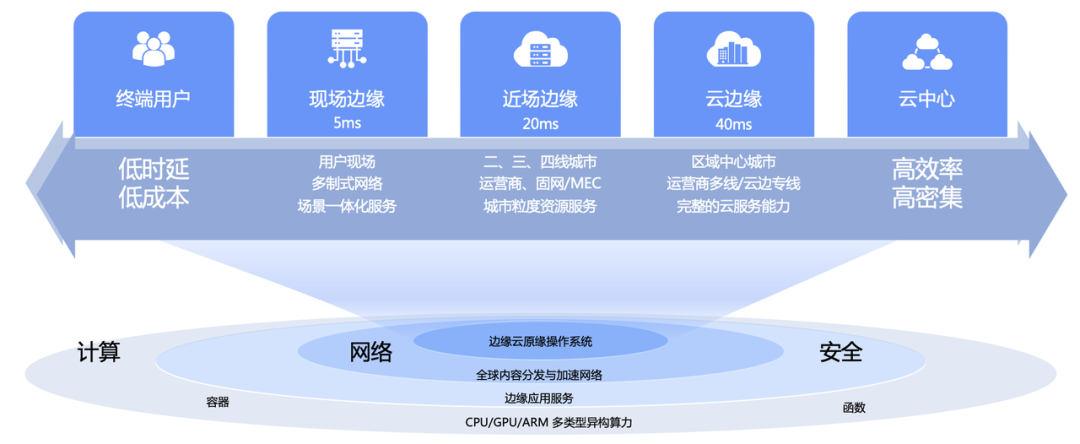
Volcano Engine Edge Cloud is a cloud computing service based on cloud computing basic technology and edge heterogeneous computing power combined with network, built on edge large-scale infrastructure, forming an edge-based computing, network, storage, security, intelligence A new generation of distributed cloud computing solutions with core capabilities.
01- Edge scene storage challenges
Edge storage is mainly for typical business scenarios that adapt to edge computing, such as edge rendering. The edge rendering of the volcano engine relies on the underlying massive computing power resources, which can help users realize the easy arrangement of millions of rendering frame queues, the scheduling of rendering tasks nearby, and the parallel rendering of multi-task and multi-node, which greatly improves the rendering. Briefly introduce the storage encountered in edge rendering question:
- It is necessary to unify the metadata of the object storage and the file system, so that after the data is uploaded through the object storage interface, it can be directly operated through the POSIX interface;
- Meet the needs of high-throughput scenarios, especially when reading;
- Fully implements the S3 interface and the POSIX interface.
In order to solve the storage problems encountered in edge rendering, the team spent nearly half a year conducting storage selection tests. Initially, the team chose the company's internal storage components, which can better meet our needs in terms of sustainability and performance. But when it comes to edge scenes, there are two specific problems:
- First of all, the company's internal components are designed for the central computer room, and there are requirements for physical machine resources and quantity, which are difficult to meet in some peripheral computer rooms;
- Secondly, the storage components of the entire company are packaged together, including: object storage, block storage, distributed storage, file storage, etc., while the edge side mainly needs file storage and object storage, which need to be tailored and transformed, and an online stable also requires a process.
After the team discussed, a feasible solution was formed: CephFS + MinIO gateway . MinIO provides object storage service, the final result is written to CephFS, and the rendering engine mounts CephFS to perform rendering operations. During the test and verification process, when the number of files reached tens of millions, the performance of CephFS began to degrade, occasionally freezing, and the feedback from the business side did not meet the requirements.
Similarly, there is another solution based on Ceph, which is to use Ceph RGW + S3FS. This solution can basically meet the requirements, but the performance of writing and modifying files does not meet the scene requirements.
After more than three months of testing, we have clarified several core requirements for storage in edge rendering:
- The operation and maintenance should not be too complicated : storage R&D personnel can get started with the operation and maintenance documents; the operation and maintenance work of later expansion and online fault handling should be simple enough.
- Data reliability : Because the storage service is directly provided to the user, the successfully written data is not allowed to be lost or inconsistent with the written data.
- Use a set of metadata and support both object storage and file storage : In this way, when the business side is using it, it does not need to upload and download files multiple times, reducing the complexity of the business side's use.
