background
Is JSON/XML bad?
Well, there is no serialization scheme as popular as JSON and XML, free, convenient, powerful expressive and cross-platform. is the default preference for common data transfer formats. However, with the increase in the amount of data and the improvement of performance requirements, the performance problems brought about by this freedom and generality cannot be ignored.
JSON and XML use strings to represent all data. For non-character data, literal representation takes up a lot of extra storage space and is severely affected by the size and precision of the value. A 32-bit floating point number 1234.5678 occupies 4 bytes of space in memory. If it is stored as utf8, it needs to occupy 9 bytes of space. In the environment where utf16 is used to express strings like JS, it needs to occupy 18 bytes of space. Using regular expressions for data parsing is very inefficient when dealing with non-character data. It not only consumes a lot of operations to parse the data structure, but also converts literals into corresponding data types.
In the face of massive data, this format itself can become the IO and computing bottleneck of the entire system, or even direct overflow.
What's beyond JSON/XML?
Among the many serialization schemes, according to the storage scheme, it can be divided into string storage and binary storage. String storage is readable, but due to the above problems, only binary storage is considered here. Binary storage can be divided into those that require IDL and those that do not require IDL, or are divided into self-describing and non-self-describing (whether IDL is required for deserialization).
The process of using IDL is required:
-
Write the schema using the IDL syntax defined by the schema
-
Use the compiler provided by the solution to compile the schema into code (class or module) in the language used by the producers and consumers
-
The data producer refers to the code, constructs the data according to its interface, and serializes it
-
The consumer refers to the code and reads data according to its interface
The process of using IDL is not required:
-
The producer and the consumer agree on the data structure through the document
-
Producer Serialization
-
Consumer Deserialization
etc.
-
protocol buffers
-
Transport protocol used by gRPC, binary storage, requires IDL, not self-describing
-
High compression rate, highly expressive, widely used in Google products
-
flat buffers
-
Google launches serialization scheme, binary storage, requires IDL, non-self-describing (self-describing scheme is not cross-platform)
-
High performance, small size, support string, number, boolean
-
avro
-
The serialization scheme used by Hadoop, which combines the advantages of the binary scheme and the string scheme, only the serialization process requires IDL, self-describing
-
However, the scene is limited, there is no mature JS implementation, and it is not suitable for the Web environment. No comparison is made here.
-
Thrift
-
Facebook's scheme, binary storage, requires IDL, non-self-describing
-
Basically only integrated and used in RPC, no comparison is made here
-
DIMBIN
-
Serialization scheme designed for multi-dimensional arrays, binary storage, no IDL required, self-describing
-
High performance, small size, support string, number, boolean
Private message me to receive the latest and most complete C++ audio and video learning and improvement materials, including ( C/C++ , Linux , FFmpeg , webRTC , rtmp , hls , rtsp , ffplay , srs )


Optimization principle
Principles of space optimization
Using numeric types instead of literals to store values can save a considerable amount of space in itself. Protocol buffers use varints to compress values in order to achieve higher compression ratios. (However, the tests below show that in environments where gzip can be used, this solution does not help)
The principle of time optimization
The binary format uses a specific location to record the data structure and the offset of each node data, which saves the time spent parsing the data structure from the string and avoids the performance problems caused by long strings. In the GC language , and also greatly reduce the generation of intermediate waste.
In environments that can perform direct memory operations (including JS), data can also be directly read through memory offsets, avoiding copy operations and opening up additional memory space. Both DIMBIN and flatbuffers use this idea to optimize data storage performance. In the JS environment, the time-consuming to extract data from the memory segment by creating a DataView or TypedArray is basically negligible.
Storing strings in the binary scheme requires additional logic for UTF8 encoding and decoding, and the performance and volume are not as good as string formats such as JSON.
What is DIMBIN?
Our data visualization scenarios often involve real-time updates of millions or even tens of millions of pieces of data. In order to solve the performance problem of JSON, we used the idea of memory offset operation to develop DIMBIN as a serialization scheme, and based on it, we designed Many transport formats for web-side data processing.
As a simple and straightforward optimization idea, DIMBIN has become our standard solution for data transmission, maintaining absolute simplicity and efficiency.
We have just open-sourced DIMBIN and contributed to the community, hoping to bring you a lighter, faster, and more web-friendly solution than JSON/protocol/flatbuffers.
