Evolution of Distributed Scheduling
The Internet is changing with each passing day, and business is becoming more and more complex. There is no doubt that scheduling (timed tasks) has become an indispensable part of the Internet business system. Business is a powerful driving force for technological change. High concurrency, high throughput, and high availability are also driving technological changes. They also pursue higher scheduling, and distributed scheduling applications are born. So what exactly is distributed scheduling? As follows, along with my "chestnuts", let's evolve together.
business background
Asynchronous real-name authentication is performed on user data, and users have new registrations every day. With the growth of business, the daily registrations are increasing. The user table is user, the initial state of authentication is (0), the authentication is successful (1), and the authentication is unsuccessful (2). In order to respond quickly to the business, programmer Xiao Huang wrote a timed task in java. It was found that the data of the previous day had not been processed by the next day. The boss of programmer Xiao Huang found him and asked for optimization. Xiao Huang said that it would be solved by modifying the scheduling frequency. Indeed, after the scheduling frequency was modified, it did meet the current needs. After running like this for another three months, the problem reappeared. Xiao Huang found that the performance of the application server and database did not reach the bottleneck, so he considered using a thread pool. One thread pool was responsible for loading data, and a group of threads were processing data. After this optimization, the system ran online for a while. Suddenly one day, the company leader found Xiao Huang and said that the system does not currently provide services, the data backlog is serious, and the company is about to go public, and the amount of data will increase sharply. Xiao Wang quickly found out that it was because the service was down. Xiao Huang quickly solved the problem, but there were quite a few problems worthy of Xiao Huang's deep thinking. Xiao Huang tried to introduce a distributed scheduling framework to meet future business surges and services. Horizontal expansion, high availability, etc.
application
-
single vision
An application instance is deployed, in which there is a program that reads data from the user table regularly, calls the Ministry of Public Security interface for real-name authentication for each user data in the user table, saves the information after authentication, and finally saves the status in the user The field is updated from the initial state (0) to authentication success (1), and if failed to (2)
- Multi-instance version
Two application instances (A instance and B instance) are deployed, and data is read from the user table at regular intervals, and subsequent services remain unchanged. When reading data, it is necessary to ensure that the data is not read repeatedly. We have done a modulo method here, such as dividing the id by 2. If the data with a remainder of 0 is obtained and executed by the A instance, if the data with a remainder of 1 is obtained and executed Acquired and executed by the B instance.
Question 1.
What should I do if I want three instances or four or five instances to process data? In fact, it is also very simple to modify the modulo method of the data, and then each application goes online. This also leads to different configuration of the application.
2.
If one of the instances hangs, who will handle that part of the data? If the above stand-alone version basically cancels the business corresponding to this scheduling? unless restarted, or redeployed
- What does distributed scheduling do?
For the above scenario, the distributed scheduling framework needs to allocate data to multiple instances for processing, and the data is not repeatedly processed. The tasks can be reassigned after the system is down, and the application can be scaled horizontally when the data surges. With these functions, the above scenarios can be well satisfied.
DST overview
DST (Distributed scheduling task) is a lightweight distributed scheduling framework based on the database as the registry. It is written in Java and has almost no dependencies on third-party jars. The core jar does not exceed 100KB. The framework design aims to provide a high-quality distributed scheduling framework that integrates functionality, reliability, ease of use, efficiency, maintainability, and portability. All source codes are now open, and various integration methods such as springboot, spring+mybatis+springmvc, and java-application are provided. In the future, various client cores and alarm mechanisms such as python will be implemented.
DST is divided into two parts, dst-client and dst-console, which are not directly related. dst-client is the core of scheduling. The application can schedule and host on dst-console by integrating dst-client and adding single configuration. dst-console provides functions such as application and scheduling task management, statistical reports, etc. The downtime of dst-console does not affect the normal operation of all scheduling.
DST features
- Application instance automatic registration
DST application instances register themselves and keep heartbeats to automatically detect instance survival. The registration and management center is single and easy to maintain.
- Application instance automatic selection (HA)
The DST application instance will automatically select the master (Master) during the startup process, and the master is responsible for task sharding to ensure the consistency of the probability that the instance obtains the task.
- Automatic sharding of DST instances
DST has a Master instance responsible for sharding all activated scheduling tasks according to the application instance, and the sharding rules can be configured by itself.
