Three business principles
3.1 Transaction basis
Transaction is an important feature that distinguishes MySQL from NoSQL, and is a key technology to ensure data consistency in relational databases. A transaction can be regarded as the basic execution unit for database operations, which may contain one or more SQL statements. When these statements are executed, either all of them are executed, or none of them are executed. MySQL transactions consist of four features:
Atomicity : The statement is either fully executed or not executed at all, which is the core feature of a transaction, and the transaction itself is defined by atomicity. The implementation is mainly based on the undo log log.
Durability : Guarantee that data will not be lost due to downtime and other reasons after the transaction is committed. The implementation is mainly based on the redo log log.
Isolation : Ensure that transaction execution is not affected by other transactions as much as possible. The default isolation level of InnoDB is RR. The implementation of RR is mainly based on the lock mechanism, hidden columns of data, undo log and next-key lock mechanism.
Consistency : The ultimate goal pursued by transactions, the realization of consistency requires both the guarantee of the database level and the guarantee of the application level.
In fact, the principle of our study of transactions is to study how MySQL's InnoDB engine guarantees these four characteristics of transactions
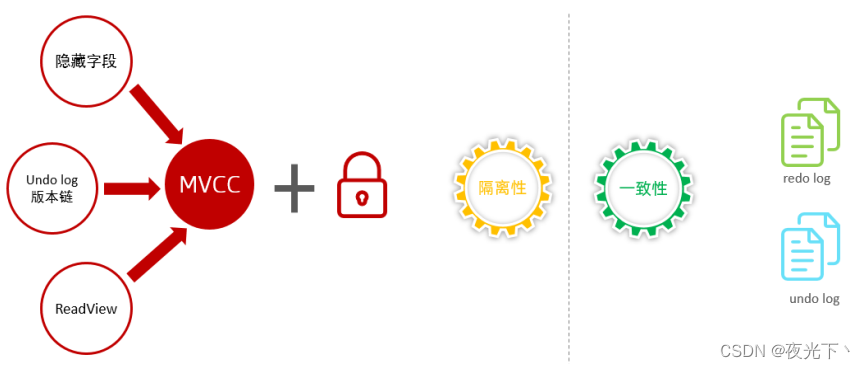
For these four characteristics, they are actually divided into two parts. The atomicity, consistency, and persistence are actually guaranteed by two logs in InnoDB, one is the redo log and the other is the undo log. Persistence is guaranteed by database locks and MVCC.

3.2 redo log
The redo log (redo log) is the log of the InnoDB engine layer, which is used to record the data changes caused by the transaction operation, and records the physical modification of the data page. The InnoDB engine updates the data by first writing the update records into the redo log, and then updating the contents of the log to the disk when the system is idle or according to the set update strategy. This is the so-called pre-written technology (Write Ahead logging). This technology can greatly reduce the frequency of IO operations and improve the efficiency of data refresh.
The log file consists of two parts: redo log buffer (redo log buffer) and redo log file (redo log file), the former is in memory, the latter is in disk. After the transaction is committed, all modification information will be saved in the log file, which is used for data recovery when an error occurs during the process of flushing dirty pages to disk.
What problems will exist if there is no redo log?
In the InnoDB storage engine, the main memory area is the buffer pool. Many data pages are cached in the buffer pool. When we operate on the data, we do not directly operate the data in the disk, but operate the data in the buffer pool. Data, if the data we need does not exist in the buffer pool, the data will be loaded from the disk through the background thread, put into the buffer pool, and then the data in the buffer pool will be modified. The modified data page is called Dirty pages, and dirty pages are not directly flushed to the disk, but flushed to the disk through a background thread at a certain time, so as to ensure that the data in the buffer and the disk are consistent, because the dirty page data in the buffer is not real-time refreshed. If after a period of time, an error occurs in the process of flushing the dirty page to the disk, resulting in the data not being persisted, and the user has completed the modification of the buffer data during the operation, and the operation is returned successfully, so there is no guaranteed transaction persistence.