Scheme comparison
For use in the Web/JS environment, we choose four solutions: JSON, protocol buffers, flat buffers, and DIMBIN, and compare them from seven aspects.
Engineering
Protocolbuffers and flatbuffers represent the complete workflow advocated by Google. Strict, standardized, unified, IDL-oriented, designed for multi-terminal collaboration, for python/java/c++. Generate code through IDL, and use a consistent development process for multiple platforms/multiple languages. If the team adopts this kind of workflow, then this solution is more manageable, and the multi-end collaboration and interface change are more controllable.
But if you leave this engineering structure, it will be relatively complicated.
JSON/XML and DIMBIN are neutral, do not require IDL, and do not make assumptions or restrictions on engineering solutions and technology selection. You can only pass the document specification interface, or you can add schema constraints yourself.
Deployment/coding complexity
Protocolbuffers and flatbuffers should be added at an early stage of project design and as a key link in the workflow. If it is added for performance optimization purposes, it will have a greater impact on the project architecture.
JSON is basically the infrastructure of all platforms, with no deployment costs.
DIMBIN only requires one package to be installed, but requires data structure flattening, if the data structure cannot be flattened, it will not benefit from it.
When used in JS:
-
The number of lines of code deserialized using JSON serialization is basically within 5
-
Using DIMBIN is about 10 lines
-
To use the protocol, you need to write a schema (proto) file separately, and import hundreds of lines of compiled code. When serializing and deserializing, you need to operate the data of each node through an object-oriented interface (each node on the data structure is is an object)
-
To use flatbuffer, you need to write a schema (fbs) file separately, and introduce hundreds of lines of compiled code. The serialization process needs to process each node through a state machine-style interface, manually convert and put the data of each node, and the writing experience is relatively abrasive. People; the deserialization process reads the data of each node through the object operation interface
Performance (JS environment)
Protocol's official website claims that the performance is higher than JSON. The test data is obviously not JS-side. Our test shows that its JS-side performance is worse than JSON (it is much worse when the amount of data is large).
The process of processing strings in all binary schemes is similar: utf16 in js needs to be decoded into unicode, then encoded into utf8, written to the buffer, and the data address of each string is recorded. This process is expensive in performance, and if varint (protocol buffers) is not used, there is no advantage in size.
When dealing with string data, JSON performance is always the best, serialization performance JSON > DIMBIN > flatbuffers > proto, deserialization JSON > proto > DIMBIN > flatbuffers
Flatbuffers and DIMBIN have obvious performance advantages when dealing with numerical data.
Serialization properties for flattened numeric data DIMBIN > flatbuffers > JSON > proto,
Deserialize DIMBIN > flatbuffers > 100,000 times > JSON > proto
volume
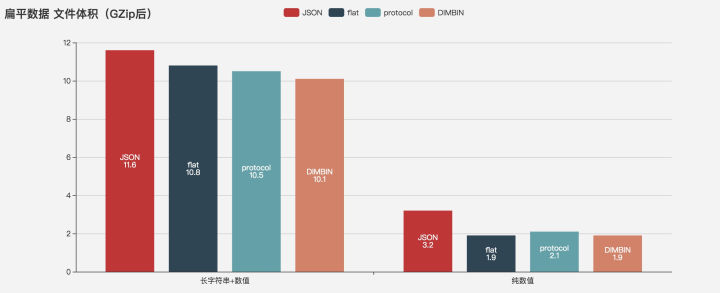
When using a mixed structure of strings and numbers or pure numbers, protocol < DIMBIN < flat < JSON When using pure strings, JSON is the smallest, and the binary scheme is relatively large
After Gzip, the volume of DIMBIN and flat is the smallest and basically the same, but the protocol has no advantage. It is guessed that it may be a side effect of varint.
expressiveness
Protocol is designed for strongly typed languages, the supported types are much richer than JSON, and the data structure can be very complex; Flatbuffers supports three basic types of numeric/boolean/string, and the structure is similar to JSON; DIMBIN supports numeric/boolean There are three basic types of value/string. Currently, only multi-dimensional array structures are supported (key-value pairs are not supported or encouraged), and more complex structures need to be encapsulated on them.
degrees of freedom
Both JSON and DIMBIN are self-describing, (in weakly typed languages) schema is not required, users can dynamically generate data structures and data types, and the producer and consumer can agree on it. If type checking is required, it needs to be encapsulated in the upper layer .
