Cache is an important component in distributed systems, which mainly solves the performance problem of hot data access in high concurrency and big data scenarios. Provides fast access to high-performance data.
1. Cache overview
Cache is an important component in distributed systems, which mainly solves the performance problem of hot data access in high concurrency and big data scenarios. Provides fast access to high-performance data.
1.1 The principle of caching
(1) Storage (device) that writes/reads data faster;
(2) Cache data to the location closest to the application;
(3) Cache the data to the location closest to the user.
1.2 Cache classification
In distributed systems, the application of caching is very extensive. From the perspective of deployment, there are the following aspects of caching applications.
(1) CDN cache;
(2) Reverse proxy cache;
(3) Distributed Cache;
(4) Local application cache;
1.3 Cache media
Commonly used middleware: Varnish, Ngnix, Squid, Memcache, Redis, Ehcache, etc.;
Cached content: files, data, objects;
Cached media: CPU, memory (local, distributed), disk (local, distributed)
1.3 Cache Design
The cache design needs to address the following issues:
(1) What is cached?
Which data needs to be cached: 1. Hot data; 2. Static resources;
(2) The location of the cache?
CDN, reverse proxy, distributed cache server, native (memory, hard disk)
(3) How to cache the problem?
- Expiration Policy
1. Fixed time: For example, the specified cache time is 30 minutes;
2. Relative time: such as data that has not been accessed in the last 10 minutes;
- synchronization mechanism
- write in realtime; (push)
- Asynchronous refresh; (push and pull)
2. CDN cache
CDN mainly solves the problem of caching data to the location closest to the user, generally caching static resource files (pages, scripts, pictures, videos, files, etc.). The domestic network is extremely complex, and network access across carriers will be very slow. In order to solve the problem of cross-operator or user access in various places, CDN applications can be deployed in important cities. Enable users to obtain the desired content nearby, reduce network congestion, and improve user access response speed and hit rate.
2.1 CND principle
The basic principle of CDN is to widely use various cache servers, and distribute these cache servers to regions or networks where user access is relatively concentrated. When users visit a website, the global load technology is used to direct the user's access to the nearest working normal cache. On the server, the cache server directly responds to user requests.
(1) Before CDN application is deployed

Network request path:
Request: local network (local area network) - "operator network -" application server room
Response: application server room - "operator network -" local network (local area network)
Without considering the complex network, it takes 3 nodes and 6 steps to complete a user access operation from request to response.
(2) After deploying the CDN application
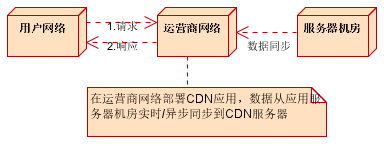
network path:
Request: local network (local area network) - "operator network
Response: Carrier Network - "Native Network (LAN)
Without considering the complex network, it takes 2 nodes and 2 steps to complete a user access operation from request to response.
Compared with not deploying CDN service, the access of 1 node and 4 steps is reduced. Greatly improve the response speed of the system.
2.2 Advantages and disadvantages of CDN
(1) Advantages (from Baidu Encyclopedia)
1. Local Cache acceleration: Improve access speed, especially for sites with a large number of pictures and static pages;
2. Mirroring service: eliminates the impact of the bottleneck of interconnection between different operators, realizes network acceleration across operators, and ensures that users in different networks can get good access quality;
3. Remote acceleration: The remote access user intelligently selects the Cache server automatically according to the DNS load balancing technology, selects the fastest Cache server, and accelerates the speed of remote access;
4. Bandwidth optimization: automatically generate a remote Mirror (mirror) cache server of the server, read data from the cache server when remote users access, reduce the bandwidth of remote access, share network traffic, and reduce the load of the original site WEB server.
5. Cluster anti-attack: The widely distributed CDN nodes and the intelligent redundancy mechanism between nodes can effectively prevent hacker intrusion and reduce the impact of various DDoS attacks on the website, while ensuring better service quality.
