Understanding MySQL - Indexing and Optimization
Reprinted from: http://www.cnblogs.com/hustcat/archive/2009/10/28/1591648.html
Written before: Indexes have a crucial impact on the speed of queries, and understanding indexes is also the starting point for database performance tuning. Consider the following situation, assuming that a table in the database has 10^6 records, the page size of the DBMS is 4K, and 100 records are stored. If there is no index, the query will scan the entire table. In the worst case, if all data pages are out of memory, 10^4 pages need to be read. If these 10^4 pages are randomly distributed on disk, it needs to be read. 10^4 I/Os, assuming that the disk I/O time is 10ms per I/O (ignoring the data transfer time), it will take a total of 100s (but it's actually a lot better). If you build a B-Tree index on it, you only need to perform log100(10^6)=3 page reads, which takes 30ms in the worst case. This is the effect of indexing. In many cases, when your application performs SQL queries very slowly, you should think about whether you can build an index. Into the title:
Chapter 2, Indexing and Optimization
1. Select the data type of the index
MySQL supports many data types, and choosing the appropriate data type to store data has a great impact on performance. Generally speaking, here are some guidelines to follow:
(1) Smaller data types are generally better: Smaller data types generally require less space in disk, memory, and CPU cache, and are faster to process.
(2) Simple data types are better: Integer data has less processing overhead than characters, because the comparison of strings is more complicated. In MySQL, the built-in date and time data types should be used instead of strings to store time; and the integer data type to store IP addresses.
(3) Try to avoid NULL: You should specify the column as NOT NULL, unless you want to store NULL. In MySQL, columns with null values are difficult to optimize because they complicate indexes, index statistics, and comparison operations. You should replace the null value with 0, a special value, or an empty string.
1.1. Selecting
an identifier It is very important to choose an appropriate identifier. The choice should not only consider the storage type, but also how MySQL performs operations and comparisons. Once a data type is selected, it should be ensured that all related tables use the same data type.
(1) Integer: Usually the best choice as an identifier, because it can be processed faster and can be set to AUTO_INCREMENT.
(2) Strings: Try to avoid using strings as identifiers, they consume better space and are slower to process. Also, in general, strings are random, so their position in the index is also random, which can lead to page splits, random access to disk, clustered index splits (for storage engines that use clustered indexes).
2. Getting started with indexes
For any DBMS, indexes are the most important factor for optimization. For a small amount of data, the impact of not having a suitable index is not very large, but when the amount of data increases, the performance will drop sharply.
If multiple columns are indexed (combined index), the order of the columns is very important, and MySQL can only perform efficient searches on the leftmost prefix of the index. For example:
Assuming that there is a composite index it1c1c2(c1,c2), the query statement select * from t1 where c1=1 and c2=2 can use this index. The query statement select * from t1 where c1=1 can also use this index. However, the query statement select * from t1 where c2=2 cannot use this index, because there is no leading column for the combined index, that is, to use the c2 column for search, c1 must be equal to a certain value.
2.1. Types of
indexes Indexes are implemented in the storage engine, not in the server layer. Therefore, the indexes of each storage engine are not necessarily the same, and not all storage engines support all index types.
2.1.1. The B-Tree index
assumes the following table:
| CREATE TABLE People ( last_name varchar(50) not null, first_name varchar(50) not null, dob date not null, gender enum('m', 'f') not null, key(last_name, first_name, dob) ); |
Its index contains the last_name, first_name, and dob columns for each row in the table. Its structure is roughly as follows:
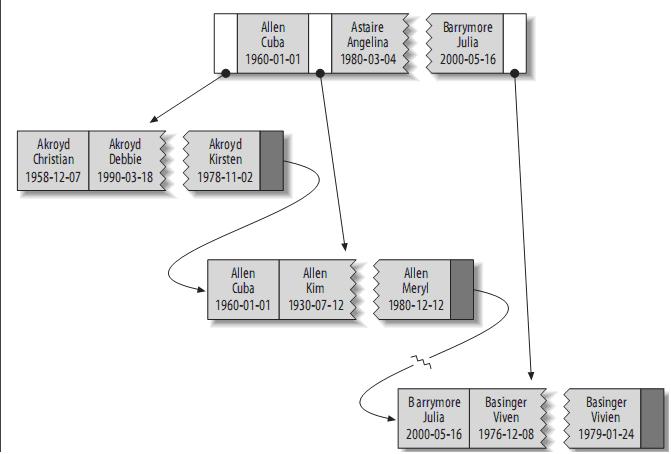
The index stores the values in the order in the indexed column. You can use B-Tree indexes for full-key, key-range, and key-prefix queries. Of course, if you want to use an index, you must ensure that you query by the leftmost prefix of the index.
