Article directory
- Basic I/O
-
- 1. Revisiting the file
- 2. In-depth understanding of file system calls
- 3. Redirect
- 4. How to understand that everything is a file under Linux
- 5. Buffer
- 6. Disk files
- 7. Soft and hard links
- 8. Dynamic library and static library
Basic I/O
1. Revisiting the file
1.1 Preparations
1.1.1 Asking questions
A few questions before talking about files:
- Do you really understand the principle and operation of files? Not a language problem, but a system problem
- Is it only C/C++ that has file operations? python, java, go...their file operation methods are different, how to understand this phenomenon? Is there a unified perspective to look at all language file operations?
- When operating a file, the first thing to do is to open the file. What is the purpose of opening the file? How to understand it?
1.1.2 Consensus reached
- File = content + attribute => operations on files include: operations on content and operations on attributes
- When the file is not being operated, where is the file generally located? disk
- When we operate on files, where do the files need to be? Why? memory, because the von Neumann system
- When we operate on a file, the file needs to be loaded into the memory in advance. Is the content or the attribute loaded? at least have attributes
- When we operate on the file, the file needs to be loaded into the memory in advance. Is it you who load the file into the memory (are you opening it alone)? No, there must be a lot of different files in the memory properties of
- So in summary, the essence of opening a file is to load the required file attributes into the memory . There must be a large number of opened files inside the OS at the same time, so should the operating system manage these opened files? To, first describe, then organize (how to manage)
First describe: the file structure struct file built in memory {file attribute (it can come from the disk), struct file*next} indicates the file to be opened
For each opened file, a struct structure corresponding to the file object must be created in the OS, and all struct file structures can be linked with a certain data structure => within the OS, the opened file is managed , It is converted into adding, deleting, checking and modifying the linked list
=> Conclusion: The file is opened, and the OS needs to create a corresponding kernel data structure for the opened file

- Files can actually be divided into two categories: disk files, opened files (memory files) [the first half of this article talks about opened files, and the second half talks about disk files]
- The file is opened, who is opening it? OS, but who made the OS open? User (represented by a process [the written code compiles and runs to become a process])
- All our previous file operations are the relationship between the process and the opened file
- It is the relationship between the process and the opened file: the relationship between struct task_struct and struct file
1.2 Recalling C language file operations
The following content can also be called the language scheme of file operation
1.2.1 Writing files
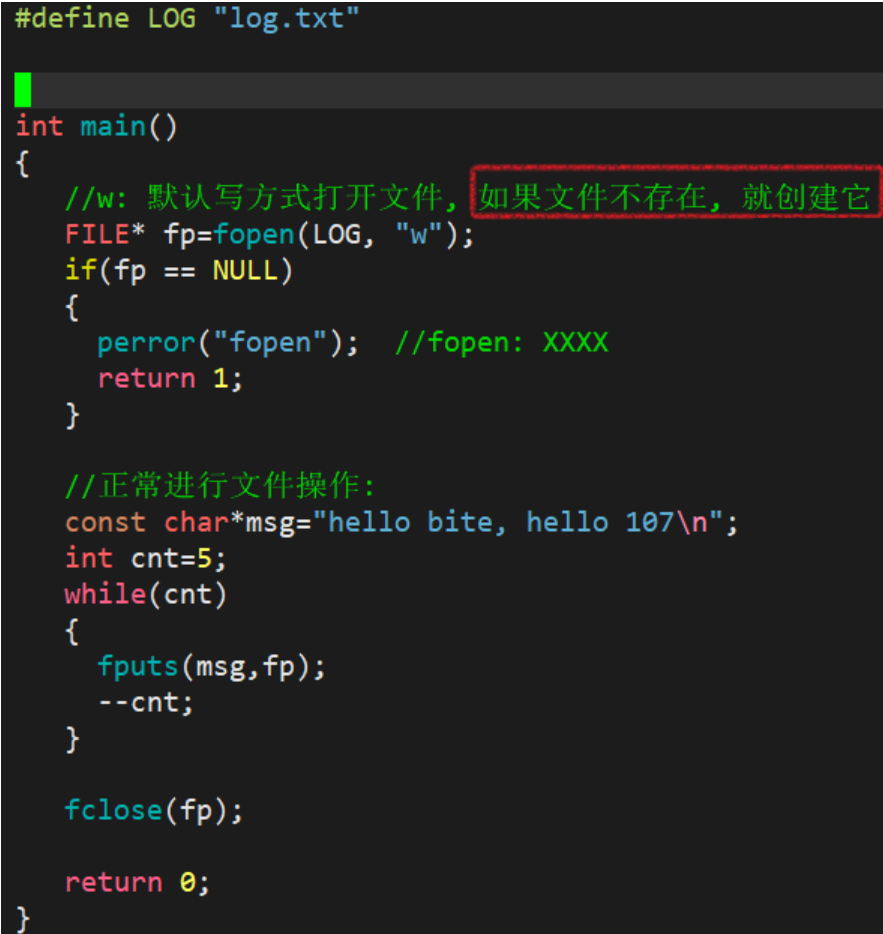
Discrimination

fprintf
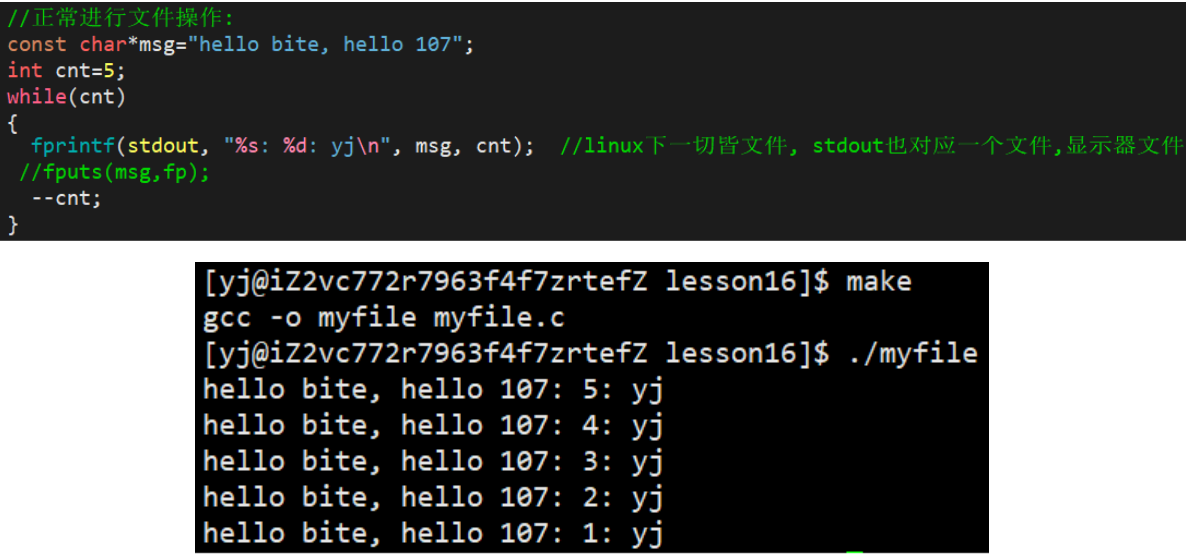
snprintf
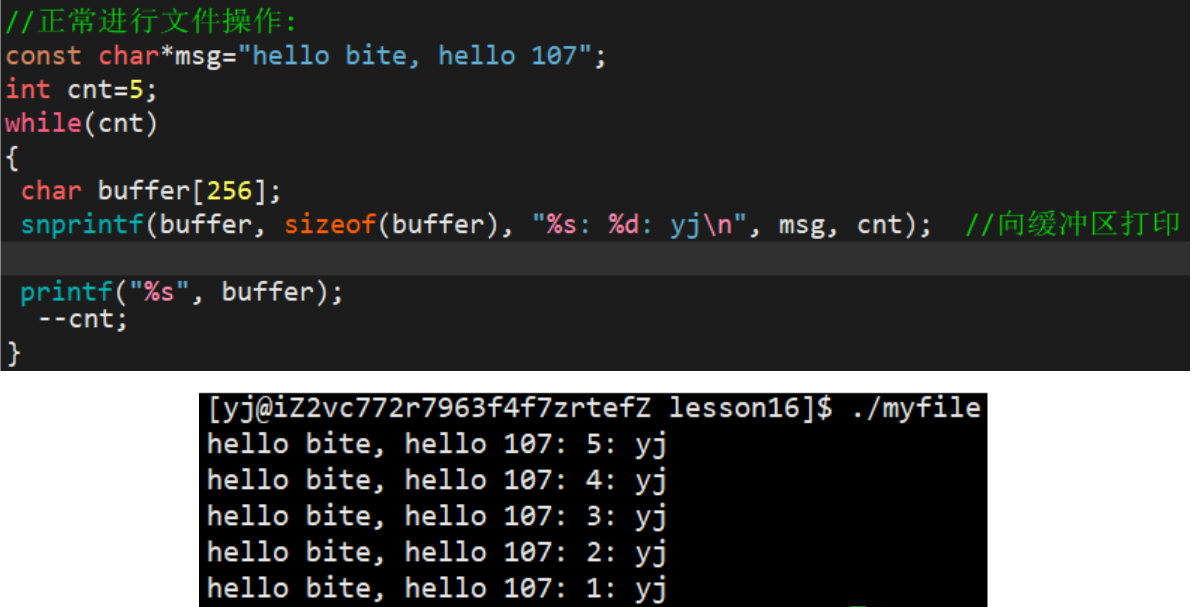
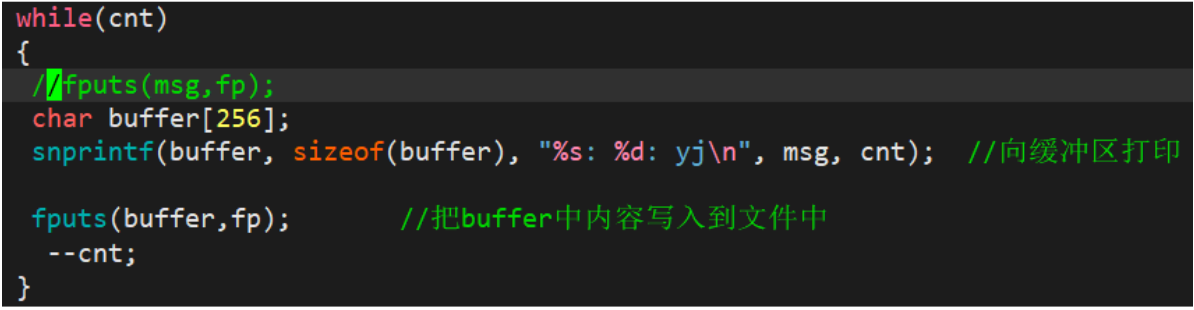
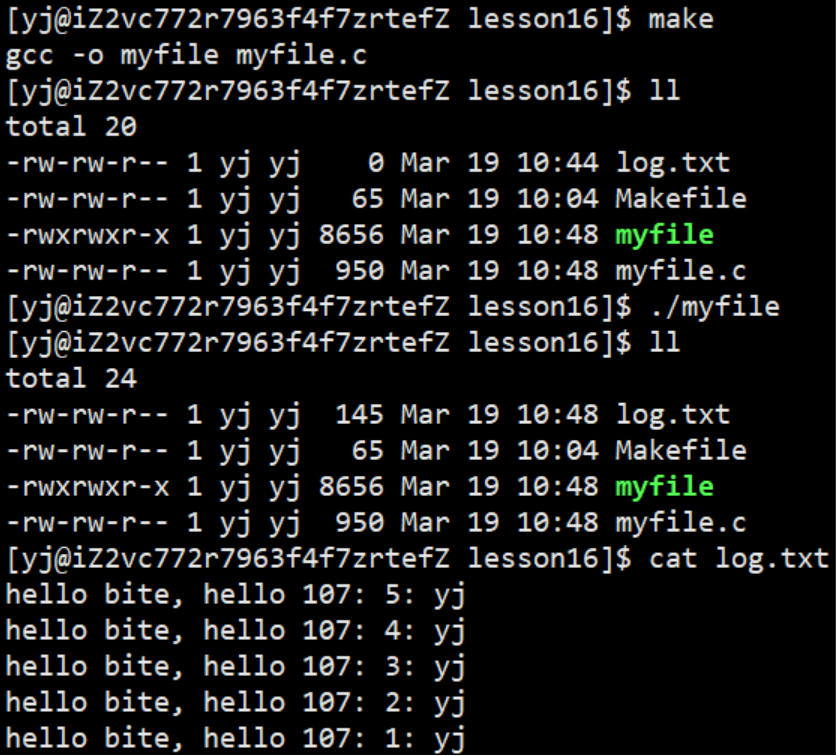
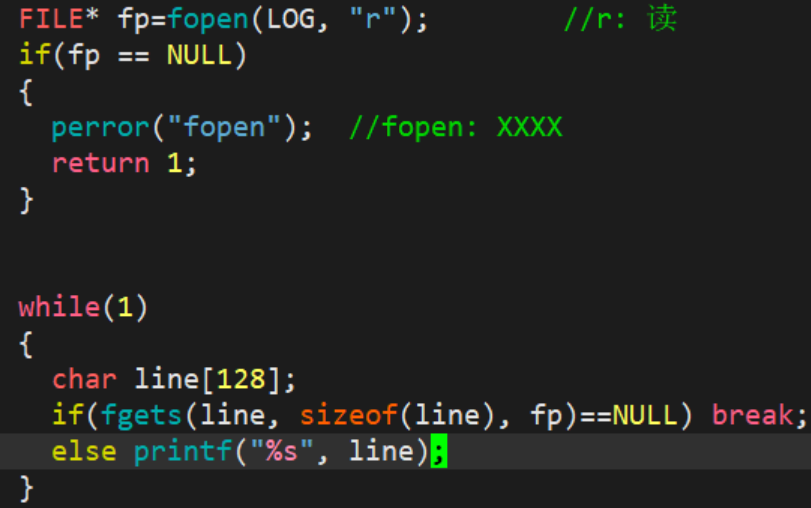
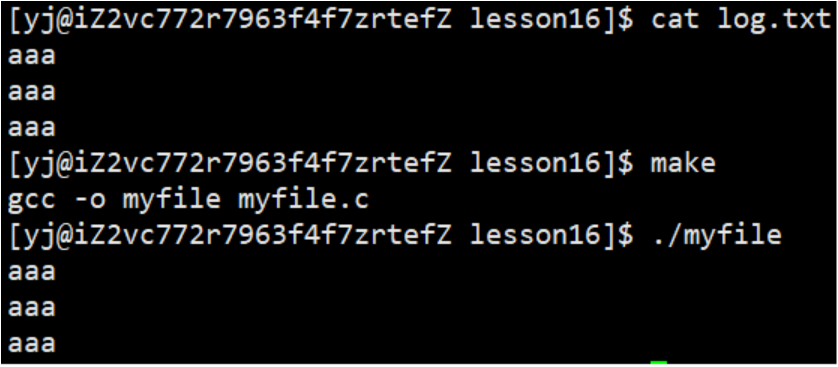
1.2.2 Reading files
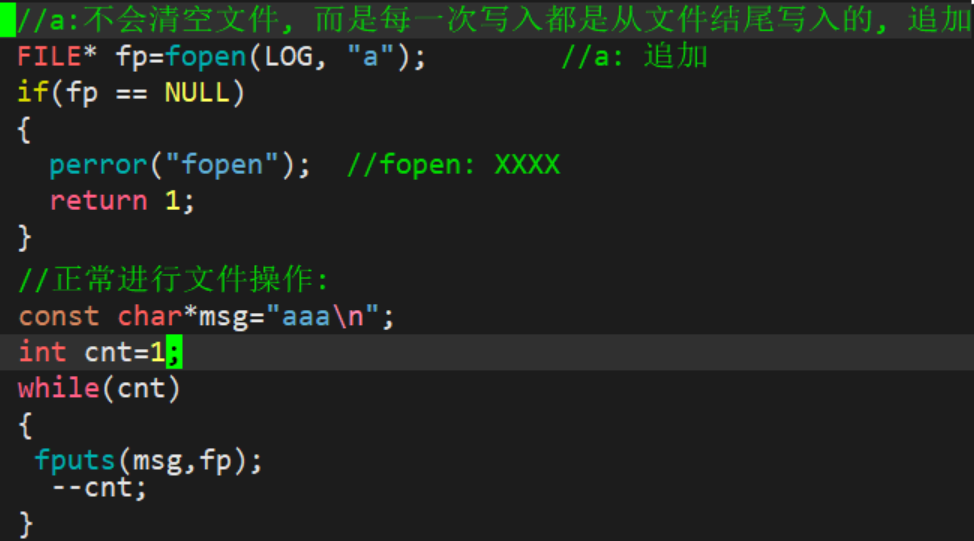
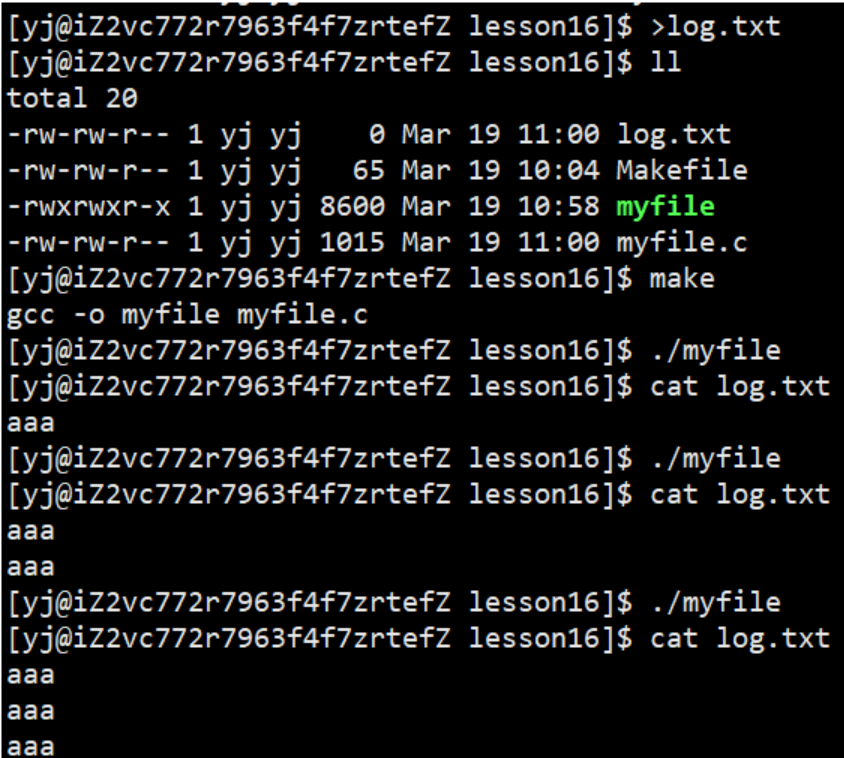
1.2.3 Appending to a file
1.3 System calls for file operations
The following content can also be called the system scheme of file operation
1.3.1 Introduction of OS interface open (bit flag)
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
int open(const char *pathname, int flags);
int open(const char *pathname, int flags, mode_t mode);
pathname: 要打开或创建的目标文件
flags: 打开文件时,可以传入多个参数选项,用下面的一个或者多个常量进行“或”运算,构成flags。
参数:
O_RDONLY: 只读打开
O_WRONLY: 只写打开
O_RDWR : 读,写打开
这三个常量,必须指定一个且只能指定一个
O_CREAT : 若文件不存在,则创建它。需要使用mode选项,来指明新文件的访问权限
O_APPEND: 追加写
返回值:
成功:新打开的文件描述符
失败:-1
Regarding the second parameter flags, it is a bitmap structure:

Small demo :
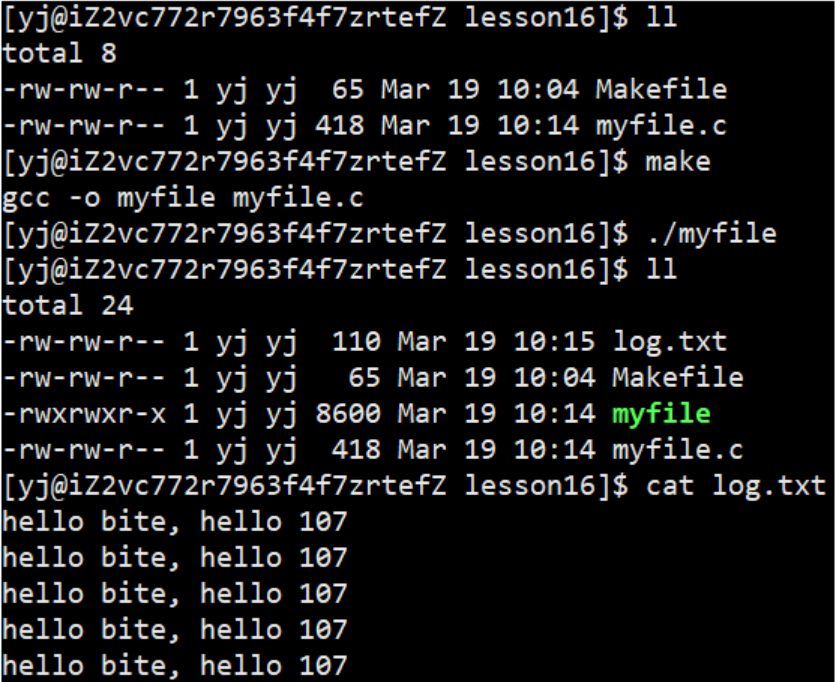
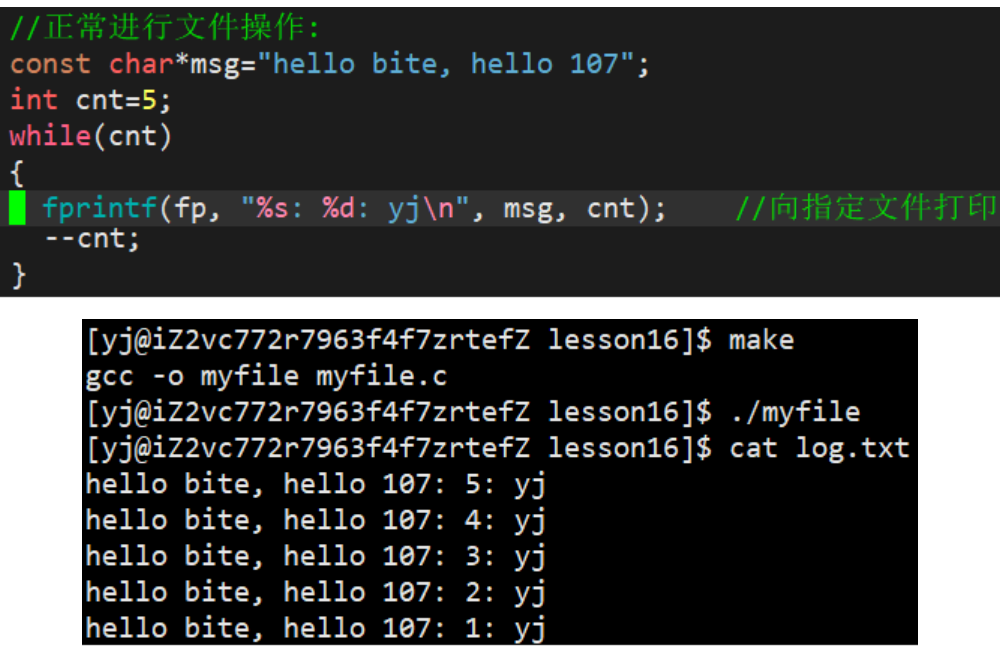
The following code:
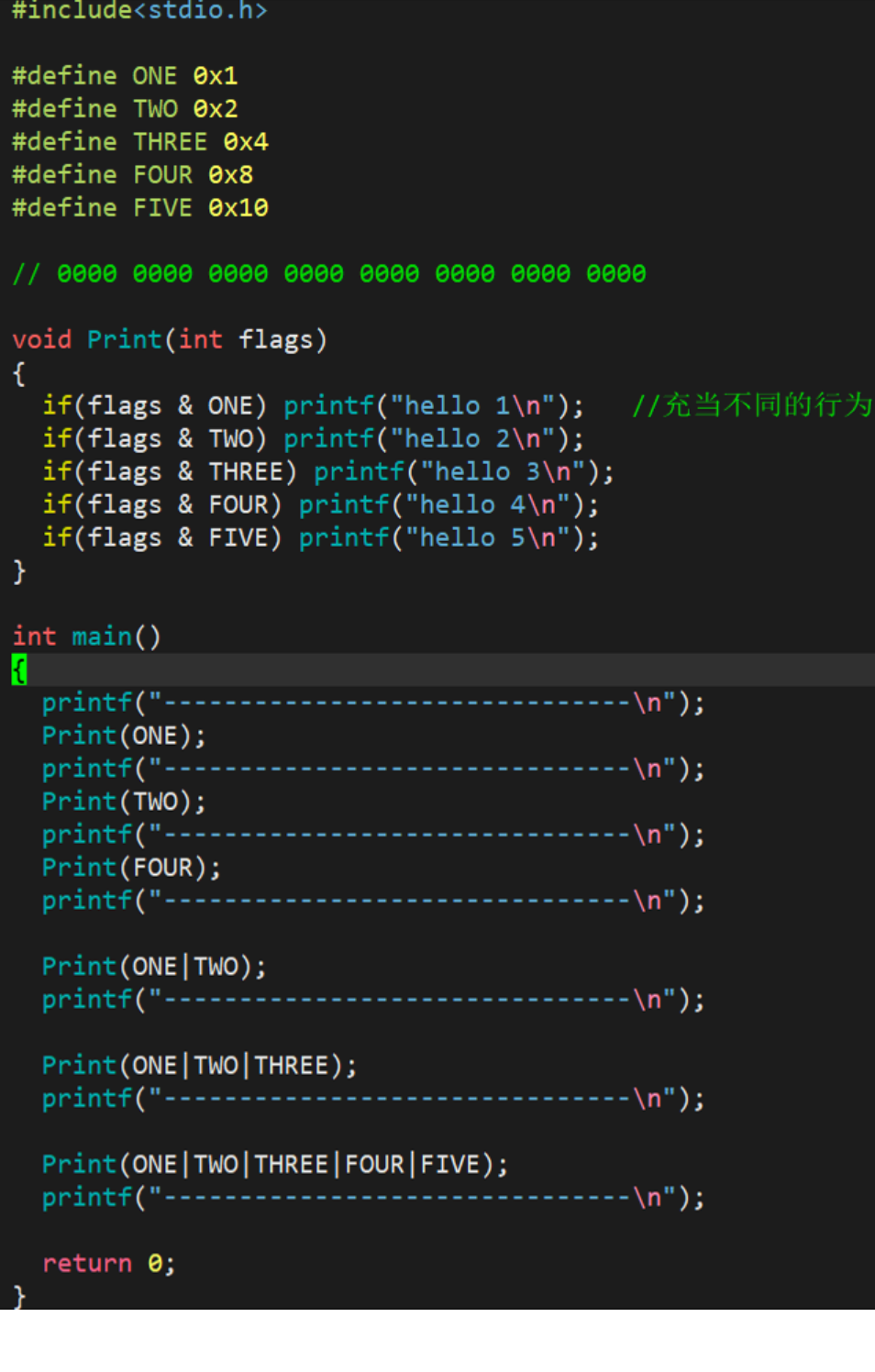
operation result:
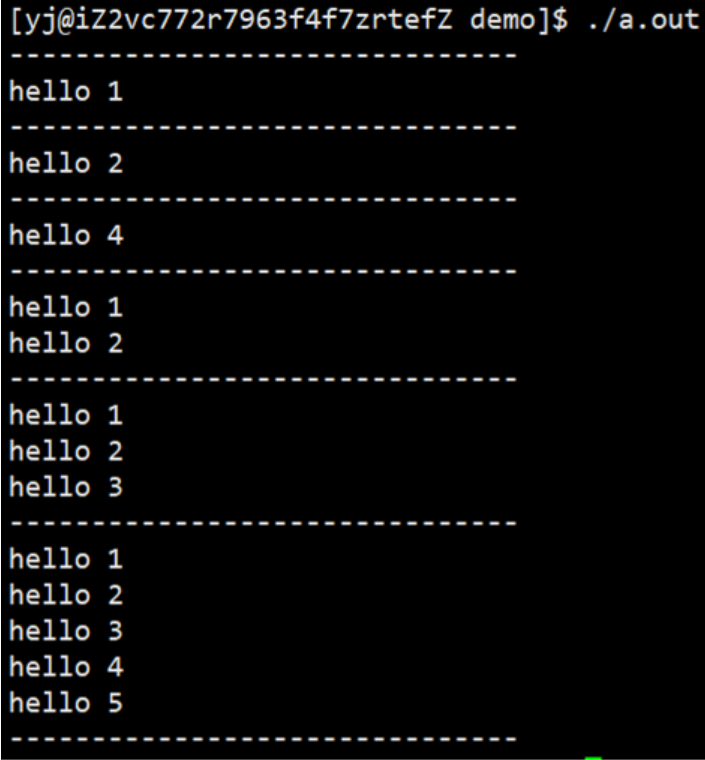
1.3.2 Write operation
int fd = open(FILE_NAME, O_WRONLY | O_CREAT | O_TRUNC, 0666);
1.3.3 Add operation
int fd = open(FILE_NAME, O_WRONLY | O_CREAT | O_APPEND, 0666);
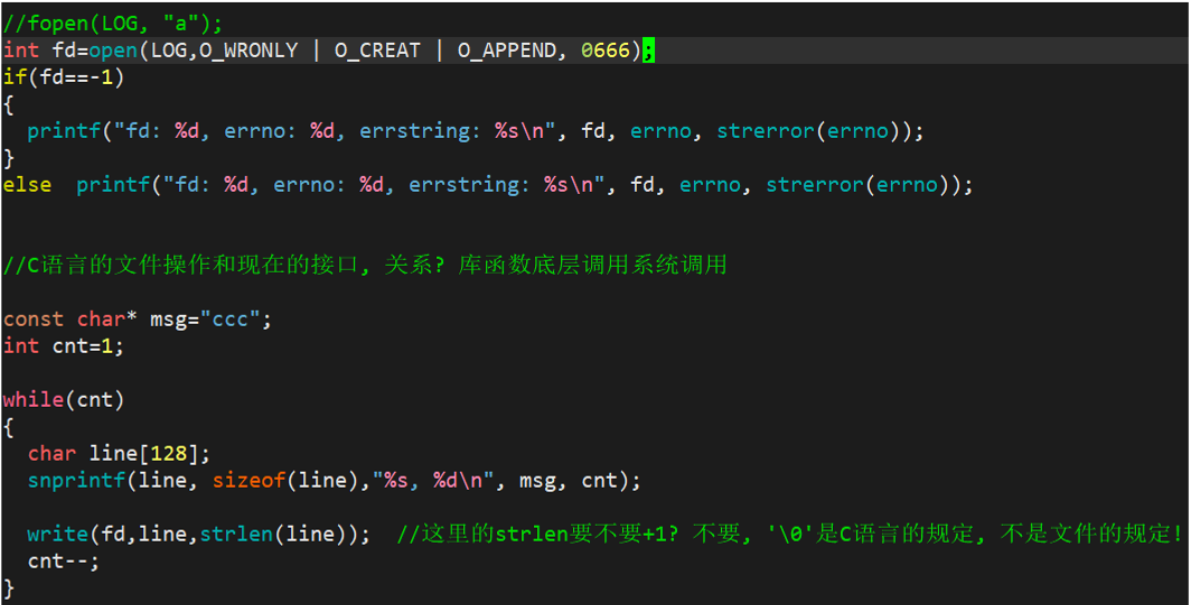
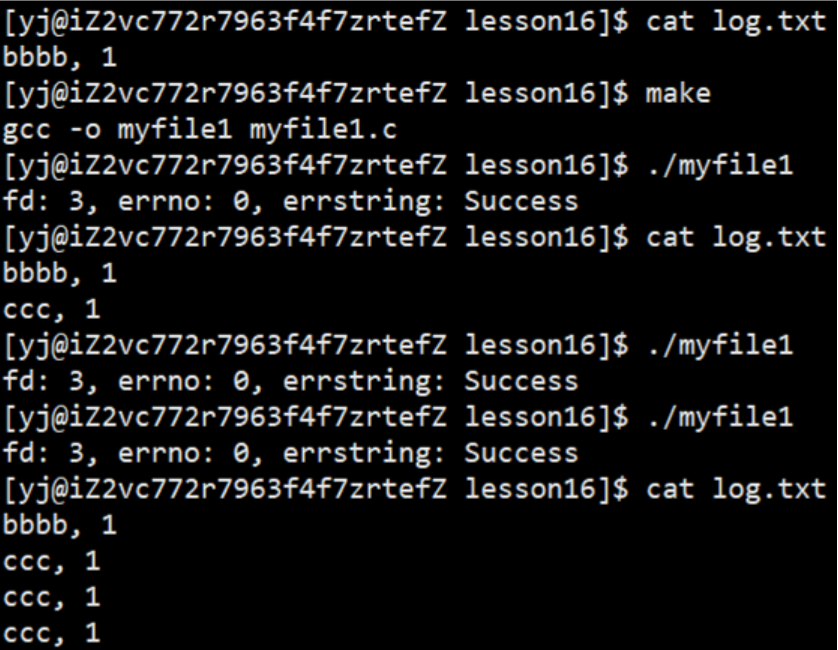
1.3.4 Read-only operation
int fd = open(FILE_NAME, O_RDONLY);