(2) Disadvantages
1. Dynamic resource caching requires attention to real-time performance;
Solution: mainly cache static resources, establish multi-level cache or quasi-real-time synchronization for dynamic resources;
2. How to ensure data consistency and real-time needs to be weighed;
solve:
- Set cache invalidation time (1 hour, eventual consistency);
- data version number;
2.3 CND Architecture Reference
Excerpted from "Cloud Universe Video CDN System"
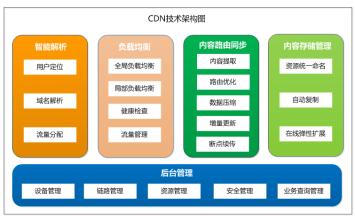
2.4 CND technology practice
At present, small and medium-sized Internet companies generally rent third-party CDN services based on comprehensive cost considerations, while large Internet companies use self-built or third-party integration. For example, Taobao just started to use third-party. When the traffic is very large, the third-party company cannot support its CDN traffic. Taobao finally adopts the method of self-built CDN.
Taobao CDN, as shown below (from the Internet):
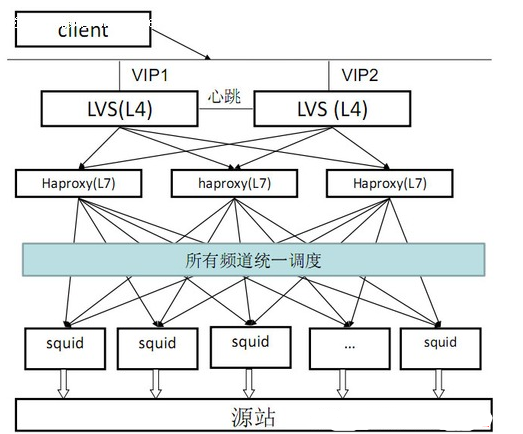
3. Reverse proxy cache
Reverse proxy refers to the deployment of a proxy server in the website server room to achieve load balancing, data caching, security control and other functions.
3.1 Cache principle
The reverse proxy is located in the application server room and handles all requests to the web server. If the page requested by the user is buffered on the proxy server, the proxy server sends the buffered content directly to the user. If there is no buffering, first send a request to the WEB server, retrieve the data, cache it locally, and then send it to the user. By reducing the number of requests to the WEB server, the load on the WEB server is reduced.
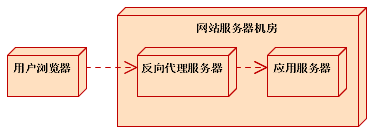
The reverse proxy generally caches static resources, and forwards dynamic resources to the application server for processing. Commonly used caching application servers are Varnish, Ngnix, and Squid.
3.2 Squid example
Squid reverse proxy generally only caches static resources, dynamic programs do not cache by default. Cache static pages based on HTTP headers returned from the web server. There are four most important HTTP header tags:
Last-Modified: Tell the reverse proxy when the page was modified
Expires: tells the reverse proxy when pages should be removed from the buffer
Cache-Control: tells the reverse proxy if the page should be cached
Pragma: used to contain implementation-specific instructions, the most commonly used is Pragma:no-cache
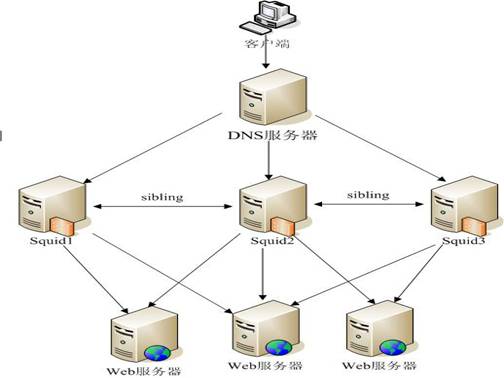
Squid reverse proxy to accelerate website instance
(1) Through the DNS polling technology, the client's request is distributed to one of the Squid reverse proxy servers for processing;
(2) If the Squid caches the user's requested resource, it will directly return the requested resource to the user;
(3) Otherwise, this Squid will send the uncached request to the neighbor Squid and the background WEB server for processing according to the configured rules;
(4) This not only reduces the load of the background WEB server, but also improves the performance and security of the entire website.