So, how to solve the above problems? A log redo log is provided in InnoDB. Next, let’s analyze how to solve this problem through redolog

With the redolog, when the data in the buffer is added, deleted, or modified, the changes in the data page of the operation will be recorded in the redolog buffer first. When the transaction is committed, the data in the redo log buffer will be flushed to the redo log disk file. After a period of time, if an error occurs when flushing the dirty pages in the buffer to the disk, you can use the redo log for data recovery at this time, thus ensuring the durability of the transaction. And if the dirty pages are successfully flushed to the disk or the data involved has been placed on the disk, the redolog is useless at this time and can be deleted, so the two existing redolog files are written cyclically.
There are some details of the redo log that we need to pay attention to. The size of the redo log is fixed. In order to be able to continuously write the update records, two flag positions are set in the redo log, checkpoint and write_pos, respectively indicating record erasure Where to delete and where to record writes. This structure is much like a circular queue:

The space between write_pos and checkpoint can be used to write new data, and writing and erasing are both backwards and cyclically repeated. When write_pos catches up with the checkpoint, it means that the redo log is full. At this time, the new database update statement cannot be executed. It is necessary to stop and delete some records first, execute the checkpoint rule, and flush the dirty data pages and dirty log pages in the buffer. to disk (dirty data pages and dirty log pages refer to data and logs that are still in memory and have not been flushed to disk), freeing up writable space.
When talking about redo log, we have to talk about buffer pool, which is an area allocated in memory, which contains the mapping of some data pages in the disk, and serves as a buffer for accessing the database. When requesting to read data, it will first judge whether it is hit in the buffer pool, and if it is not hit, it will be retrieved on the disk and put into the buffer pool. When requesting to write data, it will be written to the buffer pool first, and the modified data in the buffer pool will be periodically refreshed to the disk. This process is also known as brushing.
When the data is modified, in addition to modifying the data in the buffer pool, the operation will also be recorded in the redo log. When the transaction is committed, the data will be flushed according to the records of the redo log. If MySQL crashes, the data in the redo log can be read when restarting to restore the database, thereby ensuring the durability of transactions and enabling the database to obtain crash-safe capabilities.
In addition to the disk flushing of dirty data mentioned above, in fact, when the redo log is recorded, in order to ensure the persistence of the log file, it is also necessary to go through the process of writing the log records from the memory to the disk. The redo log log can be divided into two parts, one is the cache log redo log buffer stored in volatile memory, and the other is the redo log log file saved on the disk redo log file.
In order to ensure that each record can be written to the log on the disk, the fsync operation of the operating system will be called every time the log in the redo log buffer is written to the redo log file (fsync function: included in the UNIX system header In the file #include, it is used to synchronize all modified file data in memory to the storage device). In the process of writing, it also needs to go through the os buffer of the operating system kernel space.

