Time series forecasting | MATLAB implements Bayesian optimization CNN-LSTM time series forecasting (stock price forecasting)
Table of contents
List of effects







basic introduction
MATLAB implements Bayesian optimization CNN-LSTM (convolutional long short-term memory neural network) time series prediction, Bayes-CNN-LSTM model stock price prediction
Model building
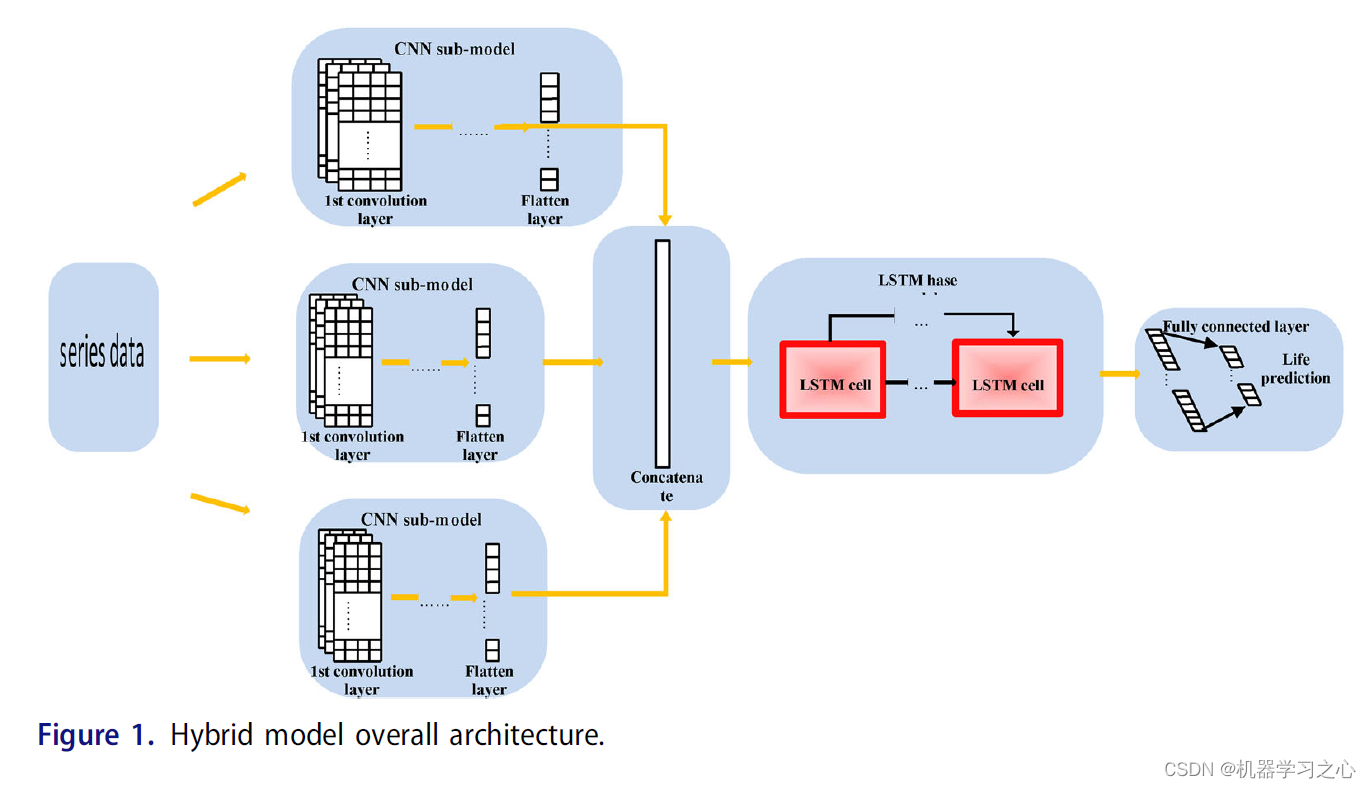
- The CNN-LSTM model combines the advantages of CNN and LSTM. The CNN-LSTM network model is shown in Figure 1. The first part of the CNN-LSTM model used in this paper is a CNN partial pooling layer consisting of a convolutional layer and a maximum value. The original data is preprocessed and input into the CNN convolution layer, and the convolution kernel is used to adaptively extract the vital features. The convolution layer will traverse the input information, and convolve the convolution kernel weight and the local sequence to obtain the preliminary feature matrix. , more expressive than raw sequence data (matrix).
