background
It has been almost two months since the last article that took you to realize your own mini chatgpt article. The self-made mini chatgpt article has not been updated for two reasons: 1. I have been looking for a model with a suitable size and a good performance. This article will introduce you to some concepts of large model training, and then introduce you to the fine-tuning learning of the pretrain model on your own data set.
Everyone has been talking about large models, but it feels like everyone is only talking about large models. It seems that I haven’t seen an article introducing the whole process of the large model, 1. What steps need to go through 2. What are the means to learn knowledge 3. How to do domain-specific knowledge enhancement 4. How to let the machine Understand people better (adapt to the expressions of different people, and give the answers they want accurately; in fact, it is to enhance the fuzzy adaptability of the intelligent body).
This article will try to answer the above questions. Of course, some technical details and technical processes cannot be fully covered. There are two reasons: 1. Different situations have different solutions, so I can only talk about a general direction. 2. The company does not allow me to disclose all the details, after all, this is a matter of money.
Large model training process
1. Pretain model: Most of the cases at this stage are designed as unsupervised or weakly supervised learning, making the model a well-read and knowledgeable generalist
2. Model fine-tuning: This part mainly makes a small amount of labels or knowledge supplements to the pretrain model, allowing generalists to sort out their knowledge structure into a system
3. Upstream task learning: This part of the task trains the professional skills of the model, allowing the model to have a stronger working force when it has general knowledge, and it will also reshape the general knowledge system
4. Alignment learning: profound and capable, but it needs to be more understandable and easier to communicate with him, so alignment is needed, and the mainstream of this part is RLHF
The above several processes are not just done in one round, often it takes many rounds of iterations to make the model perform better. The above process division of labor is carried out sequentially in the first few rounds, with relatively obvious boundaries. However, the borders of iterations become more blurred in the later stages, and several methods are often used together at the same time. So everyone knows that there are these processes and means, and there is no need to worry about their clear boundaries.
large model training
fine tune
The core idea of Fine-tune is to utilize a pre-trained model trained on a large dataset (such as ImageNet, COCO, etc.), and then use a smaller dataset (less than the number of parameters) to fine-tune it [3 ] . The advantage of this is that compared to training the model from scratch, Fine-tune can save a lot of computing resources and time costs, improve computing efficiency, and even improve accuracy [ 1 ][ 2 ].
Finetune refers to fine-tuning for specific tasks based on the pre-trained model to improve the performance of the model. There are many specific methods of Fine-tune, but in general, fine-tuning can be performed by adjusting the number of layers of the model, adjusting the learning rate, adjusting the batch size, etc. [2 ] .
The advantage of Finetune is that it does not need to completely retrain the model, thereby improving efficiency, because the accuracy of the new training model generally starts to rise slowly from a very low value, but finetune allows us to get a better result after a relatively small number of iterations .
Although Fine-tune has many advantages, it also has some disadvantages. For example, Fine-tune requires a large dataset to improve the performance of the model, which may make some tasks difficult to achieve. In addition, the performance of Fine-tune largely depends on the quality and applicability of the pre-trained model, and if there is a discrepancy between the pre-trained model and the fine-tuned dataset, Fine-tune may fail to improve the model performance [1 ] .
In the future, Fine-tune technology will continue to be widely used. On the one hand, with the continuous development and improvement of the deep learning model, the quality and applicability of the pre-trained model will continue to improve, making it more suitable for Fine-tune technology. On the other hand, Fine-tune technology will also help to solve some problems in practical applications, such as small data sets and difficult data set labeling [ 1 ][ 3 ].

