What is a file system
When it comes to file systems, most people are unfamiliar. But each of us uses the file system almost every day. For example, when you open Windows, macOS or Linux, whether you use Explorer or Finder, you are dealing with the file system. If you have installed the operating system by yourself, there must be a step in the first installation, which is to format the disk. When formatting, you need to choose which file system the disk needs to use.

The definition of a file system on Wikipedia is:
In computing, file system is a method and data structure that the operating system uses to control how data is stored and retrieved.
In short, a file system manages data on some kind of physical storage medium (such as disk, SSD, CD, tape, etc.) . The most basic concepts in the file system are files and directories. All data corresponds to a file, and the data is managed and organized in a tree structure through directories. Based on the organizational structure of files and directories, some more advanced configurations can be performed, such as configuring permissions for files, counting file sizes, modification times, and limiting the upper limit of file system capacity, etc.
Some of the more common file systems in different operating systems are listed below:
- Linux:ext4、XFS、Btrfs
- Windows:NTFS、FAT32
- macOS:APFS、HFS+
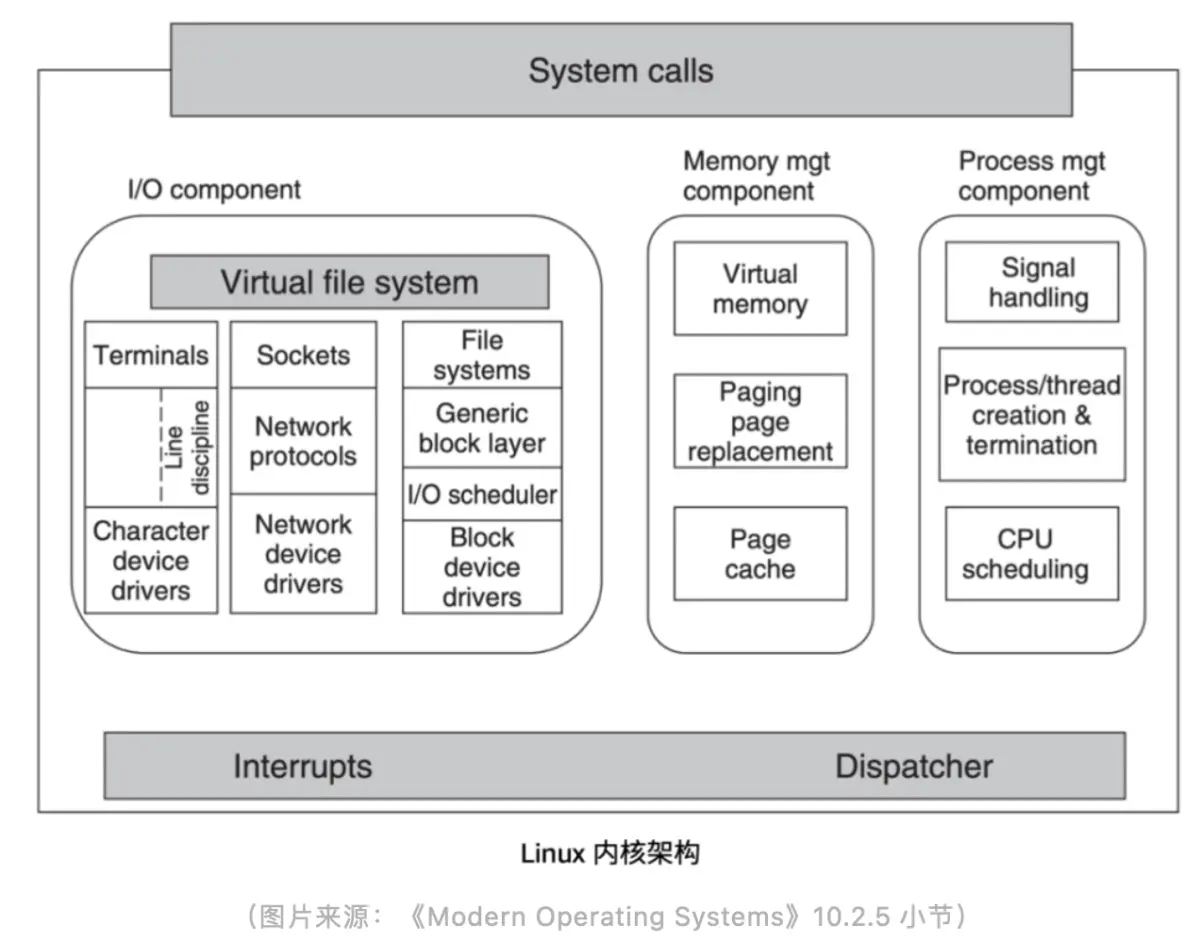
The picture above is the architecture of the Linux kernel, the Virtual file system area on the left, which is the virtual file system referred to as VFS. Its function is designed to help Linux adapt to different file systems. VFS provides a common file system interface, and different file system implementations need to adapt to these interfaces.