- The pooling layer used in this paper is the maximum pooling layer. The pooling operation performs data dimension reduction on the extracted features to avoid model overfitting and retain the main features. The max pooling layer takes the feature matrix obtained by the previous convolution layer as input, slides a pooling window on this matrix, takes the maximum value of the pooling window in each sliding, and outputs a more expressive feature matrix.
- After pooling, an LSTM layer is connected, and the correlation vector is extracted and constructed by CNN into a long-term time series as the input data of LSTM. The convolutional layer flattens the data of the convolutional layer (Flatten), adds Flatten to the model, and compresses the data of (height, width, channel) into a one-dimensional array of long, high and wide channels, and then we can add direct dense layers.
- For the convolution pooling data compression feature operation, the feature fusion extracted by multiple convolution feature extraction frameworks or from the output layer fusion, the fully connected layer aggregates the learned features, and the activation function uses Relu.
- The Relu function has unilateral inhibition, which can generate more sparsity and avoid gradient vanishing. Before the final output, set the Dropout rate to 0.2 to avoid overfitting the model.
- Usually, hyperparameters need to be optimized during model training, and a set of optimal hyperparameters is selected for the model to improve the performance and effectiveness of prediction, such as batch_size, full_num, lstm_num, num_filter in the CNN-LSTM model. Setting hyperparameters empirically can make the final combination of model hyperparameters not necessarily optimal, which affects how well the model network fits and how well it generalizes to the test data.
- The pseudo-code

- When using Bayesian optimization for CNN-LSTM, CNN-LSTM with different parameter combinations is used as the independent variable, and the average error (MAE) is used as the output y of the Bayesian framework. The specific steps are as follows:
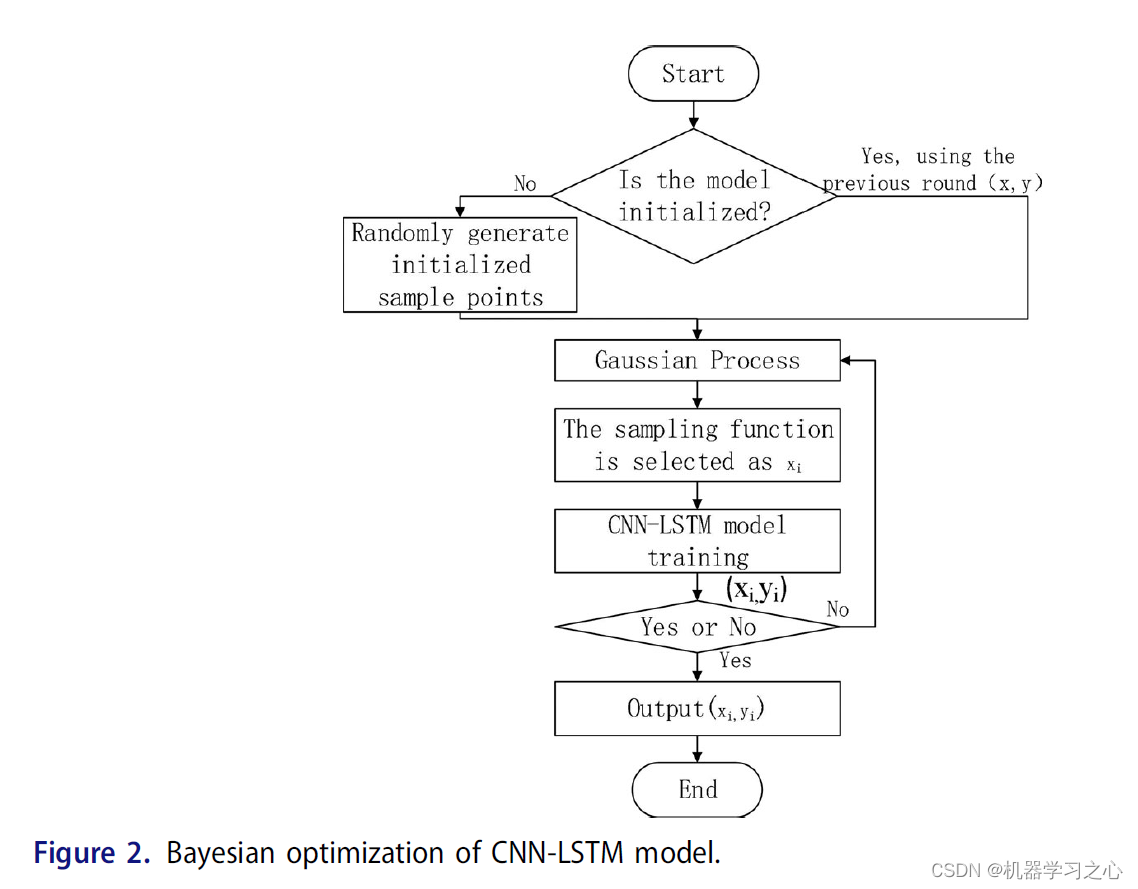
- Tune model parameters by tuning optimization algorithms, learning repetition rates, and Bayesian optimization hyperparameters.
