Autor: JD Retail Zhang Luyao
1. Cenários de aplicação
Atualmente, existem muitas funções no sistema que requerem processamento atrasado: cancelamento de tempo limite de pagamento, tempo limite de fila, envio atrasado de SMS, WeChat e outros lembretes, atualização de token, expiração de cartão de membro, etc. Por meio do processamento atrasado, os recursos do sistema são bastante economizados e não há necessidade de consultar o banco de dados para tarefas de processamento.
Atualmente, a maioria das funções é concluída por tarefas de temporização. Existem dois tipos de tarefas de temporização: quartz e xxljob. O tempo de pesquisa é curto e executado uma vez por segundo, o que coloca uma certa pressão no banco de dados e tem um intervalo de 1 segundo erro. O tempo de polling é longo, por exemplo, uma vez a cada 30 minutos, um dado é inserido às 03h01, e a expiração é normalmente executada às 3h31, mas quando o polling é realizado às 3h30, os dados de 3:00-3:30 é escaneado, mas a varredura é menor que 3: Os dados de 31 só podem ser escaneados às 4:00, o que equivale a um atraso de 29 minutos!
2. Pesquisa sobre métodos de processamento de atraso
1.DelayQueue
1. Método de implementação:
A fila de bloqueio de atraso fornecida pelo jvm classifica as tarefas com diferentes tempos de atraso por meio da fila de prioridade, bloqueia por meio da condição e adquire as tarefas atrasadas durante o período de suspensão.
Quando uma nova tarefa é adicionada, ele julgará se a nova tarefa é a primeira tarefa a ser executada. Se for, a fila de espera será liberada para evitar que os elementos recém-adicionados precisem ser executados e não possam ser normalmente obtidos pela execução fio.
2. Problemas existentes:
1. Operação autônoma, depois que o sistema está inativo, não é possível realizar novas tentativas efetivas
2. Falha ao executar registro e backup
3. Nenhum mecanismo de repetição
4. Quando o sistema reiniciar, a tarefa será apagada!
5. Não é permitido o consumo de fragmentos
3. Vantagens: implementação simples, bloqueio quando não há tarefa, economia de recursos e tempo de execução preciso
2. Fila de atraso mq
Método de implementação: confie no mq e obtenha a função de consumo atrasado definindo o tempo de consumo atrasado. Assim como o rabbitMq e o jmq, você pode definir o tempo de consumo atrasado. RabbitMq é implementado definindo o tempo de expiração da mensagem e colocando-a na fila de mensagens mortas para consumo.
Problemas existentes:
1. A configuração de tempo não é flexível. Cada fila tem um tempo de expiração fixo. Sempre que uma fila de atraso é criada, uma nova fila de mensagens precisa ser criada
Vantagens: Contando com o jmq, ele pode monitorar, consumir registros e tentar novamente de forma eficaz, tem a capacidade de consumir várias máquinas ao mesmo tempo e não tem medo de tempo de inatividade
3. Tarefas agendadas
Pesquisando dados qualificados por meio de tarefas agendadas
deficiência:
1. É necessário ler o banco de dados comercial, o que coloca uma certa pressão no banco de dados.
2. Há um atraso
3. Quando a quantidade de dados digitalizados é muito grande, ela ocupa muitos recursos do sistema.
4. A fragmentação não pode ser consumida
vantagem:
1. Após o consumo falhar, você pode continuar a consumir na próxima vez e ter a capacidade de tentar novamente.
2. Poder de compra estável
4.redis
As tarefas são armazenadas em redis e a fila zset de redis é usada para classificar de acordo com a pontuação. O programa obtém continuamente o consumo de dados da fila por meio do thread para realizar a fila de atraso
vantagem:
1. Consultar redis é mais rápido que o banco de dados, e o comprimento da fila definido é muito grande, e a consulta será realizada de acordo com a estrutura da tabela de salto, que é altamente eficiente
2. Redis pode ser classificado de acordo com o carimbo de data/hora, você só precisa consultar a tarefa da pontuação no carimbo de data/hora atual
3. Sem medo de reiniciar a máquina
4. Consumo distribuído
deficiência:
1. Limitado pelo desempenho do redis, 10 W simultâneos
2. Vários comandos não podem garantir a atomicidade. Usar scripts lua exigirá que todos os dados estejam em um fragmento redis.