When using Linux on a daily basis, all system call requests will first reach the VFS, and then the VFS will request the actual file system used. The designer of the file system needs to comply with the VFS interface protocol to design the file system. The interface is shared, but the specific implementation of the file system is different, and each file system can have its own implementation. Further down the file system is the storage medium, and the stored data will be organized according to different storage media.

The figure above is a request process for a write operation. Writing a file in Linux is actually a write()system call. When you call write()an operation request, it will first reach the VFS, then the VFS will call the file system, and finally the file system will write the actual data to the local storage medium.
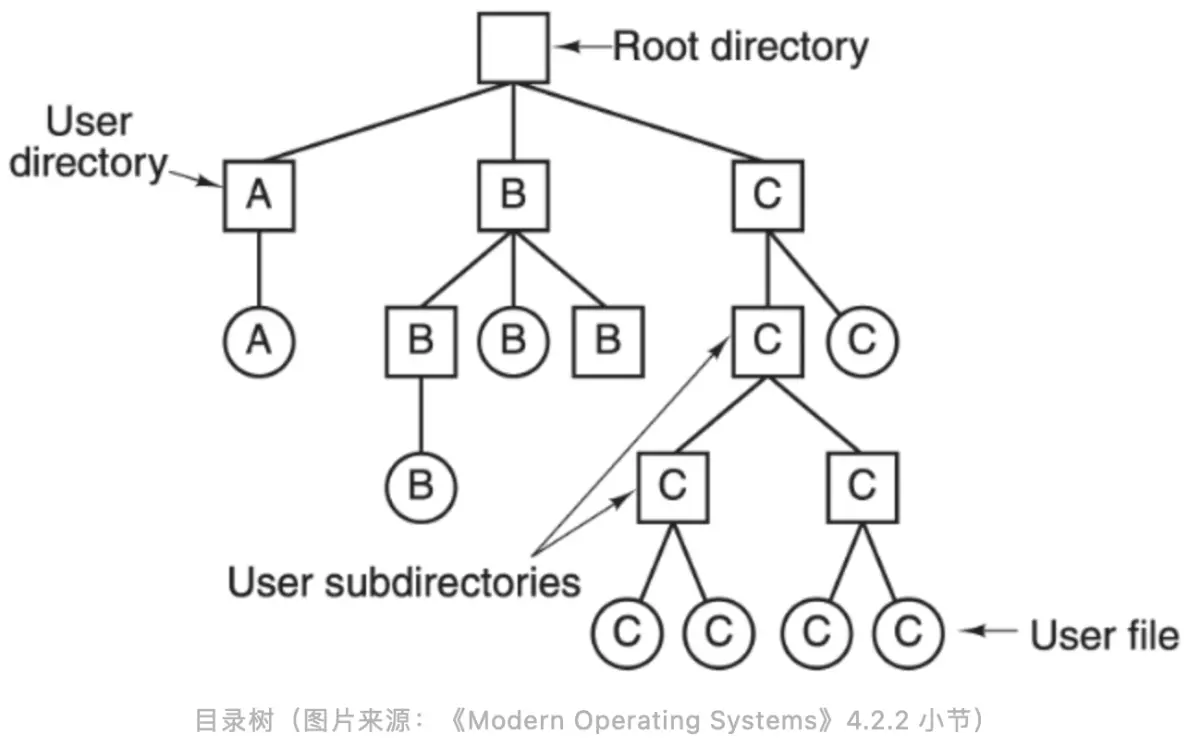
The above figure is a directory tree structure. In the file system, all data is organized in such a tree structure. From the top root node down, there are different directories and different files. The depth of this tree is uncertain, which is equivalent to the depth of the directory is uncertain, which is determined by each user. The leaf node of the tree is each file.
