This series is coming to an end, and there will be one or two articles later on, how to use AI to actually apply in industrial production and R&D, how to guide the synthesis of chemical molecules, and how to do DNA research prediction and synthesis.
background
Recently, chatpdf has been widely circulated in various media, and the effect is very shocking. There are probably three reasons:
1. PDF is a kind of preservation document in everyone's impression, and it is not easy to do secondary data processing
2. You can do question and answer on the content in the pdf, and you can also do translation by the way, and generate summary opinions for long articles
3. You can find where a point of view appears
But in fact, if you are a student who is doing nlp and is a little familiar with office automation, you should know that the above points are not difficult.
1. PDF can actually be operated as easily as word.
2. The abstract of the article is difficult, but chatgpt is capable of organizing knowledge, just adjust the api
3. It can be realized by integrating the automation ability + chatgpt
recurrent
How to read pdf with python
Use python to read and process pdf files, save the files as csv, and sort by text content, lines, and pages. Use PyPDF2 to extract pdf data, and save the content, page number, and row number of each line into cvs with pandas. The specific operation is as follows, and the result is shown on the right.
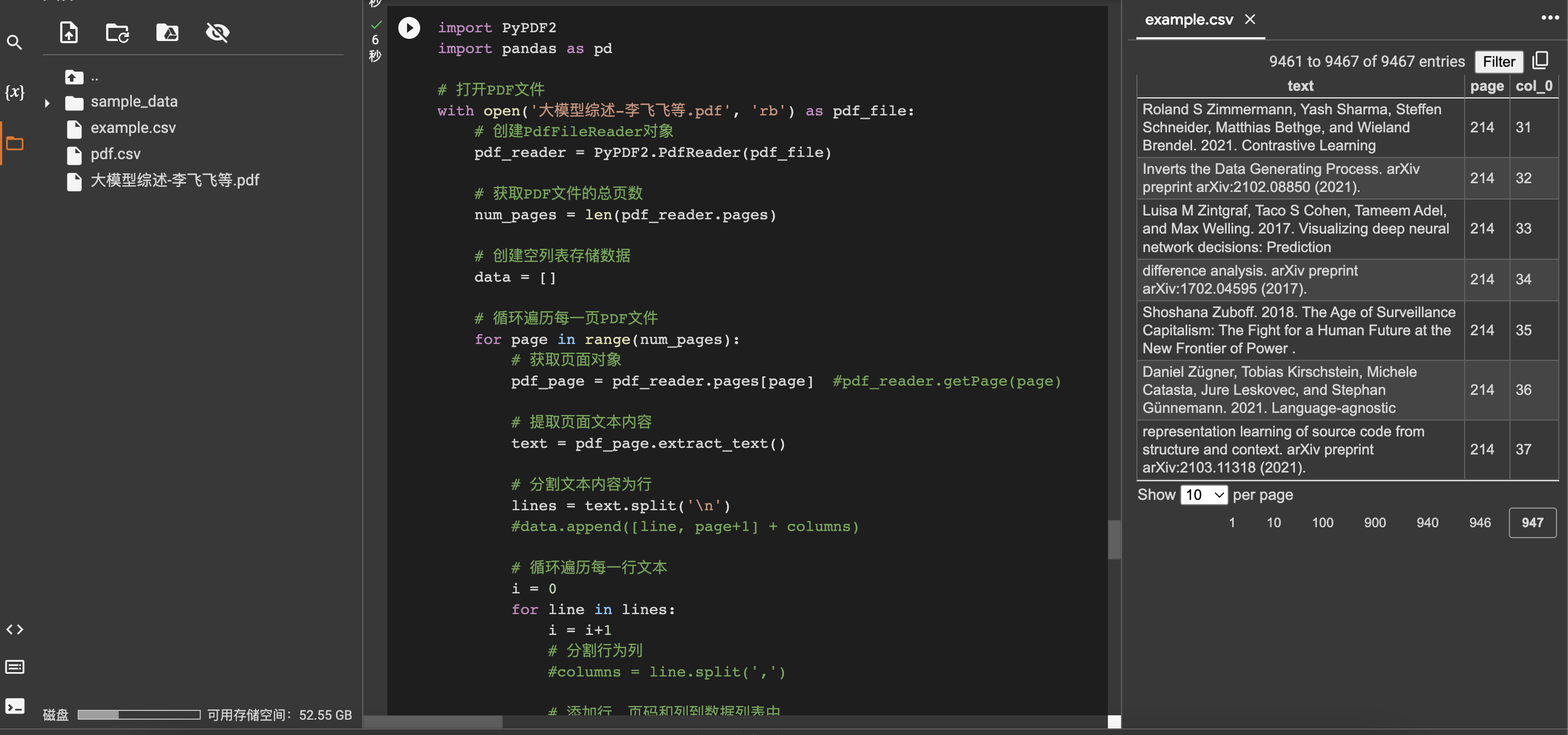
code show as below:
import PyPDF2
import pandas as pd
# 打开PDF文件
with open('大模型综述-李飞飞等.pdf', 'rb') as pdf_file:
# 创建PdfFileReader对象
pdf_reader = PyPDF2.PdfReader(pdf_file)
# 获取PDF文件的总页数
num_pages = len(pdf_reader.pages)
# 创建空列表存储数据
data = []
# 循环遍历每一页PDF文件
for page in range(num_pages):
# 获取页面对象
pdf_page = pdf_reader.pages[page] #pdf_reader.getPage(page)
# 提取页面文本内容
text = pdf_page.extract_text()
# 分割文本内容为行
lines = text.split('\n')
#data.append([line, page+1] + columns)
# 循环遍历每一行文本
i = 0
for line in lines:
i = i+1
# 分割行为列
#columns = line.split(',')
# 添加行、页码和列到数据列表中
data.append([line, page+1, i])
# 将数据列表转换为Pandas DataFrame对象
df = pd.DataFrame(data, columns=['text', 'page'] + [f'col_{i}' for i in range(len(data[0])-2)])
# 将DataFrame对象保存为CSV文件
df.to_csv('example.csv', index=False)How to send pdf information to chatgpt
How to extract abstract
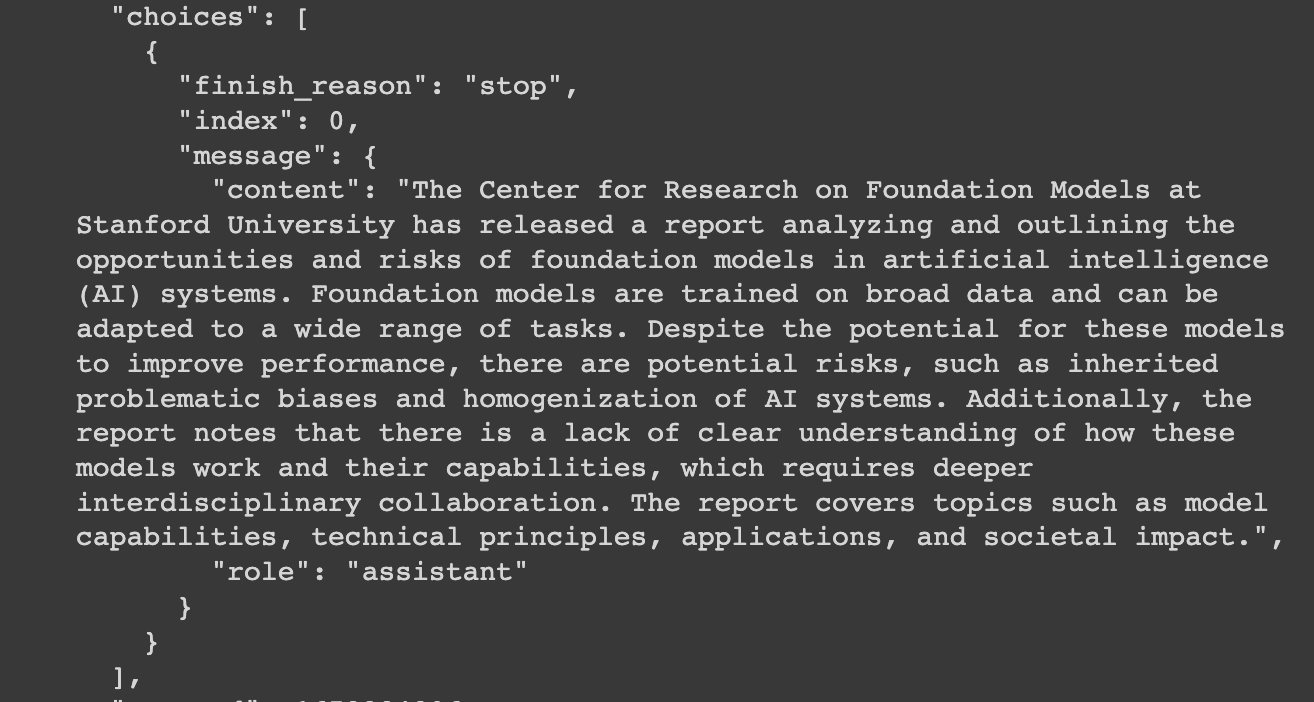