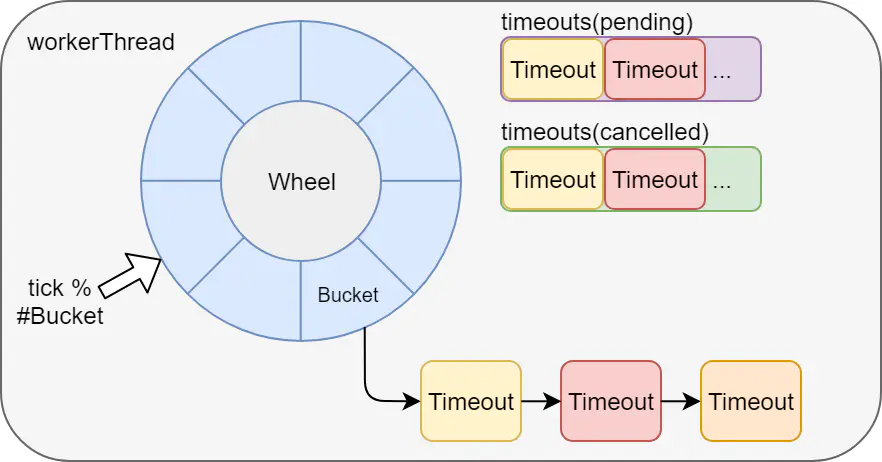
5. Roda do tempo
A execução de tarefas atrasadas por meio da roda do tempo também é baseada na operação autônoma do jvm. Por exemplo, kafka e netty implementam rodas do tempo, e o watchdog de redisson também é realizado por meio da roda do tempo do netty.
Desvantagens: Não é adequado para o uso de serviços distribuídos e as tarefas serão perdidas após o tempo de inatividade.
3. Alcance metas
Compatível com os componentes de eventos assíncronos atualmente em uso e fornece componentes de atraso de alto desempenho, repetíveis, registrados, de monitoramento de alarme e mais confiáveis.
•Confiabilidade da transmissão da mensagem: Depois que uma mensagem entra na fila de espera, é garantido que ela seja consumida pelo menos uma vez.
•Cliente suporta rico: suporta vários idiomas.
• Alta disponibilidade: oferece suporte à implantação de várias instâncias. Depois que uma instância é suspensa, há uma instância de backup que continua a fornecer serviços.
•Tempo real: um determinado erro de tempo é permitido.
•Suporte para exclusão de mensagens: os usuários corporativos podem excluir mensagens especificadas a qualquer momento.
• Consulta de consumo de suporte
• Suporta repetição manual
• Aumentar o monitoramento da execução do evento assíncrono atual
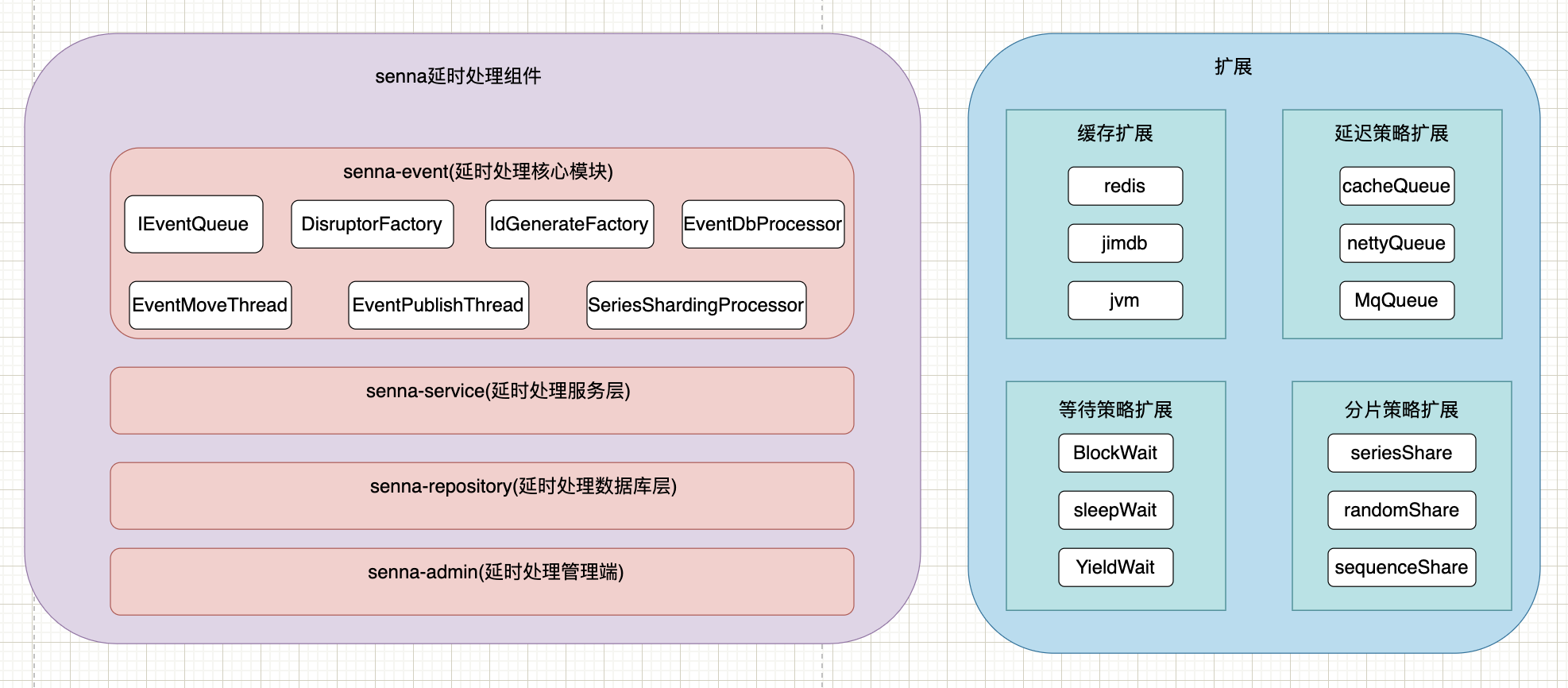
4. Projeto de arquitetura
5. Atrasar a implementação do componente
1. Princípio de implementação
No momento, optamos por usar o jimdb para implementar a função de atraso por meio do zset e armazenar o id da tarefa e o tempo de execução correspondente como pontuação na fila zset. Por padrão, eles serão classificados por pontuação e, a cada vez, pegamos o id da tarefa de 0 pontos no tempo atual,
Ao enviar uma tarefa atrasada, um id único será gerado de acordo com o timestamp + ip da máquina + queueName + sequência, e o corpo da mensagem será construído, criptografado e colocado na fila zset.