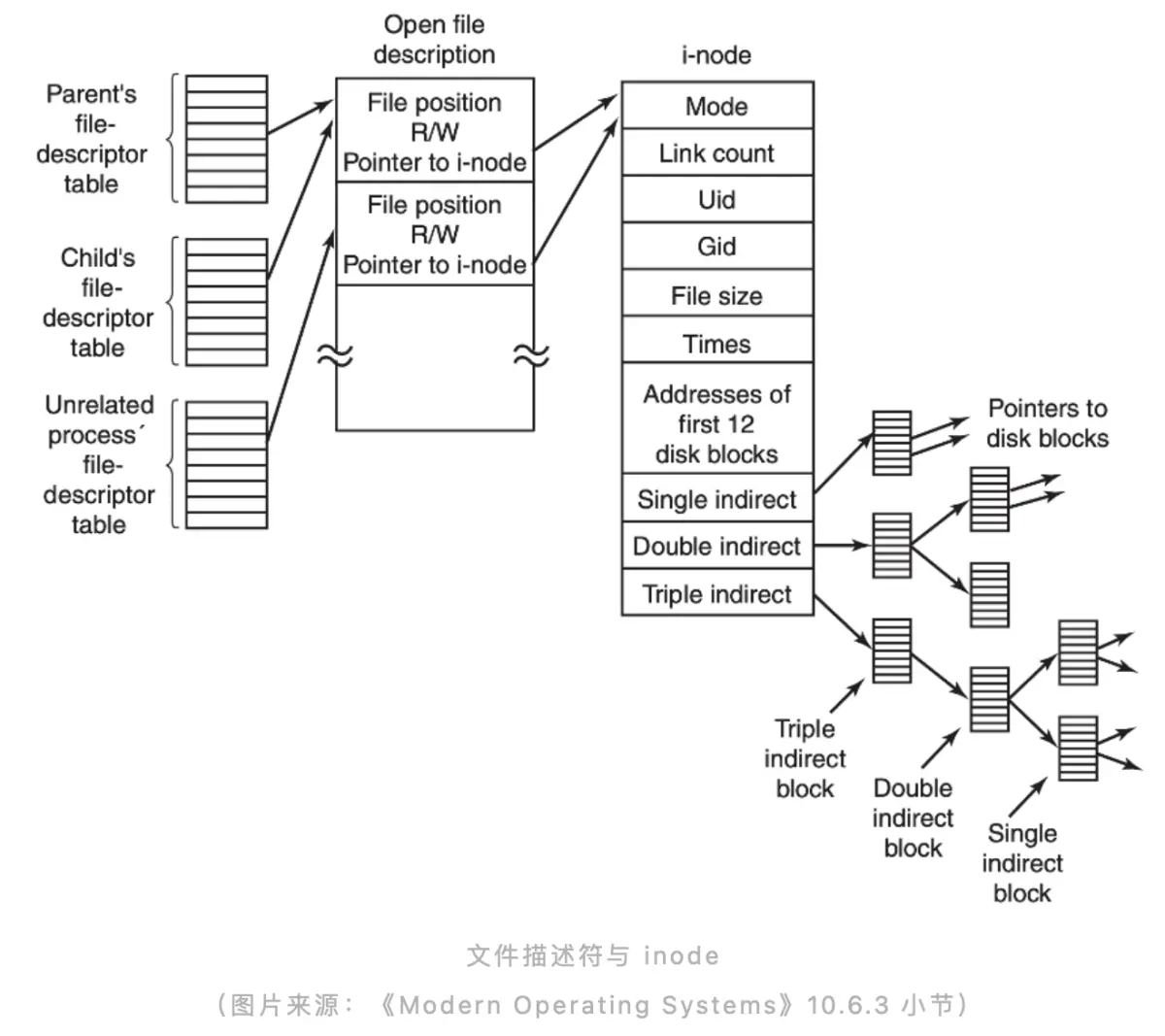
The rightmost inode is the internal data structure of each file system. This inode may be a directory, or it may be an ordinary file. Inode will contain some meta information about the file, such as creation time, creator, which group it belongs to, permission information, file size, etc. In addition, there will be some pointers or indexes pointing to data blocks on the actual physical storage medium in each inode. The above are some data structures and processes that may be involved when actually accessing a stand-alone file system. As an introduction, let everyone have a more intuitive understanding of the file system.
Distributed file system architecture design
The stand-alone file system has been able to meet the needs of most of our usage scenarios and manage a lot of data that needs to be stored on a daily basis. However, with the development of the times and the explosive growth of data, the demand for data storage is also increasing, and the distributed file system has emerged as the times require .