- Simple scheduling
You only need to implement the defined interface to complete the scheduling and efficient scheduling of custom methods.
- Centralized management of scheduling
The management platform can manage all tasks, add and start and stop workbenches for scheduling tasks, automatically bind servers as needed, dynamically modify the scheduling time configuration without stopping, dynamically configure processing threads, and dynamically modify the amount of scheduling data.
- Scheduling rule optimization configuration
Scheduling rules support standard Cron expressions, and can also specify simple time intervals (for example: run once every 500s, only need to configure 500).
- Dynamic expansion
Machines can be added without interruption according to the business capacity, and the scheduling shards can be obtained by themselves, and can be added to the scheduling at will.
- Dynamic shrink
In the case of some services downtime or shrinking, the application will re-select the master and recalculate the shards, which will not hinder the data processing.
- Scheduling Statistics
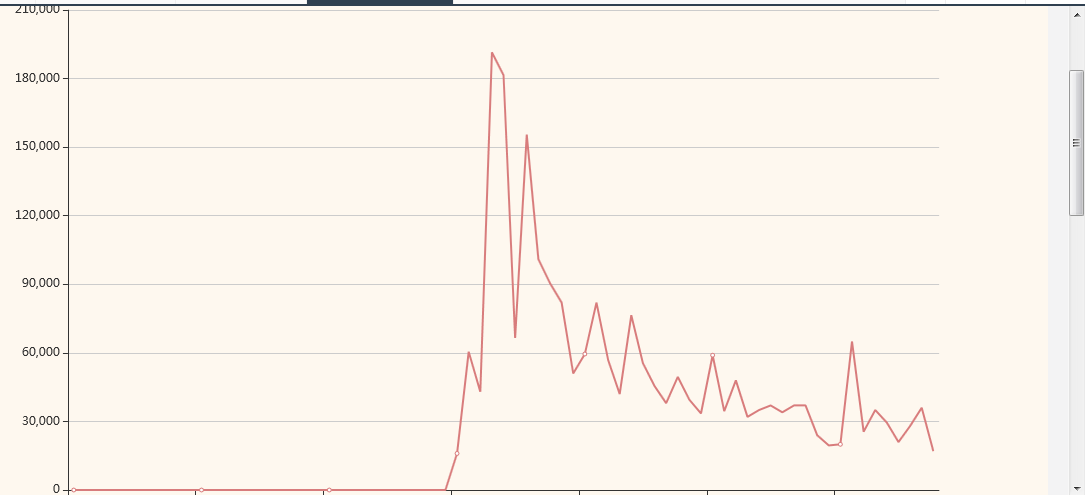
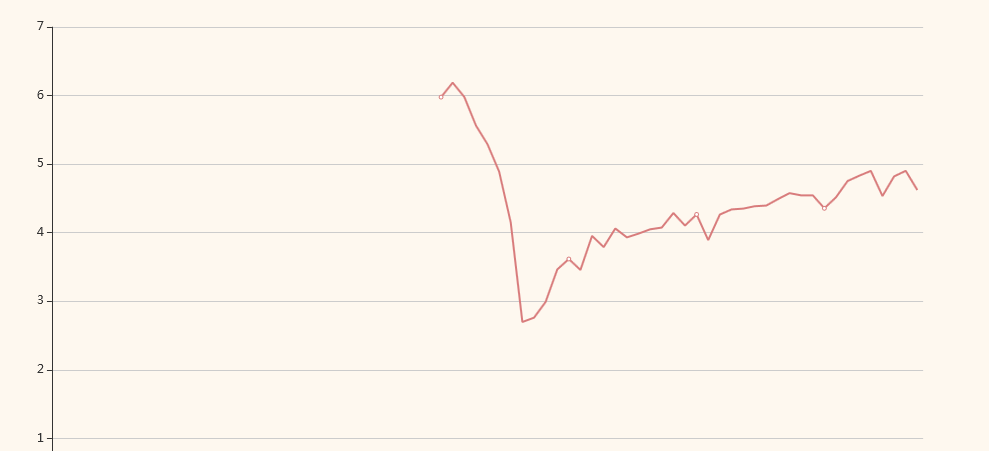
View the scheduling trend graph and scheduling details online, and view the processing results and time consumption of each thread.
