Flink project environment preparation
Introduction to Flink
Flink originated from a project called Stratosphere, which is a research project jointly conducted by three universities in Berlin and other universities in Europe, led by Volker Markl, a professor at the Technical University of Berlin. In April 2014, Stratosphere's code was copied and donated to the Apache Software Foundation, on which Flink was redesigned.

Development History
- In August 2014, Flink's first version 0.6 was officially released (as for versions before 0.5, it was under the name of Stratosphere). At the same time, several core developers of Fink founded Data Artisans, which mainly focuses on Fink's commercial applications and helps enterprises deploy large-scale data processing solutions.
- In December 2014, the Flink project completed its incubation and became the top project of the Apache Software Foundation.
- In April 2015, Flink released an important milestone version 0.9.0. It was at this time that many large companies at home and abroad began to pay attention to and participate in the construction of the Flink community.
- In January 2019, Alibaba, which has been investing in Flink for a long time, acquired Data Artisans at a price of 90 million euros; after that, it made its internal version Blink open source, and then merged it with the Flink 1.9.0 version released in August . Since then, Flink has been known by more and more people and has become the hottest new generation big data processing framework.
It can be seen that it took only a few years for Flink to become popular from its real start. In just a few years, Flink has been released from the first stable version 0.9 to 1.13.0 during the writing of this book, and new functions and features have been continuously added during this period. From the beginning, Flink has had a very active community and it has been growing rapidly. The specific positioning of Flink is: Apache Flink is a framework and a distributed processing engine.
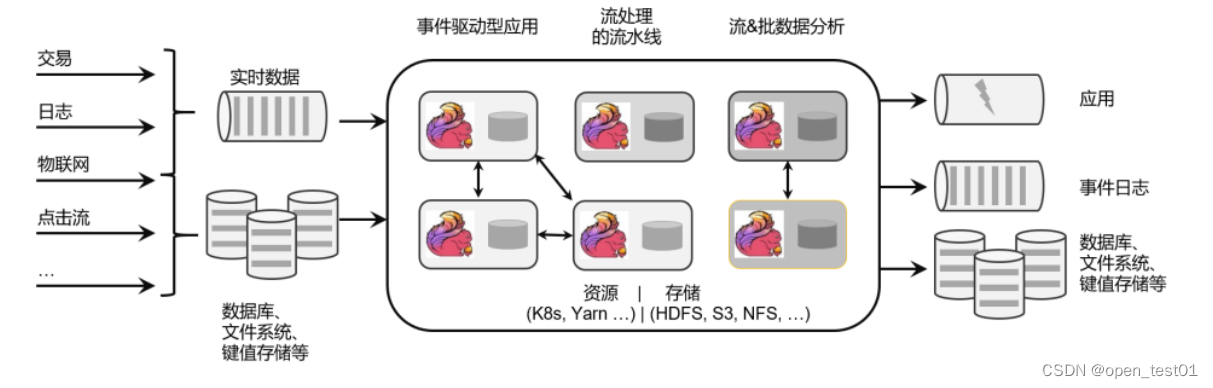
For stateful computation on unbounded and bounded data streams. Flink is designed to run in all common cluster environments, performing computations at in-memory execution speed and at any scale.
Flink project environment preparation
Create Maven
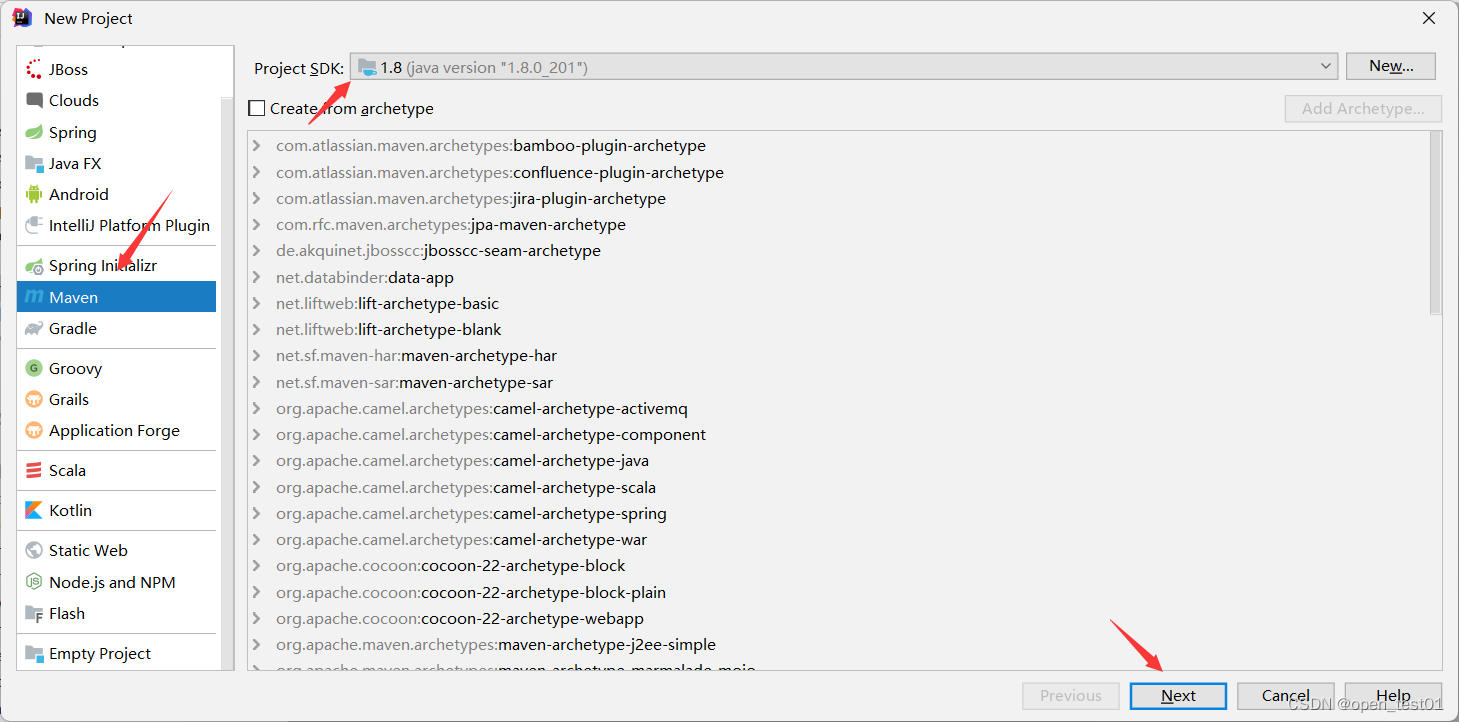
set project name
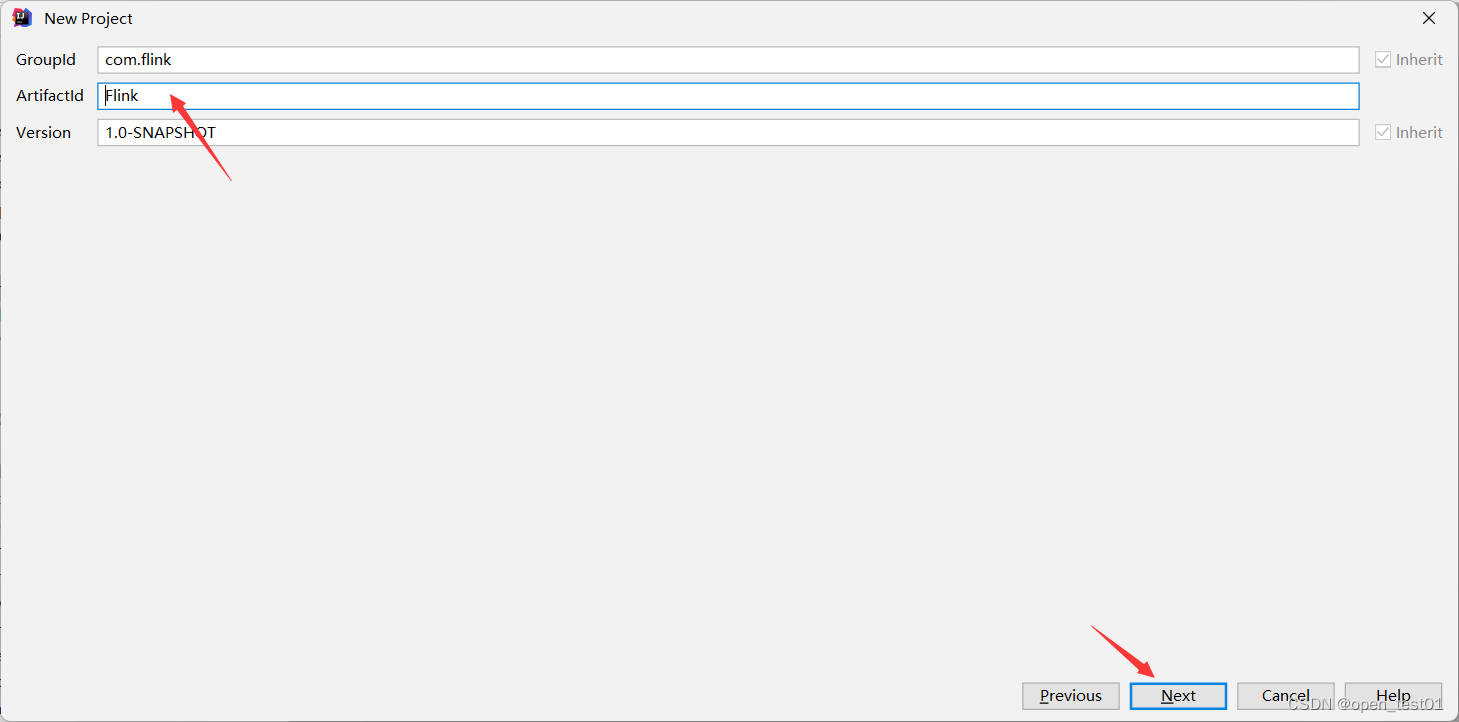
project path
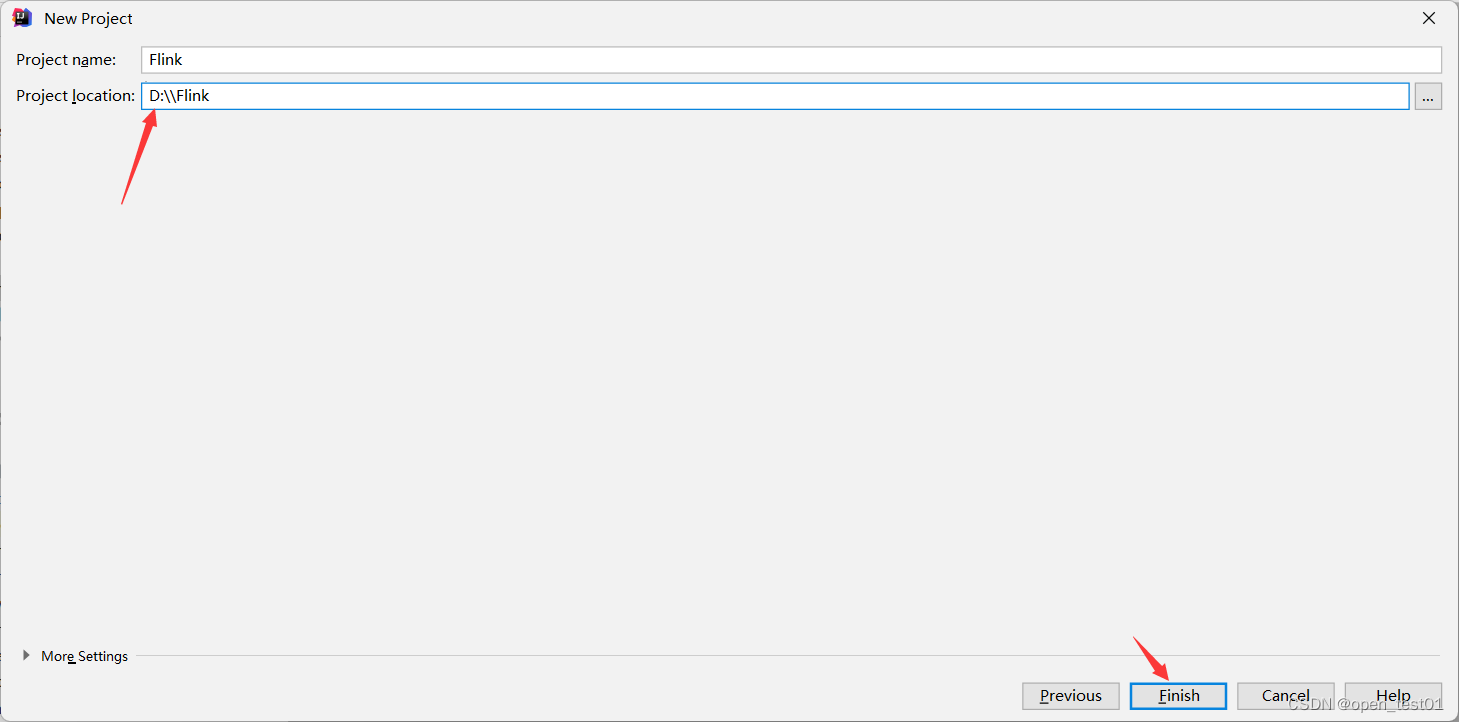
add dependencies
<properties>
<flink.version>1.13.0</flink.version>
<target.java.version>1.8</target.java.version>
<scala.binary.version>2.12</scala.binary.version>
</properties>
<dependencies>
<!-- 引入 Flink 相关依赖-->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-scala_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-scala_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
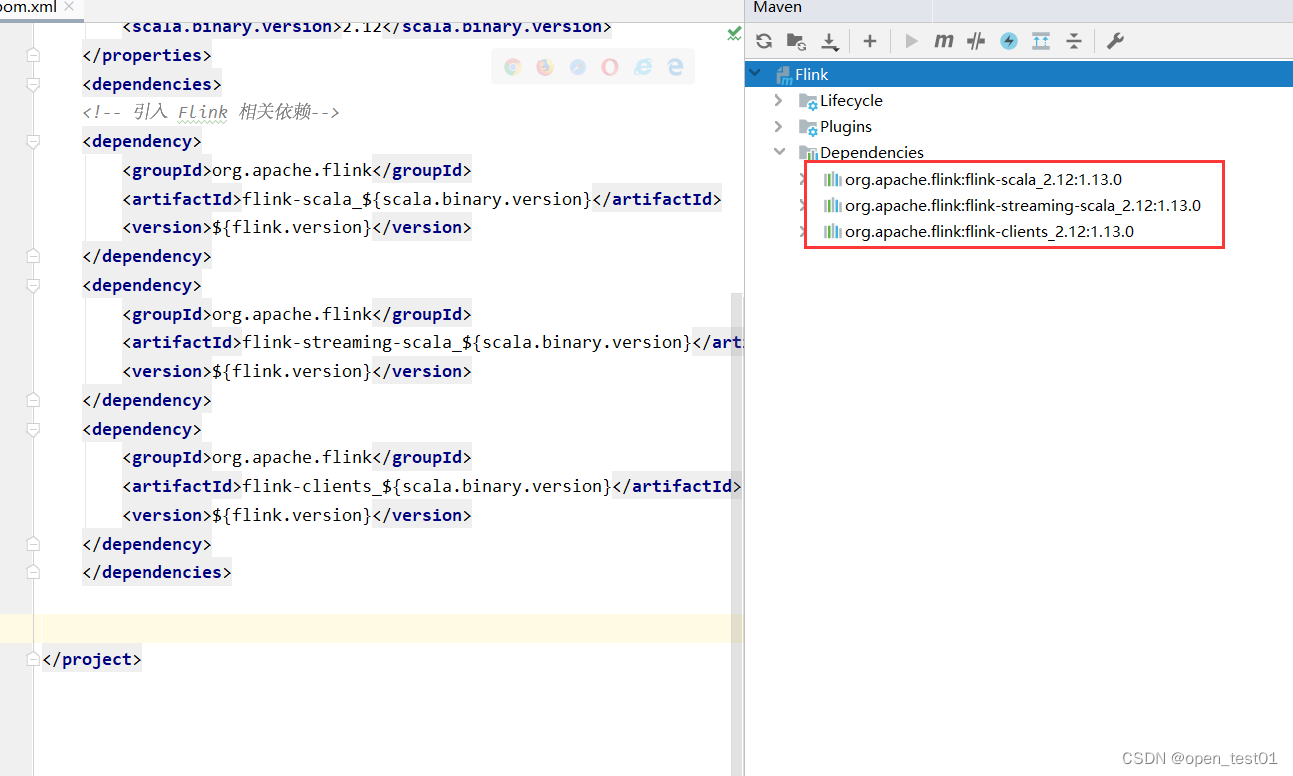
</dependencies>View imported dependencies
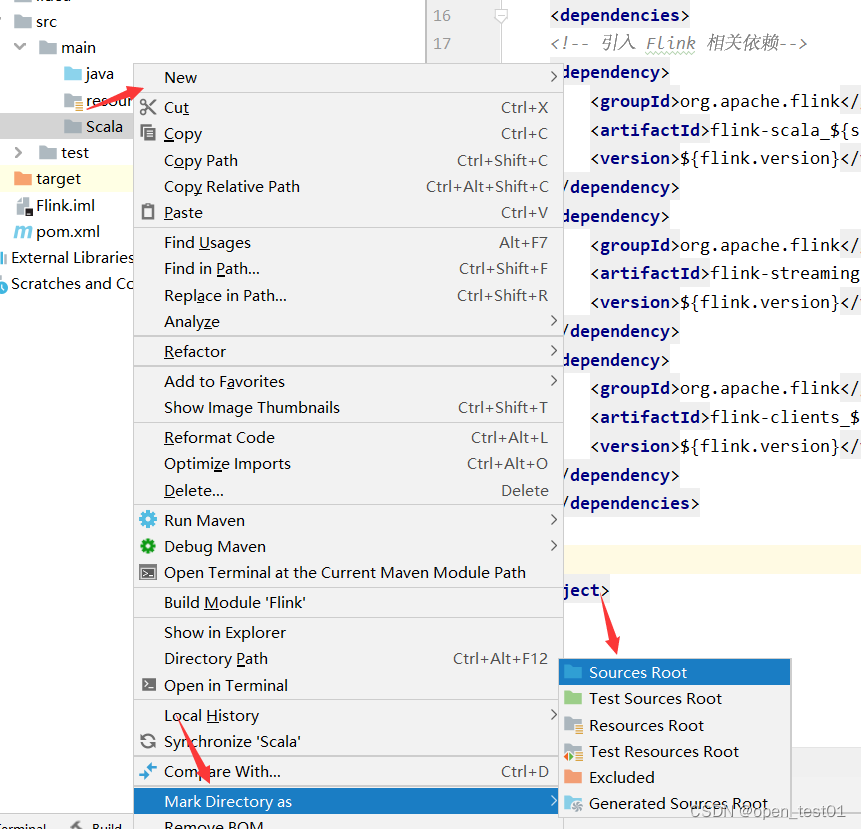
Create a new Scala directory under the main directory

Set the Scala directory as the source code directory
Add Scala support

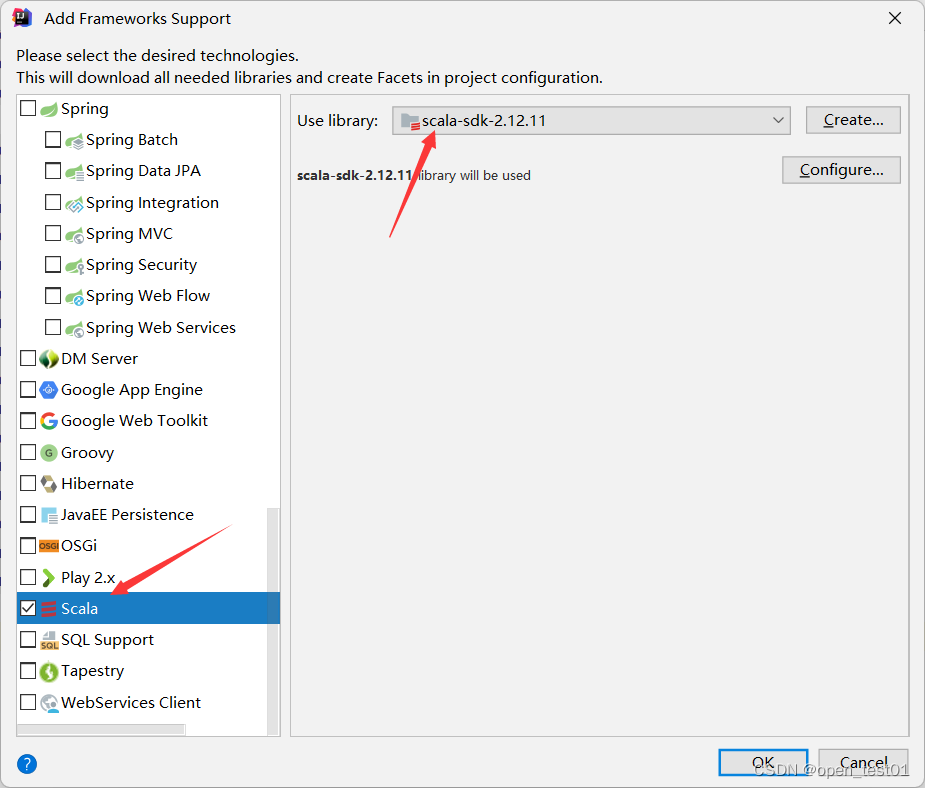
If you don't have the Scala SDK installed, refer to the link: Preliminary Exploration of Scala_open_test01's Blog - CSDN Blog
Implement WordCount
Simply prepare a data
