Python crawler web content acquisition:
-
One: A simple way to send a request to the server:
# -- coding:utf-8 -- import urllib2 Send a request to the specified url and return a file-like object in response response = urllib2.urlopen("http://www.baidu.com") The object returned by the server supports the methods of the python file object read() method: read the entire class content of the file and return a string html = response.read() print htmlBut such methods are often easy to be discovered by anti-reptiles, so we need further camouflage.
-
The first step of anti-reptile:
First, we need to understand what the browser does when it sends a request to the server: here we can use the Fiddler package capture tool to download, install and configure Fiddler (specific configuration method), when our browser sends a request to the server ( For example, if you visit http://www.baidu.com in the browser ), the following Header request information can be obtained from the corresponding Baidu link file in the file captured by the Fiddler packet capture tool.
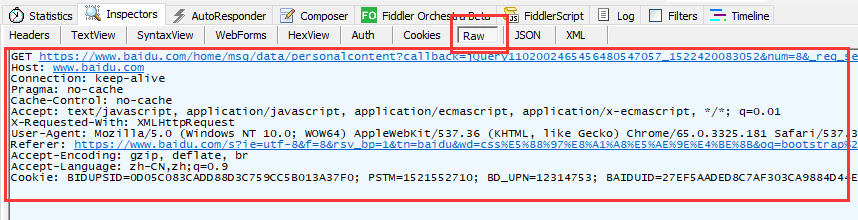
Fiddler packet capture tool Header request information
# Request method (GET / POST /...) GET https://www.baidu.com?&t=1520930345744&sid=1455_13549_21088_20928 HTTP/1.1 # Specify the Internet host and port number of the requested resource Host: www.baidu.com # Link method ( keep-alive / close /... ) Connection: keep-alive # Media types accepted by the browser Accept: text/plain, /; q=0.01 X-Requested-With: XMLHttpRequest # User-Agent tells the HTTP server the name and version of the operating system and browser used by the client User-Agent: Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.186 Safari/537.36 Referer: https://www.baidu.com/ # The browser declares the encoding method it receives, usually specifying the compression method Accept-Encoding: gzip, deflate, br Accept-Language: zh-CN,zh;q=0.9 #local cookie information Cookie: BAIDUID=955895CE3A39E426AF6E5CF53F2B:FG=1; BIDUPSID=955895CE3A39E426AF53F2B;
After getting the Header information requested by the browser, we can simulate the browser to access the server as follows:
-
Simulate a get request:
# -*- coding:utf-8 -*- from urllib import request,parse url = "http://www.baidu.com/s" kwd = input("Please enter the keyword to query: ") wd = {"wd":kwd} #Convert a dictionary type data to a string type (url: "wd=875398%jsjdj%") wd = parse.urlencode(wd) fill_url = url + "?" + wd header = { "User-Agent":"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.186 Safari/537.36" } #Construct a request object through the urllib2.Resquest() method req = request.Request(fill_url,headers = header) #Send a request to the specified url and return the response file-like object response = request.urlopen(req) #The object returned by the server supports the method of the python file object #read() method: read the entire class content of the file and return a string html = response.read() print(html) -
Simulate post request\Using local cookies to obtain content that can only be obtained after logging in:
#!/usr/bin/python #-*- coding:utf-8 -*- from urllib import request,parse #import json url = "https://mail.qq.com/cgi-bin/frame_html?t=frame_html&sid=3-L3dxbAFqMTDGY8&url=/cgi-bin/mail_list?folderid=8%26folderkey=8%26page=0%26t=mail_list_group%26ver=236935.0%26cachemod=maillist%26cacheage=7200%26r=" header = { "Host": "mail.qq.com", "Connection": "keep-alive", "User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.186 Safari/537.36", "Accept": "image/webp,image/apng,image/*,*/*;q=0.8", "Accept-Language": "zh-CN,zh;q=0.9", "Cookie": "RK=k0HCcQgeOg; pgv_pvi=4384783360; tvfe_boss_uuid=e72e765a79d2f90f; 。。。*", } req = request.Request(url,headers = header) print(request.urlopen(req).read().decode('utf-8')) -
Get the json data loaded by Ajax:
#!/usr/bin/python #-*- coding:utf-8 -*- from urllib import request,parse import json url = "https://movie.douban.com/j/chart/top_list?type=11&interval_id=100%3A90&action" header = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.186 Safari/537.36"} formData = { "start":"0", "limit":"5" } data = parse.urlencode(formData).encode('UTF-8') req = request.Request(url,data = data,headers = header) print(request.urlopen(req).read().decode('UTF-8'))