- Superior architecture
The system architecture is superior, which can save server resources. Each DST instance has unified task refresh, statistics, and cleanup threads, and there is no additional resource consumption. The application is built based on spring-boot+maven.
Architecture design
overall design
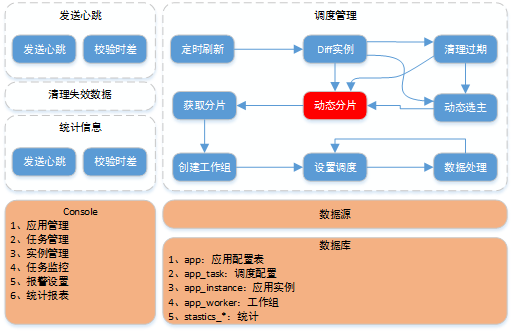
console
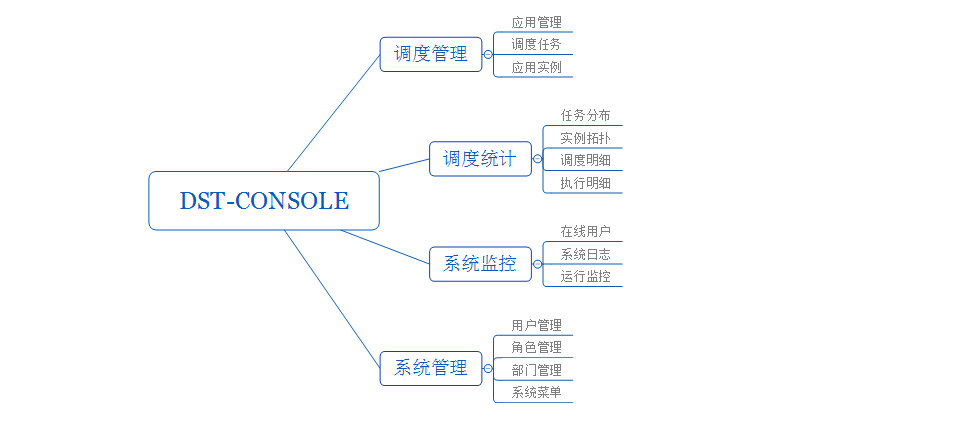
Quick start
1. Environmental preparation
JDK:1.8+
Mysql:5+
Maven:3+
git;2+
2. Download
git clone https://gitee.com/xiaoleiziemail/xlz-dst.git
There are two parts dst and dst-demo after the source code is downloaded. Inside dst is the core code of dst, and dst-demo is
the maven compilation of dst by various access methods
3. Application integration dst-client
Currently, projects such as spring+mybatis are used as examples, and maven is used for construction. JDK requires 1.7+. Currently, dst-ssm in dst-demo is used as an example.
3.1 Add dependencies, the current stable version is 1.0.1
<dependency>
<groupId>com.xlz</groupId>
<artifactId>dst-client</artifactId>
<version>1.0.1</version>
</dependency>
The framework is in The dependency problem was considered at the beginning of the design, so try not to use third-party jars, but some jars are still used. If there is a jar conflict, please eliminate it by yourself. The best configuration is as follows:
<dependency>
<groupId>com. xlz</groupId>
<artifactId>dst-client</artifactId>
<version>1.0.1</version>
<exclusions>
<exclusion>
<groupId>ch.qos.logback</groupId>
<
<exclusion>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
</exclusion>
<exclusion>
<groupId>org.springframework</groupId>
<artifactId>spring-beans</artifactId>
</exclusion>
<exclusion>
<groupId>org.springframework</groupId>
<artifactId>spring-core</artifactId>
</exclusion>
<exclusion>
<groupId>org.springframework</groupId>
<artifactId>spring-context</artifactId>
</exclusion>
<exclusion>
<groupId>commons-logging</groupId>
<artifactId>commons-logging</artifactId>
</exclusion>
</exclusions>
</dependency>
3.2、应用程序配置方面需要配置调度中心的数据库数据源:
<bean id="dataSource" class="org.apache.commons.dbcp.BasicDataSource">
<property name="driverClassName" value="${jdbc.driverClassName.db2}" />
<property name="url" value="${jdbc.url.db2}" />
<property name="username" value="${jdbc.username.db2}" />
<property name="password" value="${jdbc.password.db2}" />
<property name="maxActive" value="${jdbc.maxActive.db2}" />
<property name="initialSize" value="${jdbc.initialSize.db2}" />
<property name="maxWait" value="${jdbc.maxWait.db2}" />
<property name="maxIdle" value="${jdbc.maxIdle.db2}" />
<property name="testOnBorrow" value="${jdbc.testOnBorrow.db2}" />
<property name="validationQuery" value="select 1 from dual" />
<property name="defaultAutoCommit" value="false" ></property>
</bean>
3.3. Introduce distributed scheduling framework
<bean id="dstManagerBeanFactory" class="com.xlz.manager.DstManagerBeanFactory">
<property name="dataSource" ref="dataSource"></ property>
<property name="appNo" value="ssm"></property> <!--application number-->
</bean>
3.4. To develop scheduling tasks, you need to inherit the AbstractWorker abstract class, which is mainly composed of select methods and execute
import java.util.Arrays;
import java.util.List;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.annotation.Autowired;
import com.test.bo.MyTestDO;
import com.test.service.MyTestService;
import com.xlz.domain.ShardItem;
import com.xlz.worker.AbstractWorker;
public class TestScheduleBean1 extends AbstractWorker<MyTestDO>{
protected final Logger LOG = LoggerFactory.getLogger(getClass());
@Autowired
private MyTestService myTestService;
@Override
public List<MyTestDO> select() {
ShardItem[] items = getShardItems();
StringBuffer item = new StringBuffer();
for(int i =0 ;i < items.length;i++){
if(i > 0)
item.append(",");
item.append(items[i].getItemId());
}