Feed the paper into ChatGPT and let the model generate a summary. The following code can be used to feed papers into ChatGPT and let the model generate summaries:
#每次prompt有限制,可以分批输入,要抽取的好,有些拼接技巧,各位看官自己动动脑动动手试试
import openai
openai.api_key = "你的apitoken"
openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Who won the world series in 2020?"},
{"role": "assistant", "content": "The Los Angeles Dodgers won the World Series in 2020."},
{"role": "user", "content": "Please generate a summary of the given article: {}\n\n ARTICLE TEXT HERE".format(' '.join(df['text'][0:200]))}
]
)The effect is as follows:
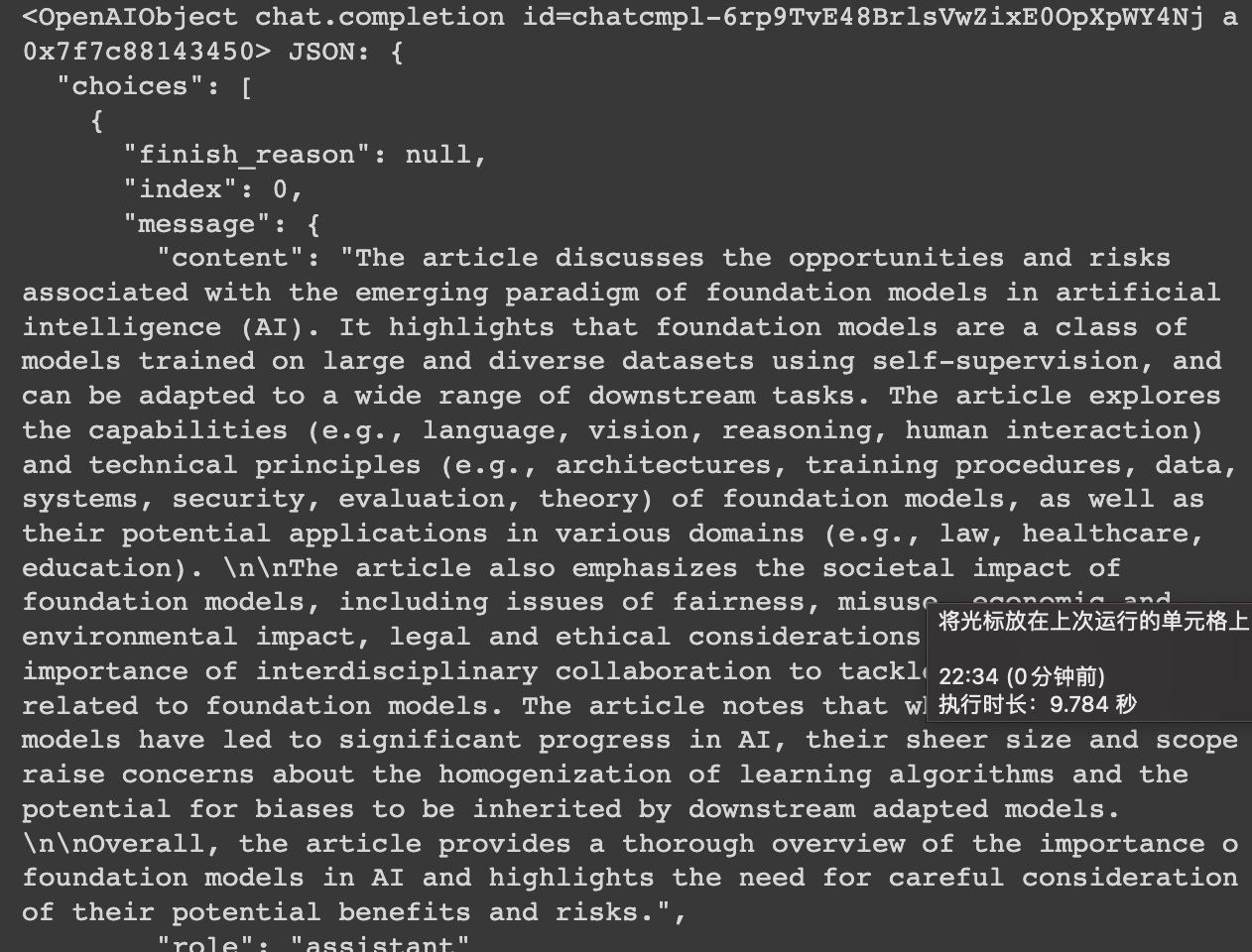
How to ask a question to find the original text
code show as below:
import openai
openai.api_key = "你的api token"
openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Who won the world series in 2020?"},
{"role": "assistant", "content": "The Los Angeles Dodgers won the World Series in 2020."},
{"role": "user", "content": "Please analyze the given article {article} and list the key {key} topics discussed: \n\n ARTICLE TEXT HERE".format(article =' '.join(df['text'][0:200]),key = 'where ia content?')
