This blog mainly introduces several methods to speed up neural network training.
We know that in the case of a large number of training samples, if all the samples are sent into the neural network at one time, and the network parameters are updated every iteration, the efficiency is very low. Why? Because the formula for the parameter update of the gradient descent method is generally:
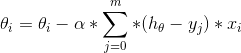
If batch gradient descent is used (adjusting the parameters with all samples at once), the calculation of the summation term in the above formula will be very time-consuming, because the total number of samples m is a large number. Then there is the first acceleration method: Stochastic Gradient Descent, or SGD for short. The idea is that the sample data is fed into the network one by one, and the parameters are updated every time a sample is used, which can converge to the optimal value extremely quickly, but will produce large fluctuations. Another is the mini-batch gradient descent method. The idea is to split the data into small batches and send them to the neural network in batches, and update the network parameters every time a batch is sent. Experiments show that this method integrates the advantages of the two gradient descent methods, and is a better acceleration method.
The second type of acceleration method is the method of adding a momentum term. We know that when updating network parameters, if the first few times are updated in one direction, then the next time is likely to be updated in that direction, then we can use the last direction as my update this time basis. For example, I want to find the bottom of a mountain, when I go down the mountain from the mountain, if the first step is down and the second step is down, then I can go faster in the third step. In this way, network training is accelerated. Not only that, but this method can also avoid the network falling into local minima to some extent.

When the above situation occurs, the network goes to point A and finds that the gradient is already zero, and it is likely that it will not continue to go down, directly thinking that point A is the minimum value. When we add the momentum term, we can use the momentum of the previous moment to make it rush past point A and continue to go down.
The third type of acceleration method is AdamGrad, which automatically adjusts the size of the learning rate. The learning rate under this method dynamically changes the size of the learning rate according to the historical gradient value. It needs to compute the sum of the squares of the historical gradients of the parameters updated to that t round.
The fourth acceleration method is RMSprop, which is an adaptive learning rate algorithm, which differs from the AdamGrad method in that it only calculates the average of the historical gradients of the parameters updated to this t round.
The fifth acceleration method is Adam, which is also an adaptive learning rate adjustment algorithm and is also the most widespread. It utilizes the first and second moment estimates of the gradient. The learning rate adjusted by this method is relatively stable, and the estimated results are more accurate.
Of course, there are many, many ways to speed up neural network training, but the above are just a few of the more common ones.
In the PyTorch deep learning framework, the implemented optimizers cover Adadelta, Adagrad, Adam, Adamax, RMSprop, Rprop, and more.
In order to visually compare the performance of each optimizer, I use the PyTorch framework to solve a quadratic function fitting problem with a neural network.
import torch
import torch.utils.data as Data
import torch.nn.functional as F
from torch.autograd import Variable
import matplotlib.pyplot as plt
torch.manual_seed(1) #Set the seed so that the results are reproducible
LR = 0.01 #learning rate learning rate
BATCH_SIZE = 32 #The size of a batch
EPOCH = 12 #Iteration rounds
#manufacturing data
x = torch.unsqueeze(torch.linspace(-1,1,1000),dim=1) #Generate 100 values between [-1,1]
y = x.pow(2) + 0.1*torch.normal(torch.zeros(x.size())) #y=x^2, plus 0.1 times the perturbation of the normal distribution
plt.scatter(x.numpy(),y.numpy())
plt.show() #Show sample data
#batch training
torch_dataset = Data.TensorDataset(data_tensor=x,target_tensor=y)
loader = Data.DataLoader(dataset=torch_dataset,batch_size=BATCH_SIZE,shuffle=True,num_workers=2,)
#shuffle=True means random sampling, num_workers means the number of threads
class Net(torch.nn.Module):
def __init__(self):
super(Net,self).__init__()
self.hidden = torch.nn.Linear(1,20) #20 neurons in the hidden layer
self.predict = torch.nn.Linear(20,1) #1 neuron in the output layer, representing the predicted result
def forward(self,x):
x = F.relu(self.hidden(x)) #The hidden layer sets the relu activation function
x = self.predict(x) #output layer direct linear output
return x
#Create a Net for each optimizer
net_SGD = Net()
net_Momentum = Net()
net_RMSprop = Net()
net_Adam = Net()
nets = [net_SGD,net_Momentum,net_RMSprop,net_Adam] # put it into a list
opt_SGD = torch.optim.SGD(net_SGD.parameters(),lr=LR)
opt_Monentum = torch.optim.SGD(net_Momentum.parameters(),lr=LR,momentum=0.8)
opt_RMSprop = torch.optim.RMSprop(net_RMSprop.parameters(),lr=LR,alpha=0.9)
opt_Adam = torch.optim.Adam(net_Adam.parameters(),lr=LR,betas=(0.9,0.99))
optimizers = [opt_SGD,opt_Monentum,opt_RMSprop,opt_Adam]
#define error function
loss_func = torch.nn.MSELoss()
losses_his = [[],[],[],[]]
for epoch in range(EPOCH):
print('Epoch:',epoch)
for step,(batch_x,batch_y) in enumerate(loader):
b_x = Variable(batch_x)
b_y = Variable(batch_y)
for net,opt,l_his in zip(nets,optimizers,losses_his):
output = net(b_x)
loss = loss_func(output,b_y)
opt.zero_grad() #Clear the gradient for the next calculation
loss.backward() #Error back propagation
opt.step() #Apply gradient
l_his.append(loss.data[0])
labels = ['SGD','Momentum','RMSprop','Adam']
for i,l_his in enumerate(losses_his):
plt.plot(l_his,label=labels[i])
plt.legend(loc='best') #The legend is placed in the best position
plt.xlabel('Steps')
plt.ylabel('Loss')
plt.ylim((0,0.2))
plt.show()
Raw training data visualization:

Results of performance comparison of different Optimizers:

Analysis of the results: From the above figure, we can see that the SGD fluctuates significantly, and the Adam method has the best effect. Of course, the performance of each optimizer also has a lot to do with the distribution of the training data.