programming
- Complete program private letter blogger.
%% 搭建CNN模型
rng('default');
inputSize = 1;
numEpochs = 200;
batchSize = 16;
nTraining = length(label);
% CONV -> ReLU -> MAXPOOL -> FC -> DROPOUT -> FC -> SOFTMAX
layers = [ ...
sequenceInputLayer(inputSize)
convolution1dLayer(5,100,'Padding',2,'Stride', 1) % 卷积层 1
batchNormalizationLayer;
reluLayer(); % ReLU 层 1
convolution1dLayer(5,70,'Padding',2,'Stride', 1); % 卷积层 2
batchNormalizationLayer;
maxPooling1dLayer(1,'Stride',1); % 最大池化 池化层 1
convolution1dLayer(3,50,'Padding',1,'Stride', 1); % 卷积层 3
reluLayer(); % ReLU 层 3
maxPooling1dLayer(1,'Stride',1);
convolution1dLayer(3,40,'Padding',1,'Stride', 1); % 卷积层 4
reluLayer(); % ReLU 层 2
maxPooling1dLayer(1,'Stride',1); % 最大池化 池化层 1
fullyConnectedLayer(1,'Name','fc1')
regressionLayer]
options = trainingOptions('adam',...
'InitialLearnRate',1e-3,...% 学习率
'MiniBatchSize', batchSize, ...
'MaxEpochs',numEpochs);
[net,info1] = trainNetwork(input_train,output_train,layers,options);
%% 提取特征
fLayer = 'fc1';
trainingFeatures = activations(net, input_train, fLayer, ...
'MiniBatchSize', 16, 'OutputAs', 'channels');
trainingFeatures=cell2mat(trainingFeatures);
for i=1:length(trainingFeatures)
TF{
i}=double(trainingFeatures(:,i));
end
%% 搭建LSTM模型
inputSize = 1;
numHiddenUnits = 100;
layers = [ ...
sequenceInputLayer(inputSize)
lstmLayer(numHiddenUnits,'OutputMode','last')
lstmLayer(numHiddenUnits-30)
lstmLayer(numHiddenUnits-60)
fullyConnectedLayer(1)
regressionLayer]
options = trainingOptions('adam',...
'InitialLearnRate',1e-3,...% 学习率
'MiniBatchSize', 8, ...
'MaxEpochs',50, ...
'Plots','training-progress');
[net1,info1] = trainNetwork(TF,output_train',layers,options);
%% 测试集
% 测试集提取特征
testingFeatures = activations(net, input_test, fLayer, ...
'MiniBatchSize', 8, 'OutputAs', 'channels');
testingFeatures=cell2mat(testingFeatures);
for i=1:length(testingFeatures)
TFT{
i}=double(testingFeatures(:,i));
end
YPred = predict(net1,TFT);
YPred=mapminmax('reverse',YPred,yopt);
summarize
Bayesian optimization can make full use of historical tuning information, reduce unnecessary evaluation of the objective function, and improve the efficiency of parameter search. In the model training process, the ADAM optimization algorithm is used to further optimize the network weight parameters to make the prediction results more accurate. The proposed hyperparameter-based optimization search scheme combined with stock prediction should use the CNN-LSTM model, and the selected model has higher prediction accuracy and generalization ability.
references
[1] https://blog.csdn.net/kjm13182345320/article/details/127261869?spm=1001.2014.3001.5501
[2] https://blog.csdn.net/kjm13182345320/article/details/127261869?spm=1001.2014.3001.5501
[3] G. W. Jiao, and C. Hu, G: Gun barrel life evaluation and prediction, J. Ordnance Equip.Eng. 39, 66 (2018).
[4] M. T. Li et al., Barrel life prediction method based on inner surface melting layer theory,J.Gun Launch Control, 5–8 (2009).