}
]
)The effect is as follows:
The line number and page number are not displayed because I did not bring the data that was processed and stored in the csv before. You can try the effect yourself, it is not difficult.
how to translate
import openai
openai.api_key = "你的api token"
openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Who won the world series in 2020?"},
{"role": "assistant", "content": "The Los Angeles Dodgers won the World Series in 2020."},
{"role": "user", "content": "把输入的英文{article} 翻译成中文 : \n\n ARTICLE TEXT HERE".format(article =' '.join(df['text'][0:20]))
}
]
)The result is as follows:
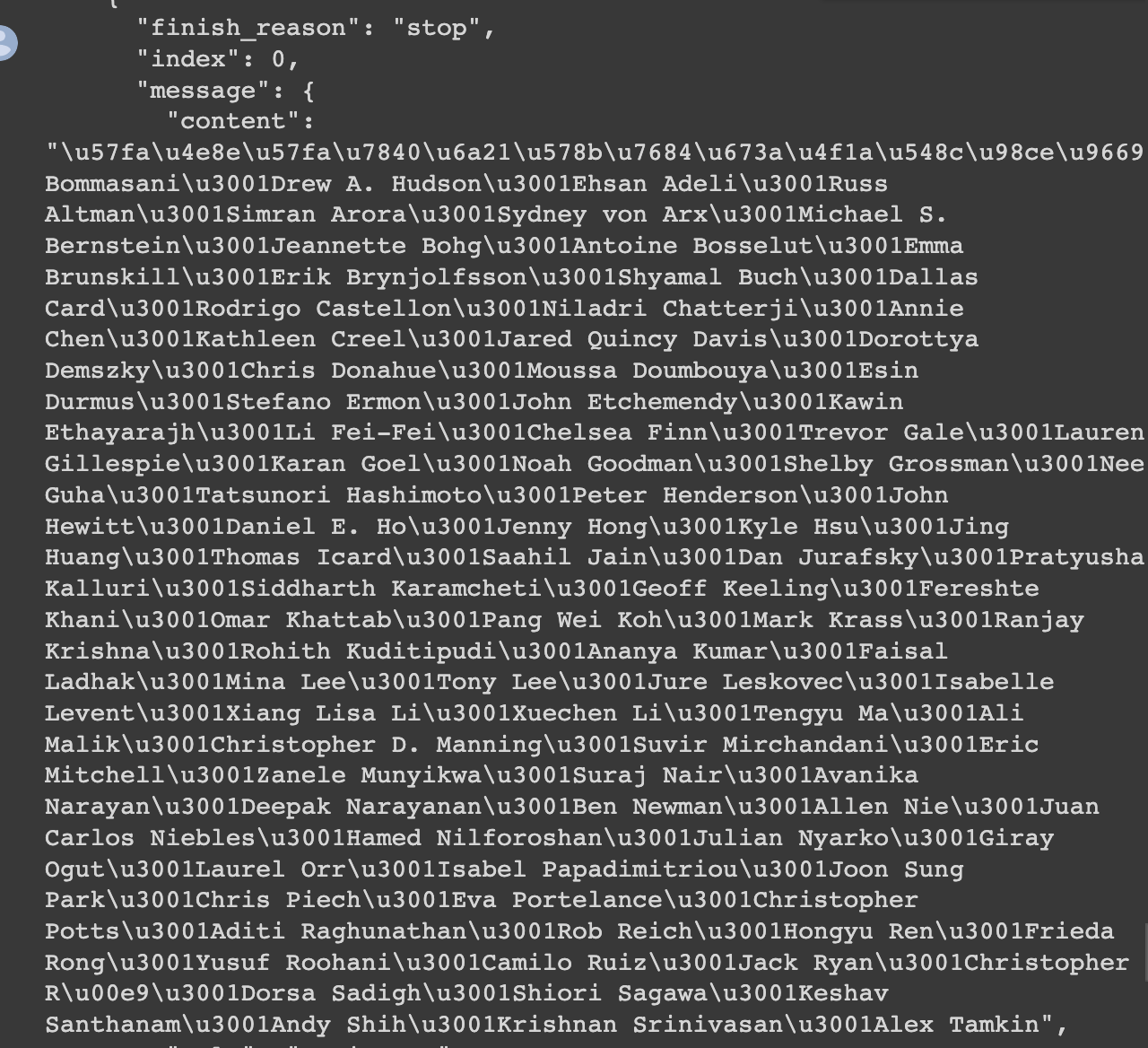
utf-8 into Chinese