System.out.println("当前任务:"+getAppTask().getId()+"==========当前分片:"+item.toString());
//Get data and add it to the queue of pending documents
String tableName = getAppTask().getTaskParam();
List<MyTestDO> list = myTestService.getMyTestList
(getShardItemCount(),item.toString(),
getAppTask().getFetchDataNumber(),tableName);
/*if("my_test_1". equals(tableName)){
LOG.error("The number of records loaded this time is: {}, the total number of shards of the current task is: {}, the shards obtained by the current scheduling are after splicing: {}-- - The original is {}", list.size(), getShardItemCount(), item.toString(), getShardItems());
}*/
return list;
}
@Override
protected void execute(MyTestDO obj) throws Exception{
String tableName = getAppTask().getTaskParam();
myTestService.update(obj,tableName,getRegisterWorker());
}
public void test(){
LOG.info("============我是自定义方法=============="+Arrays.toString(getShardItems()));
}
}
At this point, the application configuration is completed, but the configuration of the console is not completed at this time, and the scheduling cannot be executed.
4, dst-console installation and use
4.1. Deploy
in mysql to initialize two databases, dst and dst_console. The script is in the dst/sql directory.
The current dst-console is developed by springboot, jdk1.8+. After compiling, you can directly command the command line:
java -jar dst-console.jar
Linux background startup can execute the command:
nohup java -jar dst-console.jar &
can also be packaged into war and thrown into tomact for deployment, requiring tomcat1.8+
4.2. In the application configuration
initialization data, we can see the configuration application data, currently The ssm test application we use
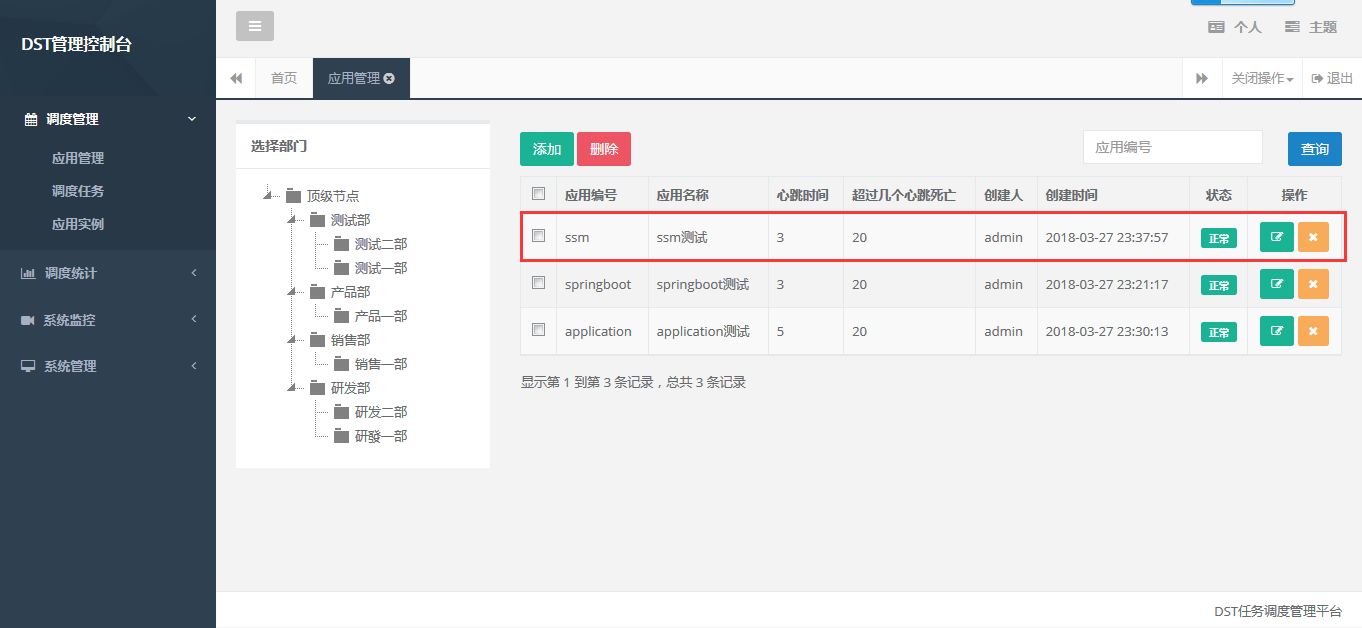
4.3, task configuration
In the initialization data, we see the configured task data, currently we are using
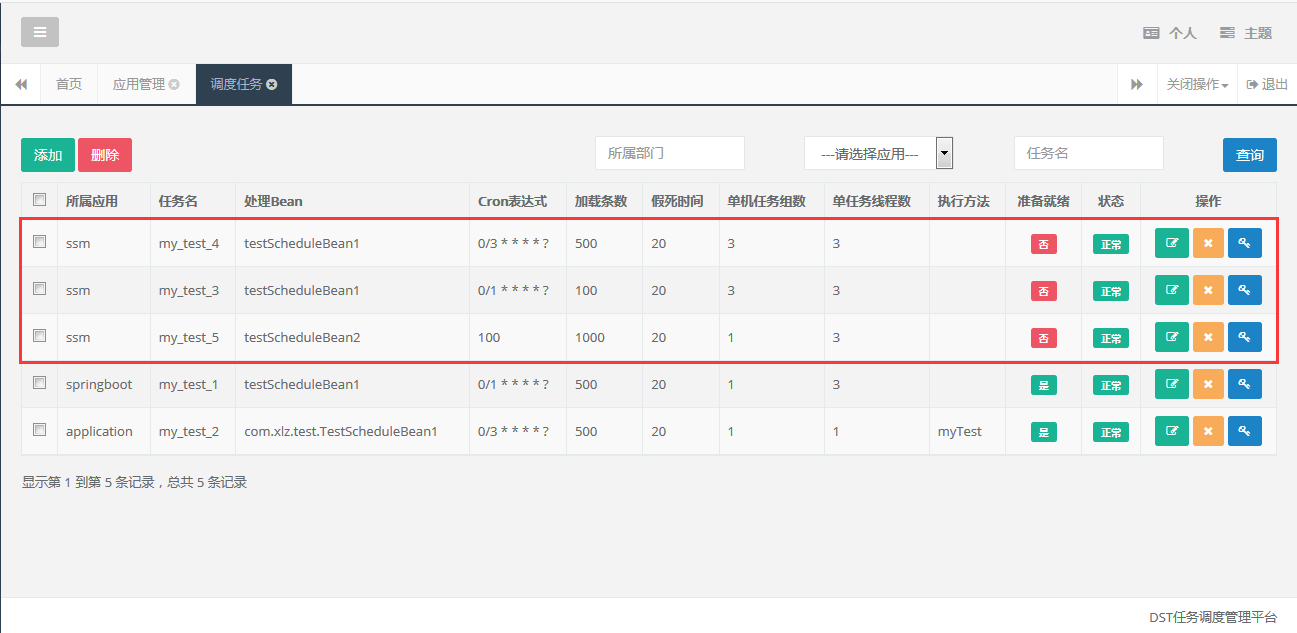
So far, the system can be scheduled according to the specified scheduling time.
