Click the card below to follow the " CVer " official account
AI/CV heavy dry goods, delivered in the first time
Click to enter —>【Computer Vision】WeChat Technology Exchange Group
In the early morning of February 28, 2023, the acceptance results of the CVPR 2023 top conference papers will be released! This time, I did not release the paper ID list first, but directly emailed the author (friends in the circle of friends posted screenshots one after another, announcing the good news ~ have you been swiped?!).
The main committee of CVPR 2023 officially released the acceptance data for this paper: 9,155 valid submissions (12% more than CVPR 2022), 2,360 were included (only 2,145 were submitted in CVPR 2016), and the acceptance rate was 25.78% .

The CVPR 2023 conference will be held in Vancouver, Canada from June 18th to 22nd, 2023 . The number of offline participants this time will definitely be much more than last year, because there will be a large wave of domestic scholars participating in academic exchanges offline (public travel busi).

Amusi simply predicts that the number of work related to " diffusion models, multimodality, pre-training, and MAE " in the work included in CVPR 2023 will increase significantly.
This article quickly sorts out 10 latest works of CVPR 2023, the contents are as follows. If you want to keep learning about more updated CVPR 2023 papers and codes, you can pay attention to CVPR2023-Papers-with-Code, reply in the background of CVer public account: CVPR2023 , you can download it, the link is as follows:
https://github.com/amusi/CVPR2023-Papers-with-Code
This project started in 2020, with a total of 600+ submissions! The number of Stars has exceeded 10,000+! Covering the thesis work of CVPR 2020-2023, I am very happy to help some students.
If your CVPR 2023 paper is accepted, please submit issues~
Backbone
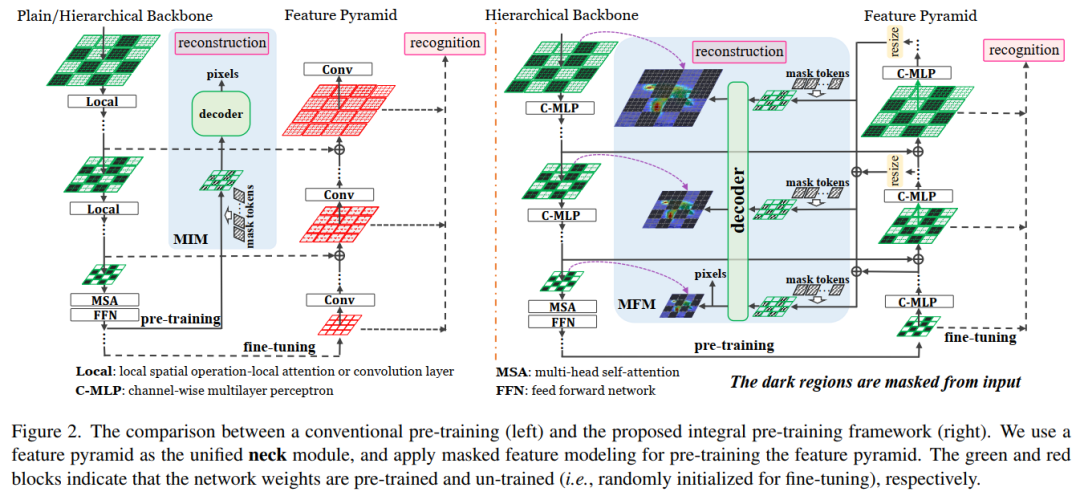
1. Integrally Pre-Trained Transformer Pyramid Networks
Unit: UCAS, Huawei, Pengcheng Laboratory
Paper: https://arxiv.org/abs/2211.12735
Code: https://github.com/sunsmarterjie/iTPN
This paper proposes the overall pre-trained ViT pyramid network (iTPN): through the overall pre-training backbone and pyramid network, the gap of upstream pre-training and fine-tuning is reduced, and the performance is SOTA! The performance is better than CAE, ConvMAE and other networks, and the code is open source!
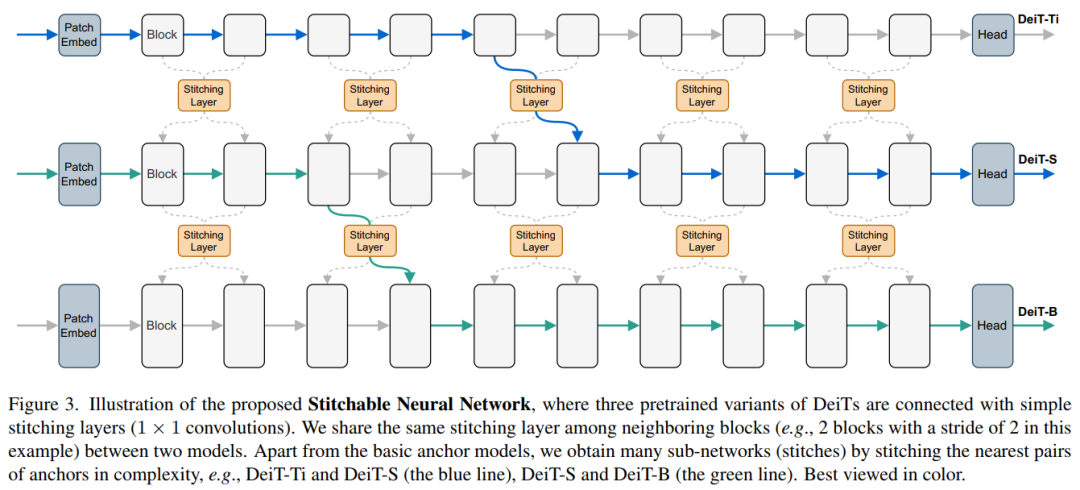
2. Stitchable Neural Networks
Unit: Monash University ZIP Lab
Homepage: https://snnet.github.io/
Paper: https://arxiv.org/abs/2302.06586
Code: https://github.com/ziplab/SN-Net
Stitchable Neural Network (SN-Net): A new scalable and efficient framework for model deployment that can rapidly generate a large number of networks with different complexity and performance trade-offs, facilitating the development of deep models for real-world applications Large-scale deployment, the code is about to open source!
THERE IS
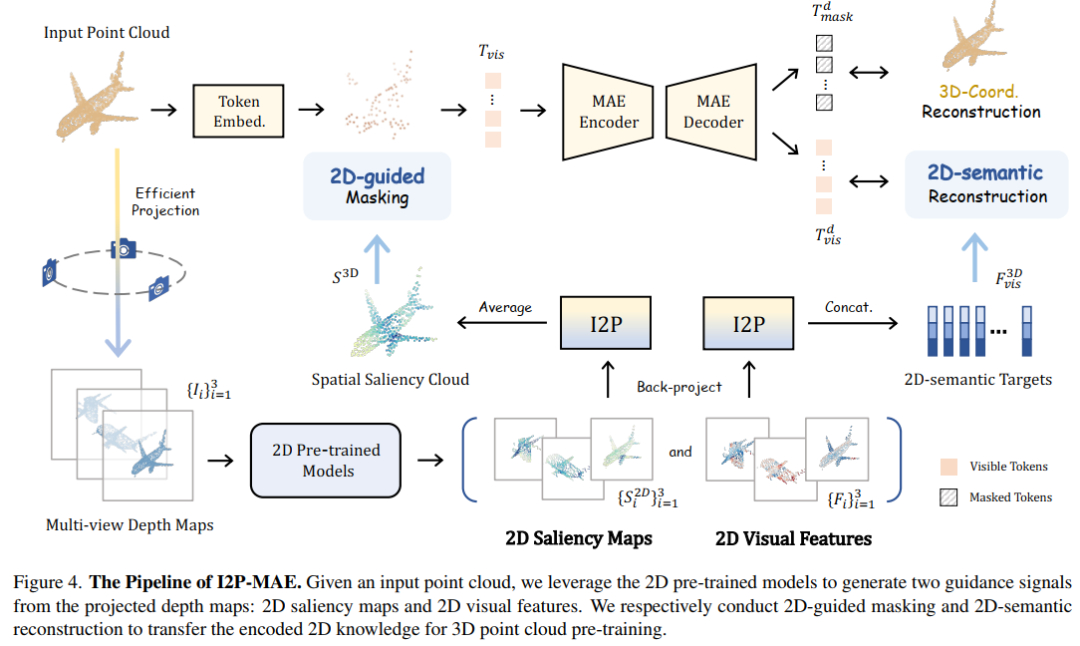
3. Learning 3D Representations from 2D Pre-trained Models via Image-to-Point Masked Autoencoders
Units: Shanghai AI Lab, CUHK MMLab, Peking University
Paper: https://arxiv.org/abs/2212.06785
Code: https://github.com/ZrrSkywalker/I2P-MAE
I2P-MAE: Image-to-Point masked autoencoder, a method for obtaining superior 3D representation from 2D pre-trained models, performing SOTA on 3D point cloud classification (refresh ModelNet40 and ScanObjectNN new records)! The performance is better than P2P, PointNeXt and other networks, and the code will be open source soon!