Ao mover a thread, a tarefa que atingiu o tempo de execução é movida para a fila de liberação, esperando que o consumidor a obtenha.
A parte de monitoramento integra ump
Os registros de consumo são concluídos por meio de backup redis + persistência do banco de dados.
O método implementado pelo cache é apenas um tipo de implementação, cujo método de implementação pode ser controlado por meio de parâmetros e pode ser expandido livremente por meio do spi.
2. Estrutura da mensagem
Cada Trabalho deve conter os seguintes atributos:
• Tópico: tipo de trabalho, ou seja, QueueName
•Id: o identificador único do Trabalho. Usado para recuperar e excluir as informações do Trabalho especificadas.
•Atraso: O trabalho precisa atrasar o tempo. Unidade: segundos. (O servidor irá convertê-lo em tempo absoluto)
•Body: O conteúdo do Job, que é armazenado no formato json para que os consumidores façam processamentos de negócios específicos.
•traceId: o traceId do encadeamento de envio, após o pfinder subseqüente suportar a configuração traceId, ele pode compartilhar o mesmo traceid com o encadeamento de envio, o que é conveniente para rastreamento de log
A estrutura específica é mostrada na figura abaixo:

TTR é projetado para garantir a confiabilidade da transmissão de mensagens.
3. Fluxo de dados e fluxograma

Publique e consuma com base no método redis-disruptor, que pode ser usado como uma mensagem. Os consumidores usam a fila sem bloqueio do disruptor de evento assíncrono original para consumo e não há bloqueio entre aplicativos diferentes e filas diferentes
1. Apoie o aplicativo para apenas publicar, não consumir e alcançar a função de fila de mensagens.
2: Suporte a agrupamento.Para o problema de chaves grandes, se houver muitos eventos, você pode definir o número de filas de atraso e baldes de fila de tarefas para reduzir o problema de bloqueio de redis causado por chaves grandes.
3: Através da configuração do ducc, o desempenho é expandido. Atualmente, apenas o consumo está ativado e o consumo está desativado.