4.4 Rich report functions are also provided in dst-console
Application task distribution map:
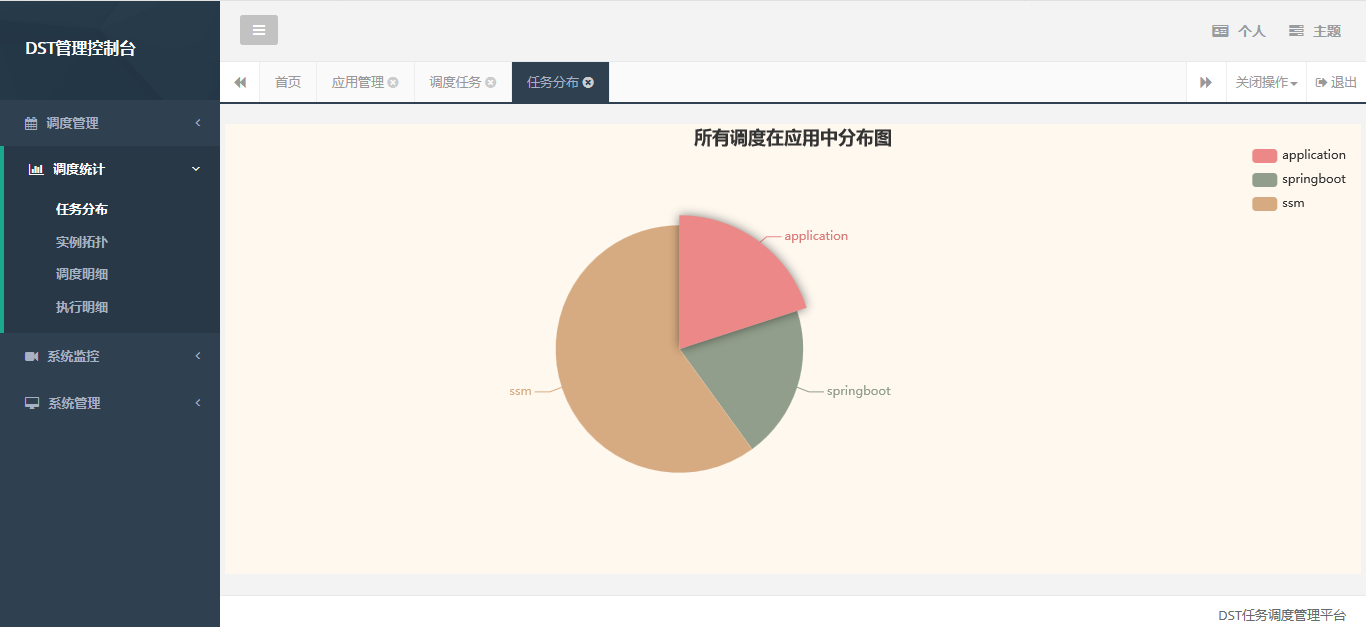