(1) Match the full value: Specify a specific value for all columns in the index. For example, the index in the image above can help you find Cuba Allen who was born on 1960-01-01.
(2) Match a leftmost prefix: You can use the index to find the person whose last name is Allen, using only the first column in the index.
(3) Match a column prefix: For example, you can use the index to find people whose last name starts with J, which only uses the first column in the index.
(4) Match a range of values: You can use the index to find people whose last name is between Allen and Barrymore, and only use the first column in the index.
(5) Match one part exactly and match a range on another part (Match one part exactly and match a range on another part): You can use the index to find people whose last name is Allen and whose first name starts with the letter K.
(6) Index-only queries: If the columns of the query are all located in the index, there is no need to read the value of the tuple.
Since the nodes in the B-tree are stored sequentially, the index can be used to search (to find some values), and the query results can also be ORDER BY. Of course, the use of B-tree indexes has the following limitations:
(1) The query must start from the leftmost column of the index. This has been mentioned many times. For example, you can't use an index to find people who were born on a certain day.
(2) An index column cannot be skipped. For example, you cannot use an index to find people whose last name is Smith and who was born on a certain day.
(3) The storage engine cannot use the column to the right of the range condition in the index. For example, if your query is WHERE last_name="Smith" AND first_name LIKE 'J%' AND dob='1976-12-23', the query will only use the first two columns in the index, because LIKE is a range query .
2.1.2. Hash index
In MySQL, only the Memory storage engine supports hash index, which is the default index type of Memory table, although Memory table can also use B-Tree index. The Memory storage engine supports non-unique hash indexes, which are rare in the database field. If multiple values have the same hash code, the index stores their row pointers in a linked list in the same hash table entry.
Suppose the following table is created:
CREATE TABLE testhash (
fname VARCHAR(50) NOT NULL,
lname VARCHAR(50) NOT NULL,
KEY USING HASH(fname)
) ENGINE=MEMORY;
The data contained are as follows: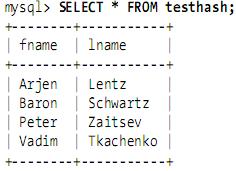
Suppose the index uses the hash function f( ) as follows:
| f ('Arjen') = 2323 f('Baron') = 7437 f('Peter') = 8784 f ('Vadim') = 2458 |
At this point, the structure of the index is roughly as follows:
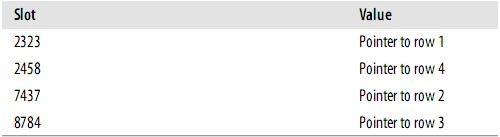
Slots are ordered, but records are not. When you execute
mysql> SELECT lname FROM testhash WHERE fname='Peter';
MySQL will calculate the hash value of 'Peter', and then use it to query the indexed row pointer. Since f('Peter') = 8784, MySQL will look up 8784 in the index and get a pointer to record 3.
Because the index itself only stores very short values, the index is very compact. The hash value does not depend on the data type of the column, the index of a TINYINT column is as large as the index of a long string column.
Hash index has the following limitations:
(1) Since the index only contains hash code and record pointer, MySQL cannot avoid reading records by using the index. But accessing records in memory is very fast and doesn't have much impact on sex.
(2) You cannot use hash index sorting.
(3) Hash index does not support partial key matching, because the hash value is calculated by the entire index value.
(4) Hash indexes only support equality comparisons, such as using =, IN( ) and <=>. For WHERE price>100 does not speed up the query.
2.1.3. Spatial (R-Tree) Index
MyISAM supports spatial indexing, which is mainly used for geospatial data types, such as GEOMETRY.