1.4 Answer the questions
To answer the questions posed above:
- Is it only C/C++ that has file operations? python, java, go...their file operation methods are different, how to understand this phenomenon? Is there a unified perspective to look at all language file operations?
Not only C/C++ has file operations, but also other languages; the file operation methods of each language are different because different languages have personalized file operations to meet the grammatical paradigm of different languages; look at all language file operations from a unified perspective: all To call the interface of the system to complete the file operation
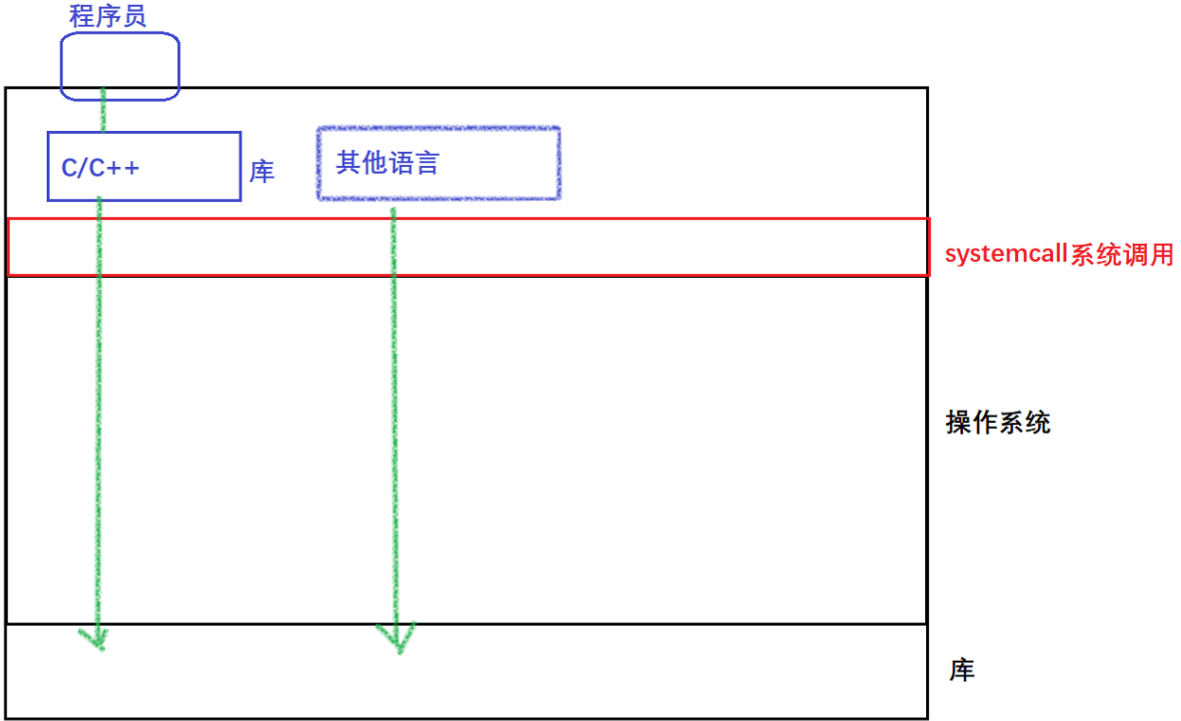
- When operating a file, the first thing to do is to open the file. What is the purpose of opening the file? How to understand it?
The essence of opening a file is to load the required file attributes into the memory. For each opened file, a struct structure corresponding to the file object must be created in the OS. All struct file structures can be linked with a certain data structure. Get up => Inside the OS, the management of the opened files is converted into adding, deleting, checking and modifying the linked list
2. In-depth understanding of file system calls
2.1 File descriptors
- Learning the file system call function open, we found that the open function will have a return value, this return value is the file descriptor, and the file descriptor is a small integer
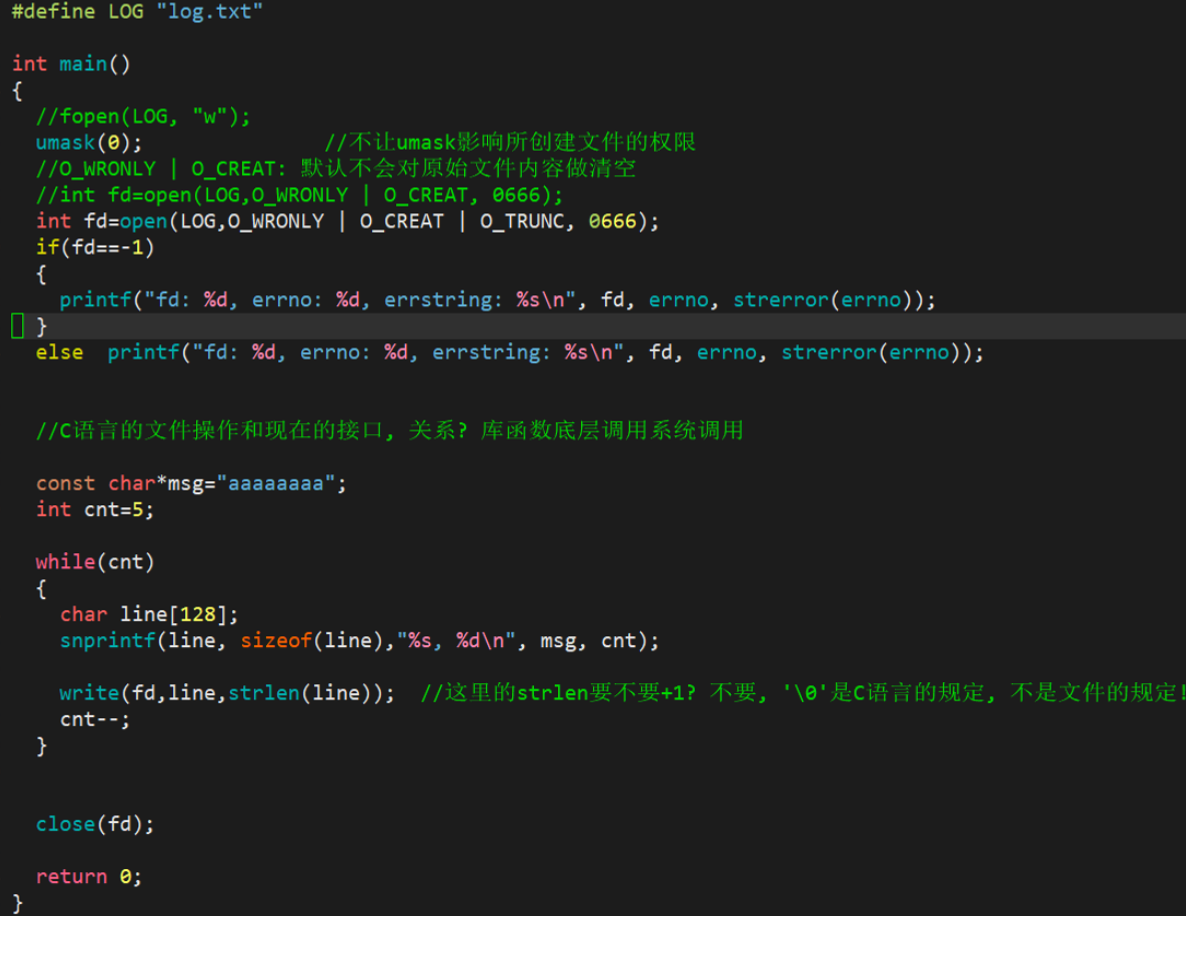
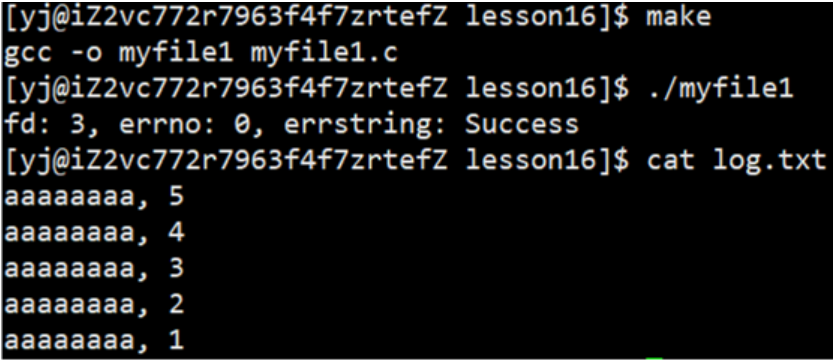
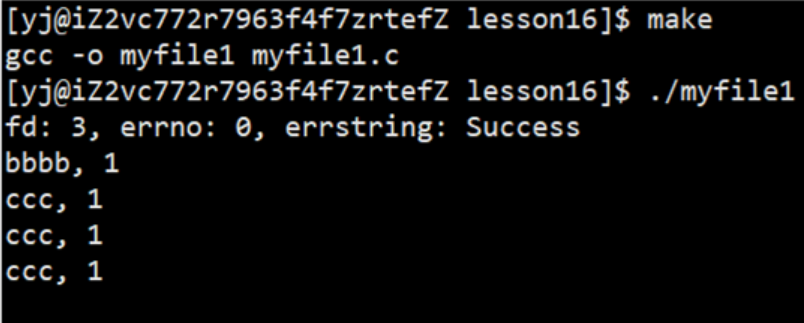
Open the LOG file (log.txt file) in writing mode and receive the return value, print out the file descriptor, and observe the running results
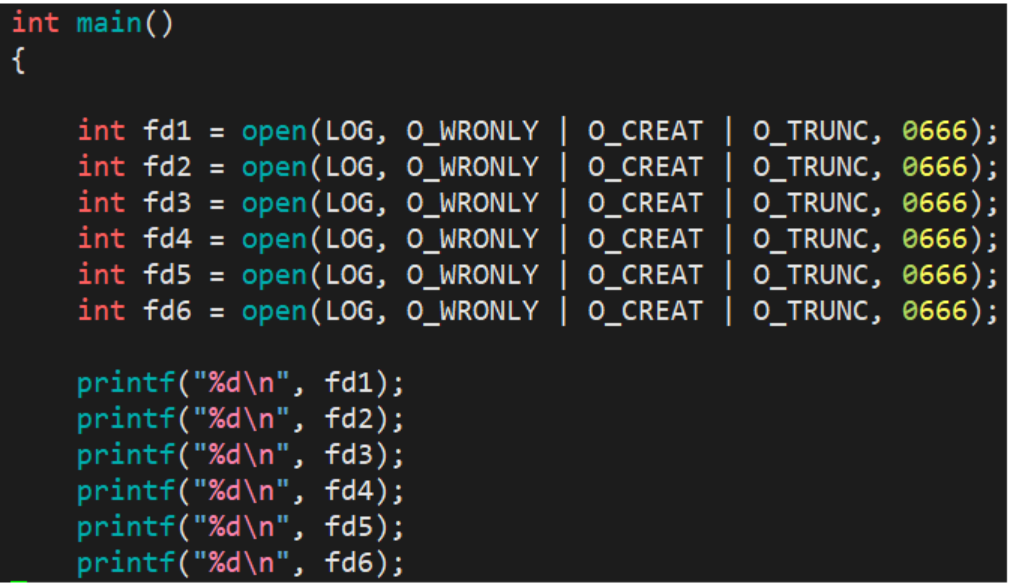
operation result:
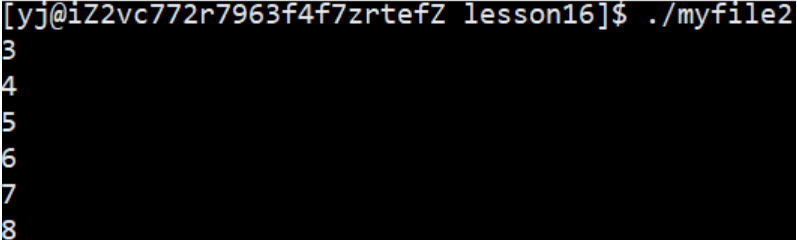
We will find that the printing result starts from 3 and increases successively, so we lead to two questions:
- Why does the result start from 3 instead of 0, in sequence 0, 1 , 2...
- What kind of structure will increase continuously and sequentially like the above result?
Let's solve these two problems
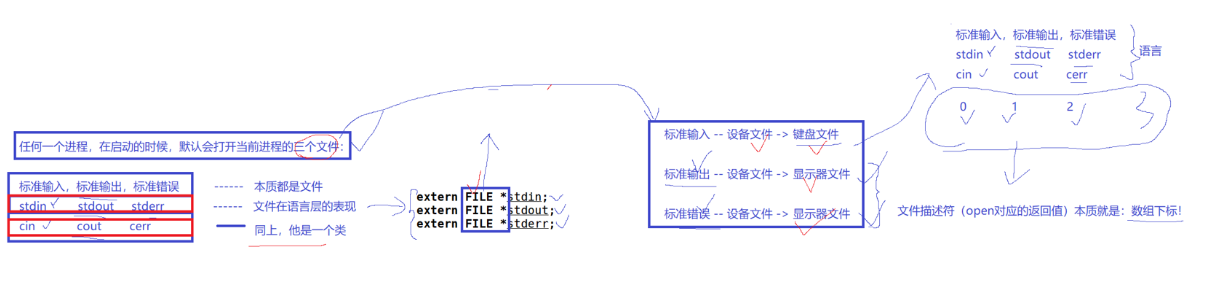
2.1.1 stdin & stdout & stderr
C will open three input and output streams by default, namely stdin, stdout, stderr
Careful observation reveals that the types of these three streams are all FILE , the return value type of fopen, and the file pointer *
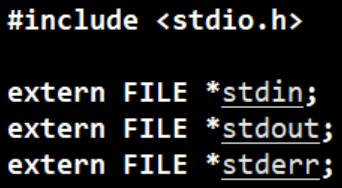
Small demo:
Write the following code:
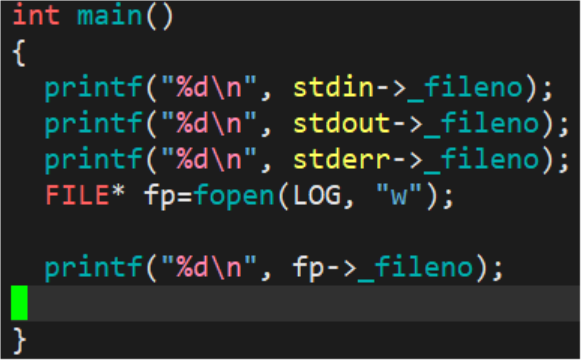
Running observations found:
At this time, 0, 1, 2 are printed
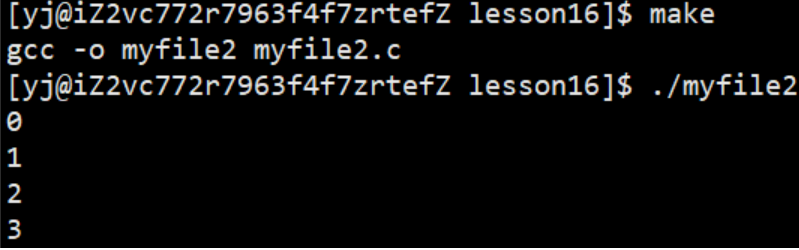
So this also explains why the file descriptor starts from 3 by default, because 0, 1, and 2 are occupied by default. These interfaces of our C language encapsulate the default calling interface of the system. At the same time, the FILE structure of C language also encapsulates the file descriptor of the system.
Understanding FIEL
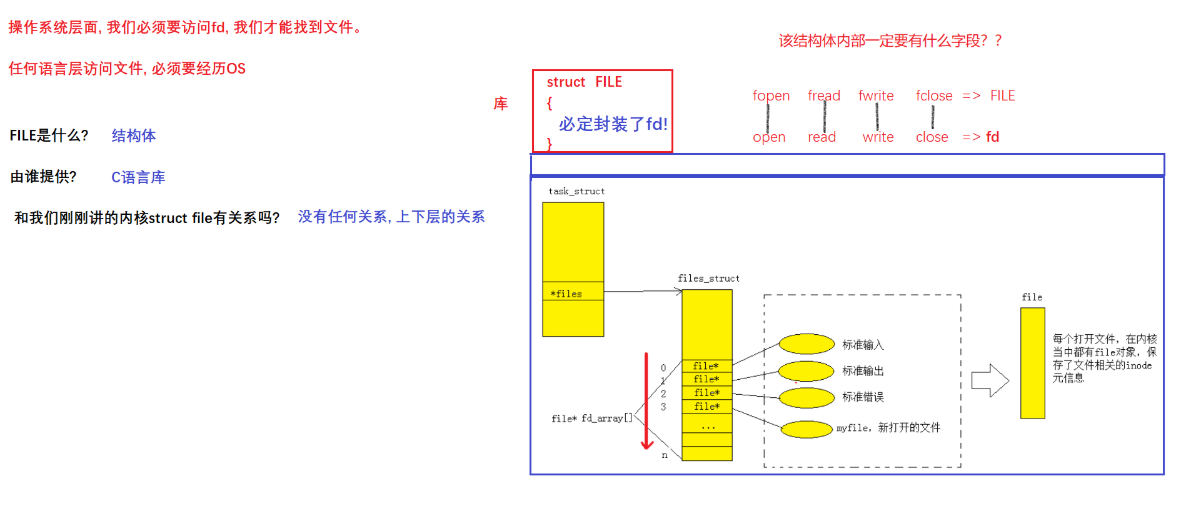
Summarize
- By default, a Linux process has three open file descriptors, namely standard input 0, standard output 1, and standard error 2.
- The physical devices corresponding to 0,1,2 are generally: keyboard, monitor, monitor
2.1.2 The nature of file descriptors
To solve the second problem, what kind of structure will increase continuously and sequentially like the above result?
As shown below:
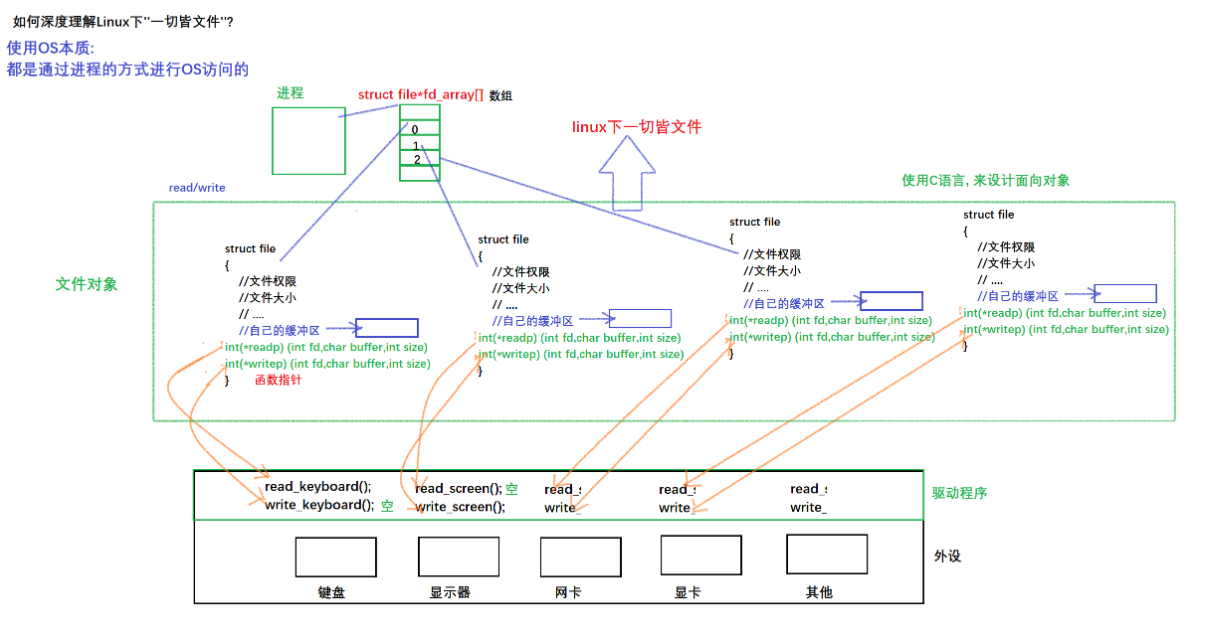
The PCB contains a files pointer, which points to a structure belonging to the corresponding relationship between the process and the file: struct files_struct, and this structure contains an array called the struct file* fd _array[]pointer array, so the first three 0, 1, and 2 in the figure are replaced by the keyboard and The display calls, which is why the subsequent file descriptors start from 3, and then fill in the address of the file into the No. 3 file descriptor, and the No. 3 file descriptor now points to the newly opened file.
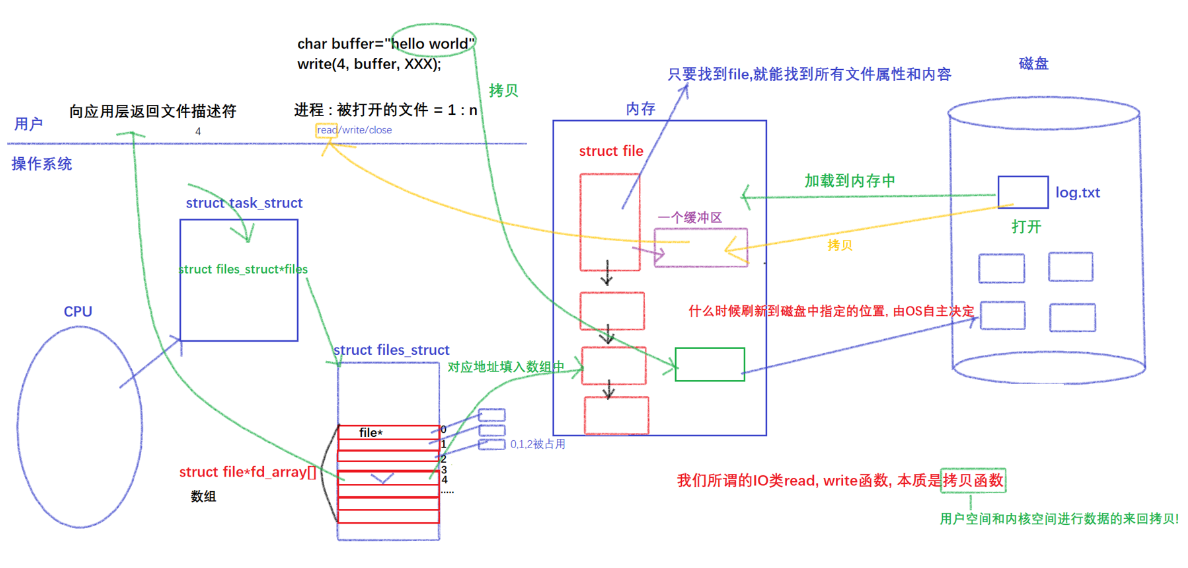
Then return the No. 3 descriptor to the user through the system call to get a number called 3, so when a process accesses a file, it needs to pass in 3, find the corresponding file descriptor table through the system call, and find it through the stored address If the corresponding file is found, the file can be operated on. Therefore, the essence of a file descriptor is an array subscript.
So what are the benefits of doing this?
As shown in the figure below, the process management is on the left, and the file system is on the right, which completes the decoupling between modules
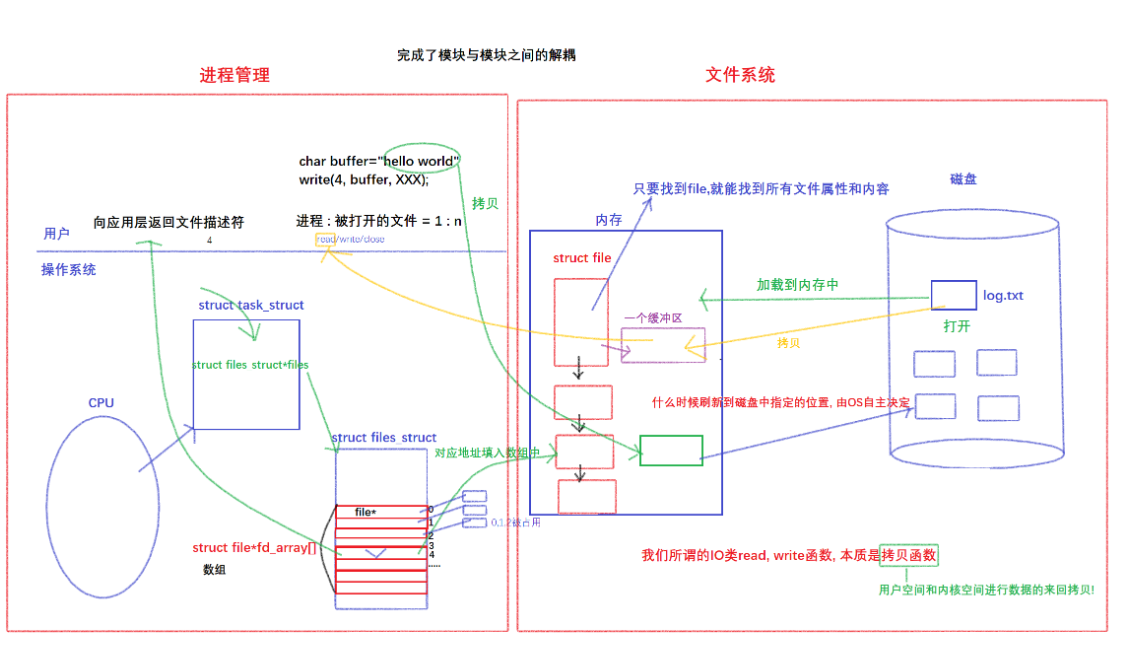
2.1.3 Allocation rules for file fd
Look directly at the code:
#include <stdio.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
int main()
{
int fd = open("myfile", O_RDONLY);
if(fd < 0){
perror("open");
return 1;
}
printf("fd: %d\n", fd);
close(fd);
return 0;
}
The output found isfd: 3
Turn off 0 or 2, then look at
#include <stdio.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
int main()
{
close(0);
//close(2);
int fd = open("myfile", O_RDONLY);
if(fd < 0){
perror("open");
return 1;
}
printf("fd: %d\n", fd);
close(fd);
return 0;
}
The finding is that the result is: fd: 0orfd 2
Allocation rules for file descriptors: In the files_struct array, find the smallest subscript that is not currently being used as a new file descriptor.
3. Redirect
3.0 What is Redirection
#include <stdio.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <stdlib.h>
int main()
{
close(1);
int fd = open("myfile", O_WRONLY|O_CREAT, 00644);
if(fd < 0){
perror("open");
return 1;
}
printf("fd: %d\n", fd);
close(fd);
return 0;
}
According to the allocation rules of file descriptors mentioned above, we will explain this code in order:
First close the stdout (standard output: output to the display) corresponding to the file descriptor 1, and then allocate it through f, the fd of this file will scan from small to large and find that the position of 1 is not used, so the newly created file will be myfile is connected with the corresponding pointer:
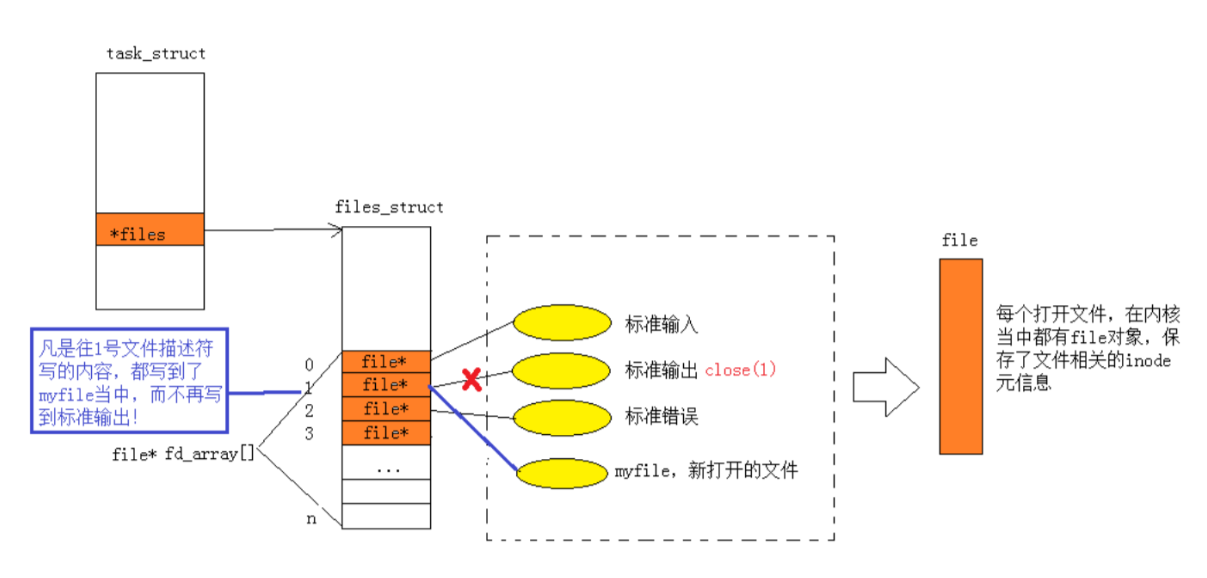
Therefore, when our printf prints to stdout, since the upper file descriptor stdout corresponds to 1, the corresponding file in array[1] will be found in the kernel for operation, but at this time 1 corresponds to no longer the standard output to The monitor, but the myfile file, so we will not see the value of fd on the monitor when printing, but in the myfile file.
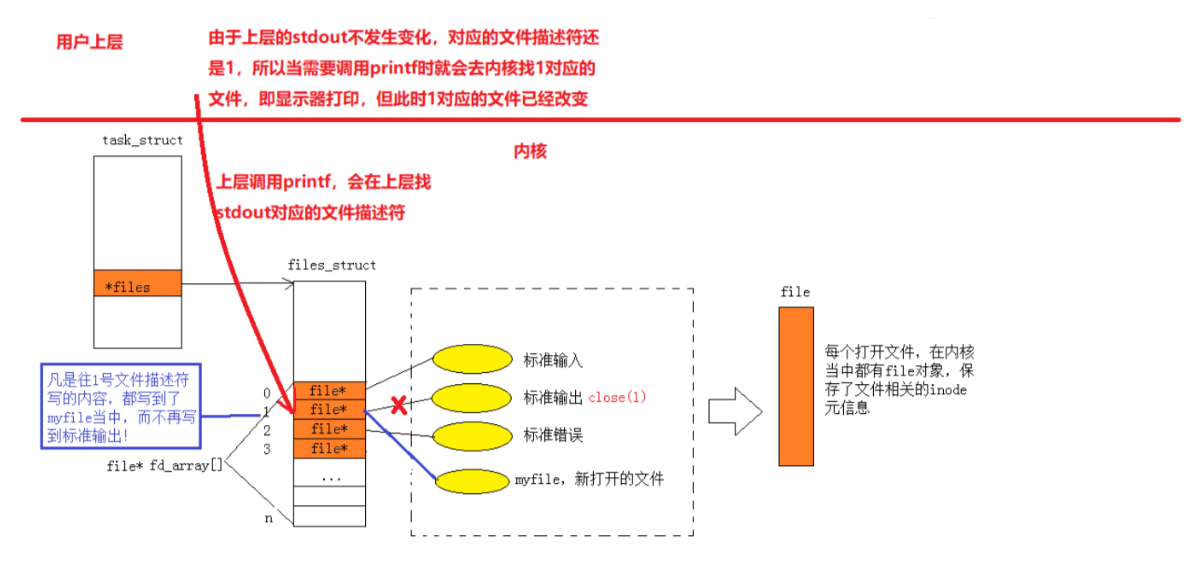
- The essence of redirection: In the case where the upper layer cannot perceive, within the OS, change the specific subscript in the descriptor table of the file corresponding to the process
3.1 3 types of redirection
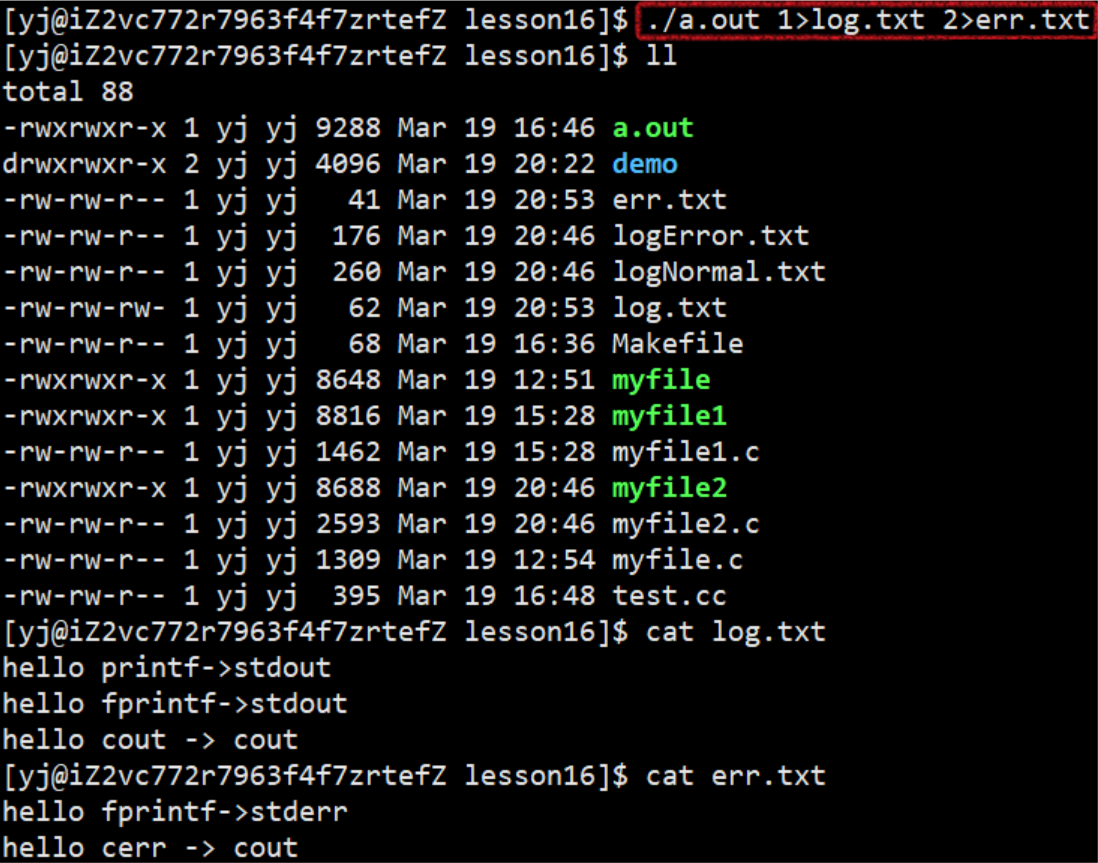
3.1.1 Output Redirection
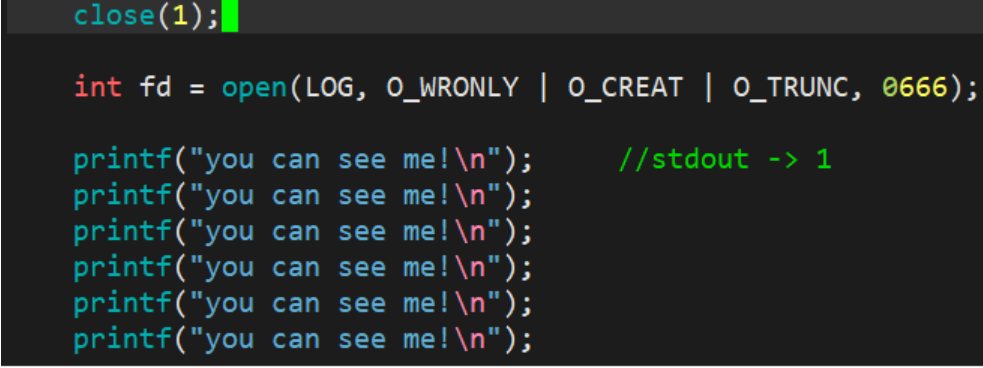
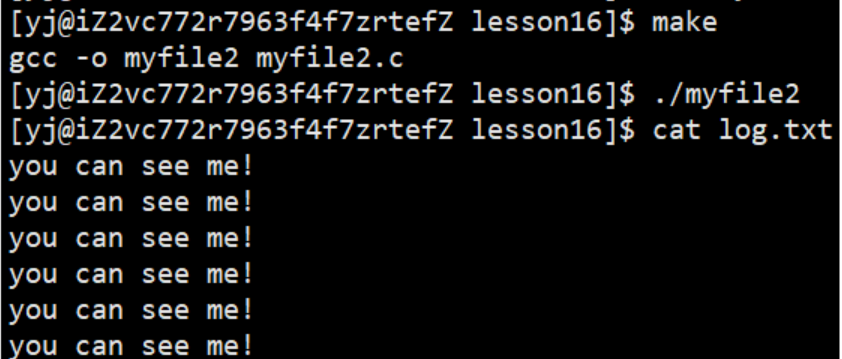
At this time, we found that the content that should have been output to the display is output to the file log.txt, where fd=1. This phenomenon is called output redirection.
3.1.2 Input redirection
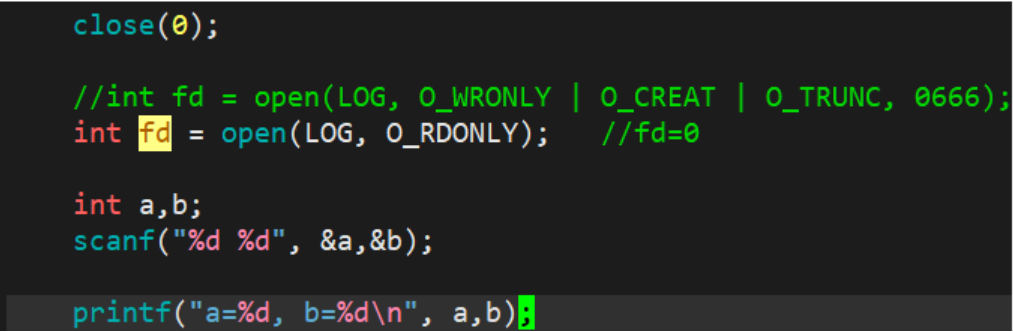
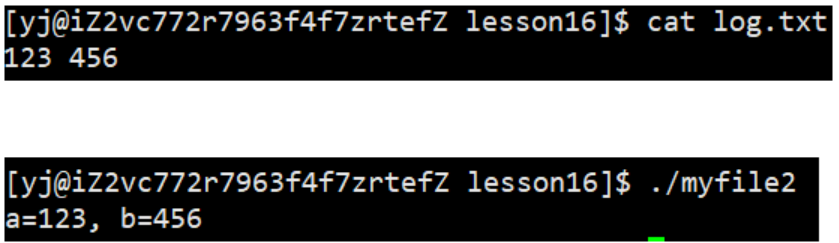
At this time, we found that the content should be input through the keyboard, and the content is directly read from the file log.txt, where fd=0. This phenomenon is called input redirection.
3.1.3 Append redirection
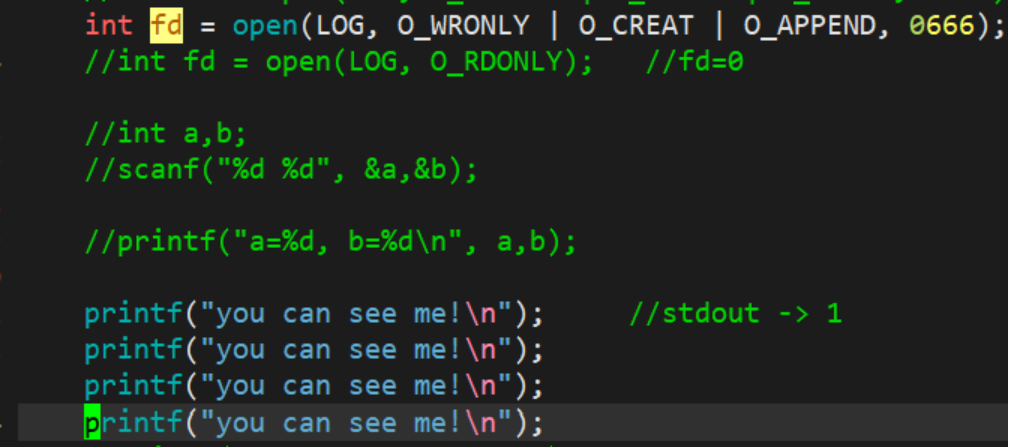
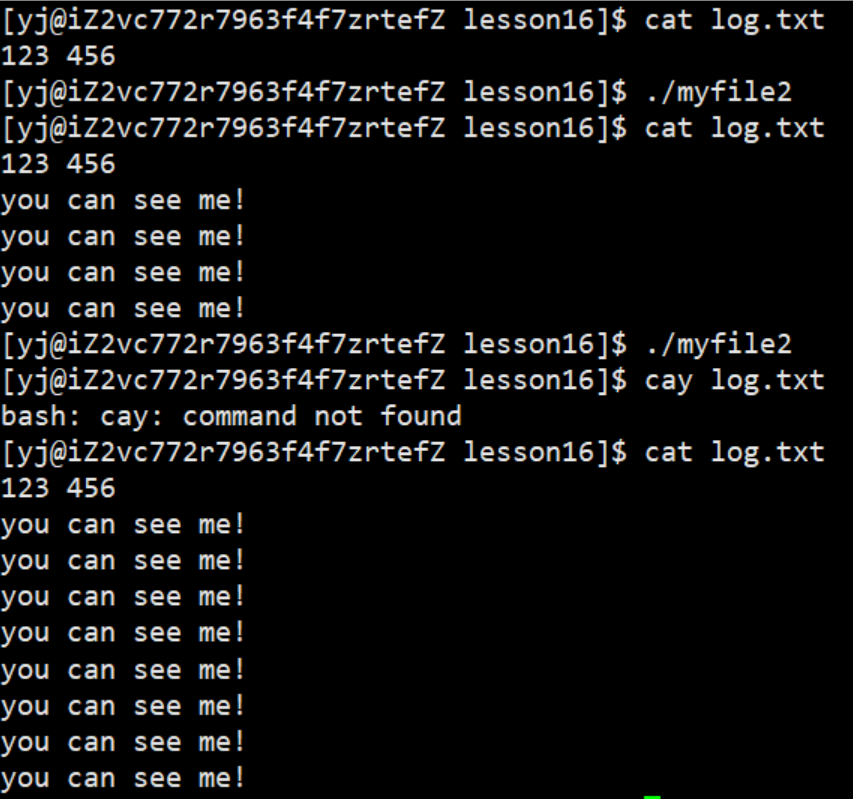
At this time, we found that the content that should have been appended to the display is appended to the file log.txt, where fd=1. This phenomenon is called append redirection.
3.1.4 Supplement
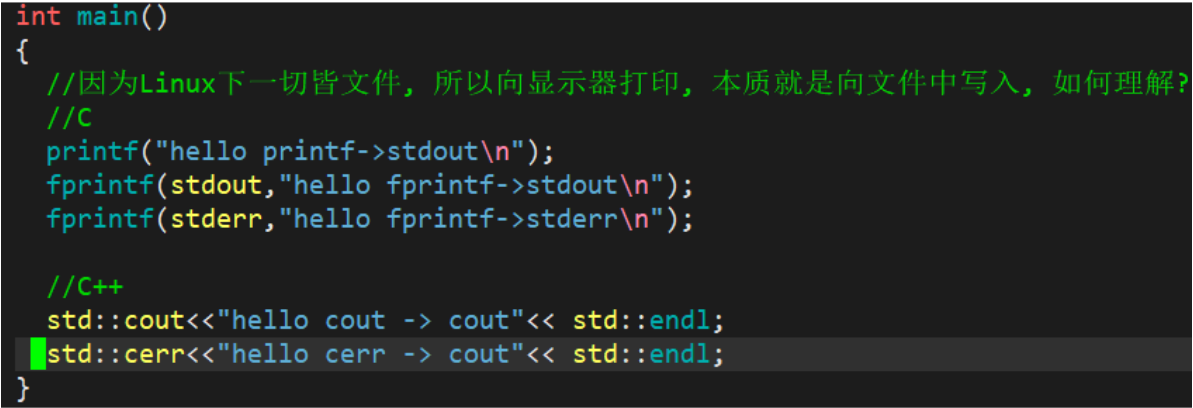
operation result:

Together print to the display:
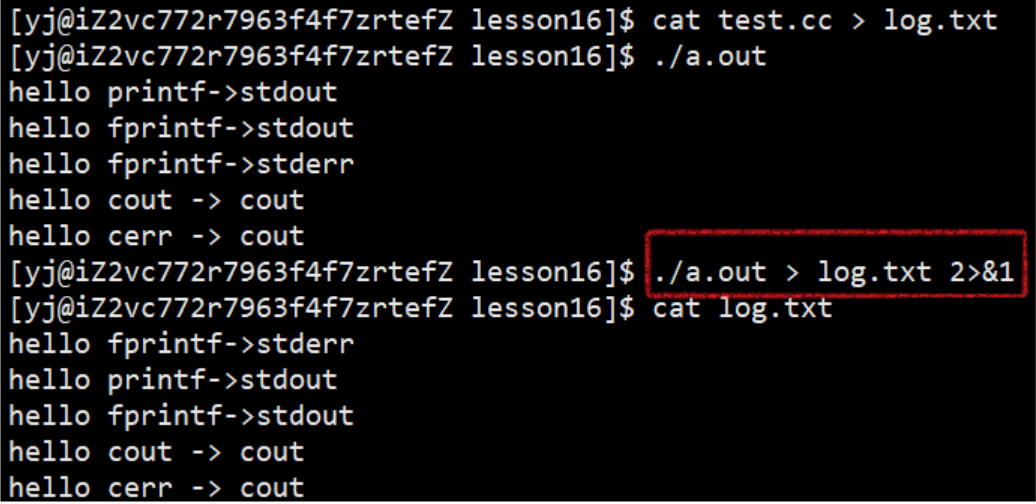
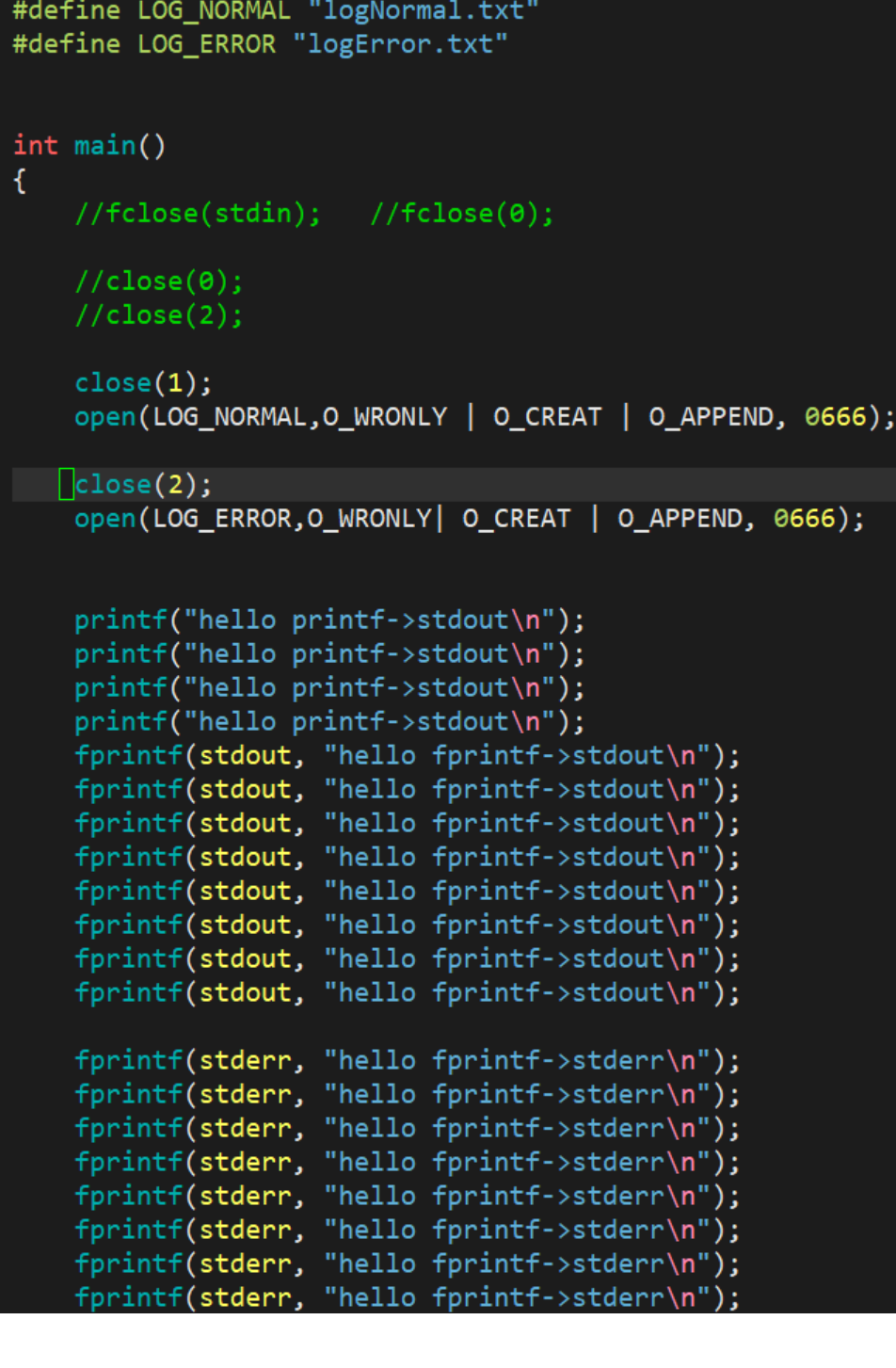
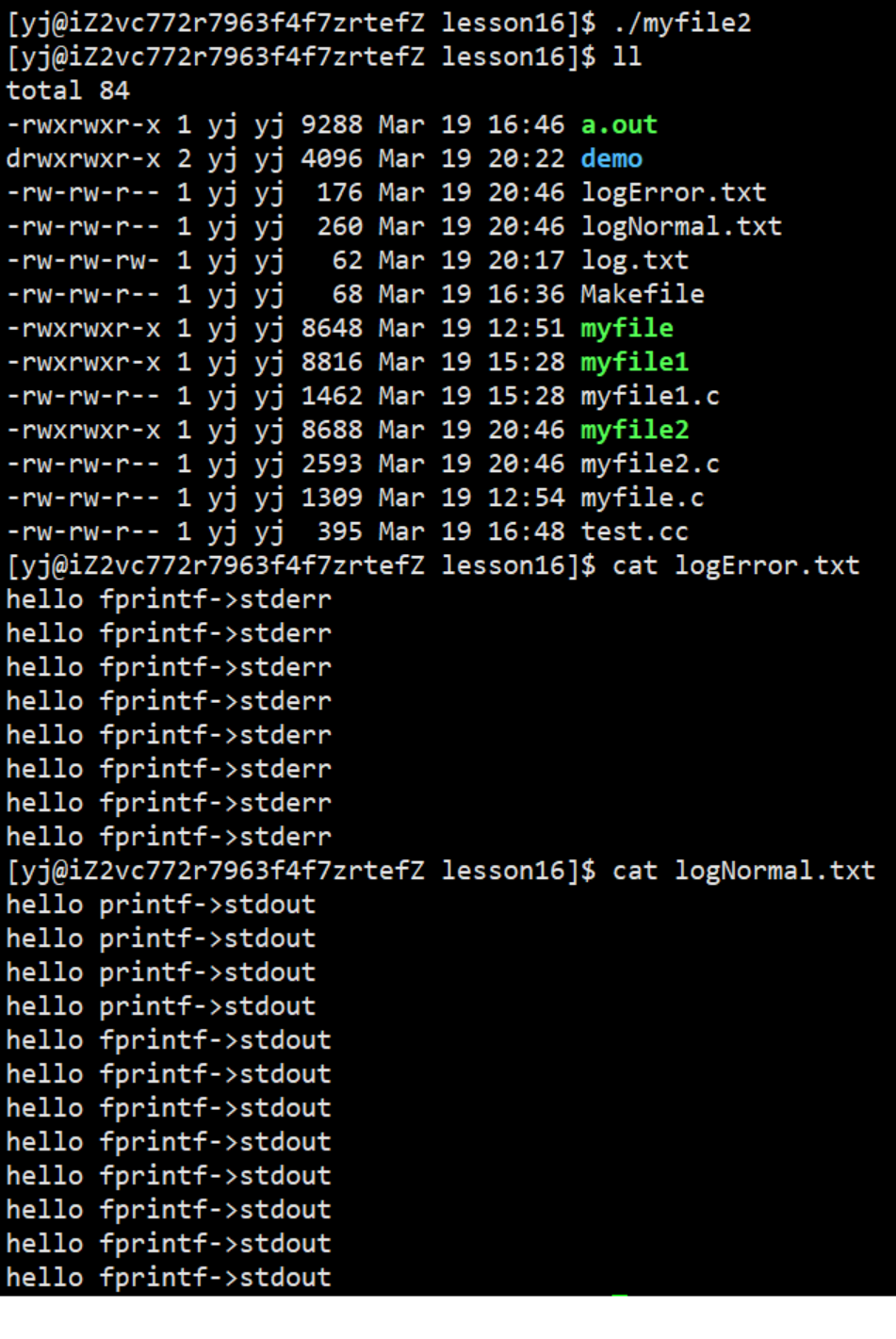
Normal messages are printed to log.normal, abnormal messages are printed to log.error
Solution:
- write the code:
- A few simple redirection instructions:
3.2 Redirection of dup2 system calls
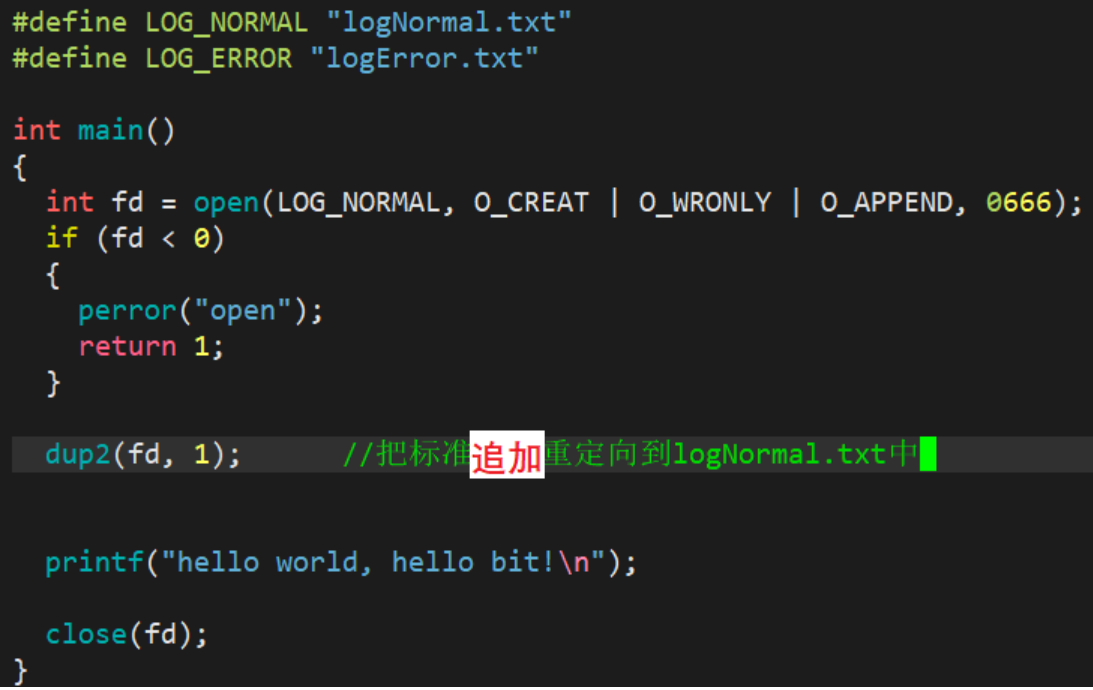
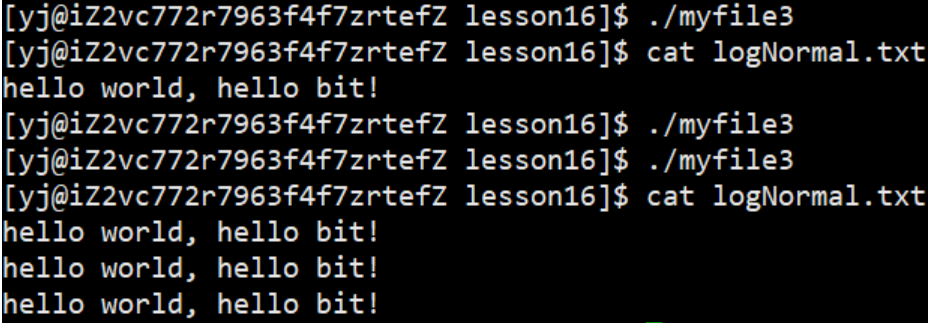
Whether it is allocation rules or redirection demonstrated above, it is very troublesome to directly close the operation, because such a close operation is not flexible enough, so now we introduce a system call redirection interface:dup2
int dup2(int oldfd, int newfd);//newfd的内容最终会被oldfd指向的内容覆盖
Demo:
4. How to understand that everything is a file under Linux
5. Buffer
5.1 Knowledge introduction
5.1.1 Introducing phenomena
Use C language function and system call interface to print strings to the display
#include <stdio.h>
#include <unistd.h>
#include<string.h>
int main()
{
//C库
fprintf(stdout, "hello fprintf\n");
//系统调用
const char *msg = "hello write\n";
write(1, msg, strlen(msg)); //+1?
return 0;
}
result:

After adding fork on the basis of this code
#include <stdio.h>
#include <unistd.h>
#include<string.h>
int main()
{
//C库
fprintf(stdout, "hello fprintf\n");
//系统调用
const char *msg = "hello write\n";
write(1, msg, strlen(msg)); //+1?
//代码结束之前,进行创建子进程
fork();
return 0;
}
result:
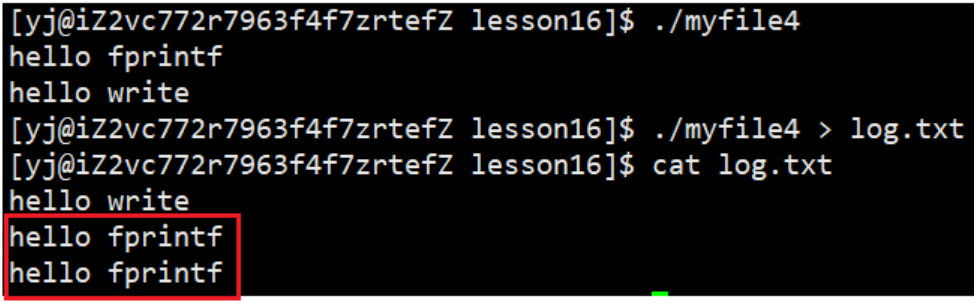
It is still a normal phenomenon to run directly, but when redirected to log.txt, the C interface is printed twice, why does this phenomenon occur?
5.1.2 Understanding buffers
5.1.2.1 Why there is a buffer
As an example:
A and B are friends with each other. One day, A in Xi'an wants to send something to B in Beijing. He can choose to ride a bicycle from Xi'an to Beijing to deliver the item to B. It is theoretically possible, but it will take a lot of time for A; So he chooses to give the things to the courier company, and asks the courier company to help him send the things, and B receives them soon.

