The database is always the most critical part of the application. At the same time, the higher the concurrency stage is, the database often becomes the bottleneck. If the database tables and indexes are not well designed at the beginning, the horizontal expansion of the database and the sub-database and sub-tables will encounter difficulties in the later stage. .
For Internet companies, MySQL
databases are generally used .
First, the overall structure of the database
Let's first look at the overall structure of Mysql data as follows:
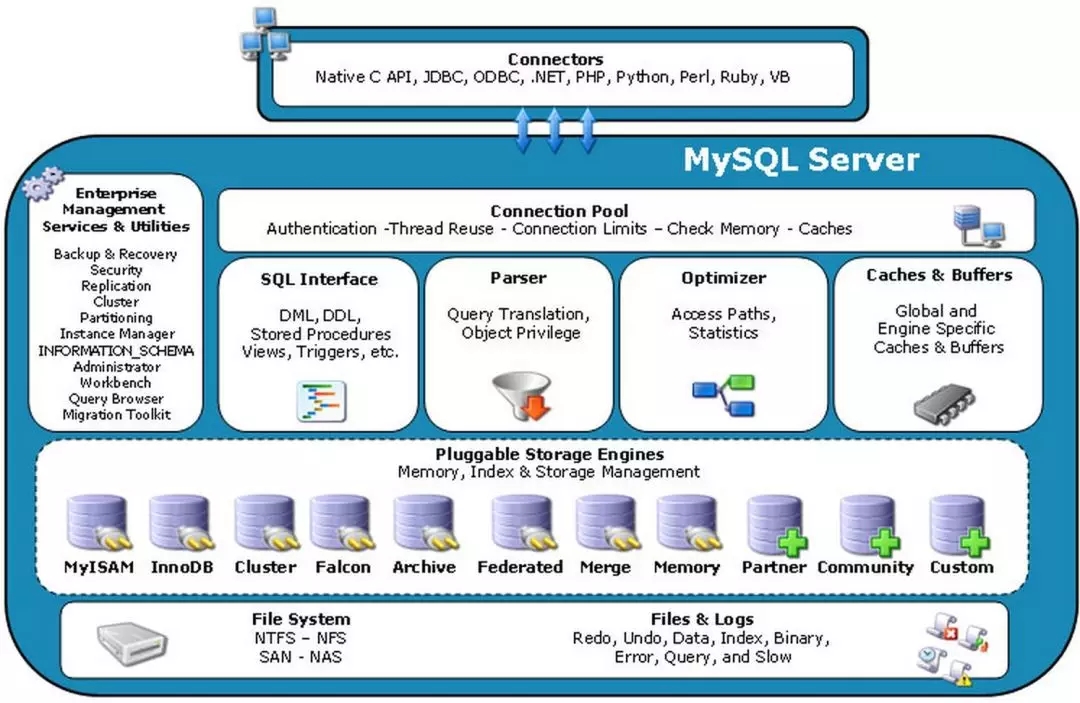
This is a very classic Mysql system architecture diagram, through which we can see the functions of various parts of Mysql.
When the client connects to the database, the first thing it faces is the connection pool, which is used to manage user connections and perform certain authentication and authentication.
After connecting to the database, the client will send SQL statements, and the SQL interface module is to accept the user's SQL statements.
SQL statements often need to comply with strict grammatical rules, so a parser is required to parse the statement. The principle of parsing the grammar is as learned in the compilation principle, from a statement to a syntax tree.
The query that the user belongs to can be optimized, so that the fastest query path can be selected, which is the role of the optimizer.
In order to speed up the query, there is a query cache module. If the query cache has a hit query result, the query statement can directly go to the query cache to fetch data.
All the above components are the database service layer, followed by the database engine layer. The current mainstream database engine is InnoDB.
For any modification to the database, the database service layer will record it in the binary log, which is the basis for primary and secondary replication.
For the database engine layer, a well-known diagram is as follows:

At the storage engine layer, there are also caches and logs, and the final data falls on the disk.
The cache of the storage engine layer is also used to improve performance, but unlike the cache of the database service layer, the cache of the database service layer is a query cache, while the cache of the database engine layer is cached for both reads and writes. The cache of the database service layer is based on query logic, while the cache of the database engine engine is based on data pages, which can be said to be physical.
哪怕是数据的写入仅仅写入到了数据库引擎层中的缓存,对于数据库服务层来讲,就算是已经持久化了,当然这个时候会造成缓存页和硬盘上的页的数据的不一致,这种不一致由数据库引擎层的日志来保证完整性。
所以数据库引擎层的日志和数据库服务层的也不同,服务层的日志记录的是一个个的修改逻辑,而引擎层的日志记录的是缓存页和数据页的物理差异。
二、数据库的工作流程
在收到一个查询的时候,Mysql的架构中的各个组件是如此工作的:
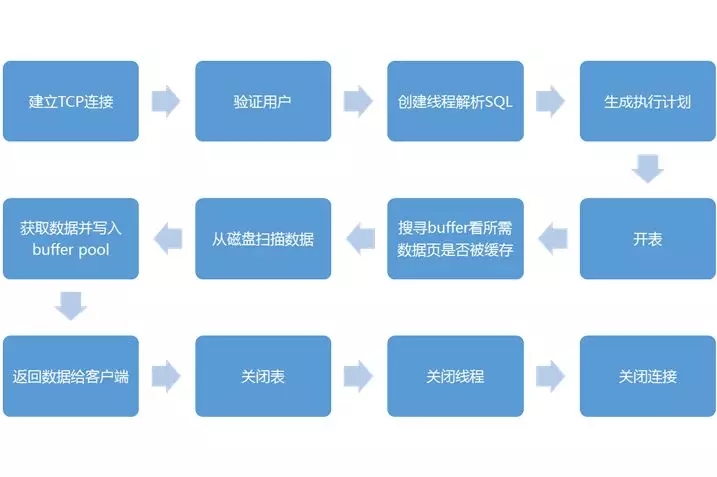
客户端同数据库服务层建立TCP连接,连接管理模块会建立连接,并请求一个连接线程。如果连接池中有空闲的连接线程,则分配给这个连接,如果没有,在没有超过较大连接数的情况下,创建新的连接线程负责这个客户端。
在真正的操作之前,还需要调用用户模块进行授权检查,来验证用户是否有权限。通过后,方才提供服务,连接线程开始接收并处理来自客户端的SQL语句。
连接线程接收到SQL语句之后,将语句交给SQL语句解析模块进行语法分析和语义分析。
如果是一个查询语句,则可以先看查询缓存中是否有结果,如果有结果可以直接返回给客户端。
如果查询缓存中没有结果,就需要真的查询数据库引擎层了,于是发给SQL优化器,进行查询的优化。如果是表变更,则分别交给insert, update, delete, create,alter处理模块进行处理。
接下来就是请求数据库引擎层,打开表,如果需要的话获取相应的锁。
接下来的处理过程就到了数据库引擎层,例如InnoDB。
在数据库引擎层,要先查询缓存页中有没有相应的数据,如果有则可以直接返回,如果没有就要从磁盘上去读取。
当在磁盘中找到相应的数据之后,则会加载到缓存中来,从而使得后面的查询更加高效,由于内存有限,多采用变通的LRU表来管理缓存页,保证缓存的都是经常访问的数据。
获取数据后返回给客户端,关闭连接,释放连接线程,过程结束。
三、数据库索引的原理
在整个过程中,最容易称为瓶颈点的是数据的读写,往往意味着要顺序或者随机读写磁盘,而读写磁盘的速度往往是比较慢的。
如果加快这个过程呢?相信大家都猜到了就是建立索引。
为什么索引能够加快这个过程呢?
相信大家都逛过美食城,里面众多家餐馆琳琅满目,如果你不着急呢,肚子不饿,对搜索的性能没有要求,就可以在商场里面慢慢逛,逛一家看一家,知道找到自己想吃的餐馆。但是当你饿了,或者你们约好了餐馆,你一定想直奔那个餐馆,这个时候,你往往会去看楼层的索引图,快速的查找你目标餐馆的位置,找到后,直奔主题,就会大大节约时间,这就是索引的作用。
所以索引就是通过值,快速的找到它的位置,从而可以快速的访问。
索引的另外一个作用就是不用真正的查看数据,就能够做一些判断,例如商场里面有没有某个餐馆,你看一下索引就知道了,不必真的到商场里面逛一圈,再如找出所有的川菜馆,也是只要看索引就可以了,不用一家一家川菜馆跑。
那么在Mysql中,索引是如何工作的呢?
Mysql的索引结构,往往是一棵B+树。
一棵m阶B+树具有如下的性质:
节点分索引节点和数据节点。索引节点相当于B树的内部节点,所有的索引节点组成一棵B树,具有B树的所有的特性。在索引节点中,存放着Key和指针,并不存放具体的元素。数据节点相当与B树的外部节点,B树的外部节点为空,在B+树中被利用了起来,用于存放真正的数据元素,里面包含了Key和元素的其他信息,但是没有指针。
整棵索引节点组成的B树仅仅用来查找具有某个Key的数据元素位于哪个外部节点。在索引节点中找到了Key,事情没有结束,要继续找到数据节点,然后将数据节点中的元素读出来,或者二分查找,或者顺序扫描来寻找真正的数据元素。
M这个阶数仅仅用来控制索引节点部分的度,至于每个数据节点包含多少元素,与m无关。
另外有一个链表,将所有的数据节点串起来,可以顺序访问。
这个定义的比较抽象,我们来看一个具体的例子。
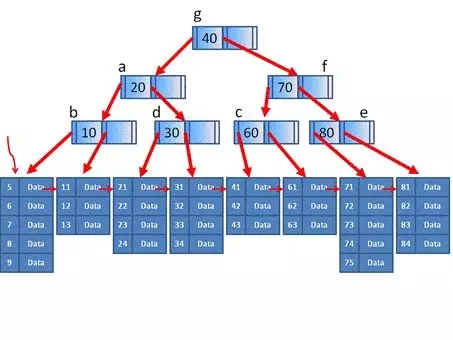
从图中我们可以看出,这是一个3阶B+树,而一个外部数据节点最多包含5项。如果插入的数据在数据节点,如果不引起分裂和合并,则索引节点组成的B树就不会变。
如果在71到75的外部节点插入一项76,则引起分裂,71,72,73成为一个数据节点,74,75,76成为一个数据节点,而对于索引节点来讲相当于插入一个Key为74的过程。
如果在41到43的外部节点中删除43,则引起合并,41,42,61,62,63合并成一个节点,对于索引节点来讲,相当于删除Key为60的过程。
查找的时候,由于B+树层高很小,所以能够比较快速的定位,例如我们要查找值62,在根节点发现大于40则访问右面,小于70则访问左面,大于60则访问右面,在叶子节点的第二个,就找到了62,成功定位。
在Mysql的InnoDB中,有两种类型的B+树索引,一种称为聚簇索引,一种称为二级索引。
聚簇索引的叶子节点就是数据节点,往往是主键作为聚簇索引,二级索引的叶子节点存放的是KEY字段加主键值。因而通过二级索引访问数据,要访问两次索引。
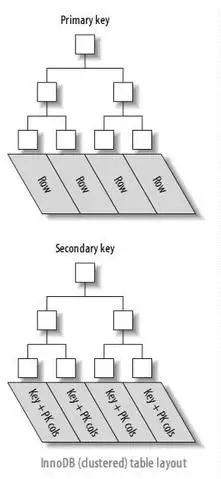
还有一种索引的形式称为组合索引,或者复合索引,可以在多个列上建立索引。

这种索引的排序规则为,先比较第一列,在第一列相等的情况下,比较第二列,以此类推。
四、数据库索引的优缺点
数据库索引的优势最明显的就是减少I/O,下面分析几种场景。
对于=条件的字段,可以直接通过查找B+树的方式,通过很少的硬盘读取次数(相当于B+树层高),就能够到达叶子节点,然后直接定位到数据的位置。
对于范围的字段,由于B+树里面都是排好序的,范围可以很快的通过树进行定位。
同理对于orderby/group by/distinct/max/min,由于B+树是排好序的,也是能够很快的得到结果的。
还有一个常见的场景称为索引覆盖数据。例如A, B两个字段作为条件字段,常出现A=a AND B=b,同时select C, D时候,往往会建联合索引(A, B),是一个二级索引,所以搜索的时候,通过二级索引的B+树能够很快的找到相应的叶子节点和记录,但是记录中有的是聚簇索引的ID,所以还需要查找一次聚簇索引的B+树,找到真正的表中的记录,然后在记录中,将C,D读取出来。如果建立联合索引的时候为(A, B, C, D),则在二级索引的B+树中就有了所有的数据,可以直接返回了,减少了一次搜索树的过程。
当然索引肯定是有代价的,天下没有免费的午餐。
索引带来的好处多是读的效率的提高,而索引带来的代价就是写的效率的降低。
插入和修改数据,都有可能意味着索引的改变。
插入的时候,往往会在主键上建设聚簇索引,因而主键较好使用自增长,这样插入的数据就总是在最后,而且是顺序的,效率比较高。主键不要使用UUID,这样顺序比较随机,会带来随机的写入,效率比较差。主键不要使用和业务有关,因为与业务相关意味着会被更新,将面临着一次删除和重新插入,效率会比较差。
通过上面对于B+树的原理的介绍,我们可以看出B+树的分裂代价还是比较大的,而分裂往往就产生于插入的过程中。
而对于数据的修改,则基本相当于删除再插入,代价也比较大。
对于一些字符串的列的二级索引,往往会造成随机的写入和读取,对I/O的压力也比较大。
五、解读数据库军规背后的原理
了解了这两种索引的原理,我们就能够解释为什么很多所谓的数据库的军规长这个样子了。下面我们来一一解释。
什么情况下应该使用组合索引而非单独索引呢?
假设有条件语句A=a AND B=b,如果A和B是两个单独的索引,在AND条件下只有一个索引起作用,对于B则要逐个判断,而如果使用组合索引(A, B),只要遍历一棵树就可以了,大大增加了效率。但是对于A=a OR B=b,由于是或的关系,因而组合索引是不起作用的,因而可以使用单独索引,这个时候,两个索引可以同时起作用。
为什么索引要有区分度,组合索引中应该讲有区分度的放在前面?
如果没有区分度,例如用性别,相当于把整个大表分成两部分,查找数据还是需要遍历半个表才能找到,使得索引失去了意义。
如果有组合索引,还需要单列索引吗?
如果组合索引是(A, B),则对于条件A=a,是可以用上这个组合索引的,因为组合索引是先按照第一列进行排序的,所以没必要对于A单独建立一个索引,但是对于B=b就用不上了,因为只有在第一列相同的情况下,才比较第二列,因而第二列相同的,可以分布在不同的节点上,没办法快速定位。
索引是越多越好吗?
当然不是,只有在必要的地方添加索引,索引不但会使得插入和修改的效率降低,而且在查询的时候,有一个查询优化器,太多的索引会让优化器困惑,可能没有办法找到正确的查询路径,从而选择了慢的索引。
为什么要使用自增主键
因为字符串主键和随机主键会使得数据随机插入,效率比较差,主键应该少更新,避免B+树和频繁合并和分裂。
为什么尽量不使用NULL
NULL在B+树里面比较难以处理,往往需要特殊的逻辑进行处理,反而降低了效率。
为什么不要在更新频繁的字段上建立索引
更新一个字段意味着相应的索引也要更新,更新往往意味着删除然后再插入,索引本来是一种事先在写的阶段形成一定的数据结构,从而使得在读的阶段效率较高的方式,但是如果一个字段是写多读少,则不建议使用索引。
为什么在查询条件里面不要使用函数
例如ID+1=10这种条件,索引是事先写入的时候生成好的,ID+1这种操作在查询阶段,索引无能为例,没办法把所有的索引都先做一个计算,然后再比较吧,代价太大了,因而应该使用ID=10-1。
为什么不要使用NOT等负向查询条件
你可以想象一下,对于一棵B+树,跟节点是40,如果你的条件是等于20,就去左面查,你的条件等于50,就去右面查,但是你的条件是不等于66,索引应该咋办?还不是遍历一遍才知道。
为什么模糊查询不要以通配符开头
对于一棵B+树来讲,如果根是字符def,如果通配符在后面,例如abc%,则应该搜索左面,例如efg%,则应该搜索右面,如果通配符在前面%abc,则不知道应该走哪一面,还是都扫描一遍吧。
为什么OR要改成IN,或者使用Union
OR查询条件的优化往往比较难找到较佳的路径,尤其是OR的条件比较多的时候,尤其如此,对于同一个字段,使用IN就好一些,数据库会对IN里面的条件进行排序,并统一通过二分搜索的方法处理。对于不同的字段,使用Union,则可以让每一个子查询都使用索引。
为什么数据类型应该尽量小,常用整型来代替字符型,长字符类型可以考虑使用前缀索引?
因为数据库是按照页存放的,每一页的大小是一样的,如果数据类型比较大,则页数会比较多,每一页放的数据会比较少,树的高度会比较高,因而搜索数据要读取的I/O数目会比较多,插入的时候节点也容易分裂,效率会降低。使用整型来代替字符型多是这个考虑,整型对于索引有更高的效率,例如IP地址等。如果有长字符类型需要使用索引进行查询,为了不要使得索引太大,可以考虑将字段的前缀进行索引,而非整个字段。
六、查询优化的方法论
要找到需要优化的SQL语句,首先要收集有问题的SQL语句。
MySQL 数据库提供了慢SQL日志功能,通过参数slow_query_log,获取执行时间超过一定阈值的SQL语录列表。
没有使用索引的SQL语句,可以通过long_queries_not_using_indexes参数开启。
min_examined_row_limit,扫描记录数大于该值的SQL语句才会被记入慢SQL日志。
找到有问题的语句,接下来就是通过explainSQL,获取SQL的执行计划,是否通过索引扫描记录,可以通过创建索引来优化执行效率。是否扫描记录数过多。是否持锁时间过长,是否存在锁冲突。返回的记录数是否较多。
接下来可以定制化的优化。没有被索引覆盖的过滤条件涉及的字段,在区分度较大的字段上创建索引,如果涉及多个字段,尽量创建联合索引。
扫描记录数非常多,返回记录数不多,区分度较差,重新评估SQL语句涉及的字段,选择区分度高的多个字段创建索引
扫描记录数非常多,返回记录数也非常多,过滤条件不强,增加SQL过滤条件
schema_redundant_indexes查看有哪些冗余索引。
如果多个索引涉及字段顺序一致,则可以组成一个联合索引schema_unused_indexes查看哪些索引从没有被使用。
七、读写分离的原理
数据库往往写少读多,所以性能优化的第一步就是读写分离。

主从复制基于主节点上的服务层的日志实现的,而从节点上有一个IO线程读取这个日志,然后写入本地。另有一个线程从本地日志读取后在从节点重新执行。

如图是主从异步复制的流程图。在主实例写入引擎后就返回成功,然后将事件发给从实例,在从实例上执行。这种同步方式速度较快,但是在主挂了的时候,如果还没有复制,则可能存在数据丢失问题。
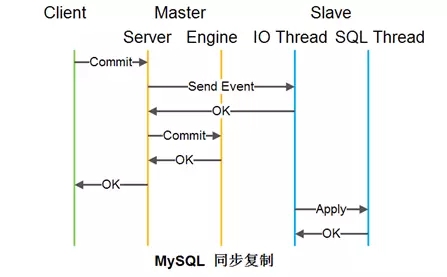
数据库同步复制也不同,是当从节点落盘后再返回客户端,当然这样会使得性能有所降低,网易数据库团队是通过组提交,并行复制等技术将性能提上来。
有了主从复制,在数据库DAO层可以设置读写分离策略,也有通过数据库中间件做这个事情的。
其实数据库日志还有很多其他用处,如使用canal(阿里巴巴开源项目: 基于mysql数据库binlog的增量订阅&消费)订阅数据库的binlog,可以用于更新缓存等。
http://architect.dataguru.cn/article-13451-1.html