The above lists some distributed file systems that everyone is relatively familiar with or uses more. There are open source file systems and closed source products used within the company. From this picture, we can see a very concentrated time point. A large number of distributed systems were born around 2000. These distributed file systems are still more or less in contact with us in our daily work. Before 2000, there were also various shared storage, parallel file systems, and distributed file systems, but they were basically built on some dedicated and expensive hardware .
Since the publication of Google's GFS (Google File System) paper in 2003, it has largely influenced the design concepts and ideas of a large number of distributed systems. GFS proves that we can use relatively cheap general-purpose computers to build a sufficiently powerful, scalable, and reliable distributed storage , and define a file system based entirely on software without relying on many proprietary or expensive hardware resources. To build a distributed storage system.
Therefore, GFS greatly lowers the threshold for using distributed file systems, so the shadow of GFS can be more or less seen in subsequent distributed file systems. For example, Yahoo's open source HDFS is basically implemented according to the GFS paper. HDFS is also the most widely used storage system in the field of big data.
"POSIX Compatible" in the fourth column above indicates the compatibility of this distributed file system with the POSIX standard. POSIX (Portable Operating System Interface) is a set of standards used to regulate the implementation of the operating system, including standards related to the file system. The so-called POSIX compatibility is to meet all the characteristics that a file system defined in this standard should have, rather than only have individual ones, such as GFS. Although it is a pioneering distributed file system, it is actually not a POSIX-compatible file. system.
Google made a lot of trade-offs when designing GFS at that time. It discarded many features of the traditional stand-alone file system and retained some distributed storage requirements for the Google search engine scene at that time . So strictly speaking, GFS is not a POSIX-compatible file system, but it gives you an inspiration, and you can also design a distributed file system in this way.
Next, I will focus on taking several relatively representative distributed file system architectures as examples to introduce to you, if you want to design a distributed file system, which components will be required and some problems that may be encountered.
GFS
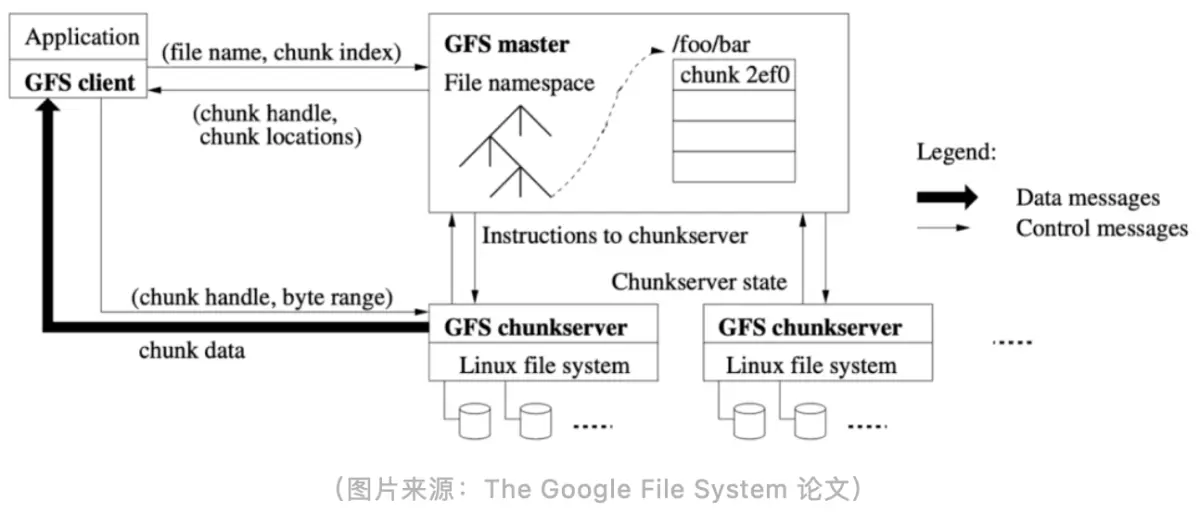
First of all, take the most mentioned GFS as an example. Although it was announced in 2003, I think its design is not outdated so far, and there are many places worth learning from. The main components of GFS can be divided into three parts. The leftmost GFS client is its client, and then the middle GFS master is its metadata node. The bottom two are GFS chunkservers, which are the actual data storage nodes. The master and chunkserver communicate through the network, so it is a distributed file system. Chunkservers can continuously scale out as the amount of data grows.