3.2 Proxy cache comparison
Commonly used proxy caches include Varnish, Squid, and Ngnix. A simple comparison is as follows:
(1) Varnish and squid are professional cache services, and nginx needs third-party module support;
(2) Varnish uses an in-memory cache, which avoids frequently exchanging files in memory and disk, and has higher performance than Squid;
(3) Varnish is a memory cache, so it supports small files such as css, js, and small pictures. The back-end persistent cache can use Squid or ATS;
(4) Squid has complete and large functions, and is suitable for various static file caching. Generally, an HAProxy or nginx will be hung on the front end for load balancing to run multiple instances;
(5) Nginx uses the third-party module ncache to do the buffering, and its performance basically reaches varnish. It is generally used as a reverse proxy, which can realize simple caching.
Here I recommend an architecture learning exchange group to everyone. Communication and learning group number: 575745314 It will share some videos recorded by senior architects: Spring, MyBatis, Netty source code analysis, high concurrency, high performance, distributed, principles of microservice architecture, JVM performance optimization, distributed architecture, etc. These become the necessary knowledge system for architects. You can also receive free learning resources, which are currently benefiting a lot
4. Distributed cache
CDN, reverse proxy cache, mainly solves the cache of static files or resources requested by users. The data source is generally static files or dynamically generated files (with cache header identification).
Distributed cache mainly refers to the cache that cache users frequently access data, and the data source is the database. Generally, it plays a role in hot data access and reducing database pressure.
At present, distributed cache design is an essential architectural element in large-scale website architecture. Commonly used middleware are Memcache, Redis.
4.1Memcache
Memcache is a high-performance, distributed memory object caching system. By maintaining a unified huge hash table in memory, it can be used to store data in various formats, including images, videos, files, and database retrieval results. Simply put, the data is called into the memory, and then read from the memory, thereby greatly improving the reading speed.
Memcache features:
(1) Using physical memory as a cache area, it can run independently on the server. Each process has a maximum of 2G. If you want to cache more data, you can open more memcache processes (different ports) or use distributed memcache for caching to cache data on different physical machines or virtual machines.
(2) The key-value method is used to store data, which is a single-index structured data organization, which can make the query time complexity of data items O(1).
(3) The protocol is simple: the protocol based on the text line can directly access data on the memcached server through telnet, which is simple and convenient for various caches to refer to this protocol;
(4) High-performance communication based on libevent: Libevent is a set of program libraries developed by C. It encapsulates event processing functions such as kqueue of BSD system and epoll of Linux system into an interface, which improves performance compared with traditional select. .
(5) Built-in memory management method: All data is stored in memory, and data access is faster than hard disk. When the memory is full, the unused cache is automatically deleted through the LRU algorithm, but the data disaster recovery problem is not considered, and the service is restarted , all data will be lost.
(6) Distributed: each memcached server does not communicate with each other, accesses data independently, and does not share any information. The server does not have distributed capabilities, and distributed deployment depends on the memcache client.
(7) Cache strategy: Memcached's cache strategy is the LRU (least recently used) expiration strategy. When storing a data item in memcached, you can specify its expiration time in the cache, which is permanent by default. When the memcached server runs out of allocated memory, the stale data is replaced first, followed by the most recently unused data. In LRU, memcached uses a Lazy Expiration strategy. It does not monitor whether the stored key/vlue pair expires, but checks the timestamp of the record when obtaining the key value, and checks whether the key/value pair space expires. This reduces the load on the server.
4.1.1 How Memcache works
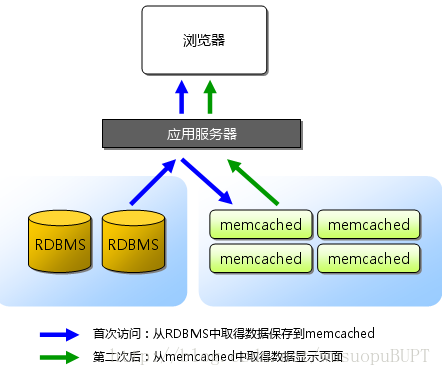
The workflow of MemCache is as follows:
(1) First check whether the client's request data is in memcached, if so, return the request data directly, and no longer perform any operations on the database;
(2) If the requested data is not in memcached, check the database, return the data obtained from the database to the client, and cache a copy of the data in memcached (the memcached client is not responsible, and requires program implementation);
(3) Each time the database is updated, the data in memcached is updated to ensure consistency;
(4) When the memory space allocated to memcached is used up, the LRU (Least Recently Used, least recently used) strategy plus the expiration expiration strategy will be used. The expired data will be replaced first, and then the recently unused data will be replaced.
4.1.2Memcache cluster
Although memcached is called a "distributed" cache server, there is no "distributed" function on the server side. Each server is a completely independent and isolated service. The distribution of memcached is implemented by client programs.
When storing/retrieving the key value from the memcached cluster, the memcached client program calculates which server to store in according to a certain algorithm, and then stores the key value in this server.
Accessing data is divided into two steps. The first step is to select a server, and the second step is to access data.

Distributed algorithm (Consistent Hashing):
There are two algorithms for selecting the server, one is to calculate the distribution based on the remainder, and the other is to calculate the distribution based on the hash algorithm.
Remainder algorithm:
first obtain the integer hash value of the key, then divide it by the number of servers, and determine the access server according to the remainder.
Advantages: simple and efficient calculation;
Disadvantage: Almost all caches are invalidated when memcached servers are increased or decreased.
Hash algorithm: (Consistent Hash)
First calculate the hash value of the memcached server, and distribute it on the 32-th power circle from 0 to 2, and then use the same method to calculate the hash value of the key to store the data and map it Go to the circle, and finally start the search clockwise from the position where the data is mapped, and save the data to the first server found. If it exceeds the 32nd power of 2 and still cannot find the server, save the data to the first server. on a memcached server.
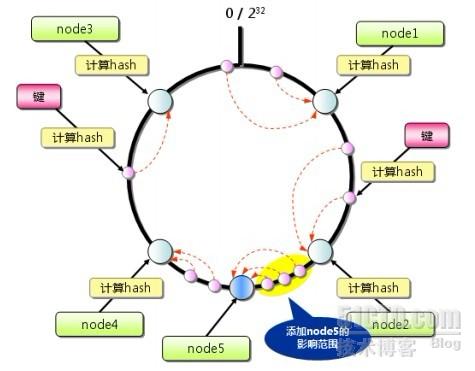
If a memcached server is added, only keys on the first server in the counter-clockwise direction of the increased server on the circle will be affected.
Consistent Hash Algorithm: Solve the problem that the number of hits of nodes increased by the remainder algorithm is greatly reduced. In theory, inserting a physical node will affect the hit of node data with the number of virtual nodes/2 on average.
4.2Redis
Redis is an open source (BSD licensed), in-memory, multi-data structure storage system. Can be used as database, cache and message middleware. Supports multiple types of data structures such as strings, hashes, lists, sets, sorted sets and range queries, bitmaps, hyperloglogs and geospatial ) index radius query.
Built-in replication (replication), LUA scripting (Lua scripting), LRU-driven events (LRU eviction), transactions (transactions) and different levels of disk persistence (persistence), and through Redis sentinel (Sentinel) and automatic partition (Cluster) Provide high availability (high availability).
4.2.1 Common data types of Redis
1、String
Common commands: set, get, decr, incr, mget.
Application scenario: String is the most commonly used data type, similar to the key value storage method of Memcache.
Implementation method: String stored in redis is a string by default, which is referenced by redisObject. When incr, decr and other operations are encountered, it will be converted into a numeric type for calculation. At this time, the encoding field of redisObject is int.
2、Hash
Common commands: hget, hset, hgetall.
Application scenario: Take storing a user information object data, for example:

Method to realize:
The Value corresponding to Redis Hash is actually a HashMap internally, and there are actually two different implementations here.
(1) When the number of Hash members is relatively small, Redis will use a one-dimensional array-like method for compact storage in order to save memory, instead of using the real HashMap structure, and the encoding of the corresponding value redisObject is zipmap;
(2) When the number of members increases, it will be automatically converted into a real HashMap, and the encoding is ht.
3、List
Common commands: lpush,rpush,lpop,rpop,lrange.
Application scenarios:
There are many application scenarios of Redis list, and it is also one of the most important data structures of Redis. For example, the follow list of twitter, the list of fans, etc. can be implemented by the list structure of Redis.
Method to realize:
The implementation of Redis list is a doubly linked list, which can support reverse search and traversal, which is convenient for operation. However, it brings some additional memory overhead. Many internal implementations of Redis, including send buffer queues, also use this data structure.
4、Set
Common commands: sadd, spop, smembers, sunion.
Application scenarios:
The function provided by Redis set to the outside world is similar to that of list, which is a list function. The special feature is that set can automatically arrange weights. When you need to store a list of data and do not want duplicate data, set is a good choice. , and set provides an important interface for judging whether a member is in a set collection, which is also not provided by list.
Method to realize:
The internal implementation of set is a HashMap whose value is always null. In fact, it is used to quickly arrange weights by calculating the hash. This is also the reason why set can judge whether a member is in the set.
5、Sorted set
Common commands: zadd, zrange, zrem, zcard;
scenes to be used:
The usage scenario of Redis sorted set is similar to that of set, the difference is that set is not automatically sorted, while sorted set can sort members by providing an additional priority (score) parameter by the user, and it is inserted in order, that is, automatic sorting . When you need an ordered and non-repeating set list, you can choose the sorted set data structure. For example, the public timeline of twitter can be stored with the publication time as the score, so that it is automatically sorted by time when it is obtained.
Method to realize:
The interior of Redis sorted set uses HashMap and SkipList to ensure the storage and ordering of data. HashMap stores the mapping from members to scores, and the skip list stores all members. The sorting is based on the storage in HashMap. The score, using the structure of the jump table can obtain relatively high search efficiency, and is relatively simple in implementation.
4.2.2 Redis Cluster
(1) High availability solution implemented by keepalived
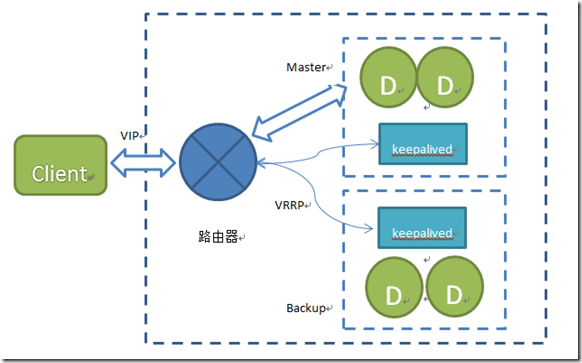
Switching process:
1. When the Master hangs up, the VIP drifts to the Slave; the keepalived on the Slave notifies redis to execute: slave of no one, start providing services
2. When the Master gets up, the VIP address does not change, the keepalived of the Master notifies redis to execute the slaveof slave IP host, and starts to synchronize data as the slave
3. And so on
Master-slave simultaneous Down machine situation:
1. Unplanned, without consideration, generally there is no such problem
2. Planned restart, save the main database data through operation and maintenance means before restarting; need to pay attention to the order:
1. Shut down all redis on one of the machines, so that the master must be switched to another machine (multi-instance deployment, both master and slave on a single machine); and shut down the machine
2. Dump the main redis service in turn
3. Close the main
4. Start the master and wait for the data load to complete
5. Start from
6. Delete the DUMP file (to avoid slow loading during restart)
(2) Use Twemproxy to implement a cluster solution
The C version proxy open sourced by twitter supports both memcached and redis. The latest version is: 0.2.4, which is under continuous development; https://github.com/twitter/twemproxy.twitter uses it mainly to reduce the network between the front end and the cache service number of connections.
Features: Fast, lightweight, reduces the number of back-end Cache Server connections, easy to configure, supports ketama, modula, random, and commonly used hash sharding algorithms.
