
Series Article Directory
Article directory
- Series Article Directory
- foreword
- A single server process
- Second, the multi-server process
- Three, multi-type server process
- 4. Distributed storage
- 5. The future of game servers
- 6. Games on the cloud
- 7. Cloud Gaming
- Summarize
foreword
The early Internet infrastructure and network software technology were not perfect, and there were characteristics such as less data storage and slow transmission speed. In addition, the early display technology only supported text display, so the early online games were some text with weak interactivity and small amount of data. Interactive game. However, with the development of graphical interface technology and Internet technology, the amount of network data storage and transmission has increased, a variety of games have appeared, and the corresponding server technology has become more and more complex.
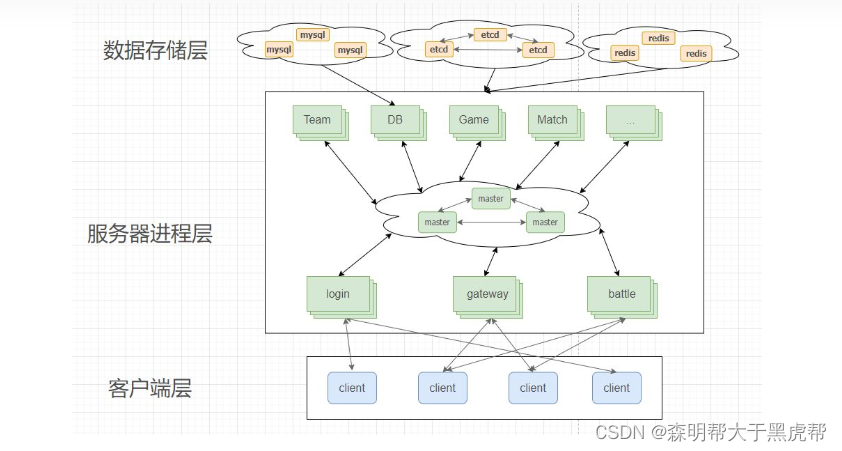
This article is mainly divided into two parts, the first part is server history and present. This part is mainly about the origin of the room server architecture. The main goal is to let everyone know the origin and function of each component of the modern server architecture, and how the server has developed from the previous single server architecture to the current complex multi-type server architecture. The development diagram is as follows.
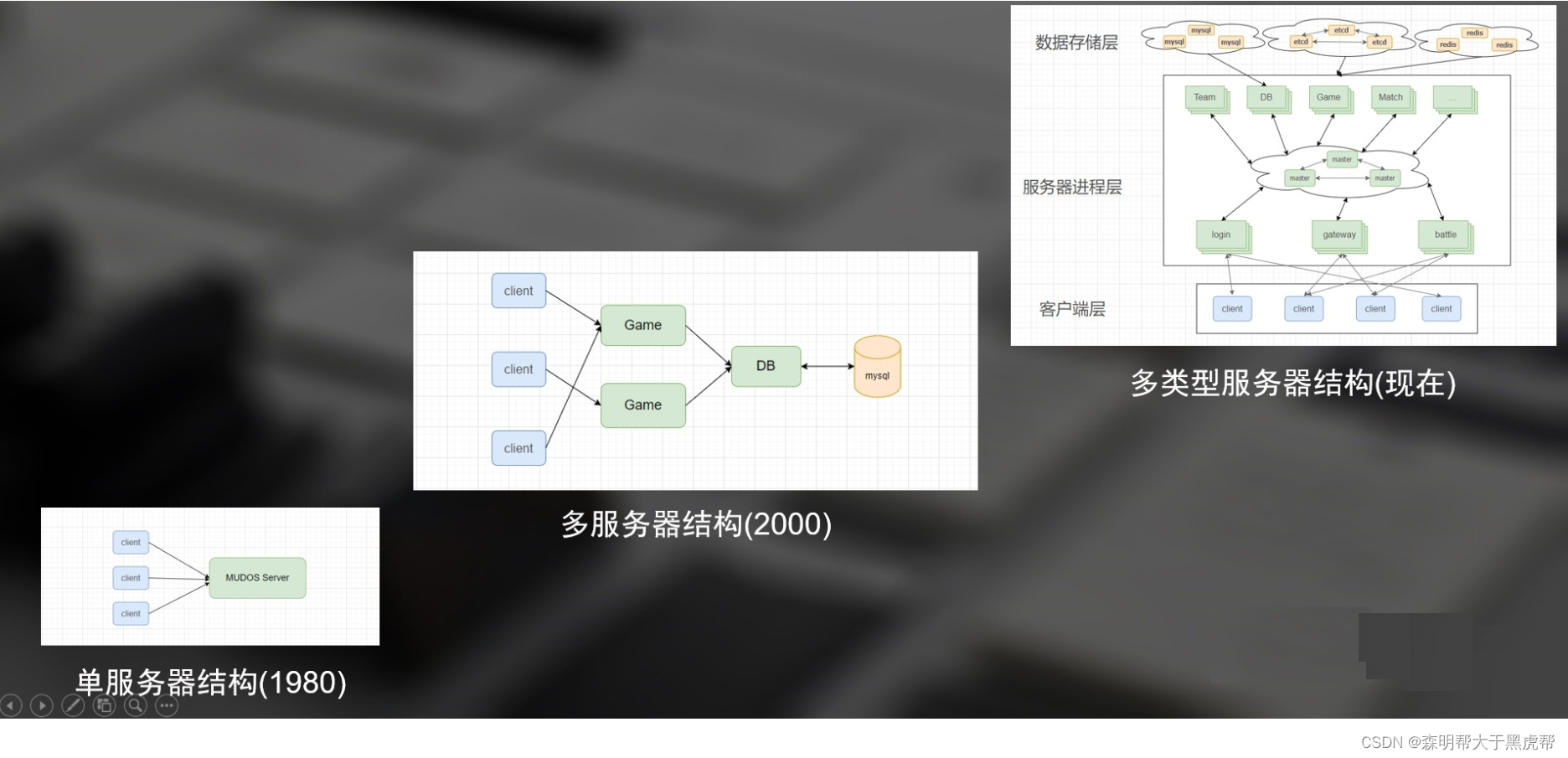
The second part is the future of servers. The main content of this part is how games go to the cloud, what is cloud gaming, and how cloud gaming works. From the historical development of the server, we can better understand the composition of the current server architecture, and we can also see the future development trend of game servers. The development trend of the server mainly depends on the game player demand and the upstream and downstream technology industry chain. From the current point of view: the game content is getting more and more refined, the amount of Internet transmission is getting bigger and bigger, and the development of cloud computing is growing. I personally think that the future development of servers will be games on the cloud and cloud games.
A single server process
In 1978, a student in the UK wrote the world's first MUD program "MUD1". MUD1 mainly uses text narration. After entering the game, the server tells you what scene you are in, what data you have and so on. For example, if you enter and go up, the program will tell you that you have climbed halfway up the mountain, as shown in the figure below.

In 1980, the "MUD1" program was connected to ARPANET and the source code of the program was also shared with ARPANET. Since then, there have been many adaptations of "MUD1", and the continuous improvement of "MUD1" has also produced the open source MUDOS. MUDOS uses a single-threaded non-blocking socket to serve all players. All players' logical requests are sent to the same thread for processing. The main thread updates all objects every second, and player data is directly stored to the local disk .
