Datax from alibaba uses
1. Introduction
DataX is an open source version of Alibaba Cloud DataWorks data integration, and it is an offline data synchronization tool/platform widely used in Alibaba Group. DataX implements efficient data synchronization between various heterogeneous data sources including MySQL, Oracle, OceanBase, SqlServer, Postgre, HDFS, Hive, ADS, HBase, TableStore (OTS), MaxCompute (ODPS), Hologres, DRDS, etc.
2. Features
As a data synchronization framework, DataX abstracts the synchronization of different data sources into a Reader plug-in that reads data from the source data source, and a Writer plug-in that writes data to the target end. In theory, the DataX framework can support data synchronization of any data source type Work. At the same time, the DataX plug-in system serves as an ecosystem. Every time a new data source is connected, the newly added data source can communicate with the existing data source.
DataX in detail
3. Supported databases
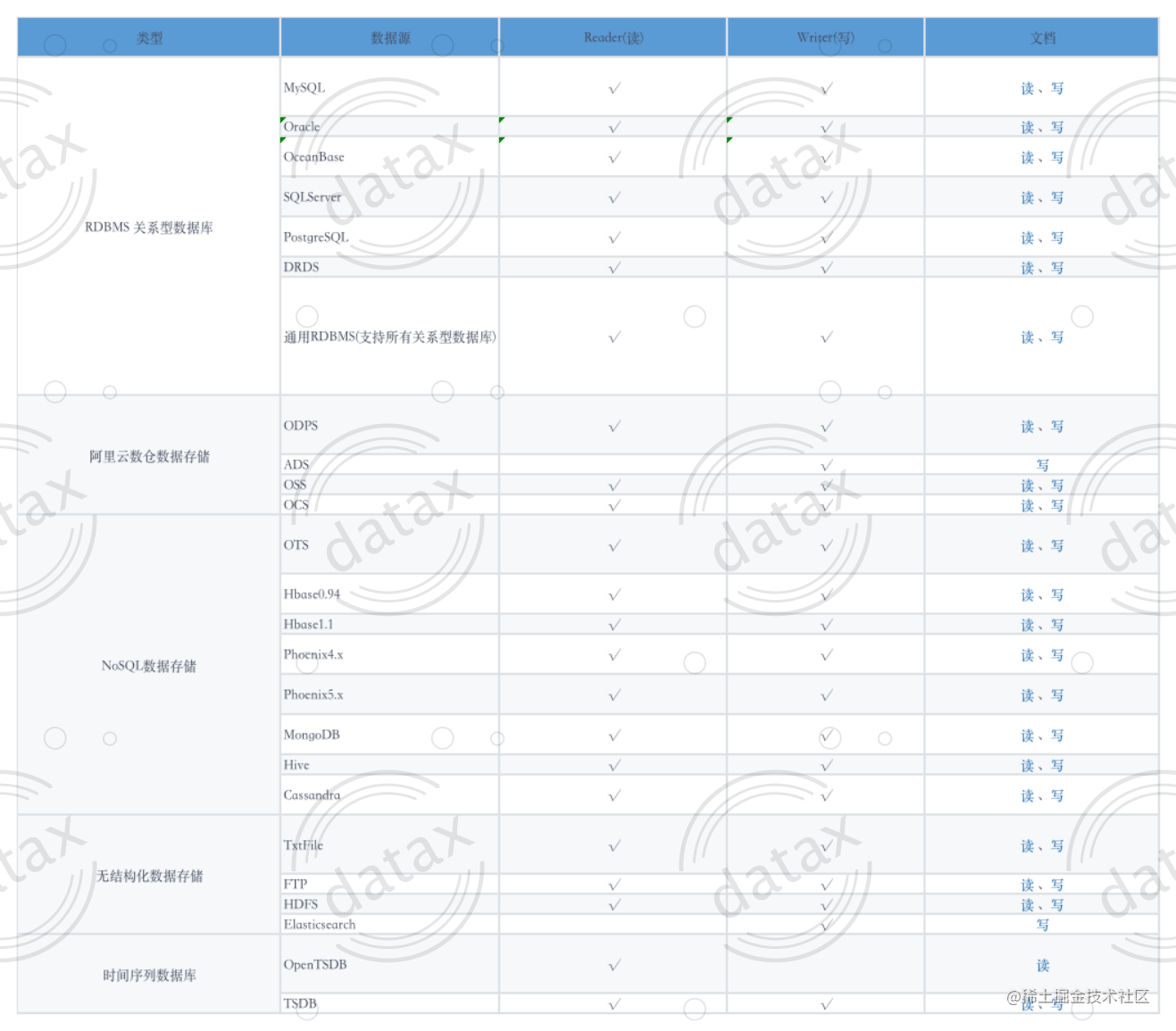
DataX currently has a relatively comprehensive plug-in system, and mainstream RDBMS databases, NOSQL, and big data computing systems have been connected. Currently, the supported data is as shown in the figure below. For details, please click: DataX Data Source Reference Guide .
