[From: https://www.cnblogs.com/OldJack/p/6658779.html]
1. What is coding
Encoding refers to the process of converting information from one form or format to another.
In computers, coding, in a nutshell, is the conversion of information that a human can understand (often called plaintext) into information that a computer can understand. As we all know, what computers can read is high and low levels, that is, binary bits (0, 1 combination).
Decoding refers to converting the information that the computer can understand into the information that the human can understand.
2. The origin of coding
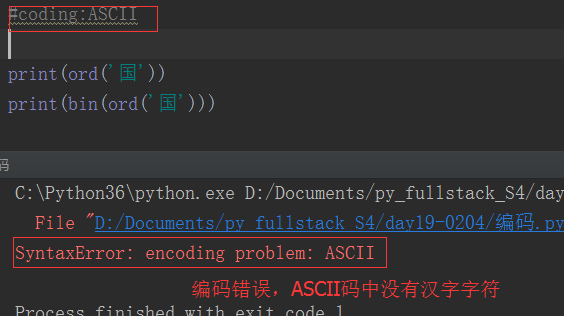
As mentioned in the previous blog, since computers were first invented and used in the United States, people used ASCII encoding at the beginning. ASCII encoding occupies 1 byte, 8 binary bits, and can represent up to 2**8=256 characters.
With the development of computers, ASCII code can no longer meet the needs of people in the world. Because there are many languages in the world, there are far more than 256 characters. So each country engages in the encoding of its own country on the basis of ASCII.
For example, in China, in order to deal with Chinese characters, the GB2312 code was designed, and a total of 7445 characters were included, including 6763 Chinese characters and 682 other symbols. The Chinese character extension specification GBK1.0 in 1995 included 21,886 symbols. GB18030 in 2000 is the official national standard to replace GBK1.0. The standard includes 27,484 Chinese characters, as well as Tibetan, Mongolian, Uyghur and other major minority languages.

However, in terms of coding, countries are "separate" and it is difficult to communicate with each other. Hence the emergence of Unicode encoding. Unicode is a character encoding scheme developed by an international organization that can accommodate all the characters and symbols in the world.
Unicode stipulates that characters are represented by at least 2 bytes, so at least 2**16=65536 characters can be represented. In this way, the problem seems to be solved, people of all countries can add their own words and symbols to Unicode, and they can communicate easily from now on.
However, at that time, when the memory capacity of the computer was a lot of money, North American countries such as the United States did not accept this code. Because this increases the size of their files out of thin air, which in turn affects memory usage and affects work efficiency. This is embarrassing.
Obviously, international standards are not welcome in the United States, so utf-8 encoding came into being.
UTF-8 is the compression and optimization of Unicode encoding. It no longer requires at least 2 bytes, but classifies all characters and symbols: the content in ASCII code is stored in 1 byte, European characters Save with 2 bytes, East Asian characters with 3 bytes.
In this way, everyone gets what they want, and everyone is happy.
3. How utf-8 saves storage space and traffic
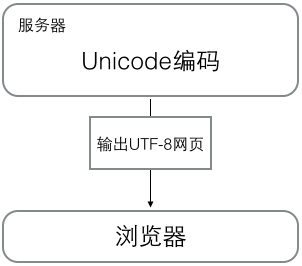
When the computer is working, the data in the memory is always represented by the Unicode encoding. When the data is to be saved to the disk or transmitted over the network, the utf-8 encoding will be used for operation.
In the computer, the unicode character set of "I'm Jack" is the encoding table like this:
I 0x49 ' 0x27 m 0x6d 0x20jie 0x6770g 0x514b _ _
Each character corresponds to a hexadecimal number (for people to read, 0x represents a hexadecimal number), but the computer can only read binary numbers, so the actual representation in the computer is as follows:
I 0b1001001 ' 0b100111 m 0b1101101 0b100000 Jay 0b110011101110000 g 0b101000101001011
I 00000000 01001001 ' 00000000 00100111 m 00000000 01101101 00000000 00100000 Jie 01100111 01110000g 01010001 01001011
This string of characters occupies a total of 12 bytes, but comparing the Chinese and English binary codes, it can be found that the first 9 digits of English are all 0, which is a waste of space and traffic.
See how utf-8 is resolved:
I 01001001 ' 00100111 m 01101101 00100000 Jie 11100110 10011101 10110000g 11100101 10000101 10001011
UTF-8 uses 10 bytes, which is 2 bytes less than Unicode. However, Chinese is rarely used in our programs. If 90% of the content in our program is in English, 45% of storage space or traffic can be saved.