NeRF
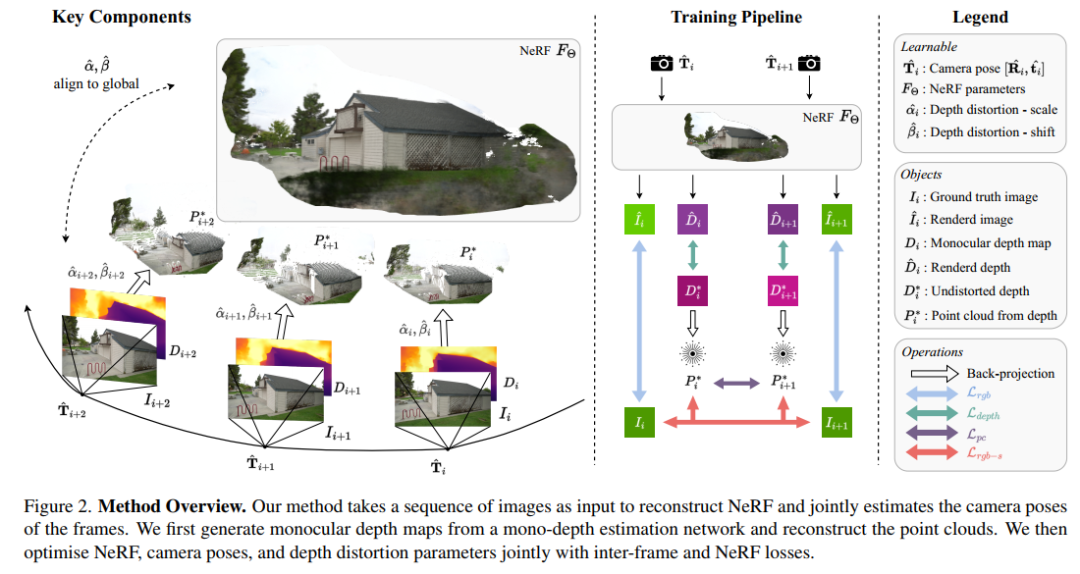
4. NoPe-NeRF: Optimising Neural Radiance Field with No Pose Prior
Unit: University of Oxford
Home: https://nope-nerf.active.vision/
Paper: https://arxiv.org/abs/2212.07388
Code: None
NoPe-NeRF: An End-to-End Differentiable Model for Joint Camera Pose Estimation and Novel View Synthesis from Image Sequences, Experiments on Real Indoor and Outdoor Scenes Show: This method is superior in novel view rendering quality and pose estimation In terms of accuracy, it outperforms existing methods.