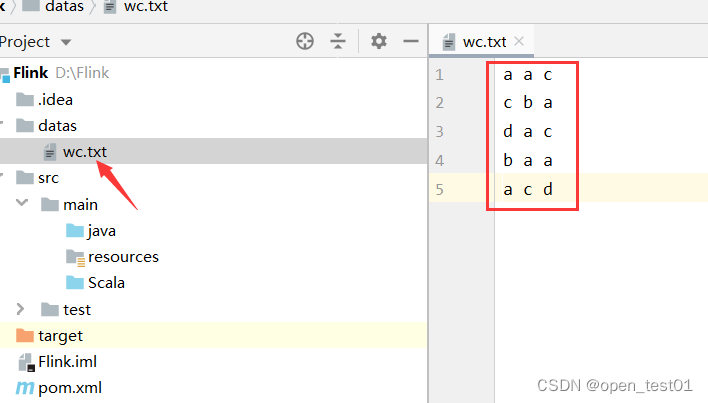
Batch processing implements WordCount
def main(args: Array[String]): Unit = {
//创建执行环境
val env: ExecutionEnvironment = ExecutionEnvironment.getExecutionEnvironment
//读取文件数据
val line: DataSet[String] = env.readTextFile("datas\\wc.txt")
//对数据集进行转换处理
val value: DataSet[(String, Int)] = line.flatMap(_.split(" ")).map(word => (word,1))
//分组
val gpword: GroupedDataSet[(String, Int)] = value.groupBy(0) //按索引位置分组
//聚合统计
val rs: AggregateDataSet[(String, Int)] = gpword.sum(1)//索引位置累加聚合
//输出
rs.print()