Therefore, when storing and transmitting, most of the time follow utf-8 encoding

4. Encoding and decoding in Python2.x and Python3.x
1. In Python2.x, there are two types of strings: str and unicode. str stores bytes data, unicode type stores unicode data
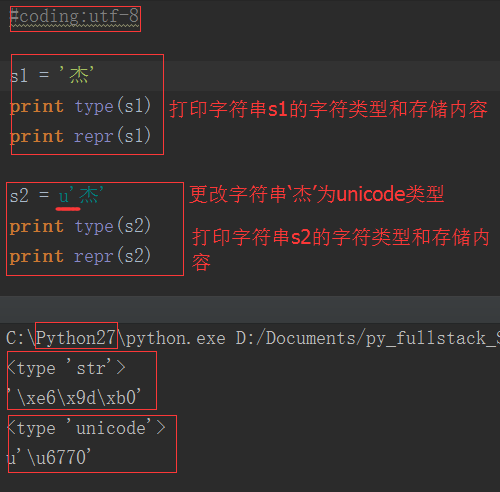
As can be seen from the above figure, str type stores hexadecimal byte data; unicode type stores unicode data. UTF-8 encoded Chinese occupies 3 bytes, and unicode encoded Chinese occupies 2 bytes.
Byte data is often used for storage and transmission, and unicode data is used to display plaintext. How to convert the two data types:
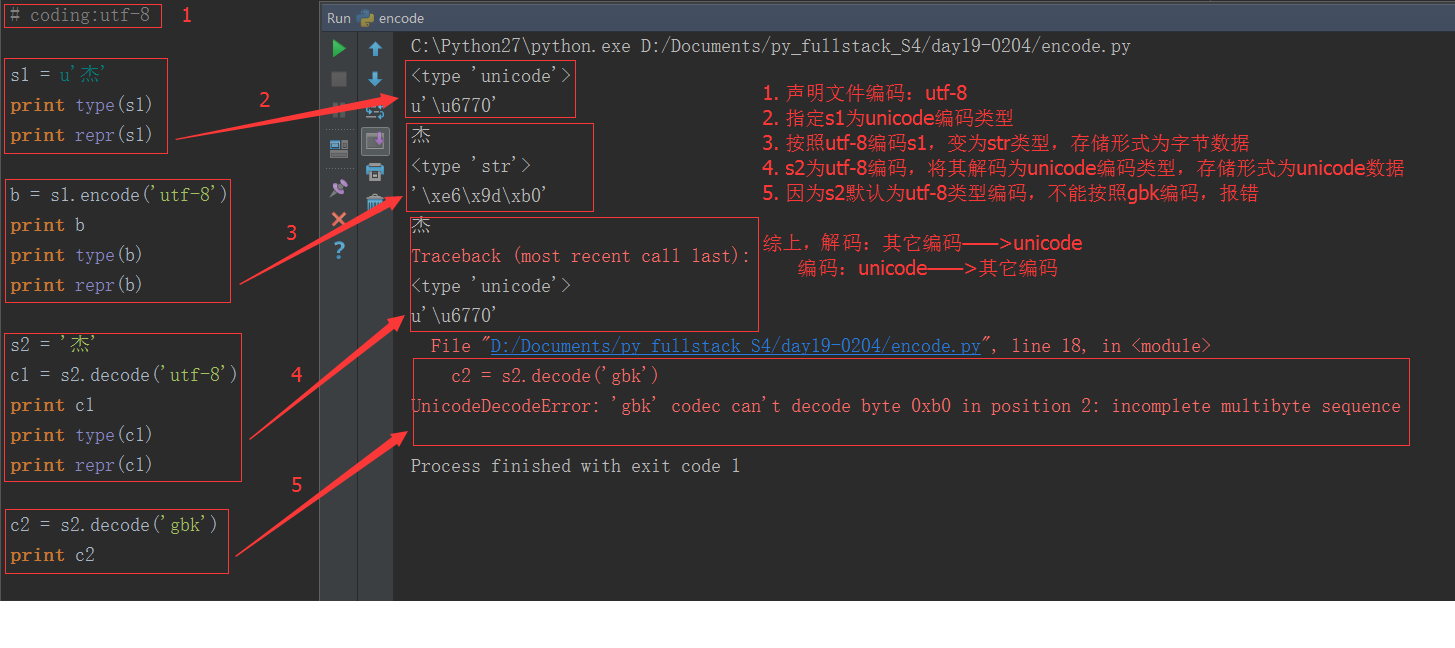
Either utf-8 or gbk is just an encoding rule, a rule for encoding unicode data into byte data, so utf-8 encoded bytes must be decoded with utf-8 rules, otherwise garbled characters will appear Or report an error.
Features of python2.x encoding:
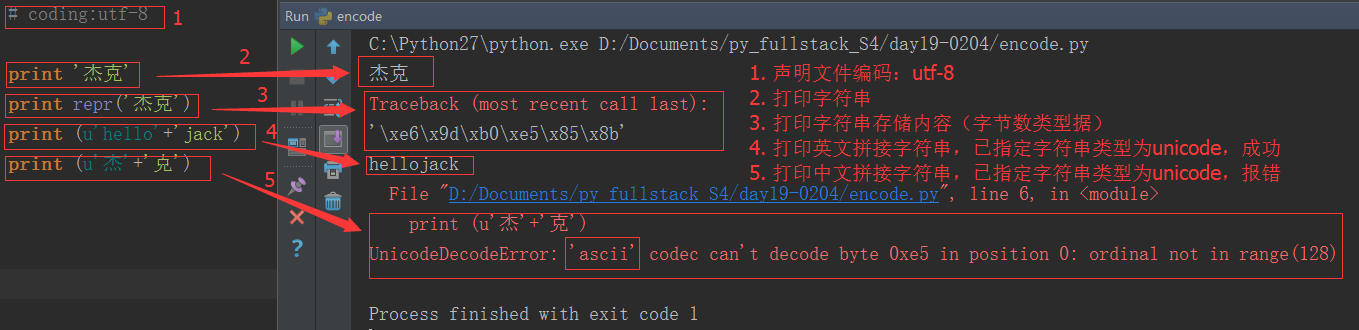
Why does the English splicing succeed, but the Chinese splicing report an error?
This is because in python2.x, the python interpreter silently covers up the conversion from byte to unicode. As long as the data is all ASCII, all conversions are correct. Once a non-ASCII character sneaks into your program, then the default The decoding will fail, resulting in a UnicodeDecodeError error. The python2.x encoding makes it easier for programs to deal with ASCII. The price you pay is that you will fail when dealing with non-ASCII.
2. In Python3.x, there are only two types of strings: str and bytes.
The str type stores unicode data, and the bytse type stores bytes data. Compared with python2.x, the name is just changed.
Remember this sentence mentioned in the previous blog post? ALL IS UNICODE NOW
python3 renamed the unicode type to str ,the old str type has been replaced by bytes.

Probably the most important new feature of Python 3 is a clearer distinction between text and binary data, and no automatic decoding of bytes strings. Text is always Unicode, represented by the str type, and binary data is represented by the bytes type. Python 3 doesn't mix str and bytes in arbitrary implicit ways, which is what makes the distinction between the two especially clear. You can't concatenate strings and bytes packets, you can't search for strings in bytes packets (and vice versa), and you can't pass strings to functions that take bytes packets as arguments (and vice versa).
Note: Regardless of python2 or python3, the unicode data directly corresponds to the plaintext, and printing the unicode data will display the corresponding plaintext (including English and Chinese)
5. Encoding of files from disk to memory
When we are editing text, the characters in memory correspond to unicode encoding, because unicode covers the widest range, and almost all characters can be displayed. But how does the data change when we save text etc on disk?
The answer is a byte string of bytes encoded by some encoding. For example, utf-8, a variable-length encoding, saves space very well; of course, there are gbk encoding of historical products and so on. Therefore, in our text editor software, there are default encoding methods for saving files, such as utf-8, such as gbk. When we clicked save, these editing software had "silently" done the coding for us.
Then when we open the file again, the software silently decodes the data for us, decodes the data into unicode, and then presents the plaintext to the user! So, unicode is the data closer to the user, and bytes is the data closer to the computer.
In fact, the python interpreter is also similar to a text editor, it also has its own default encoding. The default ASCII code of python2.x and the default utf-8 of python3.x can be queried as follows:
import sys print(sys.getdefaultencoding())
输出:ascii
If we don't want to use the default interpreter encoding, we need the user to declare it at the beginning of the file. Remember the declarations we often made in python2.x?
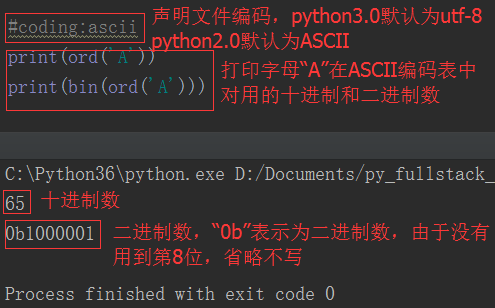
#coding:utf-8
If the python2 interpreter executes a utf-8 encoded file, it will decode utf-8 with the default ASCII. Once there is Chinese in the program, the decoding will be wrong, so we declare #coding:utf- at the beginning of the file. 8. In fact, it tells the interpreter that you should not decode the file with the default encoding, but decode it with utf-8. The python3 interpreter is much more convenient because of the default utf-8 encoding.
References
1. http://www.cnblogs.com/yuanchenqi/articles/5956943.html
2. http://www.cnblogs.com/284628487a/p/5584714.html