2.1.4. Full-text index Full-text
index is a special index type of MyISAM, mainly used for full-text search.
3. High-performance indexing strategy
3.1. Clustered Indexes
Clustered indexes ensure that tuples with similar keyword values are stored in the same physical location (so it is not appropriate to build clustered indexes for string types, especially random strings. , which will cause the system to perform a large number of move operations), and a table can only have one clustered index. Because indexes are implemented by the storage engine, not all engines support clustered indexes. Currently, only solidDB and InnoDB are supported.
The structure of a clustered index is roughly as follows: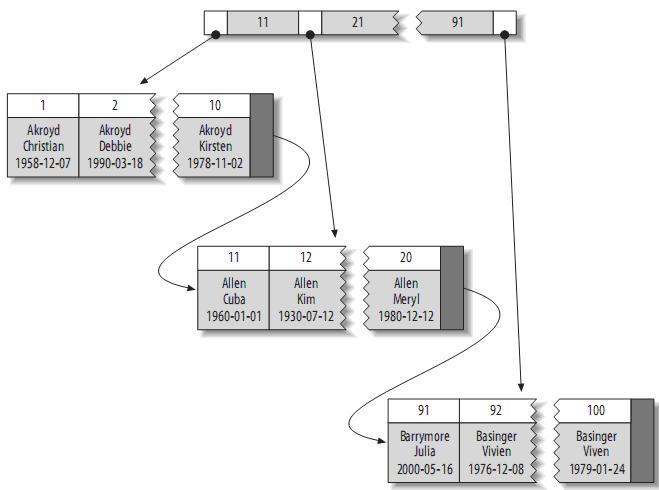
Note: Leaf pages contain complete tuples, while inner node pages contain only indexed columns (indexed columns are integers). Some DBMSs allow users to specify clustered indexes, but MySQL's storage engine so far does not support it. InnoDB creates a clustered index on the primary key. If you don't specify a primary key, InnoDB will use an index with unique, non-null values instead. If no such index exists, InnoDB defines a hidden primary key and then creates a clustered index on it. Generally speaking, DBMS will store the actual data in the form of clustered index, which is the basis of other secondary indexes.
3.1.1. Comparison of the data layout of InnoDB and MyISAM
In order to better understand the clustered index and non-clustered index, or the primary index and the secondary index (MyISAM does not support clustered index), let’s compare the data layout of InnoDB and MyISAM. For The following table:
| CREATE TABLE layout_test ( col1 int NOT NULL, col2 int NOT NULL, PRIMARY KEY(col1), KEY(col2) ); |
Assuming that the value of the primary key is between 1---10,000, and inserted in random order, then use OPTIMIZE TABLE to optimize. col2 is randomly assigned a value between 1---100, so there will be many duplicate values.
(1) The data layout of MyISAM The
layout is very simple. MyISAM stores data on the disk in the order of insertion, as follows: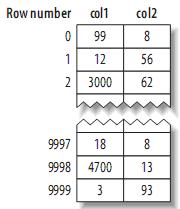
Note: The left side is the row number, starting from 0. Because the size of the tuple is fixed, MyISAM can easily find the position of a certain byte from the beginning of the table.
According to some established primary key index structure is roughly as follows: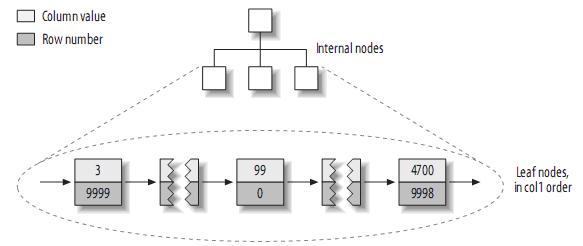
Note: MyISAM does not support clustered indexes. Each leaf node in the index only contains a row number, and the leaf nodes are stored in the order of col1.
Let's take a look at the index structure of col2: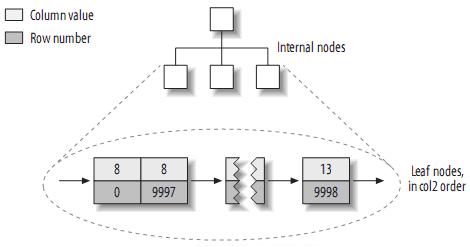
In fact, in MyISAM, the primary key is no different from any other index. The Primary key is just a unique, non-null index called PRIMARY.