The above is excerpted from: Introduction to official documents
4. Common usage scenarios
1.1 MysqlReader plugin
1.1.1 Quick introduction:
The MysqlReader plug-in implements reading data from Mysql. In the underlying implementation, MysqlReader connects to the remote Mysql database through JDBC, and executes the corresponding sql statement to SELECT the data from the mysql database.
Unlike other relational databases, MysqlReader does not support FetchSize.
1.1.2 Implementation principle:
In short, MysqlReader connects to the remote Mysql database through the JDBC connector, and generates query SELECT SQL statements according to the information configured by the user, and then sends them to the remote Mysql database, and executes the SQL to return the results using the DataX custom data type Assembled into an abstract data set and passed to the downstream Writer for processing.
For the information of Table, Column and Where configured by the user, MysqlReader splices it into SQL statements and sends it to the Mysql database; for the querySql information configured by the user, MysqlReader directly sends it to the Mysql database.
1.1.3 Parameter description:
jdbcUrl : Description: Describes the JDBC connection information to the peer database, using JSON array description, and supports one library to fill in multiple connection addresses. The reason why JSON arrays are used to describe the connection information is because Ali Group supports multiple IP detections internally. If multiple IPs are configured, MysqlReader can detect the connectivity of the IPs in turn until a legal IP is selected. If all connections fail, MysqlReader reports an error. Note that jdbcUrl must be included in the connection hive. For the external use of Ali Group, just fill in a JDBC connection with the JSON array.
username : Description: The username of the destination database
password : Description: The password of the destination database
table : Description: The table name of the destination table (one or more tables are supported. When configuring multiple tables, you must ensure that all table structures are consistent.)
Note: table and jdbcUrl must be included in the connection hive
column : Description: The fields in which data needs to be written in the destination table, and the fields are separated by English commas. For example: "column": ["id", "name", "age"]. If you want to write all columns sequentially, use * to indicate, for example: “column”: ["*"].
splitPk : Description: When MysqlReader extracts data, if splitPk is specified, it means that the user wants to use the field represented by splitPk to split the data, and DataX will start concurrent tasks for data synchronization, which can greatly improve the performance of data synchronization.
It is recommended that splitPk users use the primary key of the table, because the primary key of the table is usually relatively uniform, so the split shards are not prone to data hotspots.
Currently splitPk only supports integer data segmentation, and does not support other types such as floating point, string, and date. If the user specifies other unsupported types, MysqlReader will report an error!
If splitPk is not filled in, including not providing splitPk or the value of splitPk is empty, DataX regards it as using a single channel to synchronize the table data.
where : Description: filter conditions, MysqlReader splices SQL according to the specified column, table, and where conditions, and extracts data based on this SQL. In actual business scenarios, the data of the current day is often selected for synchronization, and the where condition can be specified as gmt_create > $bizdate . Note: The where condition cannot be specified as limit 10, limit is not a legal where clause of SQL.
The where condition can effectively perform business incremental synchronization. If you do not fill in the where statement, including the key or value that does not provide where , DataX is regarded as synchronizing the full amount of data.
querySql : Description: In some business scenarios, the where configuration item is not enough to describe the filtering conditions, and users can customize the filtering SQL through this configuration type. When the user configures this item, the DataX system will ignore the configuration types of table and column, and directly use the content of this configuration item to filter the data. For example, if you need to synchronize data after multi-table join, use select a,b from table_a join table_b on table_a.id = table_b.id
When the user configures querySql, MysqlReader directly ignores the configuration of table, column, and where conditions, and the priority of querySql is higher than that of table, column, and where options. (Not mandatory, but the actual application scenario needs to specify the logic, all used according to actual needs)
{
"job": {
"setting": {
"speed": {
"channel": 3
},
"errorLimit": {
"record": 0,
"percentage": 0.02
}
},
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"username": "root",
"password": "root",
"column": [
"id",
"name"
],
"splitPk": "db_id",
"connection": [
{
"table": [
"table"
],
"jdbcUrl": [
"jdbc:mysql://127.0.0.1:3306/database"
]
}
]
}
},
"writer": {
"name": "streamwriter",
"parameter": {
"print":true
}
}
}
]
}
}
1.2 MysqlWriter plugin
1.2.1 Quick introduction:
The MysqlWriter plug-in implements the function of writing data to the destination table of the Mysql main library. In the underlying implementation, MysqlWriter connects to the remote Mysql database through JDBC, and executes the corresponding insert into ... or (replace into ...) sql statement to write the data into Mysql, which will be submitted to the database in batches internally, requiring the database itself to use the innodb engine .
MysqlWriter is for ETL development engineers, who use MysqlWriter to import data from data warehouses to Mysql. At the same time, MysqlWriter can also be used as a data migration tool to provide services for DBA and other users.