The two core parts of GFS are master and chunkserver . We want to implement a file system, whether it is stand-alone or distributed, we need to maintain information such as file directories, attributes, permissions, links, etc. These information are the metadata of a file system, and these metadata information needs to be stored in the central node master save. Master also contains a tree-structured metadata design.
When the actual application data is to be stored, it will eventually fall on each chunkserver node, and then the chunkserver will rely on the file system of the local operating system to store these files.
There are connections between the chunkserver, the master, and the client. For example, when the client initiates a request, it needs to obtain the metadata information of the current file from the master first, then communicate with the chunkserver, and then obtain the actual data. All files in GFS are stored in chunks. For example, for a large file of 1GB, GFS will divide the file into chunks according to a fixed size (64MB). After chunking, it will be distributed to different chunkservers. , so when you read the same file, it may actually involve communicating with different chunkservers.
At the same time, the chunk of each file will have multiple copies to ensure the reliability of the data. For example, if a certain chunkserver is down or its disk is broken, the security of the entire data is still guaranteed. The copy mechanism can be used to help you ensure Data reliability. This is a very classic distributed file system design. Now look at many open source distributed system implementations, which more or less have the shadow of GFS.
I have to mention here, the next generation of GFS: Colossus. Due to the obvious scalability problems in the architecture design of GFS, Google continued to develop Colossus based on GFS. Colossus not only provides storage capabilities for various products within Google, but is also open to the public as a storage base for Google cloud services. Colossus is designed to enhance storage scalability and availability to handle massively growing data demands. Tectonic, which will be introduced below, is also a storage system for benchmarking Colossus. Due to space constraints, this blog will no longer introduce Colossus. Friends who are interested can read the official blog .
Tectonic
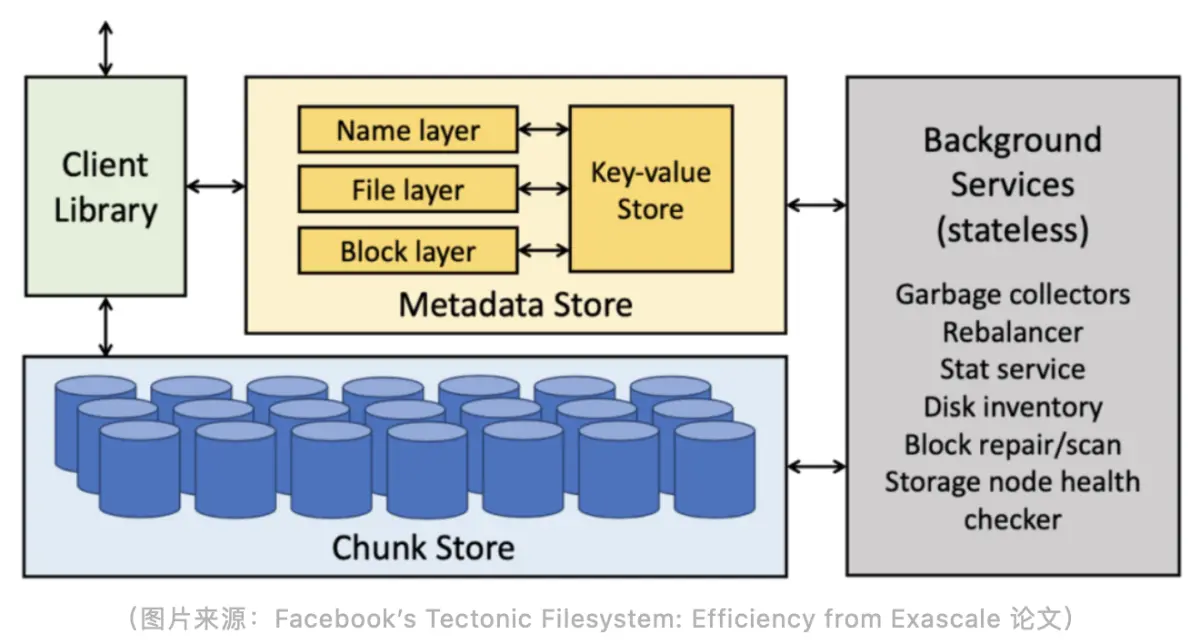
Tectonic is currently the largest distributed file system within Meta (Facebook) . The Tectonic project started around 2014 (previously called Warm Storage), but it was not until 2021 that a paper was published to introduce the architecture design of the entire distributed file system.