(2) InnoDB data layout
InnoDB stores data in the form of clustered indexes, so its data layout is very different. The structure of its storage table is roughly as follows: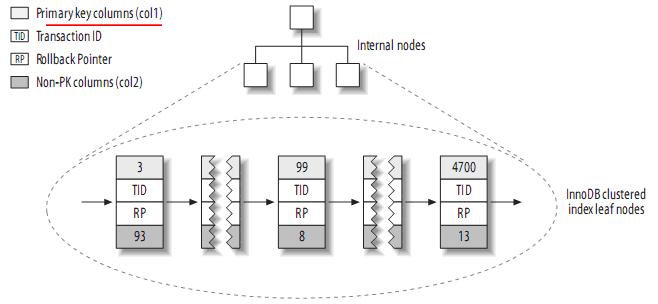
Note: Each leaf node in a clustered index contains the value of the primary key, transaction ID and rollback pointer - for transactions and MVCC, and the remaining columns (eg col2).
Relative to MyISAM, secondary indexes are very different from clustered indexes. The leaves of InnoDB's secondary indexes contain the value of the primary key instead of row pointers, which reduces the overhead of maintaining the secondary index when moving data or when data pages are split, because InnoDB does not need to update the index's row pointers. Its structure is roughly as follows: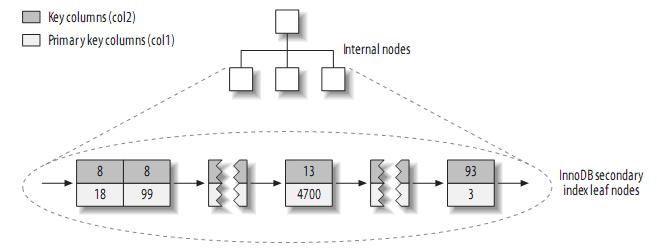
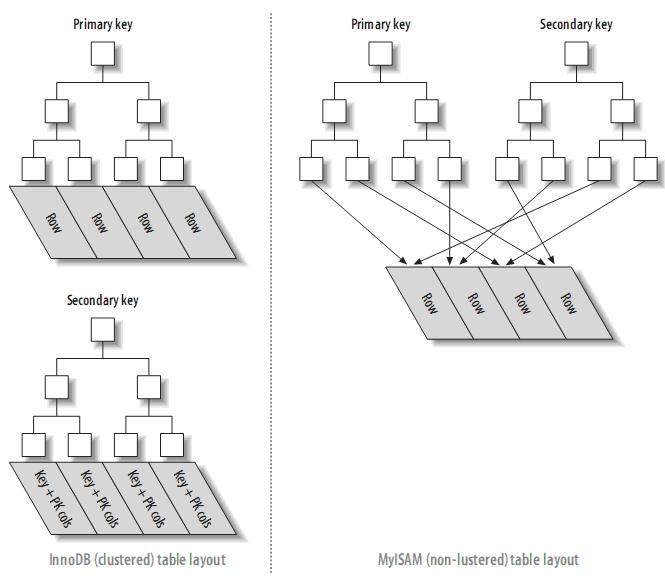
Comparison of clustered index and non-clustered index table:
3.1.2. Insert rows in the order of primary key (InnoDB)
If you use InnoDB and don't need special clustered indexes, a good practice is to use a surrogate key - independent of the data in your application. The easiest way to do this is to use an AUTO_INCREMENT column, which will ensure that records are inserted in order, and will improve the performance of queries that use primary key joins. Random clustered primary keys should be avoided as much as possible. For example, a string primary key is a bad choice because it makes inserts random.
3.2. Covering Indexes
If the index contains all the data that satisfies the query, it is called a covering index. Covering indexes are a very powerful tool that can greatly improve query performance. Only needing to read the index instead of reading the data has the following advantages:
(1) Index items are usually smaller than records, so MySQL accesses less data;
(2) Indexes are stored in order of value, as opposed to random access Recording requires less I/O;
(3) Most data engines can better cache indexes. For example, MyISAM only caches indexes.