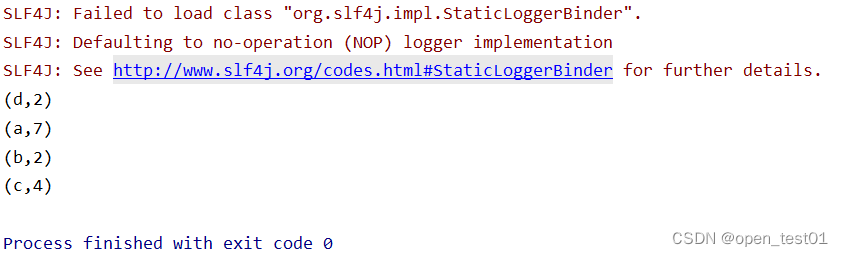
}
Bounded stream processing implements WordCount
def main(args: Array[String]): Unit = {
//创建执行环境
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
//读取文件数据
val line: DataStream[String] = env.readTextFile("datas\\wc.txt")
//对数据集进行转换处理
val fl: DataStream[(String, Int)] = line.flatMap(_.split("")).map(w => (w,1))
//分组
val gp: KeyedStream[(String, Int), String] = fl.keyBy(_._1)
//聚合统计
val rs: DataStream[(String, Int)] = gp.sum(1)
//输出
rs.print()
//执行当前任务
env.execute()
}As we can see, this is quite different from the result of batch processing. Batch processing will only output a final statistical number for each word; while in the print result of stream processing, every time the word "a" appears, there will be a frequency statistical data output. This is the characteristic of stream processing. Data is processed one by one, and every time a piece of data comes in, it will be processed and output once. By printing the results, we can clearly see the process of increasing the number of words "a".