Then why is it necessary to refresh the redo log to the disk every time a transaction is committed, instead of directly flushing the dirty pages in the buffer pool to the disk?
Because in business operations, we generally read and write disks randomly instead of sequentially. The redo log writes data to the disk file. Since it is a log file, it is written sequentially. Sequential writes are much more efficient than random writes. This way of writing logs first is called WAL (Write-Ahead Logging)
InnoDB and MVCC
MVCC only works under the two isolation levels of READ COMMITTED and REPEATABLE READ. The other two isolation levels are not compatible with MVCC, because READ UNCOMMITTED always reads the latest data row, not the data row that conforms to the current transaction version. SERIALIZABLE will lock all rows read.
3.3 undo log
Rollback log, used to record the information before the data is modified, has two functions
- Provides rollback (guarantees atomicity of transactions)
- MVCC (Multi-Version Concurrency Control)
The undo log is different from the physical log redo log. It is a logical log. It can be considered that when a record is deleted, a corresponding insert record will be recorded in the undo log, and vice versa. When a record is updated, it will record an opposite When the update record is rolled back, the corresponding content can be read from the logical records in the undo log for rollback.
Undo log destruction : The undo log is generated when the transaction is executed, and the undo log will not be deleted immediately when the transaction is committed, because these logs may also be used by MVCC.
Undo log storage : undo log is recorded in segments. Each undo operation occupies an undo log segment when recording. In addition, undo log will also generate redo log, because undo log also needs to achieve persistence Protect.
The innodb storage engine adopts a segmented approach to undo management. **rollback segment is called a rollback segment, and there are 1024 undo log segments in each rollback segment
In previous versions, only one rollback segment was supported, so only 1024 undo log segments could be recorded. Later, MySQL5.5 can support 128 rollback segments, that is, support 128*1024 undo operations, and you can also customize the number of rollback segments through the variable innodb_undo_logs (the variable was innodb_rollback_segments before version 5.6), and the default value is 128.
The undo log is stored in the shared tablespace by default.
references:
Four MVCCs
4.1 Basic concepts
It is multi-version concurrency control. MVCC is a concurrency control method, generally in the database management system, to achieve concurrent access to the database.
Why do you need MVCC? Databases typically use locks to achieve isolation. The most primitive lock, locking a resource will prevent any other thread from accessing the same resource. However, a feature of many applications is the scenario of more reads and less writes. The number of reads of a lot of data is much greater than the number of modifications, and the mutual exclusion of read data is not necessary. Therefore, a read-write lock method is used. Read locks and read locks are not mutually exclusive, while write locks, write locks, and read locks are mutually exclusive. This greatly improves the concurrency capability of the system. Later, people found that concurrent reading was not enough, and proposed a method to prevent conflicts between reading and writing, which is to save the data in a way similar to snapshots when reading data, so that the read lock does not conflict with the write lock. Yes, different transaction sessions will see their own specific version of the data. Of course, snapshot is a conceptual model, and different databases may implement this function in different ways.
4.1.1 Current read
What is read is the latest version of the record. When reading, it must be ensured that other concurrent transactions cannot modify the current record, and the read record will be locked. For our daily operations, such as: select ... lock in share mode (shared lock), select ... for update, update, insert, delete (exclusive lock) are all current reads.
Suppose you want to update a record, but another transaction has already deleted this data and committed it. If you don’t lock it, there will be a conflict. Therefore, when updating, it must be currently read, get the latest information and lock the corresponding records.
references:
Current reading of MySQL - short book
4.1.2 Snapshot read
A simple select (without locking) is a snapshot read, a snapshot read, which reads the visible version of the recorded data, which may be historical data, without locking, and is a non-blocking read.
- Read Committed: Every time you select, a snapshot read is generated.
- Repeatable Read: After the transaction is started, the first select statement is where the snapshot is read.
- Serializable: snapshot read will degenerate into current read
4.1.3 MVCC
The full name is Multi-Version Concurrency Control, multi-version concurrency control. Refers to maintaining multiple versions of a data, so that there is no conflict in read and write operations. Snapshot read provides a non-blocking read function for MySQL to implement MVCC. The specific implementation of MVCC also needs to rely on three implicit fields in the database record, undo log log, and readView.
4.2 Hidden fields
When we created the above table, we can see these three fields explicitly when we look at the table structure. In fact, in addition to these three fields, InnoDB will automatically add three hidden fields to us and their meanings are:
| hidden field |
meaning |
| DB_TRX_ID |
Recently modified transaction ID, the transaction ID of the record inserted into this record or the last modification of this record |
| DB_ROLL_PTR |
Rollback pointer, pointing to the previous version of this record, used to cooperate with undo log, pointing to the previous version. |
| DB_ROW_ID |
Hidden primary key, if the table structure does not specify a primary key, this hidden field will be generated. |
The first two fields mentioned above will definitely be added. Whether to add the last field DB_ROW_ID depends on whether the current table has a primary key. If there is a primary key, the hidden field will not be added
4.3 undo log
When inserting, the generated undo log is only needed for rollback, and can be deleted immediately after the transaction is committed. During update and delete, the generated undo log is not only needed when rolling back, but also when reading snapshots, and will not be deleted immediately
version chain
There is a table with raw data:

DB_TRX_ID: Represents the latest modification transaction ID, which is the transaction ID of the record inserted into this record or the last modification of the record, which is self-incrementing.
DB_ROLL_PTR: Since this piece of data is just inserted and has not been updated, the value of this field is null.
Then, there are four concurrent transactions accessing this table at the same time

When transaction 2 executes the first modification statement, it will record the undo log log, recording the appearance before the data change; then update the record, and record the transaction ID of this operation, the rollback pointer, and the rollback pointer is used to specify if a rollback occurs Roll, which version to roll back to.

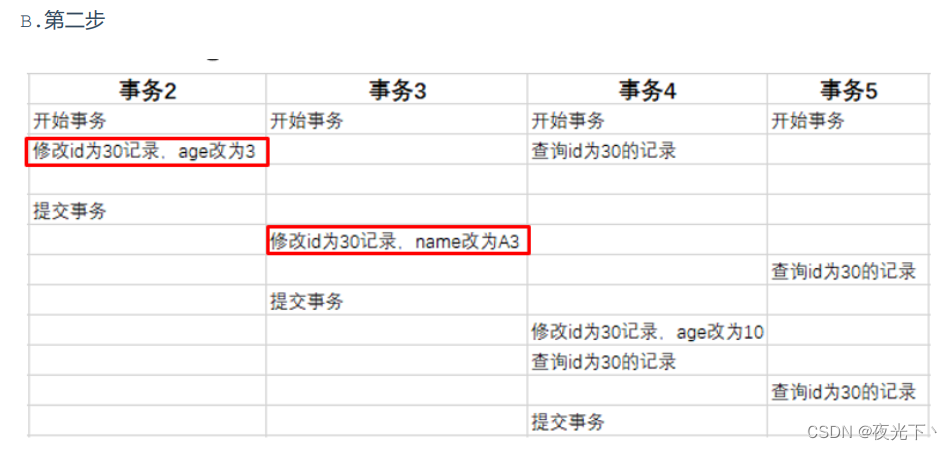
When transaction 3 executes the first modification statement, it will also record the undo log log, recording the appearance before the data change; then update the record, and record the transaction ID of this operation, the rollback pointer, and the rollback pointer is used to specify if Roll back, which version to roll back to


When transaction 4 executes the first modification statement, it will also record the undo log log, recording the appearance before the data change; then update the record, and record the transaction ID of this operation, the rollback pointer, and the rollback pointer is used to specify if Roll back, which version to roll back to.