prompt learn
The basic concept of Prompt Learning: Prompt Learning is a natural language processing technology that guides the model to complete different tasks by adding a short prompt text in front of the input of the pre-trained model [1 ] . These prompt texts are usually in the form of questions or instructions that tell the model how to understand the input and generate the output. The advantage of prompt learning is that it can accomplish multiple tasks with a small amount of data [ 2 ].
Multi-Prompt Learning: Multi-Prompt Learning is an extended form of Prompt Learning, which can apply multiple Prompts to a problem to achieve data enhancement or problem decomposition [1 ] . Common Multi-Prompt Learning methods include parallel methods, augmentation methods, and combination methods [ 2 ]. The parallel method performs multiple prompts in parallel, and aggregates the results of multiple single prompts by weighting or voting; the enhanced method inputs a case similar to the current problem together with the current input, so that the model can make predictions more accurately ; the combination method combines multiple prompts together to train the model for more complex tasks [ 2 ].
How to choose an appropriate pre-training model: Selecting an appropriate pre-training model is one of the key steps in Prompt Learning. When choosing a model, the following factors need to be considered: task type, dataset, model size, and training time, etc. [ 1 ]. Generally, the larger the size of the pre-trained model, the better it will perform on various tasks, but at the same time it needs to consume more computing resources [ 1 ].
How to adjust the training strategy of Prompt: Another key step of Prompt Learning is how to adjust the training strategy of Prompt. You can use the method of simply improving the model effect under full data, or use Prompt as an auxiliary method under few-shot/zero-shot, or fix the pre-training model and only train Prompt[[1].
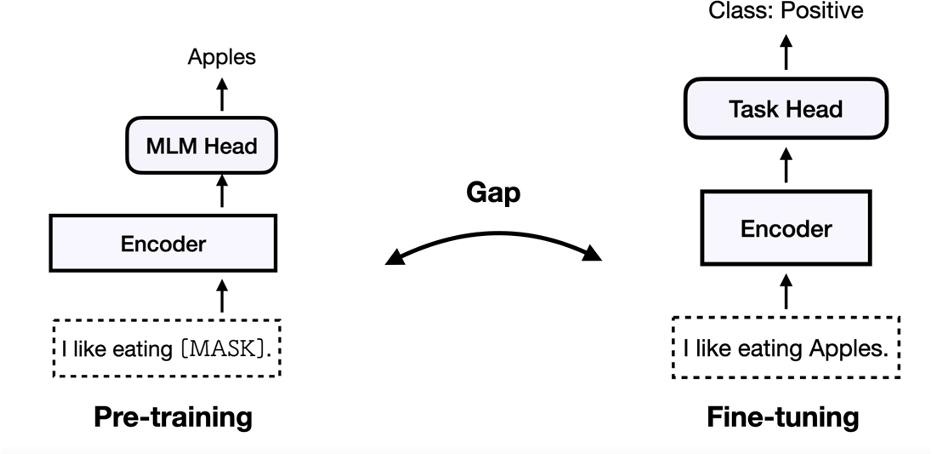
As shown in the figure above, finetune's pre-training method uses PLMs as the basic encoder, and adds an additional neural layer for specific tasks in the downstream tasks of finetune, and adjusts all parameters. There is a gap between pre-training and fine-tuning tasks.

As shown in the above figure, the prompt uses the same MLM task during pre-training and finetuning downstream tasks. Bridging the gap between model tuning and pre-training to enhance few-shot learning. Using PLMs as the base encoder, adding additional context (template) and [MASK] positions, projecting labels to label words (verbalizer), closing the gap between pre-training and fine-tuning.
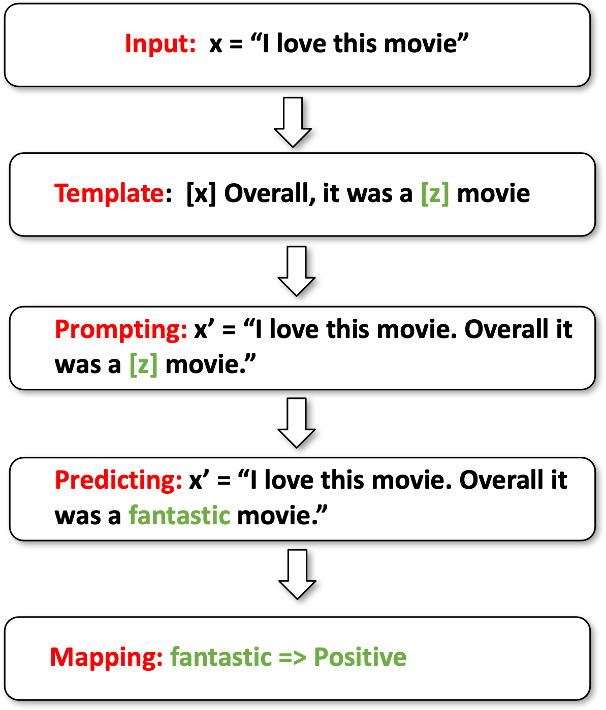
The above is a schematic diagram of the process of converting user comments to prompts, including template selection, template packaging, MLM output word selection, and word mapping to comment positive and negative.
template selection
Artificial template design includes that experts design a set of templates based on their understanding of the problem to convert the solution to a specific problem into an expression method suitable for natural language generation. The following is a structured template made by people for QA problems, which converts QA problems into problems of generative model generation output.