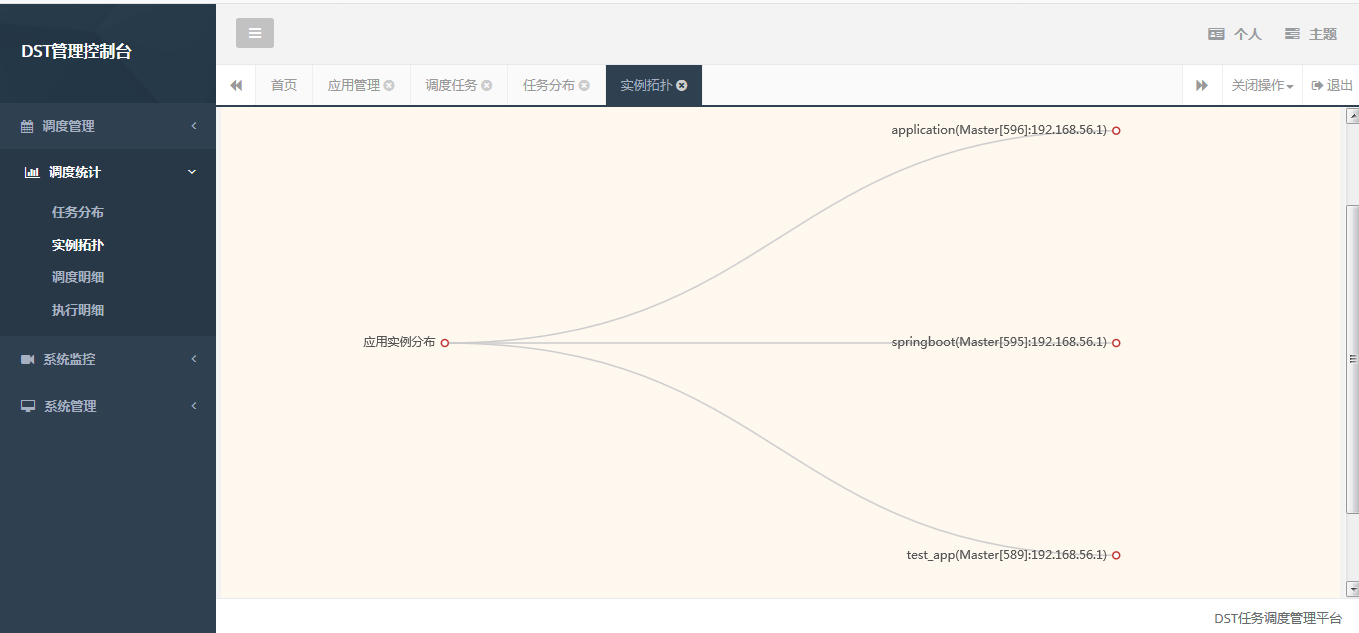
Example distribution map:
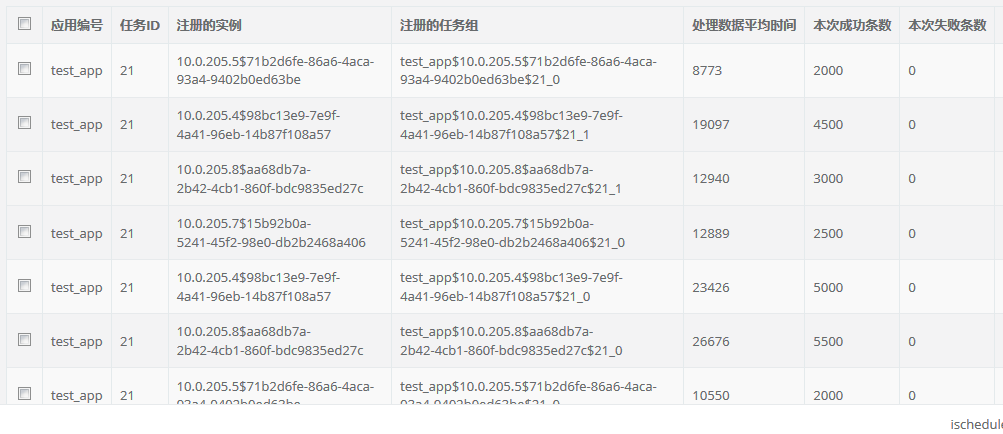
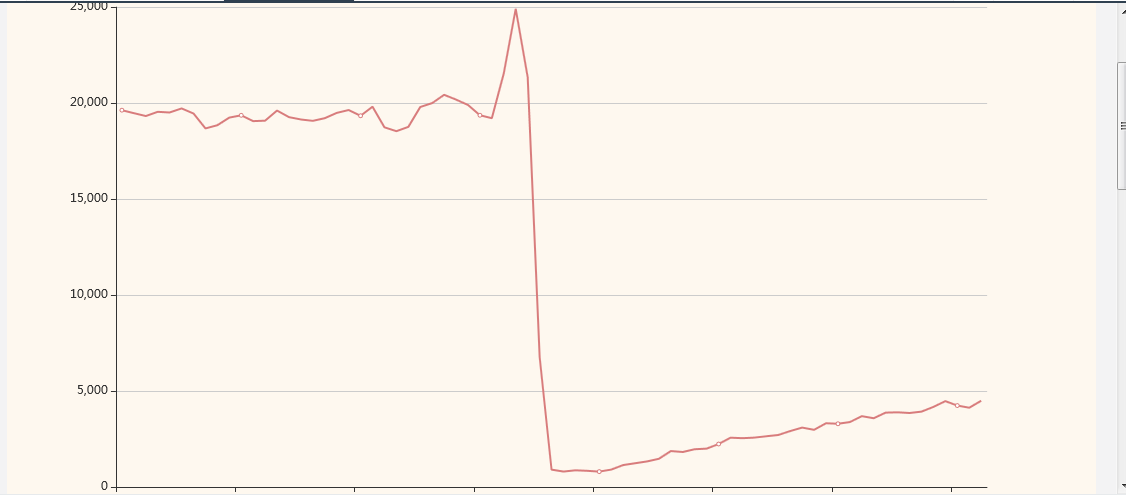