- Better performance for reading : The team needs to solve the scenario of more reading and less writing, so they hope to have better reading performance.
- Community activity : An active community can respond faster when solving existing problems and actively promoting the iteration of new functions.
After clarifying the core requirements, we found that the three previous solutions did not quite meet the needs.
02- Benefits of using JuiceFS
The Volcano Engine edge storage team learned about JuiceFS in September 2021 and had some exchanges with the Juicedata team. After communication, we decided to try it in the edge cloud scenario. The official documentation of JuiceFS is very rich and highly readable. You can learn more details by reading the documentation.
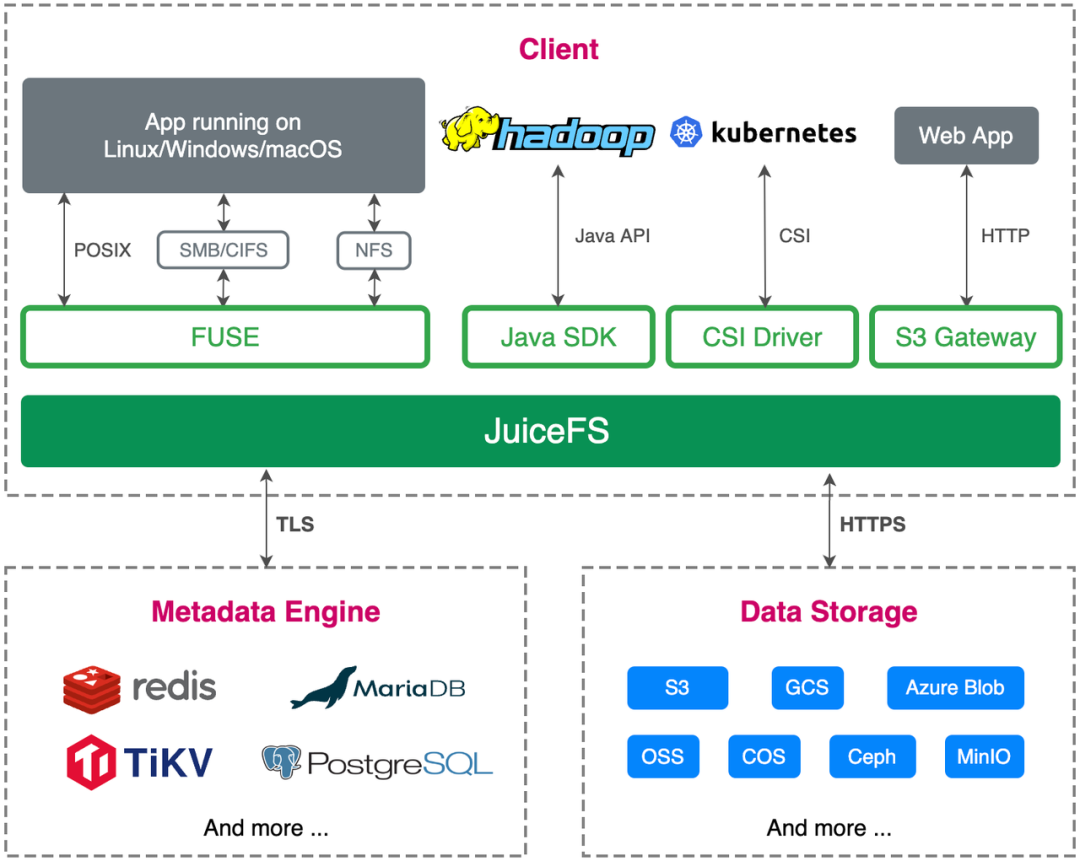
Therefore, we started to do PoC tests in the test environment, focusing on feasibility verification, complexity of O&M and deployment, and adaptation to upstream business, and whether it meets the needs of upstream business.
We deployed two sets of environments, one based on single-node Redis + Ceph , and the other based on single-instance MySQL + Ceph .
In terms of the overall environment construction, because Redis, MySQL and Ceph (deployed through Rook) are relatively mature, and the reference materials for deploying the operation and maintenance plan are relatively comprehensive. At the same time, the JuiceFS client can also connect these databases and Ceph simply and conveniently. The deployment process is very smooth.