Protocolbuffers and flatbuffers must write IDL and generate the corresponding code before coding. To modify the interface, you need to modify the IDL and regenerate the code, deploy it to the producer and consumer, and then encode based on it.
-
The C++ and java implementations of Protocolbuffers have self-describing features, which can be embedded in .proto files, but still need to compile a top-level interface to describe this "self-describing embedded data", which is basically not practical, and its documentation also says that Google's internal Never used it this way (not in line with IDL's design principles).
-
flatbuffers has a self-describing fork (flexbuffers), experimental, no JS support, no related documentation.
Multilingual support
Protocolbuffers and flatbuffers server and client language support is complete. The two are preferentially developed for C++/Java(android)/Python. The JS side lacks some advanced functions and has no complete documentation. You need to study the example and the generated code yourself, but the code is not long and the comments are fully covered.
JSON has tools for basically all programming languages.
DIMBIN is developed and optimized for JS/TS, and currently provides c# version, and support for c++, wasm, java and python is planned.
Use case (only test JS environment)
We generate a typical data, use flat and non-flat structures, use JSON, DIMBIN, protocol and flat buffers to achieve the same function, and compare the performance, volume and convenience of various solutions.
Test Data
We generate two versions of test data: non-flattened (multi-layered key-value structure) data and equivalent flattened (multidimensional array) data
Considering the particularity of string processing, we tested string/numeric mixed data, pure string data, and pure numeric data separately during testing.
// 非扁平化数据
export const data = {
items: [
{
position: [0, 0, 0],
index: 0,
info: {
a: 'text text text...',
b: 10.12,
},
},
// * 200,000 个
],
}
// 等效的扁平化数据
export const flattedData = {
positions: [0, 0, 0, 0, 0, 1, ...],
indices: [0, 1, ...],
info_a: ['text text text', 'text', ...],
info_b: [10.12, 12.04, ...],
}JSON
Serialization
const jsonSerialize = () => {
return JSON.stringify(data)
}deserialize
const jsonParse = str => {
const _data = JSON.parse(str)
let _read = null
// 由于flat buffers的读取操作是延后的,因此这里需要主动读取数据来保证测试的公平性
const len = _data.items.length
for (let i = 0; i < len; i++) {
const item = _data.items[i]
_read = item.info.a
_read = item.info.b
_read = item.index
_read = item.position
}
}DIMBIN
Serialization
import DIMBIN from 'src/dimbin'
const dimbinSerialize = () => {
return DIMBIN.serialize([
new Float32Array(flattedData.positions),
new Int32Array(flattedData.indices),
DIMBIN.stringsSerialize(flattedData.info_a),
new Float32Array(flattedData.info_b),
])
}deserialize
const dimbinParse = buffer => {
const dim = DIMBIN.parse(buffer)
const result = {
positions: dim[0],
indices: dim[1],
info_a: DIMBIN.stringsParse(dim[2]),
info_b: dim[3],
}
}DIMBIN currently only supports multi-dimensional arrays and cannot handle tree-like data structures, so there is no comparison here.
