Kafka cluster construction and producer-consumer case
The cluster built in this article uses three machines, namely server01,server02,server03: linux system is centos6.7.
kafka needs to be used with zookeeper. Before installing kafka, you need to install the zookeeper cluster. For installing the zookeeper cluster, you can refer to: Zookeeper cluster environment construction
1. Building a Kafka cluster
1.1 Download the kafka installation package
Go to the download page of kafka's official website to download, the download page link is as follows:
The version installed in this article is:kafka_2.12-1.1.0.tgz
1.2 Upload linux machine, unzip, rename
/hadoop1.2.1 Upload to the directory of the server01 machine
scp kafka_2.12-1.1.0.tgz hadoop@server01:/hadoop1.2.2 Unzip:
tar -zxvf kafka_2.12-1.1.0.tgz1.2.3 Rename to kafka
mv kafka_2.12-1.1.0 kafka1.3 Configure the configuration file of kafka
Enter the kafka/config directory and edit the server.propertiesfile, as shown in the figure:
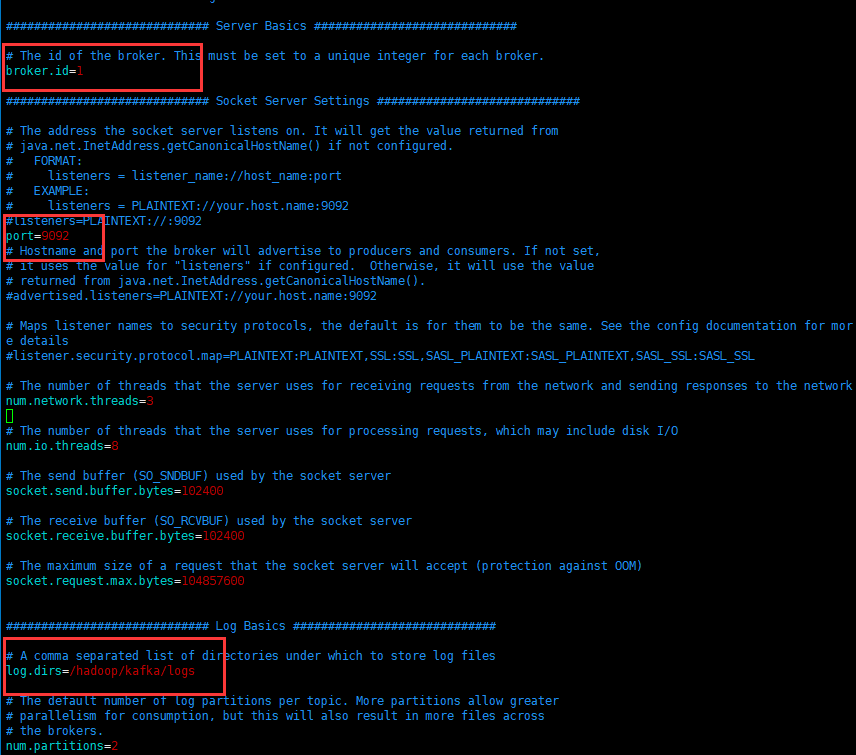
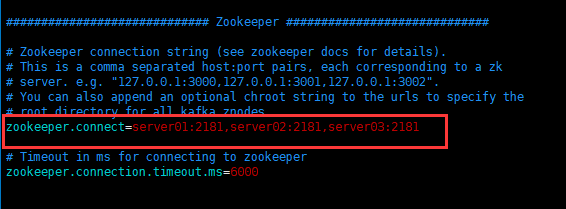
The red boxes are those that need to be modified by yourself, and the rest are defaults.
