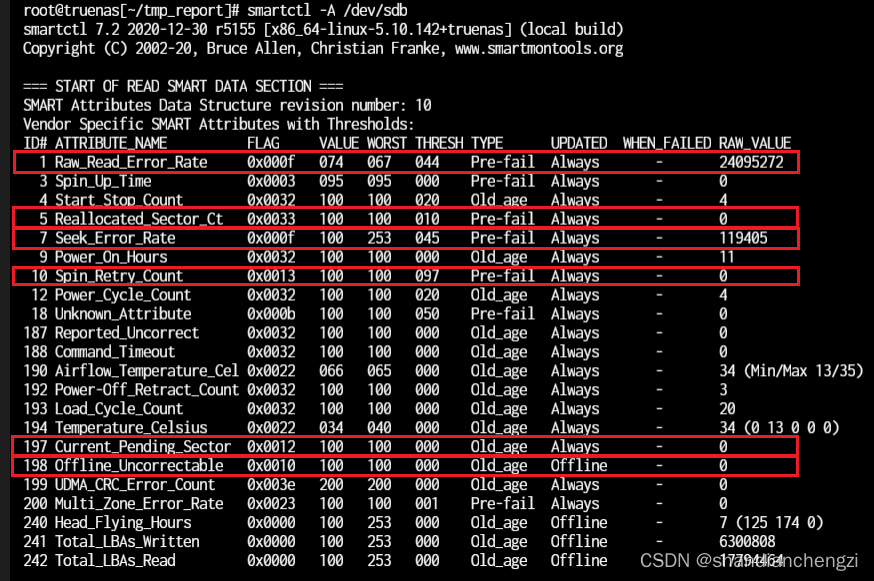
Any of these attributes may indicate a problem with the disk that needs further inspection or replacement.
Note that different disks may use different property names and units of count . When looking at SMART attributes, be sure to review the full contents of the smartctl command output and carefully review any attributes that may indicate a disk problem .
4 Don't see the Error_Counters property in the output?
If you do not see the "Error_Counters" attribute after running the "smartctl -a" command, it may be because your disk does not support this attribute, or it is not being reported correctly. Different disks may support different SMART attributes , so some attributes may not apply to your disk.
In this case, you can look at other parts of the "smartctl -a" command output for other attributes that might indicate a disk problem. For example, you can view attributes related to disk health, such as temperature, noise, vibration, disk spin speed, and more. You can also view any messages reporting disk errors or warnings.
Note that if you think there are problems with the disk but cannot confirm them with SMART attributes, there are other tools you can use for more comprehensive disk diagnostics and testing. For example, you can use the disk test tool provided by the disk manufacturer, or use a third-party tool to perform a full disk scan and test.
5 Is it normal that Seek_Error_Rate is very high?
It is usually not normal to see a large number of Seek_Error_Rate values in a SMART report . This attribute refers to the frequency of disk seek errors and is one of the key SMART indicators. Higher values generally mean that there is a higher likelihood of a problem and should be noticed.
However, disk SMART attributes should be interpreted according to the disk manufacturer's recommendations . Different manufacturers may use different algorithms and scales to calculate SMART attribute values. Also, some disks may have an automatic error correction feature, which means that even if there are some errors in the SMART report, the disk will still work fine.
Therefore, it is recommended that you check the disk manufacturer's documentation for details on SMART attribute values, or you can provide the SMART report to the manufacturer for analysis for a more accurate interpretation. If you are concerned about the health of the disk, it is a good idea to back up important data and consider replacing the disk.
My hardware model is: ST16000NM000J-2TW103. Seagate calculates Seek_Error_Rate in different ways. For details, please refer to the article on station b: Seagate mechanical hard disk read error rate and seek error rate are high? Let's see how it's calculated!