There are two types of index data structures commonly used in MySQL: B+ tree index and hash index. Let's take a look at the difference between these two index data structures and their different application suggestions.
difference between the two
Remarks : Let me first say that in the MySQL document, the B+ tree index is actually written as BTREE , for example, it is written like the following:
CREATE TABLE t(
aid int unsigned not null auto_increment,
userid int unsigned not null default 0,
username varchar(20) not null default '',
detail varchar(255) not null default '',
primary key(aid),
unique key( uid) USING BTREE ,
key (username(12)) USING BTREE - here the uname column only creates a partial index with the leftmost 12 characters in length
) engine=InnoDB;
A classic B+ tree index data structure is shown in the following figure: (The picture comes from the network)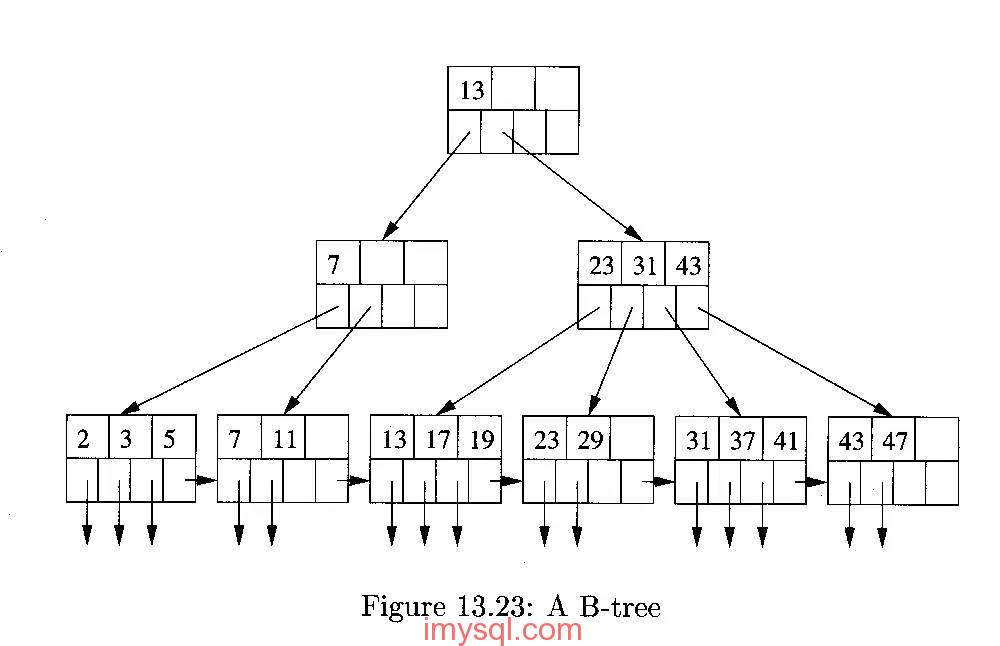
The B+ tree is a balanced multi-fork tree, the height difference from the root node to each leaf node does not exceed 1, and the nodes at the same level are linked by pointers.
In the conventional search on the B+ tree, the search efficiency from the root node to the leaf node is basically the same, and there will be no large fluctuations. Moreover, during the sequential scan based on the index, the bidirectional pointer can also be used to quickly move left and right, which is very efficient.
Therefore, B+ tree indexes are widely used in scenarios such as databases and file systems. By the way, one of the reasons why the xfs file system is much more efficient than ext3/ext4 is that its file and directory index structures all use B+ tree indexes, while the file directory structure of ext3/ext4 uses Linked list, hashed B-tree , Extents/Bitmap and other index data structures, so under high I/O pressure, its IOPS capability is not as good as xfs.
For details, see:
https://en.wikipedia.org/wiki/Ext4
https://en.wikipedia.org/wiki/XFS
The schematic diagram of the hash index is like this: 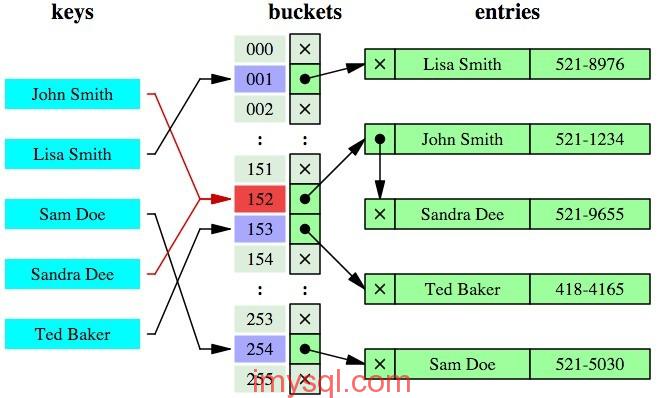
(picture from the network)
Simply put, a hash index uses a certain hash algorithm to convert the key value into a new hash value. When searching, it does not need to search from the root node to the leaf node level by level like a B+ tree, only one hash algorithm is needed. You can locate the corresponding position immediately, and the speed is very fast.
From the above figure, the obvious difference between B+ tree index and hash index is:
- If it is an equal-value query, then the hash index obviously has an absolute advantage , because the corresponding key value can be found only after one algorithm; of course, the premise is that the key value is unique. If the key value is not unique, you need to find the location of the key first, and then scan backwards according to the linked list until the corresponding data is found;
- It can also be seen from the schematic diagram that if it is a range query retrieval, the hash index is useless at this time , because the originally ordered key value may become discontinuous after the hash algorithm. There is no way to use the index to complete the range query retrieval;
- In the same way, the hash index cannot use the index to complete the sorting , and some fuzzy queries like 'xxx%' (this kind of partial fuzzy query is actually a range query in essence);
- The hash index also does not support the leftmost matching rule of the multi-column joint index ;
- The keyword retrieval efficiency of the B+ tree index is relatively average, and it does not fluctuate as much as the B tree. In the case of a large number of duplicate key values, the efficiency of the hash index is also extremely low, because there is a so-called hash collision problem .
postscript
In MySQL, only HEAP/MEMORY engine tables can explicitly support hash indexes (NDB also supports this, but this is not commonly used), and the adaptive hash index of the InnoDB engine is not listed here, because this is not an index creation can be specified.
It should also be noted that the data of the HEAP/MEMORY engine table will be lost after the mysql instance is restarted.
Generally, the B+ tree index structure is suitable for most scenarios, and it is more advantageous to use a hash index in the following scenarios:
In the HEAP table, if the stored data has a low degree of repetition (that is to say, the cardinality is large), the column data is mainly equivalence query, and there is no range query and no sorting. Hash index is especially suitable.
For example this SQL:
SELECT … FROM t WHERE C1 = ?; — only equality query
In most scenarios, there will be query features such as range query, sorting, and grouping, and B+ tree indexing is sufficient.