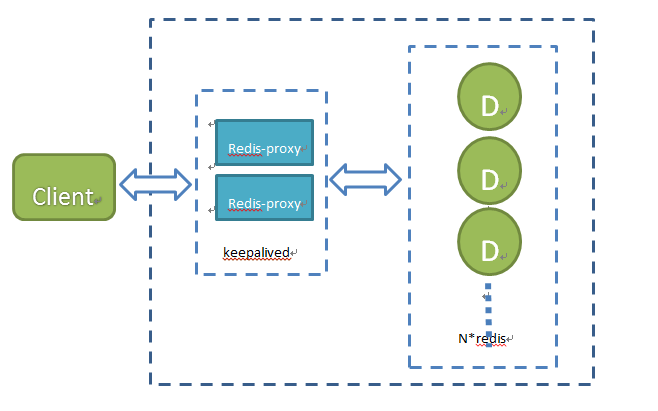
Here, keepalived is used to implement a high-availability master-standby solution to solve the proxy single-point problem;
advantage:
1. For the client, the redis cluster is transparent, the client is simple, and it is used for dynamic expansion.
2. When the Proxy is a single point and processes consistent hashing, there is no split-brain problem in cluster node availability detection
3. High performance, CPU-intensive, and the redis node cluster has redundant CPU resources, which can be deployed on the redis node cluster without additional equipment
4.3 Comparison between Memcache and Redis
(1) Data structure: Memcache only supports key value storage, Redis supports more data types, such as key value, hash, list, set, zset;
(2) Multithreading: Memcache supports multithreading, and redis supports single threading; Memcache is better than redis in terms of CPU utilization;
(3) Persistence: Memcache does not support persistence, and Redis supports persistence;
(4) Memory utilization: high memcache, low redis (higher than memcache in the case of compression);
(5) Expiration policy: After the memcache expires, if the cache is not deleted, it will lead to the problem of fetching the data next time. Redis has a special thread to clear the cached data;
5. Local cache
The local cache refers to the cache within the application, and the standard distributed system generally consists of multiple levels of caches. The local cache is the cache closest to the application and can generally cache data to the hard disk or memory.
3.1 Hard Disk Cache
Cache data to the hard disk, and read from the hard disk when reading. The principle is to directly read the local file, which reduces the network transmission consumption and is faster than reading the database through the network. It can be used in scenarios where the speed requirement is not very high, but a large amount of cache storage is required.
3.2 Memory cache
Directly storing data in the local memory and maintaining the cache object directly through the program is the fastest way to access.
6. Example of Cache Architecture
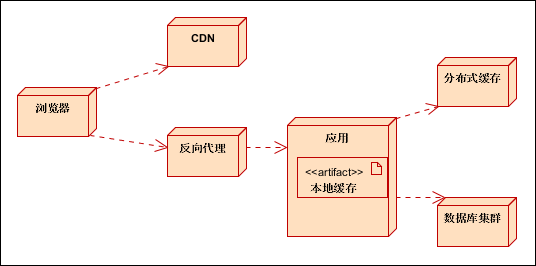
Division of Responsibilities:
- CDN: store HTML, CSS, JS and other static resources;
- Reverse proxy: separation of dynamic and static, only static resources requested by users are cached;
- Distributed cache: cache hot data in the database;
- Local cache: cache common data such as application dictionaries;
Request process:
(1) The browser initiates a request to the client, and returns directly if the CDN has a cache;
(2) If the CDN has no cache, access the reverse proxy server;
(3) If the reverse proxy server has a cache, it will return directly;
(4) If the reverse proxy server has no cache or dynamic request, access the application server;
(5) The application server accesses the local cache; if there is a cache, it returns to the proxy server and caches the data; (dynamic requests are not cached)
(6) If there is no data in the local cache, read the distributed cache; and return to the application server; the application server caches the data to the local cache (part);
(7) If there is no data in the distributed cache, the application reads the database data and puts it into the distributed cache;
Here I recommend an architecture learning exchange group to everyone. Communication and learning group number: 575745314 It will share some videos recorded by senior architects: Spring, MyBatis, Netty source code analysis, high concurrency, high performance, distributed, principles of microservice architecture, JVM performance optimization, distributed architecture, etc. These become the necessary knowledge system for architects. You can also receive free learning resources, which are currently benefiting a lot
7. Data Consistency
Cache is a node before data persistence. It mainly puts hot data in the medium closest to the user or has a faster access speed to speed up data access and reduce response time.