Before developing Tectonic, Meta mainly used HDFS, Haystack, and f4 to store data internally. HDFS was used in data warehouse scenarios (limited by the storage capacity of a single cluster, and dozens of clusters were deployed), and Haystack and f4 were used in non-structural data storage scenarios. The positioning of Tectonic is to meet the business scenario requirements of these three types of storage support in one cluster. Like GFS, Tectonic is mainly composed of three parts, namely Client Library, Metadata Store and Chunk Store .
The innovation of Tectonic lies in its layered processing at the Metadata layer and the architecture design of separation of storage and calculation . From the architecture diagram, we can see that Metadata is divided into three layers: Name layer, File layer and Block layer. Traditional distributed file systems treat all metadata as the same type of data and do not explicitly distinguish them. In Tectonic's design, the Name layer is the metadata related to the name of the file or the directory structure, the File layer is the data related to some attributes of the current file itself, and the Block layer is the metadata of each data block in the Chunk Store location.
The reason why Tectonic needs such a layered design is because it is a very large-scale distributed file system, especially at the level of Meta (EB-level data). At this scale, there are very high requirements for the load capacity and scalability of the Metadata Store .
The second innovation lies in the separation of storage and computing of metadata. The three layers mentioned above are actually stateless and can be scaled horizontally according to business load. But the Key-value Store in the above figure is a stateful storage, and the communication between the layer and the Key-value Store is through the network.
Key-value Store is not entirely developed by Tectonic itself, but uses a distributed KV storage called ZippyDB inside Meta to support metadata storage. ZippyDB is a distributed KV storage based on RocksDB and Paxos consensus algorithm. Tectonic relies on ZippyDB's KV storage and the transactions it provides to ensure the consistency and atomicity of the metadata of the entire file system.
The transaction function here is very important. If you want to implement a large-scale distributed file system, you must expand the Metadata Store horizontally. After horizontal expansion, data fragmentation is involved, but there is a very important semantic in the file system is strong consistency, such as renaming a directory, which will involve many subdirectories, how to efficiently rename at this time Directory and ensuring consistency in the renaming process is a very important point in the design of a distributed file system, and it is also a difficult point generally considered by the industry .
Tectonic's implementation relies on the transactional features of the underlying ZippyDB to ensure that file system operations must be transactional and strongly consistent when only the metadata of a single shard is involved . However, since ZippyDB does not support cross-shard transactions, Tectonic cannot guarantee atomicity when processing cross-directory metadata requests (such as moving files from one directory to another).
Tectonic also has innovations in the Chunk Store layer. As mentioned above, GFS uses multiple copies to ensure data reliability and security. The biggest disadvantage of multiple copies is its storage cost. For example, you may only store 1TB of data, but traditionally, you will keep three copies, so at least 3TB of space is required for storage, which doubles the storage cost. It may be okay for small-scale file systems, but for EB-level file systems like Meta, the three-copy design mechanism will bring very high costs, so they use EC (Erasure Code) at the Chunk Store layer, which means correction The method of deleting codes is implemented. In this way, only about 1.2 to 1.5 times the redundant space can be used to ensure the reliability and security of the entire cluster data, which saves a lot of storage costs compared to the three-copy redundancy mechanism . Tectonic's EC design is so detailed that it can be configured for each chunk, which is very flexible.
At the same time, Tectonic also supports multiple copies, depending on the storage form required by the upper-layer business. EC does not need a particularly large space to ensure the reliability of the overall data, but the disadvantage of EC is that when the data is damaged or lost, the cost of rebuilding the data is very high, and it needs to consume more computing and IO resources.
Through the paper, we know that Meta's largest Tectonic cluster currently has about 4,000 storage nodes, with a total capacity of about 1590PB and a file volume of 10 billion. This file volume is also a relatively large scale for a distributed file system. . In practice, tens of billions can basically meet most of the current usage scenarios .

Let's take a look at the layer design in Tectonic. The three layers Name, File, and Block actually correspond to the data structure in the underlying KV storage, as shown in the figure above. For example, the Name layer uses the directory ID as the key for sharding, the File layer uses the file ID for sharding, and the Block layer uses the block ID for sharding.
Tectonic abstracts the metadata of the distributed file system into a simple KV model, which can be very good for horizontal expansion and load balancing, and can effectively prevent hot spots in data access.
JuiceFS
JuiceFS was born in 2017, later than GFS and Tectonic. Compared with the birth of the first two systems, the external environment has undergone tremendous changes.