In real life, the meaning of the express delivery industry is to save the sender’s time. For this example, Xi’an is equivalent to the memory, sender A is equivalent to the process, the package is the data that the process needs to send, Beijing is equivalent to the disk, and B It is a file on the disk, so it can be seen as follows:

In the von Neumann system, we know that the speed of direct memory access to disk and other peripherals is relatively slow, that is, just like the example we gave, A will take a lot of time to deliver the package in person, so SF Express also belongs to the memory Copy the existing data in the memory to this space, and the copy function will return directly, that is, A will leave after receiving the notification from SF Express. During the execution of your code, the data in the corresponding memory space of SF Express, that is, the package, will be continuously sent to the other party, that is, to the disk. In this process, the space opened up by SF Express is equivalent to a buffer zone.
So what is the point of the buffer? - Save the caller's time . System calls also take time
5.1.2.2 Buffer flush strategy
- No buffering, instant refresh
- row buffering, row flushing
- Full buffering, refresh when the buffer is full
(1) The display uses a refresh strategy: line buffering
(2) Ordinary files adopt refresh strategy: full buffer
5.1.2.3 Where is the buffer
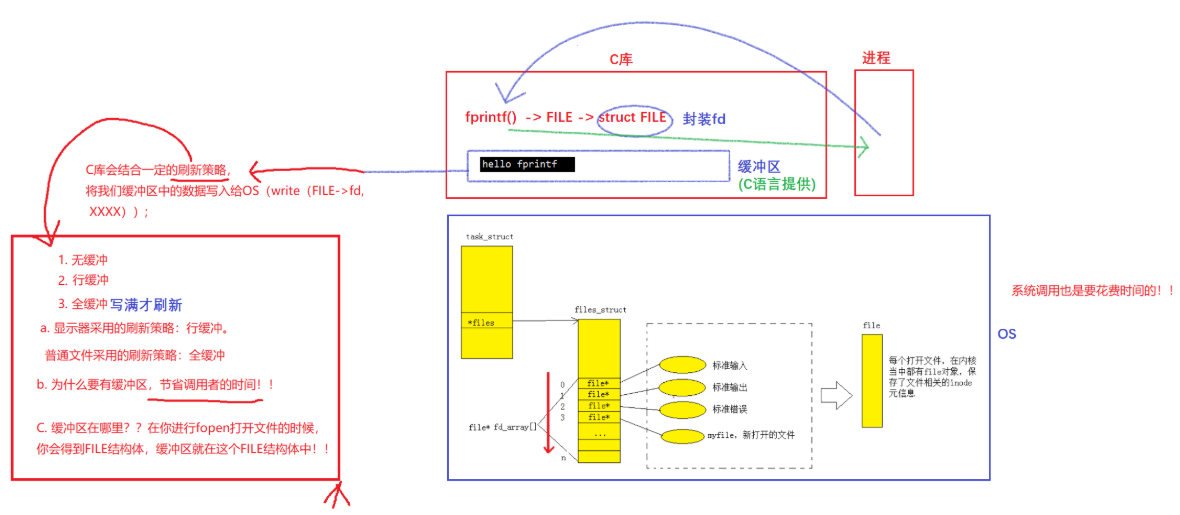
When you open the file with fopen, you will get the FILE structure, and the buffer is in this FILE structure
5.1.3 Explain why it is printed twice
-
write is a system call, there is no buffer, and the direct call is written to the operating system, so in both cases it will only be printed once
-
When printing to the display, the refresh scheme is line buffering, the string has been flushed from the buffer before fork, and fork does nothing
-
When redirecting to a file, fprintf writes data into the buffer, and the refresh scheme changes from line buffering to full buffering. There is no way to fill the buffer with a single string, and the string to be written by fprintf before fork is still in the buffer and there is no After being refreshed, a child process is created after fork, and stdout belongs to the parent process. When a child process is created, the process exits immediately! No matter who exits first, the buffer must be refreshed (that is, the buffer is modified). Once modified, due to the independence of the process, copy-on-write will occur, so the data will eventually be printed in two copies.
5.2 Self-encapsulated FILE
The following is a demo version, focusing on the presentation principle
Let me explain in advance: when we close the file, fclose(FILE*), C language will help us flush the buffer
mystdio.h
#pragma once
#include<stdio.h>
#include<string.h>
#include<sys/types.h>
#include<sys/stat.h>
#include<malloc.h>
#include<fcntl.h>
#include<unistd.h>
#include<assert.h>
#define NUM 1024
#define BUFF_NONE 0x1 //无缓冲
#define BUFF_LINE 0x2 //行缓冲
#define BUFF_ALL 0x4 //全缓冲
typedef struct _MY_FILE
{
int fd;
char outputffer[NUM]; //输出缓冲区
int flags; //刷新方式
int current; //outputbuffer下一次要写入的位置
}MY_FILE;
MY_FILE *my_fopen(const char *path, const char *mode);
size_t my_fwrite(const void *ptr, size_t size, size_t nmemb, MY_FILE *stream);
int my_fclose(MY_FILE *fp);
int my_fflush(MY_FILE *fp);
mystdio.c
#include "mystdio.h"
// fopen("/a/b/c.txt", "a");
// fopen("/a/b/c.txt", "r");
// fopen("/a/b/c.txt", "w");
MY_FILE *my_fopen(const char *path, const char *mode)
{
//1. 识别标志位 --- 判断文件打开方式
int flag=0;
if(strcmp(mode, "r")==0) flag |= O_RDONLY;
else if(strcmp(mode, "w")==0) flag |= (O_CREAT | O_WRONLY | O_TRUNC);
else if(strcmp(mode, "a")==0) flag |= (O_CREAT | O_WRONLY | O_APPEND);
else{
//其他的一些打开方式
}
//2. 尝试打开文件
mode_t m = 0666; //设置创建文件的默认权限
int fd=0;
if(flag & O_CREAT) fd = open(path, flag, m);
else fd = open(path, flag);
if(fd<0) return NULL;
//3. 给用户返回MY_FILE对象, 需要先进行构建
MY_FILE* mf = (MY_FILE*)malloc(sizeof(MY_FILE));
if(mf == NULL) //打开文件失败
{
close(fd);
return NULL;
}
//4. 初始化MY_FILE对象
mf->fd=fd;
mf->flags=BUFF_LINE; //默认刷新方式: 行刷新
memset(mf->outputffer, '\0', sizeof(mf->outputffer));
//或: my->outputbuffer[0]=0; //初始化缓冲区
mf->current=0; //开始时, 缓冲区中数据为0
//5. 返回打开的文件
return mf;
}
// 我们今天返回的就是一次实际写入的字节数,我就不返回个数了
size_t my_fwrite(const void *ptr, size_t size, size_t nmemb, MY_FILE *stream)
{
//1. 缓冲区如果已经满了,就直接刷新
if(stream->current == NUM) my_fflush(stream);
//2. 根据缓冲区剩余情况, 进行数据拷贝即可
size_t user_size = size*nmemb; //用户想写的字节
size_t my_size=NUM - stream->current; //我还剩余的字节
size_t writen = 0; //实际所写字节数
if(my_size >= user_size) //足以容纳用户想写的数据
{
memcpy(stream->outputffer+stream->current, ptr, user_size);
//3. 更新计数器字段
stream->current+=user_size;
writen=user_size;
}
else //空间不够
{
memcpy(stream->outputffer+stream->current, ptr, my_size);
//3. 更新计数器字段
stream->current+=my_size;
writen = my_size;
}
//4. 开始计划刷新, 他们高效体现在哪里 --- TODO
//不发生刷新的本质, 不进行写入, 就是不进行IO, 不进行系统调用, 所以my_write函数调用会非常快, 数据会暂时保存在缓冲区中
// 可以在缓冲区中挤压多份数据, 统一进行刷新写入, 本质: 就是一次IO可以IO更多的数据, 提高IO效率
if(stream ->flags & BUFF_ALL)
{
if(stream->current ==NUM) my_fflush(stream);
}
else if(stream ->flags & BUFF_LINE)
{
if(stream->outputffer[stream->current-1] =='\n') my_fflush(stream);
}
else
{
//TODO
}
return writen;
}
int my_fflush(MY_FILE *fp)
{
assert(fp);
write(fp->fd, fp->outputffer, fp->current);
fp->current=0;
fsync(fp->fd); //强制刷新
return 0;
}
int my_fclose(MY_FILE *fp)
{
assert(fp);
//1. 冲刷缓冲区
if(fp->current > 0) my_fflush(fp);
//2. 关闭文件
close(fp->fd); //关闭文件描述符
//3. 释放堆空间
free(fp);
//4. 指针置为NULL --- 可以设置
fp=NULL;
return 0;
}
main.c
#include "mystdio.h"
#define MYFILE "log.txt"
int main()
{
MY_FILE *fp = my_fopen(MYFILE, "w");
if(fp == NULL) return 1;
const char*str="hello my fwrite";
int cnt=5;
//操作文件
while(cnt)
{
char buffer[1024];
snprintf(buffer, sizeof(buffer), "%s: %d\n", str, cnt--);
size_t size = my_fwrite(buffer,strlen(buffer), 1,fp);
sleep(1);
printf("当前成功写入: %lu个字节\n", size);
}
my_fclose(fp);
return 0;
}
5.3 The relationship between buffer and OS
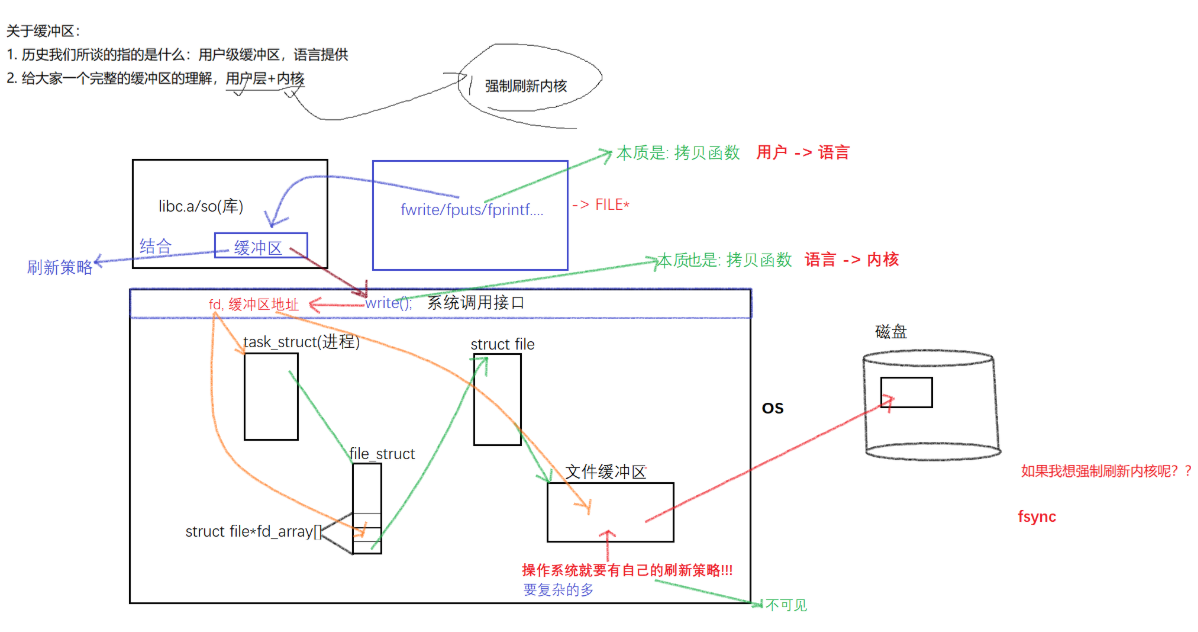
The character strings we write to the disk are written according to row refresh, but they are not directly written to the disk, but first written to the buffer corresponding to the file in the operating system. The file structure, in addition to some interfaces, also has a kernel buffer, and our data corresponds to the file descriptor through the file structure, and then written into the kernel buffer, and finally refreshed to the disk by the operating system, and refresh This process is determined by the operating system independently, rather than some line buffering, full buffering, and no buffering we just discussed, because the buffers we mentioned are based on the FILE structure of the application layer C language. Refresh strategy, and the self-refresh strategy of the operating system is much more complicated than the strategy we mentioned, because the operating system needs to consider its own storage situation, so the process of writing data from the operating system to the peripheral has nothing to do with the user.
Therefore, it takes such a long cycle for a piece of data to be written to the hardware (peripherals): first, the data written by the user enters the buffer corresponding to FILE, which is at the user language level, and then through the refresh strategy we mentioned Refresh to the kernel buffer in the operating system guided by the file descriptor of the struct file* in the operating system, and finally write to the peripheral device through the refresh strategy independently determined by the operating system. If the OS is down, the data may be lost, so if we want to refresh the data to the peripheral in time, we need some other interfaces to force the OS to refresh to the peripheral, that is, a new interface: , call int fsync(int fd)this After the function, the data in the kernel buffer is forced to be flushed to the peripheral
5.4 Summary
Therefore, there are two types of buffers we mentioned above: user buffers and kernel buffers. User buffers are language-level buffers. For C language, user buffers are in the FILE structure. Other languages It is also similar; while the kernel buffer belongs to the operating system level, its refresh strategy is refreshed according to the actual situation of the OS, and has nothing to do with the user level.
6. Disk files
In the first half of the study, all we study are opened files. What if there is no opened file? If a file is not opened, how is it managed by the OS? (The second half of the article mainly talks about disk files)
- Files that have not been opened can only be stored quietly in peripheral devices such as disks
There are a large number of files on the disk, and most of them are not opened. These files also need to be statically managed so that we can find and open them at any time. How is the disk managed?
6.1 Disk structure
The disk is the only mechanical structure in our computer. To understand how the operating system manages unopened files on the disk, we first need to understand the physical structure, storage structure, and logical structure of the disk device, and then understand the operating system's management method for the disk on this basis.
6.1.1 The physical structure of the disk
Generally speaking, the hard disk structure includes: disk, magnetic head, disk spindle, control motor, head controller, data converter, interface, cache, etc.

Platters: Disks are stacked, which means that a disk has many platters.
Surface: A platter has two surfaces.
Heads: There is one head on each side. That is to say, if the disk has five pieces, then there are ten sides, and there are also ten heads. There is no contact between the magnetic head and the disk surface, and it is suspended on the disk surface . Once the disk surface rotates at a high speed, the magnetic head will float, so the disk must be prevented from shaking, otherwise the magnetic head will swing up and down, scratching the disk surface, resulting in binary data on the disk. lost.
Motor: After the disk is powered on, the motor will make the disk rotate counterclockwise at a high speed, and the magnetic head will swing back and forth at this time. Therefore, the motor device can control the swing of the magnetic head and the rotation of the platter.

It can be found that the disk also has its own hardware circuit. The hardware circuit has hardware logic, which can be called the servo system of the disk itself , that is, the servo system can be composed of hardware circuits, so as to send binary instructions to the disk, so that the disk can be positioned or addressed. A specific area to read the corresponding data on the disk.
extension:
The laptop is not loaded with a mechanical disk, but an SSD. The disk is the only mechanical device in our computer. Compared with other devices, since the disk is a hardware structure + peripherals, the hard disk access is relatively slow (only relative), so the operating system needs to handle a lot of work. Although disks are rarely seen at present, disks are still the mainstream on the enterprise side. Because SSDs are too expensive and have read and write restrictions, they are easy to be broken down. Even if the access speed far exceeds that of disks, they cannot completely replace disks.
Note: The disk is highly airtight and can be disassembled, but it will be scrapped once it is disassembled under normal external conditions
6.1.2 Disk storage structure
Understand the disk storage structure Try to understand the data read and write once on the hardware
platter
A disk is made up of multiple platters (disc 0 in the figure below).
The surface of the platter is coated with magnetic substances, which are used to record binary data. Because the front and back sides can be coated with magnetic substances, a disc may have two disc surfaces.

track, sector
Each platter is divided into tracks, and each track is divided into sectors. As shown below:

cylinder
Each disk surface corresponds to a magnetic head. All magnetic heads are connected to the same magnetic arm, so all magnetic heads can only "advance and retreat together". Tracks with the same relative position on all disks form a cylinder. As shown below
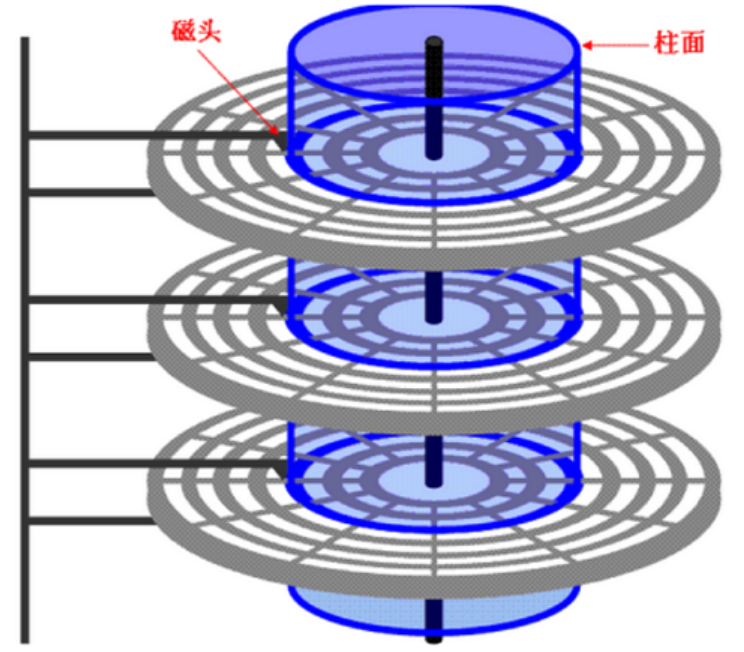
From the above, ** can use (cylinder number, disk number, sector number) to locate any "disk block". ** Namely: CHS positioning method .
6.1.3 Logical structure of the disk
premise:
The above content mainly explains that if the OS can know any CHS address, it can access any sector.
So is the CHS address directly used inside the OS? No
Why not use the CHS positioning method to locate the address inside the OS?
- The OS is software, and the disk is hardware. The hardware locates an address, CHS, but if the OS directly uses this address, what if the hardware changes? Does the OS have to change accordingly? The OS needs to be decoupled from the hardware
- Even for a sector, 512 bytes, the basic data volume per IO is very small. Hardware: 512 bytes, the OS actually performs IO, and the basic unit is 4KB (adjustable) — disk: block device. Therefore, the OS needs to have a new set of addresses for block-level access
The tape in the figure below is an analogy to a disk. After the tape case is disassembled and the tape is pulled out, its structure is linear, that is to say, the data in the tape is read in a linear manner.