In terms of business adaptation, the edge cloud is developed and deployed based on cloud native. JuiceFS supports the S3 API, is fully compatible with the POSIX protocol, and supports CSI mounting, which fully meets our business needs.
After comprehensive testing, we found that JuiceFS fully meets the needs of the business side and can be deployed and run in production to meet the online needs of the business side.
Benefit 1: Business Process Optimization
Before using JuiceFS, edge rendering mainly used ByteDance's internal object storage service (TOS). Users uploaded data to TOS, and the rendering engine downloaded the files uploaded by users from TOS to the local, and the rendering engine read the local files. , to generate the rendering result, and then upload the rendering result back to TOS, and finally the user downloads the rendering result from TOS. There are several links in the overall interaction process, and a lot of network and data copying are involved in the middle, so there will be network jitter or high delay in this process, which will affect the user experience.
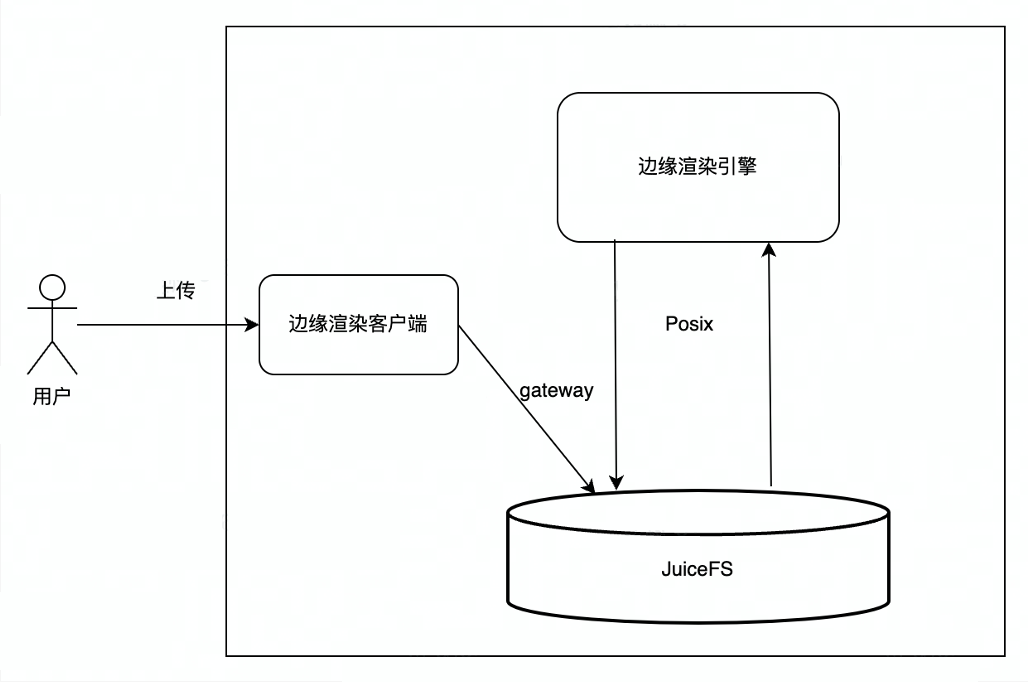
After using JuiceFS, the process becomes that the user uploads through the JuiceFS S3 gateway. Since JuiceFS realizes the unification of object storage and metadata of the file system, JuiceFS can be directly mounted to the rendering engine, and the rendering engine uses the POSIX interface to process files. Read and write, the end user directly downloads the rendering result from the JuiceFS S3 gateway, the overall process is more concise, efficient, and more stable.
Benefit 2: Acceleration of reading files and sequential writing of large files
Thanks to JuiceFS's client-side caching mechanism, we can cache frequently read files locally in the rendering engine, greatly speeding up file reading. We did a comparative test on whether to open the cache, and found that the throughput can be increased by about 3-5 times after using the cache .
Similarly, because the write model of JuiceFS is to write memory first, when a chunk (default 64M) is full, or when the application calls the forced write interface (close and fsync interface), the data will be uploaded to the object storage, and the data upload is successful After that, update the metadata engine. Therefore, when writing large files, write to memory first, and then write to disk, which can greatly improve the writing speed of large files.