Diffusion Models
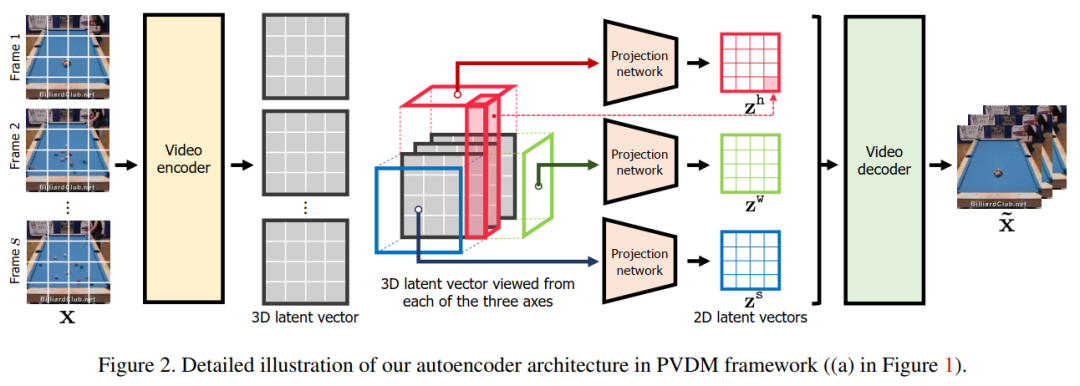
5. Video Probabilistic Diffusion Models in Projected Latent Space
Unit: KAIST, Google
Homepage: https://sihyun.me/PVDM/
Paper: https://arxiv.org/abs/2302.07685
Code: https://github.com/sihyun-yu/PVDM
PVDM is said to be the first latent diffusion model for video synthesis that learns video distributions in a low-dimensional latent space and can be efficiently trained with high-resolution videos under limited resources to synthesize videos of any length using a single model Video, code just open source! Unit: KAIST, Google
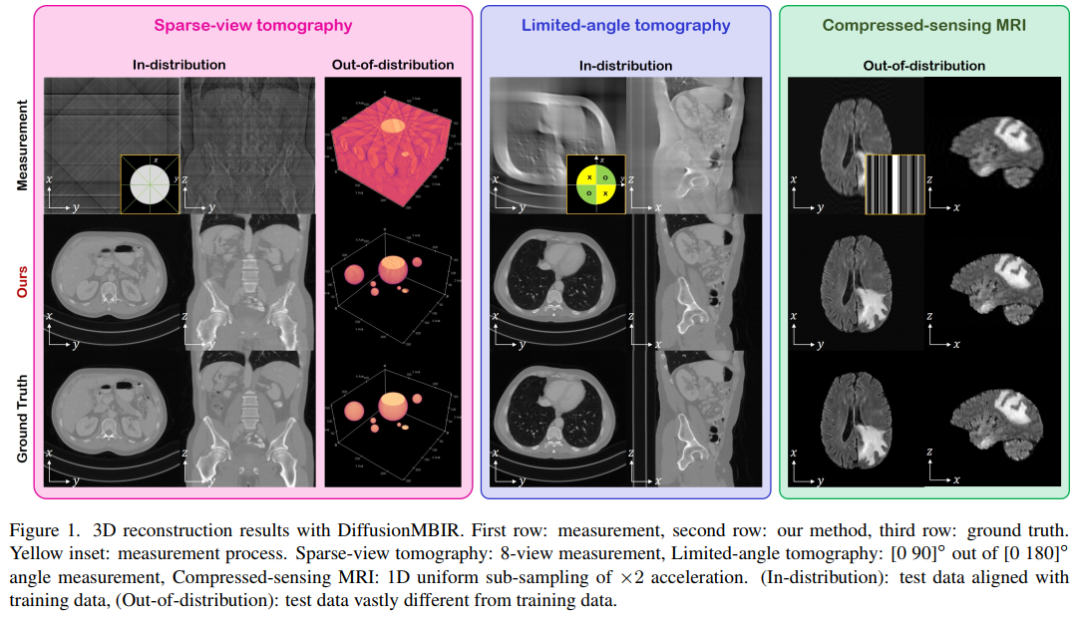
6. Solving 3D Inverse Problems using Pre-trained 2D Diffusion Models
Unit: KAIST, Los Alamos National Laboratory
Paper: https://arxiv.org/abs/2211.10655
Code: None
This paper proposes DiffusionMBIR: a diffusion model reconstruction strategy for 3D medical image reconstruction, which is demonstrated experimentally to achieve state-of-the-art reconstruction for sparse-view CT, limited-angle CT, and compressed-sensing MRI.
Vision and Language (Vision-Language)
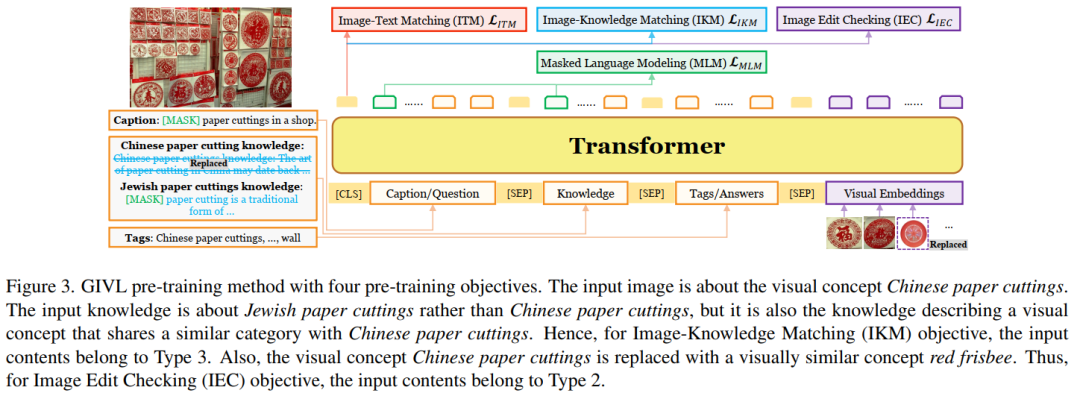
7. GIVL: Improving Geographical Inclusivity of Vision-Language Models with Pre-Training Methods
Unit: UCLA, Amazon Alexa AI
Paper: https://arxiv.org/abs/2301.01893
Code: None
This paper proposes GIVL: a geo-inclusive vision and language pre-training model that achieves state-of-the-art and more balanced performance on geographically diverse V&L tasks.
Object Detection
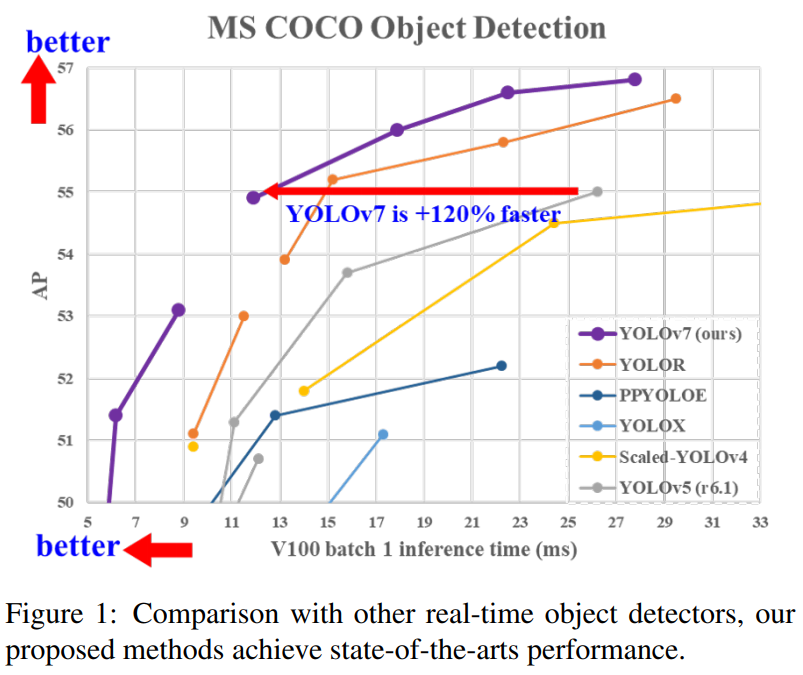
8. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors
Unit: YOLOv4 original crew
Paper: https://arxiv.org/abs/2207.02696
Code: https://github.com/WongKinYiu/yolov7
Surpass YOLOv5, YOLOX, PPYOLOE, YOLOR and other target detection networks!