Expand the surface of the disk in a linear fashion:
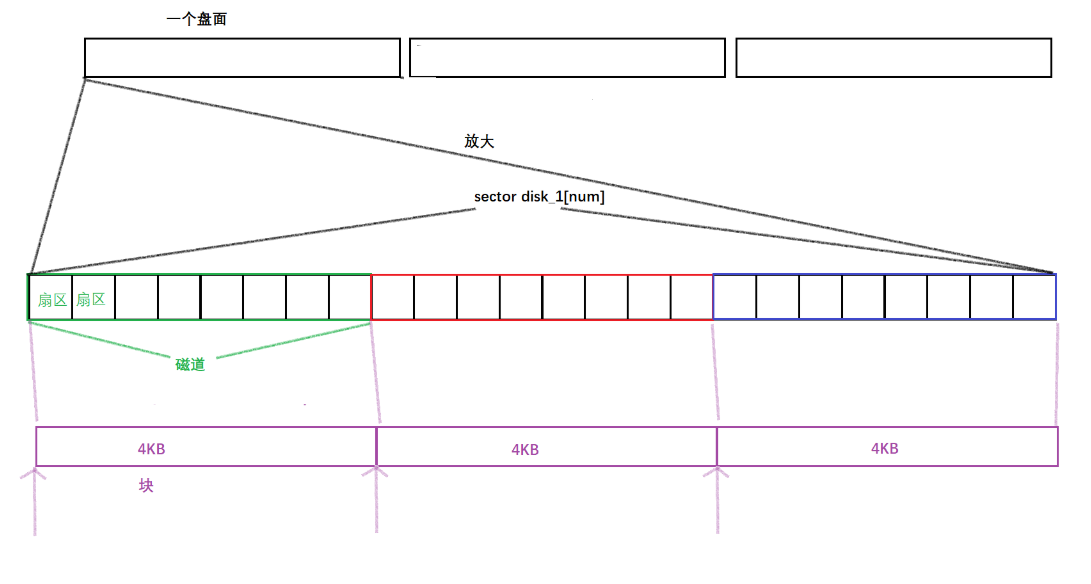
A track can be regarded as an array. At this time, when locating a sector, you only need to use the array subscript to complete the positioning.
The OS performs IO in units of 4KB, so an OS-level file block should include 8 sectors
Conventional computer access method: starting address + offset, we can also regard the data block as a type, similarly only need to know the starting address of the data block (subscript address of the first sector) + 4KB (type of block) can be accessed
Therefore, the address of a block is essentially a subscript of the array. In the future, when we represent a block, we can use linear subscripts to locate a block.
At this time, if you want to find the specified sector, as long as you know the subscript of this sector, you can locate the specified sector on the disk. Inside the operating system, we call this address an LBA address (Logical Block Address), that is, a logical block address.
But our disk only recognizes CHS addresses, so we can realize the conversion between CHS addresses and LBA addresses in some way
like:
The formula of logical sector number LBA:
LBA (logical sector number) = number of heads × number of sectors per track × current cylinder number + number of sectors per track × current head number + current sector number – 1 For example: CHS
= 0/0/1, then according to the formula LBA=255 × 63 × 0 + 63 × 0 + 1 – 1= 0
6.2 Understanding the file system
6.2.1 Disk partition and grouping
For example, for a 500GB disk, the IO unit of the file system is obviously not large enough when the file system IO unit is 4KB. We divide it into each area, and it is not convenient to manage when each 100GB is a partition, so we need to group these 100GB into groups of 5GB to manage
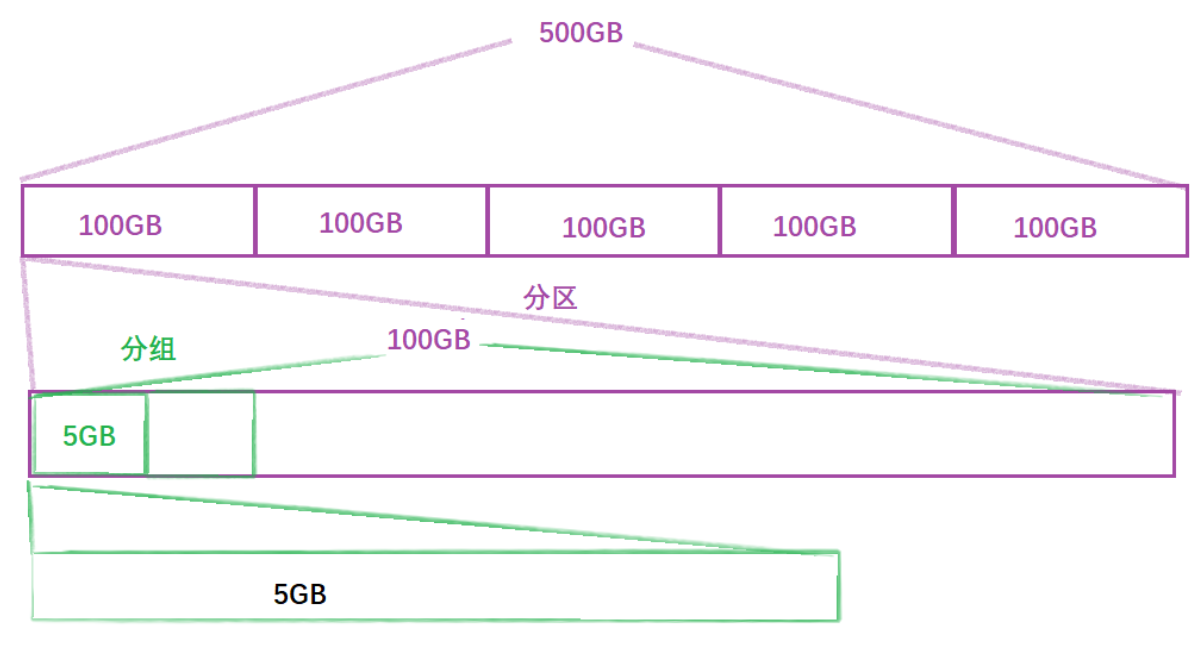
After the group is divided, if one group can be managed well, then other groups only need to copy the management method of this group to manage this partition in the same way; and then copy the management mode of one partition to other partitions to manage Well the whole disk is gone . Using the idea of divide and conquer, as long as the 5GB disk space is managed well, the entire disk space can be managed well. In the above way, the part that needs to be managed after grouping becomes the following structure:
-
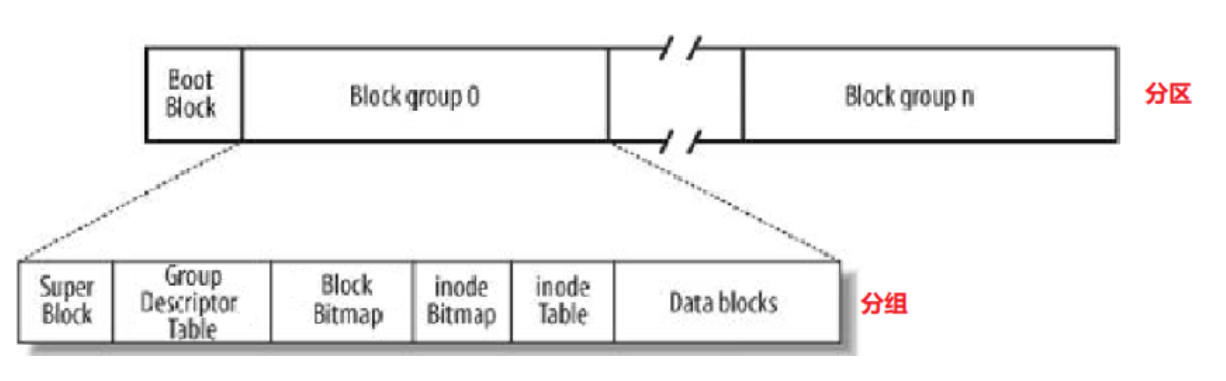
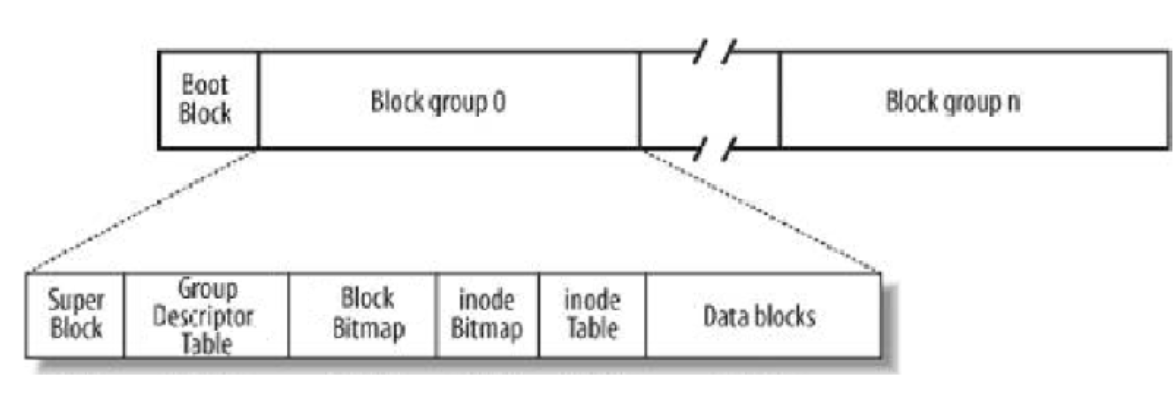
Block Group: The ext2 file system will be divided into several Block Groups according to the size of the partition. And each Block Group has the same structure. Examples of government-managed districts
-
The first part of the data in each partition is the Boot Block, followed by each group, which is related to the computer booting, we don't need to care about it.
6.2.2 Group management method
-
Super Block (Super Block) : store the structural information of the file system itself. The recorded information mainly includes: the total amount of bolck and inode, the number of unused blocks and inodes, the size of a block and inode, the time of the latest mount, the time of the latest data writing, and the time of the last inspection of the disk and other related information of the file system. The information of the Super Block is destroyed, it can be said that the entire file system structure is destroyed . The Super Block is not placed in the partition like the Boot Block, but each group has one for backup. Once other Super Blocks are abnormal, other normal Super Blocks will be copied over.
-
GDT , Group Descriptor Table: block group descriptor, describing block group attribute information
-
Inode
file = content + attribute, the content and attribute of the file in the Linux operating system are separated , and the inode is used to store the file attribute. The inode is a fixed size, one inode per file. Inside the group, there may be multiple inodes, and the inodes need to be distinguished. Each inode has its own inode number, so the inode number also belongs to the attribute id of the corresponding file -
In a partition, there will be a large number of files in the inode table, and there will be a large number of inode nodes. A group needs to have an area to store the inode nodes of all files in the group. This area is the inode table . -
Data blocks
, the content of a file changes, we use data blocks to save the file content, so a valid file needs [1,n] data blocks to save the content, then if there are multiple files, more data blocks are needed — Data blocks -
inode Bitmap
The bitmap structure corresponding to the inode. Each bit indicates whether an inode is free and available -
Each bit of Block Bitmap indicates whether the data block is free and available
6.2.3 In-depth understanding of inodes
(1) inode vs. filename
The Linux system only recognizes the inode number, and the file name does not exist in the inode attribute of the file . The filename is for the user
(2) Re-understand the catalog
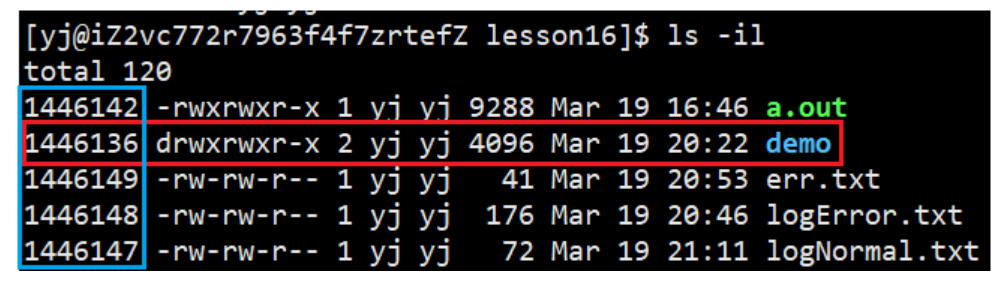
Are directories files? Yes; do directories have inode numbers? Yes. ls - ilYou can view the inode of the file by
Does the catalog have content? Yes, what is the content?
Any file must be inside a directory, so a directory needs a data block to have content. The data block of the directory stores the mapping relationship between the file name and the file inode number in the directory, and in the directory, the file name and inode are mutually is the key value
(3) Basic process of accessing files
When we access a file, we access it in a specific directory. For example, the basic process of cat log.txt (print file content):
- First, in the current directory, find the inode number of log.txt
- A directory is also a file, and it must belong to a partition. Combined with inode, find the group in the partition, and find the inode of the file in the inode Table in the group
- Through the mapping relationship between the inode and the corresponding data block, find the data block of the file, load it into the OS and complete the display on the display
6.2.4 How to understand the addition, deletion and modification of files
Delete Files
- First construct the mapping relationship between data block and inode according to the file name, and find the inode number of this file
- According to the mapping relationship between the inode number and the inode attribute, set the bit position corresponding to the block bitmap to 0
- Set the bit corresponding to the inode bitmap to 0 according to the inode number
So deleting a file only needs to modify the bitmap
Create a file
Find the bit number of 0 in the inode bitmap, set it to 1, and then fill in all the attributes of the file in the space of the subscript corresponding to the number in the inode table; then find one or more bit numbers of 0 in the block bitmap, Set it to 1, and then fill in all the contents of the file into the subscript space corresponding to the number of data blocks; finally modify the super block, and at the same time, need to write the mapping relationship between the file name and inode of the new file into the data block of the directory .
6.2.5 Additional details
- What should I do if a file is deleted by mistake?
Theoretically speaking, 1. Know the inode number of the deleted file, first take the inode number and set the bit corresponding to the inode bitmap from 0 to 1 in the group of the specific deleted file, then the file will not be overwritten ;2. Then read the inode table according to the inode, extract the data block occupied by the current file from the inode table, and set the bitmap corresponding to the data block to 1 again. At this point, the attributes and corresponding contents of the file are restored.
But the premise of all this is that the inode of the original file is not used by the new file – if the new file uses the inode of the original file, then the corresponding inode table and data in the data block will be overwritten, so the best practice after the file is accidentally deleted Just don't do anything, so as not to occupy the inode of the original file by creating a new file.
When it comes to actually recovering files, it is best to use the relevant tools for recovery.
-
The inode number is uniquely valid within a partition and cannot cross partitions (generally a partition is a file system); so the inode number can be used to determine the grouping
-
Who did the partitioning and grouping we learned, filling in the system properties? When did you do it?
It is done by the OS. After the partition is completed, in order to make the partition work normally, we need to format the partition. The process of formatting is actually the management attribute information of the file system written by the OS to the partition.
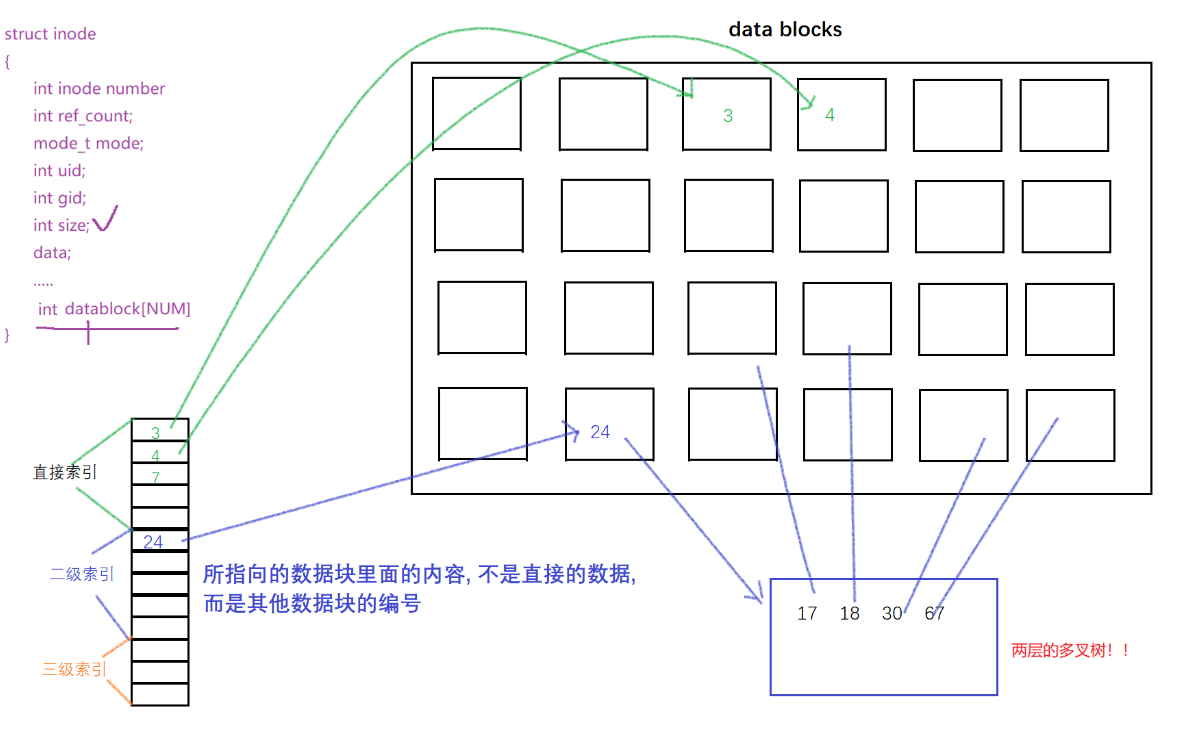
- If the inode only uses an array to establish a mapping relationship with the data block, assuming that a data block stores 4kb of data and has 15 arrays, does it mean that a file can contain at most 15*4=60kb of data? No
- Is it possible that for a packet, the data block is not used up, the inode is gone, or the inode is not used up, and the data block is used up? It is possible, but this situation will basically not happen
7. Soft and hard links
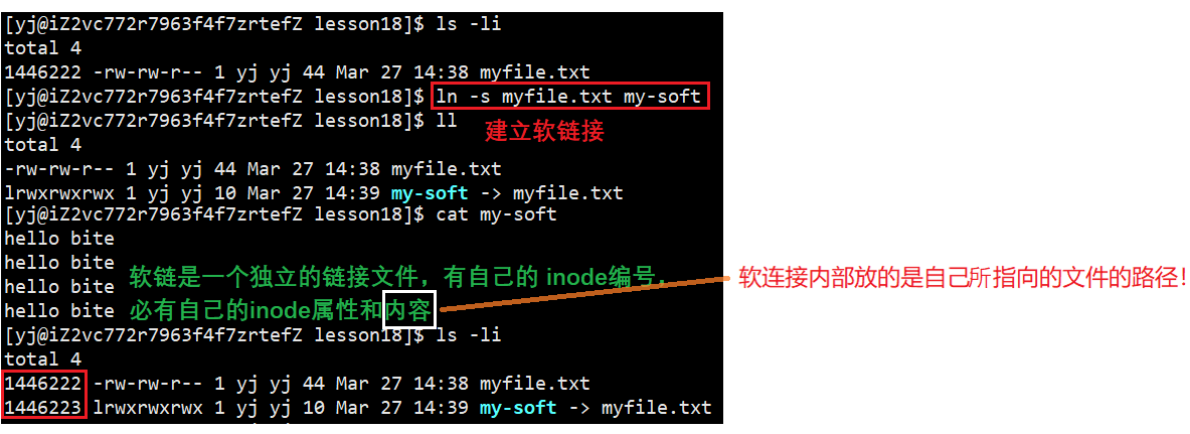
7.1 Soft link (symbolic link)
ls -n 文件名 所创建软链接名
use
The general way we want to run an executable program in a deep directory:

In fact, we can create a soft link to this program to make it run
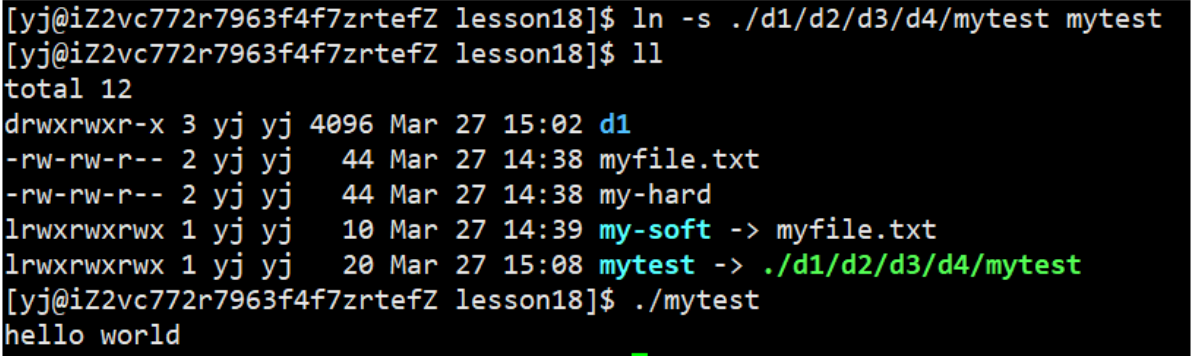
It can be seen that soft links are equivalent to Windows shortcuts
7.2 Hard links
ln 文件名 所创建硬链接名
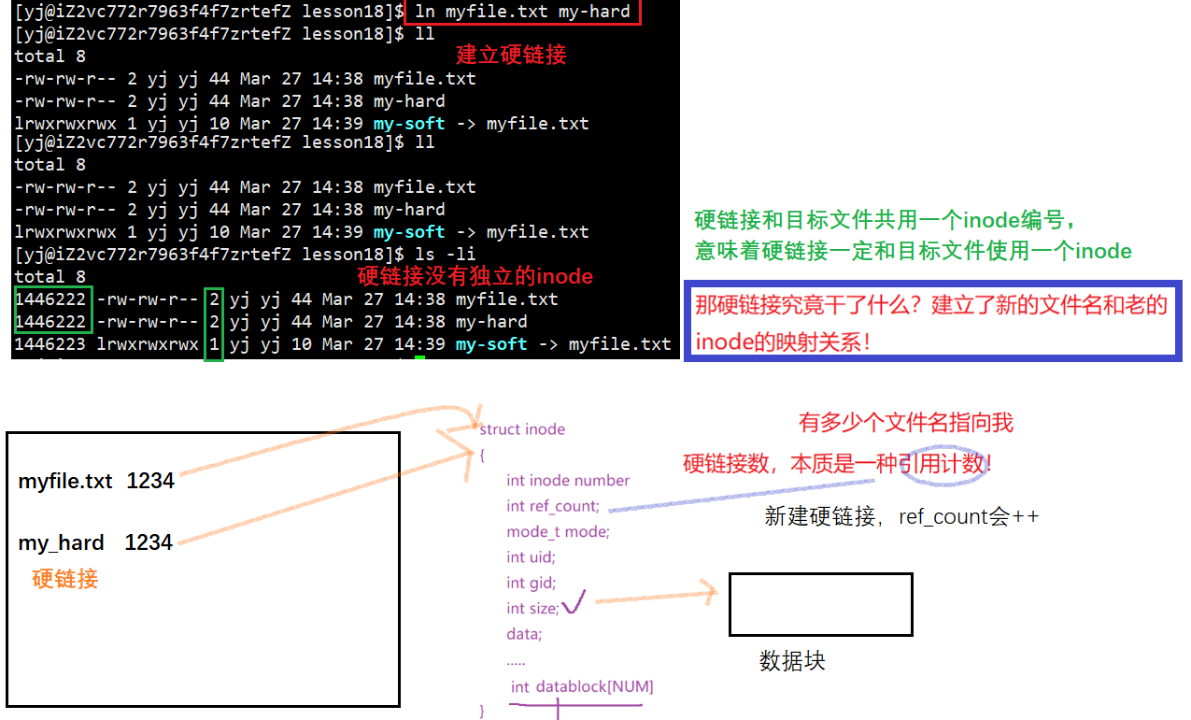
If myfile.txt is deleted, the content of the file can still be accessed through the hard link, because only one mapping relationship is removed, the counter is decremented by 1, and there is still a mapping relationship that can be accessed. Therefore, it can be seen that only when the hard link counter is 0, is a file truly deleted
Want to delete a hard link: You can delete it directly with rm or delete unlink 硬链接名it with
7.3 Understanding .
In the current path, we create a normal file and an empty directory

Observation found that the number of hard links between the two is different, the number of ordinary files is 1, and the number of directories is 2. In fact, it indirectly shows that there is still a file that is the same as the Inode of dir, forming a hard link. Enter the dir directory to observe:
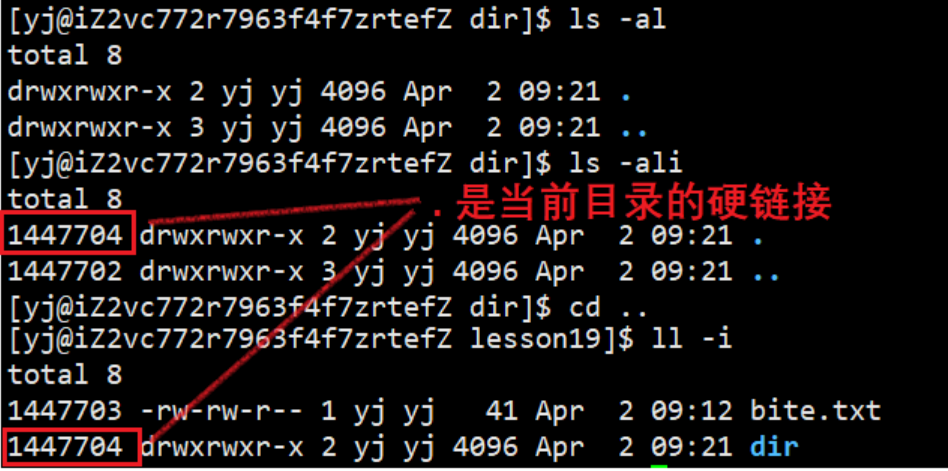
We found that the implicit . is actually a hard link of dir, and the . file is automatically generated, so the reason why the initial hard link of the directory is 2 is because of the hard link of .
So in a directory, .is a hard link to the current directory
7.4 Understanding...
We can verify that in the current directory, the inode number is viewed in the absolute path mode and the mode, and the two are exactly the same;
In the same way: absolute path and relative path... Check the inode numbers of the upper-level directory, and find that the two are exactly the same; there are 3 hard links under the upper-level directory lesson19, which are: lesson19 itself, . , . . .