Second, the multi-server process
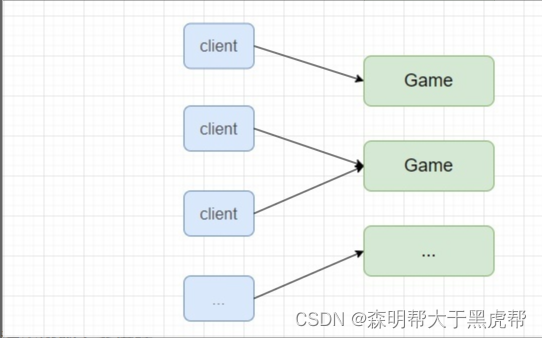
Around 2000, online games have entered the era of full graphics from text MUDs. The game content has become more and more abundant, and the amount of game data has become larger and larger. The early MUDOS architecture has become more and more unbearable, various load problems have gradually surfaced, and the traditional single-server structure has become a bottleneck. Therefore, the server is divided into multiple game logic servers (Game), and players are allocated to each game process. Each game logic server is responsible for the services of a certain number of players, as shown in the figure below.
Three, multi-type server process
Earlier, there were fewer players involved in online games, and the game content was relatively simple. All game content logic was run in the same server process. With the development of graphics technology, there are more and more online game players, and the game content is becoming richer and more complex, resulting in an increasing amount of game data. Therefore, different types of server processes appear to serve different needs.
1. Splitting the database
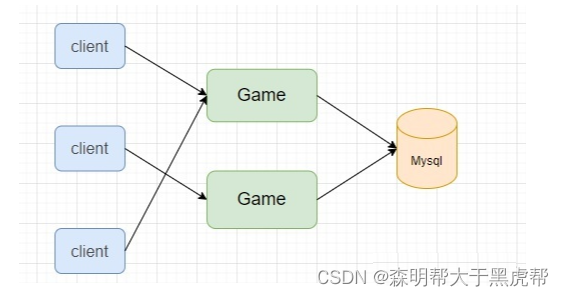
An important function of the server is to store the player's game data, so that the next time the player goes online, the previous game data can be read to continue the game. Previously, the data persistent storage of text MUD games used the local file storage of the server. When the player goes offline or periodically, the data is stored in the EXT disk. This kind of storage is logically no problem, but the player frequently goes online and offline. This leads to frequent I/O on the server, resulting in an increasing load, and the EXT disk partition is relatively fragile, and a slight power failure is prone to data loss. Therefore, the first step is to split the file and store it in the database (Mysql), as shown in the following figure.
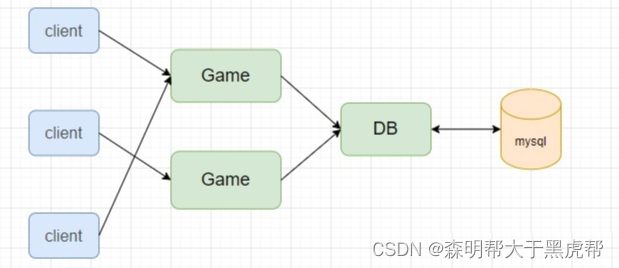
1. Database Agent Process (DB)
After the database is split, the game logic is separated from the data storage, which reduces the coupling of the system. If each game logic server (Game) needs to fetch data, it can directly connect to the database to obtain data, but when a large number of players operate at the same time, multiple game servers access the database at the same time, and a large amount of data repeated access and data exchange occurs, making the database a bottleneck. Therefore, a data proxy process (DB) is added between the game logic server (Game) and the database. The game server does not directly access the database but accesses the data proxy process. The data proxy process also provides in-memory data cache, caches some hot data, reduces the Database I/O. As shown below.
2. In-memory database
The open source of Internet technology has greatly promoted the development and improvement of various special software. A special memory database has emerged in open source technology. This kind of special memory database provides easy-to-use and convenient storage structures, and has high readability. Therefore, the game server introduces this kind of dedicated in-memory database to cache server hotspot data. At present, the most widely used in-memory databases are Redis and Memcached . After the introduction of the in-memory database, the database agent process (DB) no longer caches data, but instead loads the player data from the Mysql database into the in-memory database when the player goes online, and periodically stores the data in the in-memory database to the Mysql database.
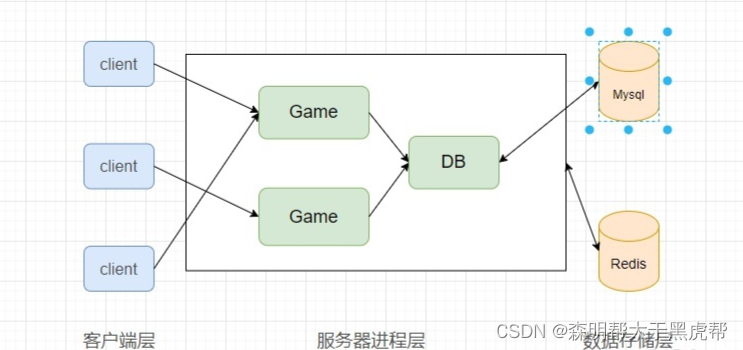
2. Splitting of logical processes
The above structure did not last for too long. Due to the gradual enrichment of game function types, in order to improve the running speed and game experience of each function of the game, a variety of dedicated server types began to appear, such as chat server (IM), match server (Match) and There are several advantages to separating these dedicated servers for leaderboard servers (Rank), etc.:
- Reduce coupling: If all logic runs in one process, if a game function fails, it will affect all the functions of the game, causing the game to not continue. For example, splitting the chat into a separate server, if the chat server hangs, it will only affect the chat, not your lobby logic, scene logic and other logic.
- Allocating pressure: A function like matching usually requires a large number of players to be placed in a pool, and then several players with similar ability values are selected to compete. This involves a large number of sorting and comparison operations, which will result in a large CPU usage and thus Block the processing of other logic. Therefore, the function of matching is generally split into a matching server (Match).
- Guarantee data consistency: It is typical to form a team. The team is composed of multiple people. Each player may be assigned to a different logical server (GameServer) due to the load of pressure. If a team is maintained in each logical server Data, there will be data inconsistency, which is more difficult to handle, so a better way is to split the team function into a team server (Team), and put the team data in one place.
After splitting into different server types, the architecture diagram is as follows: After
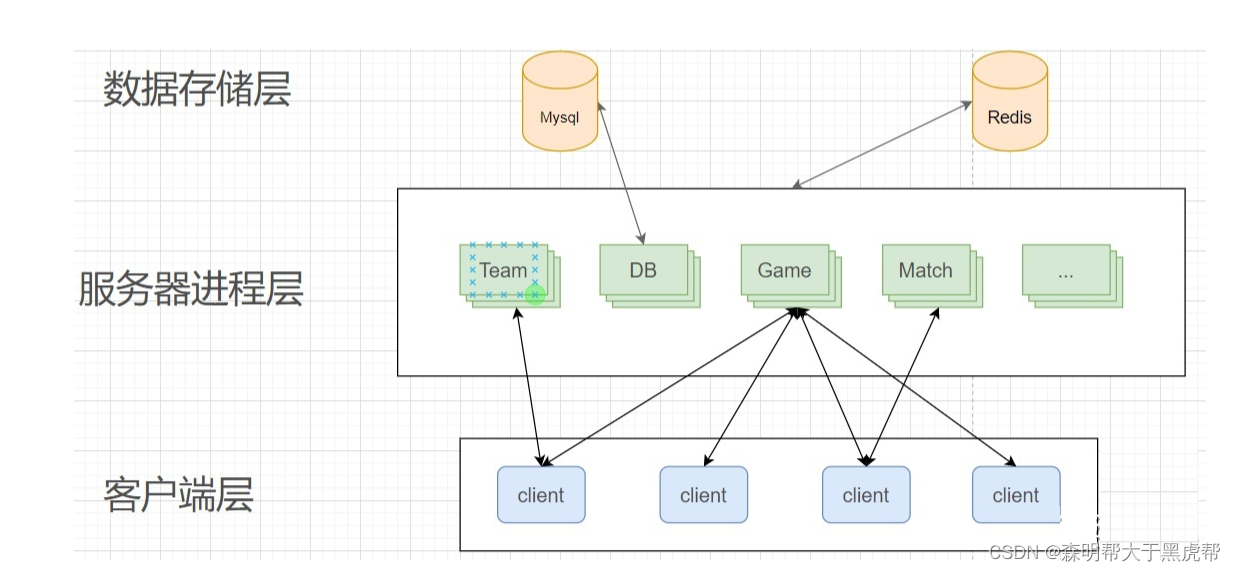
splitting into different servers, the same player client may interact with multiple servers at the same time, such as matching or chatting when you form a team, and some Status changes frequently, such as players frequently matching and unmatching. If each specific function client needs to connect to a corresponding server, the change of the connection and the communication of data will become very troublesome, and the intermediate state is prone to errors, so a gateway server (Gateway) has been split.