Protocol Buffers
schema
First, you need to write the schema according to the proto3 syntax
syntax = "proto3";
message Info {
string a = 1;
float b = 2;
}
message Item {
repeated float position = 1;
int32 index = 2;
Info info = 3;
}
message Data {
repeated Item items = 1;
}
message FlattedData {
repeated float positions = 1;
repeated int32 indices = 2;
repeated string info_a = 3;
repeated float info_b = 4;
}compile to js
Compile the schema into a JS module using the protoc compiler
./lib/protoc-3.8.0-osx-x86_64/bin/protoc ./src/data.proto --js_out=import_style=commonjs,,binary:./src/generated
Serialization
// 引入编译好的JS模块
const messages = require('src/generated/src/data_pb.js')
const protoSerialize = () => {
// 顶层节点
const pbData = new messages.Data()
data.items.forEach(item => {
// 节点
const pbInfo = new messages.Info()
// 节点写入数据
pbInfo.setA(item.info.a)
pbInfo.setB(item.info.b)
// 子级节点
const pbItem = new messages.Item()
pbItem.setInfo(pbInfo)
pbItem.setIndex(item.index)
pbItem.setPositionList(item.position)
pbData.addItems(pbItem)
})
// 序列化
const buffer = pbData.serializeBinary()
return buffer
// 扁平化方案:
// const pbData = new messages.FlattedData()
// pbData.setPositionsList(flattedData.positions)
// pbData.setIndicesList(flattedData.indices)
// pbData.setInfoAList(flattedData.info_a)
// pbData.setInfoBList(flattedData.info_b)
// const buffer = pbData.serializeBinary()
// return buffer
}deserialize
// 引入编译好的JS模块
const messages = require('src/generated/src/data_pb.js')
const protoParse = buffer => {
const _data = messages.Data.deserializeBinary(buffer)
let _read = null
const items = _data.getItemsList()
for (let i = 0; i < items.length; i++) {
const item = items[i]
const info = item.getInfo()
_read = info.getA()
_read = info.getB()
_read = item.getIndex()
_read = item.getPositionList()
}
// 扁平化方案:
// const _data = messages.FlattedData.deserializeBinary(buffer)
// // 读数据(避免延迟读取带来的标定误差)
// let _read = null
// _read = _data.getPositionsList()
// _read = _data.getIndicesList()
// _read = _data.getInfoAList()
// _read = _data.getInfoBList()
}Flat buffers
schema
First, you need to write the schema according to the proto3 syntax
table Info {
a: string;
b: float;
}
table Item {
position: [float];
index: int;
info: Info;
}
table Data {
items: [Item];
}
table FlattedData {
positions:[float];
indices:[int];
info_a:[string];
info_b:[float];
}compile to js
./lib/flatbuffers-1.11.0/flatc -o ./src/generated/ --js --binary ./src/data.fbs
Serialization
// 首先引入基础库
const flatbuffers = require('flatbuffers').flatbuffers
// 然后引入编译出的JS模块
const tables = require('src/generated/data_generated.js')
const flatbufferSerialize = () => {
const builder = new flatbuffers.Builder(0)
const items = []
data.items.forEach(item => {
let a = null
// 字符串处理
if (item.info.a) {
a = builder.createString(item.info.a)
}
// 开始操作 info 节点
tables.Info.startInfo(builder)
// 添加数值
item.info.a && tables.Info.addA(builder, a)
tables.Info.addB(builder, item.info.b)
// 完成操作info节点
const fbInfo = tables.Info.endInfo(builder)
// 数组处理
let position = null
if (item.position) {
position = tables.Item.createPositionVector(builder, item.position)
}
// 开始操作item节点
tables.Item.startItem(builder)
// 写入数据
item.position && tables.Item.addPosition(builder, position)
item.index && tables.Item.addIndex(builder, item.index)
tables.Item.addInfo(builder, fbInfo)
// 完成info节点
const fbItem = tables.Item.endItem(builder)
items.push(fbItem)
})
// 数组处理
const pbItems = tables.Data.createItemsVector(builder, items)
// 开始操作data节点
tables.Data.startData(builder)
// 写入数据
tables.Data.addItems(builder, pbItems)
// 完成操作
const fbData = tables.Data.endData(builder)
// 完成所有操作
builder.finish(fbData)
// 输出
// @NOTE 这个buffer是有偏移量的
// return builder.asUint8Array().buffer
return builder.asUint8Array().slice().buffer
// 扁平化方案:
// const builder = new flatbuffers.Builder(0)
// const pbPositions = tables.FlattedData.createPositionsVector(builder, flattedData.positions)
// const pbIndices = tables.FlattedData.createIndicesVector(builder, flattedData.indices)
// const pbInfoB = tables.FlattedData.createInfoBVector(builder, flattedData.info_b)
// const infoAs = []
// for (let i = 0; i < flattedData.info_a.length; i++) {
// const str = flattedData.info_a[i]
// if (str) {
// const a = builder.createString(str)
// infoAs.push(a)
// }
// }
// const pbInfoA = tables.FlattedData.createInfoAVector(builder, infoAs)
// tables.FlattedData.startFlattedData(builder)
// tables.FlattedData.addPositions(builder, pbPositions)
// tables.FlattedData.addIndices(builder, pbIndices)
// tables.FlattedData.addInfoA(builder, pbInfoA)
// tables.FlattedData.addInfoB(builder, pbInfoB)
// const fbData = tables.FlattedData.endFlattedData(builder)
// builder.finish(fbData)
// // 这个buffer是有偏移量的
// return builder.asUint8Array().slice().buffer
// // return builder.asUint8Array().buffer
}deserialize
// 首先引入基础库
const flatbuffers = require('flatbuffers').flatbuffers
// 然后引入编译出的JS模块
const tables = require('src/generated/data_generated.js')
const flatbufferParse = buffer => {
buffer = new Uint8Array(buffer)
buffer = new flatbuffers.ByteBuffer(buffer)
const _data = tables.Data.getRootAsData(buffer)
// 读数据(flatbuffer在解析时并不读取数据,因此这里需要主动读)