1.2.2 Implementation principle:
MysqlWriter obtains the protocol data generated by Reader through the DataX framework, and generates it according to the writeMode you configured
insert into...(When the primary key/unique index conflicts, the conflicting rows will not be written) or replace into...(When there is no primary key/unique index conflict, the behavior is consistent with insert into, and the new row will replace the original row when there is a conflict. There are rows with all fields) statement to write data to Mysql. For performance considerations, PreparedStatement + Batch is adopted, and rewriteBatchedStatements=true is set to buffer the data into the thread context Buffer. When the Buffer accumulates to a predetermined threshold, a write request is initiated.
Note: The database where the destination table is located must be the main database to write data; the entire task must have at least the insert/replace into... permission, whether other permissions are required depends on the statements specified in preSql and postSql in your task configuration.
1.2.3 Parameter description:
jdbcUrl : Description: JDBC connection information of the destination database. When the job is running, DataX will append the following attributes to the jdbcUrl you provide: yearIsDateType=false&zeroDateTimeBehavior=convertToNull&rewriteBatchedStatements=true
Notice:
1. Only one jdbcUrl value can be configured on a database. This is different from MysqlReader that supports multiple standby database detection, because it does not support the situation where there are multiple master databases in the same database (dual master import data situation)
2. jdbcUrl follows the official Mysql specification, and can fill in additional connection control information. For example, if you want to specify the connection code as gbk, add the attribute useUnicode=true&characterEncoding=gbk after jdbcUrl. For details, please refer to the official Mysql documentation or consult the corresponding DBA.
username : Description: The username of the destination database
password : Description: The password of the destination database
table : Description: The table name of the destination table (one or more tables are supported. When configuring multiple tables, you must ensure that all table structures are consistent.)
Note: table and jdbcUrl must be included in the connection hive
column : Description: The fields in which data needs to be written in the destination table, and the fields are separated by English commas. For example: "column": ["id", "name", "age"]. If you want to write all columns sequentially, use * to indicate, for example: “column”: ["*"].
session : Description: When DataX obtains the Mysql connection, it executes the SQL statement specified by the session, and modifies the current connection session attributes (changing the sql_mode option, etc., not required)
preSql : Description: Before writing data to the target table, the standard statement here will be executed first. If there is a table name that you need to operate in Sql, please use @table to represent it, so that when the Sql statement is actually executed, the variable will be replaced according to the actual table name. For example, your task is to write to 100 isomorphic sub-tables at the destination (table names: datax_00, datax01, ... datax_98, datax_99), and you want to delete the data in the table before importing the data, then you It can be configured like this: "preSql":["delete from table name"], the effect is: before executing to write data to each table, the corresponding delete from corresponding table name will be executed first. (pre-processing before writing, optional)
postSql : Description: After writing data to the target table, the standard statement here will be executed. (The principle is the same as preSql, post-processing after writing, not mandatory)
writeMode : Description: Control writing data to the target table using insert into or replace into or ON DUPLICATE KEY UPDATE statement
batchSize : Description: The number of records submitted in batches at one time, this value can greatly reduce the number of network interactions between DataX and Mysql, and improve the overall throughput. However, if the value is set too large, it may cause OOM of the DataX running process. (default: 1024)
{
"job": {
"setting": {
"speed": {
"channel": 1
}
},
"content": [
{
"reader": {
"name": "streamreader",
"parameter": {
"column" : [
{
"value": "DataX",
"type": "string"
},
{
"value": 19880808,
"type": "long"
},
{
"value": "1988-08-08 08:08:08",
"type": "date"
},
{
"value": true,
"type": "bool"
},
{
"value": "test",
"type": "bytes"
}
],
"sliceRecordCount": 1000
}
},
"writer": {
"name": "mysqlwriter",
"parameter": {
"writeMode": "insert",
"username": "root",
"password": "root",
"column": [
"id",
"name"
],
"session": [
"set session sql_mode='ANSI'"
],
"preSql": [
"delete from test"
],
"connection": [
{
"jdbcUrl": "jdbc:mysql://127.0.0.1:3306/test?useUnicode=true&characterEncoding=gbk",
"table": [
"test"
]
}
]
}
}
}
]
}
}
Combining the above two examples with actual usage scenarios:
{
"job": {
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"connection": [
{
"jdbcUrl": ["jdbc:mysql://127.0.0.1:3306/test_reader"],
"querySql": ["select id,unionid,mobile,state from test where state = 1"]
}
],
"password": "root",
"username": "root"
}
},
"writer": {
"name": "mysqlwriter",
"parameter": {
"column": [
"id",
"unionid",
"mobile",
"state"
],
"connection": [
{
"jdbcUrl": "jdbc:mysql://127.0.0.1:3306/test_writer",
"table": ["test_one"]
}
],
"password": "root",
"username": "root"
}
}
}
],
"setting": {
"speed": {
"channel": "1"
}
}
}
}