Table of contents
\s matches special characters, such as blank, space, tab, etc.
\w matches words, characters, such as upper and lower case letters, numbers, _ underscore
\W matches non-word characters
[ ] matches the characters listed in [ ]
{m,n} specifies the range from mn times
$ matches the trailing character
^ matches the beginning character
\B matches a non-word boundary
| matches any left or right expression
(ab) Treat the characters in parentheses as a group
Extract all the text in the source code of the web page
Extract a string within a specified range from a string
A regular expression is a set of rules for string extraction. We express this rule with a specific syntax in the regular expression to match a string that satisfies this rule. Regular expressions are universal, not only in python, but also in other languages.
The re module in python provides the function of regular expressions. There are four commonly used methods (match, search, findall) that can be used to match strings
match
match string
re.match() must match from the beginning of the string! The match method attempts to match a pattern from the beginning of the string, and if it does not match the beginning, match() returns none. The main parameters are as follows:
re.match(pattern, string)
# pattern 匹配的正则表达式
# string 要匹配的字符串example
import re
a = re.match('test','testasdtest')
print(a) #返回一个匹配对象
print(a.group()) #返回test,获取不到则报错
print(a.span()) #返回匹配结果的位置,左闭右开区间
print(re.match('test','atestasdtest')) #返回None
As we can see from the example, the re.match() method returns a matched object, not the matched content. If you need to return content, you need to call group(). The position of the matching result can be obtained by calling span(). And if there is no match from the starting position, re.match() will return None even if other parts contain the content that needs to be matched.
single character match
The following characters, all match a single character data. And there is no match at the beginning (starting from position 0 of the string), even if other parts of the string contain the content that needs to be matched, .match will return none

. matches any character
Use several dots to represent several characters
import re
a = re.match('..','testasdtest')
print(a.group()) #输出te
b = re.match('ab.','testasdtest')
print(b) #返回none,因为表达式是以固定的ab开头然后跟上通配符. 所以必须要先匹配上ab才会往后进行匹配![]()
\d matches digits
A \d represents a digit. There is no match at the beginning, even if other parts of the string contain the content that needs to be matched, .match will return none
import re
a = re.match('\d\d','23es12testasdtest')
print(a)
b = re.match('\d\d\d','23es12testasdtest')
print(b) #要求匹配三个数字,匹配不到返回none
c = re.match('\d','es12testasdtest')
print(c) #起始位置没有匹配成功,一样返回none
\D matches non-digits
There is no match at the beginning, even if other parts of the string contain the content that needs to be matched, .match will return none
import re
a = re.match('\D','23es12testasdtest')
print(a) #开头为数字所以返回none
b = re.match('\D\D','*es12testasdtest')
print(b) #返回*e\s matches special characters, such as blank, space, tab, etc.
import re
print(re.match('\s',' 23es 12testasdtest')) #匹配空格
print(re.match('\s',' 23es 12testasdtest')) #匹配tab
print(re.match('\s','\r23es 12testasdtest')) #匹配\r换行
print(re.match('\s','23es 12testasdtest')) #返回none
\S matches non-blank
import re
print(re.match('\S',' 23es 12testasdtest')) #返回none
print(re.match('\S','\r23es 12testasdtest')) #none
print(re.match('\S','23es 12testasdtest')) 
\w matches words, characters, such as upper and lower case letters, numbers, _ underscore
import re
print(re.match('\w','23es 12testasdtest')) #返回none
print(re.match('\w\w\w','aA_3es 12testasdtest')) #返回none
print(re.match('\w\w\w','\n12testasdtest')) #返回none

\W matches non-word characters
import re
print(re.match('\W','23es 12testasdtest')) #返回none
print(re.match('\W',' 23es 12testasdtest')) #匹配空格![]()
[ ] matches the characters listed in [ ]
Only the characters listed in [ ] are allowed
import re
print(re.match('12[234]','232s12testasdtest')) #因为开头的12没匹配上,所以直接返回none
print(re.match('12[234]','1232s12testasdtest')) #返回123
[^2345] does not match any of 2345
import re
print(re.match('12[^234]','232s12testasdtest')) #因为开头的12没匹配上,所以直接返回none
print(re.match('12[^234]','1232s12testasdtest')) #返回none
print(re.match('12[^234]','1252s12testasdtest')) #返回125[a-z3-5] matches characters in az or 3-5
import re
print(re.match('12[1-3a-c]','1232b12testasdtest')) #123
print(re.match('12[1-3a-c]','12b2b12testasdtest')) #12b
print(re.match('12[1-3a-c]','12s2b12testasdtest')) #返回noneIndicates the quantity
Those written above match a single character. If we want to match multiple characters, we can only repeat the matching character. This is obviously inhumane, so we also need to learn the characters to express the quantity

* Occurs 0 or countless times
import re
a = re.match('..','testasdtest')
print(a.group()) #输出te
a = re.match('.*','testasdtest')
print(a.group()) #全部输出![]()
import re
print(re.match('a*','aatestasdtest')) #匹配跟随在字母a后面的所有a字符
print(re.match('\d*','23aatestasdtest')) #匹配前面为数字的字符
print(re.match('a\d*','ad23aatestasdtest')) #输出a, 因为*也可以代表0次