At present, the usage scenarios of the edge are mainly rendering, the file system reads more and writes less, and the file writing is also mainly for large files. The requirements of these business scenarios are very consistent with the applicable scenarios of JuiceFS. After the business side replaced the storage with JuiceFS, the overall evaluation is also very high.
03- How to use JuiceFS in edge scenes
JuiceFS is mainly deployed on Kubernetes. Each node has a DaemonSet container responsible for mounting the JuiceFS file system, and then mounts it to the pod of the rendering engine in the form of HostPath. If the mount point fails, DaemonSet will take care of automatically restoring the mount point.
In terms of authority control, the edge storage uses the LDAP service to authenticate the identity of the JuiceFS cluster nodes, and each node of the JuiceFS cluster is authenticated by the LDAP client and the LDAP service.
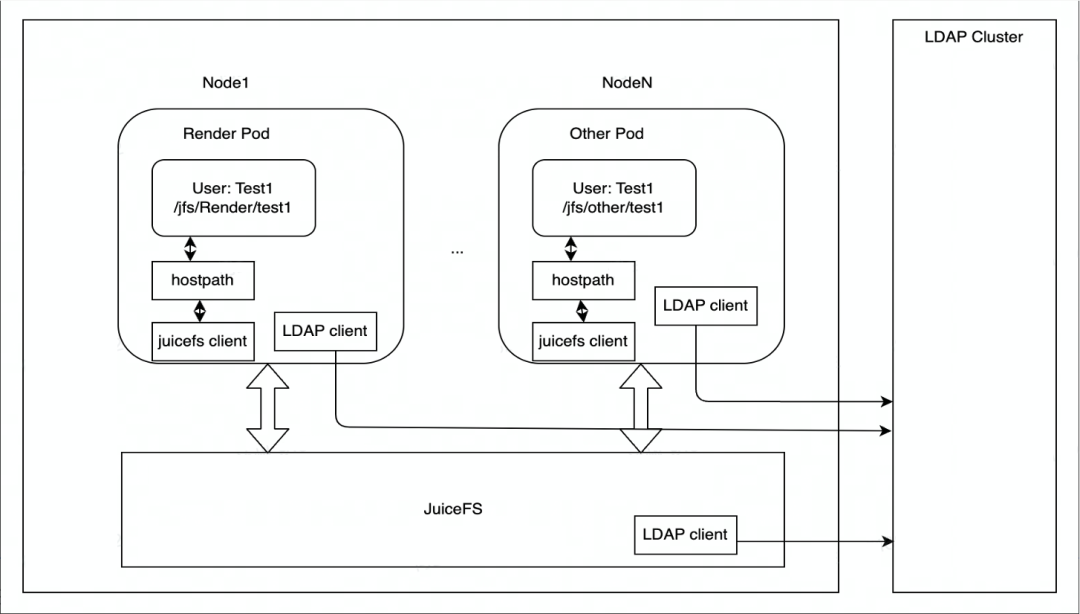
Our current application scenarios are mainly based on rendering, and will be expanded to more business scenarios in the future. In terms of data access, edge storage is currently accessed mainly through HostPath. If there is a need for elastic expansion in the future, JuiceFS CSI Driver will be considered for deployment.

04- Practical experience in production environment
metadata engine
JuiceFS supports a lot of metadata engines (such as MySQL, Redis), and the edge storage production environment of the volcano engine uses MySQL . After evaluating the scale of the data volume and number of files (the number of files is in the tens of millions, probably tens of millions, the scenario of more reads and fewer writes), as well as the write and read performance, we found that MySQL is in operation and maintenance, data reliability, And the business side has done better.
MySQL currently adopts two deployment schemes: single instance and multi-instance (one master and two slaves), which can be flexibly selected for different scenarios at the edge. In an environment with few resources, a single instance can be used for deployment, and the throughput of MySQL is relatively stable within a given range. Both of these deployment schemes use high-performance cloud disks (provided by Ceph clusters) as MySQL data disks, which can ensure that MySQL data will not be lost even in single-instance deployments.
In scenarios with abundant resources, multiple instances can be used for deployment. The master-slave synchronization of multiple instances is realized through the orchestrator component provided by MySQL Operator ( https://github.com/bitpoke/mysql-operator) . It is considered OK only if two slave instances are successfully synchronized, but a timeout period is also set. If the synchronization is not completed after the timeout expires, it will return success and an alarm will be issued. After the later disaster recovery plan is completed, the local disk may be used as the data disk of MySQL to further improve read and write performance, reduce latency and increase throughput.