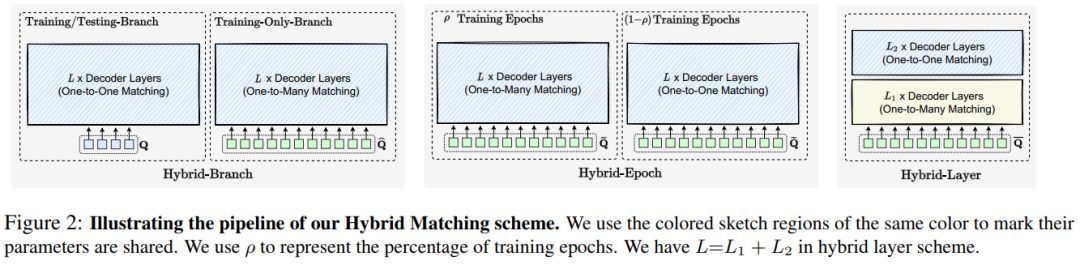
9. DETRs with Hybrid Matching
Units: Peking University, University of Science and Technology of China, Zhejiang University, MSRA
Paper: https://arxiv.org/abs/2207.13080
Code: https://github.com/HDETR
This paper proposes a very simple and effective hybrid matching scheme to solve the low training efficiency of DETR-based methods on various vision tasks (2D/3D object detection, pose estimation, etc.) and improve accuracy, such as boosting PETRv2, Network performance improvements such as TransTrack and deformable DETR, the code has been open sourced!
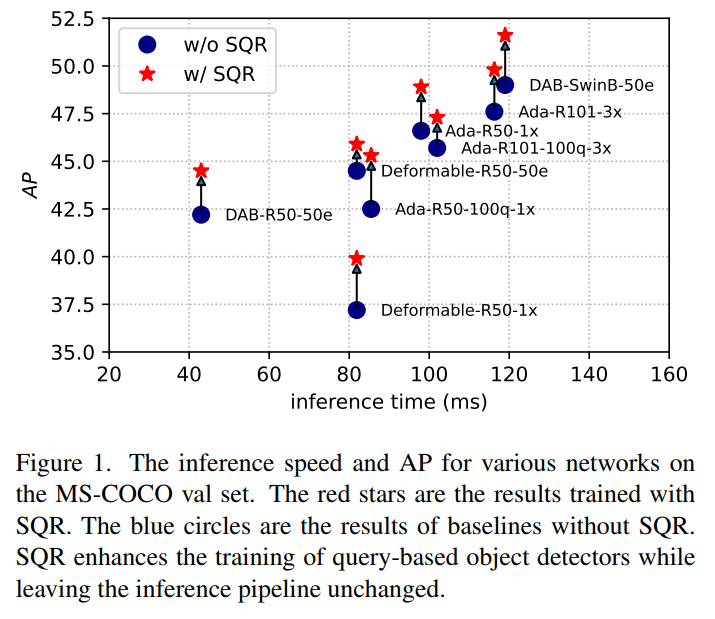
10. Enhanced Training of Query-Based Object Detection via Selective Query Recollection
Unit: CMU, Meta AI
Paper: https://arxiv.org/abs/2212.07593
Code: https://github.com/Fangyi-Chen/SQR
Plug and play! This paper proposes Selective Query Recall (SQR): a new query-based strategy for object detector training that can be easily plugged into various DETR variants, significantly improving their performance. The code is open-sourced!
Click to enter —>【Computer Vision】WeChat Technology Exchange Group
The latest CVPP 2023 papers and code download
Background reply: CVPR2023, you can download the collection of CVPR 2023 papers and code open source papers
Background reply: Transformer review, you can download the latest 3 Transformer review PDFs
目标检测和Transformer交流群成立
扫描下方二维码,或者添加微信:CVer333,即可添加CVer小助手微信,便可申请加入CVer-目标检测或者Transformer 微信交流群。另外其他垂直方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch、TensorFlow和Transformer等。
一定要备注:研究方向+地点+学校/公司+昵称(如目标检测或者Transformer+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群
▲扫码或加微信号: CVer333,进交流群
CVer学术交流群(知识星球)来了!想要了解最新最快最好的CV/DL/ML论文速递、优质开源项目、学习教程和实战训练等资料,欢迎扫描下方二维码,加入CVer学术交流群,已汇集数千人!
▲扫码进群
▲点击上方卡片,关注CVer公众号整理不易,请点赞和在看