let _read = null
const len = _data.itemsLength()
for (let i = 0; i < len; i++) {
const item = _data.items(i)
const info = item.info()
_read = info.a()
_read = info.b()
_read = item.index()
_read = item.positionArray()
}
// 扁平化方案:
// buffer = new Uint8Array(buffer)
// buffer = new flatbuffers.ByteBuffer(buffer)
// const _data = tables.FlattedData.getRootAsFlattedData(buffer)
// // 读数据(flatbuffer是使用get函数延迟读取的,因此这里需要主动读取数据)
// let _read = null
// _read = _data.positionsArray()
// _read = _data.indicesArray()
// _read = _data.infoBArray()
// const len = _data.infoALength()
// for (let i = 0; i < len; i++) {
// _read = _data.infoA(i)
// }
}Flatbuffers have poor parsing performance for strings. When the proportion of strings in the data is high, its overall serialization performance, parsing performance, and volume are not as good as JSON. For pure numerical data, it has obvious advantages over JSON. The general interface design of its state machine is cumbersome for the construction of complex data structures.
Performance
Test Environment: 15' MBP mid 2015, 2.2 GHz Intel Core i7, 16 GB 1600 MHz DDR3, macOS 10.14.3, Chrome 75
Test data: the data in the above example, 200,000, the string uses UUID*2
Test method: run 10 times to get the average value, GZip uses the default configuration gzip ./*
Unit: time ms, volume Mb
-
The proportion of strings in the data, the length of a single string, and the numerical size of the unicode in the string will all affect the test.
-
Since DIMBIN is designed for flattened data, only JSON/protocol/flatbuffers are tested for non-flattened data
Serialization performance
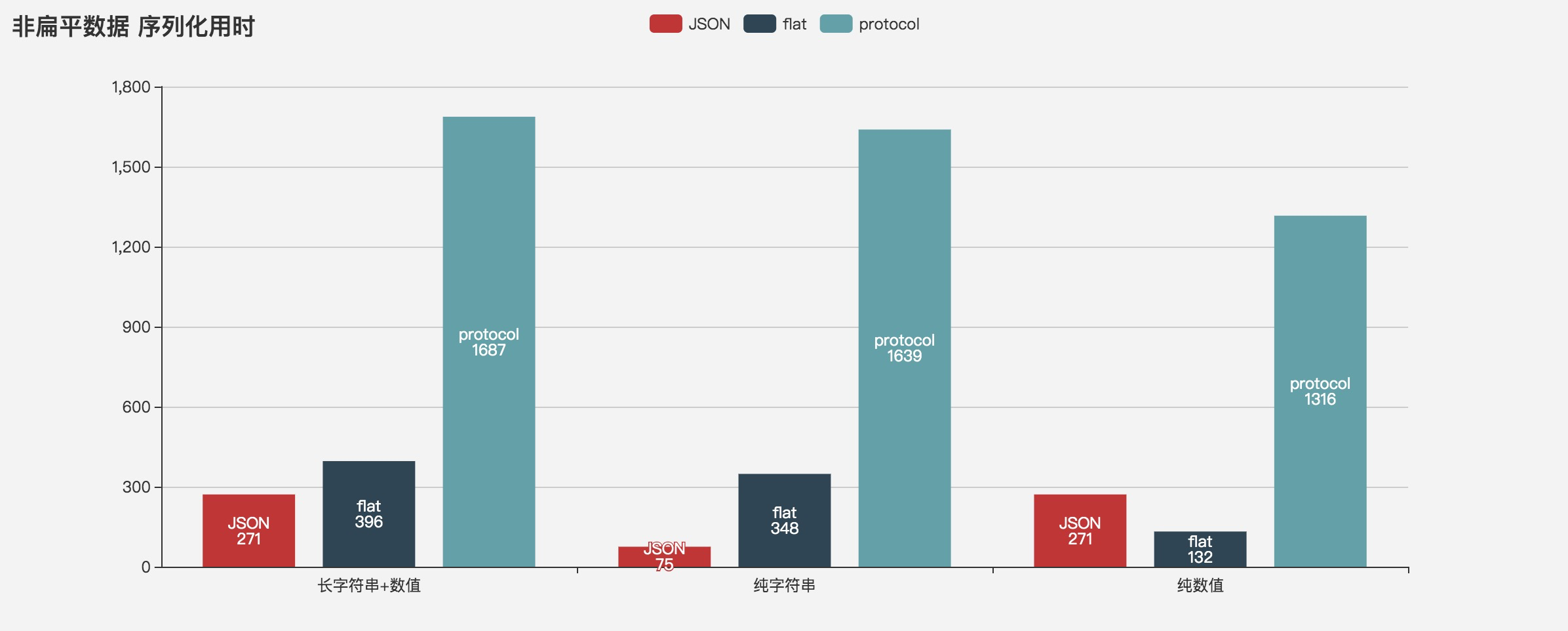
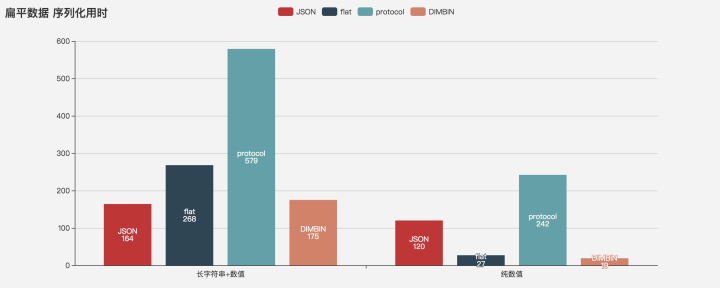
Deserialization performance
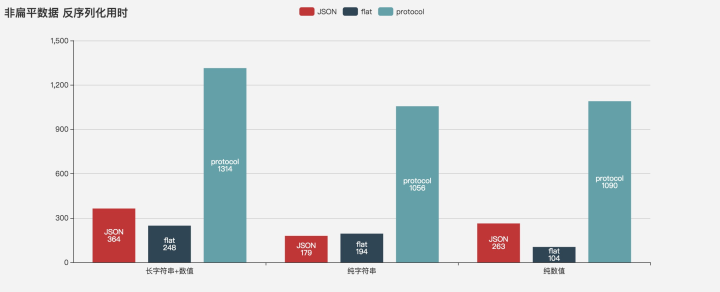
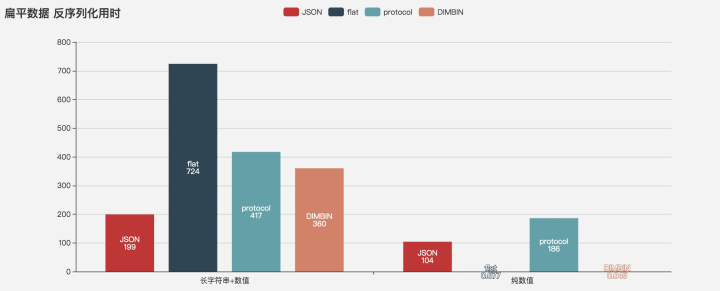
space occupation



Selection suggestion
From the test results, if your scenario has high performance requirements, it is always a wise principle to flatten the data.
-
Small amount of data, fast iteration, including a large number of string data, using JSON, which is convenient and fast;
-
Small amount of data, stable interface, static language dominance, multi-language collaboration, integrated IDL, reliance on gPRC, consider protocol buffers.
-
Large amount of data, stable interface, dominant static language, integrated IDL, data cannot be flattened, consider flat buffers.
-
Large amount of data, fast iteration, high performance requirements, data can be flattened, do not want to use heavyweight tools or modify the project structure, consider DIMBIN.