This also further verifies that the file under linux is a multi-fork tree structure
So in the directory, ..it is a hard link to the parent directory
So can you actively create a hard link for the directory?

We found that this is not allowed, so why does Linux not allow ordinary users to hard link directories?
Easy to cause loop path problem
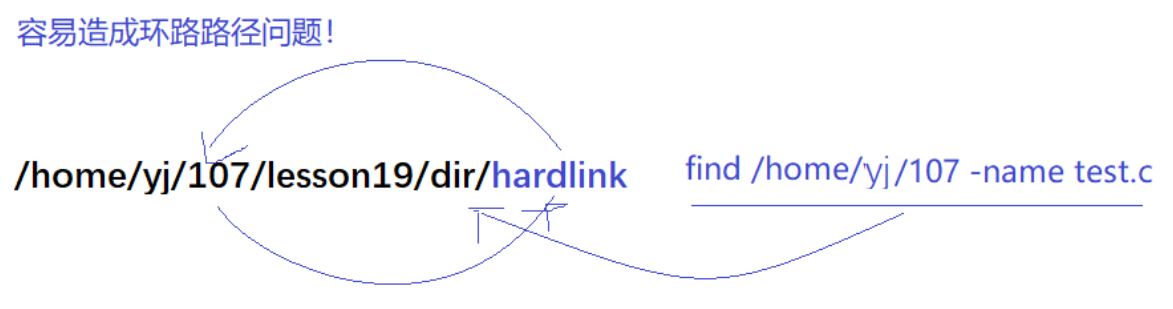
.The hard links to and ..are established by the OS itself.
7.5 Supplement
acm
explains the three times of the file below:
Access: Last access time
Modify: File content last modification time
Change: Attribute last modification time
8. Dynamic library and static library
8.1 Meet the library
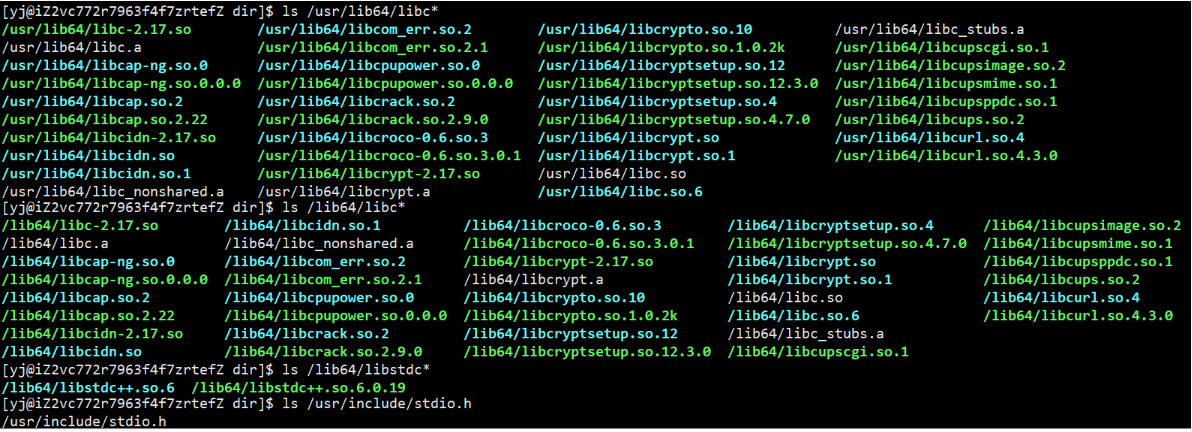
The above is the library under the linux system
Conclusion :
- The system has pre-installed C/C++ header files and library files. The header files provide method descriptions, and the library provides method implementations. There is a corresponding relationship between the header and the library, and they should be used together.
- The header file is introduced in the preprocessing stage, and the essence of the link is actually the link library
Understand the phenomenon :
- Therefore, we install the development environment under VS2022 - installing the compiler software is actually installing the libraries and files supporting the language to be developed.
- When we use the compiler, there will be an automatic syntax reminder function, which needs to include the header file first. The automatic reminder function depends on the header file.
- When we write code, how does our environment know where there are syntax errors in our code, and there are problems defining variables in those places? Don't underestimate the compiler, there are command line modes, and other automated modes to help us constantly check syntax
8.2 Why there is a library
Simply put, it is to improve development efficiency
8.3 Designing a library
8.3.1 Preliminary knowledge
Static library (.a) : The program links the code of the library into the executable file when compiling and linking. When the program is running, the static library
and dynamic library (.so) are no longer needed : the code of the dynamic library is only linked when the program is running, and multiple programs share the code of the library.
Library naming: The real name of the library is to remove the prefix lib, after removing the dot (or version number) encountered for the first time
For example these two libraries:libstdc++.so.6 libc-2.17.so
The real names are:stdc++ c
Generally, cloud servers only have dynamic libraries by default, and there are no static libraries. Static libraries need to be installed separately
When a dynamic library and a static library exist at the same time, the system uses dynamic linking by default
Compiler, when linking, if both a dynamic library and a static library are provided, the dynamic library is used first; when there is only a static library, only the static library can be used
8.3.2 Designing a static library
For example, you need to implement a simple addition and subtraction operation:
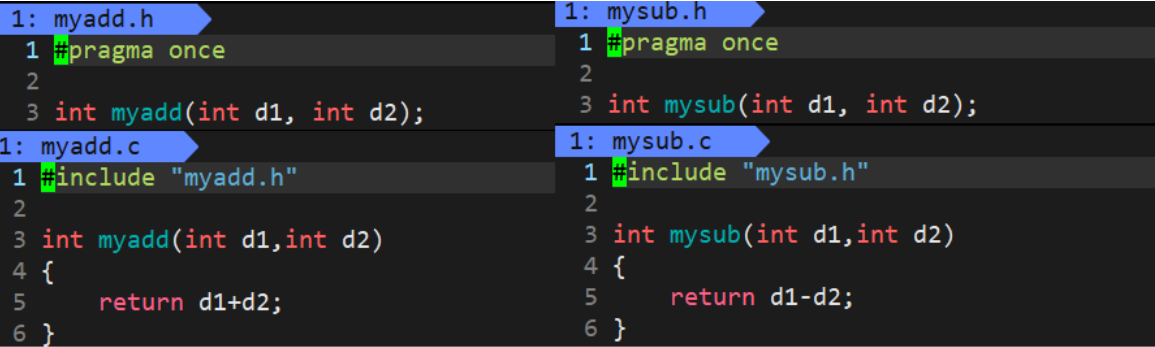
main.c implemented by otherPerson
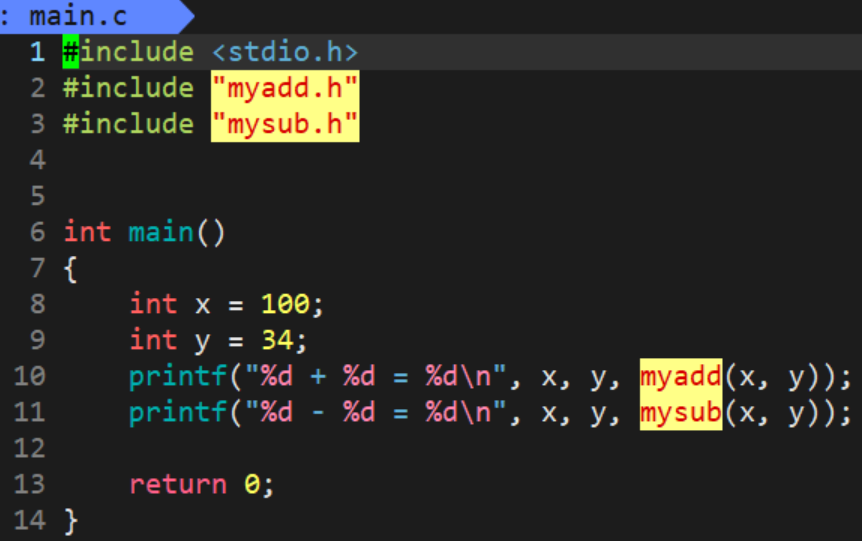
Now there is an otherPerson directory representing other users who need the implementation of addition and subtraction operations, but we don’t want to give him the source files directly, but give him the .o files generated by compiling the header files and .c files, and he writes A main.c file and compile the .c file to generate a .o file, and link these .o files to realize the operation
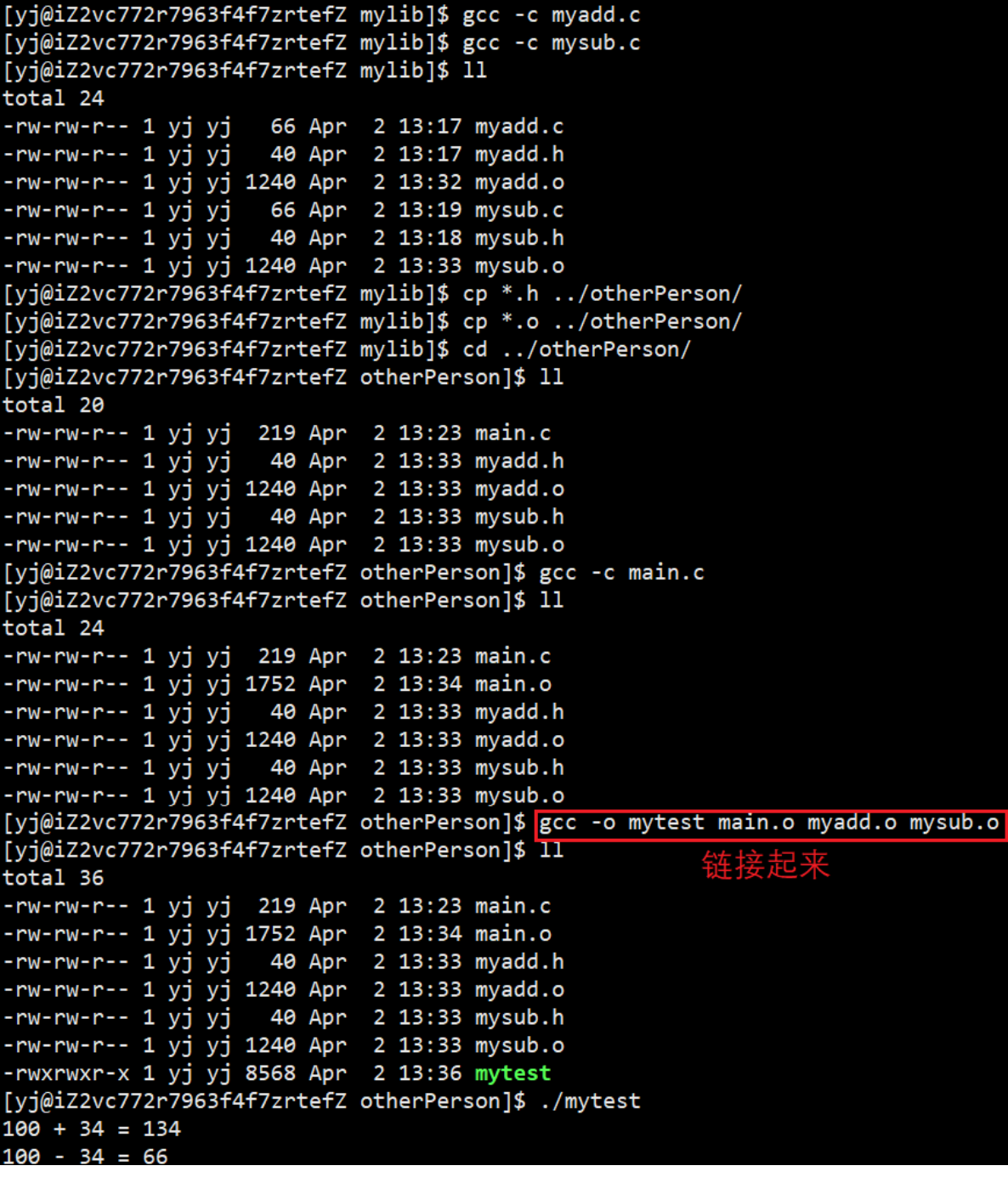
But this method of directly giving .o files to otherPerson is too troublesome, if there are too many .o files;
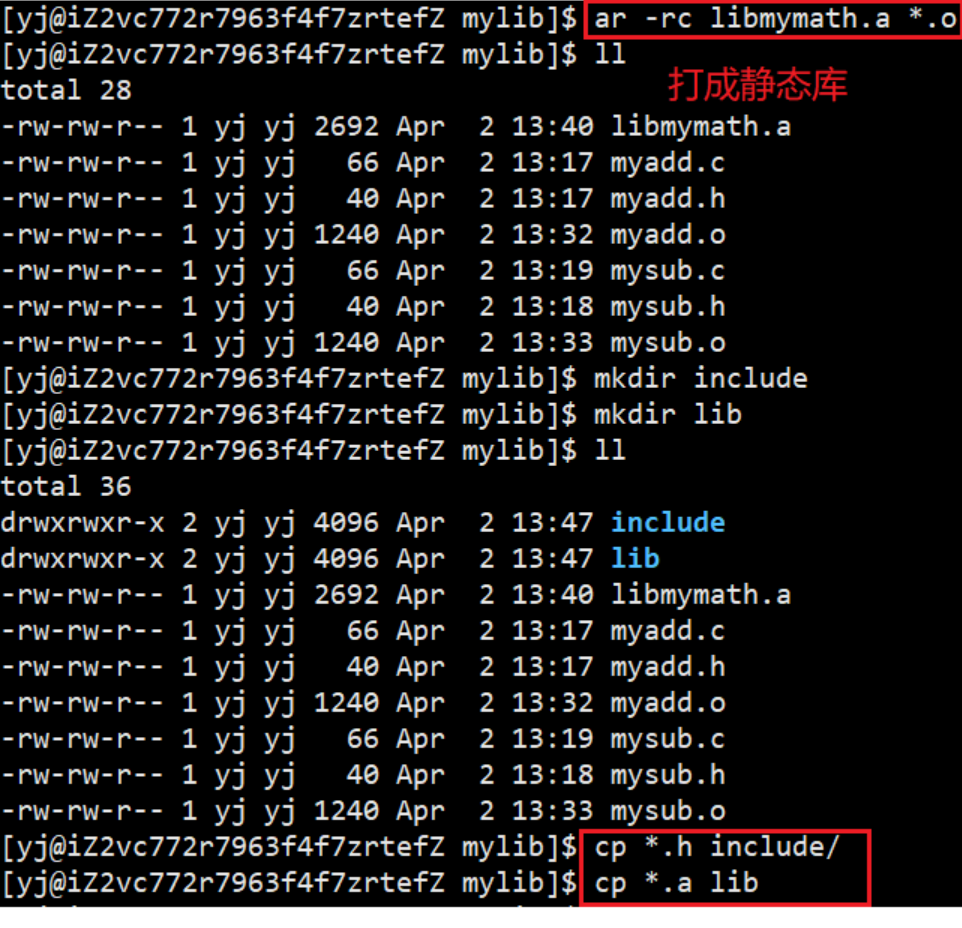
We adopt a new method, now all .o files ar -rc libmymath.a *.oare typed into static libraries by commands
Create two new directories, put the .o files in the lib directory, put the .h files in the include directory, and pack these two directories into a compressed package for otherPerson, and otherPerson can get the two by decompressing files in directories
After linking main.c file, .o file, .h file and specifying the static library name just now, the executable program mytest can be generated, just run mytest
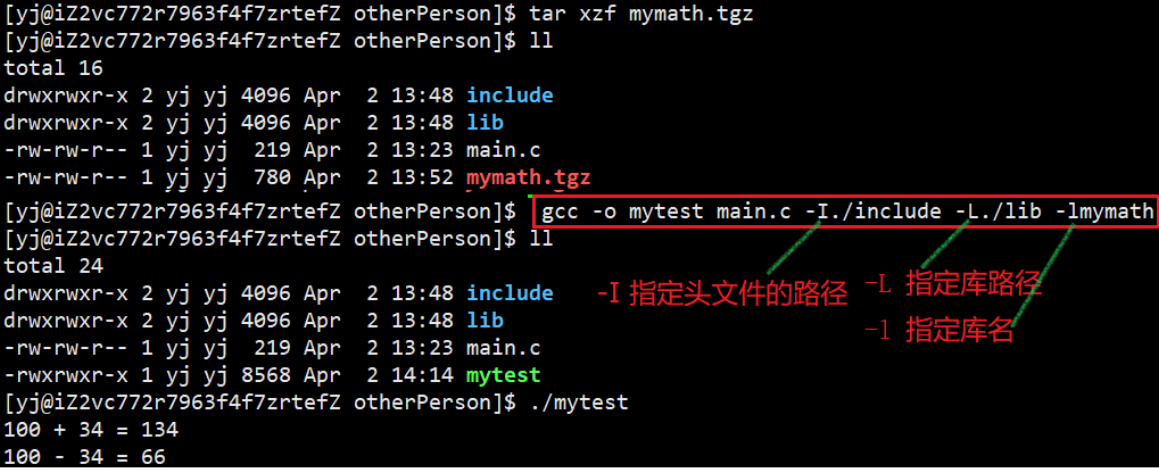
Use of third-party libraries
- Need to specify header files and library files
- If it is not installed in the default search path of system gcc and g++, the user must specify the corresponding option to inform the compiler:
a. Where is the header file
b. Where is the library file
c. Who is the library file? - Copy the library files and header files we downloaded to the default path of the system—in fact, it is to install the library under linux, so what about
uninstallation? For any software, the essence of installation and uninstallation is to copy to the system-specific path - If the library we installed is a third-party (language, operating system interface is the first and second party) library, we need to use it normally, even if it has been installed in the system, gcc , g++ must
-lspecify the name of the specific library
Understand the phenomenon:
Whether you download the library directly from the network, or the source code (compilation method) — the command for make install installation — is cp, installed in the system, we need sudo to install most of the instructions, libraries, etc. or superuser operation
8.3.3 Dynamic library configuration
Still the above scenario, at this time we want to build a dynamic library to let otherPerson execute the code
Before building a dynamic library, we first need to: gcc -fPIC -c myadd.cand gcc -fPIC -c mysub.c form a .o file (fPIC: generate position-independent code)
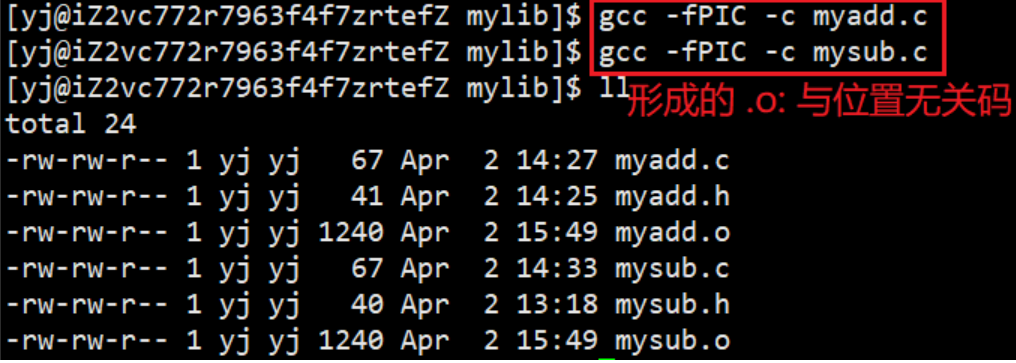
Then gcc -shared -o libmymath.so *.omake it into a dynamic library by
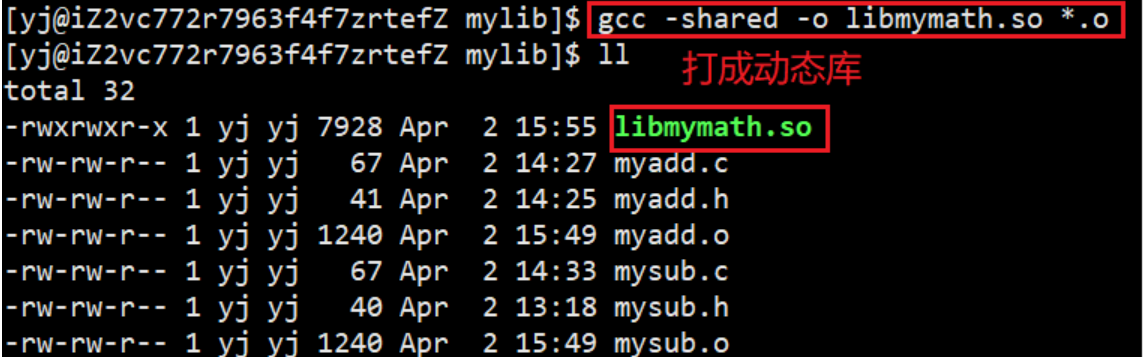
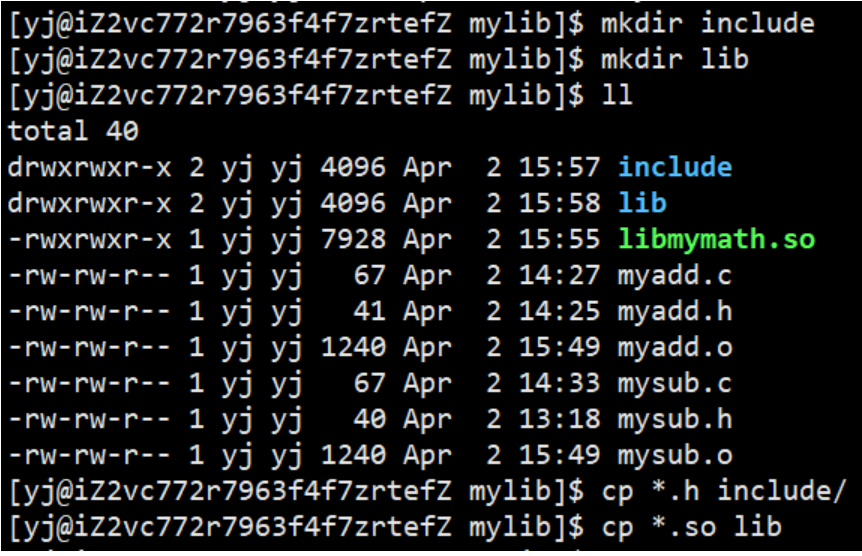
The same operation as the static library above, create two directories, put the .h file and the library file into the directory respectively, then pack it into a compressed package, and copy it to the otherPerson directory
After decompressing the otherPerson directory, link it like a static library to generate an executable program and then execute the program, but find that it cannot be executed
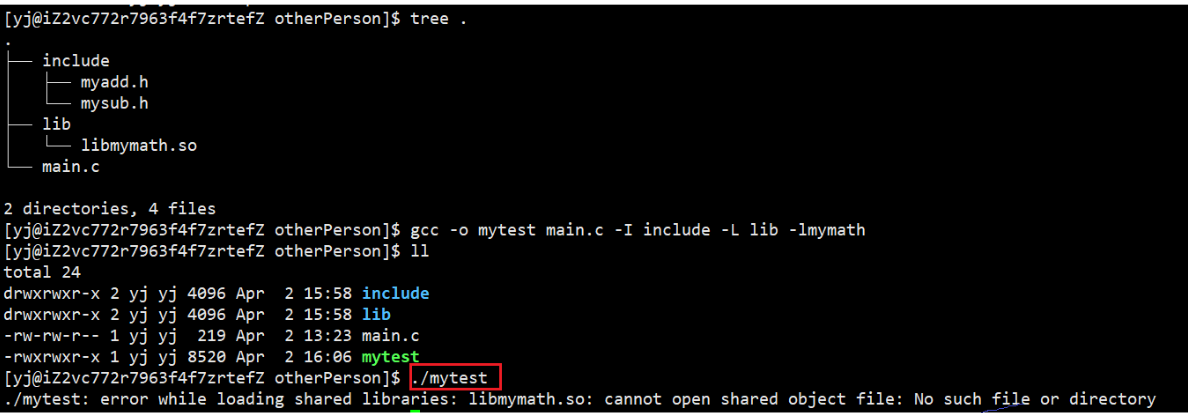
We are very confused, haven't we already told the system, where is my library and what is it called? Why can't I find it?
In fact, it is not telling the system, but telling the compiler
When running, because your .so is not in the default path of the system, the OS still cannot find it
So why can the static library be found?
The linking principle of the static library: directly copy the binary code used by the user into the target executable program , but the dynamic library will not
We can use the following three solutions to let the OS find the dynamic library:
Environment variable scheme
LD_LIBRARY_PATH
Add the dynamic library to the environment variable, which is convenient for OS and Shell to find
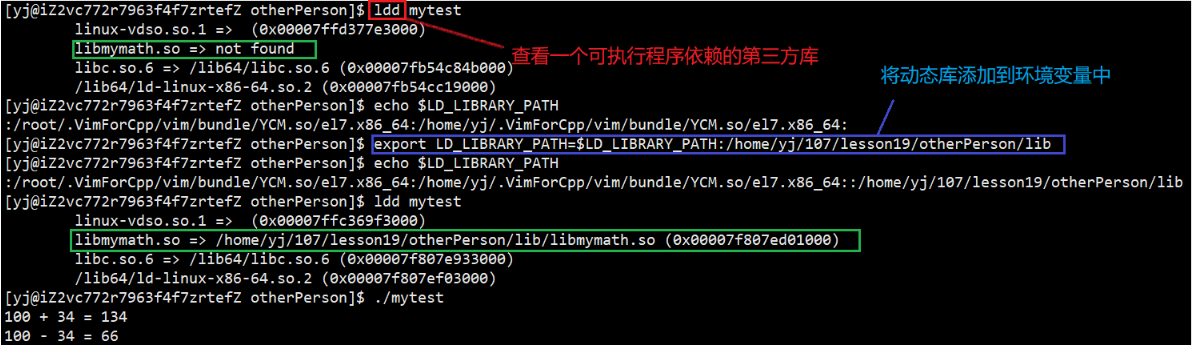
However, due to the temporary nature of environment variables, the next time we log in, our custom environment variables will be gone.
Soft link scheme
Create a soft link under the system's default search path