Finally, we found that if different transactions or the same transaction modify the same record, the undolog of the record will generate a record version linked list. The head of the linked list is the latest old record, and the tail of the linked list is the earliest old record.
4.4 ReadView
ReadView (read view) is the basis for MVCC to extract data when snapshot read SQL is executed, and records and maintains the currently active transaction (uncommitted) id of the system. ReadView contains four core fields:
| field |
meaning |
| m_ids |
The set of currently active transaction IDs |
| my_trx_id |
Minimum active transaction ID |
| max_trx_id |
Pre-allocated transaction ID, the current maximum transaction ID+1 (because the transaction ID is self-incrementing) |
| creator_trx_id |
The transaction ID of the creator of the ReadView |
In readview, the access rules of the version chain data are stipulated: trx_id represents the transaction ID corresponding to the current undolog version chain.
| condition |
is it accessible |
illustrate |
| trx_id ==creator_trx_id |
can access this version |
Established, indicating that the data is changed by the current transaction. |
| trx_id < min_trx_id |
can access this version |
Established, indicating that the data has been submitted. |
| trx_id > max_trx_id |
Can't access this version |
Established, indicating that the transaction is opened after ReadView is generated. |
| my_trx_id |
If trx_id is not in m_ids, it is possible to access this version |
Established, indicating that the data has been submitted. |
Different isolation levels have different timings for generating ReadView:
- READ COMMITTED : A ReadView is generated every time a snapshot read is performed in a transaction.
- REPEATABLE READ: A ReadView is generated only when the snapshot read is executed for the first time in a transaction, and the ReadView is subsequently reused.
References (the second must read):
Understanding Mysql MVCC in one article Develop Paper
The correct way to open MVCC in MySQL (source code evidence)_Waves___'s Blog-CSDN Blog
MySQL :: MySQL 5.7 Reference Manual :: 14.3 InnoDB Multi-Versioning
4.5 Principle Analysis
4.5.1 RC isolation level
Under the RC isolation level, a ReadView is generated every time a snapshot read is performed in a transaction .
Let's analyze how to get the data by reading and reading the data twice in transaction 5? In transaction 5, the record with id 30 is queried twice. Since the isolation level is Read Committed, snapshot reading is performed each time. A ReadView will be generated, then the ReadView generated twice is as follows.
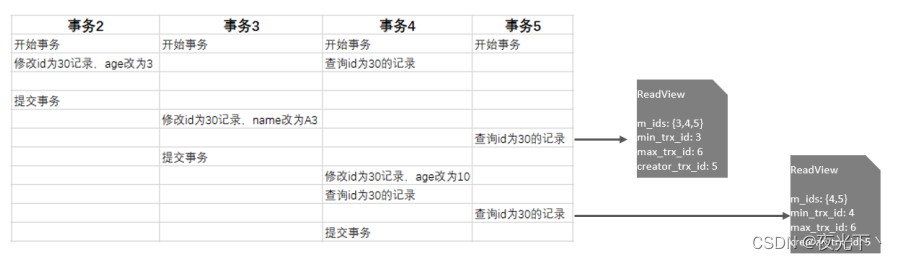
Then, when these two snapshot reads acquire data, they need to match the data in the undolog version chain according to the generated ReadView and ReadView version chain access rules, and finally determine the data returned by this snapshot read.
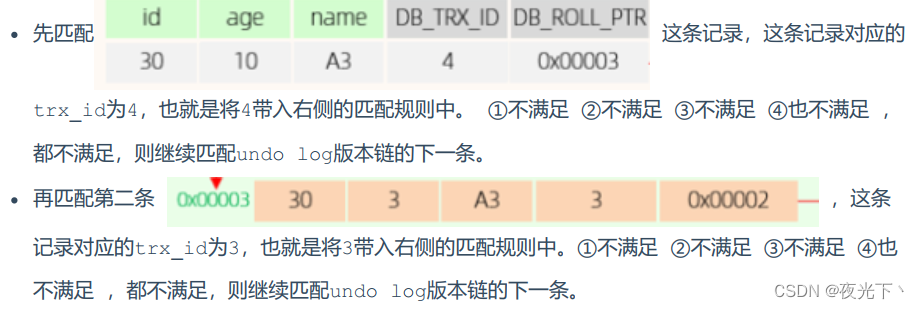
A. First look at the specific reading process of the first snapshot read:

When matching, the undo log version chain will be matched one by one from top to bottom:

B. Look at the specific reading process of the second snapshot read:

When matching, the undo log version chain will be matched one by one from top to bottom:

4.5.2 RR isolation level
Under the RR isolation level, a ReadView is generated only when the snapshot read is executed for the first time in a transaction, and the ReadView is subsequently reused. And RR is repeatable read. In a transaction, the same select statement is executed twice, and the result of the query is the same. So how does MySQL achieve repeatable reading? We will know after a brief analysis

We have seen that under the RR isolation level, the ReadView is only generated during the first snapshot read in the transaction, and the ReadView is reused later. Since the ReadViews are all the same, the version chain matching rules of the ReadView are also the same, then the final snapshot read The returned result is also the same.
Therefore, the realization principle of MVCC is realized through the hidden field of InnoDB table, UndoLog version chain, and ReadView. The MVCC + lock realizes the isolation of transactions. The consistency is guaranteed by redolog and undolog.