+ appears at least once
import re
print(re.match('a+','aaatestasdtest')) #匹配前面为字母a的字符,且a至少有1一个
print(re.match('a+','atestasdtest')) #a
print(re.match('a+','caaatestasdtest')) #none
? 1 time or 0 times
import re
print(re.match('a?','abatestasdtest')) #匹配a出现0次或者1次数
print(re.match('a?','batestasdtest')) #输出空,因为a可以为0次
print(re.match('a?','aaatestasdtest')) #a出现0次或者1次,输出1个a
{m} specifies m occurrences
import re
print(re.match('to{3}','toooooabatestasdtest')) #匹配t以及跟随在后面的三个ooo
print(re.match('to{3}','tooabatestasdtest')) #只有两个0,返回none![]()
{m,} occurs at least m times
import re
print(re.match('to{3,}','toooooabatestasdtest')) #匹配t以及跟随在后面的三个ooo至少出现3次
print(re.match('to{3,}','tooabatestasdtest')) #只有两个0,返回none![]()
{m,n} specifies the range from mn times
import re
print(re.match('to{3,4}','toooabatestasdtest')) #刚好有三个ooo,成功匹配
print(re.match('to{3,4}','tooabatestasdtest')) #只有两个o,返回none
print(re.match('to{3,4}','toooooabatestasdtest')) #提取最多四个o
match boundary
$ matches the trailing character
Defines that the entire string must end with the specified string
import re
print(re.match('.*d$','2testaabcd')) #字符串必须以d结尾
print(re.match('.*c','2testaabcd')) #字符串不是以c结尾,返回none![]()
^ matches the beginning character
Defines that the entire string must start with the specified character
import re
print(re.match('^2','2stoooabatestas')) #规定必须以2开头,否则none
print(re.match('^2s','2stoooabatestas')) #必须以2s开头\b matches a word boundary
\b: Indicates the boundary between alphanumeric and non-alphanumeric, and the boundary between non-alphanumeric and alphanumeric. That is, there cannot be letters and numbers on the right side of ve below
import re
print(re.match(r'.*ve\b','ve.2testaabcd')) #因为在python中\代表转义,所以前面加上r消除转义
print(re.match(r'.*ve\b','ve2testaabcd'))
\B matches a non-word boundary
import re
print(re.match(r'.*ve\B','2testaavebcdve')) #ve的右边需要有字母或者数字
print(re.match(r'.*ve\B','2testaave3bcdve'))![]()
match group

| matches any left or right expression
As long as any expression on both sides of the | meets the requirements
import re
print(re.match(r'\d[1-9]|\D[a-z]','2233')) #匹配|两边任意一个表达式
print(re.match(r'\d[1-9]|\D[a-z]','as')) ![]()
(ab) Treat the characters in parentheses as a group
The content in () will be packed in the tuple as a tuple character
import re
a = re.match(r'<h1>(.*)<h1>','<h1>你好啊<h1>')
print(a.group()) #输出匹配的字符
print(a.groups()) #会将()中的内容会作为一个元组字符装在元组中
print('`````````````')
b = re.match(r'<h1>(.*)(<h1>)','<h1>你好啊<h1>')
print(b.groups()) #有两括号就分为两个元组元素
print(b.group(0)) #group中默认是0
print(b.group(1)) #你好啊
print(b.group(2)) #h1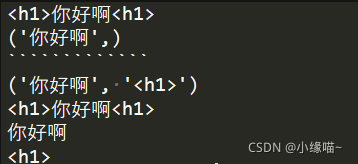
search
Similar to match, search from string
import re
print(re.match(r'\d\d','123test123test'))
print(re.search(r'\d\d','123test123test'))
findall
It can be seen literally that findall is to find all matching characters and return them in a list
import re
print(re.search(r'test','123test123test'))
print(re.findall(r'test','123test123test')) #以列表的方式返回
re.s
Another attribute re.S in findall
In the string a, contains the newline character \n, in this case
- If the re.S parameter is not used, the match is only performed in each line. If there is no line, the next line will start again.
- After using the re.S parameter, the regular expression will take this string as a whole and match it in the whole.
The following is to find the data of test.*123, because test and 123 are in different lines, if re.s is not added, he will search for each match instead of searching for the string as a whole
import re
a = """aaatestaa
aaaa123"""
print(re.findall(r'test.*123',a))
print(re.findall(r'test.*123',a,re.S))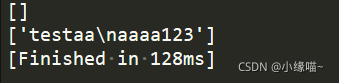
sub
Find all matching data in the string and replace
sub (the data to be replaced, what to replace, the data where the data to be replaced)
import re
print(re.sub('php','python','php是世界上最好的语言——php'))
#输出 "python是世界上最好的语言——python"
split
Split the string and return a list
import re
s = "itcase,java:php-php3;html"
print(re.split(r",",s)) #以,号进行分割
print(re.split(r",|:|-|;",s)) #以,或者:或者-或者;进行分割
print(re.split(r",|:|-|%",s)) #找不到的分隔符就忽略
Greedy vs. Non-greedy
Quantifiers in python are greedy by default, always trying to match as many characters as possible. Use the ? sign to turn off the greedy mode in python
like
import re
print(re.match(r"aa\d+","aa2323")) #会尽可能多的去匹配\d
print(re.match(r"aa\d+?","aa2323")) #尽可能少的去匹配\d
import re
s = "this is a number 234-235-22-423"
# 1.贪婪模式
resule = re.match(r"(.+)(\d+-\d+-\d+-\d)",s) #我们本想数字和字母拆解成两个分组
print(resule.groups()) #('this is a number 23', '4-235-22-4')但我们发现输出的结果中23的数字竟然被弄到前面去了
#因为+它会尽可能多的进行匹配,\d,只需要一个4就能满足,所以前面就尽可能多的匹配
# 2.关闭贪婪模式
#在数量词后面加上 ?,进入非贪婪模式,尽可能少的进行匹配
result = re.match(r"(.+?)(\d+-\d+-\d+-\d)",s)
print(result.groups()) #('this is a number ', '234-235-22-4')
the case
Match phone number
Requirements, the mobile phone number is 11 digits, must start with 1, and the second number is 35678 and one of them
import re
result = re.match(r'1[35678]\d{9}','13111111111')
print(result.group()) #匹配成功
result = re.match(r'1[35678]\d{9}','12111111111')
print(result) #none,第二位为2
result = re.match(r'1[35678]\d{9}','121111111112')
print(result) #none,有12位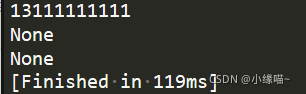
Extract all the text in the source code of the web page
As follows, extract all the text in it and remove the tags. The idea is to use the sub method to replace the label with empty
s = """<div>
<p>岗位职责:</p>
<p>完成推荐算法、数据统计、接口、后台等服务器端相关工作</p>
<p><br></p>
<P>必备要求:</p>
<p>良好的自我驱动力和职业素养,工作积极主动、结果导向</p>
<p> <br></p>
<p>技术要求:</p>
<p>1、一年以上 Python开发经验,掌握面向对象分析和设计,了解设计模式</p>
<p>2、掌握HTTP协议,熟悉NVC、MVVM等概念以及相关wEB开发框架</p>
<p>3、掌握关系数据库开发设计,掌握SQL,熟练使用 MySQL/PostgresQL中的一种<br></p>
<p>4、掌握NoSQL、MQ,熟练使用对应技术解决方案</p>
<p>5、熟悉 Javascript/cSS/HTML5,JQuery,React.Vue.js</p>
<p> <br></p>
<p>加分项:</p>
<p>大数据,数理统计,机器学习,sklearn,高性能,大并发。</p>
</div>"""The most important thing to extract is to turn off the greedy mode,
result = re.sub(r'<.*?>| ','',s) #
print(result)
If the greedy mode is turned off, the content in <xx> will match as little as possible, as long as it can satisfy the following >, and then the content of xxx in <>xxx<> will also be replaced
Extract image URL
import re
s = """<img data-original="https://img02.sogoucdn.com/app/a/100520024/36189693dc8db6bd7c0be389f8aaddbd.jpg" src="https://img02.sogoucdn.com/app/a/100520024/36189693dc8db6bd7c0be389f8aaddbd.jpg" width="250" height="375" .jpg>"""
result1 = re.search(r"src=\"https.*.jpg\"",s)
print(result1.group())
result2 = re.search(r"src=\"(https.*.jpg)\"",s) #我只是想将网址提取出来,所以httpxx加括号,这样我就可以把它单独提取出来,src则不会出来
print(result2.groups()[0])
Extract a string within a specified range from a string
Case 1
If you want from
"
csrftoken=ZjfvZBcDMcVs7kzYqexJqtKiJXIDxcmSnXhGD1ObR2deuHzaU0FuCxSmh10fSmhf; expires=Thu, 29 Jun 2023 07:59:04 GMT; Max-Age=31449600; Path=/; SameSite=Lax
”
The token value is extracted from it
import re
str = "csrftoken=ZjfvZBcDMcVs7kzYqexJqtKiJXIDxcmSnXhGD1ObR2deuHzaU0FuCxSmh10fSmhf; expires=Thu, 29 Jun 2023 07:59:04 GMT; Max-Age=31449600; Path=/; SameSite=Lax"
a = re.search(r'=(.*?);', str)
print(a.group(1)) #输出匹配的字符
Case 2
Extract the line where the keyword is located from the response packet, and you can add variables in the regular
import re
key = "威胁"
a = """
<body data-spm="7663354">
<div data-spm="1998410538">
<div class="header">
<div class="container">
<div class="message">
很抱歉,由于您访问的URL有可能对网站造成安全威胁,您的访问被阻断。
<div>您的请求ID是: <strong>
781bad0a16702307419116917e43b3</strong></div>
</div>
</div>
</div>
"""
res = re.search(r'<.*>(.*?%s.*?)<.*?>'%(key),a,re.S)
print(res.group(1).replace("\n","").replace(" ",""))