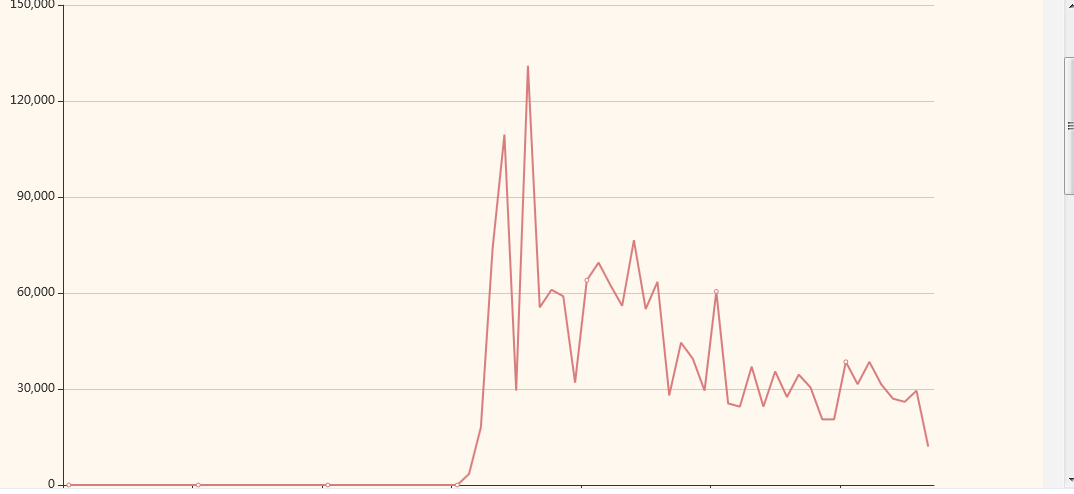
Schedule Details:
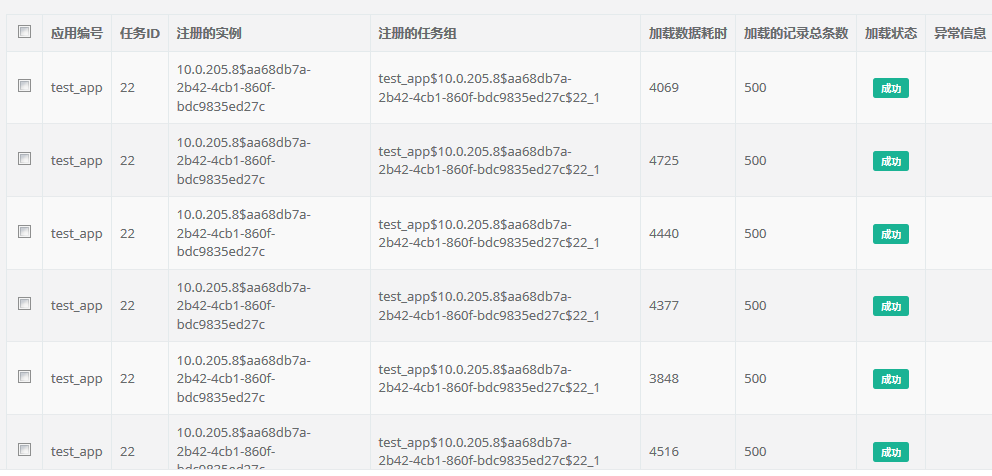
Processing details: