This article is published by NetEase Cloud
Author: Fan Xinxin
This article is only for sharing on this site. If you need to reprint, please contact NetEase for authorization.
In fact, the topic of operating system has been wanted to share with you for a long time. On the one hand, it has been delayed because of the lack of a thorough understanding of the various theories, and I am afraid that it will not be explained well; on the other hand, this problem seems to have been rare for a long time. Some people pay attention, here is the beginning of this topic. In fact, I have read these parameters several times before and after, but I have not fully understood them. Some time ago, I took advantage of the vacation to read these theories again. With a further understanding, I should sort them out here. The following figure shows several configuration requirements for the operating system environment on the official HBase documentation:

Don't be in a hurry to explain the specific meaning of each configuration. Before that, you need to focus on a concept: swap, yes, as far as this term you have heard more or less, the above parameters are more or less responsible. All have something to do with swap.
What is swap for?
Under Linux, the role of SWAP is similar to the "virtual memory" under Windows. When the physical memory is insufficient, take out part of the hard disk space to use as a SWAP partition (virtualized memory) to solve the problem of insufficient memory capacity.
SWAP means swap. As the name suggests, when a process requests the OS to find insufficient memory, the OS will swap out the temporarily unused data in the memory and put it in the SWAP partition. This process is called SWAPOUT. When a process needs these data and the OS finds that there is free physical memory, it will swap the data in the SWAP partition back to the physical memory. This process is called SWAPIN.
Of course, the swap size has an upper limit. Once the swap is used up, the operating system will trigger the OOM-Killer mechanism to kill the process that consumes the most memory to release the memory.
Why do database systems dislike swap?
Obviously, the original intention of the swap mechanism is to alleviate the embarrassment of directly rude OOM process in order to alleviate the physical memory exhaustion. But frankly, almost all databases don't like swap very much, whether MySQL, Oracal, MongoDB or HBase, why? This is mainly related to the following two aspects:
1. Database systems are generally sensitive to response delays. If swap is used instead of memory, the performance of database services must be unacceptable. For a system that is extremely sensitive to response delays, there is no difference between too much delay and unavailability of services. More serious than unavailability of services is that the process in the swap scenario is immortal, which means that the system has been unavailable... and think about if Is it a better choice to directly oom without using swap? In this way, many high-availability systems will be switched directly from master to slave, and users are basically unaware.
2. In addition, for distributed systems such as HBase, we are not worried about a node going down, but just worry about a node stagnating. When a node goes down, at most a small number of requests are temporarily unavailable and can be recovered by retrying. However, if a node is stagnant, all distributed requests will be slammed, and server-side thread resources will be occupied, causing the entire cluster to be blocked, or even the cluster will be dragged down.
From these two perspectives, it makes sense that all databases don't like swap!
How swap works
Since the databases don't like swap, is it necessary to use the swapoff command to turn off the disk cache feature? No, you can think about it, what does it mean to turn off the disk cache? In the actual production environment, no system is so radical. You must know that the world is never either 0 or 1. Everyone will choose to walk in the middle more or less, but some are biased towards 0 and some are biased towards 1. Obviously, on the issue of swap, the database must choose to use as little as possible. Several requirements of HBase's official documentation are actually to implement this policy: to minimize the impact of swap. Knowing yourself and your enemy can help you win a hundred battles. To reduce the impact of swap, you must understand how Linux memory recycling works, so as not to miss any possible doubts.
How is swap triggered?
To put it simply, Linux will trigger memory reclamation in two scenarios. One is to trigger memory reclamation immediately when it finds that there is not enough free memory during memory allocation; the other is to start a daemon process (swapd process) periodically to the system. Memory checks and proactively triggers memory reclamation after available memory drops below a certain threshold. The first scenario has nothing to say, let's focus on the second scenario, as shown in the following figure:
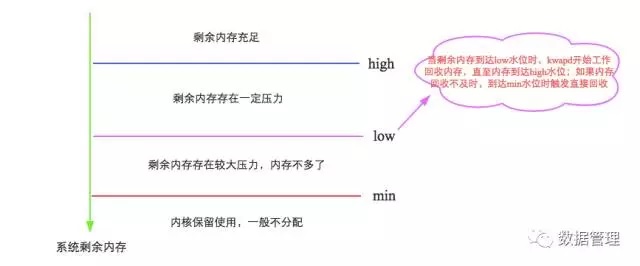
Here is the first parameter we are concerned about: vm.min_free_kbytes, which represents the minimum watermark[min] of the free memory reserved by the system, and affects watermark[low] and watermark[high]. It is simple to think that:
watermark[min] = min_free_kbytes watermark[low] = watermark[min] * 5 / 4
= min_free_kbytes * 5 / 4 watermark[high] = watermark[min] * 3 / 2
= min_free_kbytes * 3 / 2 watermark[high] - watermark[low]
= watermark[low] - watermark[min]
= min_free_kbytes / 4
It can be seen that these water levels of LInux are inseparable from the parameter min_free_kbytes. The importance of min_free_kbytes to the system is self-evident, neither too large nor too small.
If min_free_kbytes is too small, the water level buffer between [min, low] will be very small. During the kswapd recycling process, once the upper layer requests memory too fast
(Typical application: database), it will cause the free memory to easily drop below the watermark[min]. At this time, the kernel will perform directreclaim (direct reclaim), reclaim directly in the process context of the application, and then use the recovered The free page satisfies the memory request, so it will actually block the application, resulting in a certain response delay. Of course, min_free_kbytes should not be too large. On the one hand, if it is too large, it will reduce the memory of the application process and waste system memory resources. On the other hand, it will also cause the kswapd process to spend a lot of time for memory recovery. Look at this process again. Is it similar to the old generation recycling trigger mechanism in the CMS algorithm in the Java garbage collection mechanism? Think about the parameter -XX:CMSInitiatingOccupancyFraction, right? The official document requires that min_free_kbytes cannot be less than 1G (8G in a large memory system), that is, do not trigger direct recycling easily.
So far, the memory reclamation trigger mechanism of Linux and the first parameter vm.min_free_kbytes we are concerned about have been basically explained. Next, let's take a brief look at what Linux memory reclamation reclaims. There are two main types of Linux memory reclamation objects:
1. File cache, this is easy to understand. In order to avoid the file data being read from the hard disk every time, the system will store hot data in memory to improve performance. If you just read the file, you only need to release this part of the memory for memory recovery, and the next time you read the file data, you can directly read it from the hard disk (similar to HBase file cache). If you not only read the file, but also modify the cached file data (dirty data), to reclaim the memory, you need to write this part of the data file to the hard disk and release it (similar to the MySQL file cache).
2. Anonymous memory, this part of the memory has no actual carrier, unlike the file cache, which has a carrier such as a hard disk file, such as typical heap, stack data, etc. This part of memory cannot be directly released or written back to a file-like medium when it is reclaimed. That’s why the swap mechanism is created to swap out this type of memory to the hard disk and load it when needed.
What algorithm does Linux use to confirm which file cache or anonymous memory needs to be recycled? I don't care here. If you are interested, you can refer to it here. But there is a problem that we need to think about: Since there are two types of memory that can be reclaimed, how does Linux decide which type of memory to reclaim when both types of memory can be reclaimed? Or will both be recycled? Here comes the second parameter we care about: swappiness. This value is used to define how aggressively the kernel uses swap. The higher the value, the more active the kernel will use swap, and the lower the value, the lower the use of swap . positivity. The value ranges from 0 to 100, and the default is 60 . How is this swappiness achieved? The specific principle is very complicated. In short, swappiness achieves this effect by controlling more anonymous pages to be reclaimed or more cached files to reclaim when memory is reclaimed. swappiness is equal to 100, which means that anonymous memory and file cache will be recycled with the same priority. The default value of 60 means that file cache will be recycled first. As for why file cache should be recycled first, you might as well think about it (recycling file cache is usually the case It will not cause IO operations and has less impact on system performance). For the database, swap is to be avoided as much as possible, so it needs to be set to 0. It should be noted here that setting to 0 does not mean that swap is not executed!
So far, we have talked about the Linux memory recovery trigger mechanism, Linux memory recovery objects all the way to swap, and explained the parameters min_free_kbytes and swappiness. Next, let's take a look at another parameter related to swap: zone_reclaim_mode , the document says that setting this parameter to 0 can turn off NUMA's zonereclaim, what's going on? When it comes to NUMA, the databases are not happy again, and many DBAs have been miserable. So here are three simple questions: What is NUMA? What does NUMA have to do with swap? What is the specific meaning of zone _reclaim _mode?
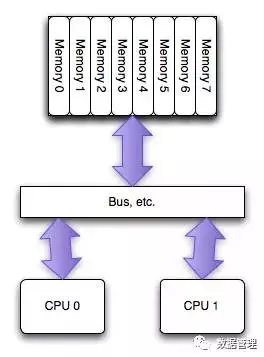
NUMA (Non-UniformMemoryAccess) is relative to UMA. Both are CPU design architectures. Early CPUs were designed as UMA structures, as shown below.
(The picture comes from the Internet) as shown:
In order to alleviate the channel bottleneck problem encountered by multi-core CPUs reading the same piece of memory, chip engineers have designed a NUMA structure, as shown in the following figure (picture from the network):

This architecture can well solve the problem of UMA, that is, different CPUs have dedicated memory areas. In order to achieve "memory isolation" between CPUs, two points of support at the software level are also required:
1. Memory allocation needs to be allocated in the dedicated memory area of the CPU where the requesting thread is currently located. If it is allocated to other CPU exclusive memory areas, the isolation will be affected to a certain extent, and the memory access performance across the bus will inevitably be reduced to a certain extent.
2. In addition, once the local memory (exclusive memory) is not enough, the memory pages in the local memory are eliminated first, instead of checking whether there is free memory borrowing in the remote memory area.
In this way, the isolation is really good, but the problem also comes: NUMA may lead to unbalanced CPU memory usage, some CPU-specific memory is not used enough, and it needs to be recycled frequently, which may cause a large number of swaps, and the system response delay will be serious. jitter. At the same time, other parts of the CPU-specific memory may be idle. This will produce a strange phenomenon: use the free command to check that the current system still has some free physical memory, but the system continues to swap, resulting in a sharp drop in the performance of some applications. See Teacher Ye Jinrong's MySQL case analysis: "Finding the culprit of SWAP on MySQL server".
Therefore, for small memory applications, the problem brought by NUMA is not prominent. On the contrary, the performance improvement brought by local memory is considerable. However, for large memory users such as databases, the stability risks brought by the default NUMA strategy are unacceptable. Therefore, the databases strongly demand that the default strategy of NUMA be improved. There are two aspects that can be improved:
1. Change the memory allocation strategy from the default affinity mode to interleave mode, which will break up the memory pages and allocate them to different CPUzones. In this way, the problem of uneven distribution of memory is solved, and the strange problem in the above case is alleviated to a certain extent. For MongoDB, it will prompt to use the interleave memory allocation strategy at startup:
WARNING: You are running on a NUMA machine.
We suggest launching mongod like this to avoid performance problems:
numactl –interleave=all mongod [other options]
2. Improve the memory reclaim strategy: I finally ask today's third protagonist parameter zone_reclaim_mode. This parameter defines different memory reclaim strategies under the NUMA architecture, and can take values 0/1/3/4, where 0 means local If the memory is not enough, you can go to other memory areas to allocate memory; 1 means that when the local memory is not enough, the local reclamation first and then allocate; 3 means that the local reclamation first reclaims the file cache object as much as possible; 4 means that the local reclamation preferentially uses swap Reclaim anonymous memory. It can be seen that HBase recommends configuring zone_reclaim_mode=0 to reduce the probability of swap to a certain extent.
It's not all about swap
1. IO scheduling strategy: There are many explanations on this topic on the Internet. I do not intend to go into details here, but only give the results. Usually for OLTP databases on sata disks, the deadline algorithm
The scheduling strategy is the optimal choice.
2. The THP (transparenthugepages) feature is turned off. The author has been wondering about the THP feature for a long time. There are two main points of doubt. One is whether THP and HugePage are the same thing, and the other is why HBase requires THP to be turned off . After reviewing the relevant documents many times, I finally found some clues. Here are four small points to explain the THP characteristics:
( 1) What is HugePage?
There are many explanations of HugePage on the Internet , you can search and read. To put it simply, computer memory is addressed by means of table mapping (memory index table). Currently, system memory uses 4KB as a page, which is the smallest unit of memory addressing. As the memory continues to grow, the size of the in-memory index table will continue to grow. If a machine with 256G memory uses 4KB small pages, the size of the index table alone will be about 4G. You must know that this index table must be installed in memory, and it is in CPU memory. If it is too large, a large number of misses will occur, and the memory addressing performance will decrease.
HugePage is to solve this problem. HugePage uses 2MB large pages instead of traditional small pages to manage memory, so that the size of the memory index table can be controlled very small, and then all of them are installed in CPU memory to prevent misses.
( 2) What is THP (TransparentHugePages)?
HugePage is a huge page theory, so how to use the HugePage feature? At present, the system provides two usage methods, one is called StaticHugePages, and the other is TransparentHugePages. The former can be known from the name as a static management strategy, which requires the user to manually configure the number of huge pages according to the system memory size, so that the corresponding number of huge pages will be generated when the system starts, and will not be changed in the future. TransparentHugePages is a dynamic management strategy that dynamically allocates huge pages to applications at runtime, and manages these huge pages, which is completely transparent to users and does not require any configuration. Also, currently THP only targets anonymous memory regions.
( 3) Why does HBase (database) require the THP feature to be turned off?
THP is a dynamic management strategy that allocates and manages huge pages during runtime, so there will be a certain degree of allocation delay, which is unacceptable for database systems that pursue response delay. In addition, THP has many other drawbacks, you can refer to this article "why-tokudb-hates-transparent-hugepages"
( 4) How much does THP turn off/on affect HBase read and write performance?
In order to verify the impact of THP on and off the performance of HBase, I did a simple test in the test environment: the test cluster has only one RegionServer, and the test load is a read-write ratio of 1:1. THP has two options of always and never in some systems, and in some systems there is an option called madvise. THP can be turned off/on with the command echoever/always>/sys/kernel/mm/transparent_hugepage/enabled. The test results are shown in the following figure:

As shown in the figure above, in the scenario where TPH is turned off (never), HBase has the best performance and is relatively stable. In the scene where THP is turned on (always), the performance drops by about 30% compared to the scene with THP turned off, and the curve jitters a lot. It can be seen that HBase online remember to turn off THP.
Summarize
The performance of any database system is related to many factors, including various factors of the database itself, such as database configuration, client usage, capacity planning, table scheme design, etc. In addition, the impact of the basic system on it is also Critical, such as operating system, JVM, etc. Many times the database encounters some performance problems, and the left and right searches cannot locate the specific cause. At this time, it is necessary to check whether the configuration of the operating system is reasonable. This article starts from several parameters required by HBase official documents, and explains the specific meanings of these parameters in detail.
NetEase has a number: an enterprise-level big data visualization analysis platform. The self-service agile analysis platform for business personnel uses PPT mode for report production, which is easier to learn and use, and has powerful exploration and analysis functions, which really help users gain insight into data and discover value. Click here for a free trial .
Learn about NetEase Cloud :
NetEase Cloud official website: https://www.163yun.com/
New user gift package: https://www.163yun.com/gift
NetEase Cloud Community: https://sq.163yun.com/