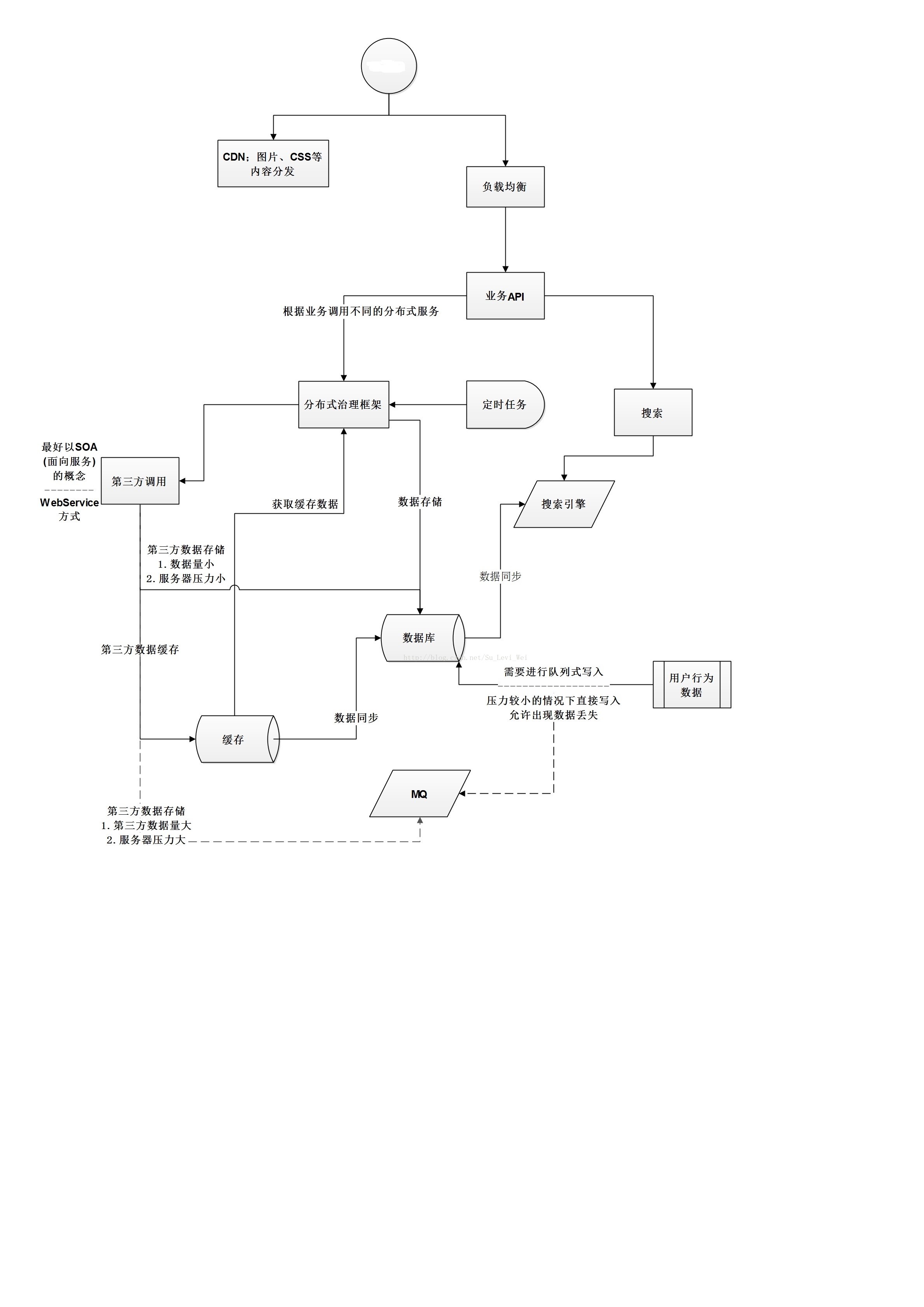
High concurrency needs to be refined, then it is divided into front-end, middle-end, and back-end. I believe everyone will be very puzzled why there are different front, middle, and back ends. Of course, everyone has a different understanding of high concurrency, technology, and architecture. Therefore, everyone's definition is different. After all, these are theoretical definitions. As long as the application is correct in actual business scenarios, the definitions are correct no matter what.
The core of high concurrency lies in the cluster, and the processing capacity is improved through the cluster. The following are all cluster-based architectures.
front end
The front-end is mainly for page access processing. At present, the general solution is to use Nginx. Because the price of F5 is too expensive, I will not elaborate here.
Nginx can forward requests from the front-end, proxy the back-end servers, and perform load balancing in the face of concurrent requests and in a cluster architecture.
Case: The front-end page is rendered using HTML+CSS, and Node.js is used to write simple business logic. If there is complex business logic, the back-end server is requested to process it, then the front-end only needs to pay attention to the rendering of the page, and Nginx only needs to It is necessary to pay attention to the forwarding of the request packet, perform load balancing processing on the request, and return the front-end page to the requester.

Middle
I believe everyone will be very confused, what does the mid-range mean?
The middle end refers to the middle layer, that is, the layer of business logic processing. In the face of a large number of high concurrent request processing, the middle end generally caches commonly used business data, and processes a large number of requests after the cache is completed. Multi-threaded batch processing.
Mid-end business processing also includes a series of operations such as manipulating data. There are many solutions here. You can improve performance through middleware, or the SparkSQL component of Mongodb+Spark, etc. There are a lot of these on Baidu, but there are not many. expounded.

rear end
The back-end mentioned here is the operation of the database. A large number of data operations are already involved in the middle-end data. However, in the face of so many concurrency, the performance of the database will drop drastically, so how to ensure the performance of the database?
Or another way of thinking, how to quickly obtain the data required by the business, or store the data generated by the business?
Sub-library sub-table, these old routines will not say more.
Find a special person to do special work. For example, the ES search engine is very fast when searching, so if you use ES as a cached data to search for data, will it work?
If Redis is a cache database, then use Redis to store data, or open an additional thread to store data, or use Mongodb to store data, and synchronize to MySQL database after setting a timer to a certain time.
But there is a synchronization problem involved here, please continue to pay attention to this blog.