Article directory
foreword
提示:本人不喜欢用专业术语来记录知识点,所以接下来会用例题+白话文的方式记录:
The main idea of selection sorting is to select a record with the smallest keyword value from the sequence to be sorted in each pass, that is, in the first pass, select the record with the smallest key value from the n records, and in the second pass, from the remaining Select the record with the smallest key value among the n-1 records, until all the records in the entire sequence are selected. In this way, a sequence ordered by the key value can be obtained from the order in which the records are selected.
提示:以下是本篇文章正文内容,下面案例可供参考
3. Selection sort
1. Direct selection sort
Thought:
First, select the record with the smallest keyword value among all records, exchange it with the first record, and then select the record with the second smallest keyword value from the rest of the records to exchange the position with the second record. And so on until all records are sorted.
- Here is a more classic gif from the Internet to show the whole process of direct selection sorting:
example:
Assume that the keyword sequence of the 8 records to be sorted is { 5, 3, 6, 4, 7, 1, 8, 2}. The sorting process is shown in the figure below. The
red color is the sorted number. Generally, [ Square brackets] instead of the
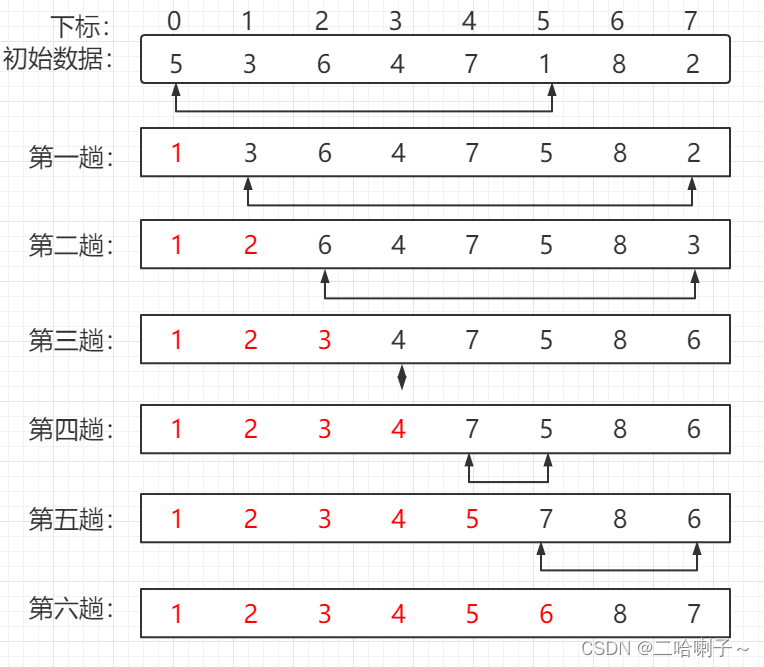
initial sequence, regard it as an unordered sequence
, and then choose the smallest one from the unordered sequence and exchange it with the first number in the unordered sequence to form an ordered sequence.
The second round also selects the smallest from the unordered sequence. exchange with the first number in the unordered sequence and
so on for
each of the following steps After each sequence is traversed, the number of records in the ordered sequence + 1, the number of unordered sequences - 1,
Code part:
public void selectSort(){
RecordNode temp; //定义一个零时变量temp
for(int i=0; i<this.curlen-1;i++) //进行i-1次遍历,this.curlen:数组的长度
{
int min=i;
for(int j=i+1;j<this.curlen; j++) //找到一个最小的
if (r[j].key.compareTo(r[min].key)<0)
min=j;
if (min!=i)
{
temp=r[i]; //以下是交换代码
r[i]=r[min];
r[min]=temp;}
}
}
performance analysis
⑴. Time complexity:
O(n 2 )
⑵. Required auxiliary space:
O(1)
⑶. Algorithm stability:
it is unstable sorting
2, tree selection sort
Thought:
- Here is a comparison classic diagram on the Internet to show the whole process of tree selection sorting:

first compare the n records, and the result of the comparison is that the one with the smaller keyword value is raised to the parent node as the winner, and the result is The winner of the comparison (the one with the smaller keyword value) is retained as the result of the first step comparison; then the pairwise comparison of the keywords is performed on this record, and so on, until a record with the smallest keyword value is selected. .