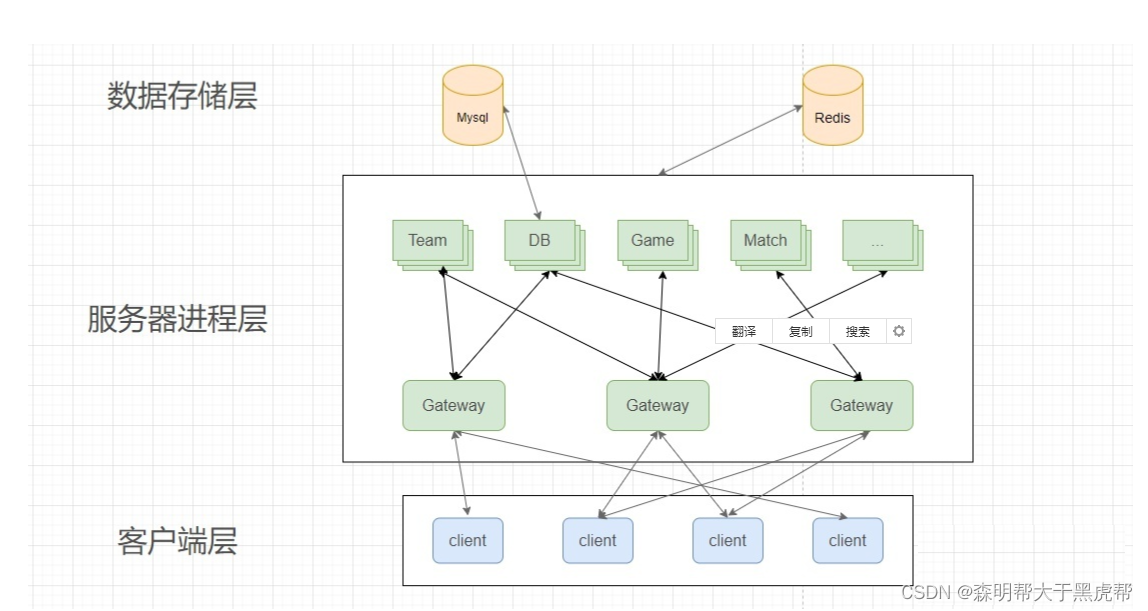
The network function between the client and the server is extracted separately, and the client is connected to the gateway server in a unified manner, and the data sent by the client is forwarded by the gateway server to various types of game servers in the backend. The data exchange between each game server is also unified to the gateway server for exchange.
3. Message queue
The above types of servers can basically provide game services for players stably, but the scalability is very poor. Each gateway server (Gateway) needs to maintain connections with all logical servers of all types. Some logical services such as large games may be good. There are thousands of them. If each one maintains a connection, maintaining these connections will consume a lot of memory and computing, and each new logical server must be connected to all gateway servers, which has poor scalability. Therefore, communication between servers usually adds a message queue process, which is specially used to forward messages between servers.
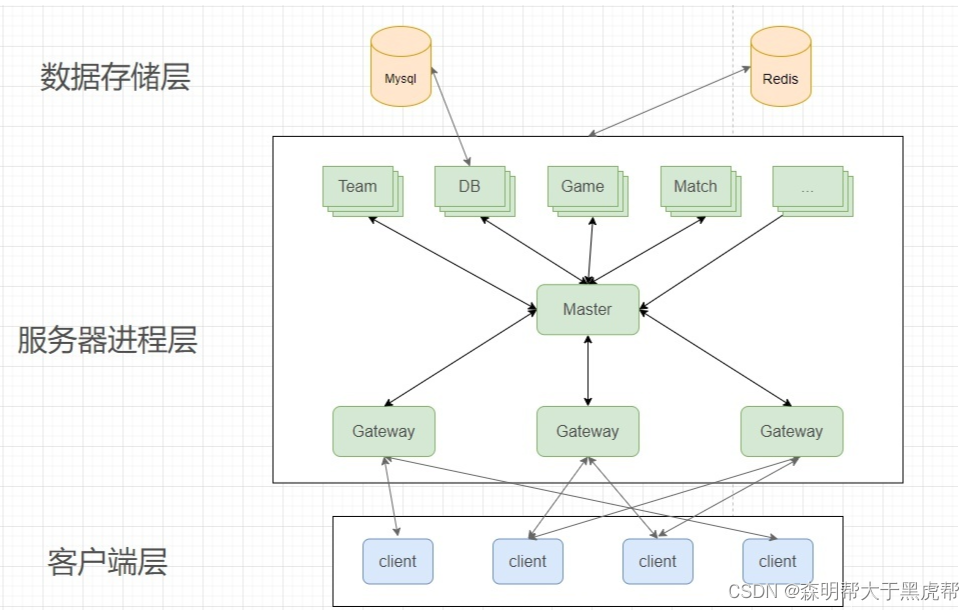
1. Global Service Manager (Master)
The old version of the server usually has a type of global service manager (Master). There is only one global service manager in the whole server, which will store the shared or unique data of the whole server. The early data caching function is also realized by the global service manager. Usually the global service manager also stores and manages the information of all servers, such as the IP address of the server, the capacity of the server and the addition and deletion of the server, etc., and the global service manager (Master) needs to connect with each server, using heartbeat It maintains whether the server is in an available state, so it is responsible for message forwarding between servers, and the global service manager (Master) plays the role of a message queue.
2. Distributed message queue
一些分区分服的服务器架构,比如分上海服、北京服和杭州服等,一个分服同时在线人数可能不超过几万人,这样服务器架构差不多够用了。现在基本上很多大型游戏也使用这样的结构,但是对于全国同服或者全世界同服的大服务器结构下,这样的架构存在一个严重的单点问题,因为所有服务器间的消息都要通过这个全局服务管理器(Master)转发,这个服务管理器的压力非常大,只要它崩掉的话,那整个游戏都跑不起来,所以会将单点的消息队列换成分布式消息队列,以减轻单个消息队列的压力。现在外界使用比较广泛的分布式消息队列有kafka、rabbitmq和nats,这些都是工业级的消息队列,功能很完善,但游戏界为了性能和自定义化一些功能,通常是自己写分布式消息队列,比如将Master换成分布式Master。
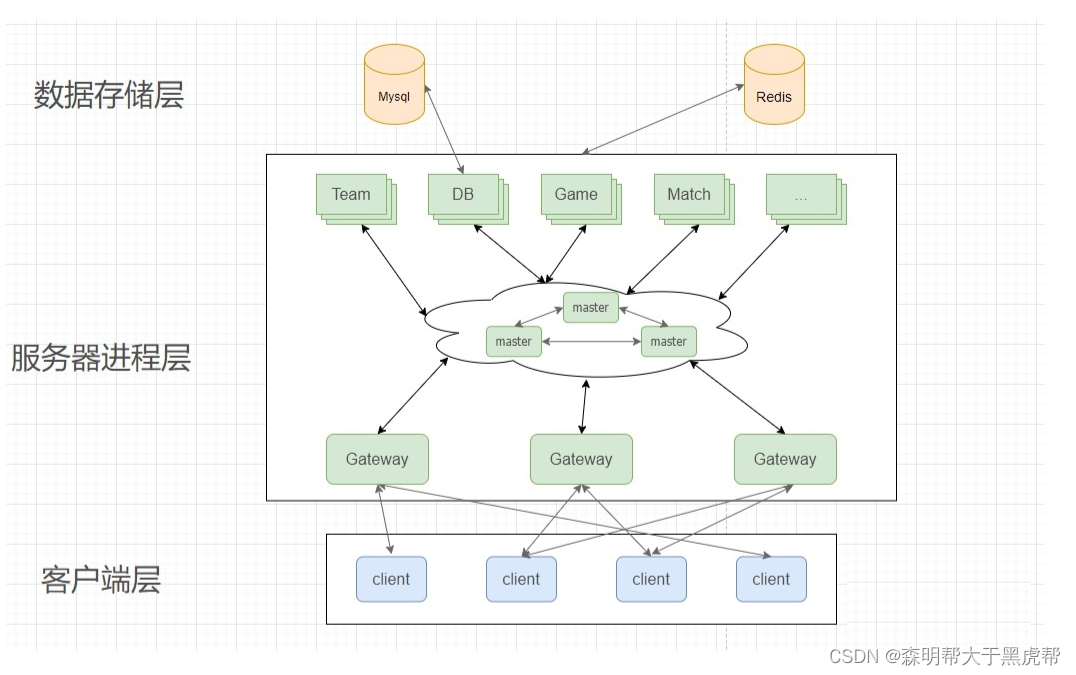
消息队列一般使用订阅/发布(sub/pub)模式,每个服务器向消息队列订阅自己要监听的主题(Topic),如果自己有消息发布(pub)的的话,就向消息队列发布,不用管向哪个服务器发布。自己订阅自己需要的,自己发布自己要发送的,很好的解耦了服务器间的耦合。
4.服务发现
消息队列由单点转换成分布式,消息队列也会从服务管理器中脱离出来,专心做消息转发的功能,那服务管理器中剩下的功能怎么办?剩下的其实就是服务发现的功能:存储各个服务器信息(IP地址,容量,服务器ID,服务器类型等)和管理服务器的增删等功能。
怎么理解服务发现的功能?我举一个实际例子。假设你的游戏已经上线,服务器也正在运行中,到了某个节日,游戏做了一个活动,这个活动做的太好了,吸引了一大批玩家,大量的玩家导致你原有的服务器撑不住,需要在线加服务器,这时候就会出现几个问题:原有的服务器怎么才能知道新加了服务器?新加的服务器怎么知道老服务器信息?服务发现就是要解决这样的问题。
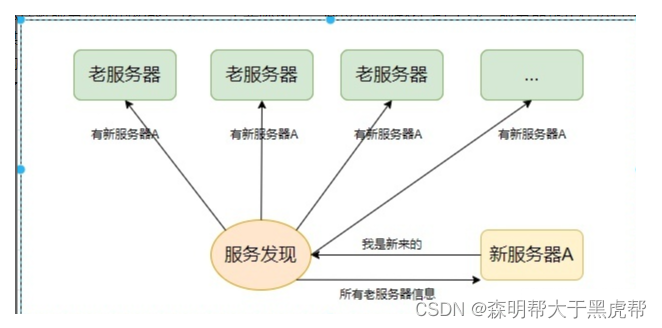
新加的服务器A向服务发现中心注册自己的信息,信息注册后,服务发现中心会将服务器A的信息广播给所有老的服务器,通知老服务器有新的服务器加进来,同时也会向新服务器A发送所有老服务器的信息。
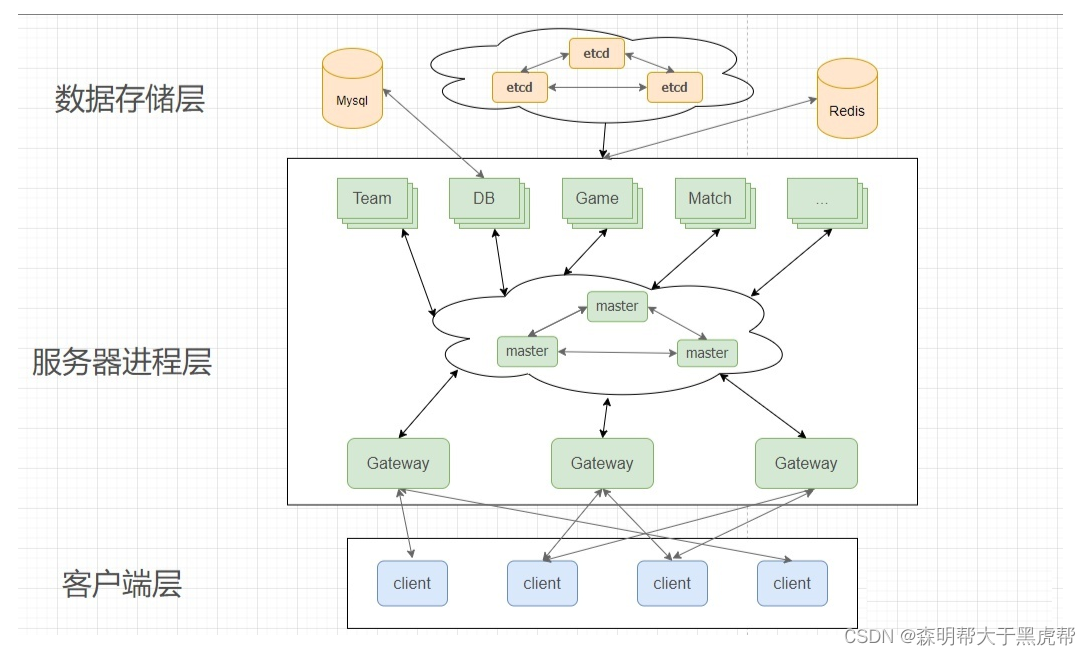
服务发现本质上是一类数据库,这类数据库为了保证数据的高可用会支持容错性。容错性一般由数据库备份保证,也就是一份数据会保存在多个机器上,保证了容错性又会带来一个新的问题,那就是多个机器上的数据是否一致,业务逻辑应该用哪个机器上的数据,数据一致性由一类共识性算法解决,比较出名的是paxos算法及其简化版raft算法,这类算法比较复杂,这里不细说,这两类算法的工业级软件实现是zookeeper和etcd。
5.负载均衡
什么是负载均衡?为什么要负载均衡? 每个服务器由一台计算机组成,单个计算机只有有限计算资源(CPU、内存和网络带宽),当大量玩家都往一个服务器中发送请求时,服务器因为计算不过来,大量请求数据积累超过内存,这样会直接导致计算机崩溃。虽然可以将服务器换成性能更好的服务器,但单个服务器性能受硬件的限制,计算的有限性很低,而且动态扩展性不强,比如线上要临时加计算资源时,不可能直接关服务器吧。所以一般都是通过软件方法,将输入的网络流量分配到多个计算机中,以平摊计算压力,这个软件方法就是负载均衡,总的来说负载均衡是高效的分配输入的网络流量到一组后端服务器。
一个游戏会有多个阶段需要用到负载均衡,这些阶段都有个共同点就是涉及到服务器的选择和变更。比如登录时要选择哪个服务器登录,RPG场景切换时服务器的切换,匹配成功进行战斗时等等,这些阶段都会涉及到负载均衡。负载均衡针对不同需求场景有不同的负载均衡方法,这里主要写登录服(Login)和网关服(Gateway)的负载均衡。
1.登录服务器的负载均衡
登录服务器是在线游戏的入口,没有登录服的话,你的游戏客户端进不去游戏,卡在登录页面。登录服的负载均衡方法大概可以分为两种,这两种方法与服务器的架构相关联的。第一类是分区分服的负载均衡,第二类是大服务器下的负载均衡方法,大服务器和分区服服务器主要的区别是:大服务器下所有人(全国或者全世界的人)可以一起比赛,不会出现同一个账号有不同数据,而分区分服的服务器是不同的登录服你的角色数据是不同的,比如你在北京服是100级,那你选择杭州服后是1级。分区分服和大服务器架构最本质的区别是是否公用了数据库。
1.分区分服
这类服务器会显示的让玩家选择在哪个服务器登录,比如在杭州服登录,比较典型的像王者荣耀这种就是使用这种方式,你进入游戏时会推荐几个空闲的服务器给你登录,如果选择已经爆满的服务器登录,会提示你服务器爆满,不能登录,这类负载均衡的方式是由玩家来决定的。
2.大服务器架构
大服务器架构下所有人都可以在一起比赛,在登录时也不会让你选服,只有一个登陆按钮,典型的像吃鸡这种游戏就是使用这种架构。那一个登录按钮是否意味着只有一个登录服务器?所有人都连一个服务器不会爆炸吗?其实登录服还是有多个的,只不过在登陆时客户端登录时程序会自动的帮你选择在哪个登录服登录,登录进去后,所有人共用同一组后端服务器和同一组数据库,所以全部人可以一起比赛。这类负载均衡方式是由客户端计算哪个服务器,计算的方法有很多,比较简单直接的就是在登录服中随机选择一个。
2.网关服务器的负载均衡
Login服务器是在线游戏的入口,通常为了更好动态的扩展服务器、减少向外界暴露内部服务器的入口以及承担更多人的登录逻辑,登录服务器所处理的逻辑很少,基本上是账号的验证、角色的创建和角色数据的加载,等账号验证完毕后,登录服根据负载均衡算法给玩家分配一个网关服务器,之后游戏的逻辑消息由网关服务器处理和转发。网关服务器的负载均衡方式通常是最小分配,也就是在一定阈值之上从现有的网关服务器中选择负载最小的一个。
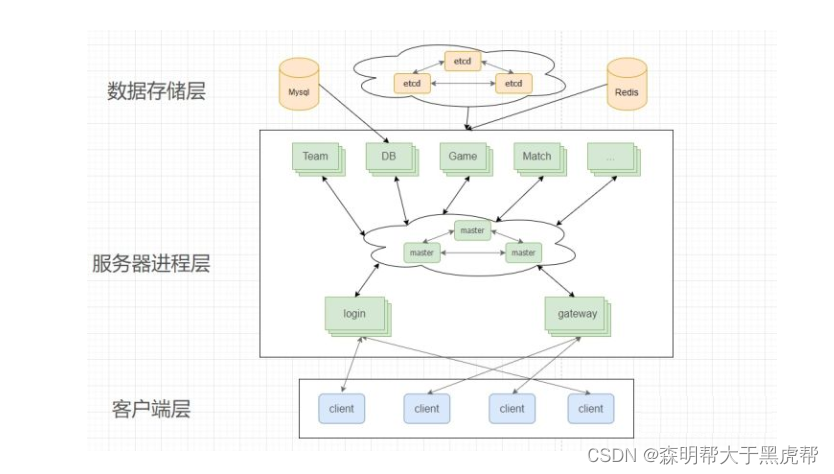
登录成功后,客户端会和登录服务器断开,以减少登录服务器压力以供其他人登录。
6.战斗服务器
上面的服务器基本上是一个大型房间类游戏服务器的完整结构了,网关服务器用来转发消息,各类内部服务器用来处理各个游戏功能的逻辑。但是所有类型的游戏功能都要经过网关服务器来转发到后端服务器吗?比如游戏的实时战斗功能,像体育竞技,吃鸡,王者荣耀的战斗。如果这类对于实时性要求非常高的战斗功能也经过网关服务器的转发的话,产生的延时是非常高的,你释放一个技能,对面半天才掉血,这非常影响战斗体验。所以一般会有一类战斗服务器(Battle),客户端直接连接战斗服务器(Battle),不用网关服务器的转发。
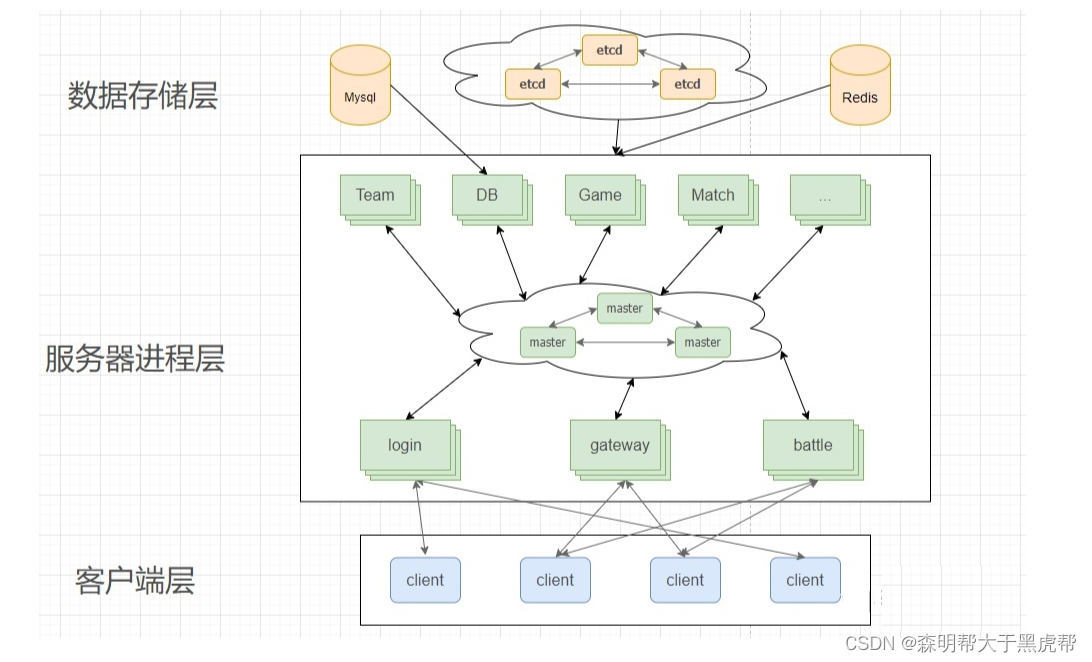
四、分布式存储
由于大型服务器数据量比较大,最终的DB和Redis也会换成分布式数据库。下图是现在房间型游戏服务器主要结构。
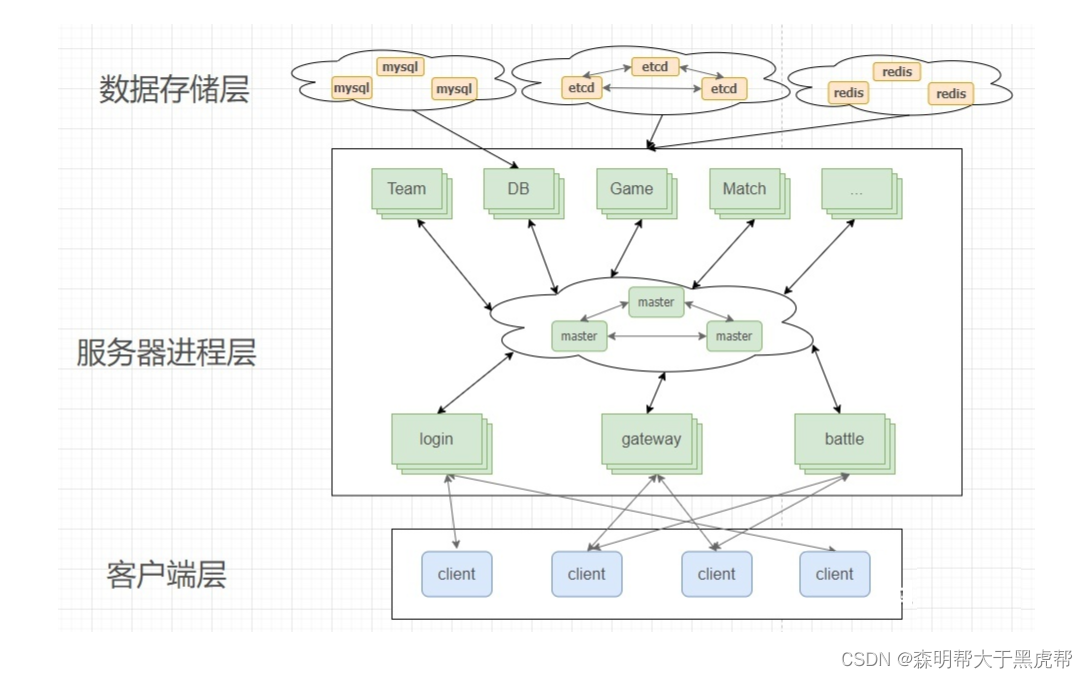
五、游戏服务器的未来
玩家习惯的变迁是个缓慢的过程,因此游戏玩法在短时间内也不会有大的变化,这也会导致游戏逻辑服务器架构也不会发生太大的变化。2003年魔兽无缝大世界出来时,刷新了大家对服务器的认知,但是这类游戏服务器架构出来还是太早了,到现在用无缝大世界的游戏也非常少,个人认为无缝大世界在近期不会有太大的发展。
从服务器历史发展来看,服务器发展趋势主要取决于玩家游戏需求以及上下游技术产业链。游戏内容的越来越精细,互联网传输量的越来越大以及云计算的发展壮大,个人认为未来服务器发展是游戏上云以及云游戏。
六、游戏上云
先前的游戏服务部署都需要经历两个阶段,一个阶段是服务器硬件的采购以及服务器部署的配置,另一个阶段是服务器的长期运维。服务器采购以及部属配置的整个流程可能需要数个月之久,而且服务部署配置后需要专门的专家进行管理,这些流程对于一些中小型公司来说是很繁杂的,会造成很大的成本问题,这也就催生出了云计算。
云计算是一种基于互联网的计算方式,通过这种方式,共享的软硬件资源和信息可以按需求提供给计算机各种终端和其他设备,使用服务商提供的电脑基建作计算和资源。有了云计算后,公司可以快速购买和配置所需的服务资源,从而花更多的资源在产品本身上。
游戏上云需要两个技术,一个是虚拟化技术。虚拟化技术是一种资源管理技术,是将计算机的各种实体资源,如服务器、网络、内存及存储等,予以抽象、转换后呈现出来,打破实体结构间的不可切割的障碍,使用户可以比原本的组态更好的方式来应用这些资源。这些资源的新虚拟部份是不受现有资源的架设方式,地域或物理组态所限制。另一个是服务编排技术,一个游戏服务的数量可能有成百上千个,而且不同的服务可能分布在不同机器上,这会给服务管理造成很大的困难,所以需要服务编排技术来解决。
1.Docker
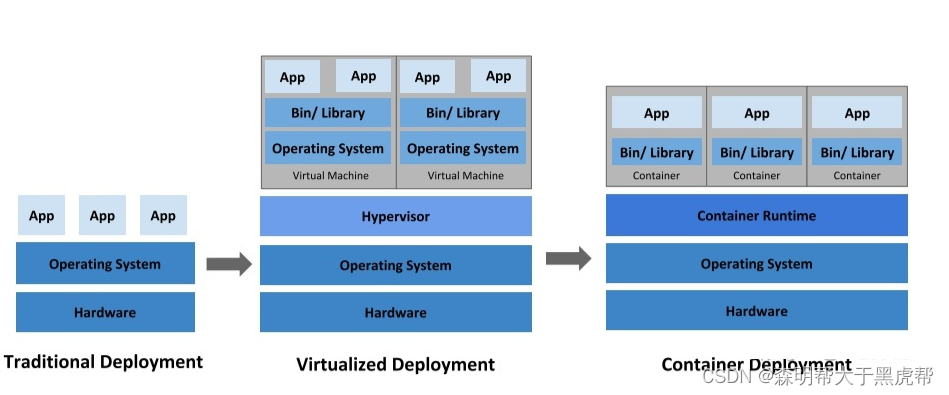
主要是三个部署方式,传统部署、虚拟机部署以及容器部署
1.传统部署
比较典型的游戏部署方式是服务器运行某个操作系统(如Ubuntu),然后各个游戏服务以进程的方式直接运行在操作系统上,因为每个进程有自己的地址空间,所以服务间的内存空间是隔离的。这种部署方式的优点是简单直接,服务没有额外的一些运算,可以极大化的利用运算资源。但这种部署方式很难限制同一台物理机上每个服务的资源使用(CPU内核的分配),存在资源争夺情况,很可能因为某个服务占用较大的计算资源导致其他应用不能正常服务,而且因为服务在同一个宿主操作系统中,各个服务可以通过读取文件感知到对方的存在,存在很大的安全隐患问题。
2.虚拟机部署
一台专用服务器的CPU内核数可能有上百个或者上千个,为了更好利用一台服务器的计算资源,避免不合理的竞争,所以引入一种完全虚拟化技术。虚拟化技术允许在物理机上同时运行多个次级操作系统。我之前用的比较多的虚拟软件是VMware,VMware使用Hypervisor对硬件资源进行虚拟化,在使用VMwave的时候需要配置虚拟机的CPU、内存和网络等资源,配好后在虚拟机中安装对应的操作系统和软件。每台虚拟机可以配置自己要使用的资源,各个虚拟机的资源互不干扰,有一个很好的隔离效果,但是虚拟机需要安装完整的操作系统,导致非常笨重。
3. 容器部署
比虚拟机更轻量级的是容器技术,如Docker。容器与虚拟机的主要差别是隔离层不一样,虚拟机在物理层面上进行隔离,然后在之上安装操作系统,容器是直接运行在宿主操作系统上,并不需要在额外安装操作系统。Docker使用Linux隔离技术(CGroup和Namespace)来隔离各个服务,并直接调用操作系统的系统调用接口,从而降低每个容器的系统开销,实现降低容器复杂度、启动快、资源占用小等特征。
虚拟机和容器都使用镜像来存储运行环境。对于Docker来说,应用的源代码与它的依赖都打包在Docker镜像中。一个游戏产品生命周期通常要经过开发团队、测试团队和运维团队。早前没有这样的容器时候,服务的交付和升级都会导致多个团队重复性的安装新的依赖环境,而且一些老上线运营的游戏都不敢轻易升级服务,生怕环境不一致导致服务运行不起来。Docker的出现很好的解决了环境问题,环境一次配置各地运行,这也降低了各个团队的交付成本。
2.Kubernetes
Docker容器本身适合运行单个服务,但一个游戏的服务有可能上千个或者上万个,这些服务可以分布在不同物理机上。如果只有几个容器,那管理是非常简单的,但当容器有成千上万个的时候,很可能会导致容器管理和编排变得非常困难。对于一些大公司来说,因为要经常维护大型服务器集群,所以都会有自己写的一套集群管理方案,这些方案包含服务资源配置、服务资源使用监控、健康状态检查以及服务的负载均衡等。
1.Kubernetes在游戏界的使用
2014年Google开源了自己的容器编排与管理工具Kubernetes,Kubernetes开始逐步在互联网界扩散,2017年之后大量互联网公司开始应用Kubernetes。但奇怪的是游戏界到现在其实也很少游戏服务使用Kubernetes部署,难道是因为技术原因吗?这个问题其实还有个大学老师专门写了篇论文来探讨(https://www.diva-portal.org/smash/get/diva2:1562637/FULLTEXT01.pdf),给出的结论是没有技术原因,只是因为习惯问题。结合自己在游戏界的经验,这个结论是正确的,当然还有一些游戏特性原因,游戏相对于互联网产品的主要差异是游戏对网络延时要求更高,使用Kubernetes的话会因为一些额外配置带来网络延时和处理延时。
之前游戏部署更多的是使用脚本部署,一些Kubernetes主要支持的特性,如服务状态监控和负载均衡功能,其实是游戏服务内部功能就要支持的,并不需要外部工具在单独支持,再加上一些大型游戏公司的产品已经上线很久了,相应的服务部署工具也会不断针对性完善,有了更熟悉的专用部署工具,而且Kubernetes本身是有上手成本的,一堆新概念要学习,所以游戏界应用Kubernetes需要一定的过度时间。当然,现在的一些新游戏都开始使用Kubernetes部署,像网易雷火的各个新游戏也都用Kubernetes部署,使用Kubernetes部署可以更方便接入公有云,动态创建游戏服务,更合理分配服务计算资源。
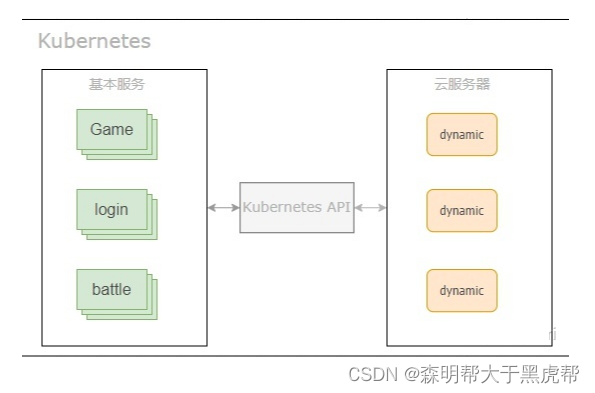
2.Kubernetes基本概念
Kubernetes的核心概念是pod,一个pod包含一个或者多个共享存储和网络的容器,以及怎样运行这些容器的规范,pod是Kubernetes上最小的部署单元,其他的一些工作负载是多个pod的扩展组合。一个pod典型包含一个运行游戏服务的容器以及一些额外的监控容器和发送log服务容器。
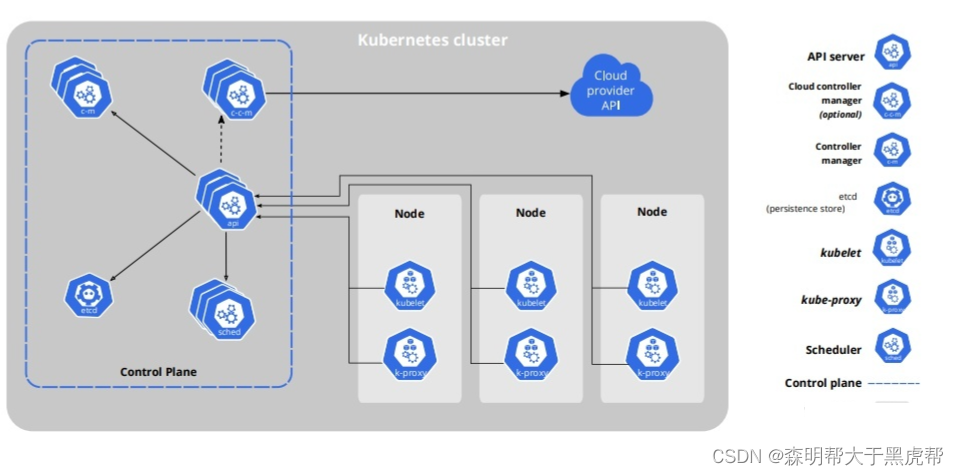
Kubernetes使用YAML来定义pod如何运行,如pod名字、使用端口以及IP、CPU和内存限制。Kubernetes的整个架构图如下。
七、云游戏
云游戏现在使用越来越广泛,以下会总结什么是云游戏,怎么实现云游戏以及目前云游戏的主要问题点和解决方案。
1.什么是云游戏
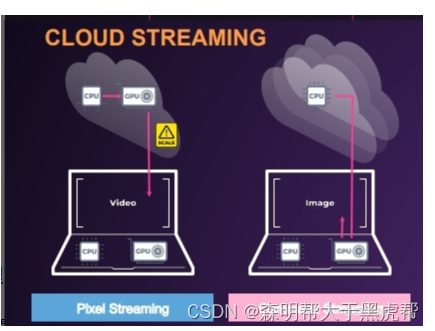
随着云计算的发展,基于云的一种游戏新形态也被提出,那就是云游戏。云游戏是游戏运行逻辑以及画面渲染由远端的服务器来完成,玩家设备不用在下载安装游戏软件,只用从服务器接收音视频流并在设备上播放。因为玩家设备并不用运行游戏,所以玩家可以在任何地方用手机这种低性能的设备玩3A主机游戏。云游戏跟传统游戏运行的最大差别是游戏是否用本地设备的GPU渲染游戏画面。
2.云游戏工作原理
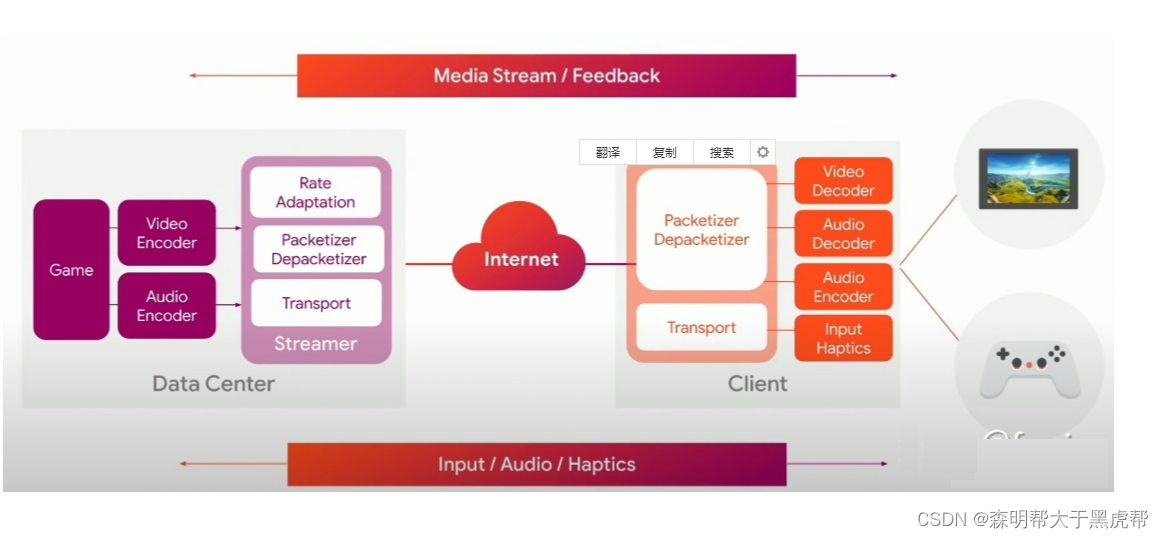
云游戏主要的工作是将服务器的游戏音视频传输到玩家播放设备上,就跟看电视差不多,不过云游戏跟电视的一个主要区别是:云游戏是有交互的,画面需要根据交互来显示,也就是需要实时渲染。大致的实现结构如下,下图也是Google云游戏平台Stadia的工作流程。首先是对服务器游戏的音视频截取并将其编码成流媒体数据,然后使用传输协议将数据传输到玩家设备上,玩家设备将数据解码并将其播放。
1.画面截取
画面截取的方法很多,不同显示驱动软件或者不同操作系统有不同的画面截取方法,比如GDI 抓图、BitBit、DDA(Desktop Duplication API)、IDD(Indirect Display Driver)、DXGI等等,DXGI是Windows系统中用户模式下最底层的图形设备接口,可以直接获取显示器的内容。
2.音视频编解码
游戏视频数据根据不同游戏画面刷新频率和分辨率有不同的大小,但通常都是很大,所以在网络上传输时都会使用视频压缩编码,目前使用比较广泛的是H.264编码格式,H264有参考帧的运动补偿、帧内预测等新特性,视频质量更高,码率更低。相较于H.264编码,最新的是H.265编码,H265在架构上与 H264 相似,但H265在图像分块、变换编码、预测编码、熵编码等模块上提出了更优的算法,提高了编码的压缩率、鲁棒性,在相同画质的情况下理论上 H265能比H264节省一半的带宽。H.264已经在手机、平板和浏览器上支持。音频一般使用opus或aac来编码。
3.数据传输
视频和音频编码后得到一个个数据块,然后将数据块传输到客户端上。Google的Stadia直接使用WebRTC传输音视频数据。当然也可以直接使用原生TCP、UDP和KCP协议传输,对于一些实时性较高的产品,比如强竞技游戏,可以使用KCP传输,KCP传输数据要比TCP要快。相对来说流视频使用UDP传输会更合适,因为游戏画面对准确性要求不高但是对实时性要求高。
4.画面显示与输入采集
传输过来的数据块解码后得到原始的画面和声音,然后使用SDL呈现画面和声音。云游戏显示质量可以分为分辨率以及帧率。良好的云游戏画质需要高分辨率(至少1080P),实现分辨率的提升需要编解码算法以及硬件能力的提升。游戏的每一帧图片是实时渲染的,每秒显示在显示器上的画面数量,决定了云游戏的体验(至少60FPS)。玩家的操作,比如键盘、鼠标、手柄等外设的信息采集也可以通过SDL实现,收集后将数据传给服务器。
3.云游戏延时
实现一个能运行的云游戏平台其实不难,现有的技术基本上很容易达到,但为什么现在很少人用云游戏平台玩游戏了?抛开什么商业模式和服务器成本不说,其中的主要原因是云游戏有很大的网络延时,这样的延时很影响游戏体验,尤其是一些对延时比较敏感的实时竞技游戏。2019年网易雷火的一位引擎大佬参加GDC时,现场测试了google Stadia云游戏平台的延时,整个延时大概在200ms左右(https://zhuanlan.zhihu.com/p/59924374),云游戏带来的额外延时是70ms左右,从视频上来看延时还是很明显的。据研究表明,游戏延时需要保持在150ms以下才会有一个较好的体验。
对于传统的在线游戏来说,延时是一个常见问题,比如移动延时。移动延时可以通过游戏逻辑来降低,比如影子跟随这类根据轨迹推算的算法。然而,这类算法并不适用于云游戏,因为云游戏仅仅传输游戏画面,没有游戏逻辑状态。那么是什么造成了云游戏的网络延时了?现在又有哪些解决方案了?
1.延时的主要原因
造成云游戏延时主要原因可以分为三类:
- 网络延时:玩家操作信息发送到服务器以及客户单接收到服务器音视频流总共时间。
- 播放延时:玩家设备接收到编码数据后到解码数据并将其显示到屏幕上的延时。
- 处理延时:服务器接收到玩家命令处理命令并返回相应视频的时间。
1.网络延时
现在云游戏体验最大的问题是网络延时问题,网络延时的主要原因是网络包在路由器上路由,网络包所经过的路由器越多,那么网络延时也会越大。由于云游戏基于云计算发展,云计算服务器分布在不同地理区域上,所以可以用云计算来选择离玩家最近服务器来降低延时,这类服务器被称为边缘节点(Edge node),所形成的技术就是边缘计算。厂家将游戏部署在边缘节点上,玩家在请求云游戏时,根据每个边缘节点的延时和负载量来选择延时最低的节点进行服务。根据Google Stadia的设计者表述,Stadia有7500个边缘节点部署在合作的ISP厂商中。
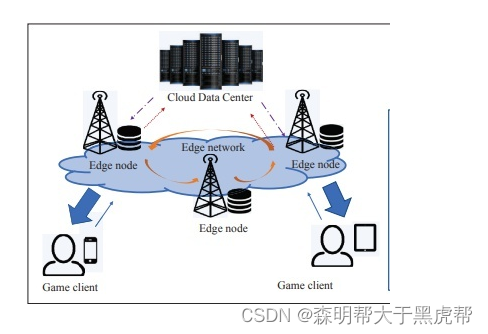
边缘计算缩短了服务器到玩家的距离,5G技术解决云游戏传输数据量问题,5G提供10Gbps以上的峰值速率、更佳的移动性能、毫秒级时延和超高密度连接。这样的技术很好的满足了云游戏的低延时和高带宽的需求,因此5G技术的普及也会促进云游戏的进一步发展。
2,播放延时
播放延时主要取决于视频编解码以及视频压缩技术,目前使用广泛的是H.264格式,像Stadia也是支持这个的。对于移动云游戏来说H.264还是不够,主要的原因是,移动设备需要在严格的延迟要求下传输大量的数据,包括高质量和高帧率的图形,这就会要求移动设备需要由一个更高的带宽。
除了视频压缩技术之外,Stadia为了降低延时提出负延时(Negative Latency)技术,这个技术使用马尔科夫链预测玩家在未来几帧内的输入,并且渲染对应的画面返回给客户端,如果在错判时给出补偿(快速隐藏错误的渲染)并且调整输入渲染。负延时技术对一些单机游戏来说比较友好,但是对于一些网络游戏来说比较难应用,因为游戏变量不仅仅只有当前玩家的输入。
3.处理延时
For rendering a game screen, you must choose the best GPU for rendering, and the resulting delay is also low. But considering the cost, it is impossible for any game to use the best GPU for rendering, such as some 2D games with low rendering requirements. At present, a large part of the continuous loss of cloud game manufacturers comes from the unreasonable use of hardware configuration, so on the premise of ensuring the game experience, reasonable scheduling of the hardware configuration of the server can reduce costs and increase the revenue of enterprises.
Virtualization plays a vital role in consolidating gaming resources and reducing hardware costs. So far, CPU, network interface and data storage virtualization technology has developed very mature, typically like Docker container technology. But GPU is an exception. Previously, researchers proposed a new GPU algorithm "vGPU" for virtual machines. The basic idea of "vGPU" is to divide GPU computing resources into multiple blocks and introduce CPU in graphics processing. To make up for the loss of GPU computing resources.
GPU virtualization can increase the game concurrency capability of the server and enhance the computing power of the virtual machine. The issue of GPU virtualization is one of the biggest obstacles preventing cloud gaming from achieving satisfactory latency and response time.
Summarize
The above is the history, present and future of the current game server architecture (cloud games). Due to the too many contents involved, the related network IO and memory model of the server are not introduced. I will talk about this part in detail in the future. It is very convenient, we must master it. Hope you all support! In addition, if there are any problems with the above, please understand my brother's advice, but it doesn't matter, the main thing is that you can persevere, and I hope that there are classmates who study together to help me correct me, but if you can please tell me gently, love and peace are eternal themes , love you all. Come on!