Automatically search to generate a prompt template, select a meta template, and then generate the optimal prompt template based on the gradient search of existing words.
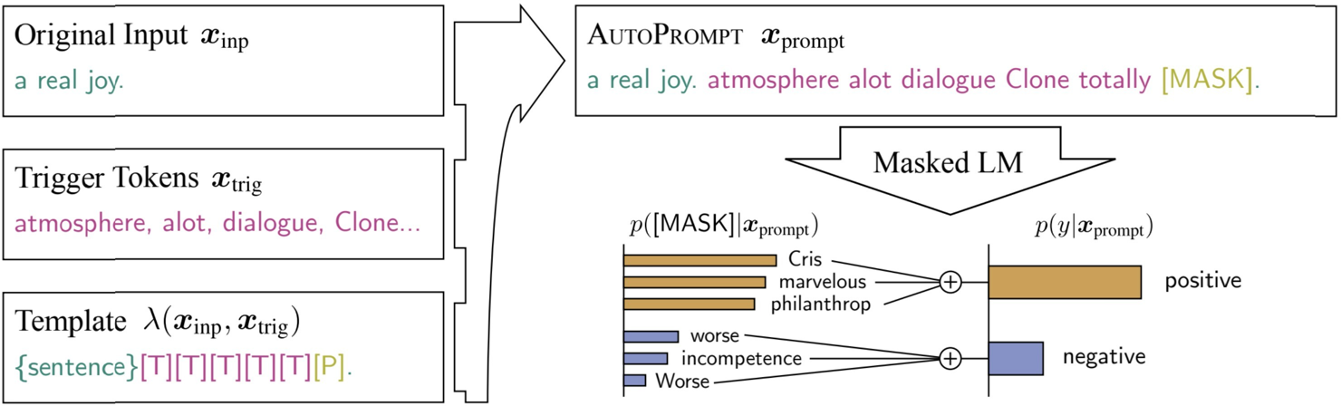
Use T5 to automatically generate templates for multiple input sentences. The operation is as shown in the figure below, the general steps: 1. Use the existing template to train a T5 model, let the model learn how to pass the corpus (level all the task input as vector input, and the output is the final template) 2. Use the task input as the input, use the training model for template generation
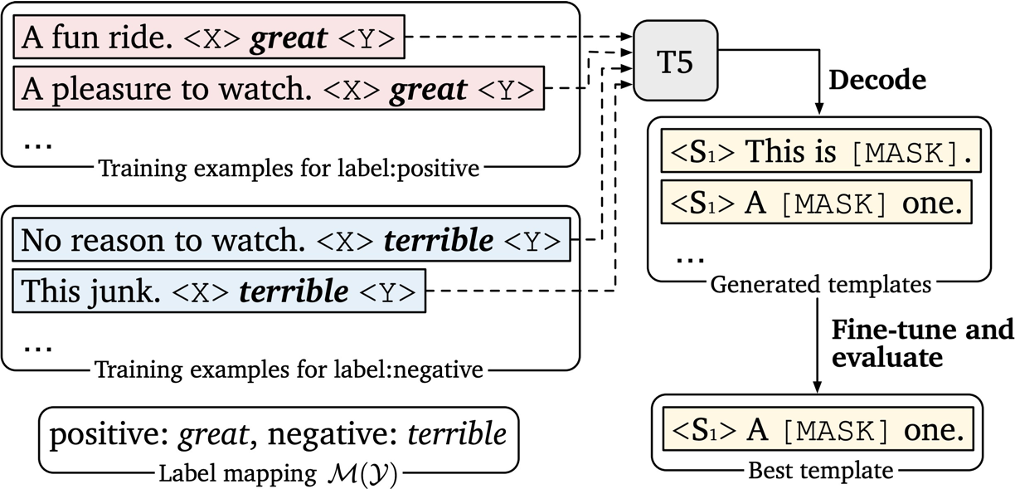
Let the pre-model automatically generate templates, the idea is as follows, fix the main pre-train model, let the model train the marked tasks, and modify the input sentence embbeding after the model is learned. Of course, the original sentence is not changed, just let The model is changed to the non-input sentence part, and finally the most prompt template can be automatically learned. Of course, this template may not be understood by people.
P-tuning v1: use hints for input layer (using reparameterization)
P-tuning v2: use hints for each layer (like prefix tuning)

fill in word choice
It is suitable for the prompt task design, and the tasks are converted into the generation mode, so there will be a conversion process of how to map the generated things to the desired results. The design and selection of the intermediate vocabulary have a great impact on the final result, so We need to design the output deep words.
Positive: great, wonderful, good.. Negative: terrible, bad, horrible…
manually generated

Brainburst generates a wave of keywords or sentence phrases, and then uses the existing knowledge base to recall more related words, concepts or phrase sentences, and then sorts and selects the recalled words, sentence phrases.
Automated generation

Similar to automatic template generation, the model is fixed, and the labeled data is used for training. When the gradient is reversed, the input embedding words are changed.
delta learn
The overall idea is to add some control parameters to make the large expressive model controllable to learn and use. Use an example as a metaphor: In cybernetics, a simple linear control matrix is used to control a large and complex system; this metaphor may not be completely accurate, because deta learn can actually be merged into the original model, which is actually a link to the learned knowledge. 's rearranged.
The real thing is to use incremental tuning to simulate a model with billions of parameters and optimize a small set of parameters.
This picture means that I am still me, but after simple changes and learning, I can become a variety of different me, but the pre-train model does not move, only the parameters involved, eyes, One picture, decoration. It is very vivid to express the training process, but I feel that it is not enough to express the meaning. But this picture has been widely spread, so I will post it here by the way.