First of all, hardware resources have developed by leaps and bounds. As a comparison, the network bandwidth of the Google computer room was only 100Mbps (data source: The Google File System paper), but now the network bandwidth of the machine on AWS has reached 100Gbps, which is 1000 times that of the year. !
Secondly, cloud computing has entered the mainstream market. Whether it is public cloud, private cloud or hybrid cloud, enterprises have entered the "cloud era". The cloud era has brought new challenges to the infrastructure architecture of enterprises. Once the traditional infrastructure designed based on the IDC environment wants to go to the cloud, it may face various problems. How to maximize the advantages of cloud computing is a necessary condition for infrastructure to better integrate into the cloud environment, and sticking to the old rules will only get twice the result with half the effort.
At the same time, both GFS and Tectonic are systems that only serve the company's internal business. Although the scale is large, the requirements are relatively single. JuiceFS is positioned to serve a large number of external users and meet the needs of diverse scenarios, so its architecture design is also quite different from these two file systems.
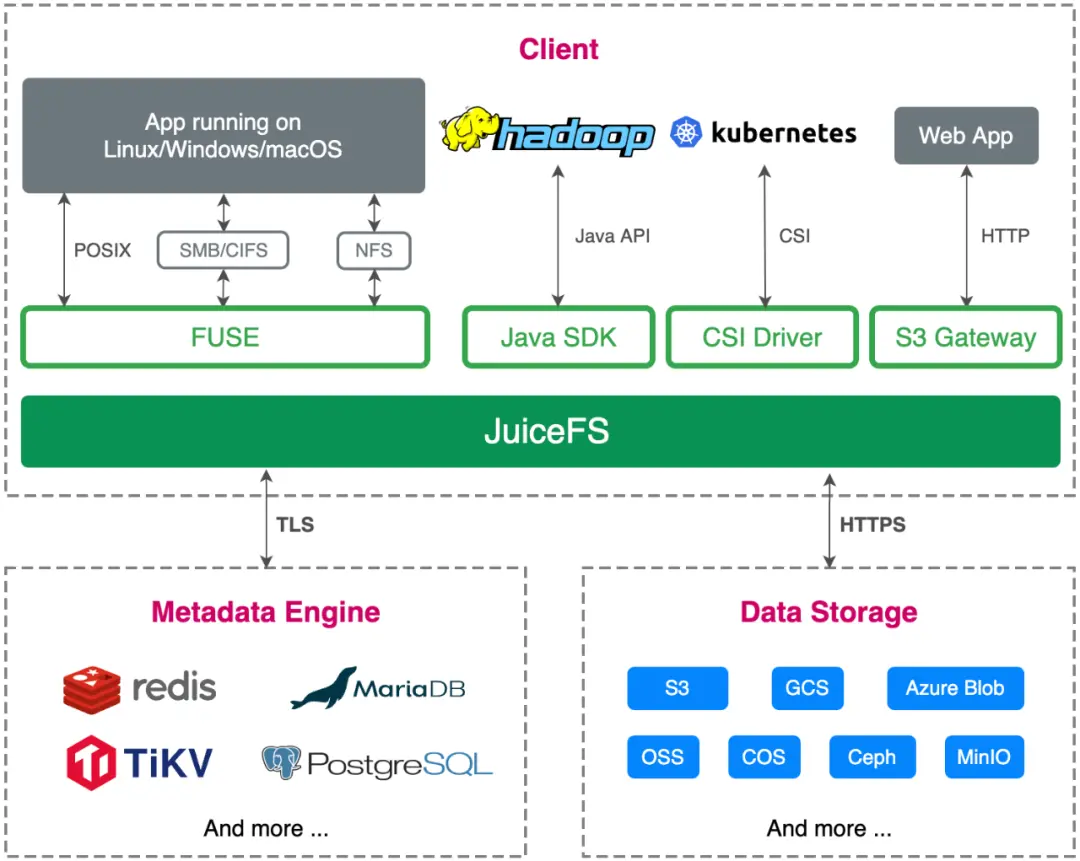
Based on these changes and differences, let's take a look at the architecture of JuiceFS. Similarly, JuiceFS is also composed of 3 parts: metadata engine, data storage and client . Although the general framework is similar, in fact, the design of each part of JuiceFS has some differences.
The first is data storage. Compared with GFS and Tectonic using self-developed data storage services, JuiceFS conforms to the characteristics of the cloud-native era in terms of architecture design, and directly uses object storage as data storage. We saw earlier that Tectonic used more than 4,000 servers to store EB-level data. It is conceivable that the operation and maintenance costs of such a large-scale storage cluster are bound to be high. For ordinary users, the benefits of object storage are out-of-the-box, flexible capacity, and a sharp drop in O&M complexity. Object storage also supports the EC feature used in Tectonic, so the storage cost can be much lower than some multi-copy distributed file systems .
However, the shortcomings of object storage are also obvious, such as not supporting object modification, poor metadata performance, inability to guarantee strong consistency, and poor random read performance. These problems are solved by the independent metadata engine designed by JuiceFS, the three-tier data architecture design of Chunk, Slice, and Block, and the multi-level cache.
The second is the metadata engine. JuiceFS can use some open source databases as the underlying storage of metadata. This is very similar to Tectonic, but JuiceFS goes a step further. It not only supports distributed KV, but also supports storage engines such as Redis and relational databases, allowing users to flexibly choose the most suitable solution according to their usage scenarios. This is based on JuiceFS is positioned as an architectural design made by a general-purpose file system. Another advantage of using open source databases is that these databases usually have fully managed services on public clouds, so the operation and maintenance costs for users are almost zero.
As mentioned earlier, Tectonic chose ZippyDB, a KV storage that supports transactions, to ensure strong consistency of metadata, but Tectonic can only guarantee the transactionality of single-shard metadata operations, while JuiceFS has stricter requirements for transactionality. Guarantee global strong consistency (that is, require transactionality across shards). Therefore, all currently supported databases must have stand-alone or distributed transaction features, otherwise there is no way to access it as a metadata engine (an example is that Redis Cluster does not support cross-slot transactions). Based on a horizontally scalable metadata engine (such as TiKV), JuiceFS is currently able to store more than 20 billion files in a single file system, meeting the storage needs of enterprises for massive data .

The above picture is the data structure design when using KV storage (such as TiKV) as the JuiceFS metadata engine. If you compare the design of Tectonic, there are similarities and some big differences. For example, the first key does not distinguish between files and directories in the design of JuiceFS, and the attribute information of files or directories is not placed in value, but has a separate key for storing attribute information (the third key).
The second key is used to store the block ID corresponding to the data. Since JuiceFS is based on object storage, it does not need to store specific disk information like Tectonic, but only needs to obtain the key of the object in some way. In the storage format of JuiceFS, metadata is divided into 3 layers: Chunk, Slice, and Block. Chunk has a fixed size of 64MiB, so the value in the second key chunk_indexcan directly calculated from the file size, offset, and 64MiB. The value obtained through this key is a set of Slice information, which includes the ID and length of the Slice. Combining these information, the key on the object storage can be calculated, and finally the data can be read or written.
The last point needs special attention. In order to reduce the overhead caused by executing distributed transactions, the third key needs to be designed close to the first two keys to ensure that transactions are completed on a single metadata engine node as much as possible. However, if distributed transactions cannot be avoided, the underlying metadata engine of JuiceFS also supports (with a slight decrease in performance) to ensure the atomicity of metadata operations.
Finally, let's look at the design of the client. The biggest difference between JuiceFS and the other two systems is that it is a client that supports multiple standard access methods at the same time, including POSIX, HDFS, S3, Kubernetes CSI, etc. The GFS client can basically be regarded as a non-standard protocol client, which does not support the POSIX standard and only supports append writing, so it can only be used in a single scenario. Tectonic's client is similar to GFS, does not support POSIX standard, only supports additional writing, but Tectonic adopts a rich client design, puts many functions on the client side, which also makes the client have the largest flexibility. In addition, the JuiceFS client also provides the cache acceleration feature, which is very valuable for storage separation scenarios under the cloud native architecture.
epilogue
The file system was born in the 1960s. With the development of the times, the file system is also constantly evolving. On the one hand, due to the popularity of the Internet and the explosive growth of data scale, the file system has undergone an architecture upgrade from stand-alone to distributed. Companies like Google and Meta are the leaders.
On the other hand, the birth and popularity of cloud computing has promoted the development of storage on the cloud. It has gradually become the mainstream for enterprises to use the cloud for backup and archiving. Some high-performance computing and big data scenarios performed in the local computer room have also begun to migrate to the cloud. , These scenarios with higher performance requirements pose new challenges to file storage. JuiceFS was born in such a background. As an object storage-based distributed file system, JuiceFS hopes to provide scalable file storage solutions for more companies of different sizes and more diverse scenarios.
If you are helpful, please pay attention to our project Juicedata/JuiceFS ! (0ᴗ0✿)