Profile Scheme
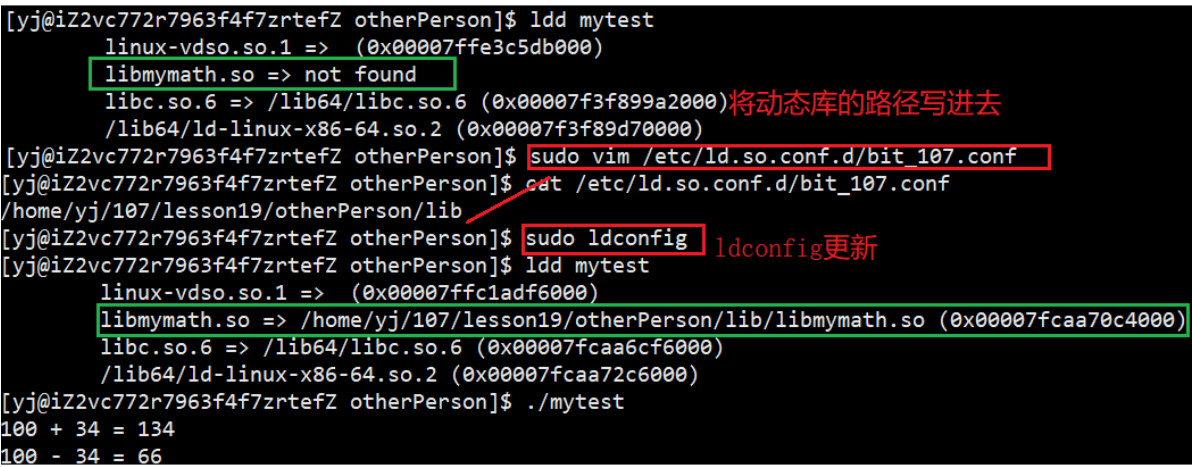
8.4 Loading understanding of dynamic and static libraries
8.4.1 Loading static libraries
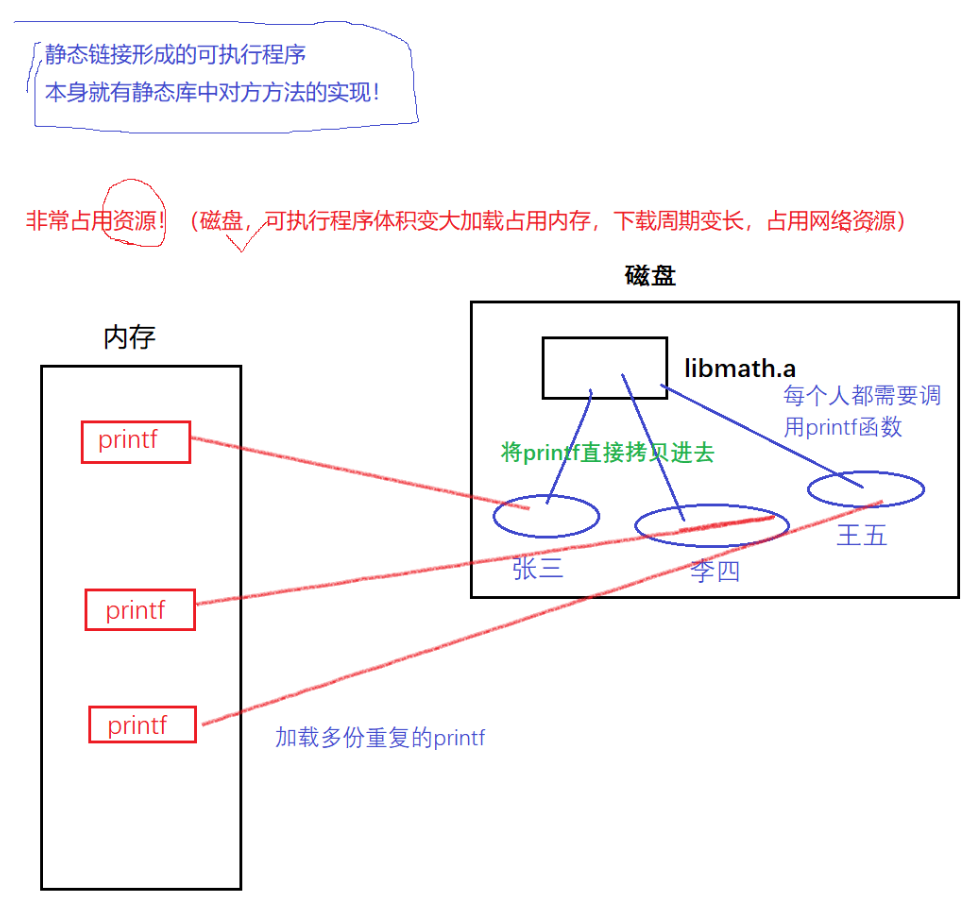
For static libraries, static libraries do not need to be loaded , but programs need to be loaded. When the static library is linked, the code (printf) is actually copied into the program, so when the program runs later, it no longer depends on the static library.
Once there are many programs, the static library will copy a large amount of repetitive code and distribute them to different programs . Through the knowledge of the process address space, we know that when the static library copies the code to the program, it actually copies the code into the code area. Therefore, when the program runs to form the process address space, the code in the static library can only be mapped to the corresponding code area of the process address space, and the future code must be accessed through a relatively definite address location .
8.4.2 Load dynamic library
Specific steps:
-
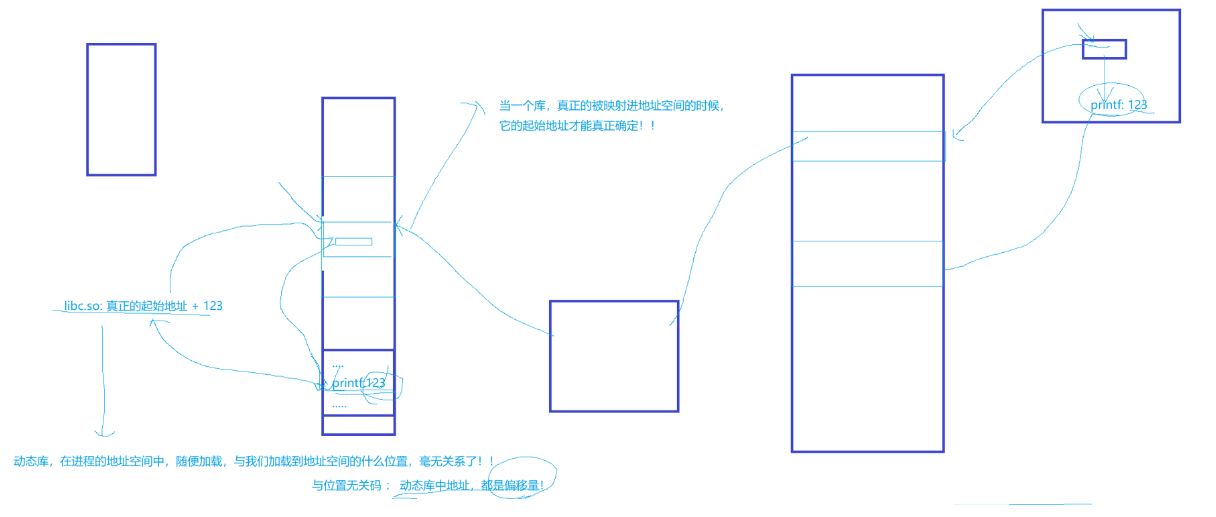
For dynamic linking, the address of a specific .o file in the dynamic library is stored in the executable program. At the same time, since the redirectable files that make up the dynamic library are generated by the position-independent code fPIC, this address is not . The real address of the o file, but the offset of the .o file in the dynamic library; (same as the virtual function table in C++)
-
Then there is the process of program running: the operating system will load the executable program in the disk into the physical memory, then create mm_struct, establish the page table mapping, and then start to execute the code. When the library function is executed, the operating system finds the function link is the address of a dynamic library, and the address is an external address, the operating system will suspend the running of the program and start loading the dynamic library;
-
Loading dynamic library: The operating system will load the dynamic library in the disk into the physical memory, and then map it to the shared area of the address space of the process through the page table, and then immediately determine the address of the dynamic library in the address space, that is, The starting address of the dynamic library, and then continue to execute the code;
-
At this time, the operating system can obtain the address of the .o file according to the address stored in the library function, that is, the offset of the .o file in the dynamic library, plus the starting address of the dynamic library, and then jump to the shared area Execute the function, and jump back after execution to continue executing the code behind the code segment. This is the loading process of the complete dynamic library.
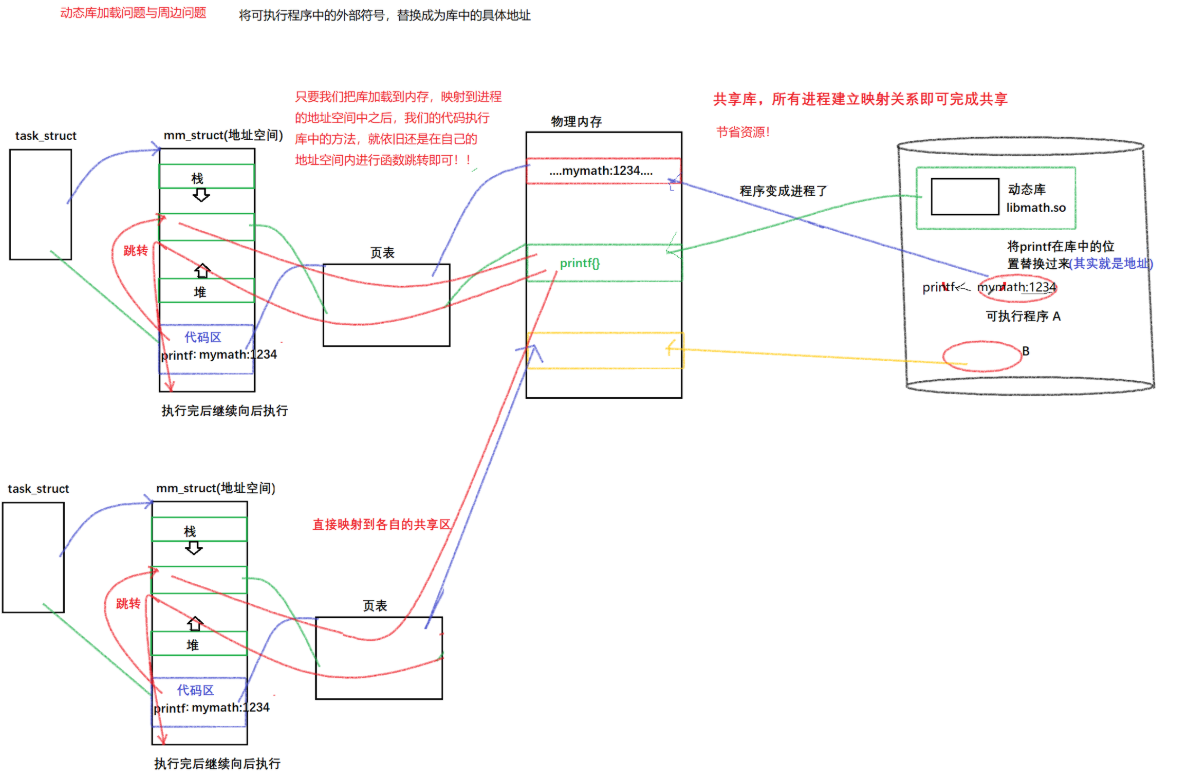
Therefore, it can be seen that the dynamic library is not like the static library. It does not need to copy a large amount of the same code. All processes can establish a mapping relationship so that multiple programs can share the code in the dynamic library.
8.4.3 Comprehension of addresses in libraries
For example, in such a scene, you are standing 50 meters away from the playground, and your friend wants to come to you, you can tell him: 1. I am 50 meters away from the playground 2. I am on the left side of the playground number, about 20 meters away ; 1 is an absolute addressing; 2 is a relative addressing. If one day the school widens the front and back of the playground, it will definitely change for address 1, but it will remain the same for address 2 (as long as the position of the tree remains the same)
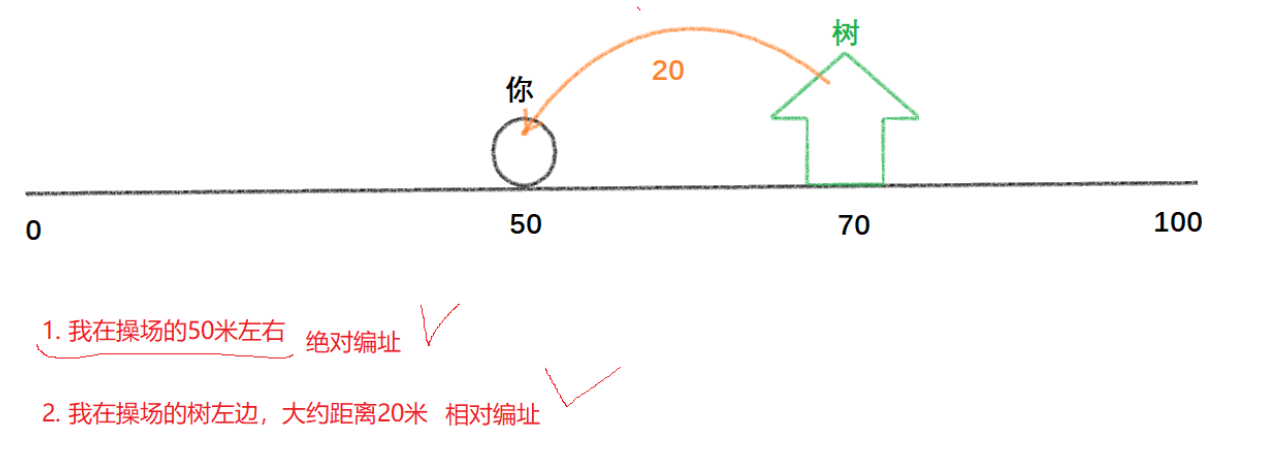
Use the above example to compare dynamic and static libraries
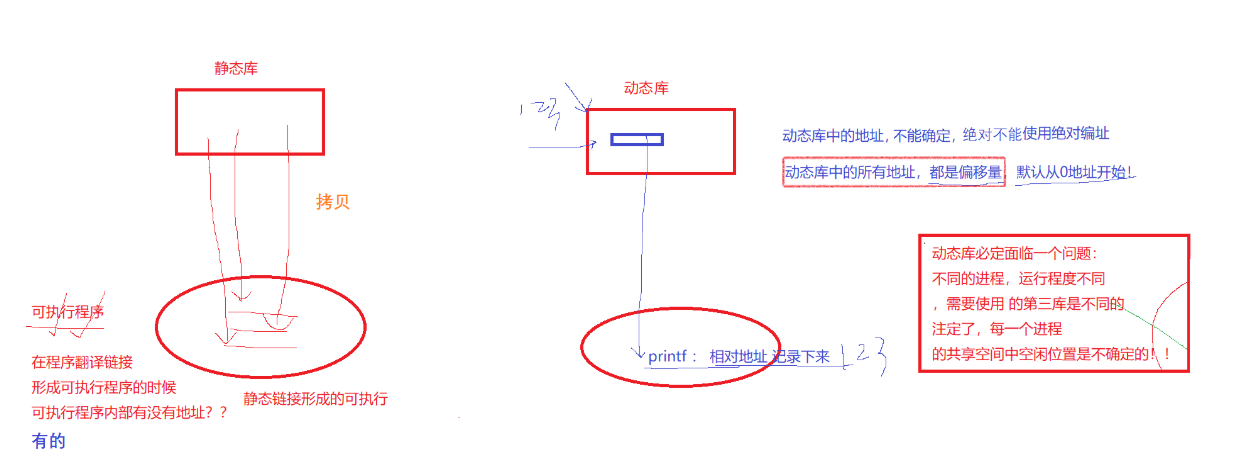
fPIC: generate a position-independent code, which is essentially an offset