Addtion: the method introduces additional trainable neural modules or parameters that do not exist in the original model;
Specification: method specifies that some parameters in the original model or process become trainable, while other parameters are frozen;
The Reparameterization: method reparameterizes existing parameters into a parameter-efficient form by transforming them.

3 factors are important for detaleran:
1. Where to insert: Sequential insertion with the original network, or bridging insertion
2. How to insert: insert only certain layers, or insert each layer of the entire network
3. How big is the matrix control: how big is the parameter that enters the control layer, one bit, or 0.5% of the original parameter

Different insertion methods and different parameters have a relatively large difference in the effect of the model. You can experience this when you actually fine-tune the model. The above table is a mathematical abstract representation of different methods. When you find that you have no ideas during the actual operation, you will come to look at this table. It will be helpful if you think about it in combination with the problem.
Practical part
This part is based on the chatglm 6B model for experiments. The specific code is in this link: GitHub - liangwq/Chatglm_lora_multi-gpu: chatglm multi-gpu with deepspeed and
The model does not have to be chatglm, llama or other models are all possible. Huggingface's peft is used for delta learning, and deepspeed is used for multi-card distributed training.
Tested: 2 cards A100 80G, 8 cards A100 80G hardware configuration data and speed are as follows:
500,000 selefinstruct data, 2 cards, 32-core cpu, 128G mem
Batch 2, gd 4 means each batch size=16; 2 epochs lora_rank=8, the amount of inserted parameters is about 7M, and it takes 20 hours to train
8 cards is about 5 hours
Fine-tuning, model convergence is very stable and the effect is good
Code explanation:
data processing logic
def data_collator(features: list) -> dict:
len_ids = [len(feature["input_ids"]) for feature in features]
longest = max(len_ids) + 1
input_ids = []
attention_mask_list = []
position_ids_list = []
labels_list = []
for ids_l, feature in sorted(zip(len_ids, features), key=lambda x: -x[0]):
ids = feature["input_ids"]
seq_len = feature["seq_len"]
labels = (
[-100] * (seq_len - 1)
+ ids[(seq_len - 1) :]
+ [tokenizer.eos_token_id]
+ [-100] * (longest - ids_l - 1)
)
ids = ids + [tokenizer.eos_token_id] * (longest - ids_l)
_ids = torch.LongTensor(ids)
attention_mask, position_ids = get_masks_and_position_ids(
ids, seq_len, longest, _ids.device, gmask=False
)
labels_list.append(torch.LongTensor(labels))
input_ids.append(_ids)
attention_mask_list.append(attention_mask)
position_ids_list.append(position_ids)
input_ids = torch.stack(input_ids)
labels = torch.stack(labels_list)
attention_mask = torch.stack(attention_mask_list)
position_ids = torch.stack(position_ids_list)
return {
"input_ids": input_ids,
"labels": labels,
"attention_mask": attention_mask,
"position_ids": position_ids,
}Inserting lora allows adding training to lora trained on other data, which means that part of the data can be used to train lora separately, and it is necessary to integrate the trained lora for joint training, which is very convenient. It is definitely a good thing for friends who do not have enough machine configuration
# setup peft
peft_config = LoraConfig(
task_type=TaskType.CAUSAL_LM,
inference_mode=False,
r=finetune_args.lora_rank,
lora_alpha=32,
lora_dropout=0.1,
)
model = get_peft_model(model, peft_config)
if finetune_args.is_resume and finetune_args.resume_path:
print("=====>load lora pt from =====》:", finetune_args.is_resume, finetune_args.resume_path)
model.load_state_dict(torch.load(finetune_args.resume_path), strict=False)The accelerate integration part, because it will not keep checkpoints, so I wrote the hardcode to keep a checkpoint every 2000 steps. This part has not yet come and only keeps the latest two checkpoint codes, so many brother checkpoint folders will be generated. If you don't use the block, you can comment it out, or write down the code yourself to keep two. Of course I will update later.
if i%2000 ==0 and accelerator.is_main_process:
#accelerator.wait_for_everyone()
path = training_args.output_dir+'/checkpoint_{}'.format(i)
os.makedirs(path)
accelerator.save(lora.lora_state_dict(accelerator.unwrap_model(model)), os.path.join(path, "chatglm-lora.pt"))
#save_tunable_parameters(model, os.path.join(path, "chatglm-lora.pt"))
i +=1summary
1. Introduced the training process of the pre-trained large model
2. Introduced commonly used training methods
3. Introduced in detail the principles of two mainstream pre-training methods: promt and delta
4. An example of multi-gpu chatglm training is given
Notice:
The next article will introduce you to the RLHF part, you can follow me