1.4 Distribute the kafka directory to server02, server03 machines
scp -r /hadoop/kafka hadoop@server02:/hadoop
scp -r /hadoop/kafka hadoop@server03:/hadoopModify broker.id in kafka/config/server.properties file (important)
As follows:


1.5 Setting environment variables
For each machine, configure environment variables
At the end of the /etc/profile file, write the following environment variables
export KAFKA_HOME=/hadoop/kafka
export PATH=$PATH:$KAFKA_HOME/binMake environment variables take effect
source /etc/profile1.6 Start the kafka cluster
On each machine, start kafka
# kafka目录,指定server.properties配置文件启动,-daemon:在后台启动
./bin/kafka-server-start.sh -daemon ./config/server.properties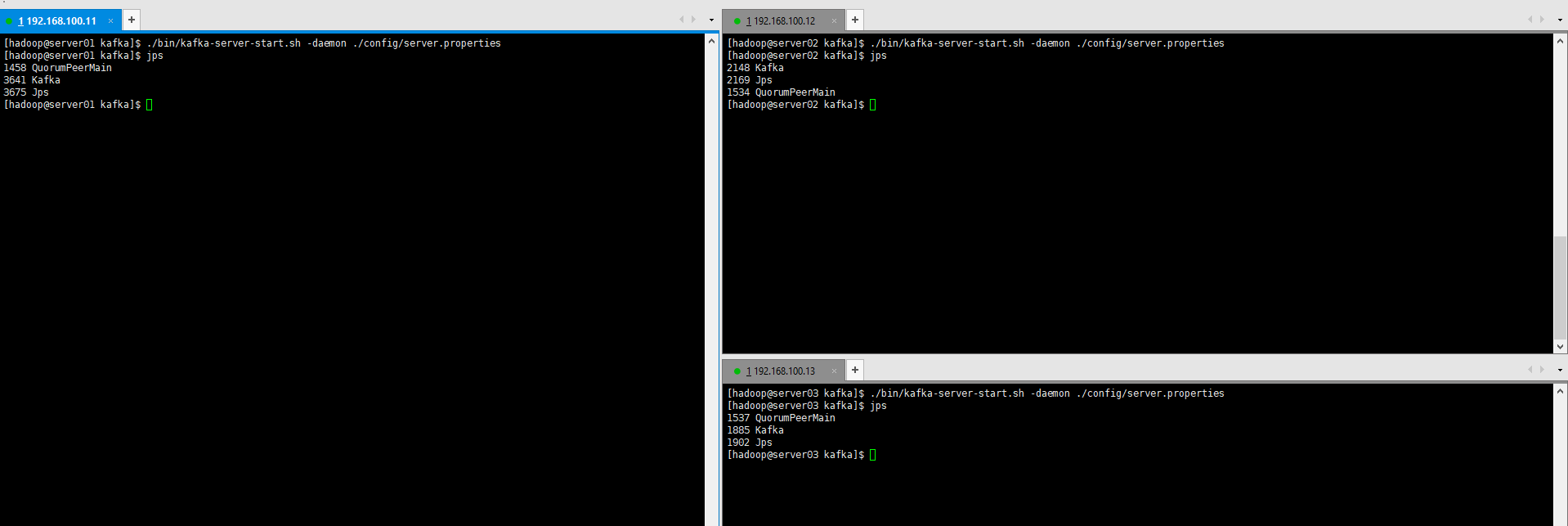
We can use the jps command to see that the kafkas of the three machines are all up.
Pay attention to a problem: if the broker.id of the cluster is repeated, kafka will hang after it gets up
Introduction to common commands in Kafka
- start up
# 显示启动
./bin/kafka-server-start.sh ./config/server.properties
# 在后台启动
./bin/kafka-server-start.sh -daemon ./config/server.properties- create topic
# --create:表示创建
# --zookeeper 后面的参数是zk的集群节点
# --replication-factor 3 :表示复本数
# --partitions 3:表示分区数
# --topic test:表示topic的主题名称
./bin/kafka-topics.sh --create --zookeeper server01:2181,server02:2181,server03:2181 --replication-factor 3 --partitions 3 --topic test- View topic
./bin/kafka-topics.sh --list --zookeeper server01:2181- delete topic
To delete a topic, you need server.propertiesto set it in , delete.topic.enable=trueotherwise just mark it for deletion or restart directly.
./bin/kafka-topics.sh --delete --zookeeper server01:2181 --topic test- execute producer command
./bin/kafka-console-producer.sh --broker-list server01:9092 --topic testExecute this command, you can enter messages (production messages) in the command window
- execute consumer commands
# --from-beginning:表示从生产的开始获取数据
./bin/kafka-console-consumer.sh --zookeeper server01:2181 --from-beginning --topic test- View topic for more detailed information
./bin/kafka-topics.sh --topic test --describe --zookeeper server01:2181Producer and Consumer Case
shell implementation
- Start the
zookeepercluster and thekafkacluster
- Start the
It was already mentioned during installation
- create topic
./bin/kafka-topics.sh --create --zookeeper server01:2181,server02:2181,server03:2181 --replication-factor 3 --partitions 3 --topic test_shell
- Execute the producer's command on the server01 machine
./bin/kafka-console-producer.sh --broker-list server01:9092 --topic test_shell- Execute the consumer's command on the server02 machine
./bin/kafka-console-consumer.sh --zookeeper server01:2181 --from-beginning --topic test_shell- In the server01 producer command window, enter some messages and press enter, the effect is as follows:

- java api implementation :
pom.xml configures kafka dependencies:
<dependencies>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka_2.9.2</artifactId>
<version>0.8.1.1</version>
</dependency>
</dependencies>Producer producer code
public class KafkaProducer {
public static void main(String[] args) throws InterruptedException {
Properties p = new Properties();
// 设置配置信息
p.put("serializer.class", "kafka.serializer.StringEncoder");// 指定序列化数据的对象,不然会导致序列化和传递的数据类型不一致
p.put("metadata.broker.list", "server01:9092");// 指定kafka broker对应的主机,格式为 host:port,host:port,...
ProducerConfig config = new ProducerConfig(p);
Producer<String, String> producer = new Producer<String, String>(config);
int count = 0;
while (true) {
// test_java:表示主题
KeyedMessage<String, String> message = new KeyedMessage<String, String>("test_java", "message_" + count);
// 发送消息
producer.send(message);
count++;
Thread.sleep(5000);
}
}
}Consumer consumer code
public class KafkaConsumer {
public static void main(String[] args) {
Properties p = new Properties();
p.put("group.id", "testGroup");// 设置group.id,必须要设置,不然报错
p.put("zookeeper.connect", "server01:2181,server02:2181,server02:2181");//zk集群设置
p.put("auto.offset.reset", "smallest");//从头开始消费,如果是largeest:表示从最后开始消费
p.put("auto.commit.interval.ms", "1000");// consumer向zookeeper提交offset的频率,单位是秒
// 在“range”和“roundrobin”策略之间选择一种作为分配partitions给consumer 数据流的策略
p.put("partition.assignment.strategy", "roundrobin");
// 将属性添加到ConsumerConfig配置中
ConsumerConfig conf = new ConsumerConfig(p);
// 创建连接
ConsumerConnector connector = Consumer.createJavaConsumerConnector(conf);
Map<String, Integer> map = new HashMap<String, Integer>();
// 设置主题,并设置partitions分区
map.put("test_java", 2);
// 创建信息流,返回一个map,map里面装载是topic对应的流信息
Map<String, List<KafkaStream<byte[], byte[]>>> streams = connector.createMessageStreams(map);
// 通过主题topic获取留信息
final List<KafkaStream<byte[], byte[]>> kafkaStreams = streams.get("test_java");
// 通过线程池获取流信息的数据
ExecutorService service = Executors.newFixedThreadPool(4);
for (int i = 0; i < streams.size(); i++) {
final int index = i;
service.execute(new Runnable() {
public void run() {
//获取信息数据,包含topic,partition,message等信息
KafkaStream<byte[], byte[]> messageAndMetadatas = kafkaStreams.get(index);
for (MessageAndMetadata<byte[], byte[]> data : messageAndMetadatas) {
String topic = data.topic();
int partition = data.partition();
String message = new String(data.message());
// 信息输出至控制台
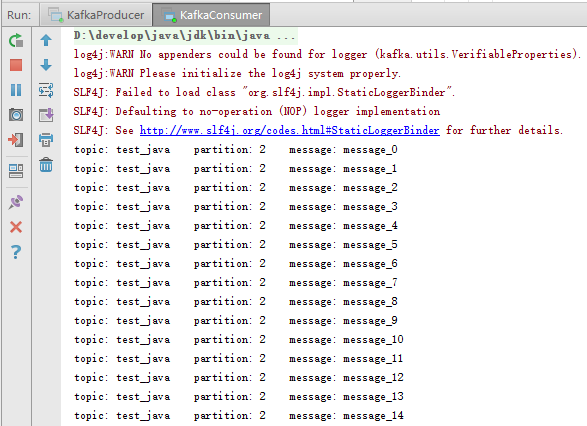
System.out.println("topic: " + topic + " partition: " + partition + " message: " + message);
}
}
});
}
}
}
Create a topic topic:
./bin/kafka-topics.sh --create --zookeeper server01:2181,server02:2181,server03:2181 --replication-factor 3 --partitions 3 --topic test_javaResults of the: