It has been said that I have been learning big data Hadoop intermittently for a while, but I still feel dizzy. helped.
My system environment is Ubuntu16.04
Software I installed:
Mysql
Jdk1.8.0_121
apache-hive-2.1.1-bin
mysql-connector-java-5.1.42-bin.jar
hadoop2.8.0
Installation process:
- Because I haven't used MySQL that comes with the Ubuntu system for a long time, and the password is wrong no matter how I enter it, I still deleted it and reinstalled it.
sudo rm /var/lib/mysql/ -R
sudo rm /etc/mysql/ -R
sudo apt-get autoremove mysql* --purge
sudo apt-get remove apparmor
sudo apt-get install mysql-server
service mysql start
mysql -u root -p
Enter the root password you set yourself to enter mysql;
Then create hive database
create database hive
show databases
Later, I remembered that the password can be reset. The following method to reset the password is OK.
Go to /etc/mysql/mysql.conf.d, edit the mysqld.cnf file, and add a line of "skip-grant-tables" under the [mysqld] section
Restart the mysql service sudo service mysql restart
Enter the mysql management command line with an empty password and switch to the mysql library.
Then follow the steps in the screenshot to reset the root password to 123456

Go back to sudo gedit /etc/mysql/mysql.conf.d/mysqld.cnf, and comment or delete the line "skip-grant-tables" that was just added.
Restart the mysql service sudo service mysql restart again, log in with the new password, and the modification is successful.
2. Unzip the compressed packages of JDK, HIVE, and HADOOP. It is best to put these unzipped files in the same directory. After saving, I can't find them directly. I put them all in the hadoopEnv directory.
Use the command vim ~/.bashrc to configure the environment. My configuration is as follows. You can modify it according to the direct path.
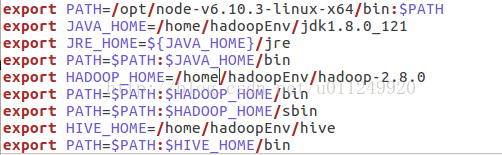
Then source ~/.bashrc will make the configuration take effect
Then you must remember to put mysql-connector-java-5.1.42-bin.jar in the lib directory of the hive directory, otherwise an error will be reported when you run hive, and you will not be able to connect to the database! ! !
At the same time, create a new warehouse folder in the hive directory.
3. Hive configuration
In Hive's conf directory, create a new hive-site.xml and perform some simple configurations. My configuration is as follows:
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/home/hadoopEnv/hive/warehouse</value>
<description>location of default database for the warehouse</description>
</property>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://localhost:3306/hive</value>
<description>JDBC connect string for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
<description>Driver class name for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword </name>
<value>Fill in your own password to connect to the database</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
<description>Username to use against metastore database</description>
</property>
</configuration>
PS: Of course, you can also create a new mysql account and password for HIVE, and then change the hive-site.xml configuration there to HIVE's Mysql account password; but you must remember to give it full permissions when logging in with the mysql root account, otherwise later Running hive will always prompt that access to the database is denied.
#创建数据库
mysql> create database hive;
#赋予访问权限
mysql> grant all privileges on hive.* to root@localhost identified by '密码' with grant option;
mysql> flush privileges;then the command line
cp hive-env.sh.template hive-env.sh4. Hadoop configuration (I am using local mode here)
(For details, please refer to the official website of apache hadoop)
First, configure ssh, not to elaborate;
Modify the information of each configuration file in the etc directory of hadoop
core-site.xml

hdfs-site.xml
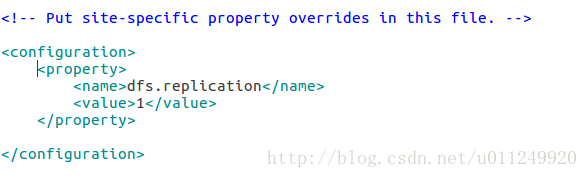
mapred-site.xml
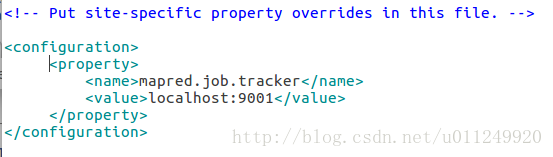
Because I am only taking the local, so first ssh localhost;
Go to the hadoop installation directory and run sbin/start-all.sh; then jps check whether all processes of hadoop are started correctly.
If the startup reports an error:
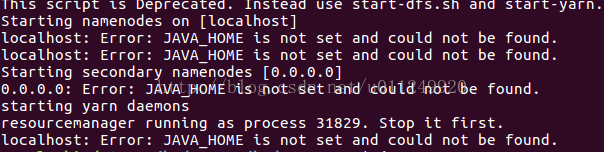
Solution:
Modify /etc/hadoop/hadoop-env.sh to set JAVA_HOME.
Absolute paths should be used.
export JAVA_HOME=${JAVA_HOME} //document original (error)
export JAVA_HOME=/home/wangly/hadoopEnv/jdk_ 1.8.0_121 //Correct, it should be changed like this
Create /tmp and /user/hive/warehouse directories on HDFS, and give group users write permissions.
HADOOP_HOME/bin/hadoop fs -mkdir /tmp
HADOOP_HOME/bin/hadoop fs -mkdir -p /user/hive/warehouse
HADOOP_HOME/bin/hadoop fs -chmod g+w /tmp
HADOOP_HOME/bin/hadoop fs -chmod g+w /user/hive/warehouse5. Run hive
Run hive --service metastore to start the hive service
Remember to initialize the hive database! ! !
.

Done~
In fact, I encountered various errors during the construction process!! Then I searched various online solutions, and finally succeeded. When you encounter problems, you must be patient, read the error log, and solve it step by step!