MySQL single instance configuration container resources:
- CPU:8C
- Memory: 24G
- Disk: 100G (based on Ceph RBD, metadata occupies about 30G disk space in the scenario of storing tens of millions of files)
- Container image: mysql:5.7
MySQL my.cnfconfiguration :
ignore-db-dir=lost+found # 如果使用 MySQL 8.0 及以上版本,需要删除这个配置
max-connections=4000
innodb-buffer-pool-size=12884901888 # 12G
object storage
The object storage uses a self-built Ceph cluster , which is deployed through Rook. The current production environment uses the Octopus version. With Rook, Ceph clusters can be operated and maintained in a cloud-native manner, and Ceph components can be managed and controlled through Kubernetes, which greatly reduces the complexity of Ceph cluster deployment and management.
Ceph server hardware configuration:
- 128 nuclear CPU
- 512GB RAM
- System disk: 2T * 1 NVMe SSD
- Data disk: 8T * 8 NVMe SSD
Ceph server software configuration:
- OS: Debian 9
- Kernel: Modify /proc/sys/kernel/pid_max
- Ceph version: Octopus
- Ceph storage backend: BlueStore
- Number of Ceph replicas: 3
- Turn off the automatic adjustment function of the placement group
The main focus of edge rendering is low latency and high performance, so in terms of server hardware selection, we configure the cluster with NVMe SSD disks. Other configurations are mainly based on the version maintained by the volcano engine, and the operating system we choose is Debian 9. For data redundancy, three copies are configured for Ceph. In an edge computing environment, EC may be unstable due to resource constraints.
JuiceFS client
The JuiceFS client supports direct connection to Ceph RADOS (better performance than Ceph RGW), but this function is not enabled by default in the official binary, so the JuiceFS client needs to be recompiled. You need to install librados before compiling. It is recommended that the librados version correspond to the Ceph version. Debian 9 does not have a librados-dev package that matches the Ceph Octopus (v15.2.*) version, so you need to download the installation package yourself.
After installing librados-dev, you can start compiling the JuiceFS client. We use Go 1.19 to compile here. In 1.19, the feature of controlling the maximum memory allocation ( https://go.dev/doc/gc-guide#Memory_limit) is added , which can prevent the JuiceFS client from taking up too much in extreme cases. OOM occurs due to more memory.
make juicefs.ceph
After compiling the JuiceFS client, you can create a file system and mount the JuiceFS file system on the computing node. For detailed steps, please refer to the official JuiceFS documentation.
05- Future and outlook
JuiceFS is a distributed storage system product in the cloud-native field. It provides a CSI Driver component that can support cloud-native deployment methods very well. It provides users with very flexible choices in terms of operation and maintenance deployment. Users can choose cloud , You can also choose privatized deployment, which is relatively simple in terms of storage expansion and operation and maintenance. It is fully compatible with the POSIX standard, and uses the same set of metadata as S3, which makes it very convenient to carry out the operation process of uploading, processing, and downloading. Because its back-end storage is an object storage feature, there is a high delay in reading and writing random small files, and the IOPS is relatively low . For scenarios with more writing and less, JuiceFS has a relatively large advantage, which is very suitable for the business needs of edge rendering scenarios .
The future plans of the Volcano Engine edge cloud team related to JuiceFS are as follows:
- More cloud-native : JuiceFS is currently used in the form of HostPath. Later, considering some elastic scaling scenarios, we may switch to using JuiceFS in the form of CSI Driver;
- Metadata engine upgrade : Abstract the gRPC service of a metadata engine, which provides multi-level caching capabilities to better adapt to scenarios with more reads and fewer writes. The underlying metadata storage may consider migrating to TiKV to support a larger number of files. Compared with MySQL, it can better increase the performance of the metadata engine through horizontal expansion;
- New functions and bug fixes : For the current business scenario, some functions will be added and some bugs will be fixed, and we expect to contribute PR to the community and give back to the community.
If you are helpful, please pay attention to our project Juicedata/JuiceFS ! (0ᴗ0✿)