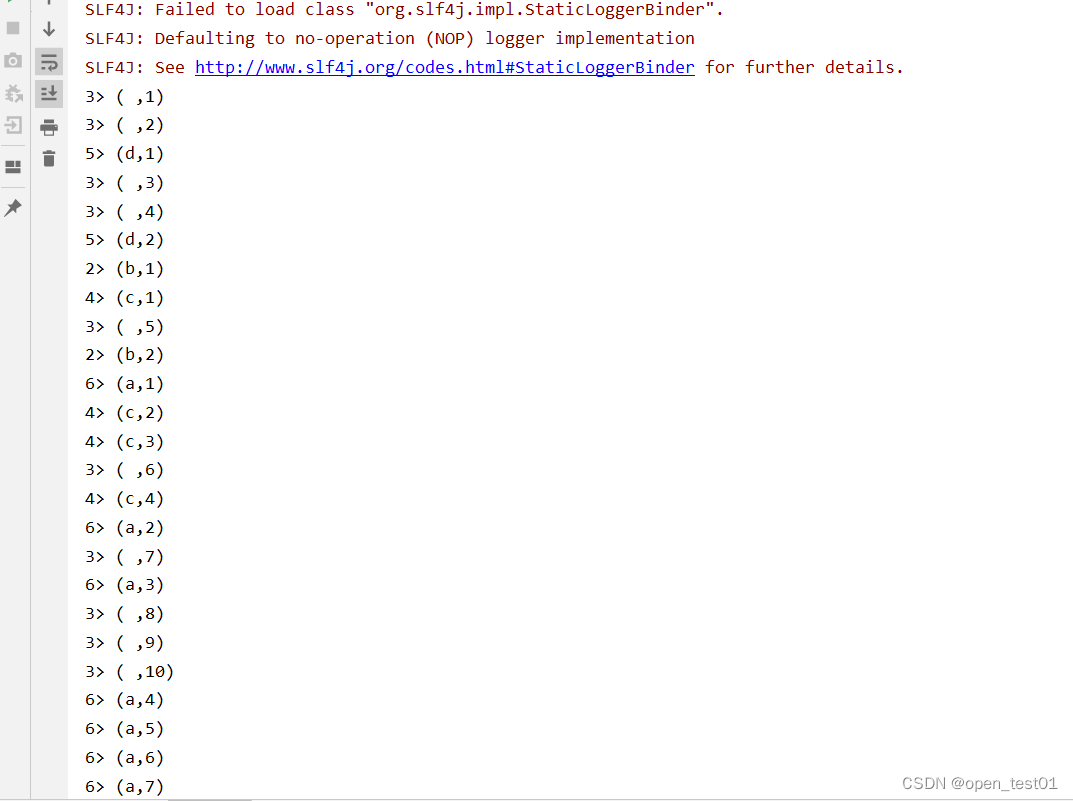
Unbounded stream processing implements WordCount
In the actual production environment, the real data flow is actually unbounded, with a beginning but no end, which requires us to maintain a state of listening to events and continuously process the captured data.
def main(args: Array[String]): Unit = {
//创建执行环境
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
//读取socket文本流数据
//socketTextStream("主机名","端口号")
val line: DataStream[String] = env.socketTextStream("master",7496)
//对数据集进行转换处理
val fl: DataStream[(String, Int)] = line.flatMap(_.split("")).map(w => (w,1))
//分组
val gp: KeyedStream[(String, Int), String] = fl.keyBy(_._1)
//聚合统计
val rs: DataStream[(String, Int)] = gp.sum(1)
//输出
rs.print()
//执行当前任务
env.execute()
}