(4) Covering indexes are especially useful for InnoDB tables, because InnoDB uses a clustered index to organize data. If the secondary index contains the data required for the query, it is no longer necessary to search in the clustered index.
A covering index cannot be any index, only a B-TREE index stores the corresponding value. Moreover, different storage engines implement covering indexes in different ways. Not all storage engines support covering indexes (Memory and Falcon do not).
For index-covered query (index-covered query), when using EXPLAIN, you can see "Using index" in the Extra column. For example, in sakila's inventory table, there is a composite index (store_id, film_id), for queries that only need to access these two columns, MySQL can use the index, as follows:
| mysql> EXPLAIN SELECT store_id, film_id FROM sakila.inventory\G *************************** 1. row *************************** id: 1 select_type: SIMPLE table: inventory type: index possible_keys: NULL key: idx_store_id_film_id key_len: 3 ref: NULL rows: 5007 Extra: Using index 1 row in set (0.17 sec) |
在大多数引擎中,只有当查询语句所访问的列是索引的一部分时,索引才会覆盖。但是,InnoDB不限于此,InnoDB的二级索引在叶子节点中存储了primary key的值。因此,sakila.actor表使用InnoDB,而且对于是last_name上有索引,所以,索引能覆盖那些访问actor_id的查询,如:
| mysql> EXPLAIN SELECT actor_id, last_name -> FROM sakila.actor WHERE last_name = 'HOPPER'\G *************************** 1. row *************************** id: 1 select_type: SIMPLE table: actor type: ref possible_keys: idx_actor_last_name key: idx_actor_last_name key_len: 137 ref: const rows: 2 Extra: Using where; Using index |
3.3、利用索引进行排序
MySQL中,有两种方式生成有序结果集:一是使用filesort,二是按索引顺序扫描。利用索引进行排序操作是非常快的,而且可以利用同一索引同时进行查找和排序操作。当索引的顺序与ORDER BY中的列顺序相同且所有的列是同一方向(全部升序或者全部降序)时,可以使用索引来排序。如果查询是连接多个表,仅当ORDER BY中的所有列都是第一个表的列时才会使用索引。其它情况都会使用filesort。
| create table actor( actor_id int unsigned NOT NULL AUTO_INCREMENT, name varchar(16) NOT NULL DEFAULT '', password varchar(16) NOT NULL DEFAULT '', PRIMARY KEY(actor_id), KEY (name) ) ENGINE=InnoDB insert into actor(name,password) values('cat01','1234567'); insert into actor(name,password) values('cat02','1234567'); insert into actor(name,password) values('ddddd','1234567'); insert into actor(name,password) values('aaaaa','1234567'); |
| mysql> explain select actor_id from actor order by actor_id \G *************************** 1. row *************************** id: 1 select_type: SIMPLE table: actor type: index possible_keys: NULL key: PRIMARY key_len: 4 ref: NULL rows: 4 Extra: Using index 1 row in set (0.00 sec)
mysql> explain select actor_id from actor order by password \G *************************** 1. row *************************** id: 1 select_type: SIMPLE table: actor type: ALL possible_keys: NULL key: NULL key_len: NULL ref: NULL rows: 4 Extra: Using filesort 1 row in set (0.00 sec)
mysql> explain select actor_id from actor order by name \G *************************** 1. row *************************** id: 1 select_type: SIMPLE table: actor type: index possible_keys: NULL key: name key_len: 18 ref: NULL rows: 4 Extra: Using index 1 row in set (0.00 sec) |
当MySQL不能使用索引进行排序时,就会利用自己的排序算法(快速排序算法)在内存(sort buffer)中对数据进行排序,如果内存装载不下,它会将磁盘上的数据进行分块,再对各个数据块进行排序,然后将各个块合并成有序的结果集(实际上就是外排序)。对于filesort,MySQL有两种排序算法。
(1)两遍扫描算法(Two passes)
实现方式是先将须要排序的字段和可以直接定位到相关行数据的指针信息取出,然后在设定的内存(通过参数sort_buffer_size设定)中进行排序,完成排序之后再次通过行指针信息取出所需的Columns。
注:该算法是4.1之前采用的算法,它需要两次访问数据,尤其是第二次读取操作会导致大量的随机I/O操作。另一方面,内存开销较小。
(3) 一次扫描算法(single pass)
该算法一次性将所需的Columns全部取出,在内存中排序后直接将结果输出。
注:从 MySQL 4.1 版本开始使用该算法。它减少了I/O的次数,效率较高,但是内存开销也较大。如果我们将并不需要的Columns也取出来,就会极大地浪费排序过程所需要的内存。在 MySQL 4.1 之后的版本中,可以通过设置 max_length_for_sort_data 参数来控制 MySQL 选择第一种排序算法还是第二种。当取出的所有大字段总大小大于 max_length_for_sort_data 的设置时,MySQL 就会选择使用第一种排序算法,反之,则会选择第二种。为了尽可能地提高排序性能,我们自然更希望使用第二种排序算法,所以在 Query 中仅仅取出需要的 Columns 是非常有必要的。
当对连接操作进行排序时,如果ORDER BY仅仅引用第一个表的列,MySQL对该表进行filesort操作,然后进行连接处理,此时,EXPLAIN输出“Using filesort”;否则,MySQL必须将查询的结果集生成一个临时表,在连接完成之后进行filesort操作,此时,EXPLAIN输出“Using temporary;Using filesort”。
3.4、索引与加锁
索引对于InnoDB非常重要,因为它可以让查询锁更少的元组。这点十分重要,因为MySQL 5.0中,InnoDB直到事务提交时才会解锁。有两个方面的原因:首先,即使InnoDB行级锁的开销非常高效,内存开销也较小,但不管怎么样,还是存在开销。其次,对不需要的元组的加锁,会增加锁的开销,降低并发性。
InnoDB仅对需要访问的元组加锁,而索引能够减少InnoDB访问的元组数。但是,只有在存储引擎层过滤掉那些不需要的数据才能达到这种目的。一旦索引不允许InnoDB那样做(即达不到过滤的目的),MySQL服务器只能对InnoDB返回的数据进行WHERE操作,此时,已经无法避免对那些元组加锁了:InnoDB已经锁住那些元组,服务器无法解锁了。
来看个例子:
| create table actor( actor_id int unsigned NOT NULL AUTO_INCREMENT, name varchar(16) NOT NULL DEFAULT '', password varchar(16) NOT NULL DEFAULT '', PRIMARY KEY(actor_id), KEY (name) ) ENGINE=InnoDB insert into actor(name,password) values('cat01','1234567'); insert into actor(name,password) values('cat02','1234567'); insert into actor(name,password) values('ddddd','1234567'); insert into actor(name,password) values('aaaaa','1234567'); |
| SET AUTOCOMMIT=0; BEGIN; SELECT actor_id FROM actor WHERE actor_id < 4 AND actor_id <> 1 FOR UPDATE; |
该查询仅仅返回2---3的数据,实际已经对1---3的数据加上排它锁了。InnoDB锁住元组1是因为MySQL的查询计划仅使用索引进行范围查询(而没有进行过滤操作,WHERE中第二个条件已经无法使用索引了):
| mysql> EXPLAIN SELECT actor_id FROM test.actor -> WHERE actor_id < 4 AND actor_id <> 1 FOR UPDATE \G *************************** 1. row *************************** id: 1 select_type: SIMPLE table: actor type: index possible_keys: PRIMARY key: PRIMARY key_len: 4 ref: NULL rows: 4 Extra: Using where; Using index 1 row in set (0.00 sec)
mysql> |
表明存储引擎从索引的起始处开始,获取所有的行,直到actor_id<4为假,服务器无法告诉InnoDB去掉元组1。
为了证明row 1已经被锁住,我们另外建一个连接,执行如下操作:
| SET AUTOCOMMIT=0; BEGIN; SELECT actor_id FROM actor WHERE actor_id = 1 FOR UPDATE; |
该查询会被挂起,直到第一个连接的事务提交释放锁时,才会执行(这种行为对于基于语句的复制(statement-based replication)是必要的)。
如上所示,当使用索引时,InnoDB会锁住它不需要的元组。更糟糕的是,如果查询不能使用索引,MySQL会进行全表扫描,并锁住每一个元组,不管是否真正需要。