Because the cache is a copy of the persistent data, there will inevitably be data inconsistencies. A condition that results in dirty reads or data that cannot be read. Data inconsistency is generally caused by network instability or node failure. According to the order of operation of the data, there are mainly the following situations.
2.1 Scenario introduction
(1) Write the cache first, then write the database
As shown below:

If the cache write is successful, but the database write fails or the response is delayed, the next time the cache is read (concurrent read), a dirty read will occur;
(2) Write the database first, then write the cache
As shown below:

If writing to the database is successful, but writing to the cache fails, the next time the cache is read (concurrently read), the data will not be read;
(3) Cache asynchronous refresh
It means that the database operation and write cache are not in the same operation step. For example, in a distributed scenario, it is impossible to write to the cache at the same time or when asynchronous refresh (remedial measures) is required.

In this case, the timeliness of data writing and cache refresh is mainly considered. For example, how long to refresh the cache does not affect the user's access to the data.
2.2 Solution
First scene:
This way of writing the cache itself is wrong, and it needs to be changed to the way of writing to the persistent medium first, and then writing the cache.
Second scene:
(1) Judging based on the response written to the cache, if the cache write fails, the database operation will be rolled back; this method increases the complexity of the program and is not recommended;
(2) When the cache is used, if the read cache fails, the database is read first, and then the cache is written back.
Third scene:
(1) First determine which data is suitable for such scenarios;
(2) Determine the reasonable data inconsistency time and the time interval for user data refresh according to the empirical value;
2.3 Other methods
(1) Timeout: set a reasonable timeout;
(2) Refresh: regularly refresh the data within a certain range (according to time, version number);
The above is a simplified data read and write scenario, which will be divided into:
(1) Consistency between cache and database;
(2) Consistency before multi-level cache;
(3) Consistency before the cache copy.
Eight, cache high availability
There are two theories in the industry. The first set of cache is the cache, which temporarily stores data and does not require high availability. The second type of cache has gradually evolved into an important storage medium and needs to be highly available.
My opinion is that whether the cache is highly available depends on the actual scenario. The critical point is whether there is an impact on the back-end database.
The specific decision-making basis needs to be comprehensively evaluated based on the scale of the cluster (data, cache), cost (server, operation and maintenance), system performance (concurrency, throughput, response time) and other aspects.
3.1 Solution
The high availability of the cache is generally achieved through distribution and replication. Distributed implementation of massive data cache, replication to achieve high availability of cached data nodes. The architecture diagram is as follows:

Among them, the distributed adopts the consistent Hash algorithm, and the replication adopts asynchronous replication.
3.2 Other methods
(1) Copy double write: The copy of the cache node is changed from asynchronous to double write. Only when both copies are successfully written can it be considered successful.
(2) Virtual layer: Consistent HASH exists. If one of the HASH rings is unavailable, the data will be written to the adjacent ring. When the HASH is available, the data will be written to the normal HASH ring, which will cause data offset problems. In this case, you can consider adding a virtual layer in front of the HASH ring.
(3) Multi-level cache: For example, the first level uses local cache, the second level uses distributed cache, and the third level uses distributed Cache + local persistence;
There are many ways, which need to be flexibly selected according to business scenarios.
9. Cache Avalanche
Avalanche refers to a situation in which a large number of requests access the database when a large number of caches are invalidated, causing the database server to be unable to withstand the request or to hang.
Solution:
(1) Reasonably plan the expiration time of the cache;
(2) Reasonably evaluate the load pressure of the database;
(3) Overload protection for the database or current limiting at the application layer;
(4) Multi-level cache design, high cache availability;
10. Cache penetration
The cache is generally in the form of key and value. When a certain key does not exist, the database will be queried. If the key does not exist all the time, the database will be frequently requested, causing access pressure to the database.
Solution:
(1) Cache the data whose result is empty. When the key has data, clear the cache;
(2) For the key that must not exist, use the Bloom filter to create a large Bitmap, and filter through the bitmap when querying;