This process can be represented by a complete binary tree with n leaf nodes
Example one:
(1)
For a sequence of 8 keys { 52, 39, 67, 95, 70, 8, 25, ¯52¯ }, the process of selecting the smallest key value using tree selection sort can use the complete binary tree shown in the following figure To represent.
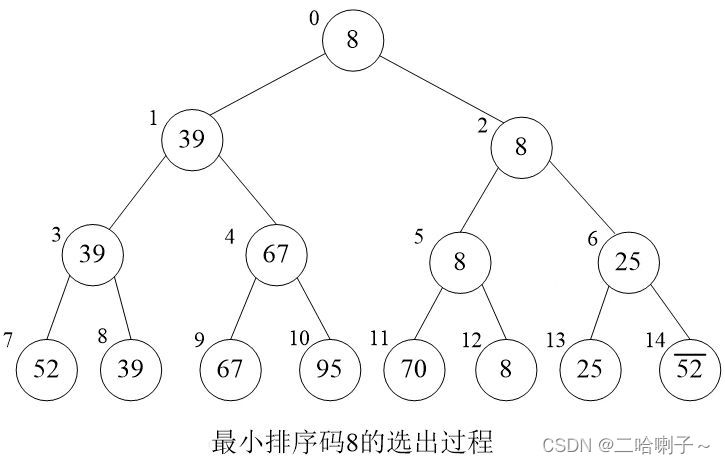
You can see that the keywords are all on the leaf nodes of the last layer.
How to choose? Two PKs, whoever is younger will go to the parent node, 52 and 39, 39 will go up; 67 and 95, 67 will go up; 70 and 8, 8 will go up;
on the previous level, whoever is younger will go to the parent node, and the last keyword smallest on top
(2)
The same as the above example question 1 (1), find the second smallest value

In the example question 1 (1), the smallest is found, and then it is regarded as an infinity "∞", and then two PKs can be used to find the second smallest, and the second smallest is found. Then replace it with infinity, find the smallest of these each time to get the parent node, and so on, and finally sort it out
performance analysis
(1) Space complexity
Although tree selection sorting reduces sorting time, it uses more additional storage space.
⑵、Time complexity
The time complexity of tree selection sorting is O(nlog 2 n)
⑶、Algorithm stability
Tree selection sorting is a stable sorting algorithm.
3. Heap sort
definition:
A heap is a sequence { r 0 , r 1 . . . r n-1 } satisfying the following properties:
For the big top heap: ri i >= r 2i+ 1 && ri i >= r 2i+ 2
For the small top heap: ri i < = r 2i+ 1 && r i <= r 2i + 2 A heap whose nodes are all larger than a child node is called a big top heap A node whose father nodes are all smaller than the child nodes is called a small top heap
- Here is a classic graph on the Internet to show the size of the top heap:
the value of the root node in the large top heap must be the largest in the entire sequence The
value of the root node in the small top heap must be the smallest in the entire sequence
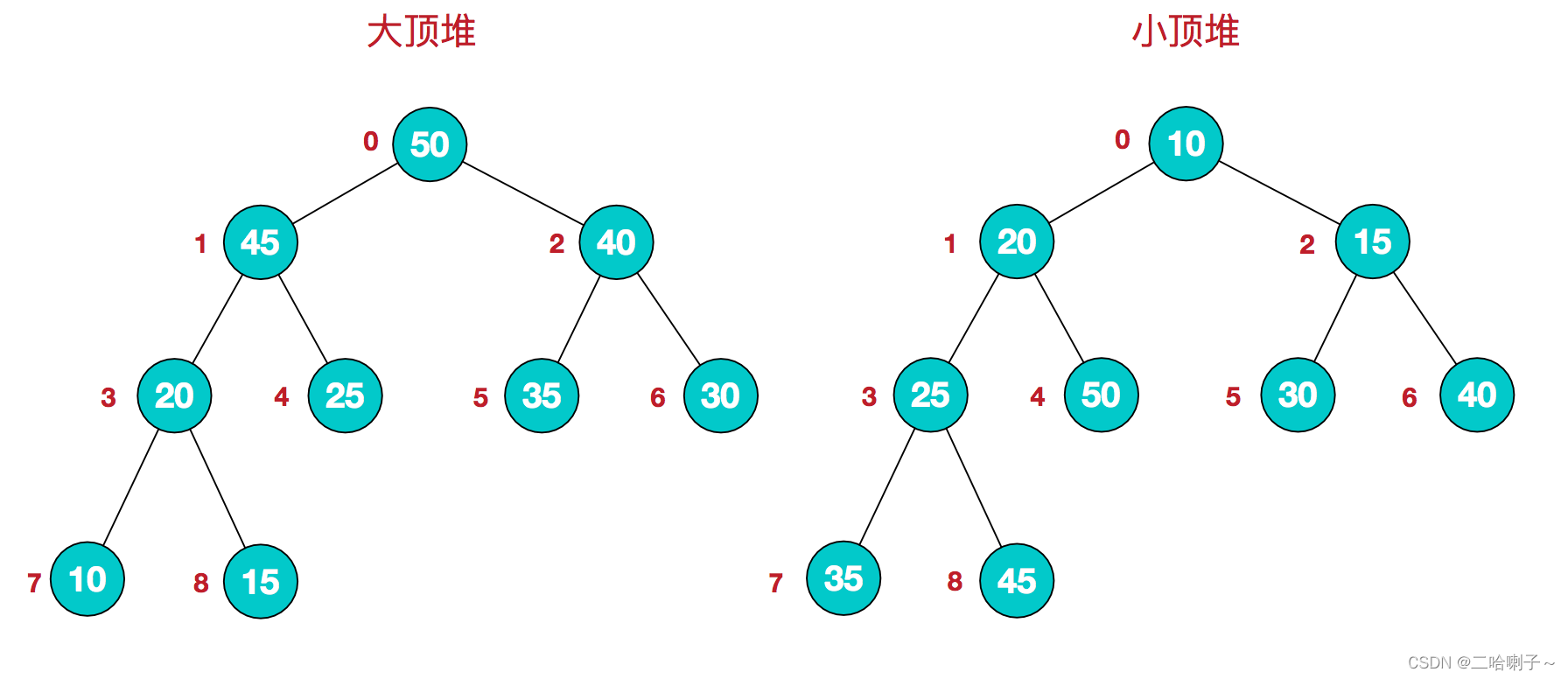
r 2i+ 1 is r i The left child of
r 2i+ 2 is the right child of r i
Therefore, the meaning of the heap shows that the value of all non-terminal nodes (parent nodes) in the complete binary tree is not greater than (or not less than) the value of its left and right child nodes.
- Here is a more classic gif from the Internet to show:

method:
First, the sequence of records to be sorted is corresponding to a complete binary tree, and it is converted into an initial heap (that is, the initial heap is first built). At this time, the root node has the largest (or smallest) key value, and then the positions of the root node and the last node (that is, the nth node) are exchanged. Except for the last node, the first n- 1 node still constitutes a complete binary tree, and then adjust them into a heap. Also swap the root node and the last node (ie the n-1th node). Repeat this process until there is only one root node left, and you will get an ordered list.
How to "filter"?
The so-called "screening" refers to the adjustment process. For a complete binary tree whose left and right subtrees are heaps, "adjusting" the root node makes the entire binary tree also become a heap.
example:
The sequence of keywords before sorting is
{ 40, 55, 49, 73, 12, 27, 98, 81, 64, 36 }
In the picture below, in the box, the brown ones are exchanged, and the green ones are not needed to move.
"Screening" is a top-down process.
It can be seen that each parent node is larger than the child node, so it is a large top heap,
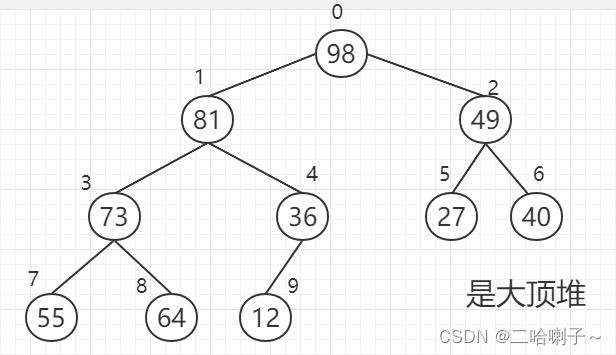
but after we have sorted it, the maximum value of 98 should be placed at the end, and the subscript is 9, but this requires 12 to be moved. Up, that is, the maximum value needs to be exchanged with the value of the last node,
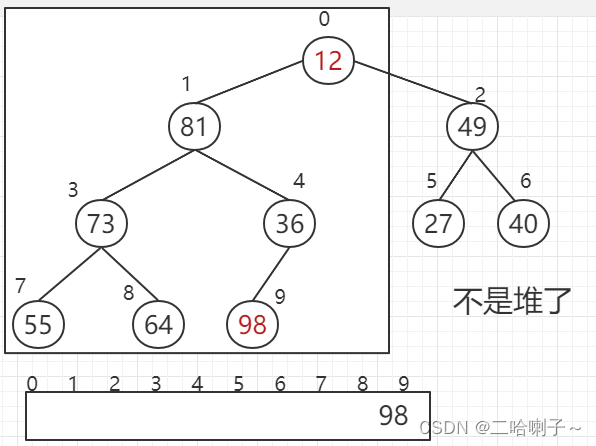
but after 98 and 12 are exchanged, it is not a heap, so it needs to be "filtered", and it is still adjusted to a large top heap
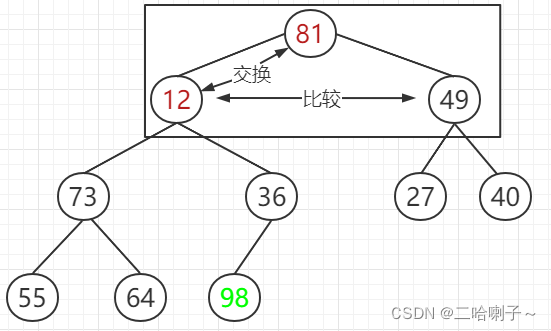
. It needs to be screened from top to bottom, but it should be noted that because the maximum value has been found and placed at the end, there is no need to rank the maximum value of 98.
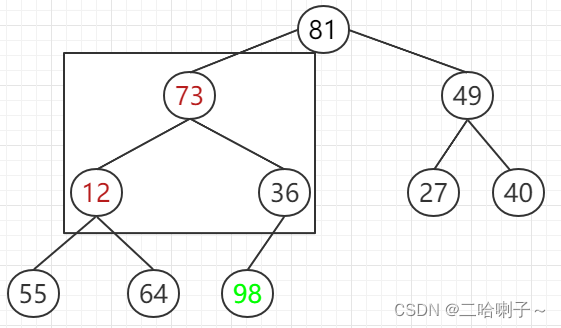
Look at 12, 81, and 49 first, if it is a big top Heap, you need to put 81 on the top, and 81 and 12 are exchanged,
but it is not a big top heap. Next, 73, 12, and 36 are compared, and whoever is larger goes up and exchanged, so 73 and 12 are exchanged
and then 55 and 64 are compared, Whoever is bigger will go up . In
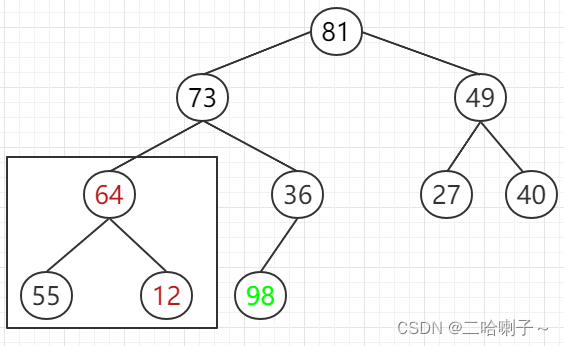
this case, it becomes a big top heap again. The
root node 81 is the largest, and it is exchanged with the last one of the disordered sequence, here is 12. . . . . And so on, each filter can find the largest, so it is sorted
How to "build initial heap"?
If you build a large top heap, the top root node must be the largest
If you build a small top heap, the top root node must be the smallest
example:
Heap building is a bottom-up "screening" process.
For example: the keyword sequence before sorting is
{ 40, 55, 49, 73, 12, 27, 98, 81, 64, 36 } First

look at the subscripts 4 and 9, 36 is larger than 12, 36 goes up,
then look at the bottom left Subscripts 3, 7, 8, 81 are larger than 73, 64, 81 goes up,
look at the right subscripts 2, 5, 6, 98 is larger than 27, 49, 98 goes up,
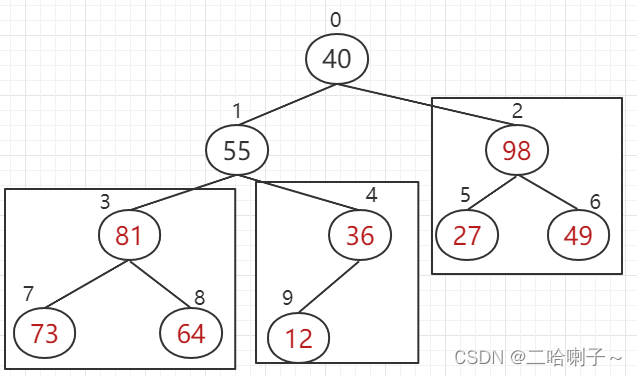
and then look at subscripts 1 , 3, 4, 81 It is larger than 55, 36, and 81 goes up,
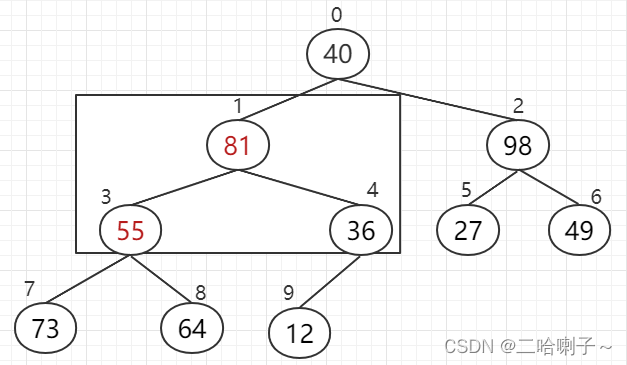
but then we find a problem: subscripts 3, 7, 8, these three numbers (55, 73, 64) cannot form a big top heap,
so after comparing the three numbers, Go up to 73
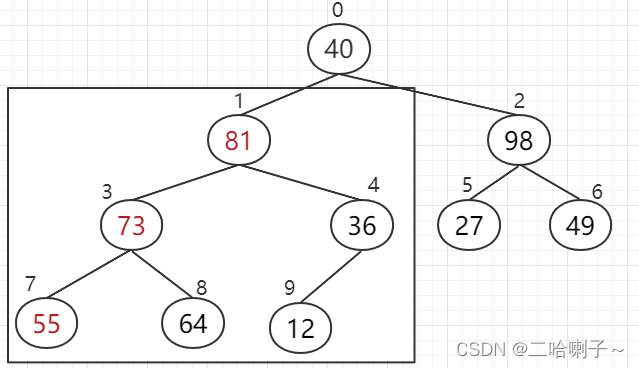
, then look at the subscripts 0, 1, 2, 98 is larger than 81, 40, and 98 goes up,
but now the subscripts 2, 5, 6, these three numbers (40, 27, 49) cannot form a big top heap,
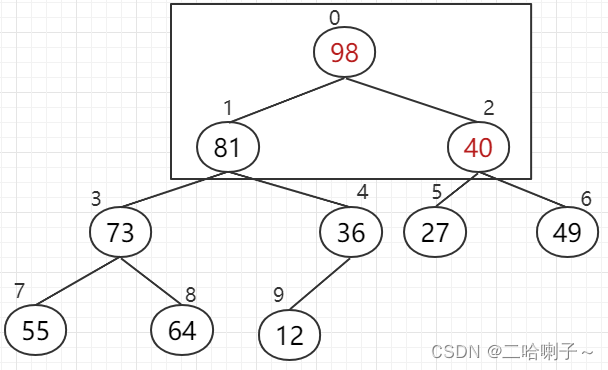
so After comparing the three numbers, 49 goes up
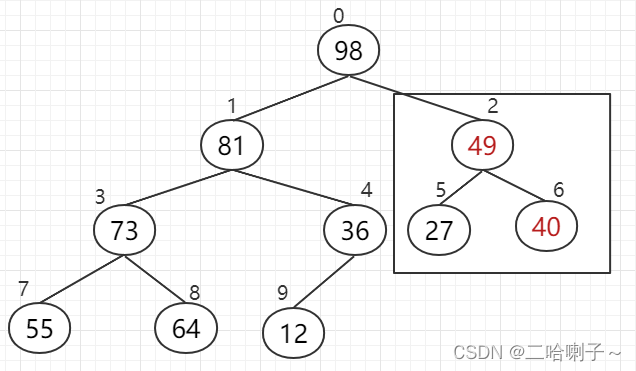
. Now, the left/right subtrees have been adjusted to heaps. Finally, only the root node needs to be adjusted so that the entire binary tree is a "heap".
This is the process of building a heap. Screening from bottom to top (according to the largest number and having children, in this question, adjust from 4, then 3, 2, and 1). During the adjustment process, pay attention to the possibility of breaking the subtree. Heap, need to continue to adjust.
code section
public class HeapSort {
public static void heapSort(int[] arr) {
if (arr == null || arr.length == 0) {
return;
}
int len = arr.length;
// 构建大顶堆,这里其实就是把待排序序列,变成一个大顶堆结构的数组
buildMaxHeap(arr, len);
// 交换堆顶和当前末尾的节点,重置大顶堆
for (int i = len - 1; i > 0; i--) {
swap(arr, 0, i);
len--;
heapify(arr, 0, len);
}
}
private static void buildMaxHeap(int[] arr, int len) {
// 从最后一个非叶节点开始向前遍历,调整节点性质,使之成为大顶堆
for (int i = (int)Math.floor(len / 2) - 1; i >= 0; i--) {
heapify(arr, i, len);
}
}
private static void heapify(int[] arr, int i, int len) {
// 先根据堆性质,找出它左右节点的索引
int left = 2 * i + 1;
int right = 2 * i + 2;
// 默认当前节点(父节点)是最大值。
int largestIndex = i;
if (left < len && arr[left] > arr[largestIndex]) {
// 如果有左节点,并且左节点的值更大,更新最大值的索引
largestIndex = left;
}
if (right < len && arr[right] > arr[largestIndex]) {
// 如果有右节点,并且右节点的值更大,更新最大值的索引
largestIndex = right;
}
if (largestIndex != i) {
// 如果最大值不是当前非叶子节点的值,那么就把当前节点和最大值的子节点值互换
swap(arr, i, largestIndex);
// 因为互换之后,子节点的值变了,如果该子节点也有自己的子节点,仍需要再次调整。
heapify(arr, largestIndex, len);
}
}
private static void swap (int[] arr, int i, int j) {
int temp = arr[i];
arr[i] = arr[j];
arr[j] = temp;
}
}
performance analysis
(1), time complexity:
O(nlog 2 n)
(2), the auxiliary space required:
O(1)
(3) Algorithm stability:
it is an unstable sorting method
Summarize
direct selection sort
First, select the record with the smallest keyword value among all records, exchange it with the first record, and then select the record with the second smallest keyword value from the rest of the records to exchange the position with the second record. And so on until all records are sorted.
tree sort
First compare the n records, the result of the comparison is that the one with the smaller keyword value is raised to the parent node as the winner, and the winner of the comparison (the one with the smaller keyword value) is obtained as the first step of comparison. The result is retained; then a pairwise comparison of keywords is performed on this record, and so on, until a record with the smallest keyword value is selected.
heap sort
If you want to sort in ascending order, you should create a large heap;
if you want to sort in descending order, you should create a small heap
To filter is to compare and exchange after being destroyed. Whoever is bigger will go up, from top to bottom
Building a heap is a process of "screening" from bottom to top.