4: Suporta configuração de tempo limite para evitar que threads de consumidores sejam executados por muito tempo
Gargalo: A velocidade de consumo é lenta e a velocidade de produção é muito rápida, o que fará com que a fila do buffer de anel fique cheia. Quando o aplicativo atual é um produtor e um consumidor, o produtor irá dormir e o desempenho depende da velocidade de consumo A máquina pode ser expandida horizontalmente para melhorar diretamente o desempenho. Monitore o comprimento da fila de redis. Se ela continuar crescendo, considere adicionar consumidores para melhorar diretamente o desempenho.
Possível situação: Como uma aplicação compartilha um disruptor e possui 64 threads consumidoras, se o consumo de um determinado evento for muito lento, todas as 64 threads estão consumindo este evento, o que fará com que outros eventos sejam consumidos por nenhuma thread consumidora, e o produtor thread também irá consumir está bloqueada, fazendo com que o consumo de todos os eventos seja bloqueado.
Para observar se existe tal gargalo de desempenho mais tarde, você pode dar a cada fila um pool de encadeamentos do consumidor.
6. exemplo de demonstração
Adicionar arquivo de configuração
Determine se deseja habilitar jd.event.enable:true
<dependency> <groupId>com.jd.car</groupId>
<artifactId>senna-event</artifactId>
<version>1.0-SNAPSHOT</version> </dependency>
configuração
jd:
senna:
event:
enable: true
queue:
retryEventQueue:
bucketNum: 1
handleBean: retryHandle
Código de consumo:
package com.jd.car.senna.admin.event;
import com.jd.car.senna.event.EventHandler;
import com.jd.car.senna.event.annotation.SennaEvent;
import lombok.extern.slf4j.Slf4j;
import org.springframework.stereotype.Component;
/**
* @author zhangluyao
* @description
* @create 2022-02-21-9:54 下午
*/
@Slf4j
@Component("retryHandle")
public class RetryQueueEvent extends EventHandler {
@Override
protected void onHandle(String key, String eventType) {
log.info("Handler开始消费:{}", key);
}
@Override
protected void onDelayHandle(String key, String eventType) {
log.info("delayHandler开始消费:{}", key);
}
}
Formulário de anotação:
package com.jd.car.senna.admin.event;
import com.jd.car.senna.event.EventHandler;
import com.jd.car.senna.event.annotation.SennaEvent;
import lombok.extern.slf4j.Slf4j;
/**
* @author zhangluyao
* @description
* @create 2022-02-21-9:54 下午
*/
@Slf4j
@SennaEvent(queueName = "testQueue", bucketNum = 5,delayBucketNum = 5,delayEnable = true)
public class TestQueueEvent extends EventHandler {
@Override
protected void onHandle(String key, String eventType) {
log.info("Handler开始消费:{}", key);
}
@Override
protected void onDelayHandle(String key, String eventType) {
log.info("delayHandler开始消费:{}", key);
}
}
enviar código
package com.jd.car.senna.admin.controller;
import com.jd.car.senna.event.queue.IEventQueue;
import lombok.extern.slf4j.Slf4j;
import org.springframework.context.annotation.Lazy;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.ResponseBody;
import org.springframework.web.bind.annotation.RestController;
import javax.annotation.Resource;
import java.util.concurrent.CompletableFuture;
/**
* @author zly
*/
@RestController
@Slf4j
public class DemoController {
@Lazy
@Resource(name = "testQueue")
private IEventQueue eventQueue;
@ResponseBody
@GetMapping("/api/v1/demo")
public String demo() {
log.info("发送无延迟消息");
eventQueue.push("no delay 5000 millseconds message 3");
return "ok";
}
@ResponseBody
@GetMapping("/api/v1/demo1")
public String demo1() {
log.info("发送延迟5秒消息");
eventQueue.push(" delay 5000 millseconds message,name",1000*5L);
return "ok";
}
@ResponseBody
@GetMapping("/api/v1/demo2")
public String demo2() {
log.info("发送延迟到2022-04-02 00:00:00执行的消息");
eventQueue.push(" delay message,name to 2022-04-02 00:00:00", new Date(1648828800000));
return "ok";
}
}
Consulte o design de Youzan: https://tech.youzan.com/queuing_delay/
7. Aplicação atual:
1. Yunxiu cancelará automaticamente após 24 horas na fila da loja
2. A Meituan solicita a atualização do token regularmente.
3. O cartão de garantia será gerado em 24 horas
5. Adiamento da geração do extrato
6. Envio de SMS atrasado